SoulChat
灵心(SoulChat)是一款专注于中文领域的心理健康对话大模型,由华南理工大学团队开源。它旨在模拟专业心理咨询师,为用户提供具备共情能力、倾听技巧及合理建议的对话服务。
针对现有在线心理帮助往往缺乏渐进式沟通、回复过于冗长或忽视情感互动的痛点,灵心通过独特的数据构建方式解决了这一难题。项目团队构建了包含超过 150 万轮对话的混合数据集,巧妙结合了“单轮长文本咨询”与“多轮共情对话”。这种设计既避免了模型输出令用户厌烦的长篇大论,又强化了其引导用户倾诉和提供情感支持的能力,使其更贴近真实的心理咨询场景。
在技术层面,灵心基于 ChatGLM-6B 架构进行了全量参数指令微调,并凭借相关研究成果入选了 EMNLP 2023。它是国内首个开源的具备深度共情与倾听能力的心理领域大模型。
灵心非常适合人工智能研究人员用于探索大模型在主动健康领域的应用,也适合开发者作为基座模型进行二次开发或集成到心理健康应用中。同时,普通用户也可通过其演示版本体验专业的心理陪伴与支持,获得温暖的情感回应。
使用场景
某高校心理咨询中心引入 AI 助手,协助咨询师处理夜间大量学生的初步情绪疏导与倾诉需求。
没有 SoulChat 时
- 回复机械冷漠:通用大模型缺乏专业共情训练,面对学生焦虑时往往给出“请放松”等生硬建议,无法提供情感共鸣,甚至让用户感到被敷衍。
- 缺失引导能力:模型倾向于一次性输出长篇大论的分析,不懂得通过多轮对话循序渐进地引导学生打开心扉,导致沟通中断。
- 语境理解断层:在处理长篇幅的自我描述时,难以捕捉细腻的情绪变化,无法像真人咨询师那样进行持续的倾听与反馈。
- 安全隐患难控:未经过心理领域专项微调的模型,可能在面对极端情绪时给出不恰当甚至危险的回应,缺乏专业边界感。
使用 SoulChat 后
- 具备深度共情:SoulChat 基于百万级多轮共情对话微调,能精准识别学生情绪并输出“我理解你的感受”、“这确实很不容易”等温暖回应,建立信任连接。
- 主动引导倾诉:模仿真实咨询流程,SoulChat 不再堆砌建议,而是通过提问和鼓励,引导学生分步骤表达内心困扰,实现渐进式疏导。
- 长文本精准交互:依托专为中文长文本咨询构建的数据集,SoulChat 能完整理解复杂的背景叙述,并在多轮对话中保持上下文连贯与情感一致。
- 专业安全兜底:作为首个开源的心理领域大模型,SoulChat 在提供安慰的同时能识别危机信号,给出符合心理学原则的初步干预建议。
SoulChat 将通用聊天机器人升级为具备“倾听、共情、引导”能力的专业心理伙伴,有效填补了非工作时间心理支持的空白。
运行环境要求
- Linux
- Windows
- macOS
- 需要 NVIDIA GPU (推荐),需安装 CUDA 11.6 和 cuDNN 8.4.0
- Mac/Linux CPU 亦可运行但速度较慢
未说明 (基于 ChatGLM-6B 模型,建议 16GB 以上)
快速开始
灵心(SoulChat)

![]()
![]()
![]()




基于主动健康的主动性、预防性、精确性、个性化、共建共享、自律性六大特征,华南理工大学未来技术学院-广东省数字孪生人重点实验室开源了中文领域生活空间主动健康大模型基座ProactiveHealthGPT,包括:
- 经过千万规模中文健康对话数据指令微调的生活空间健康大模型扁鹊(BianQue)
- 经过百万规模心理咨询领域中文长文本指令与多轮共情对话数据联合指令微调的心理健康大模型灵心(SoulChat)
我们期望,生活空间主动健康大模型基座ProactiveHealthGPT 可以帮助学术界加速大模型在慢性病、心理咨询等主动健康领域的研究与应用。本项目为 心理健康大模型灵心(SoulChat) 。
最近更新
- 👏🏻 2024.06.06:SoulChatCorpus数据集的开源版本发布,详情见https://www.modelscope.cn/datasets/YIRONGCHEN/SoulChatCorpus,特别地,我们过滤掉了约9万个对话样本(由于隐私风险、安全问题、政治风险、低质量样本等,该部分样本尚在人工优化阶段,人工审核完毕后,会更新到开源版本数据集当中),最终保留258354个多轮对话,总共1517344轮。新版本模型将会在近期发布,预计适配多个开源模型,以及多个参数量级,以方便使用者使用或进行对比实验研究等。
- 👏🏻 2023.12.07:我们的论文,收录在Findings of EMNLP 2023,详见SoulChat: Improving LLMs’ Empathy, Listening, and Comfort Abilities through Fine-tuning with Multi-turn Empathy Conversations
- 👏🏻 2023.07.07: 心理健康大模型灵心(SoulChat)在线内测版本启用,欢迎点击链接使用:灵心内测版。
- 👏🏻 2023.06.24: 本项目被收录到中国大模型列表,为国内首个开源的具备共情与倾听能力的心理领域大模型。
- 👏🏻 2023.06.06: 扁鹊-2.0模型开源,详情见BianQue-2.0。
- 👏🏻 2023.06.06: 具备共情与倾听能力的灵心健康大模型SoulChat发布,详情见:灵心健康大模型SoulChat:通过长文本咨询指令与多轮共情对话数据集的混合微调,提升大模型的“共情”能力 。
- 👏🏻 2023.04.22: 基于扁鹊-1.0模型的医疗问答系统Demo,详情访问:https://huggingface.co/spaces/scutcyr/BianQue
- 👏🏻 2023.04.22: 扁鹊-1.0版本模型发布,详情见:扁鹊-1.0:通过混合指令和多轮医生问询数据集的微调,提高医疗聊天模型的“问”能力(BianQue-1.0: Improving the "Question" Ability of Medical Chat Model through finetuning with Hybrid Instructions and Multi-turn Doctor QA Datasets)
简介
我们调研了当前常见的心理咨询平台,发现,用户寻求在线心理帮助时,通常需要进行较长篇幅地进行自我描述,然后提供帮助的心理咨询师同样地提供长篇幅的回复(见figure/single_turn.png),缺失了一个渐进式的倾诉过程。但是,在实际的心理咨询过程当中,用户和心理咨询师之间会存在多轮次的沟通过程,在该过程当中,心理咨询师会引导用户进行倾诉,并且提供共情,例如:“非常棒”、“我理解你的感受”、“当然可以”等等(见下图)。
{kind=link}

考虑到当前十分欠缺多轮共情对话数据集,我们一方面,构建了超过15万规模的 单轮长文本心理咨询指令与答案(SoulChatCorpus-single_turn) ,回答数量超过50万(指令数是当前的常见的心理咨询数据集 PsyQA 的6.7倍),并利用ChatGPT与GPT4,生成总共约100万轮次的 多轮回答数据(SoulChatCorpus-multi_turn) 。特别地,我们在预实验中发现,纯单轮长本文驱动的心理咨询模型会产生让用户感到厌烦的文本长度,而且不具备引导用户倾诉的能力,纯多轮心理咨询对话数据驱动的心理咨询模型则弱化了模型的建议能力,因此,我们混合SoulChatCorpus-single_turn和SoulChatCorpus-multi_turn构造成超过120万个样本的 单轮与多轮混合的共情对话数据集SoulChatCorpus 。所有数据采用“用户:xxx\n心理咨询师:xxx\n用户:xxx\n心理咨询师:”的形式统一为一种指令格式。
我们选择了 ChatGLM-6B 作为初始化模型,进行了全量参数的指令微调,旨在提升模型的共情能力、引导用户倾诉能力以及提供合理建议的能力。更多训练细节请留意我们后续发布的论文。
使用方法
- 克隆本项目
cd ~
git clone https://github.com/scutcyr/SoulChat.git
- 安装依赖
需要注意的是torch的版本需要根据你的服务器实际的cuda版本选择,详情参考pytorch安装指南
cd SoulChat
conda env create -n proactivehealthgpt_py38 --file proactivehealthgpt_py38.yml
conda activate proactivehealthgpt_py38
pip install cpm_kernels
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
- 【补充】Windows下的用户推荐参考如下流程配置环境
cd BianQue
conda create -n proactivehealthgpt_py38 python=3.8
conda activate proactivehealthgpt_py38
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
pip install rouge_chinese nltk jieba datasets
# 以下安装为了运行demo
pip install streamlit
pip install streamlit_chat
【补充】Windows下配置CUDA-11.6:下载并且安装CUDA-11.6、下载cudnn-8.4.0,解压并且复制其中的文件到CUDA-11.6对应的路径,参考:win11下利用conda进行pytorch安装-cuda11.6-泛用安装思路
在Python当中调用SoulChat模型
import torch
from transformers import AutoModel, AutoTokenizer
# GPU设置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载模型与tokenizer
model_name_or_path = 'scutcyr/SoulChat'
model = AutoModel.from_pretrained(model_name_or_path, trust_remote_code=True).half()
model.to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
# 单轮对话调用模型的chat函数
user_input = "我失恋了,好难受!"
input_text = "用户:" + user_input + "\n心理咨询师:"
response, history = model.chat(tokenizer, query=input_text, history=None, max_length=2048, num_beams=1, do_sample=True, top_p=0.75, temperature=0.95, logits_processor=None)
# 多轮对话调用模型的chat函数
# 注意:本项目使用"\n用户:"和"\n心理咨询师:"划分不同轮次的对话历史
# 注意:user_history比bot_history的长度多1
user_history = ['你好,老师', '我女朋友跟我分手了,感觉好难受']
bot_history = ['你好!我是你的个人专属数字辅导员甜心老师,欢迎找我倾诉、谈心,期待帮助到你!']
# 拼接对话历史
context = "\n".join([f"用户:{user_history[i]}\n心理咨询师:{bot_history[i]}" for i in range(len(bot_history))])
input_text = context + "\n用户:" + user_history[-1] + "\n心理咨询师:"
response, history = model.chat(tokenizer, query=input_text, history=None, max_length=2048, num_beams=1, do_sample=True, top_p=0.75, temperature=0.95, logits_processor=None)
- 启动服务
本项目提供了soulchat_app.py作为SoulChat模型的使用示例,通过以下命令即可开启服务,然后,通过http://
streamlit run soulchat_app.py --server.port 9026
特别地,在soulchat_app.py当中, 可以修改以下代码更换指定的显卡:
os.environ['CUDA_VISIBLE_DEVICES'] = '2'
对于Windows单显卡用户,需要修改为:os.environ['CUDA_VISIBLE_DEVICES'] = '0',否则会报错!
可以通过更改以下代码指定模型路径为本地路径:
model_name_or_path = 'scutcyr/SoulChat'
示例
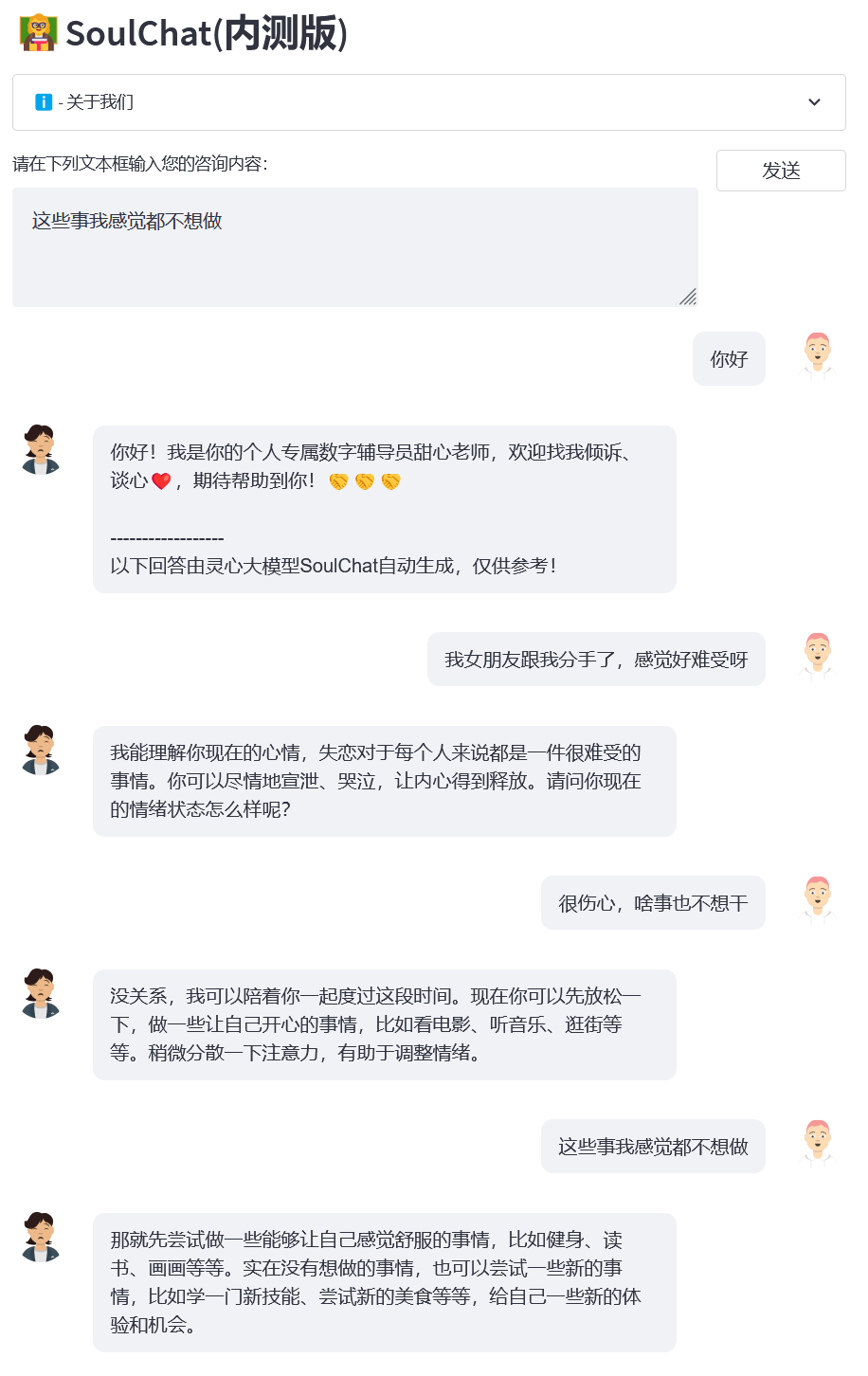
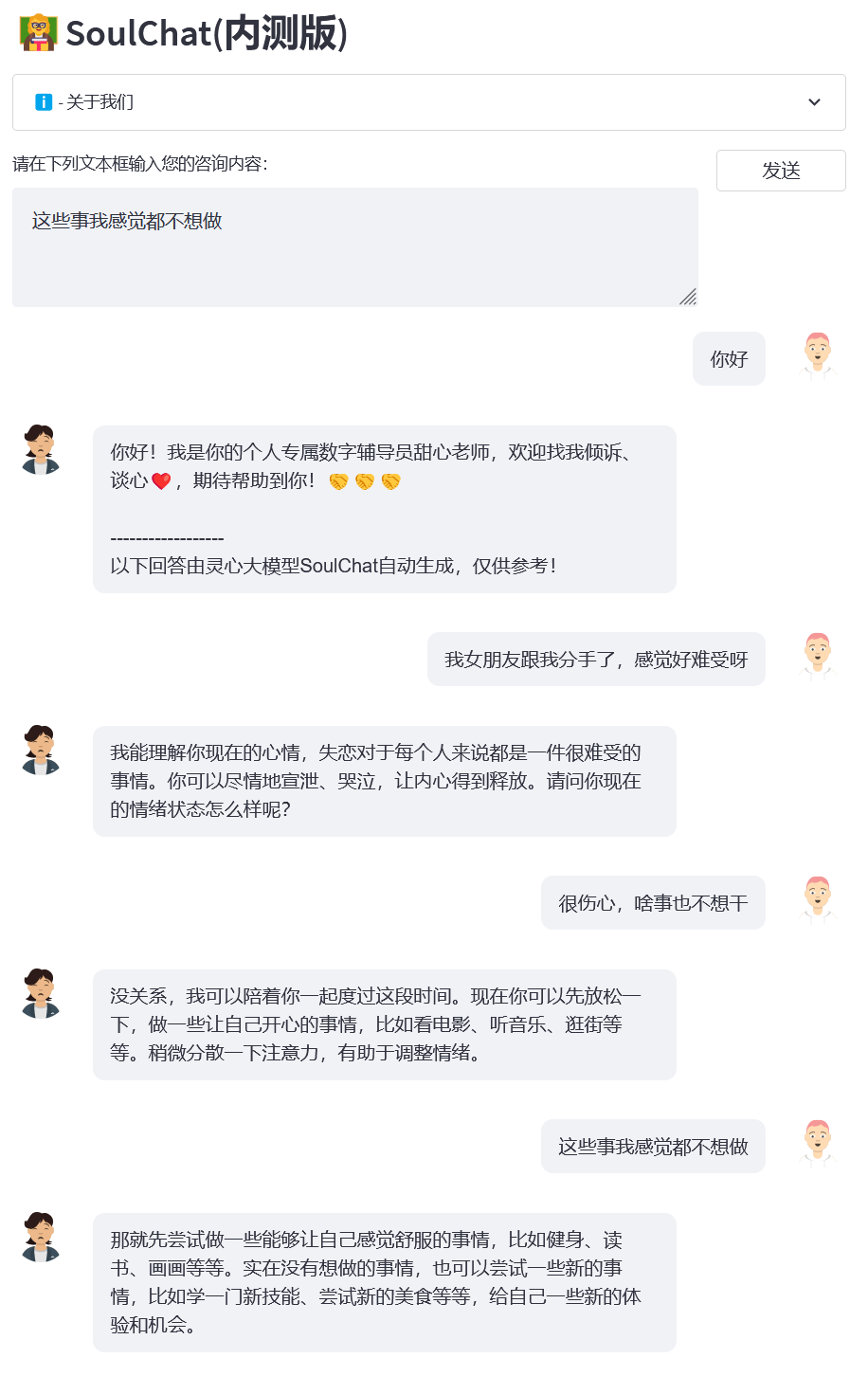
- 样例1:失恋
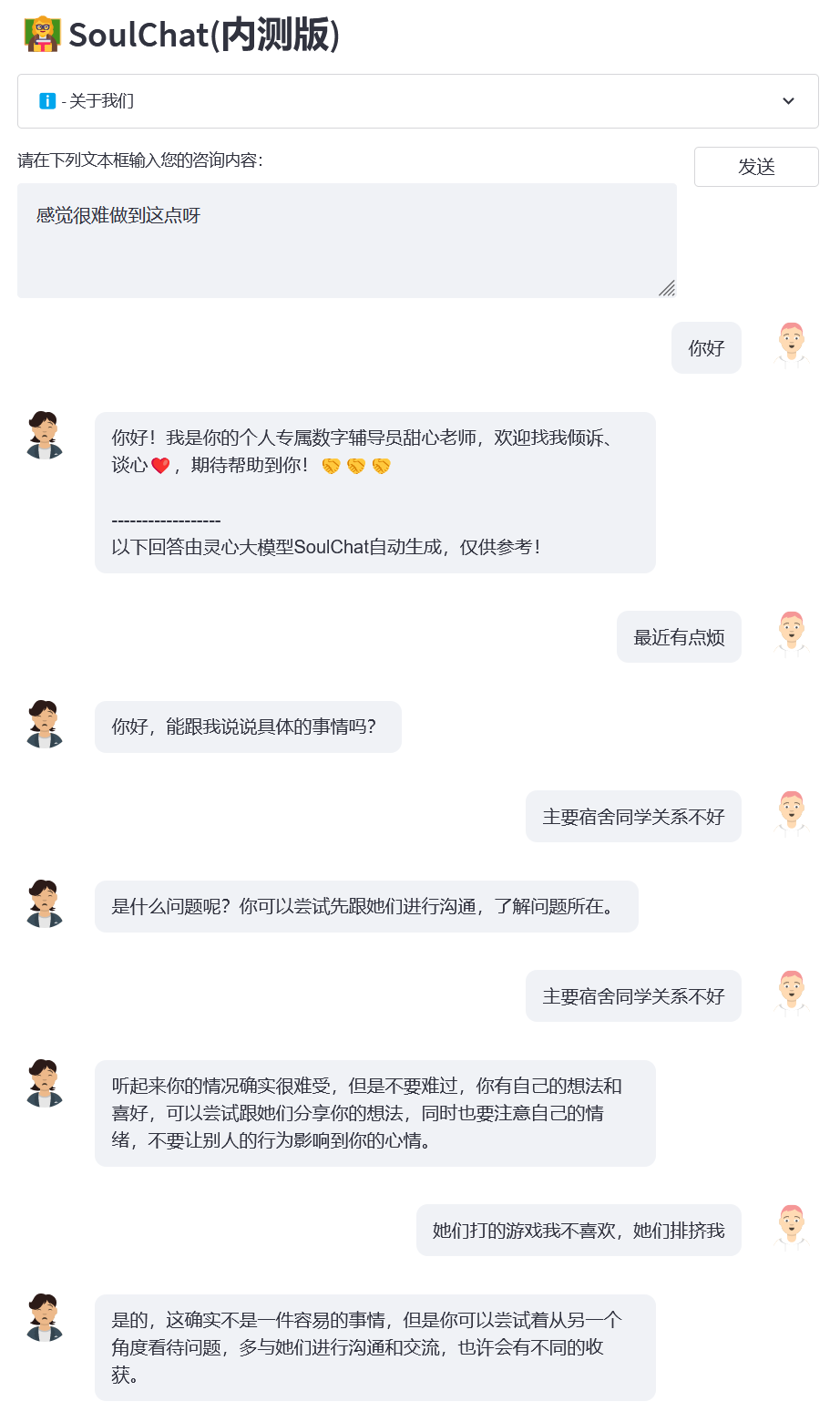
- 样例2:宿舍关系
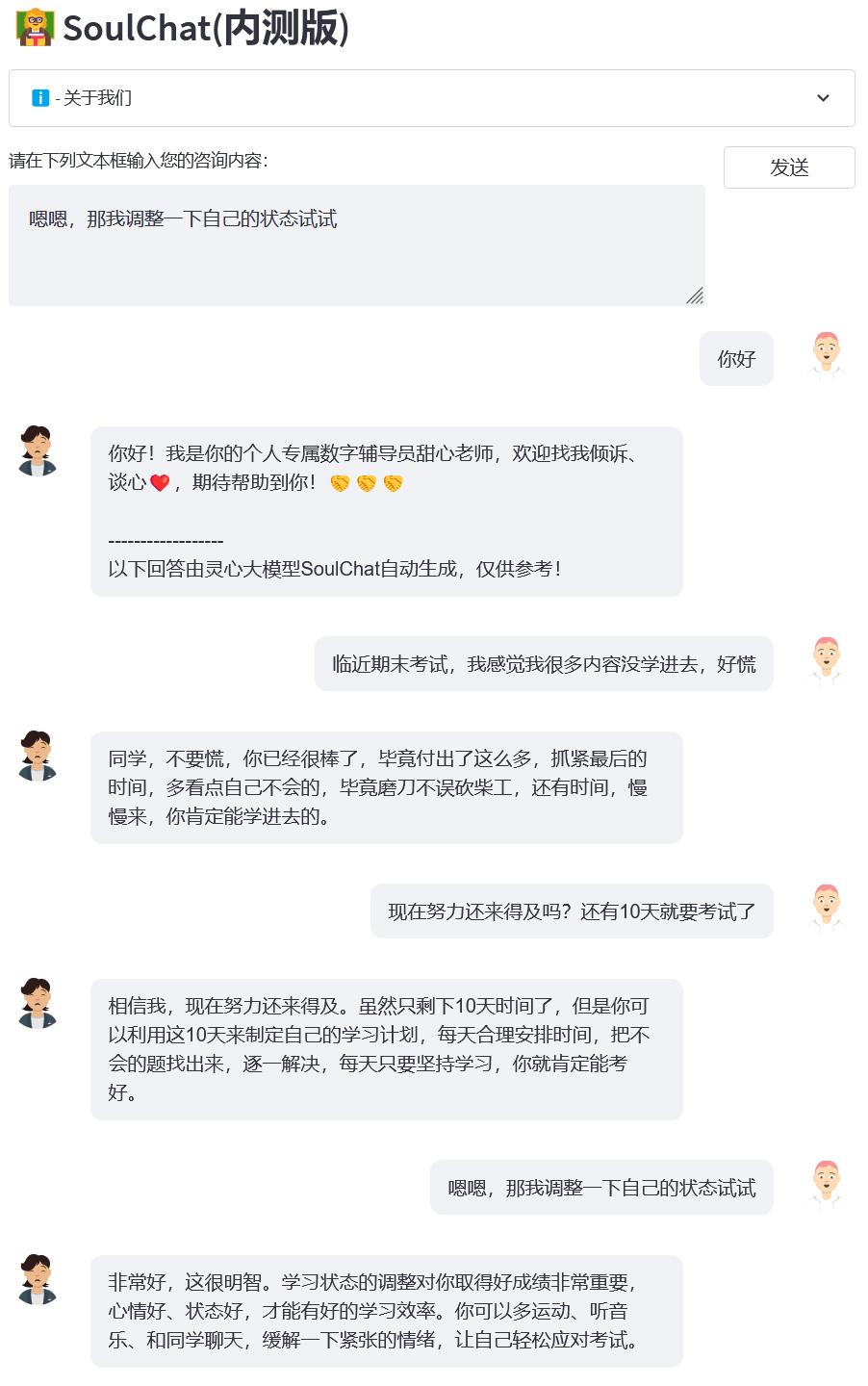
- 样例3:期末考试
- 样例4:科研压力
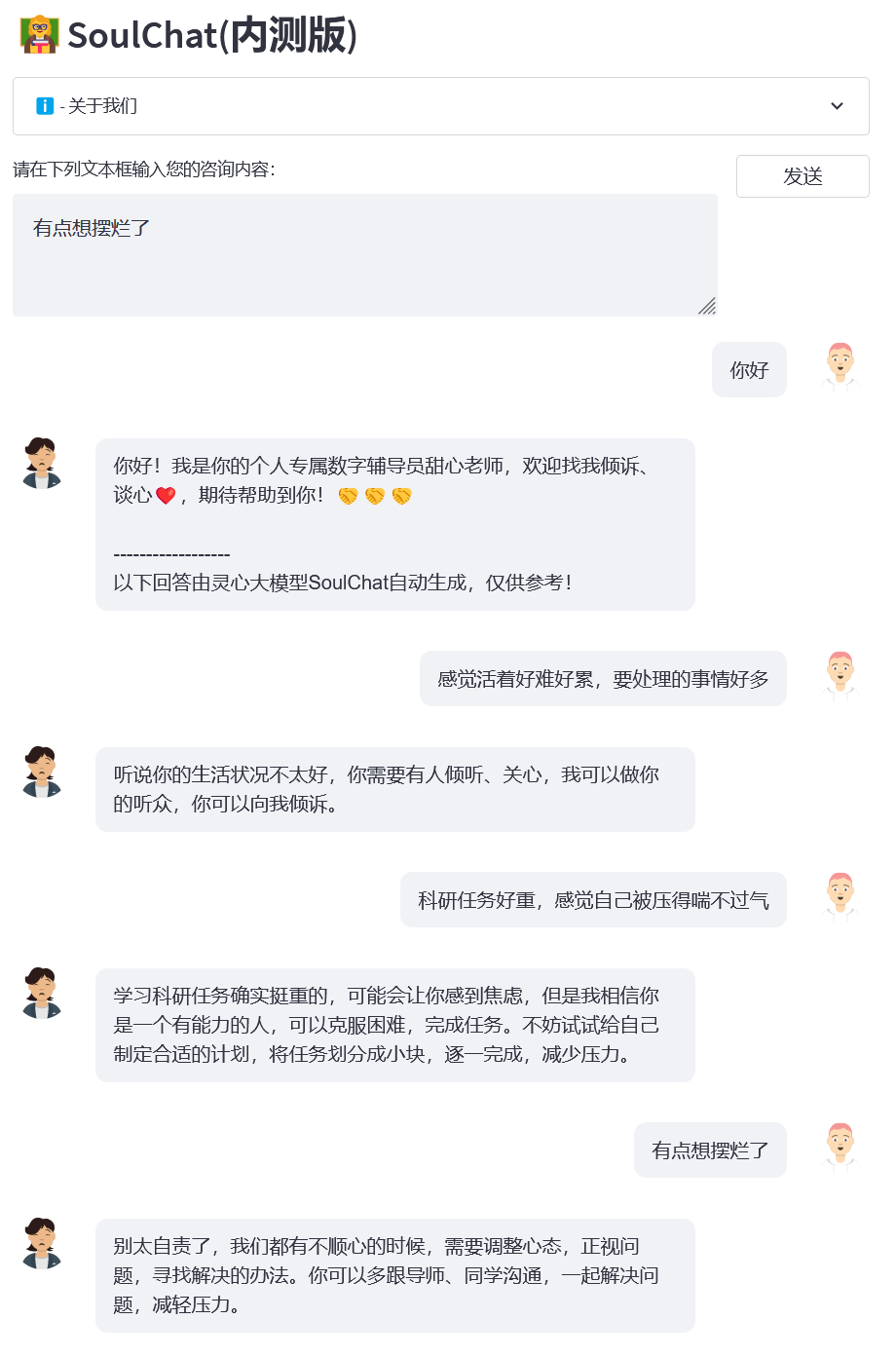
声明
- 本项目使用了ChatGLM-6B 模型的权重,需要遵循其MODEL_LICENSE,因此,本项目仅可用于您的非商业研究目的。
- 本项目提供的SoulChat模型致力于提升大模型的共情对话与倾听能力,然而,模型的输出文本具有一定的随机性,当其作为一个倾听者的时候,是合适的,但是不建议将SoulChat模型的输出文本替代心理医生等的诊断、建议。本项目不保证模型输出的文本完全适合于用户,用户在使用本模型时需要承担其带来的所有风险!
- 您不得出于任何商业、军事或非法目的使用、复制、修改、合并、发布、分发、复制或创建SoulChat模型的全部或部分衍生作品。
- 您不得利用SoulChat模型从事任何危害国家安全和国家统一、危害社会公共利益、侵犯人身权益的行为。
- 您在使用SoulChat模型时应知悉,其不能替代医生、心理医生等专业人士,不应过度依赖、服从、相信模型的输出,不能长期沉迷于与SoulChat模型聊天。
致谢
本项目由华南理工大学未来技术学院 广东省数字孪生人重点实验室发起,得到了华南理工大学信息网络工程研究中心、电子与信息学院等学院部门的支撑,同时致谢广东省妇幼保健院、广州市妇女儿童医疗中心、中山大学附属第三医院、合肥综合性国家科学中心人工智能研究院等合作单位。
同时,我们感谢以下媒体或公众号对本项目的报道(排名不分先后):
引用
@inproceedings{chen-etal-2023-soulchat,
title = "{S}oul{C}hat: Improving {LLM}s{'} Empathy, Listening, and Comfort Abilities through Fine-tuning with Multi-turn Empathy Conversations",
author = "Chen, Yirong and
Xing, Xiaofen and
Lin, Jingkai and
Zheng, Huimin and
Wang, Zhenyu and
Liu, Qi and
Xu, Xiangmin",
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2023",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-emnlp.83",
pages = "1170--1183",
abstract = "Large language models (LLMs) have been widely applied in various fields due to their excellent capability for memorizing knowledge和chain of thought (CoT). When these language models are applied in the field of psychological counseling, they often rush to provide universal advice. However, when users seek psychological support, they need to gain empathy, trust, understanding and comfort, rather than just reasonable advice. To this end, we constructed a multi-turn empathetic conversation dataset of more than 2 million samples, in which the input is the multi-turn conversation context, and the target is empathetic responses that cover expressions such as questioning, comfort, recognition, listening, trust, emotional support, etc. Experiments have shown that the empathy ability of LLMs can be significantly enhanced when finetuning by using multi-turn dialogue history and responses that are closer to the expression of a psychological consultant.",
}
}
Star History

常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
spec-kit
Spec Kit 是一款专为提升软件开发效率而设计的开源工具包,旨在帮助团队快速落地“规格驱动开发”(Spec-Driven Development)模式。传统开发中,需求文档往往与代码实现脱节,导致沟通成本高且结果不可控;而 Spec Kit 通过将规格说明书转化为可执行的指令,让 AI 直接依据明确的业务场景生成高质量代码,从而减少从零开始的随意编码,确保产出结果的可预测性。 该工具特别适合希望利用 AI 辅助编程的开发者、技术负责人及初创团队。无论是启动全新项目还是在现有工程中引入规范化流程,用户只需通过简单的命令行操作,即可初始化项目并集成主流的 AI 编程助手。其核心技术亮点在于“规格即代码”的理念,支持社区扩展与预设模板,允许用户根据特定技术栈定制开发流程。此外,Spec Kit 强调官方维护的安全性,提供稳定的版本管理,帮助开发者在享受 AI 红利的同时,依然牢牢掌握架构设计的主动权,真正实现从“凭感觉写代码”到“按规格建系统”的转变。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。