gollama
gollama 是一款专为 macOS 和 Linux 用户打造的命令行管理工具,旨在帮助用户更高效地打理本地运行的 Ollama 大语言模型。面对日益增多的模型文件,手动通过命令查看、删除或整理往往繁琐且容易出错,gollama 通过提供直观的文字用户界面(TUI),让模型管理变得像操作列表一样简单。
这款工具特别适合经常使用 Ollama 的开发者、AI 研究人员以及技术爱好者。它不仅能列出所有可用模型,还能清晰展示模型大小、量化等级、家族类型及修改日期等关键元数据。用户只需通过键盘快捷键,即可轻松完成模型的排序、筛选、运行、卸载、复制、重命名甚至直接编辑 Modelfile 等操作。此外,gollama 还具备估算显存(vRAM)占用和推送模型到仓库等实用功能,极大地提升了清理旧模型和调试环境的效率。
值得一提的是,尽管项目维护节奏有所调整,但其核心的交互式操作体验依然出色,让复杂的模型运维工作变得更加直观可控。如果你希望在终端中以更优雅的方式掌控本地的 AI 模型资源,gollama 是一个值得尝试的得力助手。
使用场景
一位本地 AI 开发者在 macOS 上长期运行 Ollama 进行模型实验,随着测试迭代,本地积累了数十个不同版本和量化等级的模型文件。
没有 gollama 时
- 清理困难:删除旧模型需逐个输入冗长的
ollama rm命令,无法批量操作,清理磁盘空间效率极低。 - 信息黑盒:难以直观对比模型的大小、量化等级或修改时间,常因记错名称而误删重要模型或重复下载。
- 调试繁琐:查看模型详细元数据或估算显存占用时,需手动查阅文档或编写脚本计算,打断开发心流。
- 管理混乱:缺乏排序和过滤功能,在模型列表过长时,寻找特定家族(如 Llama3 或 Mistral)的模型如同大海捞针。
使用 gollama 后
- 一键清理:通过 TUI 界面用空格键多选过期模型,按
D键即可批量删除,瞬间释放数十 GB 存储空间。 - 全景可视:列表直接展示大小、量化级别及修改日期,支持按这些维度排序,模型状态一目了然,杜绝误操作。
- 即时洞察:选中模型按
i键即刻 inspect 详细信息,并自动计算近似显存占用,快速判断当前硬件能否加载。 - 高效流转:利用快捷键轻松复制、重命名模型或编辑 Modelfile,甚至直接推送至 registry,模型迭代流程丝滑顺畅。
gollama 将原本碎片化、命令行式的模型运维工作,转化为直观的交互式管理体验,极大提升了本地大模型开发的效率与安全性。
运行环境要求
- macOS
- Linux
- 非必需
- 工具本身用于管理模型,不直接运行推理
- 其显存估算功能可自动检测可用的 CUDA 显存,若无 GPU 则使用系统内存进行计算
未说明(取决于所管理的 Ollama 模型大小及宿主系统需求)

快速开始
Gollama

Gollama 是一款用于管理 Ollama 模型的 macOS / Linux 工具。
它提供了一个文本用户界面(TUI),用于列出、检查、删除、复制和推送 Ollama 模型。
该应用程序允许用户通过热键交互式地选择模型、排序、过滤、编辑、运行、卸载以及对模型执行其他操作。
目录
特性
Gollama 是一款具有易用界面的 Ollama 模型管理工具。
目前仍在积极开发中,因此可能存在一些 bug 和缺失的功能。不过,我每天都在使用它来管理我的模型,尤其是在清理旧模型时非常有用。
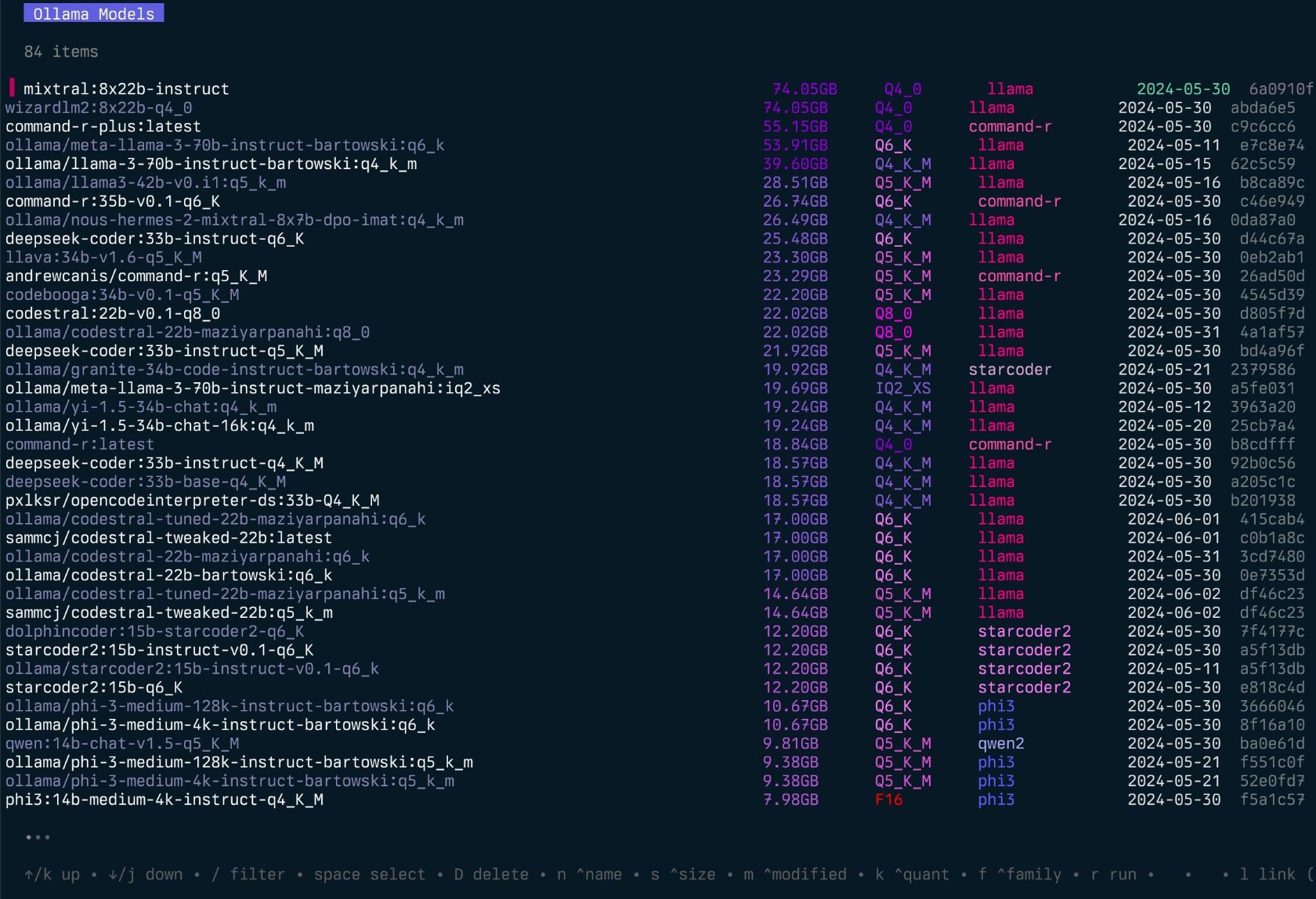
- 列出可用的模型
- 显示元数据,如大小、量化级别、模型家族和修改日期
- 编辑/更新模型的 Modelfile
- 按名称、大小、修改日期、量化级别、家族等对模型进行排序
- 选择并删除模型
- 运行和卸载模型
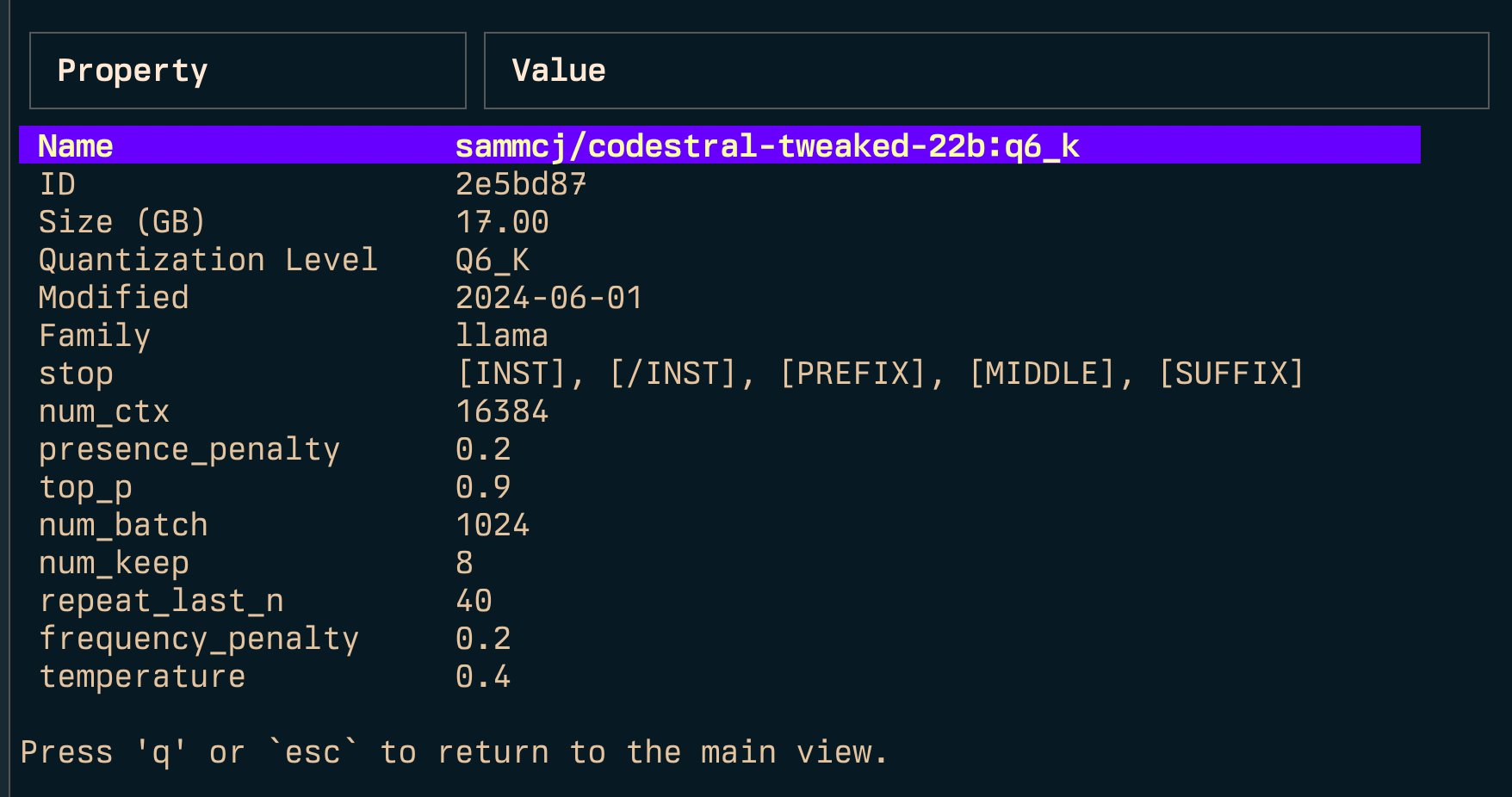
- 检查模型以获取更多详细信息
- 计算模型的大致 vRAM 使用量
- 复制/重命名模型
- 将模型推送到注册表
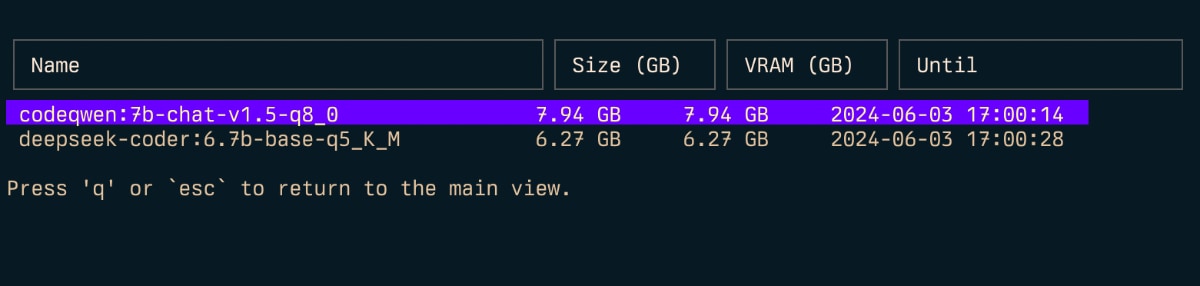
- 显示正在运行的模型
- 有一些有趣的 bug
另请参阅 - ingest,用于将代码目录/仓库转换为适合 LLM 的 Markdown 格式。
更新 [2025-12-02]:移除 LM Studio 链接功能及 Gollama 维护放缓
自 Gollama 的 v2.0.1 版本 发布以来,LM Studio 链接功能将不再可用。
与 LM Studio 之间的链接维护起来越来越麻烦,得不偿失。由于上游应用程序不断变化,同时还要适应每个用户的本地配置,这让我投入了过多的时间去维护一个我很少使用的功能。
我自己现在也不再频繁使用 Ollama 了。这也导致开发进度放缓,因为我把精力放在了其他项目上。
我曾是 Ollama 的早期采用者和贡献者,但到了 2025 年,我对 Ollama 的价值已经大不如前,几乎不再使用它。对于模型推理服务,我主要转向了使用 llama.cpp,并结合 llama-swap 来运行。过去一年里,llama.cpp 变得更加易用,项目维护良好,配置更简单,功能也多了很多,性能更是显著提升。而在笔记本电脑上运行模型时,我则使用 LM Studio,因为它既支持 MLX 模型,也支持标准的 llama.cpp 运行时来处理 GGUF 模型。
安装
go install(推荐)
go install github.com/sammcj/gollama/v2@latest
curl
我不建议使用这种方法,因为它不易于更新,但你也可以使用以下命令:
curl -sL https://raw.githubusercontent.com/sammcj/gollama/refs/heads/main/scripts/install.sh | bash
手动安装
从 发布页面 下载最新版本,然后将二进制文件解压到你的 PATH 中的一个目录。
例如:zip -d gollama*.zip -d gollama && mv gollama /usr/local/bin
如果出现“command not found: gollama”
如果看到此错误,请在 .zshrc 或 .bashrc 中添加环境变量。
echo 'export PATH=$PATH:$HOME/go/bin' >> ~/.zshrc
source ~/.zshrc
使用
要运行 gollama 应用程序,可以使用以下命令:
gollama
提示:我喜欢将 gollama 设置为 g 的别名,以便快速访问:
echo "alias g=gollama" >> ~/.zshrc
快捷键
Space: 选择Enter: 运行模型(Ollama run)i: 检查模型t: Top(显示正在运行的模型)D: 删除模型e: 编辑模型c: 复制模型U: 卸载所有模型p: 拉取现有模型ctrl+k: 拉取模型并保留用户配置ctrl+p: 拉取新模型P: 推送模型n: 按名称排序s: 按大小排序m: 按修改日期排序k: 按量化级别排序f: 按家族排序B: 按参数量排序r: 重命名模型 (正在进行中)q: 退出
Top
Top (t)
检查
Inspect (i)
命令行选项
模型管理:
-l: 列出所有可用的 Ollama 模型并退出-s <search term>: 按名称搜索模型- OR 运算符(
'term1|term2')返回匹配任一术语的模型 - AND 运算符(
'term1&term2')返回同时匹配两个术语的模型
- OR 运算符(
-e <model>: 编辑模型的 Modelfile-u: 卸载所有正在运行的模型-v: 打印版本号并退出
配置:
-h或--host: 指定 Ollama API 的主机-H:-h http://localhost:11434的快捷方式(连接到本地 Ollama API)--ollama-dir: 自定义 Ollama 模型目录--log或--log-level: 覆盖日志级别(debug、info、warn、error)
清理:
--no-cleanup: 不清理损坏的符号链接
vRAM 分析:
--vram: 估算模型的 vRAM 使用量。接受:- Ollama 模型(如
llama3.1:8b-instruct-q6_K、qwen2:14b-q4_0) - HuggingFace 模型(如
NousResearch/Hermes-2-Theta-Llama-3-8B) --fits: 可用内存(GB)用于上下文计算(如6表示 6GB)--vram-to-nth或--context: 最大上下文长度(如32k或128k)--quant: 覆盖量化级别(如Q4_0、Q5_K_M)
- Ollama 模型(如
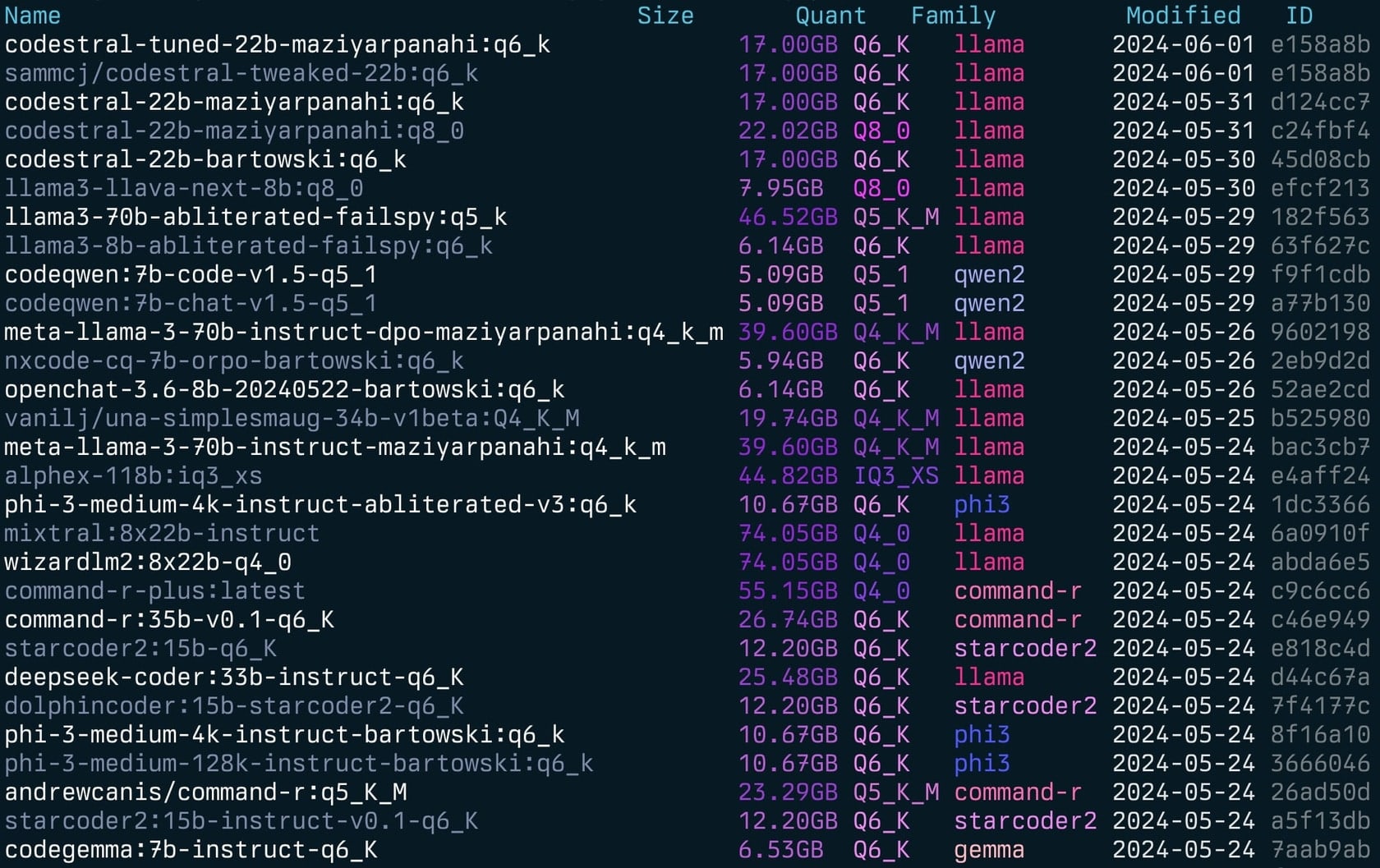
简单的模型列表
Gollama 也可以通过 -l 命令调用,以不使用 TUI 的方式列出模型。
gollama -l
列表(gollama -l):
编辑
Gollama 可以通过 -e 命令调用,以编辑某个模型的 Modelfile。
gollama -e my-model
搜索
Gollama 可以通过 -s 命令调用,以按名称搜索模型。
gollama -s my-model # 返回包含 'my-model' 的模型
gollama -s 'my-model|my-other-model' # 返回包含 'my-model' 或 'my-other-model' 的模型
gollama -s 'my-model&instruct' # 返回同时包含 'my-model' 和 'instruct' 的模型
vRAM 估计
Gollama 包含全面的 vRAM 估计功能:
- 计算已拉取的 Ollama 模型(如
my-model:mytag)或 HuggingFace 模型 ID(如author/name)的 vRAM 使用量 - 根据给定的 vRAM 限制确定最大上下文长度
- 在给定的 vRAM 和上下文限制下找到最佳量化设置
- 显示不同 k/v 缓存量化选项的估算值(fp16、q8_0、q4_0)
- 自动检测可用的 CUDA vRAM(即将推出!)或系统 RAM
要估算 vRAM 使用量:
gollama --vram llama3.1:8b-instruct-q6_K
📊 VRAM Estimation for Model: llama3.1:8b-instruct-q6_K
| 量化 | 上下文 | BPW | 2K | 8K | 16K | 32K | 49K | 64K |
| ------- | ---- | --- | --- | --------------- | --------------- | --------------- | --------------- |
| IQ1_S | 1.56 | 2.2 | 2.8 | 3.7(3.7,3.7) | 5.5(5.5,5.5) | 7.3(7.3,7.3) | 9.1(9.1,9.1) |
| IQ2_XXS | 2.06 | 2.6 | 3.3 | 4.3(4.3,4.3) | 6.1(6.1,6.1) | 7.9(7.9,7.9) | 9.8(9.8,9.8) |
| IQ2_XS | 2.31 | 2.9 | 3.6 | 4.5(4.5,4.5) | 6.4(6.4,6.4) | 8.2(8.2,8.2) | 10.1(10.1,10.1) |
| IQ2_S | 2.50 | 3.1 | 3.8 | 4.7(4.7,4.7) | 6.6(6.6,6.6) | 8.5(8.5,8.5) | 10.4(10.4,10.4) |
| IQ2_M | 2.70 | 3.2 | 4.0 | 4.9(4.9,4.9) | 6.8(6.8,6.8) | 8.7(8.7,8.7) | 10.6(10.6,10.6) |
| IQ3_XXS | 3.06 | 3.6 | 4.3 | 5.3(5.3,5.3) | 7.2(7.2,7.2) | 9.2(9.2,9.2) | 11.1(11.1,11.1) |
| IQ3_XS | 3.30 | 3.8 | 4.5 | 5.5(5.5,5.5) | 7.5(7.5,7.5) | 9.5(9.5,9.5) | 11.4(11.4,11.4) |
| Q2_K | 3.35 | 3.9 | 4.6 | 5.6(5.6,5.6) | 7.6(7.6,7.6) | 9.5(9.5,9.5) | 11.5(11.5,11.5) |
| Q3_K_S | 3.50 | 4.0 | 4.8 | 5.7(5.7,5.7) | 7.7(7.7,7.7) | 9.7(9.7,9.7) | 11.7(11.7,11.7) |
| IQ3_S | 3.50 | 4.0 | 4.8 | 5.7(5.7,5.7) | 7.7(7.7,7.7) | 9.7(9.7,9.7) | 11.7(11.7,11.7) |
| IQ3_M | 3.70 | 4.2 | 5.0 | 6.0(6.0,6.0) | 8.0(8.0,8.0) | 9.9(9.9,9.9) | 12.0(12.0,12.0) |
| Q3_K_M | 3.91 | 4.4 | 5.2 | 6.2(6.2,6.2) | 8.2(8.2,8.2) | 10.2(10.2,10.2) | 12.2(12.2,12.2) |
| IQ4_XS | 4.25 | 4.7 | 5.5 | 6.5(6.5,6.5) | 8.6(8.6,8.6) | 10.6(10.6,10.6) | 12.7(12.7,12.7) |
| Q3_K_L | 4.27 | 4.7 | 5.5 | 6.5(6.5,6.5) | 8.6(8.6,8.6) | 10.7(10.7,10.7) | 12.7(12.7,12.7) |
| IQ4_NL | 4.50 | 5.0 | 5.7 | 6.8(6.8,6.8) | 8.9(8.9,8.9) | 10.9(10.9,10.9) | 13.0(13.0,13.0) |
| Q4_0 | 4.55 | 5.0 | 5.8 | 6.8(6.8,6.8) | 8.9(8.9,8.9) | 11.0(11.0,11.0) | 13.1(13.1,13.1) |
| Q4_K_S | 4.58 | 5.0 | 5.8 | 6.9(6.9,6.9) | 8.9(8.9,8.9) | 11.0(11.0,11.0) | 13.1(13.1,13.1) |
| Q4_K_M | 4.85 | 5.3 | 6.1 | 7.1(7.1,7.1) | 9.2(9.2,9.2) | 11.4(11.4,11.4) | 13.5(13.5,13.5) |
| Q4_K_L | 4.90 | 5.3 | 6.1 | 7.2(7.2,7.2) | 9.3(9.3,9.3) | 11.4(11.4,11.4) | 13.6(13.6,13.6) |
| Q5_K_S | 5.54 | 5.9 | 6.8 | 7.8(7.8,7.8) | 10.0(10.0,10.0) | 12.2(12.2,12.2) | 14.4(14.4,14.4) |
| Q5_0 | 5.54 | 5.9 | 6.8 | 7.8(7.8,7.8) | 10.0(10.0,10.0) | 12.2(12.2,12.2) | 14.4(14.4,14.4) |
| Q5_K_M | 5.69 | 6.1 | 6.9 | 8.0(8.0,8.0) | 10.2(10.2,10.2) | 12.4(12.4,12.4) | 14.6(14.6,14.6) |
| Q5_K_L | 5.75 | 6.1 | 7.0 | 8.1(8.1,8.1) | 10.3(10.3,10.3) | 12.5(12.5,12.5) | 14.7(14.7,14.7) |
| Q6_K | 6.59 | 7.0 | 8.0 | 9.4(9.4,9.4) | 12.2(12.2,12.2) | 15.0(15.0,15.0) | 17.8(17.8,17.8) |
| Q8_0 | 8.50 | 8.8 | 9.9 | 11.4(11.4,11.4) | 14.4(14.4,14.4) | 17.4(17.4,17.4) | 20.3(20.3,20.3) |
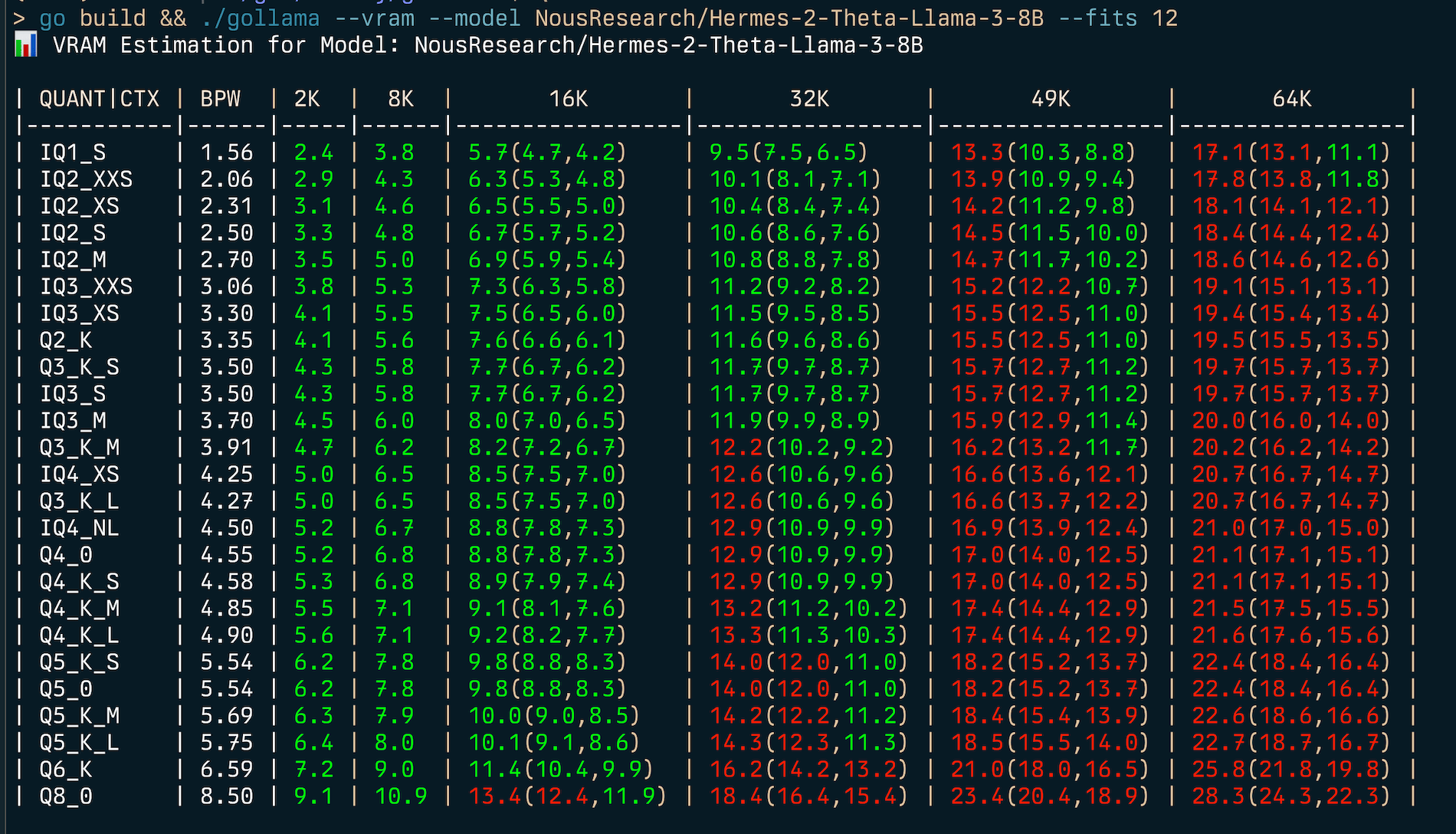
要为给定的内存限制(例如 6GB)找到最佳量化类型,可以使用 `--fits <GB 数>` 参数:
```shell
gollama --vram NousResearch/Hermes-2-Theta-Llama-3-8B --fits 6
📊 VRAM 预估:模型 - NousResearch/Hermes-2-Theta-Llama-3-8B
| 量化/上下文 | BPW | 2K | 8K | 16K | 32K | 49K | 64K |
| --------- | ---- | --- | --- | ------------ | ------------- | -------------- | --------------- |
| IQ1_S | 1.56 | 2.4 | 3.8 | 5.7(4.7,4.2) | 9.5(7.5,6.5) | 13.3(10.3,8.8) | 17.1(13.1,11.1) |
| IQ2_XXS | 2.06 | 2.9 | 4.3 | 6.3(5.3,4.8) | 10.1(8.1,7.1) | 13.9(10.9,9.4) | 17.8(13.8,11.8) |
...
这将显示一张表格,列出不同量化类型和上下文长度下的显存占用情况。
显存估算器的工作原理如下:
- 从 Hugging Face 获取模型配置(如果本地未缓存)。
- 计算模型参数、激活值和 KV 缓存所需的内存。
- 根据指定的量化设置调整计算结果。
- 使用二分搜索和线性搜索优化上下文长度或量化设置。
注意:估算器会优先使用 CUDA 显存,如果没有可用的 CUDA 显存,则会回退到系统内存进行计算。
配置
Gollama 使用位于 ~/.config/gollama/config.json 的 JSON 配置文件。该配置文件包含排序选项、列设置、API 密钥、日志级别、主题等配置项。
示例配置:
{
"default_sort": "modified",
"columns": [
"Name",
"Size",
"Quant",
"Family",
"Modified",
"ID"
],
"ollama_api_key": "",
"ollama_api_url": "http://localhost:11434",
"log_level": "info",
"log_file_path": "/Users/username/.config/gollama/gollama.log",
"sort_order": "Size",
"strip_string": "my-private-registry.internal/",
"editor": "/Applications/Visual Studio Code.app/Contents/Resources/app/bin/code",
"docker_container": ""
}
strip_string可用于移除模型名称前缀,以便在 TUI 中更清晰地显示。如果你的模型名称带有私有仓库等常见前缀,可以通过此设置将其移除。editor指定了按下 'e' 键时使用的编辑器。如果为空,则会回退到EDITOR环境变量,最后默认使用vim。支持外部编辑器(如 VS Code),并会弹出界面供用户编辑。docker_container- 实验性 - 如果设置,Gollama 将尝试在指定的容器内执行所有运行操作。theme- 实验性 主题名称(不带.json后缀)。
安装与源码构建
克隆仓库:
git clone https://github.com/sammcj/gollama.git cd gollama构建:
go get make build运行:
./gollama
主题
Gollama 支持基本的自定义主题功能,主题以 JSON 文件形式存储在 ~/.config/gollama/themes/ 目录中。可通过配置文件中的 theme 设置来选择当前主题(不带 .json 后缀)。
如果默认主题不存在,系统会自动创建:
default- 带霓虹色点缀的暗色主题(默认)light-neon- 带霓虹色点缀的浅色主题,适合浅色终端背景。
创建自定义主题的步骤如下:
- 在 themes 目录中创建一个新的 JSON 文件(例如
~/.config/gollama/themes/my-theme.json)。 - 使用以下结构:
{
"name": "my-theme",
"description": "我的自定义主题",
"colours": {
"header_foreground": "#AA1493",
"header_border": "#BA1B11",
"selected": "#FFFFFF",
...
},
"family": {
"llama": "#FF1493",
"alpaca": "#FF00FF",
...
}
}
颜色可以使用 ANSI 颜色代码(如 241)或十六进制值(如 #FF00FF)指定。family 部分用于定义列表视图中不同模型家族的颜色。
注意:使用 VSCode 扩展插件 'Color Highlight' 可以更方便地查找颜色的十六进制值。
日志
日志文件位于 gollama.log,默认存储在 $HOME/.config/gollama/gollama.log。
日志级别可以在配置文件中设置,也可以通过命令行覆盖:
# 覆盖单个命令的日志级别
gollama -C --log debug
# 或者使用长格式
gollama --create-from-lmstudio --log-level debug
可用的日志级别:debug、info、warn、error
贡献
欢迎贡献! 请先 fork 仓库,然后创建包含您更改的 pull request。

Sam |

Cameron Kingsbury |

KimCookieYa |

lif |

Denis Balan |

Doug Coleman |

Impact |

Jose Almaraz |

Jose Roberto Almaraz |

Oleksii Filonenko |

SouthWolf |

Vigilans |

agustif |

anrgct |

ondrej |
致谢
感谢 Matt Williams、Fahd Mirza 和 AI Code King 等人试用并提供了反馈。



许可证
版权所有 © 2024 Sam McLeod
本项目采用 MIT 许可证。详情请参阅 LICENSE 文件。
版本历史
v2.0.42025/12/30v2.0.32025/12/30v2.0.22025/12/30v2.0.12025/12/02v2.0.02025/12/02v1.37.52025/11/13v1.37.42025/11/11v1.37.32025/09/29v1.37.22025/09/16v1.37.12025/08/25v1.37.02025/08/24v1.36.12025/08/22v1.36.02025/08/22v1.35.32025/08/10v1.35.22025/08/10v1.35.12025/07/28v1.35.02025/07/28v1.34.12025/07/13v1.34.02025/06/12v1.33.22025/05/08常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。