envpool
EnvPool 是一款基于 C++ 构建的高性能并行环境执行引擎,专为强化学习(RL)任务设计。在强化学习训练中,传统 Python 环境往往因串行执行效率低下而成为瓶颈,EnvPool 通过引入向量化环境与线程池技术,有效解决了这一难题,能够轻松管理成百上千个并行环境实例。
无论是算法研究人员还是工程开发者,只要需要加速 RL 模型训练,EnvPool 都是理想选择。它完美兼容 OpenAI Gym、DeepMind dm_env 及 Gymnasium 等主流接口,支持同步与异步执行模式,并涵盖 Atari、Mujoco、Box2D 等多种经典环境。其核心亮点在于极致的运行效率:在标准硬件上即可实现比传统 Python 多进程方案快 3 到 20 倍的数据吞吐量,单卡环境下甚至能达成每秒百万级的帧处理速度。此外,EnvPool 不仅提供便捷的 Python 调用方式,还开放了 C++ 开发接口以便用户自定义扩展,并支持 JAX XLA 加速。作为一个通用且高效的底层基础设施,EnvPool 能帮助使用者大幅缩短实验迭代周期,让研究重心回归算法本身。
使用场景
某自动驾驶算法团队正在利用强化学习训练机械臂抓取策略,需要在 Mujoco 仿真环境中快速迭代数百万次交互数据。
没有 envpool 时
- 数据采集瓶颈严重:使用 Python 原生多进程(Subprocess)并行环境时,进程间通信开销巨大,导致每秒仅能处理约 15 万步仿真,GPU 经常因等待数据而空闲。
- 资源利用率低下:在仅有 12 核 CPU 的常规开发机上,传统向量环境吞吐量极低,无法跑满算力,训练一个基准模型耗时数天。
- 代码适配成本高:团队原有代码基于
gym接口编写,若要尝试更高效的 C++ 后端或异步执行模式,需重构大量底层交互逻辑。 - 调试与扩展困难:当需要自定义新的物理环境或支持多人博弈场景时,Python 层的性能损耗使得调试周期漫长且难以定位并发问题。
使用 envpool 后
- 吞吐量爆发式增长:借助 envpool 的 C++ 线程池与批量化 API,同一台 12 核机器上的仿真速度提升约 3 倍,在高性能集群上更是实现了每秒 300 万步的极致吞吐。
- 硬件算力充分释放:极低的通信延迟让 GPU 不再“等米下锅”,数据生成速度完全匹配模型训练需求,整体训练周期从数天缩短至数小时。
- 无缝平滑迁移:envpool 完美兼容现有的
gym和dm_env接口,团队无需修改上层强化学习算法代码,仅需替换环境初始化行即可享受加速红利。 - 灵活支持复杂场景:轻松切换同步/异步模式以适配不同算法需求,并利用其便捷的 C++ 开发接口快速集成了定制化的多智能体协作环境。
envpool 通过底层 C++ 引擎消除了 Python 并行瓶颈,将强化学习的数据生产效率提升了数量级,让算法迭代真正跟上算力的步伐。
运行环境要求
- Linux
- macOS
- Windows
- 非必需
- 该工具主要基于 CPU 并行化(使用线程池),在基准测试中使用了多达 256 个 CPU 核心
- 虽然支持与 JAX (XLA) 集成,但核心运行不依赖特定 GPU 型号、显存或 CUDA 版本
未说明(性能主要取决于 CPU 核心数量,基准测试覆盖了从 12 核到 256 核的配置)
快速开始



![]()

![]()
![]()




EnvPool 是一个基于 C++ 的批处理环境池,结合了 pybind11 和线程池技术。它具有高性能(在 Atari 游戏上可达约 100 万帧/秒,在 Mujoco 模拟器上使用 DGX-A100 可达约 300 万步/秒)以及兼容的 API 接口(同时支持 gym 和 dm_env,同步与异步模式,单人及多人环境)。目前支持以下环境:
- Atari 游戏
- Mujoco (gym)
- 经典控制强化学习环境:CartPole、MountainCar、Pendulum、Acrobot
- Toy text 强化学习环境:Catch、FrozenLake、Taxi、NChain、CliffWalking、Blackjack
- ViZDoom 单人模式
- DeepMind Control Suite
- Box2D
- Procgen
- Minigrid
以下是 EnvPool 的几大亮点:
- 兼容 OpenAI
gymAPI、DeepMinddm_envAPI 以及gymnasiumAPI; - 管理一个环境池,默认以批处理方式与环境交互;
- 同时支持同步执行和异步执行;
- 支持单人和多人环境;
- 提供易于使用的 C++ 开发者 API,方便添加新环境:自定义 C++ 环境集成;
- 即使仅使用单个环境,也能获得约 2 倍 的速度提升;
- 在 256 核 CPU 上,可实现每秒 100 万帧 的 Atari 游戏模拟或 300 万步 的 Mujoco 步骤模拟,吞吐量是基于 Python 子进程的向量化环境的 20 倍;
- 在低资源环境下(如 12 核 CPU),吞吐量仍是基于 Python 子进程的向量化环境的 3 倍;
- 与现有的 GPU 加速方案(如 Brax 或 Isaac-gym)相比,EnvPool 是一种适用于多种场景的通用解决方案,能够显著加速强化学习中的环境并行化;
- 支持 XLA,可通过 JAX jit 函数实现加速:XLA 接口;
- 与一些现有的强化学习库兼容,例如 Stable-Baselines3、Tianshou、ACME、CleanRL 或 rl_games。
- Stable-Baselines3
Pendulum-v1示例; - Tianshou
CartPole示例、Pendulum-v1示例、Atari 示例、Mujoco 示例,以及集成指南; - ACME
HalfCheetah示例; - CleanRL
Pong-v5示例(用 PPO 和 EnvPool 在 5 分钟内解决 Pong 问题;实验追踪); - rl_games Atari 示例(2 分钟搞定 Pong 和 15 分钟完成 Breakout)以及 Mujoco 示例(5 分钟搞定 Ant 和 HalfCheetah)。
- Stable-Baselines3
更多详细信息请参阅我们的 arXiv 论文!
安装
PyPI
EnvPool 目前托管在 PyPI 上,支持 Linux、macOS 和 Windows 平台上的 Python 3.11 至 3.14。
您只需运行以下命令即可安装 EnvPool:
$ pip install envpool
安装完成后,打开 Python 控制台并输入:
import envpool
print(envpool.__version__)
如果没有报错,则说明您已成功安装 EnvPool。
平台注意事项:
- PyPI 发布的二进制包无需在运行时单独安装 Qt。
- Windows 版本的 Procgen 包含所需的 Qt 运行时 DLL 文件(
Qt5Core.dll和Qt5Gui.dll),并与扩展模块一同打包。 - Windows 的源码/发布 CI 使用 Mesa 软件 OpenGL 来验证 MuJoCo 的渲染效果。若要在本地复现该设置,请将
ENVPOOL_DLL_DIR指向 Mesa DLL 目录,并设置GALLIUM_DRIVER=llvmpipe以及MESA_GL_VERSION_OVERRIDE=4.5COMPAT。 - 从源码构建仍需依赖平台特定的编译工具链,包括 Qt 5。完整的平台配置说明请参阅 从源码构建。
从源代码
请参阅指南。
文档
教程和 API 文档托管在 envpool.readthedocs.io 上。
示例脚本位于 examples/ 文件夹中;基准测试脚本位于 benchmark/ 文件夹中。
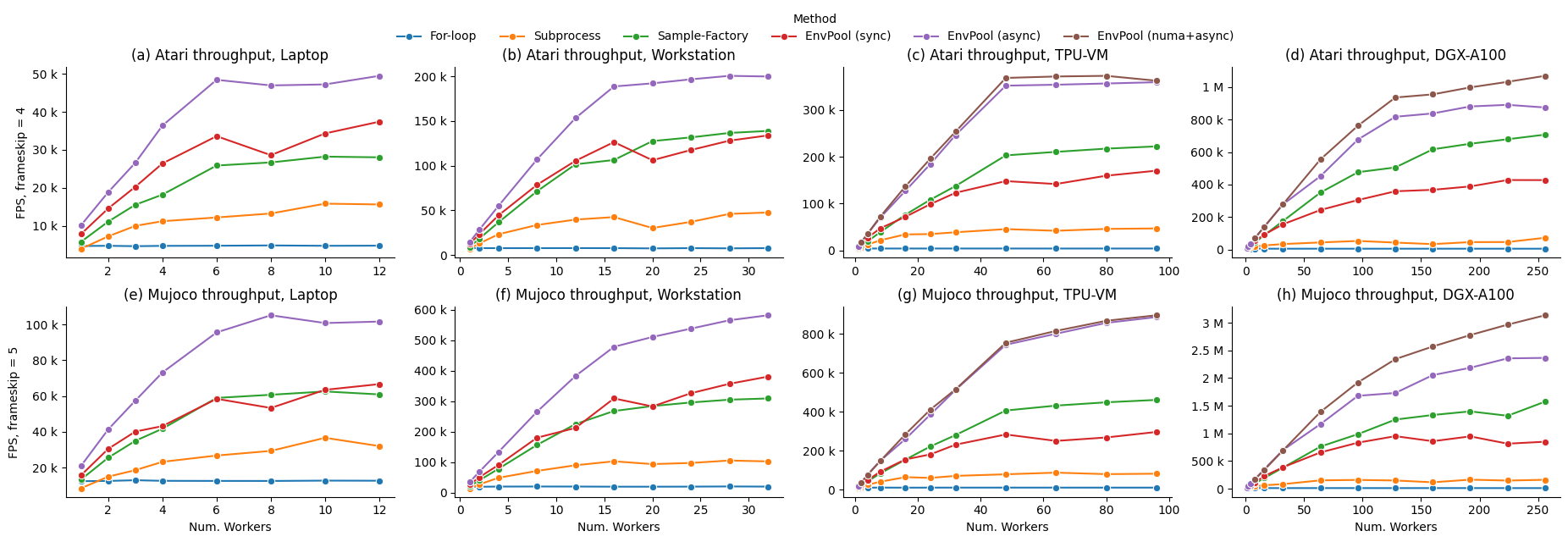
基准测试结果
以下历史基准测试表格是在不同的硬件配置下生成的,使用的环境包括 ALE Atari 环境 PongNoFrameskip-v4(带有来自 OpenAI Baselines 的环境包装器)和 Mujoco 环境 Ant-v3。硬件配置包括一台拥有 96 个 CPU 核心、2 个 NUMA 节点的 TPUv3-8 虚拟机,以及一台拥有 256 个 CPU 核心、8 个 NUMA 节点的 NVIDIA DGX-A100。当前位于 benchmark/ 中的脚本使用的是 Gymnasium 的 ALE/Pong-v5 和 Ant-v5。基准对比包括:1) 原生 Python for 循环;2) 最流行的基于 Python 子进程的强化学习环境并行化执行方式,例如 gym.vector_env;3) 据我们所知,在 EnvPool 出现之前最快的强化学习环境执行器 Sample Factory。
我们报告了 EnvPool 在同步模式、异步模式以及 NUMA + 异步模式下的性能,并将其与不同数量的工作进程(即 CPU 核心数)下的基准进行了比较。从结果可以看出,EnvPool 在所有设置下都显著优于基准。在高端配置下,EnvPool 在 256 个 CPU 核心上实现了 Atari 环境每秒 100 万帧、Mujoco 环境每秒 300 万帧的吞吐量,分别是 gym.vector_env 基准的 14.9 倍和 19.6 倍。而在典型的 12 核 CPU 的 PC 配置下,EnvPool 的吞吐量则是 gym.vector_env 的 3.1 倍和 2.9 倍。
| Atari 最高 FPS | 笔记本电脑 (12) | 工作站 (32) | TPU-VM (96) | DGX-A100 (256) |
|---|---|---|---|---|
| For-loop | 4,893 | 7,914 | 3,993 | 4,640 |
| Subprocess | 15,863 | 47,699 | 46,910 | 71,943 |
| Sample-Factory | 28,216 | 138,847 | 222,327 | 707,494 |
| EnvPool (sync) | 37,396 | 133,824 | 170,380 | 427,851 |
| EnvPool (async) | 49,439 | 200,428 | 359,559 | 891,286 |
| EnvPool (numa+async) | / | / | 373,169 | 1,069,922 |
| Mujoco 最高 FPS | 笔记本电脑 (12) | 工作站 (32) | TPU-VM (96) | DGX-A100 (256) |
|---|---|---|---|---|
| For-loop | 12,861 | 20,298 | 10,474 | 11,569 |
| Subprocess | 36,586 | 105,432 | 87,403 | 163,656 |
| Sample-Factory | 62,510 | 309,264 | 461,515 | 1,573,262 |
| EnvPool (sync) | 66,622 | 380,950 | 296,681 | 949,787 |
| EnvPool (async) | 105,126 | 582,446 | 887,540 | 2,363,864 |
| EnvPool (numa+async) | / | / | 896,830 | 3,134,287 |
更多详细信息请参阅 基准测试 页面。
API 使用
以下内容展示了 EnvPool 的同步和异步 API 使用方法。您也可以运行完整的脚本,地址为 examples/env_step.py。
同步 API
import envpool
import numpy as np
# 创建 gym 环境
env = envpool.make("Pong-v5", env_type="gym", num_envs=100)
# 或者使用 envpool.make_gym(...)
obs = env.reset() # 应该是 (100, 4, 84, 84)
act = np.zeros(100, dtype=int)
obs, rew, term, trunc, info = env.step(act)
在同步模式下,envpool 与 openai-gym/dm-env 非常相似。它具有与原版相同的 reset 和 step 函数。不过,envpool 有一个例外:默认采用批量交互。因此,在创建 envpool 时,需要指定一个 num_envs 参数,用于表示您希望同时运行多少个环境。
env = envpool.make("Pong-v5", env_type="gym", num_envs=100)
传递给 step 函数的 action 的第一个维度应等于 num_envs。
act = np.zeros(100, dtype=int)
您无需在某个环境完成时手动重置它;相反,envpool 中的所有环境都默认启用了自动重置功能。
异步 API
import envpool
import numpy as np
# 创建异步环境
num_envs = 64
batch_size = 16
env = envpool.make("Pong-v5", env_type="gym", num_envs=num_envs, batch_size=batch_size)
action_num = env.action_space.n
env.async_reset() # 向所有环境发送初始重置信号
while True:
obs, rew, term, trunc, info = env.recv()
env_id = info["env_id"]
action = np.random.randint(action_num, size=batch_size)
env.send(action, env_id)
在异步模式下,step 函数被拆分为两个部分:send 和 recv 函数。send 接受两个参数:一批动作以及每个动作对应的 env_id,用于指示将动作发送到哪个环境。与 step 不同,send 不会等待环境执行并返回下一个状态,而是在动作被送入环境后立即返回。(这也是其被称为异步模式的原因)。
env.send(action, env_id)
要获取“下一个状态”,我们需要调用 recv 函数。然而,recv 并不能保证您会收到刚刚调用 send 的那些环境的“下一个状态”。相反,最先完成执行的环境会优先被 recv 到。
state = env.recv()
除了 num_envs 之外,还有一个 batch_size 参数。虽然 num_envs 定义了 envpool 总共管理多少个环境,但 batch_size 则指定了每次与 envpool 交互时涉及的环境数量。例如,如果 envpool 中有 64 个环境正在运行,那么每次 send 和 recv 只会与其中 16 个环境进行交互。
envpool.make("Pong-v5", env_type="gym", num_envs=64, batch_size=16)
envpool.make 还有其他可配置的参数,请参阅 EnvPool Python 接口介绍。
渲染
EnvPool 通过 Python 封装暴露了渲染功能。创建环境时设置 render_mode="rgb_array" 可以获取批量的 RGB 输出,或者设置 render_mode="human" 通过 OpenCV 显示单个环境。
import envpool
env = envpool.make(
"Ant-v5",
env_type="gymnasium",
num_envs=4,
render_mode="rgb_array",
render_width=480,
render_height=480,
)
env.reset()
frames = env.render(env_ids=[0, 2])
assert frames.shape == (2, 480, 480, 3)
render() 是以批次为先的,因此即使只渲染一个环境,也会保留批次维度:env.render().shape == (1, H, W, 3)。如果省略 env_ids,EnvPool 会渲染 render_env_id(默认为 0)。camera_id 可以在每次调用时覆盖,而输出尺寸则在创建环境时通过 render_width 和 render_height 固定。
仓库的测试套件也对渲染功能进行了测试。make bazel-test 会对每个支持渲染的环境系列重复进行渲染检查,而 make release-test 则包含一个轮子烟雾测试,在 reset() 后调用 render()。在 Windows 上,MuJoCo 的渲染测试使用了上述相同的 ENVPOOL_DLL_DIR Mesa 预加载钩子,以便使用软件 OpenGL 而不是系统驱动程序。
viewer = envpool.make(
"WalkerWalk-v1",
env_type="gymnasium",
num_envs=1,
render_mode="human",
render_env_id=0,
)
viewer.reset()
viewer.render()
render_mode="human" 返回 None,并且目前每次调用仅支持一个环境 ID。此外,它还需要安装 opencv-python。
像素观测
对于 MuJoCo 任务,像素观测也可以通过常规的观测 API 直接暴露出来,只需传递 from_pixels=True 即可。这一路径是在 C++ 中原生实现的,无需通过 Python 端的 render() 进行路由。
pixels = envpool.make(
"WalkerWalk-v1",
env_type="gymnasium",
num_envs=2,
from_pixels=True,
frame_stack=3,
render_width=84,
render_height=84,
)
obs, info = pixels.reset()
assert obs.shape == (2, 9, 84, 84)
像素观测采用通道优先的布局。当 frame_stack=1 时,每个环境返回 (3, H, W);当 frame_stack=3 时,EnvPool 会将帧堆叠到通道维度上,返回 (9, H, W)。这直接符合常用的 PyTorch BCHW 规范。如果省略 render_width 或 render_height,EnvPool 会将其默认设置为 84。
贡献
EnvPool 仍处于开发阶段。未来还将添加更多环境,并且我们始终欢迎贡献,以帮助 EnvPool 不断完善。如果您希望参与贡献,请查看我们的贡献指南。
许可证
EnvPool 采用 Apache2 许可证。
其他第三方源代码和数据则遵循各自的许可证。
我们并未将这些第三方的源代码和数据包含在本仓库中。
引用 EnvPool
如果您觉得 EnvPool 对您有帮助,请在您的出版物中引用它。
@inproceedings{weng2022envpool,
author = {Weng, Jiayi and Lin, Min and Huang, Shengyi and Liu, Bo and Makoviichuk, Denys and Makoviychuk, Viktor and Liu, Zichen and Song, Yufan and Luo, Ting and Jiang, Yukun and Xu, Zhongwen and Yan, Shuicheng},
booktitle = {Advances in Neural Information Processing Systems},
editor = {S. Koyejo and S. Mohamed and A. Agarwal and D. Belgrave and K. Cho and A. Oh},
pages = {22409--22421},
publisher = {Curran Associates, Inc.},
title = {Env{P}ool: A Highly Parallel Reinforcement Learning Environment Execution Engine},
url = {https://proceedings.neurips.cc/paper_files/paper/2022/file/8caaf08e49ddbad6694fae067442ee21-Paper-Datasets_and_Benchmarks.pdf},
volume = {35},
year = {2022}
}
免责声明
本项目并非 Sea Limited 或 Garena Online Private Limited 的官方产品。
版本历史
v1.1.02026/04/04v1.0.12026/03/31v1.0.02026/03/27v0.9.12026/03/24v0.9.02026/03/23v0.8.42023/10/30v0.8.32023/09/07v0.8.22023/03/28v0.8.12023/01/08v0.8.02023/01/03v0.7.02022/12/29v0.6.62022/11/01v0.6.52022/10/18v0.6.42022/08/15v0.6.32022/07/25v0.6.22022/06/15v0.6.12022/05/24v0.6.02022/05/18v0.5.32022/05/02v0.5.22022/04/30常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。