crypto-rl
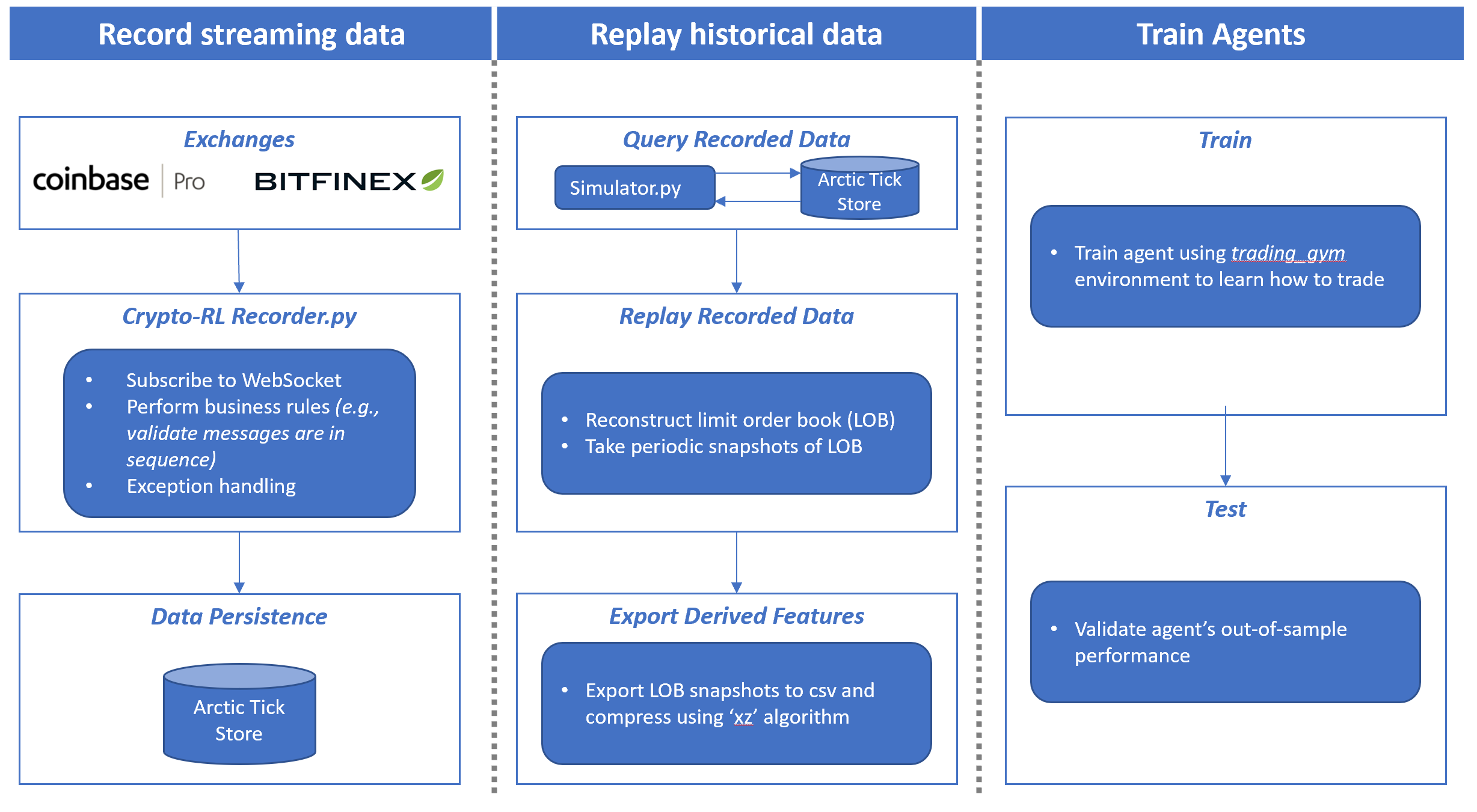
crypto-rl 是一个面向加密货币交易研究的深度强化学习开源工具包。它能从 Coinbase Pro 和 Bitfinex 两大交易所实时记录完整的限价订单簿(Limit Order Book)和逐笔成交数据,并将数据存储在基于 MongoDB 的 Arctic 数据库中;随后支持回放历史数据,提取特征用于训练交易智能体。项目内置了一个基于 DDQN(Double Deep Q-Network)算法的示例智能体,帮助用户快速上手构建自己的交易策略。
该工具主要解决研究人员在复现强化学习交易论文时缺乏高质量、结构化市场微观数据的问题。其特色在于完整保留了订单簿的动态细节,并提供了与 OpenAI Gym 兼容的自定义交易环境(gym_trading),便于集成各类强化学习算法。此外,技术指标实现注重效率,部分达到 O(1) 时间复杂度。
crypto-rl 专为量化金融领域的研究人员和算法开发人员设计,适用于学术实验或策略原型开发,但不支持实盘交易。适合希望探索基于订单流数据的智能交易系统、并具备 Python 和强化学习基础的用户使用。
使用场景
某量化研究团队希望基于深度强化学习开发一个比特币做市策略,需要利用真实限价订单簿(LOB)数据训练智能体,但缺乏高效的数据回放与训练一体化框架。
没有 crypto-rl 时
- 需手动从 Coinbase Pro 和 Bitfinex 分别拉取原始订单簿快照和逐笔成交数据,格式不统一,清洗耗时。
- 缺乏标准化的回放机制,难以将历史订单流还原为连续、低延迟的市场状态供模型训练。
- 自行构建 OpenAI Gym 环境来模拟交易过程,状态空间设计粗糙,无法有效捕捉订单簿动态特征。
- 技术指标计算效率低,在高频回测中成为性能瓶颈。
- 训练 DDQN 智能体时需从零搭建神经网络与经验回放模块,复现论文结果困难且易出错。
使用 crypto-rl 后
- 通过内置 recorder.py 一键录制多交易所全深度订单簿数据,并自动存入 Arctic 时间序列数据库,结构清晰、查询高效。
- 利用 gym_trading 模块提供的 POMDP 环境,可高保真回放历史订单流,生成 O(1) 复杂度的平稳特征(如价格压力、订单不平衡度)。
- 直接调用预置的 DDQN 实现(agent/dqn.py),快速复现《Deep Reinforcement Learning for Market Making》等论文实验。
- 内置高性能技术指标库,支持实时特征提取,显著提升训练吞吐量。
- 整个“记录—回放—训练”流程标准化,团队成员可快速迭代策略,无需重复造轮子。
crypto-rl 将加密货币订单簿数据处理与强化学习训练无缝衔接,大幅降低量化研究门槛并提升实验可复现性。
运行环境要求
- Linux
需要 NVIDIA GPU(因依赖 tensorflow-gpu==1.13.1),但未说明具体型号、显存大小和 CUDA 版本
未说明
快速开始
加密货币深度强化学习工具包(Deep Reinforcement Learning Toolkit for Cryptocurrencies)
目录:
- 目的
- 范围
- 依赖项
- 项目结构
- 设计模式
- 快速入门
- 引用本项目
- 附录
1. 目的
本应用旨在提供一个工具包,用于:
- 记录(Record) 来自两个交易所(Coinbase Pro 和 Bitfinex)的完整限价订单簿(Limit Order Book)和逐笔交易(trade tick)数据,并将其存入 Arctic Tickstore 数据库(即 MongoDB)中;
- 回放(Replay) 已记录的历史数据,以生成用于训练的特征集;
- 训练(Train) 使用 DQN(Deep Q-Network,深度 Q 网络)算法进行加密货币交易的智能体(agent)(注意:此智能体实现仅作为用户参考的示例)。
2. 范围
- 仅限研究用途:本项目不具备在交易所进行实盘交易的能力。
- 复现强化学习论文结果:这篇 文章所使用的数据集已在 Kaggle Datasets 上公开。
3. 依赖项
详见 requirements.txt
注意:为了运行和训练 DQN 智能体(./agent/dqn.py),需手动安装 tensorflow 和 Keras-RL,它们未包含在 requirements.txt 中,以确保本项目与其他开源强化学习平台(例如 OpenAI Baselines)兼容。
请使用 pip 安装以下依赖:
git+https://github.com/manahl/arctic.git
Keras==2.2.4
Keras-Applications==1.0.7
Keras-Preprocessing==1.0.9
keras-rl==0.4.2
tensorboard==1.13.1
tensorflow-estimator==1.13.0
tensorflow-gpu==1.13.1
4. 项目结构
本项目的关键组成部分及其简要说明如下:
crypto-rl/
agent/
...强化学习算法实现
data_recorder/
...用于连接、下载和检索限价订单簿数据的工具
gym_trading/
...扩展的 openai.gym 环境,用于观察限价订单簿数据
indicators/
...以 O(1) 时间复杂度实现的技术指标
design-patterns/
...模块架构的可视化图表
venv/
...用于本地部署的虚拟环境
experiment.py # 运行强化学习实验的入口点
recorder.py # 开始记录限价订单簿数据的入口点
configurations.py # 项目中使用的常量
requirements.txt # 项目依赖列表
setup.py # 执行命令 `python3 setup.py install`
# 以安装扩展的 gym 环境(即 gym_trading.py)
5. 设计模式
各模块的设计模式规范请参阅以下文档:
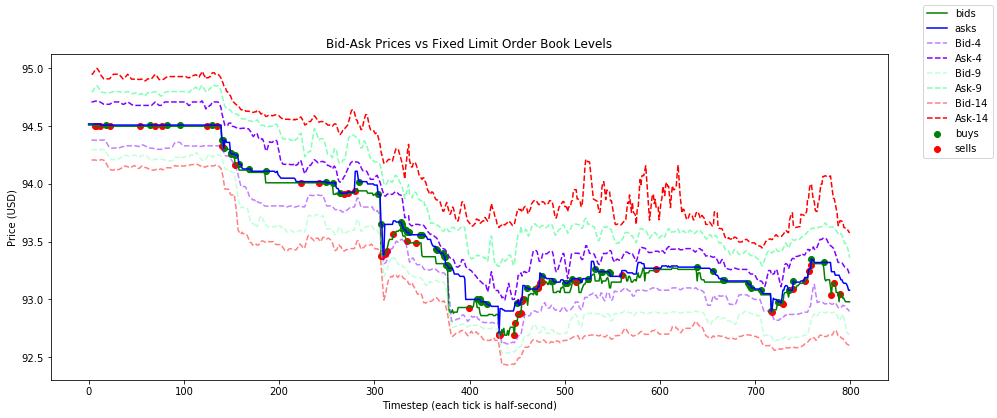
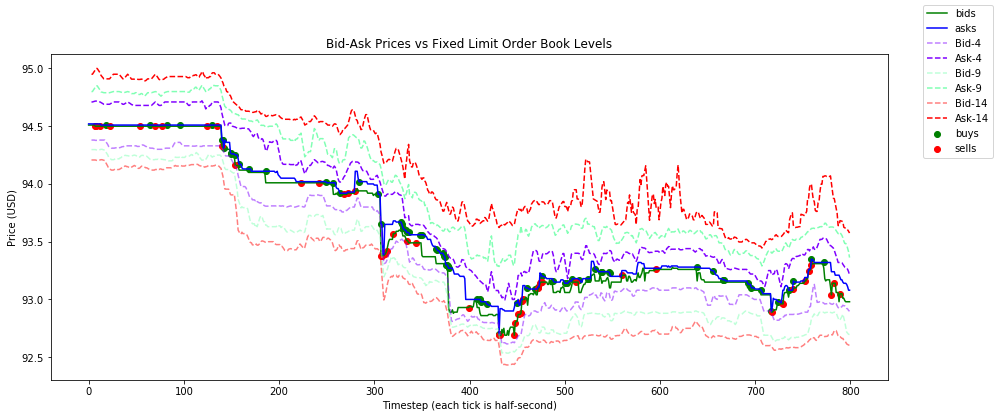
限价订单簿层级的示例快照:
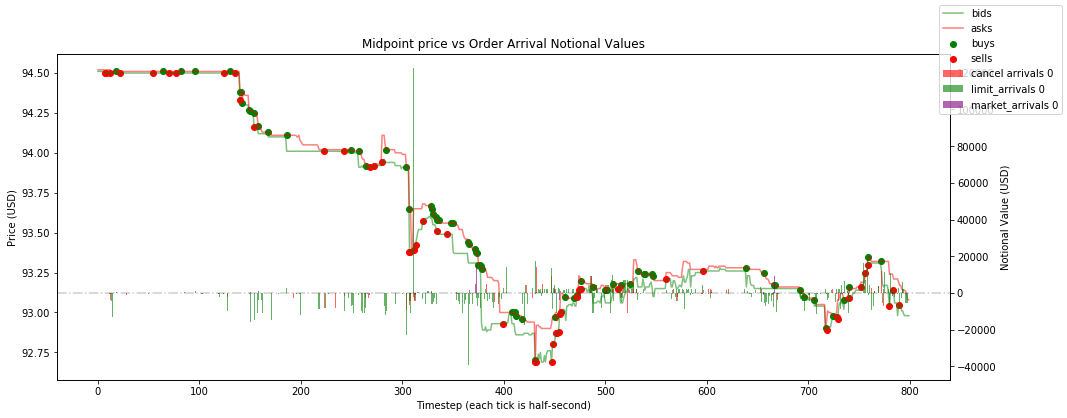
订单到达流指标的示例快照:
6. 快速入门
在本地机器上安装本项目:
# 从 GitHub 克隆项目
git clone https://github.com/sadighian/crypto-rl.git
cd crypto-rl
# 为项目依赖创建虚拟环境
python3 -m venv ./venv
# 激活虚拟环境
source venv/bin/activate
# 安装 keras-rl 依赖
pip3 install Keras==2.2.4 Keras-Applications==1.0.7 Keras-Preprocessing==1.0.9 keras-rl==0.4.2
tensorboard==1.13.1 tensorflow-estimator==1.13.0 tensorflow-gpu==1.13.1
# 安装数据库依赖
pip3 install git+https://github.com/manahl/arctic.git
# 安装本项目
pip3 install -e .
6.1 从交易所记录限价订单簿数据
步骤 1:
打开 configurations.py 文件,定义你希望订阅并记录的加密货币。
注意:篮子(basket)列表格式如下:[(Coinbase_Instrument_Name, Bitfinex_Instrument_Name), ...]
SNAPSHOT_RATE = 5 # 即每 5 秒记录一次
BASKET = [('BTC-USD', 'tBTCUSD'),
('ETH-USD', 'tETHUSD'),
('LTC-USD', 'tLTCUSD'),
('BCH-USD', 'tBCHUSD'),
('ETC-USD', 'tETCUSD')]
RECORD_DATA = True
步骤 2:
打开命令行终端,执行以下命令开始记录完整的限价订单簿和交易数据:
python3 recorder.py
6.2 回放已记录数据以导出平稳特征集
步骤 1:
确保你的数据库中已有数据。
可通过 MongoDB shell 或 Compass 进行检查。若无数据,请参考上方 6.1 从交易所记录限价订单簿数据 部分。
步骤 2:
运行历史数据模拟,对限价订单簿进行快照,并将其平稳特征导出为压缩的 CSV 文件。
你可以利用 data_recorder/tests/ 中的测试用例,或自行编写逻辑。若使用测试用例方法,请确保修改查询参数,使其与你实际记录并存储在数据库中的数据相匹配。
导出特征至压缩 CSV 的示例命令:
python3 data_recorder/tests/test_extract_features.py
6.3 训练智能体
步骤 1:
确保 data_recorder/database/data_exports/ 文件夹中已有数据。
智能体将从此处加载数据。若该文件夹中无数据,请参考上方 6.2 回放已记录数据以导出平稳特征集 部分。
步骤 2:
打开命令行终端,开始学习/训练智能体:
python3 experiment.py --window_size=50 --weights=False --fitting_file=...
所有可用的关键字参数请参阅 experiment.py 文件。
7. 引用本项目
若在研究中使用本项目,请务必引用:
@misc{Crypto-RL,
author = {Jonathan Sadighian},
title = {Deep Reinforcement Learning Toolkit for Cryptocurrencies},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/sadighian/crypto-rl}},
}
8. 附录
8.1 分支(Branches)
本项目包含多个分支,每个分支采用不同的数据持久化实现模式:
- FULL 分支旨在作为全自动交易系统的基础(即,实现了适用于需要并行处理的交易系统的设计模式),并将流式 tick 数据持久化到 Arctic Tick Store(Arctic Tick 存储)中。
注意:以下分支(即 lightweight、order book snapshot、mongo integration)自 2018 年 10 月起已不再积极维护,仅作参考之用。
- LIGHT WEIGHT 分支旨在比 full 分支更高效地记录流式数据(即,所有 WebSocket 连接均由单个进程建立,且 不维护限价订单簿(limit order book)),并将流式 tick 数据持久化到 Arctic tick store 中。
- ORDER BOOK SNAPSHOT 分支与 full 分支采用相同的设计模式,但不记录流式 tick 数据,而是每隔 N 秒对限价订单簿进行一次快照,并将快照持久化到 Arctic tick store 中。
- MONGO INTEGRATION 分支的实现与 ORDER BOOK SNAPSHOT 相同,不同之处在于使用标准的 MongoDB 而非 Arctic。该分支最初用于对 Arctic 的性能进行基准测试,且未与 FULL 分支保持同步更新。
8.2 前提假设(Assumptions)
- 你已安装虚拟环境(virtual environment)并将项目安装到该虚拟环境中(例如:
pip3 install -e .) - 你已安装 MongoDB
- 你知道如何使用命令行界面(CLI)启动 Python 脚本
- 你正在运行 Ubuntu 18 或更高版本的操作系统
8.3 更新日志(Change Log)
- 2021-09-25:更新了
requirements.txt:今后数据库需通过pip install git+https://github.com/manahl/arctic.git手动安装 - 2019-12-12:添加了文档字符串(docstrings),并对多个类进行了重构以提升代码可读性
- 2019-09-18:对
env(环境)和broker(经纪商)进行了简化重构,并增加了不同的reward(奖励)方法 - 2019-09-13:创建并实现了“订单到达”流指标('order arrival' flow metrics),灵感来源于 Xu, Ke; Gould, Martin D.; Howison, Sam D. 的论文 Multi-Level Order-Flow Imbalance in a Limit Order Book
- 2019-09-06:创建并实现了
Indicator.py基类 - 2019-04-28:为简化结构而重新组织了项目架构
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。
crawl4ai
Crawl4AI 是一款专为大语言模型(LLM)设计的开源网络爬虫与数据提取工具。它的核心使命是将纷繁复杂的网页内容转化为干净、结构化的 Markdown 格式,直接服务于检索增强生成(RAG)、智能体构建及各类数据管道,让 AI 能更轻松地“读懂”互联网。 传统爬虫往往面临反爬机制拦截、动态内容加载困难以及输出格式杂乱等痛点,导致后续数据处理成本高昂。Crawl4AI 通过内置自动化的三级反机器人检测、代理升级策略以及对 Shadow DOM 的深度支持,有效突破了这些障碍。它能智能移除同意弹窗,处理深层链接,并具备长任务崩溃恢复能力,确保数据采集的稳定与高效。 这款工具特别适合开发者、AI 研究人员及数据工程师使用。无论是需要为本地模型构建知识库,还是搭建大规模自动化信息采集流程,Crawl4AI 都提供了极高的可控性与灵活性。作为 GitHub 上备受瞩目的开源项目,它完全免费开放,无需繁琐的注册或昂贵的 API 费用,让用户能够专注于数据价值本身而非采集难题。
meilisearch
Meilisearch 是一个开源的极速搜索服务,专为现代应用和网站打造,开箱即用。它能帮助开发者快速集成高质量的搜索功能,无需复杂的配置或额外的数据预处理。传统搜索方案往往需要大量调优才能实现准确结果,而 Meilisearch 内置了拼写容错、同义词识别、即时响应等实用特性,并支持 AI 驱动的混合搜索(结合关键词与语义理解),显著提升用户查找信息的体验。 Meilisearch 特别适合 Web 开发者、产品团队或初创公司使用,尤其适用于需要快速上线搜索功能的场景,如电商网站、内容平台或 SaaS 应用。它提供简洁的 RESTful API 和多种语言 SDK,部署简单,资源占用低,本地开发或生产环境均可轻松运行。对于希望在不依赖大型云服务的前提下,为用户提供流畅、智能搜索体验的团队来说,Meilisearch 是一个高效且友好的选择。
Made-With-ML
Made-With-ML 是一个面向实战的开源项目,旨在帮助开发者系统掌握从设计、开发到部署和迭代生产级机器学习应用的完整流程。它解决了许多人在学习机器学习时“会训练模型但不会上线”的痛点,强调将软件工程最佳实践与 ML 技术结合,构建可靠、可维护的端到端系统。 该项目特别适合三类人群:一是希望将模型真正落地的开发者(包括软件工程师、数据科学家);二是刚毕业、想补齐工业界所需技能的学生;三是需要理解技术边界以更好推动产品的技术管理者或产品经理。 Made-With-ML 的亮点在于注重第一性原理讲解,避免盲目调包;同时覆盖 MLOps 关键环节(如实验跟踪、模型测试、服务部署、CI/CD 等),并支持在 Python 生态内平滑扩展训练与推理任务,无需切换语言或复杂基础设施。课程内容结构清晰,配有详细代码示例和视频导览,兼顾理论深度与工程实用性。