deepnlp
DeepNLP 是一个致力于构建"AI 服务大众点评”的开放平台,旨在从普通用户视角出发,填补当前 AI 评估领域主要依赖学术基准而缺乏真实用户体验反馈的空白。它解决了用户在面对海量 AI 应用(如聊天机器人、图像生成器、搜索引擎等)时难以甄别优劣、选择困难的问题。
在 DeepNLP 上,用户不仅可以对各类 AI 服务进行整体评分,还能针对具体功能场景(如“论文语法修正”、“医疗咨询建议”或“卡通角色绘制”)上传截图并撰写详细评测。平台支持多维度打分机制,除常规的准确性与帮助度外,还允许用户根据图像清晰度、艺术性或语言简洁度等自定义指标进行细致评价。目前,DeepNLP 已覆盖医疗、金融、教育、法律及娱乐等 30 多个垂直领域的应用场景。
无论是希望寻找靠谱 AI 工具的普通大众,还是关注产品落地表现的设计师与产品经理,亦或是需要真实用户反馈数据的研究者,都能从中获益。通过汇聚真实的用户声音与使用案例,DeepNLP 让 AI 服务的发现与选择变得更加透明、高效且贴近实际需求。
使用场景
一家专注于老年健康管理的科技公司正在为银发族筛选合适的 AI 医疗咨询助手,以确保产品推荐的安全性与准确性。
没有 deepnlp 时
- 团队只能依赖学术论文中的通用基准测试,缺乏针对“老年人慢性病咨询”这一具体场景的真实用户反馈。
- 难以评估不同 AI 在“医学术语通俗化”和“情感关怀”等细粒度维度上的表现,导致选型依据模糊。
- 需要人工逐一注册并测试数十款 AI 服务,耗时数周且无法获取其他真实用户的避坑经验。
- 缺乏可视化的多维度评分对比,无法向利益相关者直观展示为何选择某款特定模型。
使用 deepnlp 后
- 直接在 deepnlp 的"AI in HEALTHCARE"及"AI for ELDERLY"分类下,查阅大量真实用户关于医疗问答的详细评测与截图证据。
- 利用“清晰度”、“帮助性”及自定义的“适老化程度”等多维度评分,精准锁定在解释病情时最耐心、准确的 AI 服务。
- 通过社区分享的负面案例(如幻觉误导),快速排除存在安全隐患的模型,将选型周期从数周缩短至几天。
- 参考平台上已有的深度使用报告,直接生成包含具体功能对比的决策文档,大幅提升内部沟通效率。
deepnlp 通过构建 AI 服务领域的“大众点评”,让基于真实场景的多维度评估取代了盲目的技术试错,显著降低了企业与个人的选型风险。
运行环境要求
未说明
未说明

快速开始
DeepNLP AI 应用商店
DeepNLP AI 商店(http://www.deepnlp.org/store)是一个新近上线的网站,旨在让用户从用户视角出发,针对 AI 服务的各个细节撰写真实评价、评分、人工评估、提示词,并分享使用案例。这与研究者视角下的大模型或多模态基准测试有所不同。DeepNLP 希望打造一个被称为 AI 服务“Yelp”的平台——就像 Yelp 帮助用户发现本地商家和服务一样,该平台将为用户提供发现和连接各类 AI 服务、AI 应用及机器人社区的机会,从而减轻客户在选择不同 AI 服务时的负担。

详尽的 AI 服务使用案例
用户可以就某项 AI 服务(如 ChatGPT、Gemini、Perplexity、Midjourney 等)的特定功能撰写详细评测,例如 AI 在“纠正论文中的 Grammarly 错误”、“扮演医生诊断疾病”等方面的表现,或其文生图能力,如“生成卡通角色”、“绘制奇幻人形生物”等。用户只需上传对话截图或 AI 图像生成器所生成的图片即可。
多维度评分
用户可以对 AI 服务的各项功能进行整体评分(1 至 5 星),并针对每个功能的不同方面给出细化评分,包括“准确性”、“实用性”、“趣味性”,以及各功能特有的指标,如“图像清晰度”、“图像分辨率”、“艺术感”、“语法正确性”、“表达简洁性”等。

全品类与全人群覆盖
我们涵盖了 30 多个不同的使用场景类别,例如:
AI 图像生成器、AI 助手与聊天机器人、AI 翻译工具、AI 搜索引擎;
面向儿童的 AI、面向成人的 AI、面向老年人的 AI;
AI 在旅游、交通、医疗健康、商业、金融、教育、效率工具等领域的应用;
AI 在政治、娱乐、新闻、艺术体育、生活方式等领域的应用;
AI 在支付、社交、农业、科学、技术、旅行、交通运输、汽车、慈善公益、公共服务、住房、法律、通信、食品等领域的应用。
AI 应用商店按类别划分的评价与评分
AI 图像生成器
AI 搜索引擎
AI 聊天机器人助手
AI 视频生成器评价
面向老年人的 AI
面向儿童的 AI
AI 在法律领域的应用
AI 在金融领域的应用
AI 在医疗健康领域的应用
AI 在商业领域的应用
AI 在教育领域的应用
AI 在效率工具领域的应用
AI 在政治领域的应用
AI 在娱乐领域的应用
AI 在新闻领域的应用
AI 在艺术与体育领域的应用
AI 在生活方式领域的应用
AI 在支付领域的应用
AI 在社交领域的应用
AI 在农业领域的应用
AI 在科学领域的应用
AI 在技术领域的应用
AI 在旅行领域的应用
AI 在交通运输领域的应用
AI 在汽车领域的应用
AI 在慈善公益领域的应用
AI 在公共服务领域的应用
AI 在住房领域的应用
AI 在通信领域的应用
AI 在食品领域的应用
四足机器人评价
人形机器人评价
自动驾驶出租车评价
电动汽车评价
AI 应用商店的主要 AI 服务发布方
聊天机器人助手
ChatGPT 用户评价
Gemini 用户评价
Perplexity 用户评价
Claude Anthropic 用户评价
Doubao 用户评价
Qwen 用户评价
Zhipu AI 用户评价
Zhipu CogVLM AI
Character.AI 用户评价
Xinye 用户评价
GPT-5 预测评价
社交 AI
图像生成器
Midjourney 用户评价
Stable Diffusion 用户评价
Canva 用户评价
Flux AI 评价
AI 写作工具
四足与人形机器人
Figure ai 用户评价
Unitree Robotics
Boston Dynamics 评价
Anybotics 评价
Tesla 评价
Tesla Cybercab 自动驾驶出租车
Tesla Optimus|pub-tesla-optimus
电动汽车
Bmw i4 评测
Hyundai ioniq 6 评测
Byd seal 评测
Tesla Model 3 评测
视频生成器
Kling AI 评测
Dreamina Douyin 评测
Sora Openai 评测
VR头显/AI眼镜
Apple Glasses 评测
Apple VR头显 评测
Meta VR头显 评测
Meta Glasses 评测
Google VR 评测
Google Glasses
LLM推理
ChatGPT Strawberry 评测
OpenAI o1 评测
AI教育
Coursera课程评测
Udacity课程评测
Grammarly 评测
多方面对比的AI服务评测与评分
AI聊天机器人助手
ChatGPT vs Gemini
Gemini vs ChatGPT
ChatGPT vs Perplexity
Perplexity vs ChatGPT
ChatGPT vs Claude
Claude vs ChatGPT
Gemini vs Perplexity
Perplexity vs Gemini
Gemini vs Claude
Claude vs Gemini
Perplexity vs Claude
Claude vs Perplexity
doubao vs chatgpt
qwen vs chatgpt
zhipu vs chatgpt
chatgpt vs zhupu
doubao vs qwen
doubao vs zhipu ai
AI图像生成器对比
midjourney vs stable diffusion
stable diffusion vs midjourney
midjourney vs Canva
Canva vs midjourney
midjourney vs chatgpt
chatgpt vs midjourney
AI视频生成器对比
Runway vs Pika
Runway vs Kling
Runway vs Dreamina
Kling AI vs Runway
Kling AI vs Pika
Kling AI vs Dreamina
Dreamina vs Kling AI
Dreamina vs Runway
Dreamina vs Pika
AI聊天机器人
character ai vs Chatgpt
character ai vs Gemini
AI写作
Grammarly vs Chatgpt
Grammarly vs Gemini Google
无人出租车
Baidu VS Waymo 无人出租车评测
Waymo vs Baidu 用户评测
Tesla Cybercab vs Waymo
Tesla Cybercab vs Baidu Apollo
机器人
Figure AI vs Tesla
Tesla vs Figure AI
Figure AI vs Boston Dynamics
Boston Dynamics vs Figure AI
Tesla vs Boston Dynamics
Boston Dynamics vs Tesla
Unitree vs Boston Dynamics
Anybotics vs Boston Dynamics
图像生成器AI商店
DeepNLP AI商店是一个平台和社区,供用户撰写关于AI应用和服务的真实用户评论和评分。用户可以上传图片作为AI图像生成器的展示,例如Midjourney、Canva、Stable Diffusion等。人们还可以针对一些常见的用户提示(问题或意图)进行评论,比如“生成卡通角色”、“绘制幻想生物和类人生物”、“规划建筑设计”等等。

AI图像生成器展示
食品AI图像生成器
食品AI图像生成器
请Midjourney生成食品相关图片
请Stable Diffusion生成食品相关图片
请Canva生成食品相关图片
请Doubao生成食品相关图片
请Dreamina生成食品相关图片
请Zhipu AI生成食品相关图片
请Qwen生成食品相关图片
动物AI图像生成器
动物AI图像生成器
请Midjourney生成动物相关图片
请Stable Diffusion生成动物相关图片
请Canva生成动物相关图片
请Doubao生成动物相关图片
请Dreamina生成动物相关图片
请Zhipu AI生成动物相关图片
请Qwen生成动物相关图片
名人AI图像生成器
名人AI图像生成器
请Midjourney生成名人相关图片
请Stable Diffusion生成名人相关图片
请Canva生成名人相关图片
请Doubao生成名人相关图片
请Dreamina生成名人相关图片
请Zhipu AI生成名人相关图片
请Qwen生成名人相关图片
自拍AI图像生成器
自拍AI图像生成器
请Midjourney生成自拍相关图片
请Stable Diffusion生成自拍相关图片
请Canva生成自拍相关图片
请Doubao生成自拍相关图片
请Dreamina生成自拍相关图片
请Zhipu AI生成自拍相关图片
请Qwen生成自拍相关图片
体育AI图像生成器
体育主题AI图像生成器
请求MidJourney生成体育相关图像
请求Stable Diffusion生成体育相关图像
请求Canva生成体育相关图像
请求DouBao生成体育相关图像
请求Dreamina生成体育相关图像
请求智谱AI生成体育相关图像
请求通义千问生成体育相关图像
科技主题AI图像生成器
科技主题AI图像生成器
请求MidJourney生成科技相关图像
请求Stable Diffusion生成科技相关图像
请求Canva生成科技相关图像
请求DouBao生成科技相关图像
请求Dreamina生成科技相关图像
请求智谱AI生成科技相关图像
请求通义千问生成科技相关图像
旅行主题AI图像生成器
请求MidJourney生成旅行相关图像
请求Stable Diffusion生成旅行相关图像
请求Canva生成旅行相关图像
请求DouBao生成旅行相关图像
请求Dreamina生成旅行相关图像
请求智谱AI生成旅行相关图像
请求通义千问生成旅行相关图像
自然主题AI图像生成器
自然主题AI图像生成器
请求MidJourney生成自然相关图像
请求Stable Diffusion生成自然相关图像
请求Canva生成自然相关图像
请求DouBao生成自然相关图像
请求Dreamina生成自然相关图像
请求智谱AI生成自然相关图像
请求通义千问生成自然相关图像
日常生活主题AI图像生成器
日常生活主题AI图像生成器
请求MidJourney生成日常生活相关图像
请求Stable Diffusion生成日常生活相关图像
请求Canva生成日常生活相关图像
请求DouBao生成日常生活相关图像
请求Dreamina生成日常生活相关图像
请求智谱AI生成日常生活相关图像
请求通义千问生成日常生活相关图像
成功案例
使用MidJourney生成卡通角色
使用MidJourney绘制奇幻与类人生物
使用MidJourney绘制建筑效果图
使用Stable Diffusion生成卡通角色
使用Stable Diffusion生成奇幻与类人生物
使用Canva绘制奇幻与类人生物
AI视频生成器商店
AI视频生成器评测
使用Sora生成奇幻相关视频
使用Pika生成各类相关视频
使用Kling生成奇幻相关视频
使用Runway生成奇幻相关视频
使用Sora生成奇幻相关视频
法律领域的AI商店

与大多数大型语言模型(LLM)基准测试和竞技场中难以理解的胜率指标(1对1比较)不同,DeepNLP AI商店上的用户评价聚焦于AI工具在行业细分领域的具体表现,例如“向ChatGPT咨询雇佣法相关问题”或“向Gemini咨询合同与协议相关问题”。用户可以从“整体”、“准确性”、“实用性”、“趣味性”等多个维度为AI系统生成的答案进行1至5星的评分,还可以针对服务的定制化方面进行评价,比如“信息是否实时”、“生成速度”等。在这里,我们将涵盖法律领域的多个子方向,包括雇佣法、合同与协议、商业与公司法、房地产、家庭法、人身伤害、刑法、移民法以及民权法等。
提示词(问题)示例
- 您是一位专门从事雇佣法的律师。我将向您咨询几个问题,其中包括:“我的雇主能否无故解雇我?如果我住在加利福尼亚州,我能获得多少赔偿?”
- 关于职场歧视,我的权利有哪些?
- 请以雇佣法专家的身份回答这个问题:“如果我被列入绩效改进计划,我能否就不合理的评估提出申诉?”
雇佣法
雇佣法领域的最佳AI
向ChatGPT咨询雇佣法相关问题
向Perplexity AI咨询雇佣法相关问题
向Gemini咨询雇佣法相关问题
向Claude咨询雇佣法相关问题
合同与协议
合同与协议领域的最佳AI
向Perplexity AI咨询合同与协议相关问题
向ChatGPT咨询合同与协议相关问题
向Gemini咨询合同与协议相关问题
向Claude咨询合同与协议相关问题
商业与公司法
商业与公司法领域的最佳AI
向Gemini咨询商业与公司法相关问题
向ChatGPT咨询商业与公司法相关问题
向Perplexity AI咨询商业与公司法相关问题
向Claude咨询商业与公司法相关问题
房地产
房地产法领域的最佳AI
向ChatGPT咨询房地产相关问题
向Perplexity AI咨询房地产相关问题
向Gemini咨询房地产相关问题
向Claude咨询房地产相关问题
民权法
民权法领域的最佳AI
向Perplexity AI提问民权法相关问题
向Gemini提问民权法相关问题
向ChatGPT提问民权法相关问题
向Claude提问民权法相关问题
家庭法
家庭法领域的最佳AI
向ChatGPT提问家庭法及相关问题
向Claude提问家庭法相关问题
向Perplexity AI提问家庭法相关问题
向Gemini提问家庭法相关问题
人身伤害法
人身伤害法领域的最佳AI
向Perplexity AI提问人身伤害法及事故相关问题
向ChatGPT提问人身伤害法及事故相关问题
向Claude提问人身伤害法及事故相关问题
向Gemini提问人身伤害法及事故相关问题
刑事法
刑事法领域的最佳AI
向Gemini提问刑事法相关问题
向Perplexity AI提问刑事法相关问题
向ChatGPT提问刑事法相关问题
向Claude提问刑事法相关问题
移民法
移民法领域的最佳AI
向Perplexity AI提问移民法相关问题
向Gemini提问移民法相关问题
向ChatGPT提问移民法相关问题
向Gemini提问刑事法相关问题
金融领域AI:用户评分、评论与展示

提示词(问题)
- 您是股票投资专家,我将向您咨询几个问题。例如:“特斯拉是否值得买入?财报季结束后,我是否应该卖出英伟达的股票?”
- 请扮演一名交易员,回答以下问题:“请总结英伟达2024财年第四季度GAAP财务报告中的各项数据,并将其市盈率与其他科技公司如谷歌和苹果进行比较。”
- 请扮演一名金融分析师,绘制一张柱状图,比较谷歌、苹果、特斯拉、英伟达和微软的市值。
投资金融领域的AI
投资金融领域的最佳AI
向ChatGPT询问投资相关事实并寻求建议
向Gemini询问投资相关事实并寻求建议
向Claude提问投资相关问题
向Perplexity AI提问投资相关问题
保险金融领域的AI
保险金融领域最佳AI用户评分、评论与展示
向Gemini提问保险相关问题
向Perplexity AI提问保险相关问题
向ChatGPT提问保险相关问题
向Claude提问保险相关问题
抵押贷款与信贷金融中的AI
抵押贷款与信贷金融领域最佳AI
向ChatGPT提问抵押贷款与信贷相关问题
向Gemini提问抵押贷款与信贷相关问题
向Claude提问抵押贷款与信贷相关问题
向Perplexity AI提问抵押贷款与信贷相关问题
银行业金融中的AI
银行业金融领域最佳AI
向Perplexity AI提问银行业相关问题
向Gemini提问银行业相关问题
向ChatGPT提问银行业相关问题
向Claude提问银行业相关问题
债务金融中的AI
债务金融领域最佳AI
向Claude提问债务相关问题
向ChatGPT提问债务相关问题
向Gemini提问债务相关问题
向Perplexity AI提问债务相关问题
医疗健康领域的AI
医院预约
医院预约领域最佳AI
向Gemini提问医院预约相关问题
向ChatGPT提问医院预约相关问题
向Perplexity AI提问医院预约相关问题
向Claude提问医院预约相关问题
医院
疾病相关
疾病医疗健康领域最佳AI
关于疾病的就医建议
向Gemini提问患病时应避免的食物
向Perplexity AI提问疾病相关问题
向ChatGPT提问疾病相关问题
向Claude提问疾病相关问题
药物
药物医疗健康领域最佳AI
向ChatGPT提问药物相关问题
向Perplexity AI提问药物相关问题
向Gemini提问药物相关问题
向Claude提问药物相关问题
护理
护理医疗健康领域最佳AI
向Gemini提问护理相关问题
向Claude提问护理相关问题
向Perplexity AI提问护理相关问题
向ChatGPT提问护理相关问题
美容
美容医疗健康领域最佳AI
向Gemini提问护理相关问题
向Claude提问护理相关问题
向Perplexity AI提问护理相关问题
向ChatGPT提问护理相关问题
老年护理
老年护理领域的最佳AI
向Perplexity AI提问老年护理相关问题
向Gemini提问老年护理相关问题
向ChatGPT提问老年护理相关问题
向Claude提问老年护理相关问题
医疗器械
医疗器械领域的最佳AI
向ChatGPT提问医疗器械相关问题
向Claude提问医疗器械相关问题
向Perplexity AI提问医疗器械相关问题
向Gemini提问医疗器械相关问题
面向老年人的AI:用户评分、评论与展示
提示(问题)示例 服用[药物]有哪些副作用? 我该如何管理[疾病]?
例如: 泰诺有哪些副作用? 我该如何缓解关节炎疼痛?
展示案例
老年人向Gemini提问个人爱好相关问题
老年人向Gemini提问法律问题
老年人向Gemini提问健康与医药相关问题
老年人向ChatGPT提问健康与医药相关问题
老年人向Perplexity AI提问健康与医药相关问题
老年人向Claude提问健康与医药相关问题
面向儿童的AI:用户评分、评论与展示
提示(问题)示例
儿童故事讲述
- 请给我4岁的女儿讲一个关于独角兽的睡前故事。
- 帮我写一个关于汪汪队立大功里的狗狗们对抗坏蛋的故事。
绘画|AIGC
- 帮我画一张汪汪队立大功里的狗狗Chase驾驶警车的画面。
- 帮我画一张小猪佩奇在游泳池里玩耍的画面。
展示案例 向Gemini请求讲一个睡前故事 向Gemini请求绘制卡通人物 向ChatGPT请求讲一个睡前故事 向ChatGPT请求绘制卡通角色
生活方式中的AI
提示(问题)示例
模拟${角色}
我希望你以${角色}的身份作出回应,使用${角色}的语气和方式来回答。请不要添加任何解释。我的第一句话是${your_question}。
展示案例
向ChatGPT请求扮演情侣关系中的恋人
向Gemini请求扮演情侣关系中的恋人
向Character AI请求扮演情侣关系中的恋人
向Douyin的Doubao请求扮演情侣关系中的恋人
向阿里巴巴的Qwen AI请求扮演情侣关系中的恋人
向智谱AI请求扮演情侣关系中的恋人
生产力工具中的AI

写作工具
研究分析
编程
提示: 向我展示${编程语言}中${算法}的代码,无需解释。 用${编程语言}编写实现${功能}的代码,无需解释。 生成一个${描述}网站的${编程语言}代码,无需解释。 从${数据源}中提取${统计量},并以${格式}展示。
例如:
- 向我展示KL散度的LaTeX代码。
- 编写Python代码实现快速排序。
- 生成一个社区网站登录页面的HTML代码,无需解释。
- 查找2023年美国各州的离婚率,并以表格和折线图的形式展示。
展示
编程
绘图聊天
数据分析
四足机器人评测
四足机器人评测
波士顿动力Spot机器狗用户评价
Unitree Go2机器狗用户评价
Anybotics机器狗用户评价
类人机器人评测
类人机器人评测
Figure 02类人机器人用户评价
Tesla Cybercab Robotaxi早期用户评价
Tesla Optimus类人机器人评测
无人出租车评测
无人出租车评测
乘坐Waymo无人出租车并写下您的评价
乘坐百度Apollo无人出租车并写下您的评价
使用特斯拉全自动驾驶FSD功能乘车
电动汽车评测
电动汽车评测
宝马i4电动车车主评价
现代IONIQ 6电动车车主评价
比亚迪Seal电动车车主评价
特斯拉Model 3电动车车主评价
DeepNLP AI与机器人社区
DeepNLP AI与机器人社区,面向AI从业者
您是否愿意分享使用AI生产力工具(如AI写作编码助手)的经验?
您认为AI视频生成应用和工具有哪些必备功能?
Runway、Luma、Pika、Kling等AI视频生成工具,哪一款最好?为什么?
四足机器狗的典型应用场景有哪些?
类人机器人丈夫投票:选出最受欢迎的外观
类人机器人妻子:您希望自己的机器人妻子长得像哪位女性?
未来类人机器人应具备哪些最重要的功能?
类人机器人的典型应用场景有哪些?
DeepNLP智能体工具
AI智能体可视化评测:异步多智能体模拟
对话可视化智能体:面向AI系统的多模态可视化工具评述
相关博客
http://www.deepnlp.org/blog/
http://www.deepnlp.org/equation/
http://www.deepnlp.org/search/
http://www.deepnlp.org/workspace/ai_courses/
http://www.deepnlp.org/workspace/aigc_chart/
http://www.deepnlp.org/workspace/ai_writer/
http://www.deepnlp.org/workspace/detail/
统计学方程公式
机器学习方程公式
多模态生成模型简介
生成式AI搜索引擎优化:如何提升你的内容
儿童AI课程
时尚中的AI:如何辨别IWC沙夫豪森手表的真伪
时尚中的AI:如何辨别芬迪包的真伪
时尚中的AI:如何辨别蔻驰包的真伪
时尚中的AI:如何辨别普拉达包的真伪
时尚中的AI:如何辨别古驰包的真伪
时尚中的AI:如何辨别迪奥包的真伪
时尚中的AI:如何辨别爱马仕包的真伪
时尚中的AI:如何辨别香奈儿包的真伪
时尚中的AI:如何辨别路易威登包的真伪
时尚中的AI:如何辨别欧米茄手表的真伪
时尚中的AI:如何辨别劳力士手表的真伪
DeepNLP评测小组
DeepNLP汽车评测小组
DeepNLP电商评测小组
DeepNLP电商包包评测小组
DeepNLP手表包包评测小组
DeepNLP电商品牌评测列表
DeepNLP汽车品牌评测列表
AI智能体可视化评测:异步多智能体仿真
对话可视化智能体:面向AI系统的多模态可视化工具评述
对话可视化工具
智能体可视化工具
======================================================================================================================================================================================================
截至2020年底,deepnlp库已归档,仅支持TensorFlow 1.13及以下版本。
基于TensorFlow实现的深度学习自然语言处理流水线。本项目遵循“简单性”原则,旨在利用TensorFlow的深度学习库来构建全新的NLP流水线。您可以扩展该项目,使用自己的语料或语言训练模型。同时提供了中文语料的预训练模型。 此外,还提供免费的RESTful NLP API服务。详情请访问:http://www.deepnlp.org/api/v1.0/pipeline。
简要介绍
模块
NLP流水线模块:
- 分词/标记化
- 词性标注(POS)
- 命名实体识别(NER)
- 句法分析(Parse)
- textsum:基于Seq2Seq-Attention机制的自动摘要模型
- textrank:提取最重要的句子
- textcnn:文档分类
- Web API:免费的TensorFlow驱动的Web API
- 计划中:自动摘要
算法(紧跟当前最先进水平):
- 分词:基于Python CRF++模块的线性链条件随机场(CRF)
- 词性标注:基于TensorFlow的LSTM/BI-LSTM/LSTM-CRF网络
- 命名实体识别:基于TensorFlow的LSTM/BI-LSTM/LSTM-CRF网络
- 句法分析:采用前馈神经网络的Arc-Standard系统
- 文本摘要:带有注意力机制的Seq2Seq模型
- TextCNN:卷积神经网络
预训练模型:
- 中文:分词、词性标注、命名实体识别、句法分析(基于1998年《中国日报》语料)
- 特定领域的NER模型也一并提供:通用、娱乐、O2O等……欢迎贡献
- 英文:词性标注(基于Brown语料)
- 对于您的特定语言,您可以轻松使用脚本,结合您选择的语言语料来训练模型。
安装
要求
- CRF++(>=0.54)
- TensorFlow(1.4)
- Python(已测试过python2.7和python3.6) 本项目与最新的TensorFlow版本保持同步。 对于TensorFlow(<=0.12.0),请使用deepnlp <=0.1.5版本。 TensorFlow(1.0-1.3),请使用deepnlp = 0.1.6版本。 TensorFlow(1.4),请使用deepnlp = 0.1.7版本。 更多详情请参阅RELEASE.md文件。
使用pip安装
# 在Linux系统上运行以下命令:
pip install deepnlp
由于软件包大小限制,英文词性标注模型以及特定领域的命名实体识别模型文件并未在PyPI上发布。 您可以从GitHub下载预训练模型文件,并将其放置在您的安装目录.../site-packages/.../deepnlp/...中。 模型文件路径:../pos/ckpt/en/pos.ckpt;../ner/ckpt/zh/ner.ckpt
- 源码分发版,例如deepnlp-0.1.7.tar.gz:https://pypi.python.org/pypi/deepnlp
# 在Linux系统上运行以下命令:
tar zxvf deepnlp-0.1.7.tar.gz
cd deepnlp-0.1.7
python setup.py install
- 初始设置
# 使用脚本安装crf++0.58软件包
sh ./deepnlp/segment/install_crfpp.sh
# 下载所有预训练模型
python ./test/test_install.py
# 或者通过以下命令下载预训练模型:
import deepnlp
deepnlp.download('segment')
deepnlp.download('pos')
deepnlp.download('ner')
deepnlp.download('parse')
- 运行示例
# 进入./deepnlp/test文件夹
cd test
python test_segment.py # 分词
python test_pos_en.py # 英文词性标注
python test_ner_zh.py # 中文命名实体识别
python test_ner_domain.py # 领域特定的命名实体识别模型
python test_ner_dict_udf.py # 加载用户自定义词典及UDF进行消歧义
python test_nn_parser.py # 句法分析
python test_api_v1_module.py
python test_api_v1_pipeline.py
教程
设置编码
设置编码 对于Python2,其默认编码为ASCII而非Unicode,因此需使用__future__模块使其与Python3兼容。
#coding=utf-8
from __future__ import unicode_literals # 与Python3 Unicode兼容
下载预训练模型
下载预训练模型 如果您通过pip安装了deepnlp,由于文件大小限制,预训练模型并不会随软件包一同分发。不过,您可以通过调用download函数来获取完整的“分词”、“词性标注”(英、中)、“命名实体识别”(中、娱乐、O2O)以及“文本摘要”模型。
import deepnlp
# 下载所有模块
deepnlp.download()
# 下载特定模块
deepnlp.download('segment')
deepnlp.download('pos')
deepnlp.download('ner')
deepnlp.download('parse')
# 下载指定模块及领域特定模型
deepnlp.download(module = 'pos', name = 'en')
deepnlp.download(module = 'ner', name = 'zh_entertainment')
分词
分词模块
#coding=utf-8
from __future__ import unicode_literals
from deepnlp import segmenter
tokenizer = segmenter.load_model(name = 'zh_entertainment')
text = "我刚刚在浙江卫视看了电视剧老九门,觉得陈伟霆很帅"
segList = tokenizer.seg(text)
text_seg = " ".join(segList)
#结果
# 我 刚刚 在 浙江卫视 看 了 电视剧 老九门 , 觉得 陈伟霆 很 帅
词性标注
词性标注
#coding:utf-8
from __future__ import unicode_literals
import deepnlp
deepnlp.download('pos')
## 英文模型
from deepnlp import pos_tagger
tagger = pos_tagger.load_model(name = 'en') # 加载英文模型,语言代码'en',基于Brown语料库
text = "I want to see a funny movie"
words = text.split(" ") # Unicode编码
print (" ".join(words))
tagging = tagger.predict(words)
for (w,t) in tagging:
pair = w + "/" + t
print (pair)
#结果
#I/nn want/vb to/to see/vb a/at funny/jj movie/nn
## 中文模型
from deepnlp import segmenter
from deepnlp import pos_tagger
tagger = pos_tagger.load_model(name = 'zh') # 加载中文模型,语言代码'zh',基于《中国日报》语料
text = "我爱吃北京烤鸭"
words = segmenter.seg(text) # 单词以Unicode编码
print (" ".join(words))
tagging = tagger.predict(words) # 输入:Unicode编码
for (w,t) in tagging:
pair = w + "/" + t
print (pair)
#结果
#我/r 爱/v 吃/v 北京/ns 烤鸭/n
命名实体识别
命名实体识别
from __future__ import unicode_literals # 与Python3 Unicode兼容
import deepnlp
deepnlp.download('ner') # 如果是通过pip安装的,则从GitHub下载NER预训练模型
from deepnlp import ner_tagger
# 示例:娱乐模型
tagger = ner_tagger.load_model(name = 'zh_entertainment') # 基于LSTM的基础模型
#加载娱乐词典
tagger.load_dict("zh_entertainment")
text = "你 最近 在 看 胡歌 演的 猎场 吗 ?"
words = text.split(" ")
tagset_entertainment = ['actor', 'role_name', 'teleplay', 'teleplay_tag']
tagging = tagger.predict(words, tagset = tagset_entertainment)
for (w,t) in tagging:
pair = w + "/" + t
print (pair)
#结果
#你/nt
#最近/nt
#在/nt
#看/nt
#胡歌/actor
#演的/nt
#猎场/teleplay
#吗/nt
#?/nt
依存句法分析
依存句法分析
from __future__ import unicode_literals # 兼容Python3的Unicode编码
from deepnlp import nn_parser
parser = nn_parser.load_model(name = 'zh')
#示例1,同时输入词和词性标注
words = ['它', '熟悉', '一个', '民族', '的', '历史']
tags = ['r', 'v', 'm', 'n', 'u', 'n']
#句法分析
dep_tree = parser.predict(words, tags)
#从Transition命名元组中获取结果
num_token = dep_tree.count()
print ("id\tword\tpos\thead\tlabel")
for i in range(num_token):
cur_id = int(dep_tree.tree[i+1].id)
cur_form = str(dep_tree.tree[i+1].form)
cur_pos = str(dep_tree.tree[i+1].pos)
cur_head = str(dep_tree.tree[i+1].head)
cur_label = str(dep_tree.tree[i+1].deprel)
print ("%d\t%s\t%s\t%s\t%s" % (cur_id, cur_form, cur_pos, cur_head, cur_label))
# 结果
id word pos head label
1 它 r 2 SBV
2 熟悉 v 0 HED
3 一个 m 4 QUN
4 民族 n 5 DE
5 的 u 6 ATT
6 历史 n 2 VOB
流水线
#coding:utf-8
from __future__ import unicode_literals
from deepnlp import pipeline
p = pipeline.load_model('zh')
#分词
text = "我爱吃北京烤鸭"
res = p.analyze(text)
print (res[0].encode('utf-8'))
print (res[1].encode('utf-8'))
print (res[2].encode('utf-8'))
words = p.segment(text)
pos_tagging = p.tag_pos(words)
ner_tagging = p.tag_ner(words)
print (pos_tagging.encode('utf-8'))
print (ner_tagging.encode('utf-8'))
文本摘要
自动文摘
详情请见:README
TextRank
重要句子抽取
详情请见:README
TextCNN(开发中)
文档分类
训练你的模型
自行训练模型 ###分词模型 使用说明:README
###词性标注模型 使用说明:README
###命名实体识别模型 使用说明:README
###依存句法分析模型 使用说明:README
###文本摘要模型 使用说明:README
Web API服务
www.deepnlp.org 为句子和段落的常见NLP模块提供免费的Web API服务。 这些API是基于预训练TensorFlow模型的RESTful接口。目前支持中文。
- RESTful API
通过浏览器测试API,需先登录
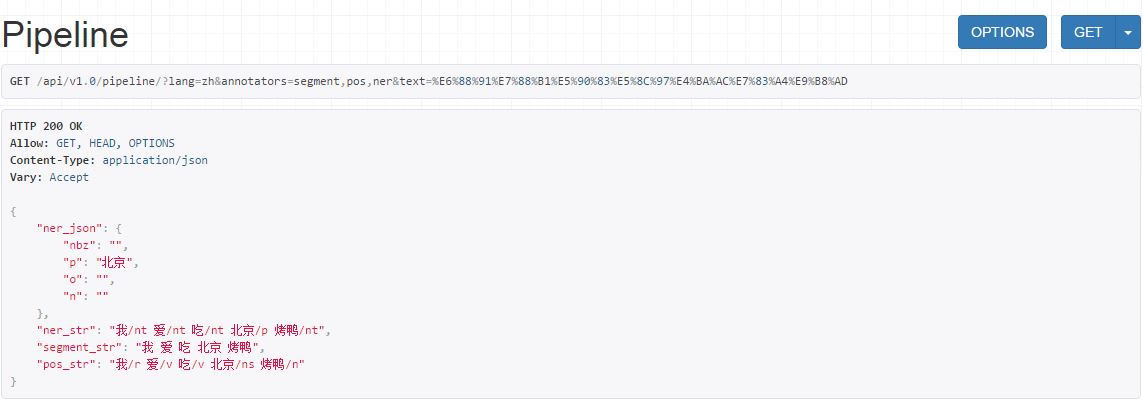
从Python调用API
更多详情请参阅 ./deepnlp/test/test_api_v1_module.py。
#coding:utf-8
from __future__ import unicode_literals
import json, requests, sys, os
if (sys.version_info>(3,0)): from urllib.parse import quote
else : from urllib import quote
from deepnlp import api_service
login = api_service.init() # 注册,若失败,则加载默认的空登录{},权限受限
conn = api_service.connect(login) # 保存包含登录Cookie的连接
# 示例URL
# http://www.deepnlp.org/api/v1.0/pipeline/?lang=zh&annotators=segment,pos,ner&text=我爱吃上海小笼包
# 定义文本和语言
text = ("我爱吃上海小笼包").encode("utf-8") # 将文本从Unicode转换为UTF-8字节
# 设置词性标注的URL
url_pos = 'http://www.deepnlp.org/api/v1.0/pos/?"+ "lang=" + quote('zh') + "&text=" + quote(text)
web = requests.get(url_pos, cookies = conn)
tuples = json.loads(web.text)
print (tuples['pos_str'].encode('utf-8')) # POS JSON {'pos_str', 'w1/t1 w2/t2'} 返回字符串
中文简介
deepnlp项目是一个基于TensorFlow平台的Python版NLP工具包,旨在将TensorFlow深度学习平台上的模块与最新算法相结合, 提供NLP基础模块的支持,并扩展到更复杂的任务,如生成式文摘等。
NLP工具包模块
- 分词 Word Segmentation/Tokenization
- 词性标注 Part-of-speech (POS)
- 命名实体识别 Named-entity-recognition(NER)
- 依存句法分析 Dependency Parsing (Parse)
- 自动文摘 Textsum (Seq2Seq-Attention)
- 关键句子抽取 Textrank
- 文本分类 Textcnn (WIP)
- 可调用 Web Restful API
- 计划中:句法分析 Parsing
算法实现
- 分词:线性链条件随机场 Linear Chain CRF,基于CRF++库实现
- 词性标注:单向LSTM/双向BI-LSTM,基于TensorFlow实现
- 命名实体识别:单向LSTM/双向BI-LSTM/LSTM-CRF混合网络,基于TensorFlow实现
- 依存句法分析:基于arc-standard体系的神经网络解析器
预训练模型
- 中文:基于人民日报语料和微博混合语料训练的分词、词性标注和实体识别模型
API服务
http://www.deepnlp.org 出于技术交流的目的,提供免费的API接口,用于对文本和篇章进行深度学习NLP分析,简单注册后即可使用。 API符合RESTful风格,内部使用的是基于TensorFlow预训练的深度学习模型。具体使用方法请参考博客: http://www.deepnlp.org/blog/tutorial-deepnlp-api/
API目前提供以下模块支持:
- 分词: http://www.deepnlp.org/api/v1.0/segment/?lang=zh&text=我爱吃北京烤鸭
- 词性标注: http://www.deepnlp.org/api/v1.0/pos/?lang=zh&text=我爱吃北京烤鸭
- 命名实体识别: http://www.deepnlp.org/api/v1.0/ner/?lang=zh&text=我爱吃北京烤鸭
- 流水线: http://www.deepnlp.org/api/v1.0/pipeline/?lang=zh&annotators=segment,pos,ner&text=我爱吃北京烤鸭
安装说明
需要
- CRF++ (>=0.54) 可从 https://taku910.github.io/crfpp/ 下载安装
- Tensorflow(1.0) 该项目的TensorFlow函数会根据最新版本更新,目前支持Tensorflow 1.0版本,对于旧版本的Tensorflow(<=0.12.0),请使用 deepnlp <=0.1.5版本,更多信息请查看 RELEASE.md
使用pip安装
pip install deepnlp
- 从源码安装,下载deepnlp-0.1.7.tar.gz文件:https://pypi.python.org/pypi/deepnlp
# Linux,运行脚本:
tar zxvf deepnlp-0.1.7.tar.gz
cd deepnlp-0.1.7
python setup.py install
- 初始设置
# 运行脚本安装crf++0.58包
sh ./deepnlp/segment/install_crfpp.sh
# 运行脚本下载预训练模型进行测试
python ./test/test_install.py
参考文献
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
cs-video-courses
cs-video-courses 是一个精心整理的计算机科学视频课程清单,旨在为自学者提供系统化的学习路径。它汇集了全球知名高校(如加州大学伯克利分校、新南威尔士大学等)的完整课程录像,涵盖从编程基础、数据结构与算法,到操作系统、分布式系统、数据库等核心领域,并深入延伸至人工智能、机器学习、量子计算及区块链等前沿方向。 面对网络上零散且质量参差不齐的教学资源,cs-video-courses 解决了学习者难以找到成体系、高难度大学级别课程的痛点。该项目严格筛选内容,仅收录真正的大学层级课程,排除了碎片化的简短教程或商业广告,确保用户能接触到严谨的学术内容。 这份清单特别适合希望夯实计算机基础的开发者、需要补充特定领域知识的研究人员,以及渴望像在校生一样系统学习计算机科学的自学者。其独特的技术亮点在于分类极其详尽,不仅包含传统的软件工程与网络安全,还细分了生成式 AI、大语言模型、计算生物学等新兴学科,并直接链接至官方视频播放列表,让用户能一站式获取高质量的教育资源,免费享受世界顶尖大学的课堂体验。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。