keeper.sh
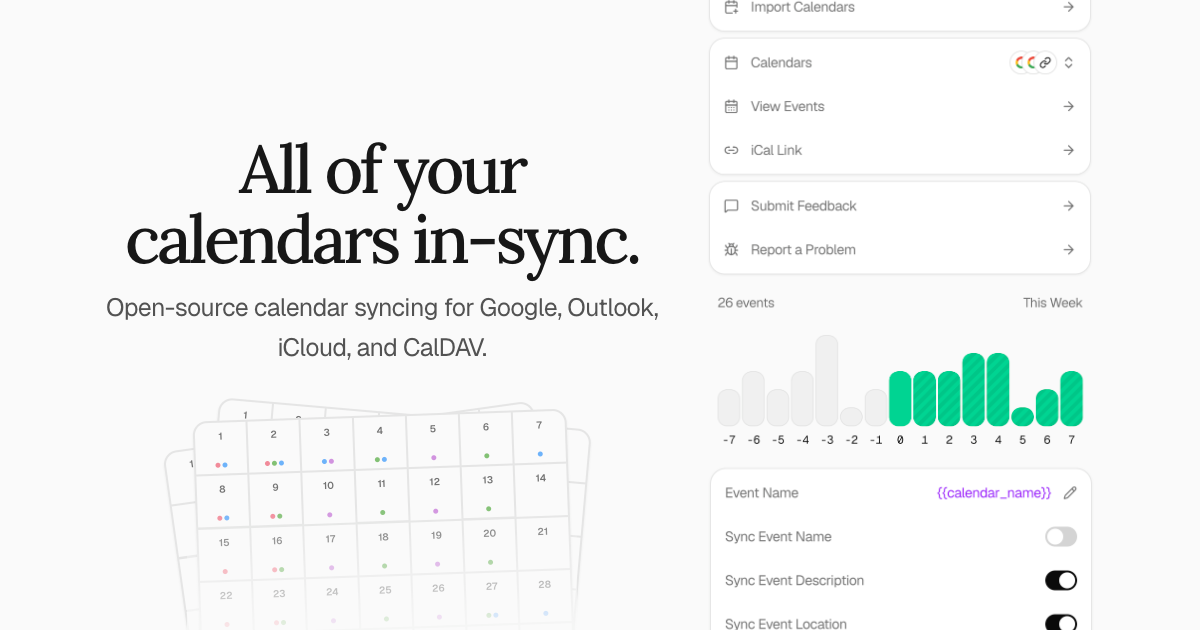
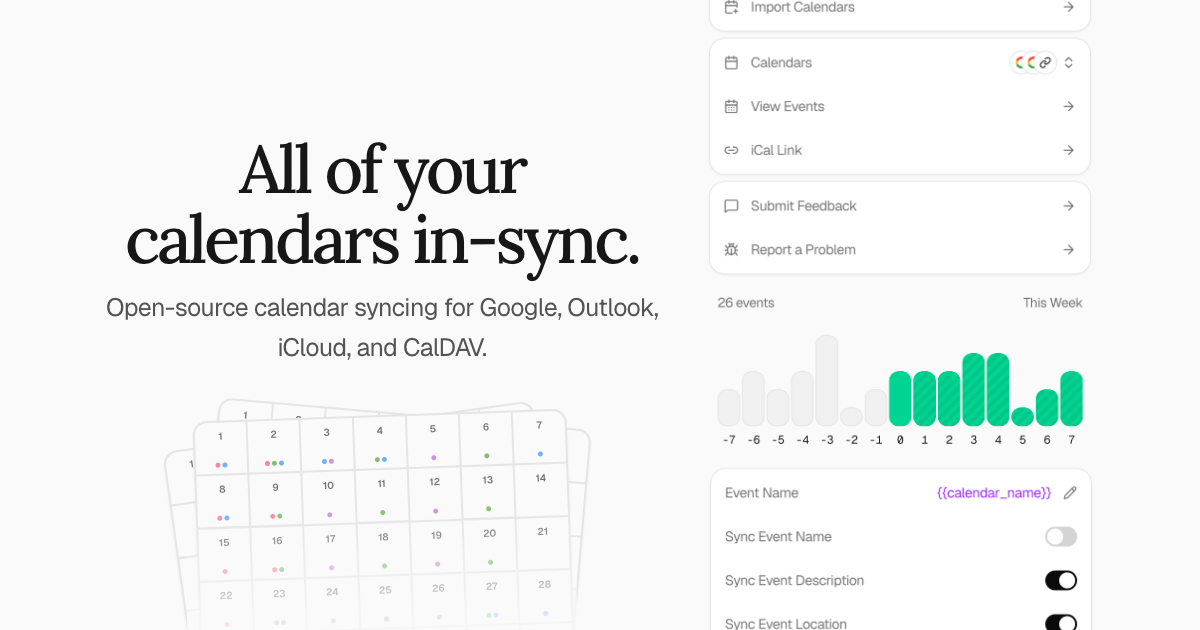
keeper.sh 是一个开源的日历同步工具,支持从 Google、Outlook、iCloud 等主流平台及 ICS 文件聚合日历事件,并通过统一的 MCP 协议服务器实现跨平台事件同步与管理。它解决了用户在多日历系统中手动同步导致的事件冲突、时间错位等问题,尤其适合需要同时管理个人、工作及业务日历的用户。
对于开发者或自托管爱好者,keeper.sh 提供了基于 AGPL-3.0 协议的完整源码,支持本地部署与 HTTPS 安全环境搭建。其核心亮点包括:
- 智能同步机制:通过源-目标事件映射自动处理新增、删除与更新操作,避免冗余事件残留;
- MCP 协议支持:为 AI 代理提供标准化的日历访问接口,便于集成自动化场景;
- 跨平台兼容性:覆盖主流日历服务及 CalDAV/ICS 格式,无需依赖特定厂商生态。
普通用户可通过图形界面快速配置同步规则,开发者则可利用其模块化架构(PostgreSQL 数据库 + Redis 缓存 + 微服务架构)进行二次开发。若你正被多平台日历同步的低效与不稳定性困扰,keeper.sh 提供了一个轻量且可靠的开源解决方案。
使用场景
一位负责多个项目的独立开发者同时管理着工作 Gmail、Outlook 客户日历以及个人 iCloud 日程,每天需要频繁在不同平台间协调会议时间。
没有 keeper.sh 时
- 需要在三个不同的日历应用间反复切换查看,极易漏看冲突时段导致会议撞车。
- 删除了某个会议后,其他平台仍残留无效事件,导致主视图长期被垃圾数据污染,影响判断。
- 无法让 AI 助手直接读取所有分散的日程,难以实现基于真实时间的自动化会议安排建议。
- 手动同步耗时且不可靠,经常出现某一方更新后另一方未生效的情况,造成沟通误会。
使用 keeper.sh 后
- keeper.sh 自动聚合所有来源事件,提供统一视图,彻底消除跨平台切换的麻烦。
- 内置智能清理机制,自动移除已失效的远程事件,保持日历视图始终清爽准确。
- 通过 MCP 协议直接暴露日程接口给 AI Agent,实现基于真实时间的自动化排期。
- 双向同步引擎确保任意端的修改即刻更新到所有关联日历,杜绝信息不同步。
keeper.sh 实现了跨平台日程的统一管控与自动化流转,彻底消除了多日历管理的摩擦成本。
运行环境要求
- Linux
- macOS
未说明
未说明
快速开始
关于
Keeper 是一款简单且开源的日历同步工具。它允许您从远程托管的 iCal 或 ICS 链接中拉取事件,并将其推送到一个或多个日历中,以便所有日历的时间段都能对齐。
功能特性
- 聚合来自远程源的日历事件
- 与事件内容无关的同步引擎
- 将聚合后的事件推送到一个或多个日历
- MCP(模型上下文协议)服务器,用于 AI 代理访问日历
- 基于 AGPL-3.0 开源
- 易于自行托管
- 易于清理远程事件
错误报告与功能请求
如果您遇到错误或有任何功能想法,可以在 GitHub 上提交问题,我们将尽快进行筛选和处理。
贡献
我们欢迎高价值和高品质的贡献。在着手开发您希望合并的大型功能之前,请先开启一个问题进行讨论。
本地开发
开发环境通过带有自动 TLS 的 Caddy 反向代理运行在 https://keeper.localhost 的 HTTPS 后面。根据 RFC 6761,.localhost 顶级域名会自动解析为 127.0.0.1 —— 无需 /etc/hosts 条目。
前置条件
入门指南
bun install
生成并信任根证书颁发机构 (CA)
开发环境通过 Caddy 运行在 HTTPS 后面。您需要生成一个本地根证书颁发机构 (Certificate Authority, CA) 并信任它,以便您的浏览器接受该证书。
mkdir -p .pki
openssl req -x509 -new -nodes \
-newkey ec -pkeyopt ec_paramgen_curve:prime256v1 \
-keyout .pki/root.key -out .pki/root.crt \
-days 3650 -subj "/CN=Keeper.sh CA"
然后在您的平台上信任它:
macOS
sudo security add-trusted-cert -d -r trustRoot \
-k /Library/Keychains/System.keychain .pki/root.crt
Linux
sudo cp .pki/root.crt /usr/local/share/ca-certificates/keeper-dev-root.crt
sudo update-ca-certificates
启动开发环境
bun dev
这将通过 Docker Compose 启动 PostgreSQL、Redis 和 Caddy 反向代理,以及本地的 API、Web、MCP 和 cron 服务。运行后,打开 https://keeper.localhost。
架构
| 服务 | 本地端口 | 访问方式 |
|---|---|---|
| Caddy | 443 | https://keeper.localhost |
| Web | 5173 | 由 Caddy 代理 |
| API | 3000 | 由 Web 在 /api 处代理 |
| MCP | 3001 | 由 Web 在 /mcp 处代理 |
| Postgres | 5432 | postgresql://postgres:postgres@localhost:5432/postgres |
| Redis | 6379 | redis://localhost:6379 |
常见问题
为什么会有这个项目?
因为我需要它。自从开始使用 Sedna——AI 治理平台——以来,我不得不在三个日历之间工作。一个用于商务,一个用于工作,一个用于个人。
会议冲突的情况频繁发生,令人沮丧。
为什么不使用其他服务?
我可能已经尝试过了。它可能太挑剔了,最终浪费了我几个小时的时间去删除那些它似乎不再想跟踪的陈旧事件,或者根本无法可靠地同步。
同步引擎是如何工作的?
- 如果我们有一个本地事件,但没有对应的事件“源 → 目标”映射,我们将该事件推送到目标日历。
- 如果我们有事件的映射,但源 ID 在源上不再存在,我们从目标中删除该事件。
- 任何带有由 Keeper 创建标记但没有相应本地跟踪的事件,我们都会将其移除。这仅为了向后兼容而执行。
事件会被标记为由 Keeper 创建,方法是在远程 UID 上使用 @keeper.sh 后缀,或者对于像 Outlook 这样不支持自定义 UID 的平台,我们将其放入 "keeper.sh" 类别中。
注意事项
- Keeper 目前仅跟踪时间段,而非事件详情、摘要、描述等。如果您需要这些功能,我推荐 OneCal。
- Keeper 目前仅从远程且公开可用的 iCal/ICS URL 获取数据,这意味着如果您的安全策略不允许这样做,其他解决方案可能更适合您。
- MCP 服务器仅提供只读访问权限。AI 代理可以列出日历和查询事件,但不能创建、修改或删除它们。
云托管
我已经让 Keeper 易于自行托管,但无论您是单纯想支持该项目,还是不想处理配置和运行自己基础设施的麻烦和开销,云托管始终是一个选项。
前往 keeper.sh 开始使用云托管版本。使用代码 README 可享受 25% 折扣。
| 免费 | 专业版 (云托管) | 专业版 (自行托管) | |
|---|---|---|---|
| 月费 | $0 USD | $5 USD | $0 |
| 年费 | $0 USD | $42 USD (-30%) | $0 |
| 刷新间隔 | 30 分钟 | 1 分钟 | 1 分钟 |
| 源限制 | 2 | ∞ | ∞ |
| 目标限制 | 1 | ∞ | ∞ |
自行托管
通过自行托管 Keeper,您可以免费获得所有高级功能,能够保证数据治理和自主权,而且很有趣。如果您将自行托管,请考虑通过在 GitHub 上赞助我来支持我和项目的开发。
目前有七种镜像可用,其中两种设计为方便使用,另外五种设计用于服务于细粒度的底层服务。
[!NOTE]
从旧版本迁移? 如果您是从较旧的基于 Next.js 的版本升级,请参阅 迁移指南 以了解环境变量更改。如果检测到旧的环境变量,新的 Web 服务器也会在启动时打印迁移通知。
环境变量
| 变量名 | 服务 | 说明 |
|---|---|---|
| DATABASE_URL | api, cron, worker, mcp |
PostgreSQL 连接 URL。 例如: postgres://user:pass@postgres:5432/keeper |
| REDIS_URL | api, cron, worker |
Redis 连接 URL。所有服务必须使用相同的 Redis 实例。 例如: redis://redis:6379 |
| WORKER_JOB_QUEUE_ENABLED | cron |
必填。设置为 true 将同步任务加入 worker 队列,或设置为 false 禁用。如果未设置,cron 服务将退出并显示迁移提示。 |
| BETTER_AUTH_URL | api, mcp |
用于身份验证重定向的基础 URL。 例如: http://localhost:3000 |
| BETTER_AUTH_SECRET | api, mcp |
会话签名的密钥。 例如: openssl rand -base64 32 |
| API_PORT | api |
Bun API 监听的端口。容器镜像中默认为 3001。 |
| ENV | web |
可选。运行时环境。可以是 development、production 或 test。默认为 production。 |
| PORT | web |
Web 服务器监听的端口。容器镜像中默认为 3000。 |
| VITE_API_URL | web |
Web 服务器用于代理请求到 Bun API 的 URL。 例如: http://api:3001 |
| COMMERCIAL_MODE | api, cron |
启用 Polar 计费流程。如果使用 Polar 进行订阅管理,请设置为 true。 |
| POLAR_ACCESS_TOKEN | api, cron |
可选。用于订阅管理的 Polar API 令牌。 |
| POLAR_MODE | api, cron |
可选。Polar 环境,sandbox 或 production。 |
| POLAR_WEBHOOK_SECRET | api |
可选。用于验证 Polar webhooks 的密钥。 |
| ENCRYPTION_KEY | api, cron, worker |
用于静态加密 CalDAV 凭证的密钥。 例如: openssl rand -base64 32 |
| RESEND_API_KEY | api |
可选。通过 Resend 发送邮件的 API 密钥。 |
| PASSKEY_RP_ID | api |
可选。通行密钥认证的依赖方 ID。 |
| PASSKEY_RP_NAME | api |
可选。通行密钥的依赖方显示名称。 |
| PASSKEY_ORIGIN | api |
可选。允许通行密钥流的源(例如:https://keeper.example.com)。 |
| GOOGLE_CLIENT_ID | api, cron, worker |
可选。Google 日历集成所需。 |
| GOOGLE_CLIENT_SECRET | api, cron, worker |
可选。Google 日历集成所需。 |
| MICROSOFT_CLIENT_ID | api, cron, worker |
可选。Microsoft Outlook 集成所需。 |
| MICROSOFT_CLIENT_SECRET | api, cron, worker |
可选。Microsoft Outlook 集成所需。 |
| POSTGRES_PASSWORD | standalone |
可选。keeper-standalone 内部 PostgreSQL 数据库的自定义密码。如果未设置,默认为 keeper。数据库未在容器外暴露,因此风险较低,但可设置以实现纵深防御。 |
| BLOCK_PRIVATE_RESOLUTION | api, cron |
可选。设置为 true 以阻止出站获取(ICS 订阅、CalDAV 服务器)解析到私有/保留网络地址。防止 SSRF (服务器端请求伪造)。默认为 false,以便与使用本地 CalDAV/ICS 服务器的自托管设置向后兼容。 |
| PRIVATE_RESOLUTION_WHITELIST | api, cron |
可选。当 BLOCK_PRIVATE_RESOLUTION 为 true 时,此逗号分隔的主机名或 IP 列表不受限制。例如: 192.168.1.50,radicale.local,10.0.2.12 |
| TRUSTED_ORIGINS | api |
可选。用于 CSRF (跨站请求伪造) 保护的额外受信任源的逗号分隔列表。 例如: http://192.168.1.100,http://keeper.local,https://keeper.example.com |
| MCP_PUBLIC_URL | api, mcp |
可选。MCP 资源的公共 URL。在 API 上启用 OAuth (授权协议) 并向客户端标识 MCP 服务器。 例如: https://keeper.example.com/mcp |
| VITE_MCP_URL | web |
可选。Web 服务器用于代理 /mcp 请求到 MCP 服务的内部 URL。例如: http://mcp:3002 |
| MCP_PORT | mcp |
可选。MCP 服务器监听的端口。 例如: 3002 |
| OTEL_EXPORTER_OTLP_ENDPOINT | api, cron, worker, mcp, web |
可选。设置后,启用通过 pino-opentelemetry-transport 将结构化日志转发到 OpenTelemetry (开放遥测) 收集器。传输运行在专用工作线程中,不影响应用性能。例如: https://otel-collector.example.com:4318 |
| OTEL_EXPORTER_OTLP_PROTOCOL | api, cron, worker, mcp, web |
可选。OTLP 导出器使用的协议。根据 OpenTelemetry 规范默认为 http/protobuf。例如: http/protobuf, grpc, http/json |
| OTEL_EXPORTER_OTLP_HEADERS | api, cron, worker, mcp, web |
可选。随每个 OTLP 导出请求发送的头部。用于身份验证(例如 Basic auth 或 API 密钥)。 例如: Authorization=Basic dXNlcjpwYXNz |
以下环境变量在构建时被固化到 Web 镜像中。它们在官方 Docker (Docker 容器引擎) 镜像中已预配置,仅当您从源代码构建时才需要设置。
| Name | Description |
|---|---|
| VITE_COMMERCIAL_MODE | 切换 Web UI 中的商业模式(true/false)。 |
| POLAR_PRO_MONTHLY_PRODUCT_ID | 可选。用于支持应用内升级链接的 Polar 月度产品 ID。 |
| POLAR_PRO_YEARLY_PRODUCT_ID | 可选。用于支持应用内升级链接的 Polar 年度产品 ID。 |
| VITE_VISITORS_NOW_TOKEN | 可选。visitors.now 分析令牌 |
| VITE_GOOGLE_ADS_ID | 可选。Google Ads 转化跟踪 ID(例如 AW-123456789) |
| VITE_GOOGLE_ADS_CONVERSION_LABEL | 可选。用于购买跟踪的 Google Ads 转化标签 |
[!NOTE]
keeper-standalone(独立容器) 自动内部配置所有内容——Web 服务器和 Bun (JavaScript 运行时) API (应用程序接口) 都位于端口80上的单个 Caddy (Web 服务器) 反向代理之后。keeper-services在一个容器内运行 Web、API、cron (定时任务) 和 worker (工作进程) 服务。Web 服务器在内部代理/api请求,因此只需暴露端口3000。- 对于独立镜像,只需暴露
web容器。API 通过VITE_API_URL内部访问。
镜像
| Tag | Description | Included Services |
|---|---|---|
keeper-standalone:2.9 |
“独立”镜像包含了您启动 Keeper 所需的一切,且配置尽可能少。 | keeper-web, keeper-api, keeper-cron, keeper-worker, redis (内存数据库), postgresql (关系型数据库), caddy |
keeper-services:2.9 |
如果您希望 Redis 和数据库存在于容器外部,可以使用“服务”镜像来启动,而不将它们包含在镜像中。 | keeper-web, keeper-api, keeper-cron, keeper-worker |
keeper-web:2.9 |
包含 Vite (前端构建工具) SSR (服务端渲染) Web 界面的镜像。 | keeper-web |
keeper-api:2.9 |
包含 Bun API 服务的镜像。 | keeper-api |
keeper-cron:2.9 |
包含 Bun cron 服务的镜像。需要 keeper-worker 进行目标同步。 |
keeper-cron |
keeper-worker:2.9 |
包含处理由 keeper-cron 排队的日历同步作业的 BullMQ (消息队列) worker 的镜像。 |
keeper-worker |
keeper-mcp:2.9 |
包含用于 AI 代理日历访问的 MCP (模型上下文协议) 服务器的镜像。Optional — 仅在需要使用 MCP 客户端时必需。 | keeper-mcp |
[!TIP]
将您的镜像锁定到主版本。次版本标签(例如
2.9),而不是latest。这可以防止在拉取新镜像时自动应用破坏性更改。
前置条件
Docker 与 Docker Compose
为了安装 Docker Compose (编排工具),请参阅 官方 Docker 文档。。
Google OAuth 凭据
[!TIP]
这是可选的,尽管没有这个您将无法设置 Google Calendar 作为目的地。
参考 官方 Google Cloud Platform 文档 生成有效的 Google OAuth (开放授权协议) 凭据。您必须授予同意屏幕 calendar.events、calendar.calendarlist.readonly 和 userinfo.email 权限范围。
一旦配置完成,将客户端 ID 和客户端密钥设置为运行时的 GOOGLE_CLIENT_ID 和 GOOGLE_CLIENT_SECRET 环境变量。
Microsoft Azure 凭据
[!TIP]
同样,这是可选的。如果您不配置此项,将无法配置 Microsoft Outlook 作为目的地。
Microsoft 似乎不太擅长编写文档,我找到的关于配置 OAuth 的非旧版最佳说明是此 社区讨论帖。。所需的权限范围是 Calendars.ReadWrite、User.Read 和 offline_access。Microsoft 的客户端 ID 和密钥分别放入 MICROSOFT_CLIENT_ID 和 MICROSOFT_CLIENT_SECRET 环境变量中。
独立容器
虽然通常您可能希望以细粒度运行容器,但如果您只是想快速启动,我们提供了一个便捷镜像 keeper-standalone:2.9。此容器包含 cron、worker、web、api 服务,以及一个配置的 redis、database 和 caddy 实例,将所有内容置于同一端口之后。虽然这是启动 Keeper 最简单的方法,但它不被视为最佳实践。
生成 keeper-standalone 环境变量
以下内容将生成一个 .env 文件,其中包含用于生成会话的密钥,以及用于加密静态 CalDAV (日历数据访问协议) 凭据的密钥。
[!IMPORTANT]
如果您计划从 http://localhost 以外的 URL 访问 Keeper, 您需要设置
TRUSTED_ORIGINS环境变量。这应该 是您将要使用的协议 - 主机名包含起源的逗号分隔列表。这是一个示例,我们将通过局域网 IP 访问 Keeper,并且我们 将通过托管在 https://keeper.example.com/ 的反向代理路由 Keeper
TRUSTED_ORIGINS=http://10.0.0.2,https://keeper.example.com如果没有这个,您将无法通过
better-auth(认证库) 包的 CSRF (跨站请求伪造) 检查。
cat > .env << EOF
# BETTER_AUTH_SECRET and ENCRYPTION_KEY are required.
TRUSTED_ORIGINS is required if you plan on accessing Keeper from an
origin other than http://localhost/
BETTER_AUTH_SECRET=$(openssl rand -base64 32) ENCRYPTION_KEY=$(openssl rand -base64 32) TRUSTED_ORIGINS= GOOGLE_CLIENT_ID= GOOGLE_CLIENT_SECRET= MICROSOFT_CLIENT_ID= MICROSOFT_CLIENT_SECRET= EOF
### 使用 Docker 运行 `keeper-standalone`
如果您只想使用 Docker CLI(命令行界面)运行,可以使用以下命令。但我建议[使用 compose.yaml(编排文件)](#run-standalone-with-docker-compose)。
```bash
docker run -d \
-p 80:80 \
-v keeper-data:/var/lib/postgresql/data \
--env-file .env \
ghcr.io/ridafkih/keeper-standalone:2.9
使用 Docker Compose 运行 keeper-standalone
如果您更倾向于使用 compose.yaml 文件,以下是示例。记得先填充您的 .env 文件。
services:
keeper:
image: ghcr.io/ridafkih/keeper-standalone:2.9
ports:
- "80:80"
volumes:
- keeper-data:/var/lib/postgresql/data
environment:
BETTER_AUTH_SECRET: ${BETTER_AUTH_SECRET}
ENCRYPTION_KEY: ${ENCRYPTION_KEY}
TRUSTED_ORIGINS: ${TRUSTED_ORIGINS}
GOOGLE_CLIENT_ID: ${GOOGLE_CLIENT_ID:-}
GOOGLE_CLIENT_SECRET: ${GOOGLE_CLIENT_SECRET:-}
MICROSOFT_CLIENT_ID: ${MICROSOFT_CLIENT_ID:-}
MICROSOFT_CLIENT_SECRET: ${MICROSOFT_CLIENT_SECRET:-}
volumes:
keeper-data:
配置完成后,您可以使用以下命令启动 Keeper。
docker compose up -d
一切设置完毕后,您可以在 http://localhost/ 访问 Keeper。您可以使用 Nginx 或 Caddy 等反向代理(reverse-proxy)将 Keeper 部署在您网络中的域名后面。
集成服务镜像
如果您想自带 Redis 和 PostgreSQL,可以使用 keeper-services 镜像。它在一个镜像中包含了 cron、web 和 api 服务。
生成 keeper-services 环境变量
cat > .env << EOF
# DATABASE_URL and REDIS_URL are required.
# *_CLIENT_ID and *_CLIENT_SECRET are optional.
BETTER_AUTH_SECRET=$(openssl rand -base64 32)
ENCRYPTION_KEY=$(openssl rand -base64 32)
DATABASE_URL=postgres://keeper:keeper@postgres:5432/keeper
REDIS_URL=redis://redis:6379
BETTER_AUTH_URL=http://localhost:3000
GOOGLE_CLIENT_ID=
GOOGLE_CLIENT_SECRET=
MICROSOFT_CLIENT_ID=
MICROSOFT_CLIENT_SECRET=
EOF
使用 Docker Compose 运行 keeper-services
填充好环境变量后,您可以选择与 keeper-services 镜像一起运行 redis 和 postgres 以快速启动。
services:
postgres:
image: postgres:17
environment:
POSTGRES_USER: keeper
POSTGRES_PASSWORD: keeper
POSTGRES_DB: keeper
volumes:
- postgres-data:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U keeper -d keeper"]
interval: 5s
timeout: 5s
retries: 5
redis:
image: redis:7-alpine
volumes:
- redis-data:/data
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 5s
timeout: 5s
retries: 5
keeper:
image: ghcr.io/ridafkih/keeper-services:latest
environment:
DATABASE_URL: ${DATABASE_URL}
REDIS_URL: ${REDIS_URL}
BETTER_AUTH_URL: ${BETTER_AUTH_URL}
BETTER_AUTH_SECRET: ${BETTER_AUTH_SECRET}
ENCRYPTION_KEY: ${ENCRYPTION_KEY}
GOOGLE_CLIENT_ID: ${GOOGLE_CLIENT_ID:-}
GOOGLE_CLIENT_SECRET: ${GOOGLE_CLIENT_SECRET:-}
MICROSOFT_CLIENT_ID: ${MICROSOFT_CLIENT_ID:-}
MICROSOFT_CLIENT_SECRET: ${MICROSOFT_CLIENT_SECRET:-}
ports:
- "3000:3000"
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
volumes:
postgres-data:
redis-data:
配置完成后,您可以使用以下命令启动 Keeper。
docker compose up -d
独立服务镜像
虽然单独运行服务被认为是最佳实践(best-practice),但它比较冗长且配置更复杂。每个服务都托管在各自的镜像中。
生成独立服务的环境变量
cat > .env << EOF
# The only optional variables are *_CLIENT_ID, *_CLIENT_SECRET
BETTER_AUTH_SECRET=$(openssl rand -base64 32)
ENCRYPTION_KEY=$(openssl rand -base64 32)
VITE_API_URL=http://api:3001
POSTGRES_USER=keeper
POSTGRES_PASSWORD=keeper
POSTGRES_DB=keeper
REDIS_URL=redis://redis:6379
BETTER_AUTH_URL=http://localhost:3000
GOOGLE_CLIENT_ID=
GOOGLE_CLIENT_SECRET=
MICROSOFT_CLIENT_ID=
MICROSOFT_CLIENT_SECRET=
EOF
配置独立服务的 compose.yaml
services:
postgres:
image: postgres:17
environment:
POSTGRES_USER: ${POSTGRES_USER}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
POSTGRES_DB: ${POSTGRES_DB}
volumes:
- postgres-data:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U keeper -d keeper"]
interval: 5s
timeout: 5s
retries: 5
redis:
image: redis:7-alpine
volumes:
- redis-data:/data
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 5s
timeout: 5s
retries: 5
api:
image: ghcr.io/ridafkih/keeper-api:latest
environment:
API_PORT: 3001
DATABASE_URL: postgres://keeper:keeper@postgres:5432/keeper
REDIS_URL: redis://redis:6379
BETTER_AUTH_URL: ${BETTER_AUTH_URL}
BETTER_AUTH_SECRET: ${BETTER_AUTH_SECRET}
ENCRYPTION_KEY: ${ENCRYPTION_KEY}
GOOGLE_CLIENT_ID: ${GOOGLE_CLIENT_ID:-}
GOOGLE_CLIENT_SECRET: ${GOOGLE_CLIENT_SECRET:-}
MICROSOFT_CLIENT_ID: ${MICROSOFT_CLIENT_ID:-}
MICROSOFT_CLIENT_SECRET: ${MICROSOFT_CLIENT_SECRET:-}
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
cron:
image: ghcr.io/ridafkih/keeper-cron:latest
environment:
DATABASE_URL: postgres://keeper:keeper@postgres:5432/keeper
REDIS_URL: redis://redis:6379
ENCRYPTION_KEY: ${ENCRYPTION_KEY}
GOOGLE_CLIENT_ID: ${GOOGLE_CLIENT_ID:-}
GOOGLE_CLIENT_SECRET: ${GOOGLE_CLIENT_SECRET:-}
MICROSOFT_CLIENT_ID: ${MICROSOFT_CLIENT_ID:-}
MICROSOFT_CLIENT_SECRET: ${MICROSOFT_CLIENT_SECRET:-}
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
web:
image: ghcr.io/ridafkih/keeper-web:latest
environment:
VITE_API_URL: ${VITE_API_URL}
PORT: 3000
ports:
- "3000:3000"
depends_on:
api:
condition: service_started
volumes:
postgres-data:
redis-data:
配置完成后,您可以使用以下命令启动 Keeper。
docker compose up -d
MCP(模型上下文协议)
Keeper 包含一个可选的 MCP(模型上下文协议)服务器,允许 AI 代理(例如 Claude)通过标准化协议访问您的日历数据。该 MCP 服务器通过 Web 应用程序托管的 OAuth 2.1 同意流程进行身份验证。
可用工具
| 工具 | 描述 |
|---|---|
list_calendars |
列出连接到 Keeper 的所有日历,包括提供商名称和账户。 |
get_events |
获取指定日期范围内的日历事件。接受 ISO 8601 日期时间和 IANA 时区标识符。 |
get_event_count |
获取同步到 Keeper 的日历事件总数。 |
连接 MCP 客户端
要连接兼容 MCP 的客户端(例如 Claude Code、Claude Desktop),请将其指向您的 MCP 服务器 URL。客户端将引导您完成 OAuth 同意流程,以授权读取您的日历数据。
示例 Claude Code MCP 配置:
{
"mcpServers": {
"keeper": {
"type": "url",
"url": "https://keeper.example.com/mcp"
}
}
}
自托管 MCP 设置
[!NOTE]
MCP 完全是可选的。所有与 MCP 相关的环境变量在所有服务和镜像中均为可选。如果未设置,Keeper 将正常启动且不包含 MCP 功能。现有的自托管部署不会受到影响。
MCP 服务器通过 Web 服务在 /mcp 路径进行代理,方式与 API 在 /api 路径代理相同。MCP 不包含在 keeper-standalone 或 keeper-services 便捷镜像中 —— 请将 keeper-mcp 镜像作为独立容器与它们一同运行。
要在自托管实例上启用 MCP:
- 使用
MCP_PORT、MCP_PUBLIC_URL、DATABASE_URL、BETTER_AUTH_SECRET和BETTER_AUTH_URL运行keeper-mcp容器。 - 在
api服务上设置MCP_PUBLIC_URL为相同的值(例如https://keeper.example.com/mcp)。 - 在
web服务上设置VITE_MCP_URL为 MCP 容器的内部 URL(例如http://mcp:3002)。
模块
应用程序
- @keeper.sh/api
- @keeper.sh/cron
- @keeper.sh/mcp
- @keeper.sh/web
- @keeper.sh/cli (即将推出)
- @keeper.sh/mobile (即将推出)
- @keeper.sh/ssh (即将推出)
模块
- @keeper.sh/auth
- @keeper.sh/auth-plugin-username-only
- @keeper.sh/broadcast
- @keeper.sh/broadcast-client
- @keeper.sh/calendar
- @keeper.sh/constants
- @keeper.sh/data-schemas
- @keeper.sh/database
- @keeper.sh/date-utils
- @keeper.sh/encryption
- @keeper.sh/env
- @keeper.sh/fixtures
- @keeper.sh/keeper-api
- @keeper.sh/oauth
- @keeper.sh/oauth-google
- @keeper.sh/oauth-microsoft
- @keeper.sh/premium
- @keeper.sh/provider-caldav
- @keeper.sh/provider-core
- @keeper.sh/provider-fastmail
- @keeper.sh/provider-google-calendar
- @keeper.sh/provider-icloud
- @keeper.sh/provider-outlook
- @keeper.sh/provider-registry
- @keeper.sh/pull-calendar
- @keeper.sh/sync-calendar
- @keeper.sh/sync-events
- @keeper.sh/typescript-config
版本历史
v2.9.272026/04/01v2.9.262026/04/01v2.9.252026/04/01v2.9.242026/04/01v2.9.232026/04/01v2.9.222026/04/01v2.9.212026/04/01v2.9.202026/04/01v2.9.182026/03/30v2.9.172026/03/26v2.9.162026/03/26v2.9.152026/03/25v2.9.142026/03/22v2.9.132026/03/22v2.9.122026/03/22v2.9.112026/03/22v2.9.102026/03/21v2.9.92026/03/21v2.9.82026/03/19v2.9.72026/03/18常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。