MovieChat
MovieChat 是一款面向长视频理解的开源 AI 模型,旨在突破传统视频分析技术在处理超长内容时的性能瓶颈。以往的方法往往因显存消耗过大,难以在普通硬件上分析数千帧以上的视频,而 MovieChat 通过创新的“从密集令牌到稀疏记忆”架构,成功实现了在 24GB 显存显卡上流畅处理超过一万帧的视频内容。
这种高效的设计大幅降低了每帧处理的显存开销,使其在 ActivityNet-QA、EgoSchema 等多个权威基准测试中表现卓越。MovieChat 不仅支持视频问答和事件定位,还具备优秀的上下文理解能力。它特别适合计算机视觉领域的研究人员、算法工程师以及希望集成长视频智能分析功能的开发者。借助 MovieChat,团队可以更经济、高效地构建下一代视频理解应用,深入挖掘长视频中的丰富信息。
使用场景
某大型物流园区的安全审计团队需要审查长达 8 小时的仓库监控录像,以精准定位一次货物损坏事故的具体发生过程与责任人。
没有 MovieChat 时
- 传统多模态模型显存消耗过大,处理超过 1 小时的视频序列时常导致计算崩溃。
- 为规避显存限制被迫随机抽帧,导致关键动作片段丢失,无法还原完整事件链条。
- 缺乏长时序记忆能力,难以建立跨时间段的上下文关联,容易对模糊画面产生误判。
- 高昂的云端算力成本使得大规模历史录像审查在经济上几乎不可行。
使用 MovieChat 后
- MovieChat 支持在单张 24GB 显卡上流畅处理超万帧视频,无需分段即可分析全程内容。
- 稀疏记忆机制有效保留关键视觉信息,即使间隔数分钟也能准确关联前后因果逻辑。
- 显存占用仅为其他方法的千分之一,大幅降低硬件门槛,普通工作站即可完成复杂查询。
- 能够精确回答“第几小时几分发生了什么”,直接输出带时间戳的高精度事件描述。
MovieChat 通过稀疏记忆架构,让长视频深度理解变得高效、低成本且精准可靠。
运行环境要求
- 未说明
支持 24GB 显存显卡(可处理>10K frames 视频),具体型号与 CUDA 版本未说明
未说明

快速开始

MovieChat
![]()
![]()
MovieChat:从密集 Token 到稀疏记忆用于长视频理解
Enxin Song*, Wenhao Chai*, Guanhong Wang*, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Xun Guo, Tian Ye, Yan Lu, Jenq-Neng Hwang, Gaoang Wang✉️
CVPR 2024.
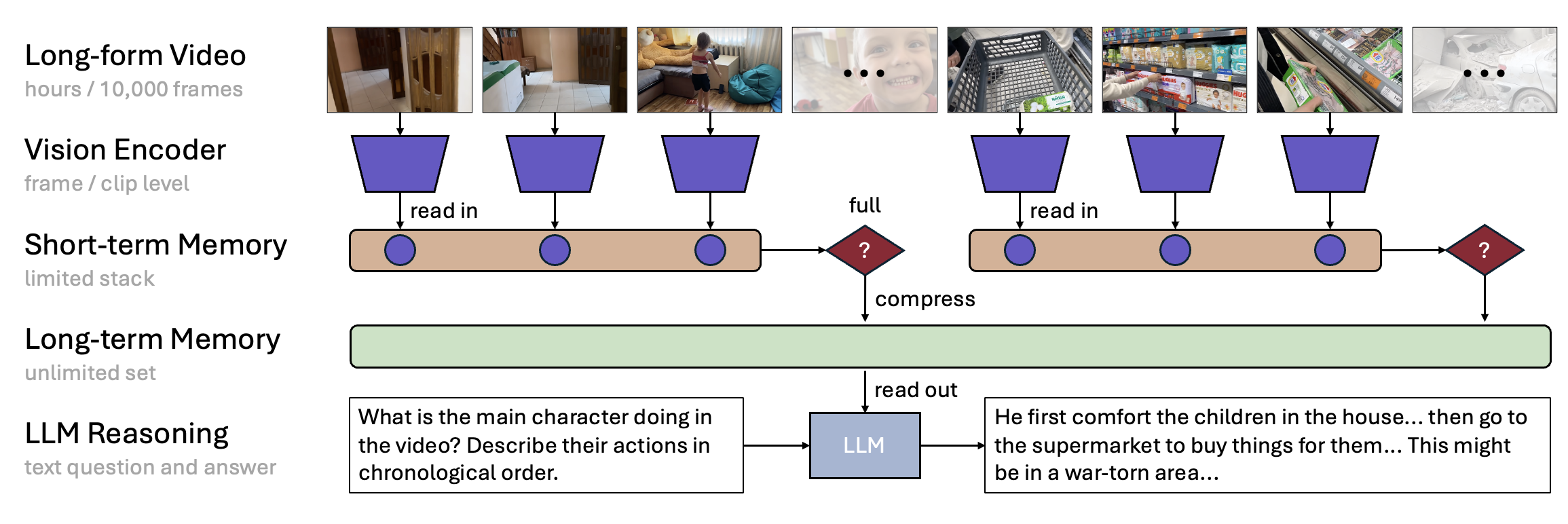
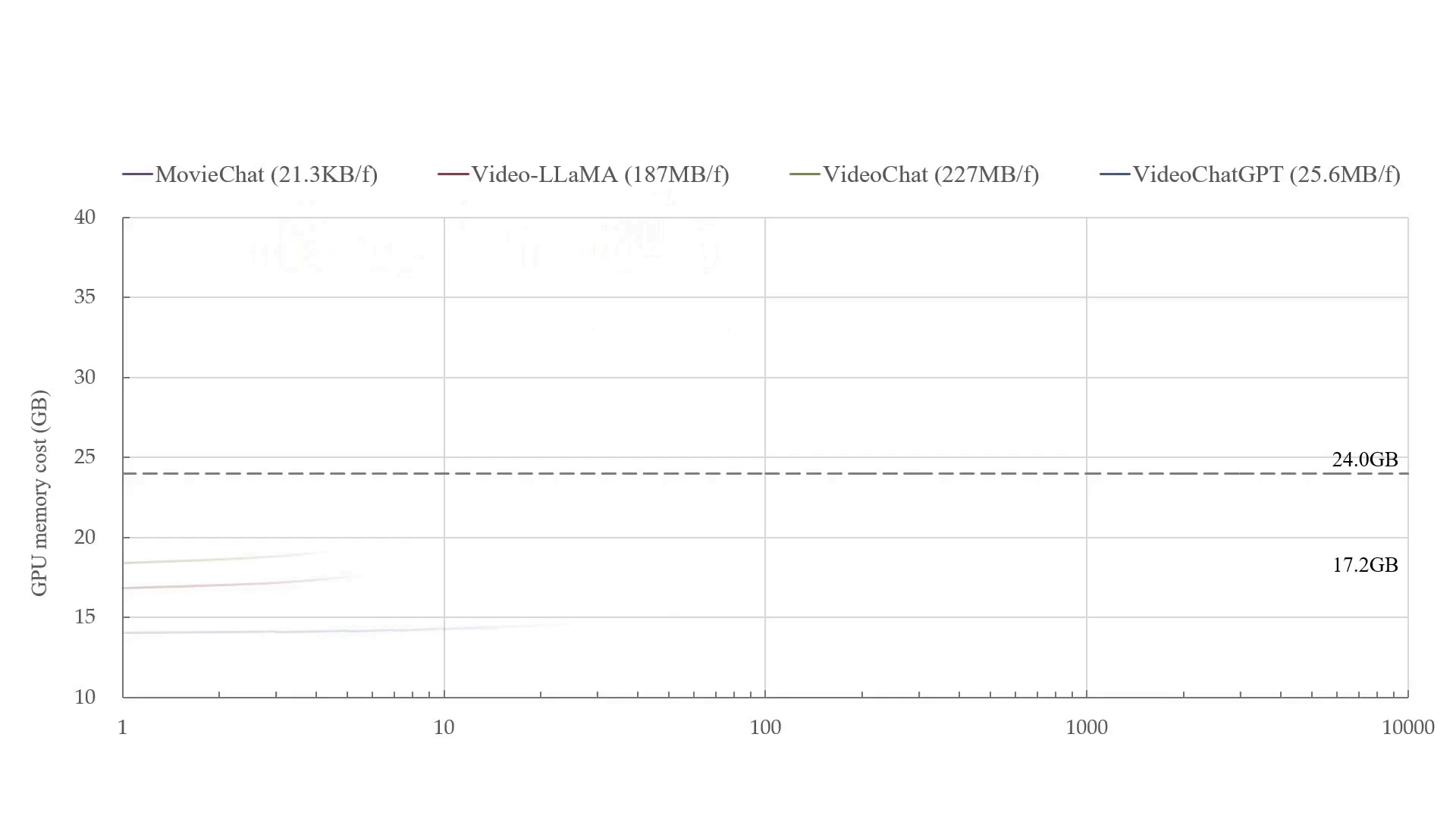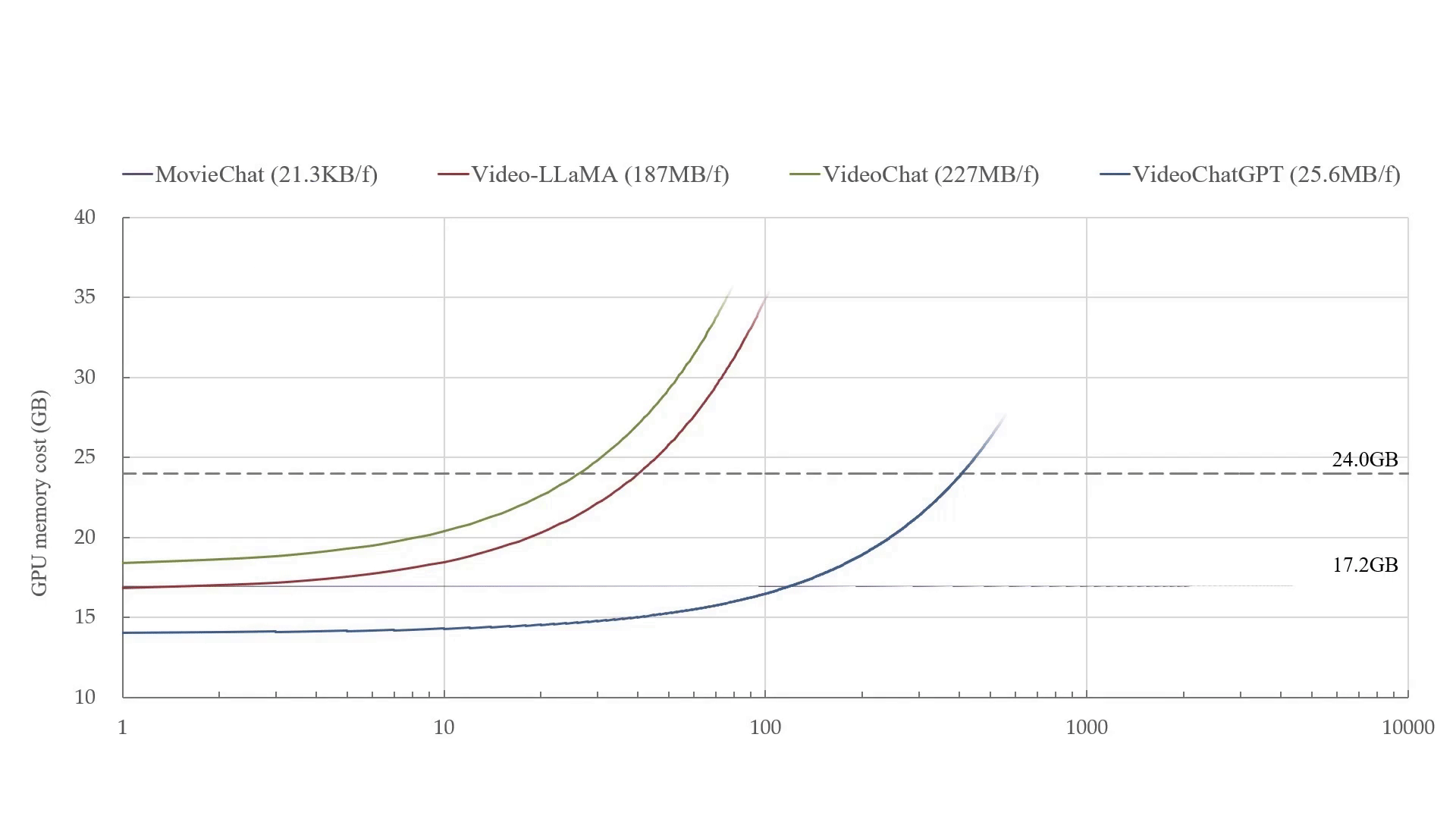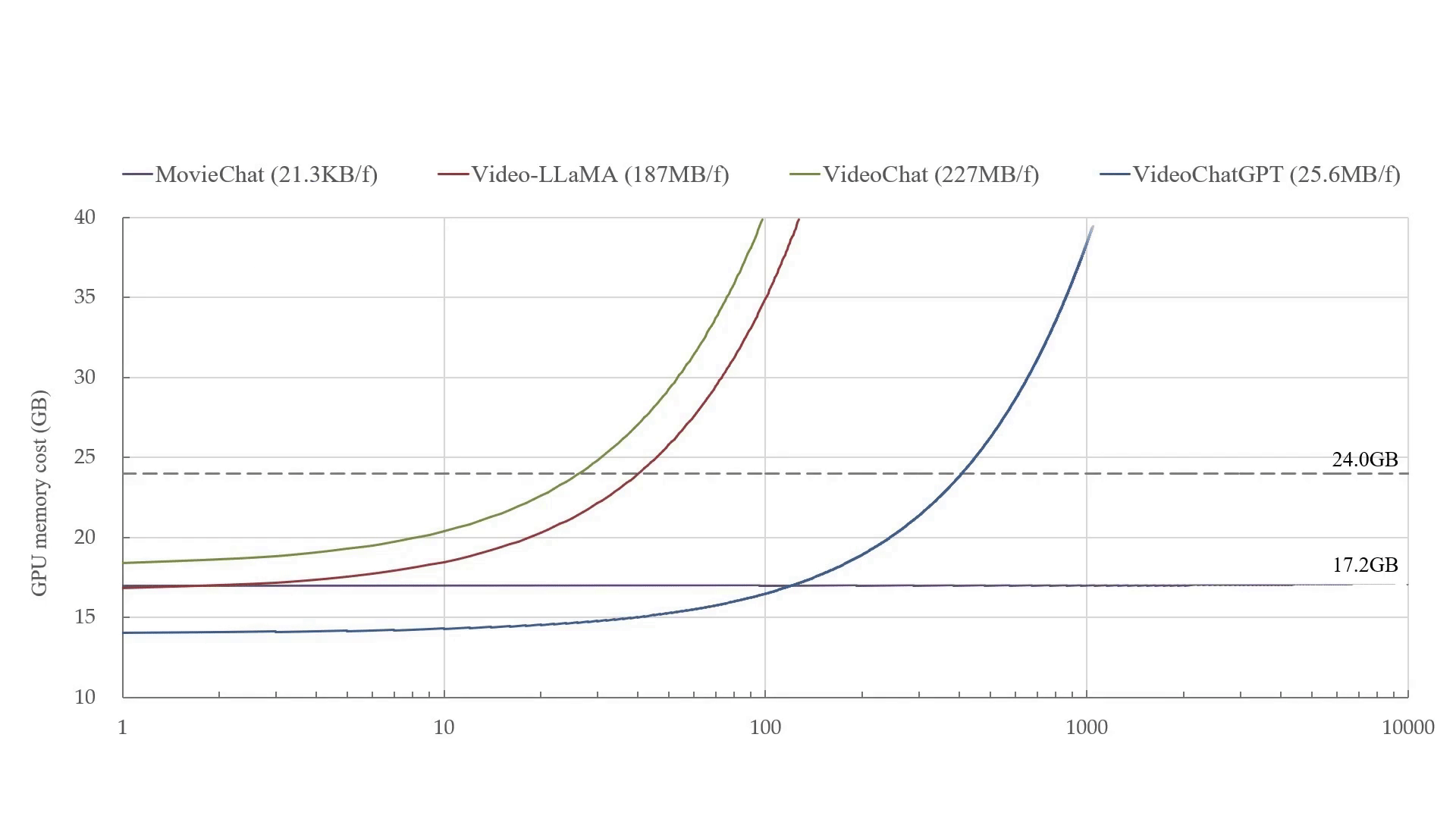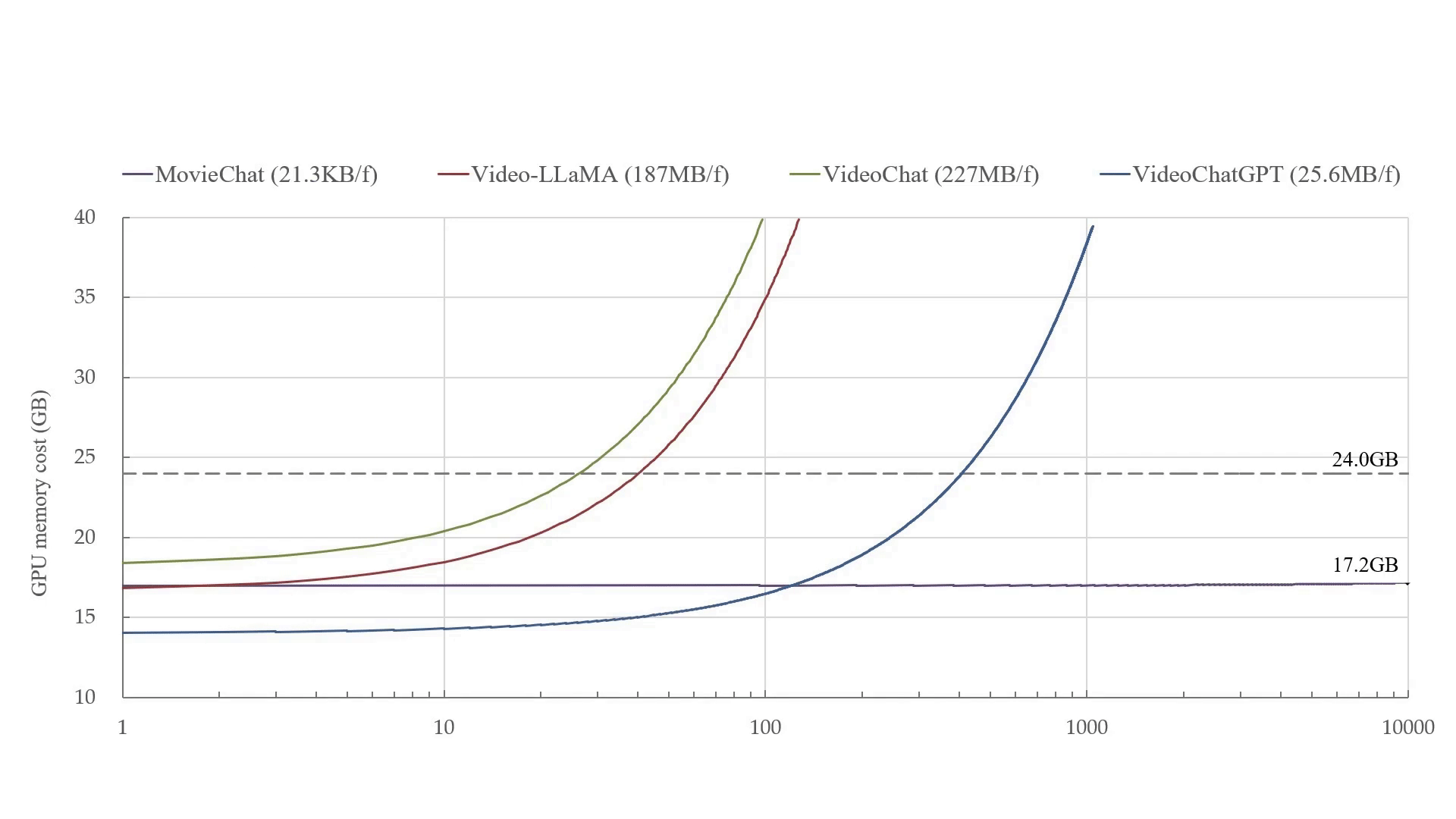
MovieChat 可以在 24GB 显存的显卡上处理超过 10K 帧的视频。在每帧 GPU 显存成本的平均增加方面(从 21.3KB/帧 到 ~200MB/帧),MovieChat 比其他方法具有 10000 倍的优势。
如果您喜欢我们的项目,请在 GitHub 上给我们点个星 ⭐ 以获取最新更新。
🔢 MovieChat-1K 排行榜
欢迎提交您的新结果!
| 模型与链接 | 备注 | 断点准确率 | 全局准确率 |
|---|---|---|---|
| Video-LLaMA | 端到端 | 39.1 | 51.7 |
| VideoChat | 端到端 | 46.1 | 57.8 |
| TimeChat | 思维链 (CoT), 上下文学习 (ICL), 在 MovieChat 上训练 | 46.1 | 73.8 |
| VideoChatGPT | 端到端 | 48.0 | 47.6 |
| MovieChat (baseline) | 端到端 | 48.3 | 62.3 |
| MovieChat+ (baseline) | 端到端 | 49.6 | 71.2 |
| Long-LLaVA | 端到端 | 54.0 | 69.6 |
| Long-LLaVA + Video-RAG | 端到端 | 54.5 | 72.9 |
| Streaming Long Video | 在 MovieChat 上训练 | 54.9 | 90.4 |
| DrVideo | 检索增强生成 (RAG) | 56.7 | 93.1 |
| ReWind | 端到端 | 57.2 | 87.6 |
| HERMES | 在 MovieChat 上训练 | 57.3 | 78.6 |
| Flash-VStream | 在 MovieChat 上训练 | 59.6 | 96.0 |
| MM-Screenplayer | 检索增强生成 (RAG) | 68.8 | 87.5 |
| VILA1.5-8B | 端到端 | - | 40.0 |
| FocusChat | 端到端 | - | 60.0 |
| llavaonevision-MovieChat | 端到端 | - | 79.0 |
| Sullam Jeoung, et al | 智能体 (Agent) | - | 84.8 |
| SEAL | 在 MovieChat 上训练 | - | 86.8 |
| HEM-LLM | 未知训练数据集 | - | 90.6 |
🔢 MovieChat 在现有基准测试上的评估
按字母顺序排列。
| 基准测试 | 结果 |
|---|---|
| ActivityNet-QA | 准确率 / 评分:45.7 / 3.4 |
| Charades-STA | R@1(IOU =0.3): 8.8 • R@1(IOU =0.5): 2.9 • R@1(IOU =0.7): 1.3 |
| CineClipQA | 总体:20.86/2.11 • 描述:23.67/2.41 • 意图:30.19/2.41 • 感知:21.80/1.97 • 时间性:16.32/1.97 • 空间性:16.40/1.98 |
| CVRR-ES | 平均:16.41 |
| EgoSchema | Top 1 准确率:53.5 |
| EventBench | 准确率:20.33 |
| InfiniBench | 全局外观:6.59 • 场景转换:6.41 • 角色动作:4.51 • 时间顺序:36.99 • 局部视觉:17.76 • 摘要:0.14 • 深层上下文:0.55 • 剧透问题:0.34 • 多个事件:0.85 • 平均:14.45/0.47 |
| InfiniBench-Vision | 准确率:14.2 • 评分:1.2 |
| LvBench | ER: 21.3 • EU: 23.1 • KIR: 25.9 • TG: 22.3 • Rea: 24.0 • Sum: 17.2 • 总体:22.5 |
| LvM-QA | 准确率 / 评分:48.3 / 2.57 |
| MLVU | 整体 TR: 29.5 • AR: 25.0 • VS: 2.33 • 单细节 NQA: 24.2 • ER: 24.7 • PQA: 25.8 • SSC: 3.23 • 多细节 AO: 28.6 • AC: 22.8 • M-Avg: 25.8 • G-Avg: 2.78 |
| MovieChat-1K | 全局准确率 / 评分:62.3 / 3.23 • 全局准确率 / 评分:48.3 / 2.57 |
| MovieCORE | 准确率:20.33 • 比较:2.90 • 深度:2.29 • 证据:2.14 • 连贯性:2.30 • 平均:2.23 |
| MSVD-QA | 准确率 / 评分:75.2 / 3.8 |
| MSRVTT-QA | 准确率 / 评分:52.7 / 2.6 |
| NExT-QA | 准确率 / 评分:49.9 / 2.7 |
| QVHighlight | mAP: 11.7 • HIT @1: 16.1 |
| RVS-Ego | 准确率 / 评分:50.7 / 3.4 |
| RVS-Movie | 准确率 / 评分:36.0 / 2.3 |
| Seed-Bench | 流程理解:29.82 • 动作识别:40.11 |
| SFD | 多项选择 V: 8.4 • L: 16.4 • VL: 8.0 • 开放式 V: 14.0 • L: 15.7 • VL: 11.8 |
| SVBench | 对话 SA: 20.46 • 对话 CC: 20.05 • 对话 LC: 27.76 • 对话 TU: 21.81 • 对话 IC: 22.21 • 对话 OS: 21.89 • 流式 SA: 17.99 • 流式 CC: 16.42 • 流式 LC: 20.37 • 流式 TU: 15.77 • 流式 IC: 19.08 • 流式 OS: 17.43 |
| TV-Caption | BertScore: 38.11 • CIDER: 8.43 • ROUGE-L: 12.09 • SPICE: 9.21 |
| VCG Bench | CI: 2.76 • DO: 2.93 • CU: 3.01 • TU: 2.24 • CO: 2.42 • 平均:2.67 |
| VDC | 相机:37.25/1.98 • 短:32.55/1.59 • 背景:28.99/1.54 • 主体:31.97/1.64 • 物体:28.82/1.46 • 平均:31.92/1.64 |
| VideoMME | 无字幕:38.2 • 无字幕 (长视频): 33.4 |
| Video-ChatGPT | 平均:2.67 • CI: 2.76 • DO: 2.93 • CU: 3.01 • TU: 2.24 • CO: 2.42 |
| VS-Ego | 准确率 / 评分:52.2 / 3.4 |
| VS-Movie | 准确率 / 评分:39.1 / 2.3 |
| YouCook2 | C: 38.5 • M: 18.8 |
:fire: 最新动态
- [2024.10.26] :keyboard: 我们将 MovieChat, MovieChat_OneVision, MovieChat-1K 上传至 lmms-eval。
- [2024.10.26] :keyboard: 我们发布了 MovieChat 的新版本,该版本使用 LLaVA-OneVision 作为基础模型,替代了原有的 VideoLLaMA。新版本可在 MovieChat_Onevision 获取。
- [2024.6.13] :film_projector: 我们在 Hugging Face 上发布了 MovieChat 测试集的真实标签 (ground truth)。
- [2024.5.10] :film_projector: 我们在 Hugging Face 上发布了 MovieChat 训练集的原始视频。
- [2024.4.29] :page_with_curl: 我们更新了 MovieChat+ 论文,包含实现细节、技术评估和数据集信息。
- [2024.4.25] :keyboard: 我们更新了 MovieChat+ 的新版本。我们发布了 MovieChat+ 代码 和相应的 评估代码。我们的论文即将发布!
- [2024.4.19] :keyboard: 我们将 MovieChat 的最新源代码更新至 PyPI (Python 包索引)。现在您可以直接使用
pip install Moviechat安装并使用 MovieChat! - [2024.3.25] :bar_chart: 我们在 CVPR 2024 会议上主办了 第四届长视频理解国际研讨会:迈向多模态 AI 助手和副驾驶 (Copilot) 的挑战赛道 1。您可以参与挑战并通过 Codalab 提交您的结果。我们将在 排行榜 上展示结果。对于每位参与者,我们希望您能以 JSON 格式提交结果,并报告平均运行时间和显存 (VRAM) 使用情况。我们将使用这些指标来筛选最高效的方法。关于挑战的详细信息,请参阅此 链接。
- [2024.3.11] :film_projector: 我们在 Hugging Face 上发布了 MovieChat-1K 的测试集。每个视频包含 3 个全局问题和 10 个断点问题。
- [2024.2.27] :tada: 我们的论文被 CVPR 2024 接收!
- [2024.2.14] :film_projector: 我们在 Hugging Face 上发布了 MovieChat-1K 的训练集。由于版权限制,我们分享由 eva_vit_g 提取的片段特征,每个视频包含 8192 帧。
- [2023.11.27] :page_with_curl: 我们更新了 论文,包含实现细节、技术评估和数据集信息。
- [2023.11.23] :keyboard: 我们更新了 MovieChat 的最新源代码。
- [2023.8.1] :page_with_curl: 我们发布了 论文。
- [2023.7.31] :keyboard: 我们发布了用于 MSVD-QA, MSRVTT-QA 和 ActivityNet-QA 短视频问答 (QA) 的评估 代码和说明。
- [2023.7.29] :joystick: 我们发布了 MovieChat 的 Gradio 演示。
- [2023.7.22] :keyboard: 我们发布了 MovieChat 的源代码。
![]()
![]()
![]()
![]()
![]()
📊MovieChat-1K 上的性能对比
| 方法 | 文本解码器 | # 帧数 | 全局模式准确率 | 全局模式得分 |
|---|---|---|---|---|
| GIT | 基于非大语言模型 (LLM) | 6 | 28.8 | 1.83 |
| mPLUG-2 | 基于非大语言模型 (LLM) | 8 | 31.7 | 2.13 |
| Video Chat | 基于大语言模型 (LLM) | 32 | 57.8 | 3.00 |
| Video LLaMA | 基于大语言模型 (LLM) | 32 | 51.7 | 2.67 |
| Video-ChatGPT | 基于大语言模型 (LLM) | 100 | 47.6 | 2.55 |
| MovieChat | 基于大语言模型 (LLM) | 2048 | 62.3 | 3.23 |
| MovieChat+ | 基于大语言模型 (LLM) | 2048 | 71.2 | 3.51 |
| MovieChat-Onevision | 基于大语言模型 (LLM) | 2048 | 79.0 | 4.20 |
✨如何快速运行 MovieChat?
我们将 MovieChat 打包并上传到了 PyPI。要快速运行 MovieChat,您需要先安装它。
pip install MovieChat
我们建议您目前安装版本 0.6.3。由于 MovieChat 会自动从 Huggingface 下载检查点(checkpoints),如果您的服务不支持从 git clone,我们建议您将检查点下载到您的服务中,并更改包中的相应路径,包括 q_former_model、ckpt_path,以及 llama_model。
在您运行以下推理代码之前,希望您能通过 ffprobe -version 验证 ffprobe 的安装情况。如果正确安装,该命令应返回 ffprobe 的版本。否则,您应该通过 sudo apt-get install ffmpeg (Ubuntu) 进行安装。
from PIL import Image
import cv2
from MovieChat.processors.video_processor import AlproVideoEvalProcessor
from MovieChat.models.chat_model import Chat
from MovieChat.models.moviechat import MovieChat
device = 'cuda:0'
print('Initializing Chat')
moviechat_model = MovieChat.from_config(device=device).to(device)
vis_processor_cfg = {'name': 'alpro_video_eval', 'n_frms': 8, 'image_size': 224}
frame_processor = AlproVideoEvalProcessor.from_config(vis_processor_cfg)
chat = Chat(moviechat_model, frame_processor, device=device)
print('Initialization Finished')
video_path = "Your video path, end with mp4"
fragment_video_path = "The path to store tmp video clips"
middle_video = False # True->Breakpoint mode, False->Global mode
question = "Your Question"
cur_min = 0 # Change it when Breakpoint mode
cur_sec = 0 # Change it when Breakpoint mode
cap = cv2.VideoCapture(video_path)
cur_fps = cap.get(cv2.CAP_PROP_FPS)
cap.set(cv2.CAP_PROP_POS_FRAMES, cur_fps)
ret, frame = cap.read()
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
pil_image = Image.fromarray(rgb_frame)
image = chat.image_vis_processor(pil_image).unsqueeze(0).unsqueeze(2).half().to(device)
cur_image = chat.model.encode_image(image)
img_list = []
msg = chat.upload_video_without_audio(
video_path=video_path,
fragment_video_path=fragment_video_path,
cur_min=cur_min,
cur_sec=cur_sec,
cur_image=cur_image,
img_list=img_list,
middle_video=middle_video,
question=question
)
answer = chat.answer(
img_list=img_list,
input_text=question,
msg = msg,
num_beams=1,
temperature=1.0,
max_new_tokens=300,
max_length=2000)[0]
print(answer)
注意,如果您收到类似 "Error reading <filename.mp4>" 的 RuntimeError,一种解决方案是使用任何其他视频文件初始化 <filename.mp4>。
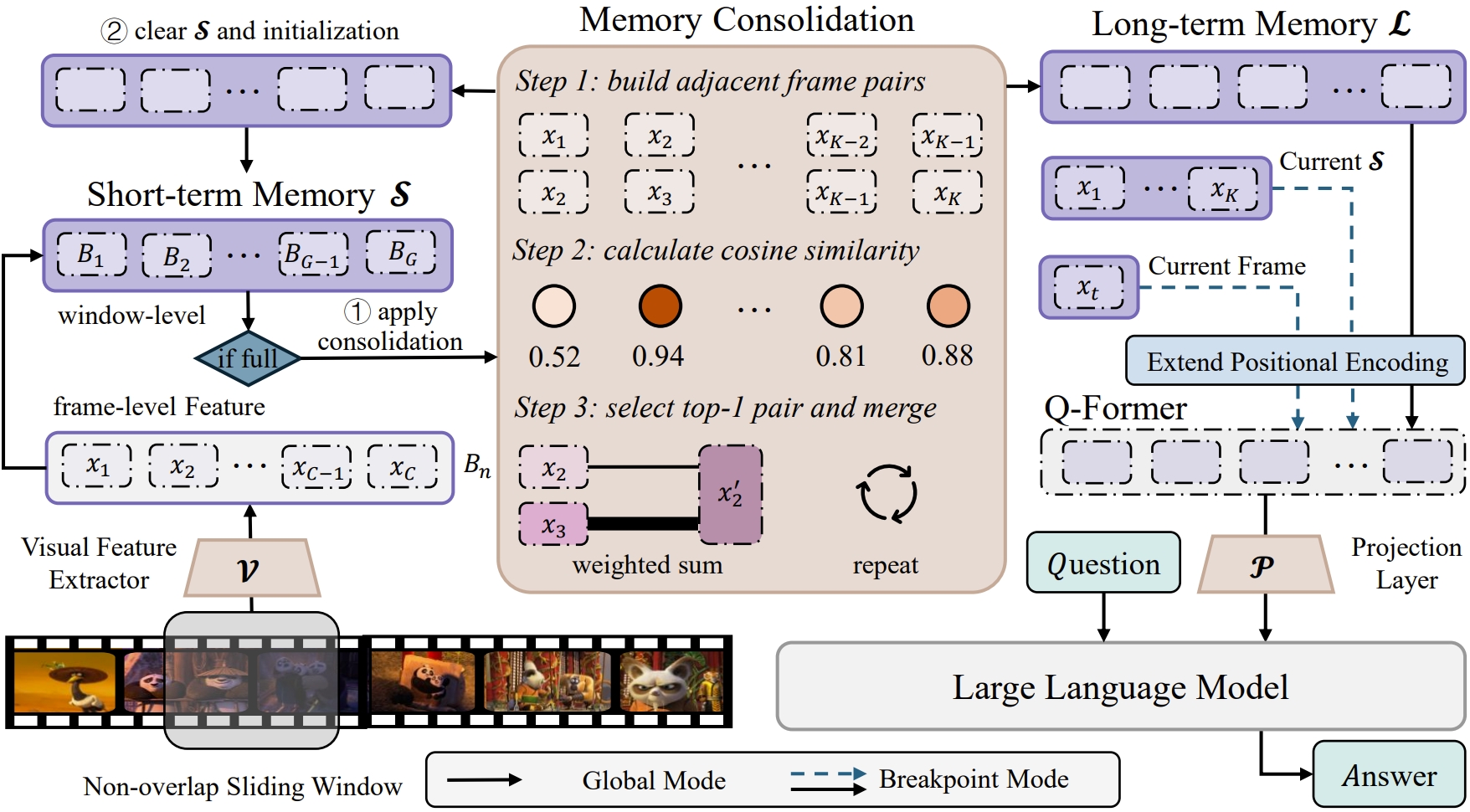
💡 概述
📣 演示视频

⚡ 对比案例

😍 示例


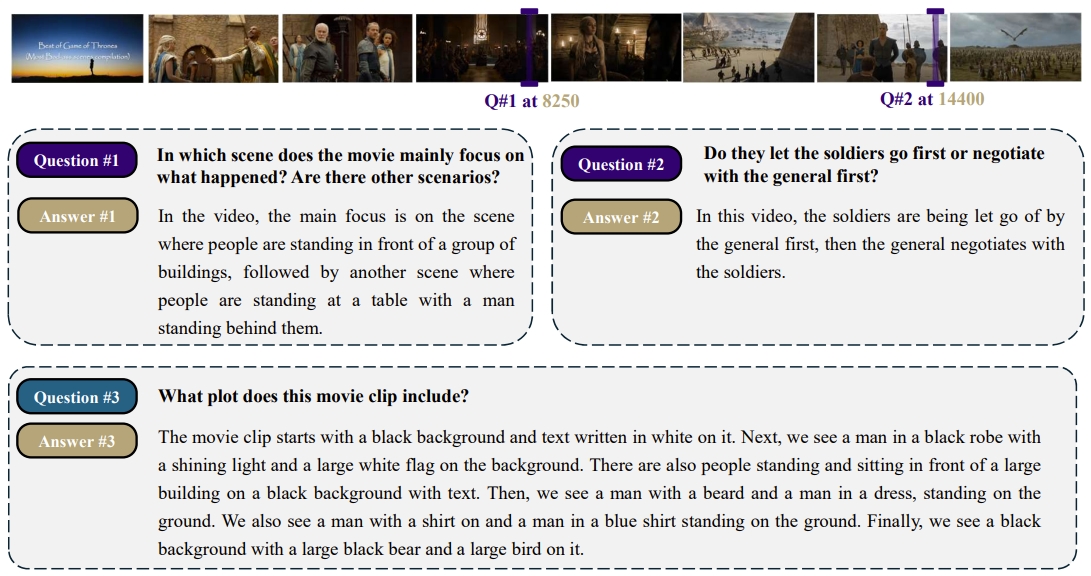

🚀 基准测试:MovieChat-1K
为了更好地评估 MovieChat 的性能,我们收集了一个用于长视频理解任务的新基准 MovieChat-1K,该基准包含来自各种电影和电视剧的 1K 个高质量视频片段,并附有 14K 条人工标注。
据我们所知,目前尚未建立长视频理解数据集。我们的工作代表了创建并公开此类数据集的第一步。我们创建了 MovieChat-1K,包含 1K 个长视频及对应的 1K 个密集描述(dense captions),以及 13K 个视觉问答对(visual question-answer pairs)。对于每个视频,我们手动设置并提供 1 个覆盖整个视频的密集描述,3 个全局模式(global mode)的问答对,以及 10 个带时间戳的断点模式(breakpoint mode)的问答对。
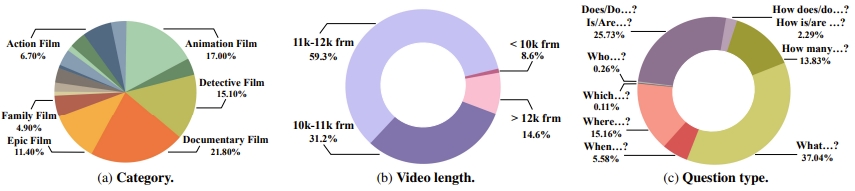
我们从 15 个流行类别中收集了视频,分布各不相同,包括纪录片、侦探片、动画片等。其中,每个视频由多个交替的场景组成,在集合背景下贡献了多样且动态的视觉叙事。超过 90% 的视频时长范围为 10K 到 12K 帧,而 14.6% 的视频时长超过 12K 帧。只有 8.6% 的视频时长少于 10K 帧。
问答对
词分布
请注意,MovieChat-1K 是专门为长视频理解任务设计的,大多数问题是开放式的,只有四分之一被归类为选择题,以"Do," "Does," "Is,"或"Are"等引导词标记。我们还计算了所提供问答对的词分布,其中包括常见物体(人、衣服等)、时间(白天、夜晚等)、场景(室内、室外等)等。
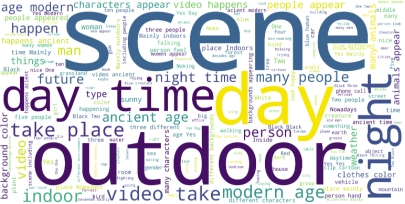
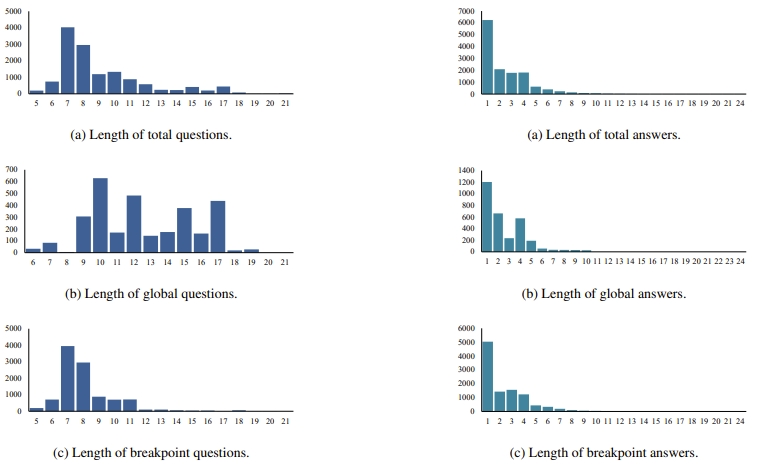
句子长度分布
MovieChat-1K 在分段片段级别上展示了多样化的问答对长度。尽管全局模式和断点模式之间的问答对分布有所不同,但大多数问题的长度倾向于集中在 5-15 个单词之间,而答案的长度通常少于 10 个单词。
密集描述
为了促进对长视频的更详细理解,我们为每个视频提供了一个密集描述。MovieChat-1K 在分段片段级别上展示了多样化的描述长度。大约三分之二的片段拥有 100-149 个单词的描述,而五分之一的片段描述少于 100 个单词。约 11% 的片段拥有超过 150 个单词的长描述。
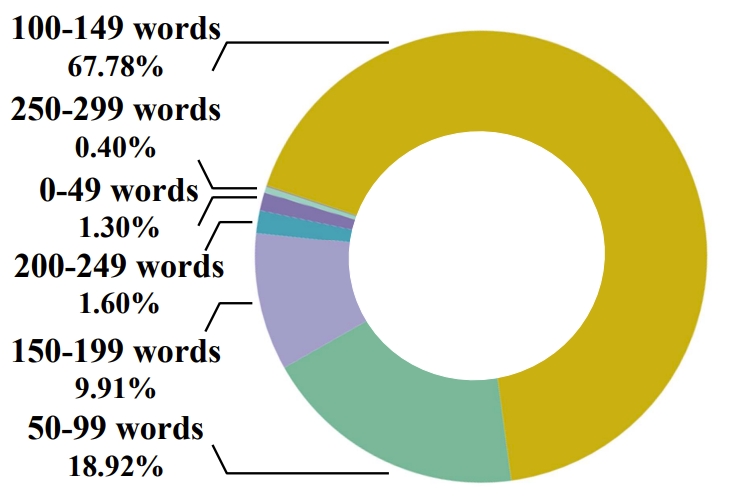
为了分析生成描述的词分布,我们计算了它们的分布。生成的描述词分布如图 B6 所示,其中包括常见物体(男人、女人、人、女孩等)、属性(侦探、各种、小、白色等)、位置(内部、后面、南边、旁边等)、场景(房间、房子、建筑、办公室等)、动作/事件(交谈、进入、离开、拿取等)等。

就动作性而言,MovieChat-1K 描述中的动词数量与 WebVid10M 数据集几乎相同。为了评估这一点,我们使用 NLTK 工具包来分析描述中的动词数量,专注于提取和标记所有唯一的动词。我们发现 WebVid10M 描述数据集中总共有 109,485 个动词,而 MovieChat-1K 描述中包含 102,988 个动词的唯一实例。虽然由于我们简单的计数方法,这些计数可能不完全准确,但我们认为它们提供了两个数据集动作性的粗略指示。
🔐 © 由于版权顾虑和电影大小限制,我们计划发布数据集的特征。请等待几周。
🛠️ 安装
环境准备
首先,创建一个 conda 环境:
conda env create -f environment.yml
conda activate moviechat
前置条件
在使用此仓库之前,请确保您已获得以下前提条件:
预训练语言解码器
- 按照 此处 的说明获取 Hugging Face 格式的原始 LLaMA 权重。
- 下载 Vicuna delta 权重 :point_right: [7B](注意:我们使用 v0 权重 而不是 v1.1 权重)。
- 使用以下命令将 delta 权重添加到原始 LLaMA 权重中,以获得 Vicuna 权重:
python apply_delta.py \
--base ckpt/LLaMA/7B_hf \
--target ckpt/Vicuna/7B \
--delta ckpt/Vicuna/vicuna-7b-delta-v0 \
MovieChat 的预训练视觉编码器
- 从 此链接 下载 MiniGPT-4 模型(训练好的线性层)。
下载预训练权重
- 从 此链接 下载预训练权重,以便在本地使用 Vicuna-7B 作为语言解码器运行 MovieChat。
🤖 如何在本地运行演示
首先,在 eval_configs/MovieChat.yaml 中设置 llama_model、llama_proj_model 和 ckpt。
然后运行脚本:
python inference.py \
--cfg-path eval_configs/MovieChat.yaml \
--gpu-id 0 \
--num-beams 1 \
--temperature 1.0 \
--text-query "What is he doing?" \
--video-path src/examples/Cooking_cake.mp4 \
--fragment-video-path src/video_fragment/output.mp4 \
--cur-min 1 \
--cur-sec 1 \
--middle-video 1 \
注意,如果您想使用全局模式(理解并回答整个视频的问题),请记住将 middle-video 改为 0。
🤝 致谢
我们要感谢以下对我们 MovieChat 项目有启发的优秀项目:
- Video-LLaMA: 面向视频理解的指令微调视听语言模型
- Token Merging: 更快的 ViT(视觉 Transformer)
- XMem: 基于 Atkinson-Shiffrin 记忆模型的长时视频目标分割
- MiniGPT-4: 利用先进的大语言模型增强视觉 - 语言理解
- FastChat: 用于训练、部署和评估基于大语言模型的聊天机器人的开放平台
- BLIP-2: 使用冻结图像编码器和大型语言模型引导语言 - 图像预训练
- EVA-CLIP: 大规模 CLIP 的训练技术改进
- LLaMA: 开源且高效的基础语言模型
- VideoChat: 以聊天为中心的视频理解
- LLaVA: 大型语言与视觉助手
🔒 使用条款
我们的 MovieChat 仅是一个研究预览版,仅供非商业用途。您严禁将我们的 MovieChat 用于任何非法、有害、暴力、种族主义或色情目的。严格禁止从事任何可能违反这些指南的活动。
✏️ 引用
如果您发现 MovieChat 对您的研究和应用有用,请使用以下 BibTeX 进行引用:
@article{song2023moviechat,
title={MovieChat: From Dense Token to Sparse Memory for Long Video Understanding},
author={Song, Enxin and Chai, Wenhao and Wang, Guanhong and Zhang, Yucheng and Zhou, Haoyang and Wu, Feiyang and Guo, Xun and Ye, Tian and Lu, Yan and Hwang, Jenq-Neng and others},
journal={arXiv preprint arXiv:2307.16449},
year={2023}
}
@article{song2024moviechat+,
title={MovieChat+: Question-aware Sparse Memory for Long Video Question Answering},
author={Song, Enxin and Chai, Wenhao and Ye, Tian and Hwang, Jenq-Neng and Li, Xi and Wang, Gaoang},
journal={arXiv preprint arXiv:2404.17176},
year={2024}
}
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。