Object-Detection-Metrics
Object-Detection-Metrics 是一个专为评估目标检测算法性能而设计的开源工具包,集成了学术界和各类竞赛中最主流的评价指标。在目标检测领域,不同研究和比赛往往采用各异的评估标准,且官方参考代码稀缺,导致研究人员在复现或对比模型时,常因自行实现指标的差异而产生偏差结果。Object-Detection-Metrics 正是为了解决这一痛点而生,它提供了一套灵活、统一且经过严格验证的计算函数,确保评估结果与官方实现完全一致,从而让不同数据集上的模型对比更加公平可信。
该工具特别适合人工智能研究人员、算法工程师以及需要严谨评估模型表现的开发团队使用。其核心亮点在于极高的易用性与兼容性:用户无需将数据转换为复杂的 XML 或 JSON 格式,直接输入真实的边界框和检测到的边界框即可快速计算精度。此外,项目不仅涵盖了经典的精确率 - 召回率曲线等指标,还推出了支持 COCO 全套指标、具备图形化界面(UI)并能评估视频检测效果的全新版本,大大降低了技术门槛,帮助用户高效完成从实验验证到论文发表的全过程。
使用场景
某自动驾驶初创团队的算法工程师正在迭代其车辆检测模型,急需在不同数据集上公平对比新旧版本的性能差异。
没有 Object-Detection-Metrics 时
- 标准混乱导致结果不可比:团队参考不同论文实现了多种指标(如 VOC mAP 与 COCO AP),因计算逻辑细微差别,导致同一模型在不同脚本下得分不一,无法判断优化是否有效。
- 数据格式转换耗时费力:官方评估代码通常强制要求将标注文件转换为特定的 XML 或复杂 JSON 格式,工程师需编写大量胶水代码进行预处理,极易引入人为错误。
- 复现权威基准困难:缺乏经过验证的参考实现,自行编写的评估逻辑难以确保与顶级竞赛(如 COCO Challenge)的官方结果完全一致,削弱了技术报告的可信度。
- 调试与可视化缺失:手动计算指标时难以直观生成精度 - 召回率曲线(Precision-Recall Curve),定位模型在特定置信度阈值下的失效原因变得如同“盲人摸象”。
使用 Object-Detection-Metrics 后
- 统一度量衡确保公平性:直接调用封装好的函数即可计算主流竞赛指标,消除了实现歧义,确保新旧模型在同一把“尺子”下进行精准对比。
- 输入灵活零负担:支持直接传入简单的边界框坐标列表,无需修改现有数据管道去适配复杂的文件格式,大幅缩短了从训练到评估的周期。
- 结果权威可信赖:该工具的核心算法已与官方实现严格对齐并经过学术验证,输出的每一项数据都能经得起同行评审和业界基准的检验。
- 分析洞察一目了然:一键生成标准的精度 - 召回率曲线及详细统计报表,帮助工程师快速定位模型在漏检或误报上的具体短板,指导针对性调优。
Object-Detection-Metrics 通过提供标准化、免配置且经学术验证的评估方案,让研发团队从繁琐的指标实现中解脱,专注于核心算法的真正突破。
运行环境要求
- 未说明 (跨平台,依赖 Python 环境)
未说明 (该工具主要用于计算评估指标,通常仅需 CPU 即可运行)
未说明
快速开始
![]()
![]()
引用
如果您在研究中使用此代码,请考虑引用以下内容:
@Article{electronics10030279,
AUTHOR = {Padilla, Rafael and Passos, Wesley L. and Dias, Thadeu L. B. and Netto, Sergio L. and da Silva, Eduardo A. B.},
TITLE = {一种基于开源工具包的对象检测指标比较分析},
JOURNAL = {Electronics},
VOLUME = {10},
YEAR = {2021},
NUMBER = {3},
ARTICLE-NUMBER = {279},
URL = {https://www.mdpi.com/2079-9292/10/3/279},
ISSN = {2079-9292},
DOI = {10.3390/electronics10030279}
}
@INPROCEEDINGS {padillaCITE2020,
author = {R. {Padilla} and S. L. {Netto} and E. A. B. {da Silva}},
title = {目标检测算法性能指标综述},
booktitle = {2020年国际系统、信号与图像处理会议(IWSSIP)},
year = {2020},
pages = {237-242},}
您可以通过此处下载该论文。
注意!本工具的新版本已在这里发布。
新版本包含所有COCO指标,支持其他文件格式,提供一个用户界面(UI)来指导评估过程,并引入了用于评估视频中目标检测的STT-AP指标。
目标检测指标
本项目的出发点在于,不同研究和实现之间对于目标检测问题的评价指标缺乏共识。尽管在线竞赛会采用各自的指标来评估目标检测任务,但只有少数竞赛提供了用于计算检测精度的参考代码片段。
希望使用不同于竞赛所提供数据集的研究人员,往往需要自行实现相应的指标计算方法。然而,错误或不一致的实现方式可能会导致结果偏差。理想情况下,为了确保不同方法之间的可比性,有必要开发一种灵活且通用的实现方案,以便无论使用何种数据集都能进行准确的基准测试。
本项目提供易于使用的函数,实现了当前最流行的目标检测竞赛所采用的相同指标。我们的实现无需对您的检测模型进行复杂输入格式的修改,也避免了将数据转换为XML或JSON文件的麻烦。我们简化了输入数据(真实框和预测框),并将学术界及各类挑战赛中常用的主流指标整合到一个统一的项目中。经过与官方实现的仔细对比,我们的结果完全一致。
在下文中,您将找到关于不同竞赛和研究中常用指标的概述,以及如何使用我们代码的示例。
目录
不同竞赛,不同指标
PASCAL VOC挑战赛 提供了一个Matlab脚本,用于评估检测结果的质量。参赛者可以在提交结果之前,利用该脚本测量其检测精度。有关其目标检测指标标准的官方文档可在此处查阅。目前PASCAL VOC目标检测挑战赛所采用的指标包括精确率-召回率曲线和平均精度。
PASCAL VOC的Matlab评估代码从XML文件中读取真实框,若要将其应用于其他数据集或特定场景,则需对代码进行相应修改。尽管像Faster-RCNN这样的项目已经实现了PASCAL VOC的评估指标,但仍需将检测到的边界框转换为特定格式。TensorFlow框架也提供了PASCAL VOC指标的实现。COCO目标检测挑战赛 使用不同的指标来评估各种算法的目标检测精度。在这里可以找到一份文档,详细介绍了用于表征COCO数据集上目标检测器性能的12种指标。该竞赛提供了Python和Matlab代码,方便用户在提交结果前验证自己的分数。不过,仍需将结果转换为竞赛要求的特定格式。
Google Open Images Dataset V4竞赛 同样使用500个类别的平均精度(mAP)来评估目标检测任务。
ImageNet物体定位挑战赛 根据每个图像的真实框与预测框之间的类别匹配情况及重叠区域大小来计算误差。最终的总误差是所有测试图像中最小误差的平均值。此处提供了更多关于其评估方法的详细信息。
重要定义
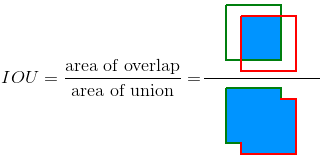
交并比(IOU)
交并比(IOU)是一种基于Jaccard指数的度量方法,用于评估两个边界框之间的重叠程度。它需要一个真实边界框 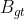 和一个预测边界框
和一个预测边界框 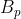 。通过计算IOU,我们可以判断检测结果是否有效(真正例)或无效(假正例)。
。通过计算IOU,我们可以判断检测结果是否有效(真正例)或无效(假正例)。
IOU的计算公式是:预测边界框与真实边界框的交集面积除以它们的并集面积:
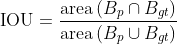
下图展示了真实边界框(绿色)与检测到的边界框(红色)之间的IOU。
真正例、假正例、假负例和真负例
指标中使用的一些基本概念:
- 真正例(TP):正确的检测。IOU ≥ 阈值 的检测
- 假正例(FP):错误的检测。IOU < 阈值 的检测
- 假负例(FN):未被检测到的真实目标
- 真负例(TN):不适用。它表示对误检的纠正。在目标检测任务中,图像中有很多不应被检测到的候选边界框。因此,TN将代表所有正确未被检测到的候选边界框(即图像中的大量可能边界框)。这就是为什么该指标不使用真负例的原因。
阈值:根据不同的指标,通常设置为50%、75%或95%。
精确率
精确率是指模型仅识别相关目标的能力。它是正确正例预测所占的百分比,计算公式如下:
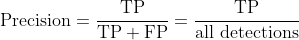
召回率
召回率是指模型找到所有相关样本(所有真实边界框)的能力。它是真正例占所有相关真实目标的百分比,计算公式如下:
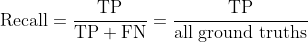
指标
在下面的主题中,我们将介绍一些用于目标检测的最常用指标。
精确率-召回率曲线
精确率-召回率曲线是一种很好的方式,可以通过绘制每个类别对象的曲线来评估目标检测器在不同置信度下的性能。如果随着召回率的增加,精确率仍然保持较高,则认为该类别的目标检测器表现良好。这意味着当调整置信度阈值时,精确率和召回率仍能维持在较高水平。另一种判断优秀目标检测器的方法是寻找能够仅识别相关目标(假正例为0,即高精确率),同时又能找到所有真实目标(假负例为0,即高召回率)的检测器。
而性能较差的目标检测器则需要通过增加检测到的对象数量(从而导致假正例增多,精确率降低)来获取所有真实目标(高召回率)。因此,精确率-召回率曲线通常从较高的精确率开始,随着召回率的增加而逐渐下降。您可以在下一节(平均精度)中看到精确率-召回率曲线的示例。这种类型的曲线被PASCAL VOC 2012挑战赛所采用,并且在我们的实现中也有提供。
平均精度
比较目标检测器性能的另一种方法是计算精确率-召回率曲线下的面积(AUC)。由于AP曲线通常是上下波动的锯齿状曲线,在同一张图上比较不同曲线(即不同检测器)往往并不容易——因为这些曲线经常会相互交叉。因此,平均精度(AP)这一数值型指标也可以帮助我们比较不同的检测器。实际上,AP是在召回率从0到1的所有取值范围内对精确率求平均得到的值。
自2010年起,PASCAL VOC挑战赛计算AP的方法发生了变化。目前,PASCAL VOC挑战赛采用的插值方法会使用所有数据点,而不是像其论文中所述那样仅插值11个等间距的点。为了重现他们的默认实现,我们的默认代码(见后文)遵循他们最新的应用方式(插值所有数据点)。不过,我们也提供了11点插值的方法。
11点插值
11点插值试图通过在一组11个等间距的召回率水平 [0, 0.1, 0.2, ... , 1] 上对精确率求平均来概括精确率-召回率曲线的形状:
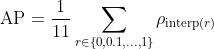
其中
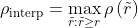
这里 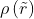 是在召回率
是在召回率 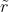 处测得的精确率。
处测得的精确率。
与直接使用每个点的精确率不同,AP是通过对11个召回率  进行插值来获得的,取的是召回值大于 的最大精确率。
进行插值来获得的,取的是召回值大于 的最大精确率。
插值所有点
与其仅在11个等间距的点上进行插值,你也可以通过所有点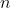 来进行插值,使得:
来进行插值,使得:
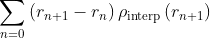
其中
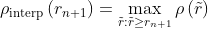
这里是在召回率下的实测精度。
在这种情况下,不再只使用少数几个点上的精度,而是通过对每个级别的精度进行插值来计算AP,即取那些召回值大于或等于 的最高精度。这样我们就能计算出曲线下方的估计面积。
的最高精度。这样我们就能计算出曲线下方的估计面积。
为了更清楚地说明,我们提供了一个比较两种插值方法的示例。
一个图解示例
通过一个例子可以帮助我们更好地理解插值平均精度的概念。考虑以下检测结果:
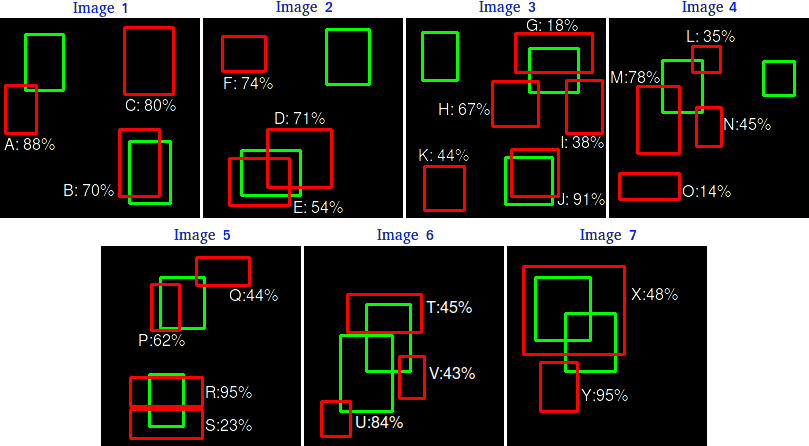
这里有7张图片,共包含15个真实标注目标(用绿色框表示)和24个检测到的目标(用红色框表示)。每个检测到的目标都有一个置信度,并用字母(A, B, ..., Y)来标识。
下表展示了各个边界框及其对应的置信度。最后一列标明了这些检测是TP还是FP。在这个例子中,如果IOU 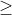 30%,则视为TP;否则为FP。通过观察上面的图片,我们可以大致判断哪些检测是TP,哪些是FP。
30%,则视为TP;否则为FP。通过观察上面的图片,我们可以大致判断哪些检测是TP,哪些是FP。
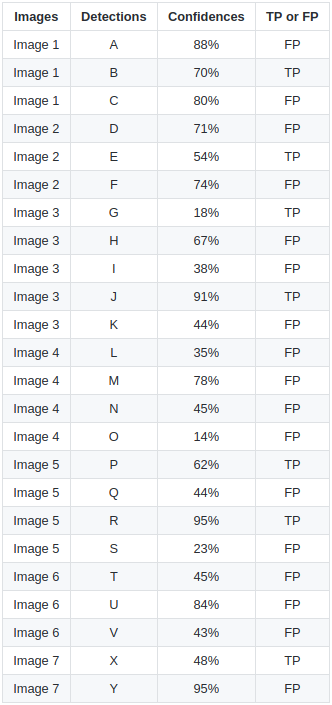
在某些图片中,多个检测框会与同一个真实标注框重叠(图片2、3、4、5、6和7)。对于这种情况,我们以具有最高IOU的预测框作为TP(例如,在图片1中,“E”是TP而“D”是FP,因为E与真实标注框的IOU大于D与真实标注框的IOU)。这一规则也适用于PASCAL VOC 2012指标:“例如,对单个物体的5次正确检测,只计为1次正确检测和4次错误检测”。
精确率与召回率曲线是通过计算累计TP或FP检测的精确率和召回率来绘制的。为此,我们首先需要按照置信度对检测结果进行排序,然后为每次累积检测计算精确率和召回率,如下表所示(请注意,对于召回率的计算,分母项(“累计TP + 累计FN”或“所有真实标注”)始终为15,因为无论检测结果如何,真实标注框的数量都是固定的):
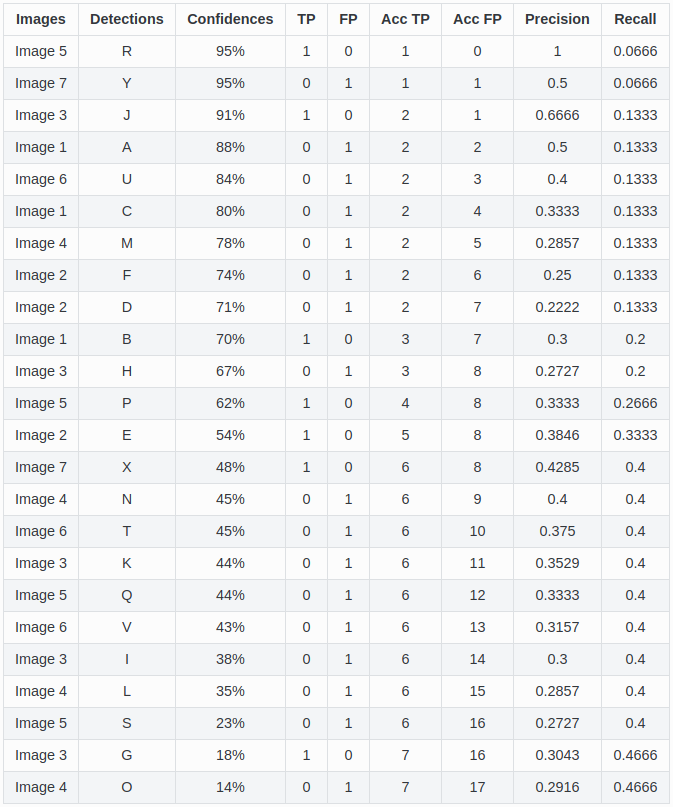
以第二行(图片7)为例进行计算:精确率 = TP/(TP+FP) = 1/2 = 0.5,召回率 = TP/(TP+FN) = 1/15 = 0.066。
绘制精确率和召回率的数值后,我们得到如下的精确率与召回率曲线:
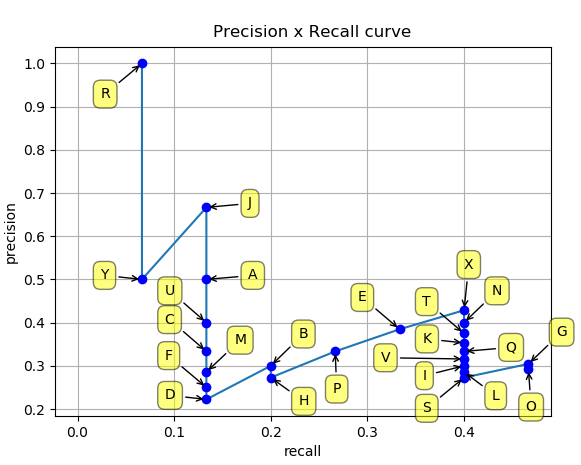
正如前面提到的,测量插值平均精度有两种不同的方法:11点插值和对所有点进行插值。下面我们对这两种方法进行比较:
计算11点插值
11点插值平均精度的思想是在一组11个召回率水平(0, 0.1, ..., 1)上对精度进行平均。插值后的精度值通过取当前召回率以上所有召回率对应的最高精度来获得,具体如下:
通过应用11点插值法,我们得到:
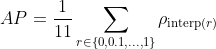
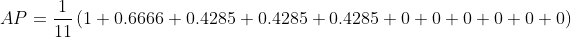
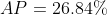
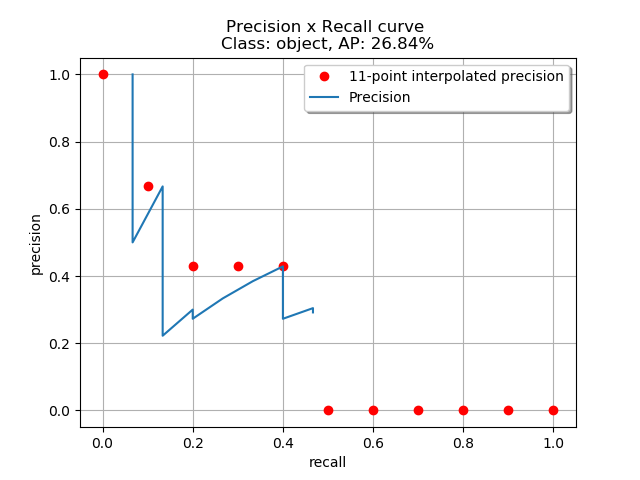
计算所有点上的插值
通过对所有点进行插值,平均精度(AP)可以被解释为精度-召回率曲线的近似AUC。其目的是减少曲线中波动的影响。通过应用前面介绍的公式,我们可以计算出各个区域的面积,如下所示。此外,我们也可以通过观察从最高召回率(0.4666)到0的召回率变化(即从右向左看图),收集每个召回率对应的最高精度值,从而直观地看到插值后的精度点,如图下所示:
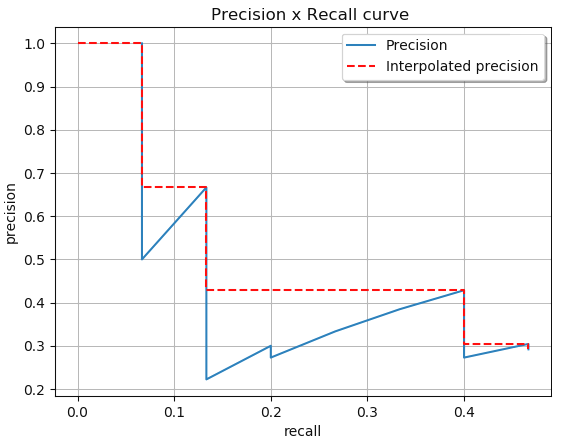
观察上图,我们可以将AUC分为4个区域(A1、A2、A3和A4):
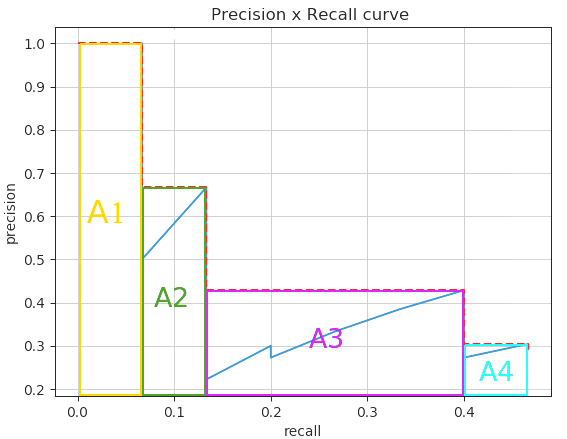
计算总面积后,即可得到AP:
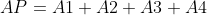
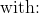
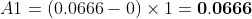
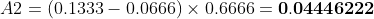
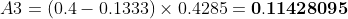
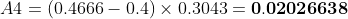
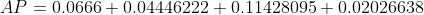
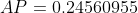
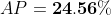
两种不同插值方法的结果略有差异:每点插值法得到24.56%,而11点插值法得到26.84%。
我们的默认实现与PASCAL VOC一致,采用每点插值法。如果希望使用11点插值法,只需将使用参数method=MethodAveragePrecision.EveryPointInterpolation的函数改为method=MethodAveragePrecision.ElevenPointInterpolation即可。
若想复现这些结果,请参阅**示例2**。
如何使用本项目
本项目旨在以非常简便的方式评估你的检测结果。如果你希望使用最常用的目标检测指标来评估你的算法,那么这里正是你需要的地方。
示例1 和 示例2 是实际案例,展示了如何直接调用本项目的核心函数,从而在使用指标时提供更大的灵活性。但如果你不想花时间理解我们的代码,可以按照以下说明轻松评估你的检测结果:
请按照以下步骤开始评估你的检测结果:
- 创建真实标注文件
- 创建你的检测文件
- 对于Pascal VOC指标,运行命令:
python pascalvoc.py
如果你想复现上面的例子,运行命令:python pascalvoc.py -t 0.3 - (可选)你可以使用参数来控制IOU阈值、边界框格式等
创建真实标注文件
- 在文件夹**groundtruths/**中,为每张图片创建一个单独的真实标注文本文件。
- 每个文件中的每一行应采用以下格式:
。 - 例如,图像“2008_000034.jpg”的真实标注边界框在文件“2008_000034.txt”中表示如下:
bottle 6 234 45 362 person 1 156 103 336 person 36 111 198 416 person 91 42 338 500
如果你愿意,也可以使用
bottle 6 234 39 128
person 1 156 102 180
person 36 111 162 305
person 91 42 247 458
创建你的检测文件
- 在文件夹**detections/**中,为每张图片创建一个单独的检测文本文件。
- 检测文件的名称必须与其对应的真实标注文件匹配(例如,“detections/2008_000182.txt”表示与“groundtruths/2008_000182.txt”相对应的检测结果)。
- 每个检测文件中的每一行应采用以下格式:
(详见此处*的使用方法)。 - 例如,“2008_000034.txt”:
bottle 0.14981 80 1 295 500 bus 0.12601 36 13 404 316 horse 0.12526 430 117 500 307 pottedplant 0.14585 212 78 292 118 tvmonitor 0.070565 388 89 500 196
同样,如果你更喜欢,也可以使用
可选参数
可选参数:
| 参数 | 描述 | 示例 | 默认值 |
|---|---|---|---|
-h,--help |
显示帮助信息 | python pascalvoc.py -h |
|
-v,--version |
检查版本 | python pascalvoc.py -v |
|
-gt,--gtfolder |
包含真实框文件的文件夹 | python pascalvoc.py -gt /home/whatever/my_groundtruths/ |
/Object-Detection-Metrics/groundtruths |
-det,--detfolder |
包含检测框文件的文件夹 | python pascalvoc.py -det /home/whatever/my_detections/ |
/Object-Detection-Metrics/detections/ |
-t,--threshold |
IOU 阈值,用于判断检测结果是真正例还是假正例 | python pascalvoc.py -t 0.75 |
0.50 |
-gtformat |
真实框坐标格式 * | python pascalvoc.py -gtformat xyrb |
xywh |
-detformat |
检测框坐标格式 * | python pascalvoc.py -detformat xyrb |
xywh |
-gtcoords |
真实框坐标参考。 如果标注的坐标是相对于图像尺寸的(如 YOLO 中使用),则设置为 rel。如果坐标是绝对值,不依赖于图像尺寸,则设置为 abs |
python pascalvoc.py -gtcoords rel |
abs |
-detcoords |
检测框坐标参考。 如果坐标是相对于图像尺寸的(如 YOLO 中使用),则设置为 rel。如果坐标是绝对值,不依赖于图像尺寸,则设置为 abs |
python pascalvoc.py -detcoords rel |
abs |
-imgsize |
图像尺寸,格式为 width,height <int,int>。如果 -gtcoords 或 -detcoords 设置为 rel,则此参数为必填项 |
python pascalvoc.py -imgsize 600,400 |
|
-sp,--savepath |
保存图表的文件夹 | python pascalvoc.py -sp /home/whatever/my_results/ |
Object-Detection-Metrics/results/ |
-np,--noplot |
如果存在,则执行过程中不显示任何图表 | python pascalvoc.py -np |
不显示。 因此,默认会显示图表 |
(*) 如果格式为 <left> <top> <width> <height>,则设置 -gtformat xywh 和/或 -detformat xywh。
如果格式为 <left> <top> <right> <bottom>,则设置 -gtformat xyrb 和/或 -detformat xyrb。
参考文献
精确率-召回率曲线与 ROC 曲线之间的关系(Jesse Davis 和 Mark Goadrich)
威斯康星大学计算机科学系及生物统计学与医学信息学系
http://pages.cs.wisc.edu/~jdavis/davisgoadrichcamera2.pdfPASCAL 视觉目标类别(VOC)挑战赛
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.157.5766&rep=rep1&type=pdf排序检索结果的评估(Salton 和 McGill,1986 年)
https://www.amazon.com/Introduction-Information-Retrieval-COMPUTER-SCIENCE/dp/0070544840
https://nlp.stanford.edu/IR-book/html/htmledition/evaluation-of-ranked-retrieval-results-1.html
版本历史
v0.22019/01/31v0.12018/06/22常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。