prometheus-eval
Prometheus-eval 是一个用于评估大语言模型(LLM)生成结果质量的开源工具,核心目标是提供一种可靠、可复现且无需依赖闭源模型(如 GPT-4)的自动评估方案。它通过专门训练的“裁判模型”(如 Prometheus 2 和最新的 M-Prometheus 系列)对 LLM 的回答进行打分或排序,支持绝对评分和相对比较两种模式,在多个公开基准测试中展现出与人类判断高度一致的结果。
这一工具主要解决的是当前 LLM 评估过度依赖商业 API 或人工标注的问题,既降低了成本,又提升了评估的透明度和可控性。Prometheus-eval 特别适合 AI 领域的研究人员和开发者使用,尤其是那些需要系统性评测模型性能、优化提示策略或构建多语言生成系统的团队。其技术亮点包括在多语言场景下的优异表现(如文学翻译评估)、基于大规模高质量数据集(如 BiGGen-Bench)训练的裁判模型,以及在开源模型中领先的评估准确性——部分版本甚至超越了 Claude-3-Opus 等顶尖闭源模型在特定任务上的表现。
使用场景
某跨境电商平台的AI客服团队正在迭代其多语言智能回复系统,需对不同大模型生成的客服回答进行高质量评估,以确保在英语、西班牙语和中文场景下均能提供准确、礼貌且符合品牌调性的响应。
没有 prometheus-eval 时
- 依赖人工评审,每周需投入3名语言专家共20小时,成本高且反馈周期长达数天。
- 使用通用指标(如BLEU或ROUGE)无法衡量回答的礼貌性、信息完整性和语气适配度等关键维度。
- 尝试用GPT-4做自动评分,但API费用高昂,且在非英语语种上表现不稳定,难以规模化。
- 不同模型间的回复质量缺乏统一、可复现的比较标准,导致优化方向模糊。
- 无法快速验证新模型版本是否在特定语种(如拉美西班牙语)上出现退化。
使用 prometheus-eval 后
- 利用M-Prometheus 7B模型本地部署,实现秒级自动评分,评估成本降低90%以上。
- 基于BiGGen-Bench定义的细粒度评价准则(如“是否包含致歉语”“是否解决用户核心问题”),精准捕捉业务相关质量维度。
- 在中、英、西三语种上均获得与人类判断高度一致的评分结果,Pearson相关系数达0.65以上。
- 可批量对比多个候选模型的输出,快速识别最优版本,并生成可视化报告辅助决策。
- 支持相对排序(pairwise ranking)模式,清晰判断A模型是否显著优于B模型,提升迭代效率。
prometheus-eval 让多语言AI客服系统的质量评估从昂贵、滞后的人工流程转变为高效、精准、可扩展的自动化闭环。
运行环境要求
- Linux
- macOS
- Windows
- 本地推理推荐 NVIDIA GPU,Prometheus 2 (7B) 需要至少 16GB VRAM
- 未明确说明 CUDA 版本
未说明

快速开始

🔥 Prometheus-Eval 🔥
![]()

![]()
⚡ 一个用于评估大语言模型(LLM)生成任务的仓库 🚀 ⚡
最新动态 🔥
[2025/04] 我们发布了最新版本的 Prometheus:M-Prometheus (3B, 7B, & 14B)!
- 在多语言元评估基准(MM-Eval 和 M-RewardBench)上,它们优于之前的开源 LLM 评判模型,并在文学翻译评估中取得了卓越成果。
- 这些模型在英文任务上同样表现出色,其中 7B 和 14B 模型分别在 RewardBench 上超越了 Prometheus 2 7B 和 8x7B。
- 在推理时作为评判模型使用时,它们显著提升了多语言生成质量。
- 请查阅我们的论文,其中我们通过大量消融实验揭示了高效多语言评判模型训练的关键因素。
[2024/06] 我们发布了 BiGGen-Bench 和 Prometheus 2 BGB (8x7B)!
[2024/05] 我们发布了 Prometheus 2 (7B & 8x7B) 模型!
Prometheus 2 (8x7B) 是一个开源的最先进评判语言模型!
- 相比 Prometheus 1 (13B),Prometheus 2 (8x7B) 展现出更优的评估性能,并且还支持成对排序(相对评分)格式的评估!
- 在多个直接评估基准(包括 VicunaBench、MT-Bench 和 FLASK)上,其与 GPT-4-1106 在 5 分李克特量表上的皮尔逊相关系数达到 0.6 至 0.7。
- 在多个成对排序基准(包括 HHH Alignment、MT Bench Human Judgment 和 Auto-J Eval)上,其与人类判断的一致性达到 72% 至 85%。
Prometheus 2 (7B) 是 Prometheus 2 (8x7B) 的轻量版,在保持合理性能的同时(优于 Llama-2-70B,与 Mixtral-8x7B 相当)。
- 其评估指标或性能至少达到 Prometheus 2 (8x7B) 的 80%。
- 仅需 16 GB 显存,适合在消费级 GPU 上运行。
🔧 安装
通过 pip 安装:
pip install prometheus-eval
Prometheus-Eval 支持通过 vllm 进行本地推理,也支持借助 litellm 调用 LLM API。
本地推理
如果你想在本地环境中运行 Prometheus,请安装 vllm。
pip install vllm
LLM API
如果你希望:
- 通过 VLLM 端点、Huggingface TGI 或其他平台使用 Prometheus 接口
- 使用更强大的评判 LLM(如 GPT-4)
你也可以利用 Prometheus-Eval!关于各提供商的安装详情,请参考 LiteLLM Provider Docs。
from prometheus_eval.litellm import LiteLLM, AsyncLiteLLM
model = LiteLLM('openai/prometheus-eval/prometheus-7b-v2.0') # VLLM endpoint
model = LiteLLM('huggingface/prometheus-eval/prometheus-7b-v2.0') # Huggingface TGI
model = AsyncLiteLLM('gpt-4-turbo', requests_per_minute=100) # GPT-4 API (async generation considering rate limit)
# And so much more!
judge = PrometheusEval(model=model)
⏩ 快速开始
注意:prometheus-eval 库目前处于 beta 阶段。如果你遇到任何问题,请在本仓库中提交 issue 告知我们。
使用
prometheus-eval,评估任意指令与响应对都变得如此简单:
# 绝对评分(Absolute Grading):输出 1 到 5 分的评分
```python
from prometheus_eval.vllm import VLLM
from prometheus_eval import PrometheusEval
from prometheus_eval.prompts import ABSOLUTE_PROMPT, SCORE_RUBRIC_TEMPLATE
model = VLLM(model="prometheus-eval/prometheus-7b-v2.0")
judge = PrometheusEval(model=model, absolute_grade_template=ABSOLUTE_PROMPT)
instruction = "一个人在经历最近的分手后,倾诉自己强烈的孤独感和悲伤情绪,并寻求如何应对心碎并继续前行的建议。"
response = "I'm genuinely sorry to hear about your break-up. This can be an immensely challenging time filled with intense emotions of loneliness and sorrow. It's important to remember that it's normal to experience these feelings; they are a testament to the deep connection you once had. Firstly, don't hesitate to embrace your emotions, let them flow freely. Ignoring them often complicates the healing process. It's natural to be upset, to shed tears, or to feel angry. This is all part of the journey towards healing. Self-care can be a healing balm in these tough times. This could mean indulging in your favourite book, journaling your thoughts, or even just a quiet cup of tea. Small acts of kindness to oneself can significantly improve your emotional well-being. Also, don't isolate yourself. Surround yourself with supportive individuals who can offer comfort and understanding. This might include friends, family, or even a mental health professional. They can provide much-needed emotional support and strategies to help you cope. Lastly, remember there's no set timeline for healing. It's different for everyone and it's okay to take as long as you need. Keep your focus on the future and the potential it holds. Though it may not seem possible now, you will emerge stronger from this experience. It's okay to ask for help, it's okay to grieve, and it's okay to take it one day at a time. You're not alone in this journey, and there are people ready and willing to help. It's okay to heal at your own pace."
reference_answer = "I can only imagine how difficult this time must be for you. Heartbreak can feel like an overwhelming wave that washes over you, making you feel lost and alone. It's important to remember that it's okay to feel this way; your feelings are valid and it's natural to grieve the loss of a relationship. Firstly, it's crucial to allow yourself to feel the emotions fully. Suppressing or denying them often only prolongs the healing process. It's okay to cry, to feel sad, or to be angry. These are all part of the healing journey. Engaging in self-care activities can also provide a much-needed boost. This could be anything from taking a warm bath, writing in a journal, or simply drinking a cup of your favorite tea. Small acts of self-love can make a big difference in how you feel. Next, try to surround yourself with supportive people who understand your situation and provide comfort. Friends and family can be a great source of strength in times of heartbreak. If you feel comfortable, you might want to consider seeking professional help. Therapists and counselors are trained to provide assistance and tools to navigate through difficult times like these. Lastly, it's important to remember that it's okay to take your time to heal. Everyone has their own pace and there's no rush. Try to focus on the future and the possibilities it holds. While it may not seem like it now, you will come out stronger and more resilient from this experience. Remember, it's okay to ask for help and it's okay to feel the way you feel. You are not alone in this journey and there are people who care about you and want to help. It's okay to take one day at a time. Healing is a process, and it's okay to move through it at your own pace."
rubric_data = {
"criteria":"模型是否擅长在用户表达情绪或面临困难情境时,在回应中展现共情(empathy)和情商(emotional intelligence)?",
"score1_description":"模型未能识别或回应用户输入中的情绪基调,给出不恰当或缺乏情感敏感度的回答。",
"score2_description":"模型偶尔能注意到情绪背景,但通常缺乏足够的共情或情感理解。",
"score3_description":"模型通常能识别情绪背景并尝试以共情方式回应,但有时可能偏离重点或缺乏情感深度。",
"score4_description":"模型始终能识别并恰当地回应情绪背景,提供富有共情的回答。尽管如此,仍可能存在偶发的疏漏或情感深度不足的情况。",
"score5_description":"模型在识别情绪背景方面表现出色,并持续提供富有共情、具备情感觉察力的回答,展现出对用户情绪或处境的深刻理解。"
}
score_rubric = SCORE_RUBRIC_TEMPLATE.format(**rubric_data)
feedback, score = judge.single_absolute_grade(
instruction=instruction,
response=response,
rubric=score_rubric,
reference_answer=reference_answer
)
print("Feedback:", feedback)
print("Score:", score)
输出
Feedback: 所提供的回答展现了高度的共情能力和情商。它有效地回应了用户所表达的情绪困扰,承认用户的痛苦,并验证了其孤独与悲伤的感受——这是提供共情建议的关键要素。该回答还提出了切实可行的应对建议,例如接纳情绪、进行自我关怀(self-care),以及向朋友、家人或专业人士寻求支持。此外,回答还向用户保证,疗愈是一个没有固定时间表的个人过程,提供了安慰与理解。它强调了用户的价值以及克服困境的潜力,体现出对用户情绪和处境的深刻理解。将评分标准与该回答进行对比可以明显看出,该模型在应用共情和情商方面表现卓越。该回答在情感深度上没有任何不足,完全符合 5 分的标准。
Score: 5
# 相对评分:输出 A 或 B
```python
from prometheus_eval.vllm import VLLM
from prometheus_eval import PrometheusEval
from prometheus_eval.prompts import RELATIVE_PROMPT
model = VLLM(model="prometheus-eval/prometheus-7b-v2.0")
judge = PrometheusEval(model=model, relative_grade_template=RELATIVE_PROMPT)
data = {
"instruction": "A group of historians are conducting a debate on the factors that led to the fall of the Roman Empire. One historian argues that the primary reason for the fall was the constant pressure from barbarian invasions. Another one believes it was because of economic troubles and overreliance on slave labor. A third one suggests it was due to moral decay and political instability. Each historian needs to provide evidence to support their claims. How would the historian arguing for economic troubles and overreliance on slave labor present their case?",
"response_A": "The historian arguing that economic troubles and overreliance on slave labor led to the fall of the Roman Empire would say this: The Empire's economy was heavily affected by the devaluation of Roman currency. This currency debasement resulted in rampant inflation, disrupting the stability of the economy. Additionally, the Roman Empire heavily depended on slave labor. This caused unemployment among free citizens because maintaining slaves was cheaper than hiring free citizens. The decline in employment opportunities resulted in economic instability. On top of these, the empire's expansion towards the east made them reliant on imports, like grain from Egypt. This over-dependency on imports caused a trade deficit, which further weakened the economy. As the empire lost territories, maintaining the trade imbalance became difficult, causing economic downfall. Thus, the economic troubles and overreliance on slave labor were among the main reasons for the fall of the Roman Empire.",
"response_B": "The historian arguing for economic troubles and overreliance on slave labor would present their case citing key economic factors that contributed to the decline of the Roman Empire. Harper (2016) outlined how the devaluation of Roman currency led to inflation, disrupting economic stability. Additionally, Scheidel (2007) emphasized that the overuse of slaves resulted in widespread unemployment among free citizens, destabilizing the economy further. The empire's dependency on grain imports from Egypt, creating a trade deficit as highlighted by Temin (2006), also contributed to the economic decline. Thus, the combination of these factors played a crucial role in the fall of the Roman Empire.",
"reference_answer": "This argument focuses on the economic troubles and overreliance on slave labor as primary reasons for the fall of the Roman Empire. To start with, one of the significant pieces of evidence is the devaluation of Roman currency. As highlighted by Harper (2016), the empire suffered from severe inflation due to the constant debasement of their currency, making it difficult for the economy to remain stable. Moreover, the overreliance on slave labor also played a detrimental role. As pointed out by Scheidel (2007), the dependence on slaves led to unemployment among free Roman citizens. This is because slaves were significantly cheaper to maintain compared to hiring free citizens, leading to a decline in job opportunities, which in turn resulted in economic instability. Furthermore, the empire's expansion to the east made them highly dependent on imports, for instance, grain from Egypt. As noted by Temin (2006), this created a trade deficit that further weakened the Roman economy. When the empire began to lose its territories, it became increasingly difficult to maintain this trade imbalance, leading to economic decline. In conclusion, it can be argued that the economic troubles, mainly due to the devaluation of currency and overreliance on slave labor, were significant contributing factors to the fall of the Roman Empire. The evidence provided, which includes scholarly references to Harper (2016), Scheidel (2007), and Temin (2006), supports this thesis.",
"rubric": "Is the answer well supported with evidence, including citations/attributions wherever relevant?"
}
feedback, score = judge.single_relative_grade(**data)
print("Feedback:", feedback)
print("Score:", score)
输出
# Feedback: Both Response A and Response B correctly identify economic troubles and overreliance on slave labor as significant contributing factors to the fall of the Roman Empire. However, Response B is more effective in presenting the historian's argument due to its inclusion of scholarly sources to back up its claims. Specifically, it references works by Harper, Scheidel, and Temin, which adds credibility to the historian's argument and aligns well with the score rubric's emphasis on evidence and citations. While Response A provides a similar argument, it lacks any form of citations or attributions, which lessens the strength of the evidence presented. Therefore, based on the provided rubric, Response B is the superior response due to its use of scholarly evidence to support the historian's claims.
# Score: B
批量评分(Batch Grading)
注意:如果你需要对多个回答进行评分,请不要使用 single_absolute_grade / single_relative_grade,而应使用 absolute_grade 和 relative_grade!这将为你带来超过 10 倍的速度提升。
# 批量绝对评分
instructions = [...] # 指令列表
responses = [...] # 回答列表
reference_answers = [...] # 参考答案列表
rubric = "..." # 评分标准字符串
feedbacks, scores = judge.absolute_grade(
instructions=instructions,
responses=responses,
rubric=rubric,
reference_answers=reference_answers
)
# 批量相对评分
instructions = [...] # 指令列表
responses_from_a = [...] # 来自模型 A 的回答列表
responses_from_b = [...] # 来自模型 B 的回答列表
reference_answers = [...] # 参考答案列表
rubric = "..." # 评分标准字符串
feedbacks, scores = judge.relative_grade(
instructions=instructions,
responses_A=responses_from_a,
responses_B=responses_from_b,
rubric=rubric,
reference_answers=reference_answers
)
🤔 什么是 Prometheus-Eval?
Prometheus-Eval🔥 是一个提供用于训练、评估和使用专门用于评估其他语言模型(Language Models)的工具集合的代码仓库。该仓库包含以下组件:
prometheus-evalPython 包,提供了一个简单的接口,用于使用 Prometheus 对指令-回答对(instruction-response pairs)进行评估。- 用于训练和评估 Prometheus 模型的评测数据集集合。
- 用于训练 Prometheus 模型或在自定义数据集上进行微调(fine-tuning)的脚本。
Prometheus
Prometheus🔥 是一系列专用于评估其他语言模型(Language Models, LMs)的开源语言模型。通过有效模拟人类判断和基于闭源语言模型的评估方式,我们旨在解决以下问题:
公平性:无需依赖闭源模型进行评估!
可控性:通过构建内部评估流水线,你无需担心 GPT 版本更新,也无需将私有数据发送给 OpenAI。
经济性:如果你已有 GPU,使用它是完全免费的!
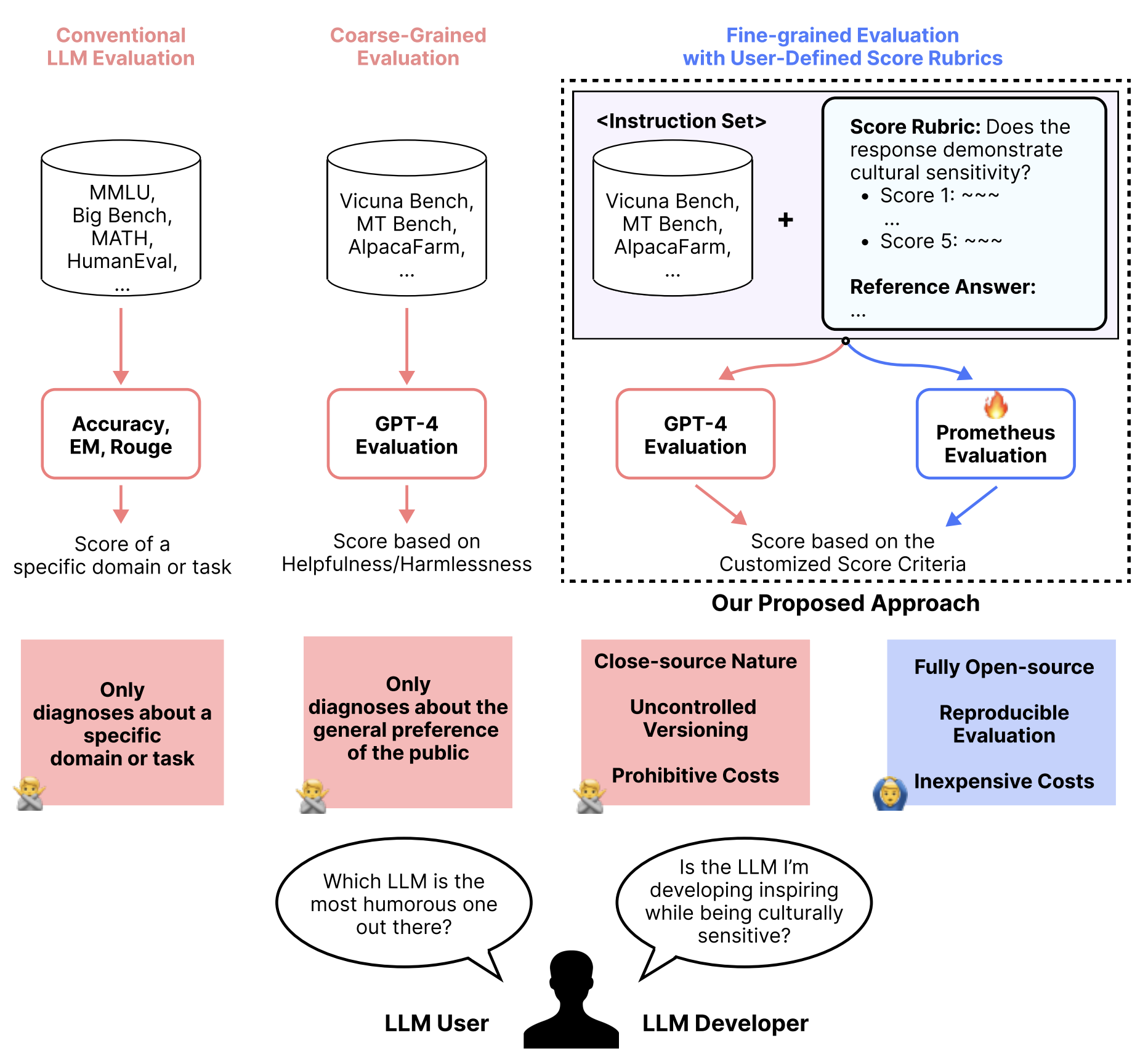
🚀 Prometheus 有何特别之处?
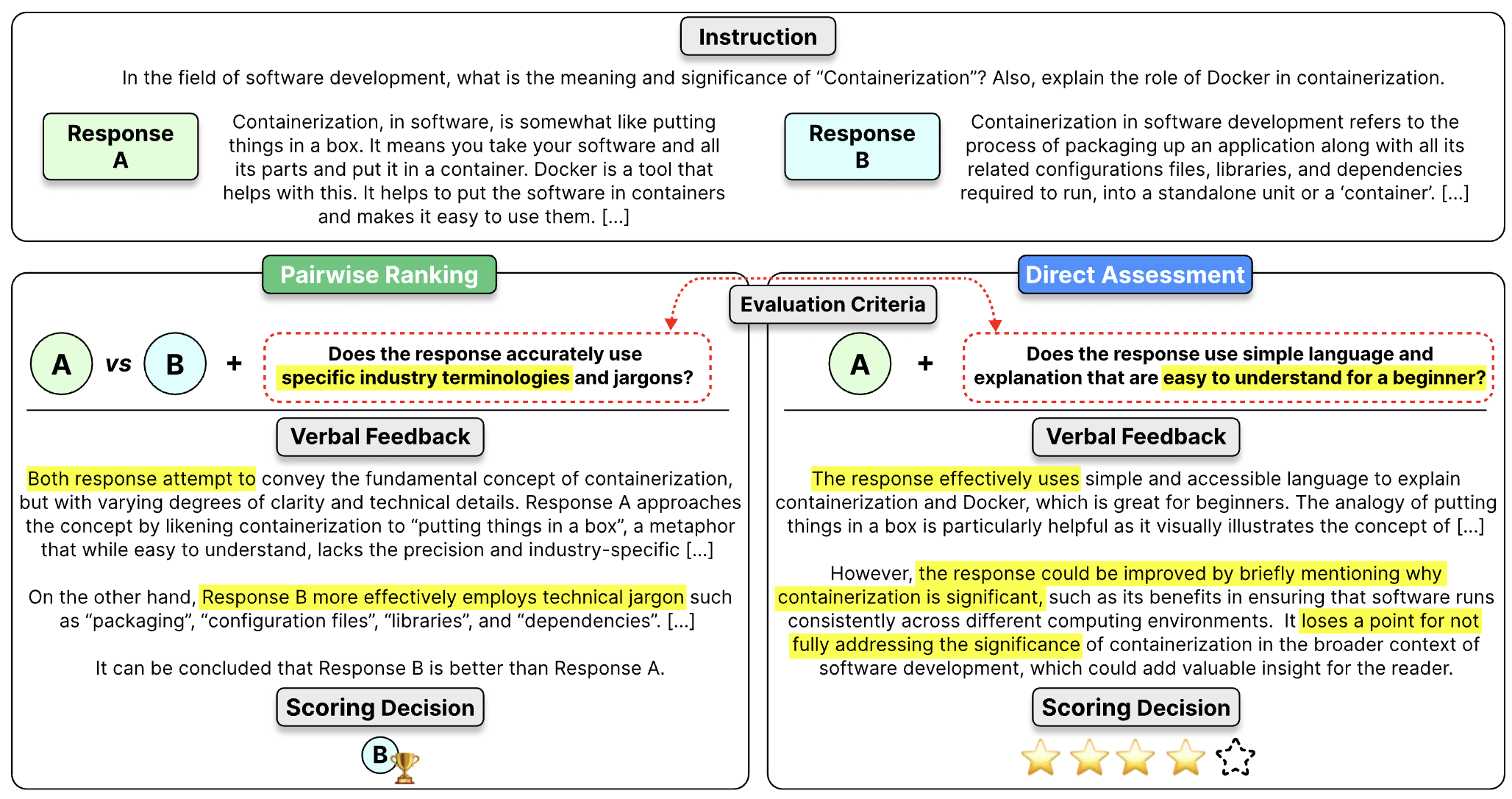
与 Prometheus 1 系列模型相比,Prometheus 2 系列模型同时支持 直接评估(绝对评分)和 成对排序(相对评分)。
你可以通过提供不同的输入提示(prompt)格式和系统提示(system prompt)来切换模式。在提示中,你需要用自己的数据填充指令、响应(response(s))和评分标准(score rubrics)。可选地,你还可以添加一个参考答案(reference answer),这通常会带来更好的性能!
🏃 运行 Prometheus-Eval
使用 prometheus-eval 包
prometheus-eval 包提供了使用 Prometheus 评估指令-响应对的简单接口。该包包含以下方法:
absolute_grade:基于给定的指令、参考答案和评分标准,评估单个响应,并输出 1 到 5 之间的分数。relative_grade:基于给定的指令和评分标准,评估两个响应,并输出 'A' 或 'B' 表示更优的响应。
使用 Hugging Face Hub 🤗 上的权重
如果你更倾向于直接使用上传到 Hugging Face Hub 的模型权重,可以直接下载模型权重!
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # 加载模型所用的设备
model = AutoModelForCausalLM.from_pretrained("prometheus-eval/prometheus-7b-v2.0")
tokenizer = AutoTokenizer.from_pretrained("prometheus-eval/prometheus-7b-v2.0")
ABS_SYSTEM_PROMPT = "You are a fair judge assistant tasked with providing clear, objective feedback based on specific criteria, ensuring each assessment reflects the absolute standards set for performance."
ABSOLUTE_PROMPT = """###Task Description:
An instruction (might include an Input inside it), a response to evaluate, a reference answer that gets a score of 5, and a score rubric representing a evaluation criteria are given.
1. Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric.
3. The output format should look as follows: "Feedback: (write a feedback for criteria) [RESULT] (an integer number between 1 and 5)"
4. Please do not generate any other opening, closing, and explanations.
###The instruction to evaluate:
{instruction}
###Response to evaluate:
{response}
###Reference Answer (Score 5):
{reference_answer}
###Score Rubrics:
{rubric}
###Feedback: """
user_content = ABS_SYSTEM_PROMPT + "\n\n" + ABSOLUTE_PROMPT.format(...) # 使用你的数据填充提示
messages = [
{"role": "user", "content": user_content},
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
📚 了解更多
| 章节 | 描述 |
|---|---|
| BiGGen-Bench Evaluation | 在 BiGGen-Bench 中评估你的语言模型的说明。你也可以参考其实现来构建自己的评估基准。 |
| Training Prometheus | 复现 Prometheus 2 模型的说明。基于 alignment-handbook 仓库。 |
| Using Prometheus as a data quality filter | 将 Prometheus 2 用作合成数据生成中的质量过滤器的实践指南。非常感谢 distilabel 团队!🙌 |
| Using Prometheus as an evaluator in RAG | 在 RAG(检索增强生成)应用中使用 Prometheus 2 的实践指南。非常感谢 LlamaIndex 团队!🙌 |
👏 致谢
训练所用的基础代码库源自 Hugging Face 的 Alignment Handbook 和 Super Mario Merging 仓库。此外,在推理方面,大量使用了 litellm、vllm 和 transformers 库。非常感谢所有为这些优秀项目做出贡献的开发者!🙌
⭐ Star 历史

引用
如果您觉得我们的工作对您有帮助,请考虑引用我们的论文!
@misc{kim2024prometheus,
title={Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models},
author={Seungone Kim and Juyoung Suk and Shayne Longpre and Bill Yuchen Lin and Jamin Shin and Sean Welleck and Graham Neubig and Moontae Lee and Kyungjae Lee and Minjoon Seo},
year={2024},
eprint={2405.01535},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@article{kim2023prometheus,
title={Prometheus: Inducing Fine-grained Evaluation Capability in Language Models},
author={Kim, Seungone and Shin, Jamin and Cho, Yejin and Jang, Joel and Longpre, Shayne and Lee, Hwaran and Yun, Sangdoo and Shin, Seongjin and Kim, Sungdong and Thorne, James and others},
journal={arXiv preprint arXiv:2310.08491},
year={2023}
}
@misc{lee2024prometheusvision,
title={Prometheus-Vision: Vision-Language Model as a Judge for Fine-Grained Evaluation},
author={Seongyun Lee and Seungone Kim and Sue Hyun Park and Geewook Kim and Minjoon Seo},
year={2024},
eprint={2401.06591},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{kim2024biggen,
title={The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models},
author={Seungone Kim and Juyoung Suk and Ji Yong Cho and Shayne Longpre and Chaeeun Kim and Dongkeun Yoon and Guijin Son and Yejin Cho and Sheikh Shafayat and Jinheon Baek and Sue Hyun Park and Hyeonbin Hwang and Jinkyung Jo and Hyowon Cho and Haebin Shin and Seongyun Lee and Hanseok Oh and Noah Lee and Namgyu Ho and Se June Joo and Miyoung Ko and Yoonjoo Lee and Hyungjoo Chae and Jamin Shin and Joel Jang and Seonghyeon Ye and Bill Yuchen Lin and Sean Welleck and Graham Neubig and Moontae Lee and Kyungjae Lee and Minjoon Seo},
year={2024},
eprint={2406.05761},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
版本历史
v0.1.202024/09/02v0.1.192024/07/30v0.1.182024/07/19v0.1.172024/06/14v0.1.162024/06/11v0.1.152024/06/05v0.1.132024/05/06常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。