ComfyUI-PainterI2V
ComfyUI-PainterI2V 是一款专为 ComfyUI 设计的增强型节点,旨在优化 Wan2.2 模型的图生视频(Image-to-Video)效果。它主要解决了在使用 4 步加速 LoRA(如 lightx2v)时,生成视频常出现的动作过于缓慢、运镜幅度不足等“慢动作”痛点。通过该节点,用户可将视频中的运动幅度提升 15% 至 50%,并显著增强对运镜提示词的响应能力,让画面动态更加自然流畅。
这款工具非常适合希望快速提升视频生成质量的设计师、内容创作者以及 AI 绘画爱好者。其最大的亮点在于“即插即用”的便捷性:无需修改复杂的工作流,只需将原生的 WanImageToVideo 节点替换为 PainterI2V,即可兼容现有流程。在技术层面,ComfyUI-PainterI2V 采用了独特的“亮度保护运动缩放”算法,在放大运动向量的同时分离亮度均值,确保画面亮度稳定;同时结合零 Latent 初始化策略,严格维持 4 步 LoRA 的时序依赖,在保证主体一致性的前提下大幅释放动态潜力。用户仅需简单调节 motion_amplitude 参数,即可针对不同场景(如跑步、行走或极限运动)获得理想的动态效果。
使用场景
一位短视频创作者正试图利用 Wan2.2 模型配合 4 步加速 LoRA(如 lightx2v),将一张静态的“极限跑酷”图片快速转化为动态视频,以满足社交媒体对高频更新的需求。
没有 ComfyUI-PainterI2V 时
- 动作严重迟缓:生成的视频中人物仿佛在慢动作回放,完全丢失了跑酷应有的爆发力和速度感。
- 运镜指令失效:即使提示词中强调了“快速推镜”或“剧烈晃动”,镜头移动依然微弱且呆板,缺乏视觉冲击力。
- 反复调试无果:为了获得正常速度,不得不尝试调整数十版提示词或更换模型,导致单条视频制作耗时从几分钟拉长至数小时。
- 动态幅度不足:整体运动幅度受限,画面显得沉闷,无法达到极限运动所需的张力,直接导致素材不可用。
使用 ComfyUI-PainterI2V 后
- 运动幅度显著提升:仅需将
motion_amplitude参数设为 1.5,人物动作瞬间提速 50%,完美还原了极限运动的疾驰感。 - 运镜控制精准听话:镜头语言对提示词的响应变得敏锐,能够轻松实现大幅度的推拉摇移,画面极具电影感。
- 工作流无缝衔接:直接替换原有节点即可生效,无需修改其他设置,原本需要数小时的调试过程缩短为几分钟的参数微调。
- 画质与亮度稳定:在增强动态的同时,核心算法确保了画面亮度不变,主体一致性良好,避免了因加速导致的画面闪烁或失真。
ComfyUI-PainterI2V 通过专有的运动缩放算法,彻底解决了 4 步 LoRA 生成视频时的“慢动作”顽疾,让高速动态内容的批量生产变得高效且可控。
运行环境要求
- 未说明
未说明(基于 Wan2.2 和 ComfyUI 生态,通常隐含需要支持 CUDA 的 NVIDIA GPU,但本文档未明确具体型号或显存要求)
未说明

快速开始
ComfyUI-PainterI2V 此节点由抖音博主:绘画小子 制作。
Wan2.2 图生视频增强节点,专门针对4步LoRA(如 lightx2v)的慢动作问题进行优化。
2026-2-13 我制作了一个PainterHumoAI2V节点,已经实现WAN2.2+Humo 直接 音频+图片 4步生成音频驱动的图生视频(AI2V)并支持首尾帧,欢迎尝试(项目内有工作流)!https://github.com/princepainter/ComfyUI-PainterNodes
2025-12-30,我更新了一个PainterI2V的优化版PainterI2Vadvanced,建议尝试使用。项目地址:https://github.com/princepainter/ComfyUI-PainterI2Vadvanced
如果你用的是KJ的wan2.2-i2v工作流,请使用这个专门为KJ开发的节点,效果一致 (https://github.com/princepainter/ComfyUI-PainterI2VforKJ)
(FirstLastFrameToVideo)首尾帧节点 PainterFLF2V:https://github.com/princepainter/Comfyui-PainterFLF2V
🛠 解决的问题
- ✅ 1.减少慢动作:提升运动幅度 15-50%
- ✅ 2.增强运镜:让运镜提示词更听话,运镜幅度更大
和wan2.2官方节点效果对比
 |
 |
 |
| motion_amplitude=1.2 | motion_amplitude=1.15 | motion_amplitude=1.15 |
 |
 |
 |
| motion_amplitude=1.5 | motion_amplitude=1.2 | motion_amplitude=1.15 |
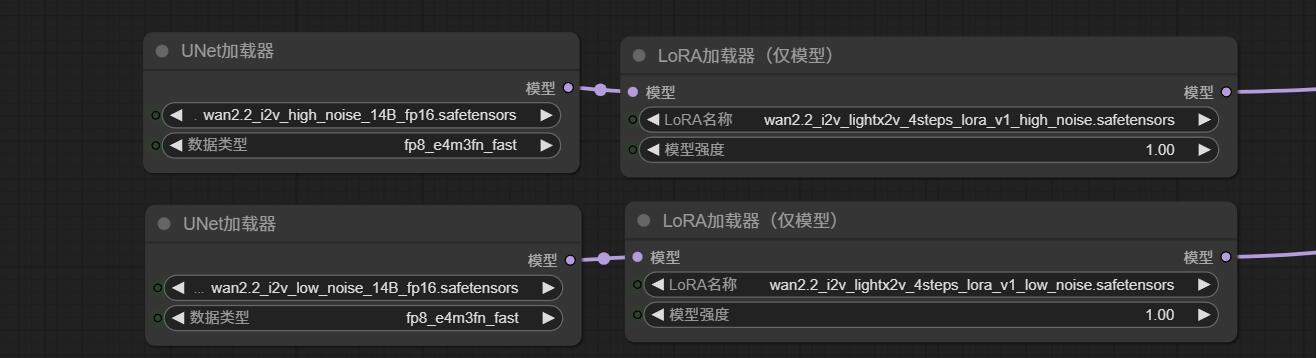
以上视频对比效果,我是使用wan2.2官方模型+light2v 4步i2v lora V1.0做的测试(见下图),其他模型使用效果有待各位自行测试
节点特点
- 单帧输入优化:专为wan2.2单帧图生视频设计
- 即插即用:完全兼容原版 Wan2.2 工作流
📦 安装
方法 1: ComfyUI Manager(推荐)
- 打开 ComfyUI Manager
- 搜索 PainterI2V
- 点击安装
方法 2: 手动安装
# 进入ComfyUI的custom_nodes目录
cd ComfyUI/custom_nodes
# 克隆仓库
git clone https://github.com/princepainter/ComfyUI-PainterI2V.git
重启ComfyUI
💡 使用方法
替换节点
在工作流中将 WanImageToVideo 替换为 PainterI2V
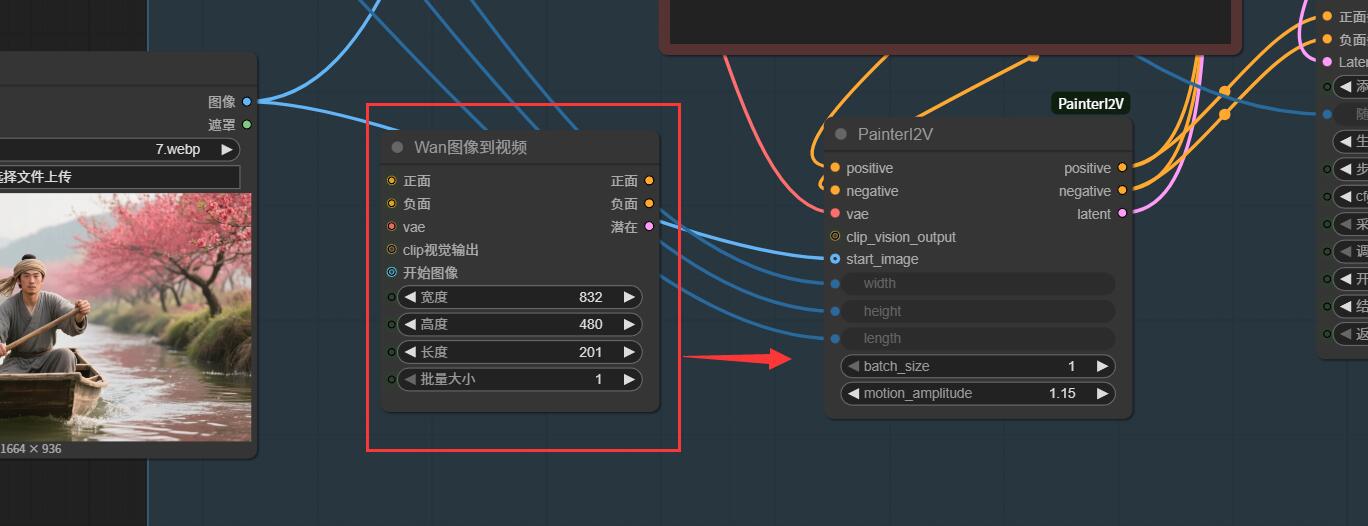
参数设置
motion_amplitude: 1.15(推荐起始值)- 其他参数与原版保持一致
场景参数推荐
| 运动类型 | 推荐参数 | 示例提示词 |
|---|---|---|
| 快速(跑步 / 跳跃) | 1.25–1.35 | "快速向前奔跑" |
| 正常(走路 / 挥手) | 1.10–1.20 | "流畅地行走" |
| 动态增强 | 1.00–1.10 | "略微增强动态和运镜" |
提示词优化
- 明确描述运动节奏,如 “快速奔跑”、“流畅行走”
- 避免模糊描述如 “移动”、“走动”
🔬 技术细节
| 参数值 | 运动提升 | 亮度变化 | 适用场景 |
|---|---|---|---|
| 1.0(原版) | 0% | 无 | 和WAN原版节点无区别 |
| 1.15(默认) | +15% | 无 | 通用场景 |
| 1.3 | +30% | 无 | 体育运动 |
| 1.5 | +50% | 无 | 极限运动 |
核心算法原理
- 亮度保护的运动缩放:放大运动向量前分离亮度均值
- 零 latent 初始化:严格保持 4 步 LoRA 的时序依赖链
- 参考帧增强:使用
reference_latents保持主体一致性,不约束运动
⚡ 进阶技巧
- 最佳效果:配合强运动提示词使用
- 运动过快:每次减少
motion_amplitude0.05 - 仍然偏慢:可适当增大到 1.4
🙏 致谢
Wan2.2 团队:提供惊人的视频生成模型
ComfyUI 社区:灵活的节点系统
🙏如果这个项目对你有帮助,请给颗星 ⭐️ 支持一下!ComfyUI-Painterl2V
This node is created by Douyin creator: 绘画小子
PainterI2V node that specifically fixes the slow-motion issue in 4-step LoRAs (e.g., lightx2v).
2025-12-30现在已经推出升级版PainterI2Vadvanced,建议使用。项目地址:https://github.com/princepainter/PainterI2Vadvanced
The comparative effects in the above video are from my test using the official Wan2.2 model + Light2v 4-step I2V LoRA V1.0. The performance of other models awaits your own testing .
If you're using KJ's wan2.2-i2v workflow, use this node specifically developed for KJ — the effect is consistent.https://github.com/princepainter/ComfyUI-PainterI2VforKJ
🛠 Problems Solved
- ✅ Reduces Slow-Motion Drag: Increases motion amplitude by 15-50%
- ✅ Enhance camera movement: Make the camera movement prompts more responsive and increase the movement amplitude.
- ✅ Optimized for Single Frame: Designed specifically for single-frame image-to-video workflows
- ✅ Plug & Play: Fully compatible with original Wan2.2 workflows
📦 Installation
Method 1: ComfyUI Manager (Recommended)
- Open ComfyUI Manager
- Search for PainterI2V
- Click Install
Method 2: Manual Installation
# Navigate to ComfyUI's custom_nodes directory
cd ComfyUI/custom_nodes
# Clone the repository
git clone https://github.com/princepainter/ComfyUI-PainterI2V.git
💡 Usage Guide
Replace the Node
In your workflow, replace WanImageToVideo with PainterI2V.
Parameter Settings
motion_amplitude: 1.15 (recommended starting value)- Keep all other parameters consistent with the original node.
Recommended Parameters by Scene
| Motion Type | Recommended Value | Example Prompt |
|---|---|---|
| Fast (running / jumping) | 1.25–1.35 | "Running forward quickly" |
| Normal (walking / waving) | 1.10–1.20 | "Walking smoothly" |
| Motion Enhancement | 1.00–1.10 | "Slightly enhance motion and camera movement" |
Prompt Optimization Tips
- Clearly describe motion rhythm, e.g., “run fast”, “walk smoothly”
- Avoid vague terms like “move” or “walk around”
🔬 Technical Details
| Parameter | Motion Boost | Brightness Change | Best For |
|---|---|---|---|
| 1.0 (original) | 0% | None | No difference from the original WAN node |
| 1.15 (default) | +15% | None | General use |
| 1.3 | +30% | None | Sports action |
| 1.5 | +50% | None | Extreme motion |
Core Algorithm Principles
- Brightness-Protected Motion Scaling: Separates luminance mean before scaling motion vectors
- Zero Latent Initialization: Strictly preserves the temporal dependency chain required by 4-step LoRAs
- Reference Frame Enhancement: Uses
reference_latentsto maintain subject consistency without constraining motion
⚡ Advanced Tips
- Best results: Use with strong motion-related prompts
- Motion too fast? Reduce
motion_amplitudeby 0.05 increments - Still too slow? Try increasing up to 1.4
🙏 Acknowledgements
- Wan2.2 Team: For the amazing video generation model
- ComfyUI Community: For the flexible node system
- Contributors & testers: For helping refine this node
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。