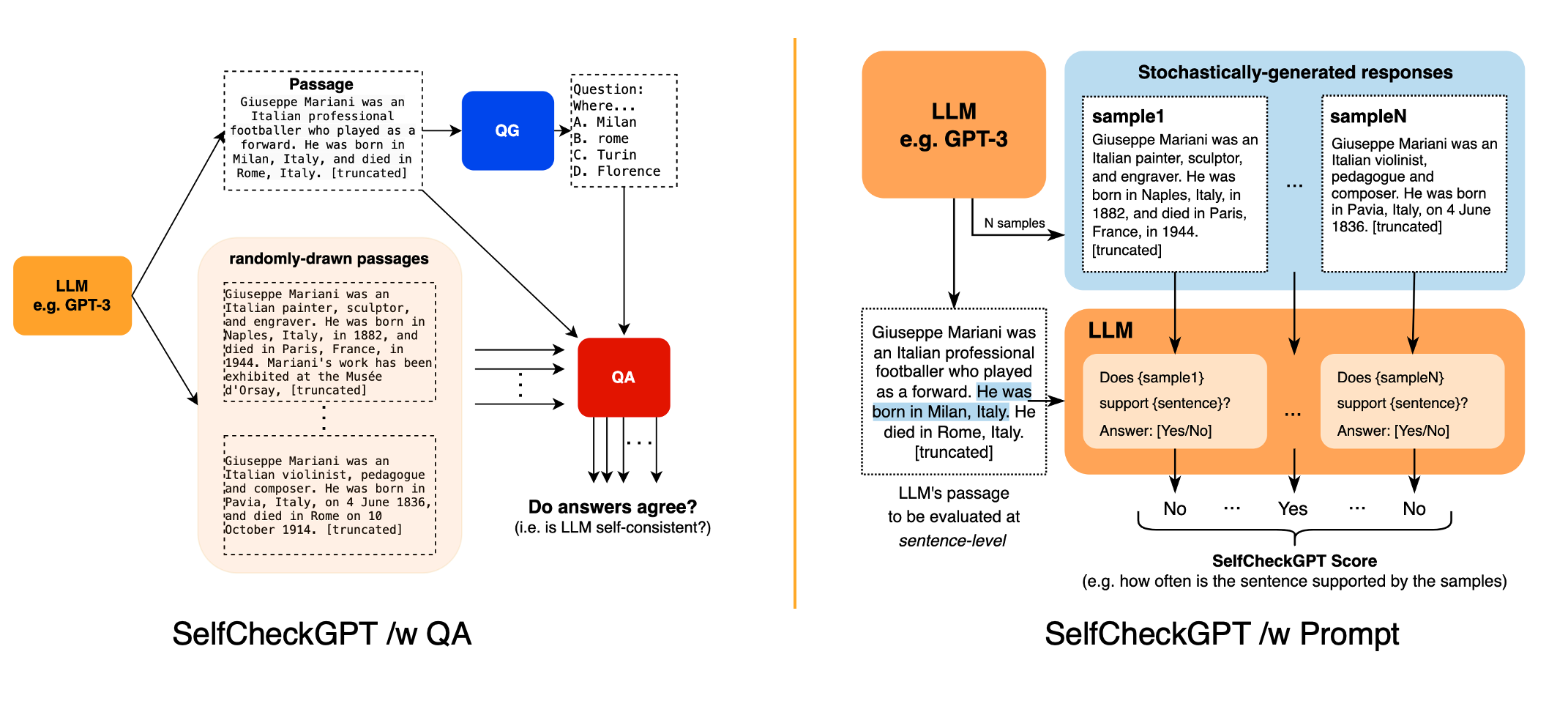
selfcheckgpt
SelfCheckGPT 是一个专门检测生成式大语言模型"幻觉"的开源工具。所谓"幻觉",就是 AI 在回答问题时可能生成看似合理但实际错误或无中生有的信息。这个工具最大的亮点是零资源和黑盒检测——既不需要外部知识库,也无需访问模型的内部参数,就能识别出哪些句子可能不靠谱。
它的工作原理很巧妙:让同一个模型对相同问题生成多个回答,通过检查这些回答之间的一致性来判断信息可信度。比如,如果多次回答都提到"迈克尔·韦纳出生于1942年3月31日",这个事实就很可能可靠;如果只出现一次,就需要打个问号。
SelfCheckGPT 提供了多种检测方法(包括问答、BERTScore、n-gram 等),能输出句子级别的可信度评分(0到1之间,分数越高越可能不真实)。工具已被 EMNLP 2023 会议接收,使用也非常简单,只需一行 pip 命令即可安装。
这个工具特别适合 AI 开发者和研究人员,帮助他们评估和提升大语言模型生成内容的准确性,构建更可靠的 AI 应用。
使用场景
某互联网医疗平台的AI团队正在开发智能问诊助手,基于GPT-4为患者提供常见疾病咨询和用药指导。每天有数千名患者提问,系统需要实时生成专业回答。
没有 selfcheckgpt 时
- 医生审核成为瓶颈:每份AI回答都必须由值班医生逐字审阅,高峰期积压严重,患者平均等待40分钟才能获得回复
- 幻觉风险难以防范:系统曾将"阿司匹林每日用量"错误写成"单次服用2g",直到患者投诉才发现,险些造成医疗事故
- 问题定位效率低下:当发现回答有误时,只能整段废弃重写,无法快速定位是"病因分析"还是"用药建议"部分出错
- 可信度无法量化:产品团队无法判断哪些回答可以高置信度直接推送,哪些必须强制人工介入,策略制定缺乏数据支撑
使用 selfcheckgpt 后
- 智能分层审核:SelfCheckMQAG自动为每个句子打分,仅将置信度低于0.3的句子标记给医生复核,审核工作量降低70%,患者等待时间缩短至12分钟
- 实时风险拦截:检测到"单次服用2g"这类异常表述时,系统自动触发二次验证流程,拦截高风险内容,上线后医疗投诉下降90%
- 精准定位修改:BERTScore版本精确定位到具体错误句子,医生只需修改"用药剂量"这一句,无需重写整个回答,单次修正时间从5分钟降至30秒
- 量化置信度策略:基于n-gram一致性评分,产品团队设定>0.8分的回答直接推送,0.5-0.8分加警示标签,<0.5分转人工,策略效果可测量可优化
selfcheckgpt让医疗AI在保障安全的前提下实现高效响应,将医生从重复审核中解放出来,专注于真正需要专业判断的复杂病例。
运行环境要求
- Linux
- macOS
- Windows
可选但强烈推荐,运行本地LLM模型需8GB+显存,CUDA 11.7+
未说明

快速开始
SelfCheckGPT
![]()
![]()

![]()
- 我们论文 "SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models" 的项目页面
- 我们研究了 selfcheck 方法的几种变体:BERTScore(基于BERT的相似度评分)、Question-Answering(问答)、n-gram(n元语法)、NLI(自然语言推理)和 LLM-Prompting(大语言模型提示)。
- [2023年11月] 感谢 Daniel Huynh 的 SelfCheckGPT-NLI 校准分析 [链接到文章]
- [2023年10月] 论文已被 EMNLP 2023 接收并即将发表 [海报]
- [2023年8月] ML Collective 演讲的幻灯片 [链接到幻灯片]
代码/包
安装
pip install selfcheckgpt
SelfCheckGPT 使用方法:BERTScore、QA、n-gram
本包中有三种 SelfCheck 分数变体,如论文所述:SelfCheckBERTScore()、SelfCheckMQAG()、SelfCheckNgram()。所有变体都有 predict() 方法,该方法会输出句子级别(sentence-level)的分数,用于衡量与采样段落(sampled passages)的一致性。您可以使用 spacy(一个自然语言处理库)等包将段落拆分为句子。为了可复现性(reproducibility),您可以在调用此函数前设置 torch.manual_seed。更多详情见 Jupyter Notebook(交互式笔记本)demo/SelfCheck_demo1.ipynb
# Include necessary packages (torch, spacy, ...)
from selfcheckgpt.modeling_selfcheck import SelfCheckMQAG, SelfCheckBERTScore, SelfCheckNgram
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
selfcheck_mqag = SelfCheckMQAG(device=device) # set device to 'cuda' if GPU is available
selfcheck_bertscore = SelfCheckBERTScore(rescale_with_baseline=True)
selfcheck_ngram = SelfCheckNgram(n=1) # n=1 means Unigram, n=2 means Bigram, etc.
# LLM's text (e.g. GPT-3 response) to be evaluated at the sentence level & Split it into sentences
passage = "Michael Alan Weiner (born March 31, 1942) is an American radio host. He is the host of The Savage Nation."
sentences = [sent.text.strip() for sent in nlp(passage).sents] # spacy sentence tokenization
print(sentences)
['Michael Alan Weiner (born March 31, 1942) is an American radio host.', 'He is the host of The Savage Nation.']
# Other samples generated by the same LLM to perform self-check for consistency
sample1 = "Michael Alan Weiner (born March 31, 1942) is an American radio host. He is the host of The Savage Country."
sample2 = "Michael Alan Weiner (born January 13, 1960) is a Canadian radio host. He works at The New York Times."
sample3 = "Michael Alan Weiner (born March 31, 1942) is an American radio host. He obtained his PhD from MIT."
# --------------------------------------------------------------------------------------------------------------- #
# SelfCheck-MQAG: Score for each sentence where value is in [0.0, 1.0] and high value means non-factual
# Additional params for each scoring_method:
# -> counting: AT (answerability threshold, i.e. questions with answerability_score < AT are rejected)
# -> bayes: AT, beta1, beta2
# -> bayes_with_alpha: beta1, beta2
sent_scores_mqag = selfcheck_mqag.predict(
sentences = sentences, # list of sentences
passage = passage, # passage (before sentence-split)
sampled_passages = [sample1, sample2, sample3], # list of sampled passages
num_questions_per_sent = 5, # number of questions to be drawn
scoring_method = 'bayes_with_alpha', # options = 'counting', 'bayes', 'bayes_with_alpha'
beta1 = 0.8, beta2 = 0.8, # additional params depending on scoring_method
)
print(sent_scores_mqag)
# [0.30990949 0.42376232]
# --------------------------------------------------------------------------------------------------------------- #
# SelfCheck-BERTScore: Score for each sentence where value is in [0.0, 1.0] and high value means non-factual
sent_scores_bertscore = selfcheck_bertscore.predict(
sentences = sentences, # list of sentences
sampled_passages = [sample1, sample2, sample3], # list of sampled passages
)
print(sent_scores_bertscore)
# [0.0695562 0.45590915]
# --------------------------------------------------------------------------------------------------------------- #
# SelfCheck-Ngram: Score at sentence- and document-level where value is in [0.0, +inf) and high value means non-factual
# as opposed to SelfCheck-MQAG and SelfCheck-BERTScore, SelfCheck-Ngram's score is not bounded
sent_scores_ngram = selfcheck_ngram.predict(
sentences = sentences,
passage = passage,
sampled_passages = [sample1, sample2, sample3],
)
print(sent_scores_ngram)
# {'sent_level': { # sentence-level score similar to MQAG and BERTScore variant
# 'avg_neg_logprob': [3.184312, 3.279774],
# 'max_neg_logprob': [3.476098, 4.574710]
# },
# 'doc_level': { # document-level score such that avg_neg_logprob is computed over all tokens
# 'avg_neg_logprob': 3.218678904916201,
# 'avg_max_neg_logprob': 4.025404834169327
# }
# }
SelfCheckGPT 使用方法:NLI(推荐)
以句子和采样段落作为输入的蕴含(Entailment)或矛盾(Contradiction)分数可以用作 selfcheck 分数。我们使用在 Multi-NLI(多体裁自然语言推理数据集)上微调的 DeBERTa-v3-large(一种预训练语言模型),对“蕴含”或“矛盾”类别的概率进行归一化(normalize),并将 Prob(contradiction) 作为分数。
from selfcheckgpt.modeling_selfcheck import SelfCheckNLI
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
selfcheck_nli = SelfCheckNLI(device=device) # set device to 'cuda' if GPU is available
sent_scores_nli = selfcheck_nli.predict(
sentences = sentences, # list of sentences
sampled_passages = [sample1, sample2, sample3], # list of sampled passages
)
print(sent_scores_nli)
# [0.334014 0.975106 ] -- based on the example above
SelfCheckGPT 使用方法:LLM 提示
提示 LLM(Llama2、Mistral、OpenAI 的 GPT)在 zero-shot(零样本)设置下评估信息一致性。我们查询 LLM 以评估第 i 个句子是否得到样本(作为上下文)的支持。与其他方法类似,分数越高表示越有可能是幻觉。下面是一个使用 Mistral 的示例:
# Option1: open-source model
from selfcheckgpt.modeling_selfcheck import SelfCheckLLMPrompt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
llm_model = "mistralai/Mistral-7B-Instruct-v0.2"
selfcheck_prompt = SelfCheckLLMPrompt(llm_model, device)
# Option2: API access
# (currently only support OpenAI and Groq)
# from selfcheckgpt.modeling_selfcheck_apiprompt import SelfCheckAPIPrompt
# selfcheck_prompt = SelfCheckAPIPrompt(client_type="openai", model="gpt-3.5-turbo")
# selfcheck_prompt = SelfCheckAPIPrompt(client_type="groq", model="llama3-70b-8192", api_key="your-api-key")
sent_scores_prompt = selfcheck_prompt.predict(
sentences = sentences, # list of sentences
sampled_passages = [sample1, sample2, sample3], # list of sampled passages
verbose = True, # whether to show a progress bar
)
print(sent_scores_prompt)
# [0.33333333, 0.66666667] -- based on the example above
LLM(大型语言模型)可以是 HuggingFace 上可用的任何模型。默认的 prompt template(提示模板)为 Context: {context}\n\nSentence: {sentence}\n\nIs the sentence supported by the context above? Answer Yes or No.\n\nAnswer: ,但您可以使用 selfcheck_prompt.set_prompt_template(new_prompt) 进行更改。
大多数模型(gpt-3.5-turbo、Llama2、Mistral)>95% 的时间会输出 'Yes' 或 'No',而任何剩余输出可设为 N/A。输出将转换为分数:Yes -> 0.0,No -> 1.0,N/A -> 0.5。inconsistency score(不一致性分数)随后通过取平均值计算得出。
数据集
wiki_bio_gpt3_hallucination 数据集目前包含 238 篇标注过的段落(v3)。您可以在论文中或我们的 HuggingFace 数据卡片上找到更多信息:https://huggingface.co/datasets/potsawee/wiki_bio_gpt3_hallucination。要使用此数据集,您可以通过 HuggingFace 数据集 API 加载,也可以直接从下方以 JSON 格式下载。
更新
我们进一步标注了 GPT-3 wikibio 段落,现在数据集包含 238 篇标注过的段落。以下是 v1 中前 65 篇段落的 ID 链接。
选项1:HuggingFace
from datasets import load_dataset
dataset = load_dataset("potsawee/wiki_bio_gpt3_hallucination")
选项2:手动下载
从我们的 Google Drive 下载,然后您可以在 Python 中加载:
import json
with open("dataset.json", "r") as f:
content = f.read()
dataset = json.loads(content)
每个实例包含:
gpt3_text:GPT-3 生成的段落wiki_bio_text:实际的 Wikipedia 段落(第一段)gpt3_sentences:使用spacy将gpt3_text拆分为句子annotation:句子级别的人工标注wiki_bio_test_idx:来自原始 wikibio 数据集(测试集)的概念/个体 IDgpt3_text_samples:采样段落列表(do_sample = True & temperature = 1.0)
实验
基于概率的基线方法(例如 GPT-3 的概率)
如我们的论文所述,生成式 LLM 的概率(和生成熵)可用于衡量其置信度。请查看我们在 demo/experiments/probability-based-baselines.ipynb 中的示例/实现。
实验结果
- 完整细节可在我们的论文中找到。
- 请注意,我们的新结果表明,LLM(如 GPT-3 (text-davinci-003) 或 ChatGPT (gpt-3.5-turbo))擅长文本不一致性评估。基于这一发现,我们尝试了 SelfCheckGPT-Prompt,其中每个待评估的句子都与每个 sampled_passage 进行比较,通过提示 ChatGPT 完成。SelfCheckGPT-Prompt 是表现最佳的方法。
在 wiki_bio_gpt3_hallucination 数据集上的结果。
| 方法 | 非事实 (AUC-PR) | 事实 (AUC-PR) | 排序 (PCC) |
|---|---|---|---|
| 随机猜测 | 72.96 | 27.04 | - |
| GPT-3 Avg(-logP) | 83.21 | 53.97 | 57.04 |
| SelfCheck-BERTScore | 81.96 | 44.23 | 58.18 |
| SelfCheck-QA | 84.26 | 48.14 | 61.07 |
| SelfCheck-Unigram | 85.63 | 58.47 | 64.71 |
| SelfCheck-NLI | 92.50 | 66.08 | 74.14 |
| SelfCheck-Prompt (Llama2-7B-chat) | 89.05 | 63.06 | 61.52 |
| SelfCheck-Prompt (Llama2-13B-chat) | 91.91 | 64.34 | 75.44 |
| SelfCheck-Prompt (Mistral-7B-Instruct-v0.2) | 91.31 | 62.76 | 74.46 |
| SelfCheck-Prompt (gpt-3.5-turbo) | 93.42 | 67.09 | 78.32 |
其他
MQAG(多项选择题问答与生成) 在我们之前的工作中提出。我们的 MQAG 实现包含在此包中,可用于:(1) 生成多项选择题,(2) 回答多项选择题,(3) 获取 MQAG 分数。
MQAG 用法
from selfcheckgpt.modeling_mqag import MQAG
mqag_model = MQAG()
它有三个主要功能:generate()、answer()、score()。我们在 demo/MQAG_demo1.ipynb 中展示了示例用法。
致谢
本工作由剑桥大学出版社与考评部(Cambridge University Press & Assessment, CUP&A)——剑桥大学的一个部门,以及剑桥英联邦、欧洲与国际信托基金支持。
引用
@article{manakul2023selfcheckgpt,
title={Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models},
author={Manakul, Potsawee and Liusie, Adian and Gales, Mark JF},
journal={arXiv preprint arXiv:2303.08896},
year={2023}
}
版本历史
0.1.72024/03/100.1.62024/02/060.1.42023/07/180.1.32023/05/250.1.22023/03/230.1.12023/03/22常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。