dlwin
dlwin 是一套专为 Windows 10 打造的深度学习环境搭建指南,帮助用户在原生系统中实现高效的 GPU 加速深度学习体验。以往在 Windows 上配置深度学习往往面临依赖复杂、环境冲突等问题,许多教程建议通过虚拟机或 Docker 解决,但这会增加资源消耗并降低性能。dlwin 摒弃了这些间接方案,提供了一套无需额外安装 MinGW、直接基于 Windows 原生的集成环境。
它兼容 Keras、TensorFlow、CNTK、MXNet 和 PyTorch 五大主流框架,并支持多种 Keras 后端组合。对于必须在 Windows 环境下工作的开发者及研究人员,dlwin 简化了从 Visual Studio、CUDA 到各类 Python 库的配置流程,确保模型训练和实验能直接在本地 GPU 上流畅运行,无需切换操作系统即可享受强大的计算能力。
使用场景
一名在 Windows 笔记本上开发图像识别算法的独立开发者,急需快速验证模型效果,但苦于硬件环境配置繁琐。
没有 dlwin 时
- 必须安装 Ubuntu 虚拟机或 Docker 容器才能运行 TensorFlow GPU 版本,占用大量系统资源且启动缓慢。
- 手动配置 CUDA、cuDNN 与 Python 版本的兼容性极差,经常因依赖冲突报错,导致数小时调试无果。
- 训练过程仅能使用 CPU,模型收敛速度慢,迭代一次实验往往需要耗费数天时间。
- 缺乏针对 Windows 原生的优化指南,网上教程多为过时信息,难以适配最新框架版本。
使用 dlwin 后
- 直接在 Windows 原生系统下通过脚本一键配置 Keras、TensorFlow、PyTorch 等主流框架的 GPU 加速环境。
- 内置 Anaconda 环境管理方案,无需单独安装 MinGW,解决了复杂的依赖冲突问题。
- 充分利用本地显卡算力,模型训练效率显著提升,当天即可完成多轮实验验证与调优。
- 支持 CNTK、MXNet 等多种后端选择,灵活适配不同项目需求,不再受限于单一框架。
dlwin 彻底消除了 Windows 平台进行深度学习的门槛,让用户无需切换操作系统即可享受高效的 GPU 计算能力。
运行环境要求
- Windows
需要 NVIDIA GPU,测试型号为 Titan X (12GB) 或 GTX 1080 Ti (11GB),要求 CUDA 9.0.176 及 cuDNN v7.0.4
测试环境 64GB,最低需求未说明

快速开始
GPU-accelerated Deep Learning on Windows 10 native (Keras/Tensorflow/CNTK/MXNet and PyTorch)
>> 最后更新于 2018 年 6 月 <<
此次最新更新:
- 支持 5 个框架(Keras/Tensorflow/CNTK/MXNet 和 PyTorch),
- 支持 3 种 GPU 加速的 Keras 后端(CNTK、Tensorflow 或 MXNet),
- 无需单独安装 MinGW,
- 使用更新版本的许多 Python 库。
当然有很多指南可以帮助你构建基于 Linux 或 Mac OS 的强大深度学习 (DL) 设置(包括 Tensorflow,遗憾的是,截至本文发布时,它还不能在 Windows 上轻松安装),但很少有人关心构建高效的 Windows 10-原生设置。大多数关注点在运行托管在 Windows 上的 Ubuntu 虚拟机 (VM) 或使用 Docker,这些都是不必要且最终不够理想的步骤。
我们也发现网上有足够多的误导性/过时信息,值得为最新稳定版本的 Keras、Tensorflow、CNTK、MXNet 和 PyTorch 整理一份分步指南。无论是组合使用(例如,Keras 搭配 Tensorflow 后端),还是独立使用——PyTorch 不能作为 Keras 后端,TensorFlow 可以独立使用——它们都是能够在 Windows 上原生运行的最强大的深度学习 Python 库之一。
如果你必须在 Windows 10 上运行你的 DL 设置,那么这里包含的信息希望能对你有所帮助。
来自 2017 年 7 月、2017 年 5 月 和 2017 年 1 月 的旧安装说明仍然可用。它们允许你将 Theano 用作 Keras 后端。
TOC
依赖项
以下是我们在 Windows 10 上进行深度学习所使用的工具和库的总结列表(版本 1709 OS Build 16299.371):
- Visual Studio 2015 Community Edition Update 3 带 Windows Kit 10.0.10240.0
- 用于其 C/C++ 编译器(而非其集成开发环境 IDE)和软件开发工具包 (SDK)。选择此特定版本是因为 CUDA 中的 Windows 编译器支持。
- Anaconda (64-bit) 带 Python 3.6 (Anaconda3-5.2.0) [用于 Tensorflow 支持] 或 Python 2.7 (Anaconda2-5.2.0) [无 Tensorflow 支持] 带 MKL 2018.0.3
- 一个提供 NumPy、SciPy 和其他科学库的 Python 发行版
- MKL 用于其针对 CPU 优化的许多线性代数运算实现
- CUDA 9.0.176 (64-bit)
- 用于其 GPU 数学库、显卡驱动和 CUDA 编译器
- cuDNN v7.0.4 (Nov 13, 2017) for CUDA 9.0.176
- 用于运行速度大幅加快的卷积神经网络
- Keras 2.1.6 带三种不同的后端:Tensorflow-gpu 1.8.0, CNTK-gpu 2.5.1, 和 MXNet-cuda90 1.2.0
- Keras 用于在 Tensorflow 或 CNTK 之上进行深度学习
- Tensorflow 和 CNTK 是用于在多维数组上评估数学表达式的后端
- Theano 是一个不再积极开发的遗留后端
- PyTorch v0.4.0
硬件
- Dell Precision T7900, 64GB RAM
- Intel Xeon E5-2630 v4 @ 2.20 GHz (1 个处理器,共 10 核,20 个逻辑处理器)
- NVIDIA GeForce Titan X, 12GB RAM
- 驱动版本:390.77 / Win 10 64
- NVIDIA GeForce GTX 1080 Ti, 11GB RAM
- 驱动版本:390.77 / Win 10 64
安装步骤
我们喜欢将我们的工具包和库保存在一个简单命名为 e:\toolkits.win 的单根文件夹中,因此每当你在下面看到以 e:\toolkits.win 开头的 Windows 路径时,请确保将其替换为你决定自己的工具包驱动器和文件夹应该是什么。
工具包
Visual Studio 2015 社区版更新 3 配合 Windows Kit 10.0.10240.0
下载 Visual Studio Community 2015 with Update 3 (x86)。它被 CUDA Toolkit (CUDA 工具包) 使用。
注意,下载需要免费的 Visual Studio Dev Essentials 许可证或完整的 Visual Studio 订阅。
运行下载的 exe 文件以安装 Visual Studio,使用最适合您的其他配置设置:
- 根据您安装 VS 2015 的位置,将
C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin添加到您的PATH环境变量中。 - 定义系统环境变量 (sysenv)
INCLUDE,值为C:\Program Files (x86)\Windows Kits\10\Include\10.0.10240.0\ucrt - 定义系统环境变量 (sysenv)
LIB,值为C:\Program Files (x86)\Windows Kits\10\Lib\10.0.10240.0\um\x64;C:\Program Files (x86)\Windows Kits\10\Lib\10.0.10240.0\ucrt\x64
参考说明:在添加上述最后两个环境变量之前,我们无法运行任何 Theano Python 文件。编译时会收到
c:\program files (x86)\microsoft visual studio 14.0\vc\include\crtdefs.h(10): fatal error C1083: Cannot open include file: 'corecrt.h': No such file or directory错误,链接时会出现缺少kernel32.lib uuid.lib ucrt.lib的错误。确实,每次打开 MINGW 命令提示符时,您可能可以运行C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin\amd64\vcvars64.bat(带正确的参数),但显然,这些系统环境变量无法在一次会话到下一次会话之间保持。
Anaconda 5.2.0 (64 位) (Python 3.6 支持 TensorFlow (TF) / Python 2.7 不支持 TensorFlow (TF))
本教程最初是使用 Python 2.7 创建的。由于 TensorFlow (张量流) 已成为 Keras 的首选后端,我们决定默认记录使用 Python 3.6 的安装步骤。根据您的偏好配置,使用 e:\toolkits.win\anaconda3-5.2.0 或 e:\toolkits.win\anaconda2-5.2.0 作为安装 Anaconda 的文件夹。
从 此处 下载 Python 3.6 Anaconda 版本,从 那里 下载 Python 2.7 版本:
运行下载的 exe 文件以安装 Anaconda:
警告:下面,我们启用了“高级选项 (Advanced Options)"中的第二个选项,因为它对我们有效,但这可能不是对您最好的选择!
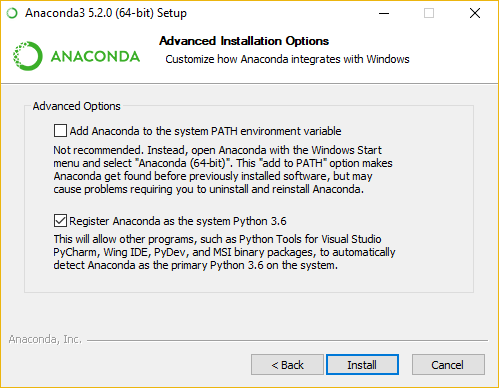
定义以下变量并按如下所示更新 PATH:
- 定义系统环境变量 (sysenv)
PYTHON_HOME,值为e:\toolkits.win\anaconda3-5.2.0 - 将
%PYTHON_HOME%,%PYTHON_HOME%\Scripts, 和%PYTHON_HOME%\Library\bin添加到PATH
创建 dlwin36 conda 环境
安装 Anaconda 后,打开 Windows 命令提示符并执行:
$ conda create --yes -n dlwin36 numpy scipy mkl-service m2w64-toolchain libpython matplotlib pandas scikit-learn tqdm jupyter h5py cython
以下是上述命令的 输出日志。
接下来,使用 activate dlwin36 激活此新环境。顺便说一下,如果您已经有旧的 dlwin36 环境,可以使用 conda env remove -n dlwin36 删除它。
可选但强烈推荐图像处理库
如果我们打算使用 GPU (图形处理器),为什么我们要安装像 MKL (数学核心库) 这样的 CPU (中央处理器) 优化的线性代数库?在我们的设置中,大多数深度学习 (Deep Learning) 的繁重工作是由 GPU 执行的,这是正确的,但 CPU 并非闲置。基于图像的 Kaggle 竞赛的一个重要部分是数据增强 (Data Augmentation)。在此背景下,数据增强是通过使用图像处理算子,对原始训练样本进行变换来制造额外的输入样本(更多训练图像)的过程。也需要基本的变换,如下采样 (downsampling) 和(均值中心化)归一化 (normalization)。如果您喜欢冒险,您将想要尝试额外的预处理增强(去噪、直方图均衡化等)。当然,您可以为此目的使用 GPU 并将结果保存到文件。然而,在实践中,当 GPU 忙于学习深度神经网络的权重时,这些操作通常是在 CPU 上并行执行的,并且增强后的数据在使用后会被丢弃。
如果您的深度学习项目是基于图像的,我们还建议安装以下库:
scikit-image: 用于 Python 编程语言的开源图像处理库,包括分割、几何变换、颜色空间操作、分析、滤波、形态学、特征检测等的算法。有关更多信息,请参见 此页面。opencv: 主要针对实时计算机视觉的编程函数库。它具有 C++、Python 和 Java 接口,并支持许多操作系统平台,包括 Windows。有关附加信息,请参见 此页面。imgaug: 基于图像的 Kaggle 竞赛的必备品,这个 Python 库通过将一组输入图像转换为一组新的、大得多的略有不同的图像,帮助您为机器学习项目增强图像。有关详细信息,请参见 此页面。
要安装这些库,请使用以下命令:
$ activate dlwin36
(dlwin36) $conda install --yes pillow scikit-image
(dlwin36) $conda install --yes -c conda-forge opencv
(dlwin36) $pip install git+https://github.com/aleju/imgaug
以下是上述命令的 输出日志。
CUDA 9.0.176 (64 位)
从 NVIDIA 网站 下载 CUDA 9.0.176 (64 位)
为什么不安装 CUDA 9.1?很简单,截至本文撰写时,TensorFlow 1.8 仍然使用 CUDA 9.0(参见问题 #15140)。
选择正确的目标平台:
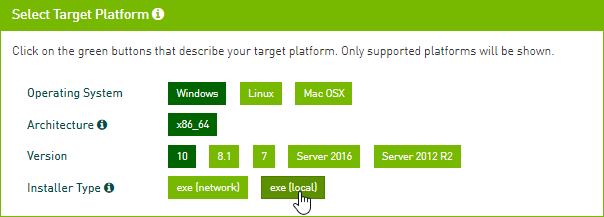
下载所有安装程序:

依次运行下载的安装程序。将文件安装到 e:\toolkits.win\cuda-9.0.176:
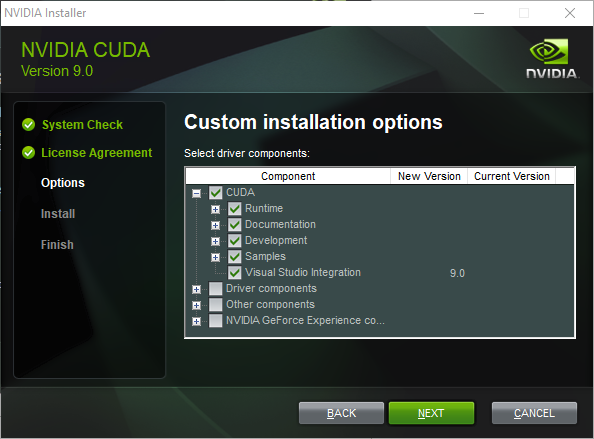
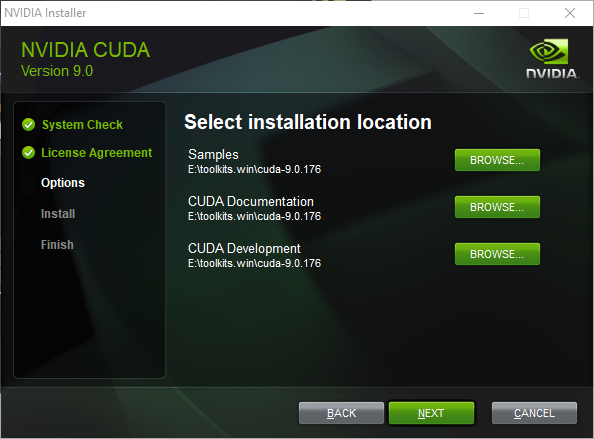
完成后,安装程序应已创建一个名为 CUDA_PATH 的系统环境变量 (sysenv),并将 %CUDA_PATH%\bin 以及 %CUDA_PATH%\libnvvp 添加到 PATH 中。请检查是否确实如此。如果由于某些原因缺少 CUDA 环境变量,则:
- 定义一个名为
CUDA_PATH的系统环境变量 (sysenv),值为e:\toolkits.win\cuda-9.0.176 - 将
%CUDA_PATH%\bin和%CUDA_PATH%\libnvvp添加到PATH中
cuDNN v7.0.4 (2017 年 11 月 13 日) 适用于 CUDA 9.0
根据 NVIDIA 的 网站,"cuDNN 为标准例程提供了高度优化的实现,例如前向和后向卷积、池化、归一化和激活层”,这些是卷积网络架构的标志。从 此处 下载 cuDNN。选择与 CUDA 版本匹配的 Windows 10 cuDNN 库:
NVIDIA 最近移除了 7.0.4 Windows 下载的选项。您可以在此处下载它 链接。
下载的 ZIP 文件包含三个目录(bin、include、lib)。提取并复制它们的内容到 %CUDA_PATH% 下同名的 bin、include 和 lib 目录中。
深度学习 Python 库
安装 keras 2.1.6
为什么不直接安装 Keras 和各种后端(TensorFlow、CNTK 或 Theano)的最新前沿/开发版本呢?简而言之,因为这会让 可重复研究 变得更困难。如果您的同事或 Kaggle 队友在不同的时间从开发分支安装了最新代码,那么您的机器上运行的代码库很可能不同,这增加了即使您使用相同的输入数据(相同的随机种子等),最终结果却不同的可能性,而这本不应该发生。仅凭这一点,我们就强烈建议只使用特定版本(point releases),并在不同机器上使用同一版本,如果您无法直接使用安装脚本,请务必记录所使用的版本。
按如下方式安装 Keras:
(dlwin36) $$ pip install keras==2.1.6
$ pip install keras==2.1.6
Collecting keras==2.1.6
Using cached https://files.pythonhosted.org/packages/54/e8/eaff7a09349ae9bd40d3ebaf028b49f5e2392c771f294910f75bb608b241/Keras-2.1.6-py2.py3-none-any.whl
Requirement already satisfied: numpy>=1.9.1 in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from keras==2.1.6) (1.14.5)
Requirement already satisfied: scipy>=0.14 in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from keras==2.1.6) (1.1.0)
Requirement already satisfied: h5py in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from keras==2.1.6) (2.8.0)
Requirement already satisfied: pyyaml in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from keras==2.1.6) (3.12)
Requirement already satisfied: six>=1.9.0 in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from keras==2.1.6) (1.11.0)
distributed 1.22.0 requires msgpack, which is not installed.
Installing collected packages: keras
Successfully installed keras-2.1.6
安装 tensorflow-gpu 1.8.0(独立安装,或作为 Keras 后端)
运行以下命令以安装 TensorFlow:
$ pip install tensorflow-gpu==1.8.0
Collecting tensorflow-gpu==1.8.0
Using cached https://files.pythonhosted.org/packages/42/a8/4c96a2b4f88f5d6dfd70313ebf38de1fe4d49ba9bf2ef34dc12dd198ab9a/tensorflow_gpu-1.8.0-cp36-cp36m-win_amd64.whl
Requirement already satisfied: six>=1.10.0 in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from tensorflow-gpu==1.8.0) (1.11.0)
Collecting grpcio>=1.8.6 (from tensorflow-gpu==1.8.0)
Downloading https://files.pythonhosted.org/packages/5d/8b/104918993129d6c919a16826e6adcfa4a106c791da79fb9655c5b22ad9ff/grpcio-1.12.1-cp36-cp36m-win_amd64.whl (1.4MB)
100% |████████████████████████████████| 1.4MB 6.6MB/s
Collecting gast>=0.2.0 (from tensorflow-gpu==1.8.0)
Collecting tensorboard<1.9.0,>=1.8.0 (from tensorflow-gpu==1.8.0)
Using cached https://files.pythonhosted.org/packages/59/a6/0ae6092b7542cfedba6b2a1c9b8dceaf278238c39484f3ba03b03f07803c/tensorboard-1.8.0-py3-none-any.whl
Requirement already satisfied: wheel>=0.26 in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from tensorflow-gpu==1.8.0) (0.31.1)
Collecting termcolor>=1.1.0 (from tensorflow-gpu==1.8.0)
Requirement already satisfied: numpy>=1.13.3 in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from tensorflow-gpu==1.8.0) (1.14.5)
Collecting protobuf>=3.4.0 (from tensorflow-gpu==1.8.0)
Downloading https://files.pythonhosted.org/packages/75/7a/0dba607e50b97f6a89fa3f96e23bf56922fa59d748238b30507bfe361bbc/protobuf-3.6.0-cp36-cp36m-win_amd64.whl (1.1MB)
100% |████████████████████████████████| 1.1MB 6.6MB/s
Collecting absl-py>=0.1.6 (from tensorflow-gpu==1.8.0)
Downloading https://files.pythonhosted.org/packages/57/8d/6664518f9b6ced0aa41cf50b989740909261d4c212557400c48e5cda0804/absl-py-0.2.2.tar.gz (82kB)
100% |████████████████████████████████| 92kB 5.9MB/s
Collecting astor>=0.6.0 (from tensorflow-gpu==1.8.0)
Using cached https://files.pythonhosted.org/packages/b2/91/cc9805f1ff7b49f620136b3a7ca26f6a1be2ed424606804b0fbcf499f712/astor-0.6.2-py2.py3-none-any.whl
Collecting html5lib==0.9999999 (from tensorboard<1.9.0,>=1.8.0->tensorflow-gpu==1.8.0)
Collecting werkzeug>=0.11.10 (from tensorboard<1.9.0,>=1.8.0->tensorflow-gpu==1.8.0)
Using cached https://files.pythonhosted.org/packages/20/c4/12e3e56473e52375aa29c4764e70d1b8f3efa6682bef8d0aae04fe335243/Werkzeug-0.14.1-py2.py3-none-any.whl
Collecting bleach==1.5.0 (from tensorboard<1.9.0,>=1.8.0->tensorflow-gpu==1.8.0)
Using cached https://files.pythonhosted.org/packages/33/70/86c5fec937ea4964184d4d6c4f0b9551564f821e1c3575907639036d9b90/bleach-1.5.0-py2.py3-none-any.whl
Collecting markdown>=2.6.8 (from tensorboard<1.9.0,>=1.8.0->tensorflow-gpu==1.8.0)
Using cached https://files.pythonhosted.org/packages/6d/7d/488b90f470b96531a3f5788cf12a93332f543dbab13c423a5e7ce96a0493/Markdown-2.6.11-py2.py3-none-any.whl
Requirement already satisfied: setuptools in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from protobuf>=3.4.0->tensorflow-gpu==1.8.0) (39.2.0)
Building wheels for collected packages: absl-py
Running setup.py bdist_wheel for absl-py ... done
Stored in directory: C:\Users\Phil\AppData\Local\pip\Cache\wheels\a0\f8\e9\1933dbb3447ea6ef557062fd5461cb118deb8c2ed074e8344bf
Successfully built absl-py
distributed 1.22.0 requires msgpack, which is not installed.
Installing collected packages: grpcio, gast, html5lib, werkzeug, bleach, markdown, protobuf, tensorboard, termcolor, absl-py, astor, tensorflow-gpu
Found existing installation: html5lib 1.0.1
Uninstalling html5lib-1.0.1:
Successfully uninstalled html5lib-1.0.1
Found existing installation: bleach 2.1.3
Uninstalling bleach-2.1.3:
Successfully uninstalled bleach-2.1.3
Successfully installed absl-py-0.2.2 astor-0.6.2 bleach-1.5.0 gast-0.2.0 grpcio-1.12.1 html5lib-0.9999999 markdown-2.6.11 protobuf-3.6.0 tensorboard-1.8.0 tensorflow-gpu-1.8.0 termcolor-1.1.0 werkzeug-0.14.1
如果您希望 TensorFlow 成为默认的 Keras 后端,请定义一个名为 KERAS_BACKEND 的系统环境变量,并将其值设置为 tensorflow。
安装 cntk-gpu 2.5.1(独立安装,或作为 Keras 后端)
根据 此链接 中的文档,按如下方式安装 CNTK(认知工具包)GPU:
(dlwin36) $ pip install https://cntk.ai/PythonWheel/GPU/cntk_gpu-2.5.1-cp36-cp36m-win_amd64.whl
Collecting cntk-gpu==2.5.1 from https://cntk.ai/PythonWheel/GPU/cntk_gpu-2.5.1-cp36-cp36m-win_amd64.whl
Downloading https://cntk.ai/PythonWheel/GPU/cntk_gpu-2.5.1-cp36-cp36m-win_amd64.whl (428.6MB)
100% |████████████████████████████████| 428.6MB 53kB/s
Requirement already satisfied: scipy>=0.17 in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from cntk-gpu==2.5.1) (1.1.0)
Requirement already satisfied: numpy>=1.11 in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from cntk-gpu==2.5.1) (1.14.5)
distributed 1.22.0 requires msgpack, which is not installed.
Installing collected packages: cntk-gpu
Successfully installed cntk-gpu-2.5.1
如果您希望 CNTK 成为默认的 Keras 后端,请定义一个名为 KERAS_BACKEND 的系统环境变量,并将其值设置为 cntk。
安装 mxnet-cu90 1.2.0(独立使用,或作为 Keras 后端)
MXNet 是一个深度学习框架,得到了亚马逊(通过 AWS)的强力支持。它也在 Azure 上得到微软的支持。要安装它,请运行以下命令:
(dlwin36) $ pip install mxnet-cu90==1.2.0 keras-mxnet==2.1.6.1
Collecting mxnet-cu90==1.2.0
Downloading https://files.pythonhosted.org/packages/72/a8/9226bd6913b7ba4657a218b9a252b60de98938dd41e8517a0b4ab4291203/mxnet_cu90-1.2.0-py2.py3-none-win_amd64.whl (457.0MB)
100% |████████████████████████████████| 457.0MB 47kB/s
Requirement already satisfied: numpy in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from mxnet-cu90==1.2.0) (1.14.5)
Requirement already satisfied: graphviz in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from mxnet-cu90==1.2.0) (0.8.3)
Collecting keras-mxnet==2.1.6.1
Downloading https://files.pythonhosted.org/packages/99/93/13ec18147fcef7c393e3fbf2d2c20171975be14e68d4c915b194be174ab6/keras_mxnet-2.1.6.1-py2.py3-none-any.whl (388kB)
100% |████████████████████████████████| 389kB 3.3MB/s
Collecting requests (from mxnet-cu90==1.2.0)
Downloading https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl (91kB)
100% |████████████████████████████████| 92kB 1.2MB/s
Collecting urllib3<1.24,>=1.21.1 (from requests->mxnet-cu90==1.2.0)
Downloading https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c53851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl (133kB)
100% |████████████████████████████████| 143kB 2.2MB/s
Collecting chardet<3.1.0,>=3.0.2 (from requests->mxnet-cu90==1.2.0)
Downloading https://files.pythonhosted.org/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca55ec7510b22e4c51f14098443b8/chardet-3.0.4-py2.py3-none-any.whl (133kB)
100% |████████████████████████████████| 143kB 2.2MB/s
Requirement already satisfied: certifi>=2017.4.17 in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from requests->mxnet-cu90==1.2.0) (2018.4.16)
Collecting idna<2.8,>=2.5 (from requests->mxnet-cu90==1.2.0)
Downloading https://files.pythonhosted.org/packages/4b/2a/0276479a4b3caeb8a8c1af2f8e4355746a97fab05a372e4a2c6a6b876165/idna-2.7-py2.py3-none-any.whl (58kB)
100% |████████████████████████████████| 61kB 3.9MB/s
distributed 1.22.0 requires msgpack, which is not installed.
Installing collected packages: urllib3, chardet, idna, requests, mxnet-cu90
Successfully installed chardet-3.0.4 idna-2.7 mxnet-cu90-1.2.0 requests-2.19.1 urllib3-1.23
如果您希望 MXNet 成为默认的 Keras 后端,请定义一个名为 KERAS_BACKEND 的系统环境变量,值为 mxnet。
安装 pytorch 0.4.0
PyTorch 是 Facebook AI Research (FAIR) 针对 Google 的 Tensorflow 提出的解决方案。仅 v0.4.0 版本才正式支持 Windows (x64)。配置需要安装 pytorch、cuda90 和 torchvision,因此,首先运行以下命令:
(dlwin36) $ conda install --yes pytorch==0.4.0 cuda90 -c pytorch
Solving environment: done
## Package Plan ##
environment location: e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36
added / updated specs:
- cuda90
- pytorch==0.4.0
The following packages will be downloaded:
package | build
---------------------------|-----------------
cuda90-1.0 | 0 2 KB pytorch
certifi-2018.4.16 | py36_0 143 KB
pytorch-0.4.0 |py36_cuda90_cudnn7he774522_1 577.6 MB pytorch
------------------------------------------------------------
Total: 577.7 MB
The following NEW packages will be INSTALLED:
cffi: 1.11.5-py36h945400d_0
cuda90: 1.0-0 pytorch
pycparser: 2.18-py36hd053e01_1
pytorch: 0.4.0-py36_cuda90_cudnn7he774522_1 pytorch [cuda90]
The following packages will be UPDATED:
certifi: 2018.4.16-py36_0 conda-forge --> 2018.4.16-py36_0
Downloading and Extracting Packages
cuda90-1.0 | 2 KB | ############################################################################## | 100%
certifi-2018.4.16 | 143 KB | ############################################################################## | 100%
pytorch-0.4.0 | 577.6 MB | ############################################################################# | 100%
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
其次,使用此命令安装 torchvision:
(dlwin36torch) $ pip install torchvision==0.2.1
Collecting torchvision==0.2.1
Using cached https://files.pythonhosted.org/packages/ca/0d/f00b2885711e08bd71242ebe7b96561e6f6d01fdb4b9dcf4d37e2e13c5e1/torchvision-0.2.1-py2.py3-none-any.whl
Requirement already satisfied: numpy in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from torchvision==0.2.1) (1.14.5)
Requirement already satisfied: pillow>=4.1.1 in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from torchvision==0.2.1) (5.1.0)
Requirement already satisfied: six in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from torchvision==0.2.1) (1.11.0)
Requirement already satisfied: torch in e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages (from torchvision==0.2.1) (0.4.0)
distributed 1.22.0 requires msgpack, which is not installed.
Installing collected packages: torchvision
Successfully installed torchvision-0.2.1
如果在 Windows 上使用 PyTorch 遇到问题,我强烈建议阅读他们的 Windows FAQ。
快速检查
检查已安装的 Python 库列表
在您的 dlwin36 conda 环境中,您应该最终获得以下库列表:
(dlwin36) $ conda list
# packages in environment at e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36:
#
包名 版本 构建 通道
absl-py 0.2.2
blas 1.0 mkl
bleach 1.5.0
bokeh 0.12.16 py36_0
ca-certificates 2018.4.16 0 conda-forge
certifi 2018.4.16 py36_0
cffi 1.11.5 py36h945400d_0
chardet 3.0.4
cloudpickle 0.5.3 py36_0
cntk-gpu 2.5.1
cuda90 1.0 0 pytorch
cycler 0.10.0 py36h009560c_0
cython 0.28.3 py36hfa6e2cd_0
cytoolz 0.9.0.1 py36hfa6e2cd_0
dask 0.18.0 py36_0
dask-core 0.18.0 py36_0
decorator 4.3.0 py36_0
distributed 1.22.0 py36_0
entrypoints 0.2.3 py36hfd66bb0_2
freetype 2.8.1 vc14_0 [vc14] conda-forge
gast 0.2.0
hdf5 1.10.2 vc14_0 [vc14] conda-forge
heapdict 1.0.0 py36_2
html5lib 1.0.1 py36h047fa9f_0
html5lib 0.9999999
icu 58.2 vc14_0 [vc14] conda-forge
idna 2.7
imgaug 0.2.5
ipykernel 4.8.2 py36_0
ipython 6.4.0 py36_0
ipython_genutils 0.2.0 py36h3c5d0ee_0
ipywidgets 7.2.1 py36_0
jedi 0.12.0 py36_1
jinja2 2.10 py36h292fed1_0
jpeg 9b vc14_2 [vc14] conda-forge
jsonschema 2.6.0 py36h7636477_0
jupyter 1.0.0 py36_4
jupyter_client 5.2.3 py36_0
jupyter_console 5.2.0 py36h6d89b47_1
jupyter_core 4.4.0 py36h56e9d50_0
Keras 2.1.6
libpng 1.6.34 vc14_0 [vc14] conda-forge
libpython 2.1 py36_0
libsodium 1.0.16 vc14_0 [vc14] conda-forge
libtiff 4.0.9 vc14_0 [vc14] conda-forge
libwebp 0.5.2 vc14_7 [vc14] conda-forge
locket 0.2.0 py36hfed976d_1
m2w64-binutils 2.25.1 5
m2w64-bzip2 1.0.6 6
m2w64-crt-git 5.0.0.4636.2595836 2
m2w64-gcc 5.3.0 6
m2w64-gcc-ada 5.3.0 6
m2w64-gcc-fortran 5.3.0 6
m2w64-gcc-libgfortran 5.3.0 6
m2w64-gcc-libs 5.3.0 7
m2w64-gcc-libs-core 5.3.0 7
m2w64-gcc-objc 5.3.0 6
m2w64-gmp 6.1.0 2
m2w64-headers-git 5.0.0.4636.c0ad18a 2
m2w64-isl 0.16.1 2
m2w64-libiconv 1.14 6
m2w64-libmangle-git 5.0.0.4509.2e5a9a2 2
m2w64-libwinpthread-git 5.0.0.4634.697f757 2
m2w64-make 4.1.2351.a80a8b8 2
m2w64-mpc 1.0.3 3
m2w64-mpfr 3.1.4 4
m2w64-pkg-config 0.29.1 2
m2w64-toolchain 5.3.0 7
m2w64-tools-git 5.0.0.4592.90b8472 2
m2w64-windows-default-manifest 6.4 3
m2w64-winpthreads-git 5.0.0.4634.697f757 2
m2w64-zlib 1.2.8 10
Markdown 2.6.11
matplotlib 2.2.2 py36_1 conda-forge
mistune 0.8.3 py36hfa6e2cd_1
mkl 2018.0.3 1
mkl-service 1.1.2 py36h57e144c_4
mkl_fft 1.0.1 py36h452e1ab_0
mkl_random 1.0.1 py36h9258bd6_0
msgpack-python 0.5.6 py36he980bc4_0
msys2-conda-epoch 20160418 1
mxnet-cu90 1.2.0
nbformat 4.4.0 py36h3a5bc1b_0
networkx 2.1 py36_0
notebook 5.5.0 py36_0
numpy 1.14.5 py36h9fa60d3_0
numpy-base 1.14.5 py36h5c71026_0
olefile 0.45.1 py36_0
opencv 3.4.1 py36_200 conda-forge
openssl 1.0.2o vc14_0 [vc14] conda-forge
packaging 17.1 py36_0
pandas 0.23.1 py36h830ac7b_0
pandoc 1.19.2.1 hb2460c7_1
pandocfilters 1.4.2 py36h3ef6317_1
parso 0.2.1 py36_0
partd 0.3.8 py36hc8e763b_0
pickleshare 0.7.4 py36h9de030f_0
pillow 5.1.0 py36h0738816_0
pip 10.0.1 py36_0
prompt_toolkit 1.0.15 py36h60b8f86_0
protobuf 3.6.0
pycparser 2.18 py36hd053e01_1
pygments 2.2.0 py36hb010967_0
pyparsing 2.2.0 py36h785a196_1
pyqt 5.6.0 py36_2
python 3.6.5 h0c2934d_0
python-dateutil 2.7.3 py36_0
pytorch 0.4.0 py36_cuda90_cudnn7he774522_1 [cuda90] pytorch
pytz 2018.4 py36_0
pywavelets 0.5.2 py36hc649158_0
pywinpty 0.5.4 py36_0
pyyaml 3.12 py36h1d1928f_1
pyzmq 17.0.0 py36hfa6e2cd_1
qt 5.6.2 vc14_1 [vc14] conda-forge
qtconsole 4.3.1 py36h99a29a9_0
requests 2.19.1
scikit-learn 0.19.1 py36h53aea1b_0
scipy 1.1.0 py36h672f292_0
send2trash 1.5.0 py36_0
setuptools 39.2.0 py36_0
simplegeneric 0.8.1 py36_2
sip 4.19.8 py36h6538335_0
six 1.11.0 py36h4db2310_1
sortedcontainers 2.0.4 py36_0
sqlite 3.22.0 vc14_0 [vc14] conda-forge
tblib 1.3.2 py36h30f5020_0
tensorboard 1.8.0
testpath 0.3.1 py36h2698cfe_0
tk 8.6.7 vc14_0 [vc14] conda-forge
toolz 0.9.0 py36_0
torchvision 0.2.1
tqdm 4.23.4 py36_0
traitlets 4.3.2 py36h096827d_0
urllib3 1.23
vs2015_runtime 14.0.25123 3
wcwidth 0.1.7 py36h3d5aa90_0
webencodings 0.5.1 py36h67c50ae_1
Werkzeug 0.14.1
widgetsnbextension 3.2.1 py36_0
wincertstore 0.2 py36h7fe50ca_0
winpty 0.4.3 4
yaml 0.1.7 vc14_0 [vc14] conda-forge
zeromq 4.2.5 vc14_1 [vc14] conda-forge
zict 0.1.3 py36h2d8e73e_0
zlib 1.2.11 vc14_0 [vc14] conda-forge
检查我们的 PATH 系统环境变量
此时,只要激活了 dlwin36 conda 环境,PATH 环境变量应该类似于以下内容:
e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36
e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\Library\mingw-w64\bin
e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\Library\usr\bin
e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\Library\bin
e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\Scripts
e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\bin
E:\toolkits.win\cuda-9.0.176\bin
E:\toolkits.win\cuda-9.0.176\libnvvp
e:\toolkits.win\anaconda3-5.2.0
e:\toolkits.win\anaconda3-5.2.0\Scripts
e:\toolkits.win\anaconda3-5.2.0\Library\bin
C:\ProgramData\Oracle\Java\javapath
C:\WINDOWS\system32
C:\WINDOWS
C:\WINDOWS\System32\Wbem
C:\WINDOWS\System32\WindowsPowerShell\v1.0\
C:\Program Files (x86)\NVIDIA Corporation\PhysX\Common
C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin
C:\Program Files (x86)\Windows Kits\10\Windows Performance Toolkit\
C:\Program Files\Git\cmd
C:\Program Files\Git\mingw64\bin
C:\Program Files\Git\usr\bin
C:\WINDOWS\System32\OpenSSH\
...
注意:若要逐行显示路径上的目录(如上所示),请在命令提示符中输入以下指令:
ECHO.%PATH:;= & ECHO.%。
快速检查每个主要 Python 库的安装情况
要快速检查已安装的后端(backends),请运行以下内容:
(dlwin36) $ python -c "import tensorflow; print('tensorflow: %s, %s' % (tensorflow.__version__, tensorflow.__file__))"
tensorflow: 1.8.0, e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages\tensorflow\__init__.py
(dlwin36) $ python -c "import cntk; print('cntk: %s, %s' % (cntk.__version__, cntk.__file__))"
cntk: 2.5.1, e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages\cntk\__init__.py
(dlwin36) $ python -c "import mxnet; print('mxnet: %s, %s' % (mxnet.__version__, mxnet.__file__))"f
mxnet: 1.2.0, e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages\mxnet\__init__.py
(dlwin36) $ python -c "import keras; print('keras: %s, %s' % (keras.__version__, keras.__file__))"
Using TensorFlow backend.
keras: 2.1.6, e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages\keras\__init__.py
(dlwin36) $ python -c "import torch; print('torch: %s, %s' % (torch.__version__, torch.__file__))"
torch: 0.4.0, e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages\torch\__init__.py
GPU 测试
使用 Keras 验证我们的 GPU 安装
我们可以使用 Keras 提供的一个示例脚本,在 MNIST 数据集 上训练一个简单的卷积网络(convnet,即 convolutional neural network)。该文件名为 mnist_cnn.py,可以在 Keras 的 examples 文件夹中找到,此处。代码如下:
'''Trains a simple convnet on the MNIST dataset.
Gets to 99.25% test accuracy after 12 epochs
(there is still a lot of margin for parameter tuning).
16 seconds per epoch on a GRID K520 GPU.
'''
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
使用 TensorFlow 后端(禁用 GPU(图形处理器))的 Keras
若要激活并测试 仅 CPU(中央处理器) 模式 下的 TensorFlow(深度学习框架) 后端,并获得一个良好的基准进行比较,请使用以下命令:
(dlwin36) $ set KERAS_BACKEND=tensorflow
(dlwin36) $ set CUDA_VISIBLE_DEVICES=-1
(dlwin36) $ python mnist_cnn.py
Using TensorFlow backend.
x_train shape: (60000, 28, 28, 1)
60000 train samples
10000 test samples
Train on 60000 samples, validate on 10000 samples
Epoch 1/12
2018-06-15 11:59:57.047920: I T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
2018-06-15 11:59:58.152643: E T:\src\github\tensorflow\tensorflow\stream_executor\cuda\cuda_driver.cc:406] failed call to cuInit: CUDA_ERROR_NO_DEVICE
2018-06-15 11:59:58.164753: I T:\src\github\tensorflow\tensorflow\stream_executor\cuda\cuda_diagnostics.cc:158] retrieving CUDA diagnostic information for host: SERVERP
2018-06-15 11:59:58.173767: I T:\src\github\tensorflow\tensorflow\stream_executor\cuda\cuda_diagnostics.cc:165] hostname: SERVERP
60000/60000 [==============================] - 60s 997us/step - loss: 0.2603 - acc: 0.9195 - val_loss: 0.0502 - val_acc: 0.9836
Epoch 2/12
60000/60000 [==============================] - 57s 952us/step - loss: 0.0873 - acc: 0.9734 - val_loss: 0.0390 - val_acc: 0.9868
Epoch 3/12
60000/60000 [==============================] - 57s 947us/step - loss: 0.0657 - acc: 0.9803 - val_loss: 0.0346 - val_acc: 0.9888
Epoch 4/12
60000/60000 [==============================] - 57s 945us/step - loss: 0.0543 - acc: 0.9842 - val_loss: 0.0348 - val_acc: 0.9886
Epoch 5/12
60000/60000 [==============================] - 56s 941us/step - loss: 0.0470 - acc: 0.9862 - val_loss: 0.0354 - val_acc: 0.9878
Epoch 6/12
60000/60000 [==============================] - 56s 939us/step - loss: 0.0410 - acc: 0.9871 - val_loss: 0.0290 - val_acc: 0.9905
Epoch 7/12
60000/60000 [==============================] - 56s 941us/step - loss: 0.0369 - acc: 0.9888 - val_loss: 0.0290 - val_acc: 0.9901
Epoch 8/12
60000/60000 [==============================] - 58s 960us/step - loss: 0.0337 - acc: 0.9892 - val_loss: 0.0261 - val_acc: 0.9916
Epoch 9/12
60000/60000 [==============================] - 57s 953us/step - loss: 0.0313 - acc: 0.9904 - val_loss: 0.0291 - val_acc: 0.9906
Epoch 10/12
60000/60000 [==============================] - 57s 958us/step - loss: 0.0286 - acc: 0.9913 - val_loss: 0.0317 - val_acc: 0.9889
Epoch 11/12
60000/60000 [==============================] - 58s 961us/step - loss: 0.0269 - acc: 0.9915 - val_loss: 0.0290 - val_acc: 0.9914
Epoch 12/12
60000/60000 [==============================] - 59s 976us/step - loss: 0.0270 - acc: 0.9915 - val_loss: 0.0304 - val_acc: 0.9916
Test loss: 0.030398282517803726
Test accuracy: 0.9916
注意:如果您已运行上述命令序列,要恢复 CUDA 检测您的 GPU 存在的能力,只需将环境变量
CUDA_VISIBLE_DEVICES设置为机器上已安装 GPU 设备的 ID 列表。换句话说,如果您只有一个 GPU,请使用set CUDA_VISIBLE_DEVICES=0。如果您有两个 GPU,请使用set CUDA_VISIBLE_DEVICES=0,1。以此类推。
使用 TensorFlow 后端(GPU)的 Keras
要激活并测试 TensorFlow 后端,请使用以下命令:
(dlwin36) $ set KERAS_BACKEND=tensorflow
(dlwin36) $ python mnist_cnn.py
Using TensorFlow backend.
x_train shape: (60000, 28, 28, 1)
60000 train samples
10000 test samples
Train on 60000 samples, validate on 10000 samples
Epoch 1/12
2018-06-15 12:14:21.774082: I T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
2018-06-15 12:14:22.219436: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1356] Found device 0 with properties:
name: GeForce GTX 1080 Ti major: 6 minor: 1 memoryClockRate(GHz): 1.645
pciBusID: 0000:04:00.0
totalMemory: 11.00GiB freeMemory: 9.09GiB
2018-06-15 12:14:22.345166: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1356] Found device 1 with properties:
name: GeForce GTX TITAN X major: 5 minor: 2 memoryClockRate(GHz): 1.076
pciBusID: 0000:03:00.0
totalMemory: 12.00GiB freeMemory: 10.06GiB
2018-06-15 12:14:22.360064: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1435] Adding visible gpu devices: 0, 1
2018-06-15 12:14:23.731981: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:923] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-06-15 12:14:23.741080: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:929] 0 1
2018-06-15 12:14:23.747608: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:942] 0: N N
2018-06-15 12:14:23.753642: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:942] 1: N N
2018-06-15 12:14:23.759825: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 8804 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1080 Ti, pci bus id: 0000:04:00.0, compute capability: 6.1)
2018-06-15 12:14:24.168800: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:1 with 9737 MB memory) -> physical GPU (device: 1, name: GeForce GTX TITAN X, pci bus id: 0000:03:00.0, compute capability: 5.2)
60000/60000 [==============================] - 10s 161us/step - loss: 0.2613 - acc: 0.9198 - val_loss: 0.0563 - val_acc: 0.9811
Epoch 2/12
60000/60000 [==============================] - 4s 71us/step - loss: 0.0875 - acc: 0.9743 - val_loss: 0.0435 - val_acc: 0.9853
Epoch 3/12
60000/60000 [==============================] - 4s 71us/step - loss: 0.0652 - acc: 0.9808 - val_loss: 0.0338 - val_acc: 0.9886
Epoch 4/12
60000/60000 [==============================] - 4s 71us/step - loss: 0.0531 - acc: 0.9844 - val_loss: 0.0324 - val_acc: 0.9896
Epoch 5/12
60000/60000 [==============================] - 4s 71us/step - loss: 0.0466 - acc: 0.9861 - val_loss: 0.0307 - val_acc: 0.9895
Epoch 6/12
60000/60000 [==============================] - 4s 71us/step - loss: 0.0421 - acc: 0.9869 - val_loss: 0.0323 - val_acc: 0.9906
Epoch 7/12
60000/60000 [==============================] - 4s 71us/step - loss: 0.0402 - acc: 0.9879 - val_loss: 0.0286 - val_acc: 0.9907
Epoch 8/12
60000/60000 [==============================] - 4s 71us/step - loss: 0.0326 - acc: 0.9896 - val_loss: 0.0299 - val_acc: 0.9909
Epoch 9/12
60000/60000 [==============================] - 4s 71us/step - loss: 0.0311 - acc: 0.9907 - val_loss: 0.0262 - val_acc: 0.9922
Epoch 10/12
60000/60000 [==============================] - 4s 71us/step - loss: 0.0310 - acc: 0.9902 - val_loss: 0.0256 - val_acc: 0.9918
Epoch 11/12
60000/60000 [==============================] - 4s 71us/step - loss: 0.0267 - acc: 0.9914 - val_loss: 0.0310 - val_acc: 0.9905
Epoch 12/12
60000/60000 [==============================] - 4s 71us/step - loss: 0.0262 - acc: 0.9917 - val_loss: 0.0281 - val_acc: 0.9919
Test loss: 0.028108230106867086
Test accuracy: 0.9919
在 GPU 加速模式下运行的、使用 TensorFlow 后端的 Keras,其速度比 CPU 模式快约 14.5 倍(58/4=14.5)。
使用 CNTK 后端(GPU)的 Keras
要激活并测试 CNTK 后端,请使用以下命令:
(dlwin36) $ set KERAS_BACKEND=cntk
(dlwin36) $ python mnist_cnn.py
Using CNTK backend
Selected GPU[0] GeForce GTX 1080 Ti as the process wide default device.
x_train shape: (60000, 28, 28, 1)
60000 train samples
10000 test samples
Train on 60000 samples, validate on 10000 samples
Epoch 1/12
60000/60000 [==============================] - 7s 110us/step - loss: 0.2594 - acc: 0.9211 - val_loss: 0.0561 - val_acc: 0.9806
Epoch 2/12
60000/60000 [==============================] - 6s 93us/step - loss: 0.0855 - acc: 0.9752 - val_loss: 0.0425 - val_acc: 0.9864
Epoch 3/12
60000/60000 [==============================] - 6s 93us/step - loss: 0.0646 - acc: 0.9805 - val_loss: 0.0327 - val_acc: 0.9887
Epoch 4/12
60000/60000 [==============================] - 6s 93us/step - loss: 0.0537 - acc: 0.9839 - val_loss: 0.0303 - val_acc: 0.9892
Epoch 5/12
60000/60000 [==============================] - 6s 94us/step - loss: 0.0466 - acc: 0.9863 - val_loss: 0.0280 - val_acc: 0.9906
Epoch 6/12
60000/60000 [==============================] - 6s 93us/step - loss: 0.0410 - acc: 0.9872 - val_loss: 0.0289 - val_acc: 0.9916
Epoch 7/12
60000/60000 [==============================] - 6s 93us/step - loss: 0.0356 - acc: 0.9896 - val_loss: 0.0278 - val_acc: 0.9917
Epoch 8/12
60000/60000 [==============================] - 6s 94us/step - loss: 0.0341 - acc: 0.9899 - val_loss: 0.0293 - val_acc: 0.9905
Epoch 9/12
60000/60000 [==============================] - 6s 94us/step - loss: 0.0325 - acc: 0.9903 - val_loss: 0.0249 - val_acc: 0.9920
Epoch 10/12
60000/60000 [==============================] - 6s 94us/step - loss: 0.0302 - acc: 0.9903 - val_loss: 0.0275 - val_acc: 0.9910
Epoch 11/12
60000/60000 [==============================] - 6s 94us/step - loss: 0.0277 - acc: 0.9913 - val_loss: 0.0258 - val_acc: 0.9915
Epoch 12/12
60000/60000 [==============================] - 6s 94us/step - loss: 0.0253 - acc: 0.9923 - val_loss: 0.0277 - val_acc: 0.9906
Test loss: 0.027684621373889287
Test accuracy: 0.9906
在此特定实验中,GPU 模式下的 CNTK 很快,但不如 TensorFlow 快。
使用 MXNet 后端(GPU)的 Keras
要激活并测试 MXNet 后端,请使用以下命令:
(dlwin36) $ set KERAS_BACKEND=mxnet
请注意,截至本文撰写之时,根据 问题 #106,目前尚无法直接使用相同的 Keras 代码并期望其在 GPU 上通过 MXNet 运行。您需要按照如下所示修改示例文件 mnist_cnn.py 中的 一行 代码:
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
应为:
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'],
context= ["gpu(0)"])
或者,使用此仓库中包含的文件 mnist_cnn_mxnet.py(它包含了上述更改),如下所示:
(dlwin36) $ set KERAS_BACKEND=mxnet
(dlwin36) $ python mnist_cnn_mxnet.py
Using MXNet backend
x_train shape: (60000, 28, 28, 1)
60000 train samples
10000 test samples
e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages\keras\backend\mxnet_backend.py:89: UserWarning: MXNet Backend performs best with `channels_first` format. Using `channels_last` will significantly reduce performance due to the Transpose operations. For performance improvement, please use this API`keras.utils.to_channels_first(x_input)`to transform `channels_last` data to `channels_first` format and also please change the `image_data_format` in `keras.json` to `channels_first`.Note: `x_input` is a Numpy tensor or a list of Numpy tensorRefer to: https://github.com/awslabs/keras-apache-mxnet/tree/master/docs/mxnet_backend/performance_guide.md
train_symbol = func(*args, **kwargs)
e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages\keras\backend\mxnet_backend.py:92: UserWarning: MXNet Backend performs best with `channels_first` format. Using `channels_last` will significantly reduce performance due to the Transpose operations. For performance improvement, please use this API`keras.utils.to_channels_first(x_input)`to transform `channels_last` data to `channels_first` format and also please change the `image_data_format` in `keras.json` to `channels_first`.Note: `x_input` is a Numpy tensor or a list of Numpy tensorRefer to: https://github.com/awslabs/keras-apache-mxnet/tree/master/docs/mxnet_backend/performance_guide.md
test_symbol = func(*args, **kwargs)
Train on 60000 samples, validate on 10000 samples
Epoch 1/12
e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages\mxnet\module\bucketing_module.py:408: UserWarning: Optimizer created manually outside Module but rescale_grad is not normalized to 1.0/batch_size/num_workers (1.0 vs. 0.0078125). Is this intended?
force_init=force_init)
[04:55:20] c:\jenkins\workspace\mxnet-tag\mxnet\src\operator\nn\cudnn\./cudnn_algoreg-inl.h:107: Running performance tests to find the best convolution algorithm, this can take a while... (setting env variable MXNET_CUDNN_AUTOTUNE_DEFAULT to 0 to disable)
60000/60000 [==============================] - 12s 192us/step - loss: 0.3480 - acc: 0.8934 - val_loss: 0.0817 - val_acc: 0.9743
Epoch 2/12
60000/60000 [==============================] - 7s 119us/step - loss: 0.1177 - acc: 0.9660 - val_loss: 0.0524 - val_acc: 0.9828
Epoch 3/12
60000/60000 [==============================] - 7s 119us/step - loss: 0.0859 - acc: 0.9750 - val_loss: 0.0432 - val_acc: 0.9857
Epoch 4/12
60000/60000 [==============================] - 7s 119us/step - loss: 0.0704 - acc: 0.9792 - val_loss: 0.0363 - val_acc: 0.9882
Epoch 5/12
60000/60000 [==============================] - 7s 119us/step - loss: 0.0608 - acc: 0.9817 - val_loss: 0.0344 - val_acc: 0.9884
Epoch 6/12
60000/60000 [==============================] - 7s 119us/step - loss: 0.0561 - acc: 0.9839 - val_loss: 0.0328 - val_acc: 0.9889
Epoch 7/12
60000/60000 [==============================] - 7s 119us/step - loss: 0.0503 - acc: 0.9853 - val_loss: 0.0322 - val_acc: 0.9890
Epoch 8/12
60000/60000 [==============================] - 7s 119us/step - loss: 0.0473 - acc: 0.9860 - val_loss: 0.0290 - val_acc: 0.9905
Epoch 9/12
60000/60000 [==============================] - 7s 119us/step - loss: 0.0440 - acc: 0.9870 - val_loss: 0.0304 - val_acc: 0.9899
Epoch 10/12
60000/60000 [==============================] - 7s 119us/step - loss: 0.0413 - acc: 0.9877 - val_loss: 0.0280 - val_acc: 0.9906
Epoch 11/12
60000/60000 [==============================] - 7s 119us/step - loss: 0.0388 - acc: 0.9888 - val_loss: 0.0281 - val_acc: 0.9913
Epoch 12/12
60000/60000 [==============================] - 7s 119us/step - loss: 0.0382 - acc: 0.9883 - val_loss: 0.0285 - val_acc: 0.9904
Test loss: 0.028510591367455346
Test accuracy: 0.9904
仅从这次单一实验来看,MXNet 似乎是三个 Keras 后端 (backend) 中速度最慢的。但是,如果您决定使用 MXNet,则可能需要实施上述警告中的更改:
e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages\keras\backend\mxnet_backend.py:89: UserWarning: MXNet Backend performs best with `channels_first` format. Using `channels_last` will significantly reduce performance due to the Transpose operations. For performance improvement, please use this API`keras.utils.to_channels_first(x_input)`to transform `channels_last` data to `channels_first` format and also please change the `image_data_format` in `keras.json` to `channels_first`.Note: `x_input` is a Numpy tensor or a list of Numpy tensorRefer to: https://github.com/awslabs/keras-apache-mxnet/tree/master/docs/mxnet_backend/performance_guide.md
train_symbol = func(*args, **kwargs)
您可以使用以下命令来实现这些更改:
(dlwin36) $ %SystemDrive%
(dlwin36) $ cd %USERPROFILE%\.keras
(dlwin36) $ cp keras.json keras.json.bak
(dlwin36) $ (echo { & echo "image_data_format": "channels_first", & echo "epsilon": 1e-07, & echo "floatx": "float32", & echo "backend": "mxnet" & echo }) > keras_mxnet.json
(dlwin36) $ (echo { & echo "image_data_format": "channels_last", & echo "epsilon": 1e-07, & echo "floatx": "float32", & echo "backend": "tensorflow" & echo }) > keras_tensorflow.json
(dlwin36) $ (echo { & echo "image_data_format": "channels_last", & echo "epsilon": 1e-07, & echo "floatx": "float32", & echo "backend": "cntk" & echo }) > keras_cntk.json
(dlwin36) $ cp -f keras_mxnet.json keras.json
注意 1:如果您在此之后想切换回 TensorFlow 或 CNTK,只需将正确的 json 文件复制到 keras.json(例如:cp -f keras_tensorflow.json keras.json 并将 KERAS_BACKEND 设置为匹配的框架(例如:set KERAS_BACKEND=tensorflow)。
注意 2:切换到 channels_first 通道排序后,我得到了以下结果:
(dlwin36) $ python mnist_cnn_mxnet.py Using MXNet backend x_train shape: (60000, 1, 28, 28) 60000 train samples 10000 test samples Train on 60000 samples, validate on 10000 samples Epoch 1/12 e:\toolkits.win\anaconda3-5.2.0\envs\dlwin36\lib\site-packages\mxnet\module\bucketing_module.py:408: UserWarning: Optimizer created manually outside Module but rescale_grad is not normalized to 1.0/batch_size/num_workers (1.0 vs. 0.0078125). Is this intended? force_init=force_init) [05:39:39] c:\jenkins\workspace\mxnet-tag\mxnet\src\operator\nn\cudnn./cudnn_algoreg-inl.h:107: Running performance tests to find the best convolution algorithm, this can take a while... (setting env variable MXNET_CUDNN_AUTOTUNE_DEFAULT to 0 to disable) 60000/60000 [==============================] - 9s 152us/step - loss: 0.3485 - acc: 0.8923 - val_loss: 0.0851 - val_acc: 0.9732 Epoch 2/12 60000/60000 [==============================] - 7s 109us/step - loss: 0.1191 - acc: 0.9652 - val_loss: 0.0529 - val_acc: 0.9824 Epoch 3/12 60000/60000 [==============================] - 7s 109us/step - loss: 0.0874 - acc: 0.9741 - val_loss: 0.0435 - val_acc: 0.9865 Epoch 4/12 60000/60000 [==============================] - 7s 109us/step - loss: 0.0740 - acc: 0.9784 - val_loss: 0.0402 - val_acc: 0.9867 Epoch 5/12 60000/60000 [==============================] - 7s 109us/step - loss: 0.0642 - acc: 0.9809 - val_loss: 0.0328 - val_acc: 0.9884 Epoch 6/12 60000/60000 [==============================] - 7s 109us/step - loss: 0.0585 - acc: 0.9826 - val_loss: 0.0346 - val_acc: 0.9897 Epoch 7/12 60000/60000 [==============================] - 7s 109us/step - loss: 0.0534 - acc: 0.9843 - val_loss: 0.0315 - val_acc: 0.9889 Epoch 8/12 60000/60000 [==============================] - 7s 109us/step - loss: 0.0491 - acc: 0.9852 - val_loss: 0.0336 - val_acc: 0.9888 Epoch 9/12 60000/60000 [==============================] - 7s 109us/step - loss: 0.0441 - acc: 0.9865 - val_loss: 0.0302 - val_acc: 0.9899 Epoch 10/12 60000/60000 [==============================] - 7s 109us/step - loss: 0.0421 - acc: 0.9877 - val_loss: 0.0303 - val_acc: 0.9903 Epoch 11/12 60000/60000 [==============================] - 7s 109us/step - loss: 0.0404 - acc: 0.9878 - val_loss: 0.0294 - val_acc: 0.9903 Epoch 12/12 60000/60000 [==============================] - 7s 109us/step - loss: 0.0381 - acc: 0.9889 - val_loss: 0.0272 - val_acc: 0.9904 Test loss: 0.027214839413274603 Test accuracy: 0.9904
速度稍快一些,但不如使用 CNTK 或 TensorFlow 后端 (backend) 的 Keras 快。
使用 PyTorch 验证我们的 GPU (图形处理单元) 安装
同样地,我们可以通过修改 PyTorch 的 示例 (examples) 文件夹 中的样本,在 MNIST 数据集上训练一个与 Keras 案例中使用的网络类似的卷积神经网络 (convnet)。新代码如下所示:
from __future__ import print_function
import sys, argparse
from time import time
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
tracker_length = 30
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
self.fc1 = nn.Linear(12*12*64, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) # 28x28x32 -> 26x26x32
x = F.relu(self.conv2(x)) # 26x26x32 -> 24x24x64
x = F.max_pool2d(x, 2) # 24x24x64 -> 12x12x64
x = F.dropout(x, p=0.25, training=self.training)
x = x.view(-1, 12*12*64) # flatten 12x12x64 = 9216
x = F.relu(self.fc1(x)) # fc 9216 -> 128
x = F.dropout(x, p=0.5, training=self.training)
x = self.fc2(x) # fc 128 -> 10
return F.log_softmax(x, dim=1) # to 10 logits
def train(args, model, device, train_loader, optimizer):
model.train()
start_time = time()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
percentage = 100. * batch_idx / len(train_loader)
cur_length = int((tracker_length * int(percentage)) / 100)
bar = '=' * cur_length + '>' + '-' * (tracker_length - cur_length)
sys.stdout.write('\r{}/{} [{}] - loss: {:.4f}'.format(
batch_idx * len(data), len(train_loader.dataset),
bar, loss.item()))
sys.stdout.flush()
train_time = time() - start_time
sys.stdout.write('\r{}/{} [{}] - {:.1f}s {:.1f}us/step - loss: {:.4f}'.format(
len(train_loader.dataset), len(train_loader.dataset), '=' * tracker_length,
train_time, (train_time / len(train_loader.dataset)) * 1000000.0, loss.item()))
sys.stdout.flush()
return len(train_loader.dataset), train_time, loss.item()
def test(args, model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, size_average=False).item() # sum up batch loss
pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
test_accuracy = correct / len(test_loader.dataset)
return test_loss, test_accuracy
def main(): # Training settings parser = argparse.ArgumentParser(description='PyTorch MNIST Example') parser.add_argument('--batch-size', type=int, default=64, metavar='N', help='input batch size for training (default: 64)') parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N', help='input batch size for testing (default: 1000)') parser.add_argument('--epochs', type=int, default=10, metavar='N', help='number of epochs to train (default: 10)') parser.add_argument('--lr', type=float, default=0.01, metavar='LR', help='learning rate (default: 0.01)') parser.add_argument('--momentum', type=float, default=0.5, metavar='M', help='SGD momentum (default: 0.5)') parser.add_argument('--no-cuda', action='store_true', default=False, help='disables CUDA training') parser.add_argument('--seed', type=int, default=1, metavar='S', help='random seed (default: 1)') parser.add_argument('--log-interval', type=int, default=10, metavar='N', help='how many batches to wait before logging training status') args = parser.parse_args() use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
for epoch in range(1, args.epochs + 1):
print("\nEpoch {}/{}".format(epoch, args.epochs))
train_len, train_time, train_loss = train(args, model, device, train_loader, optimizer)
test_loss, test_accuracy = test(args, model, device, test_loader)
sys.stdout.write('\r{}/{} [{}] - {:.1f}s {:.1f}us/step - loss: {:.4f} - val_loss: {:.4f} - val_acc: {:.4f}'.format(
train_len, train_len, '=' * tracker_length,
train_time, (train_time / train_len) * 1000000.0, train_loss,
test_loss, test_accuracy))
sys.stdout.flush()
if name == 'main': main()
我们在仓库中包含了此样本的修改版本,文件名为 [`mnist_cnn_pytorch.py`](mnist_cnn_pytorch.py)。您可以按以下方式运行:
(dlwin36) $ python mnist_cnn_pytorch.py Epoch 1/12 60000/60000 [==============================] - 7.1s 118.6us/step - loss: 0.2592 - val_loss: 0.1883 - val_acc: 0.9438 Epoch 2/12 60000/60000 [==============================] - 6.1s 102.0us/step - loss: 0.1917 - val_loss: 0.1412 - val_acc: 0.9575 Epoch 3/12 60000/60000 [==============================] - 6.1s 101.5us/step - loss: 0.2335 - val_loss: 0.1074 - val_acc: 0.9679 Epoch 4/12 60000/60000 [==============================] - 6.1s 101.2us/step - loss: 0.2038 - val_loss: 0.0828 - val_acc: 0.9741 Epoch 5/12 60000/60000 [==============================] - 6.1s 101.8us/step - loss: 0.1733 - val_loss: 0.0676 - val_acc: 0.9783 Epoch 6/12 60000/60000 [==============================] - 6.1s 101.2us/step - loss: 0.0952 - val_loss: 0.0587 - val_acc: 0.9810 Epoch 7/12 60000/60000 [==============================] - 6.1s 101.8us/step - loss: 0.0521 - val_loss: 0.0527 - val_acc: 0.9832 Epoch 8/12 60000/60000 [==============================] - 6.1s 101.5us/step - loss: 0.0993 - val_loss: 0.0484 - val_acc: 0.9834 Epoch 9/12 60000/60000 [==============================] - 6.0s 100.3us/step - loss: 0.2031 - val_loss: 0.0449 - val_acc: 0.9853 Epoch 10/12 60000/60000 [==============================] - 6.0s 100.0us/step - loss: 0.2267 - val_loss: 0.0429 - val_acc: 0.9868 Epoch 11/12 60000/60000 [==============================] - 6.1s 100.9us/step - loss: 0.0819 - val_loss: 0.0426 - val_acc: 0.9857 Epoch 12/12 60000/60000 [==============================] - 6.0s 100.7us/step - loss: 0.0312 - val_loss: 0.0370 - val_acc: 0.9872
正如预期,使用 PyTorch 进行网络训练的性能与其他框架相当。
# 建议观看和阅读
Deep Learning with Keras - Python, by The SemiColon:
@ https://www.youtube.com/playlist?list=PLVBorYCcu-xX3Ppjb_sqBd_Xf6GqagQyl
Deep Learning with Python, François Chollet
@ https://www.manning.com/books/deep-learning-with-python
# 关于作者
有关作者的更多信息,请访问:
[](https://www.linkedin.com/in/philferriere)
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。