dtreeviz
dtreeviz 是一款专为 Python 设计的决策树可视化与模型解释库。作为梯度提升机和随机森林等主流机器学习模型的核心组件,决策树的内部逻辑往往复杂难懂,而 dtreeviz 正是为了解决这一“黑盒”难题而生。它能将抽象的树状结构转化为直观、精美的图形,帮助用户轻松理解模型是如何基于特征进行判断和预测的。
这款工具特别适合数据科学家、机器学习工程师以及高校研究人员使用。无论是用于教学演示、模型调试,还是向业务方汇报分析结果,dtreeviz 都能提供强有力的支持。其独特亮点在于不仅支持基础的树结构展示,还能深入呈现样本在树中的预测路径、叶子节点的数据分布详情,甚至通过色彩丰富的图表探索特征空间与决策边界。
目前,dtreeviz 已广泛兼容 scikit-learn、XGBoost、LightGBM、Spark MLlib 及 TensorFlow 等主流框架。受 R2D3 教育动画启发,它在视觉设计上兼顾了美观性与信息密度,让枯燥的算法原理变得生动易懂,是提升模型可解释性的得力助手。
使用场景
某金融风控团队正在利用 XGBoost 模型评估小微企业贷款申请,急需向非技术背景的业务部门解释为何特定客户被拒绝。
没有 dtreeviz 时
- 只能依赖 scikit-learn 默认的文本树或简陋图形,节点重叠严重,难以看清复杂的分裂逻辑。
- 面对“为什么拒贷”的质问,无法直观展示该样本在树中的具体决策路径,只能口头复述枯燥的规则代码。
- 难以判断模型是否过度依赖某个单一特征(如仅看“成立年限”),缺乏对叶子节点样本分布的可视化验证手段。
- 业务方因不信任“黑盒”模型而抵触上线,导致项目验收周期被迫延长数周。
使用 dtreeviz 后
- 生成色彩鲜明、布局清晰的专业决策树图,业务人员能一眼看懂从根节点到叶子的完整分类过程。
- 利用预测路径解释功能,直接绘制出单个客户的决策轨迹,高亮显示关键分裂点,让拒贷理由有据可依。
- 通过叶子节点信息图,直观看到该分组内历史客户的违约率分布,快速识别并修正了模型对个别特征的过拟合问题。
- 可视化报告极大降低了沟通成本,业务部门迅速理解模型逻辑,项目顺利在一周内通过评审并投产。
dtreeviz 将晦涩的算法内部机制转化为直观的视觉语言,成功架起了数据科学家与业务决策者之间的信任桥梁。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明
快速开始
dtreeviz:决策树可视化
简介
一个用于决策树可视化和模型解释的 Python 库。决策树是 梯度提升机 和 随机森林(tm) 的基础构建模块,它们可能是处理结构化数据时最流行的两种机器学习模型。在学习这些模型的工作原理以及解释模型时,决策树的可视化可以提供极大的帮助。这些可视化灵感来源于 R2D3 制作的一段教育动画——机器学习的视觉入门。有关我们决策树可视化库及其视觉设计决策的更深入讨论,请参阅 如何可视化决策树。
目前,dtreeviz 支持:scikit-learn、XGBoost、Spark MLlib、LightGBM 和 TensorFlow。安装说明请参见 README.md#Installation。
作者
- Terence Parr,谷歌的技术负责人,2022 年之前曾任旧金山大学的数据科学/计算机科学教授,并于 2012 年担任该大学 数据科学硕士项目 的创始主任。
- Tudor Lapusan
- Prince Grover
此外,Matthew Epland (@mepland) 对代码和可视化进行了大规模的优化和清理。
示例可视化
树形可视化
 |
 |
 |
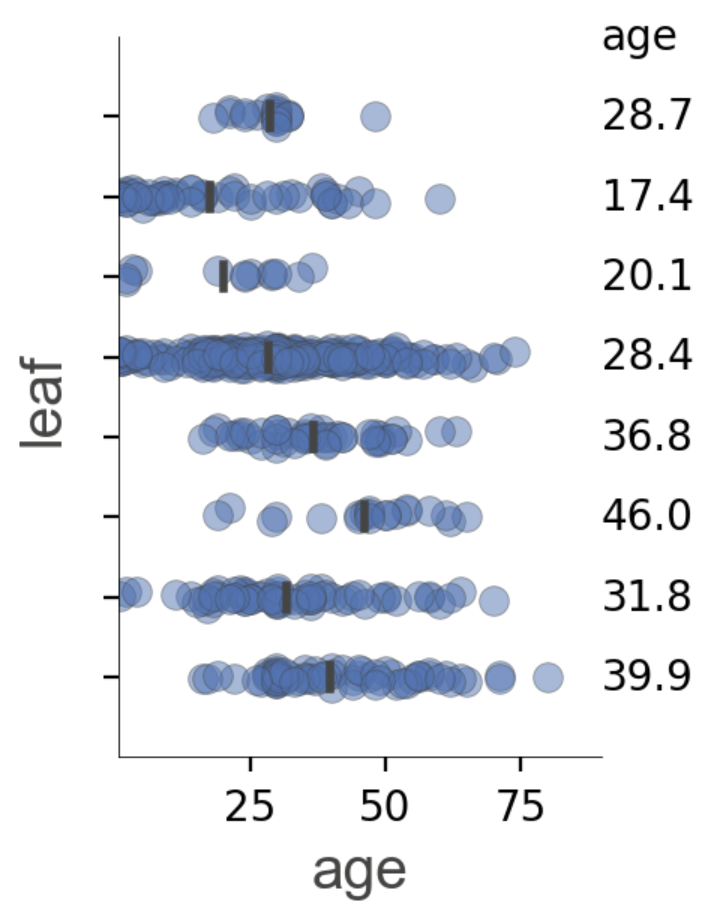
预测路径解释
 |
 |
 |
叶节点信息
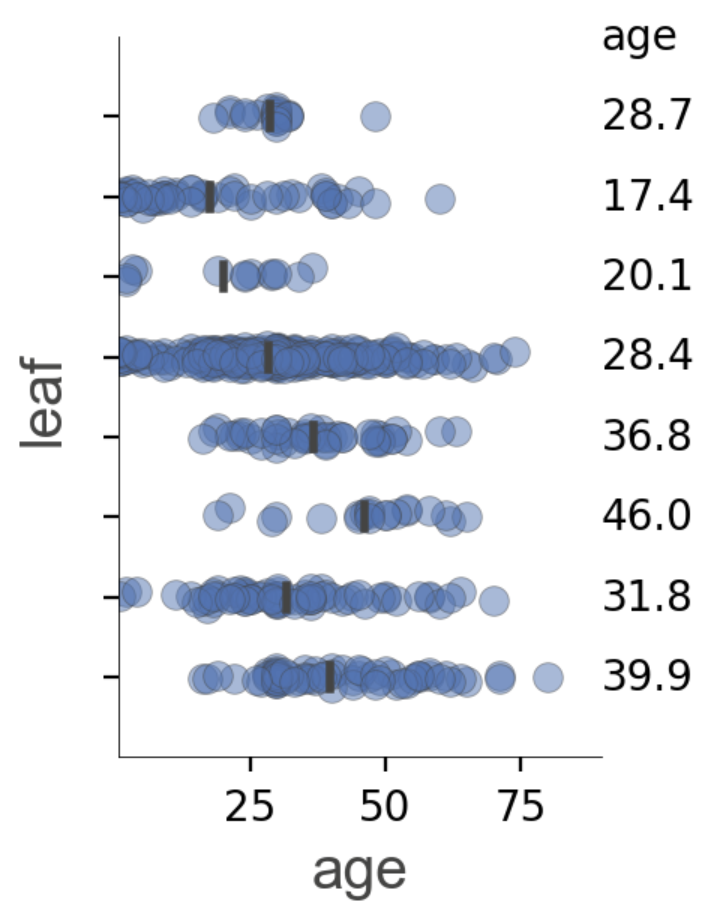 |
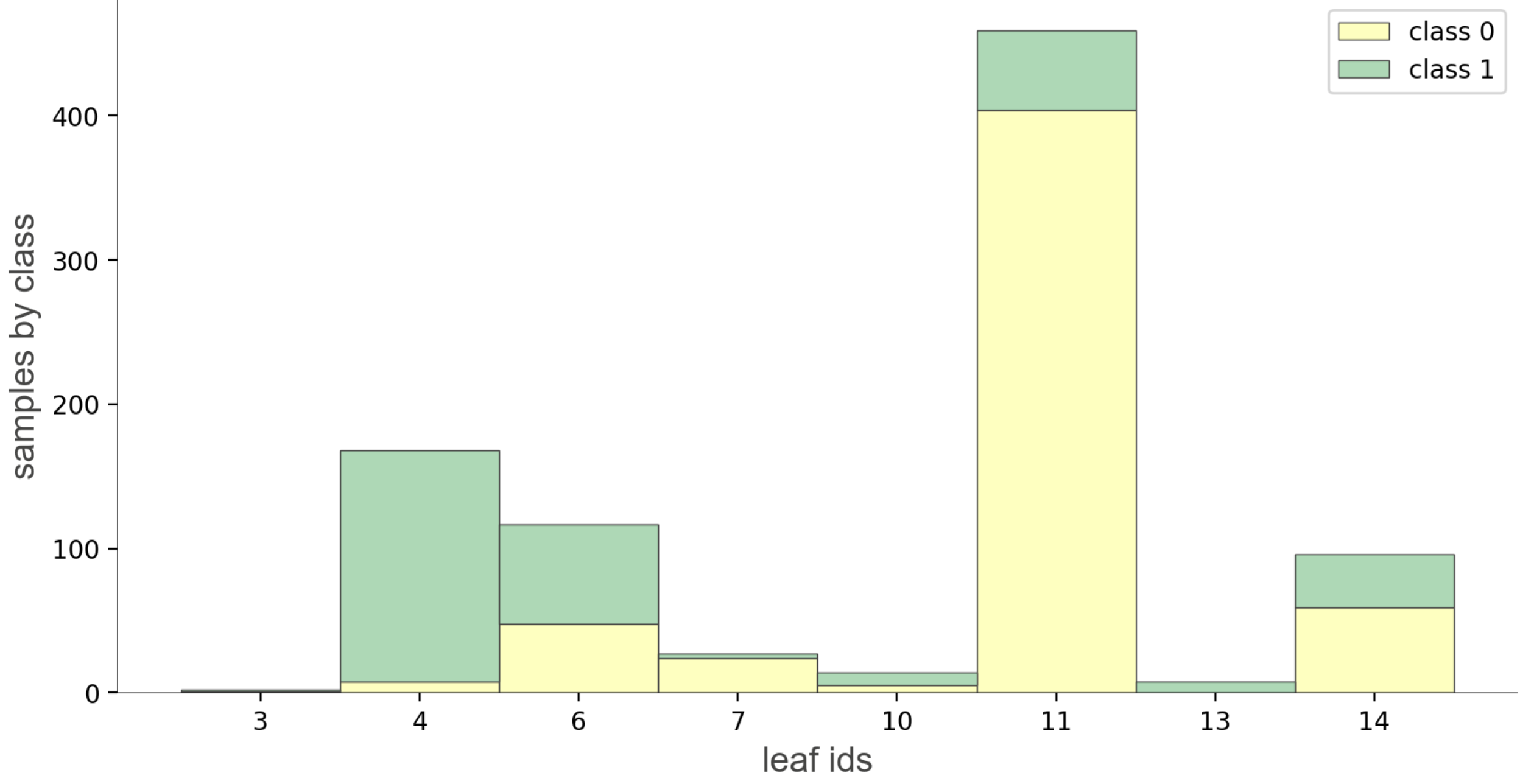 |
特征空间探索
回归
 |
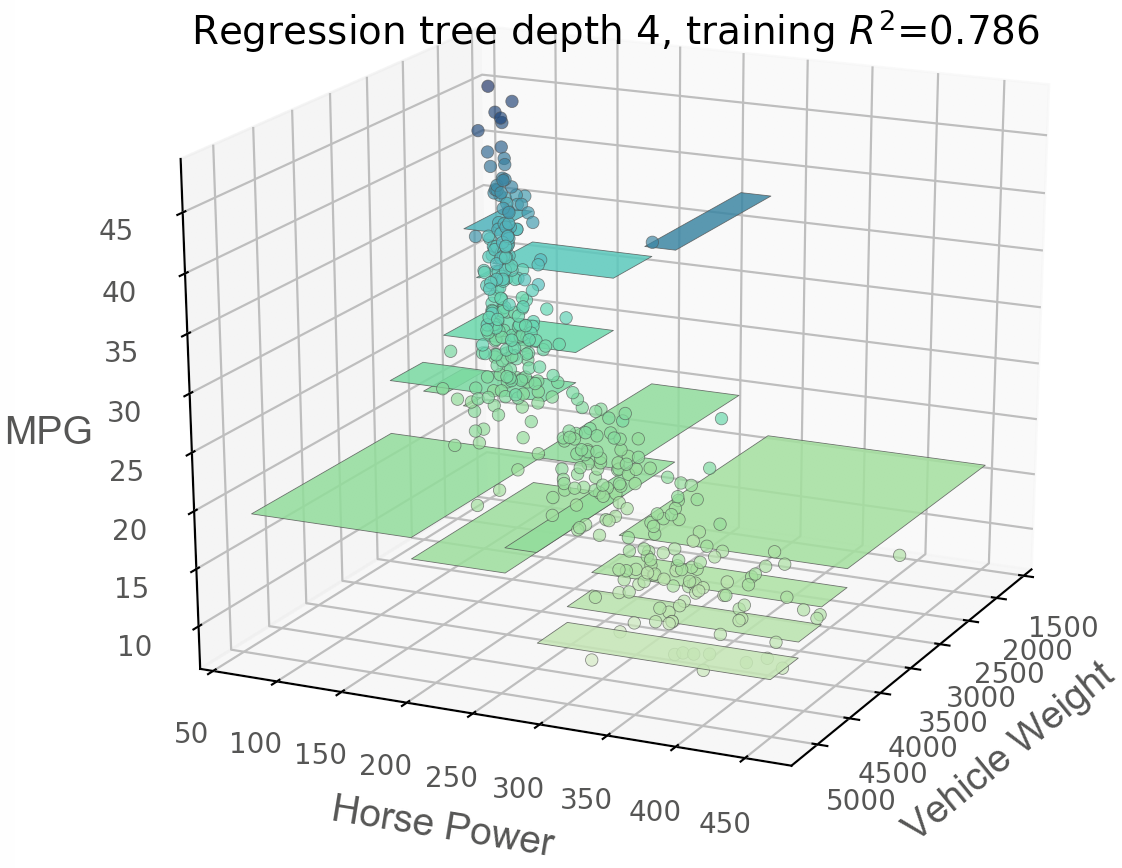 |
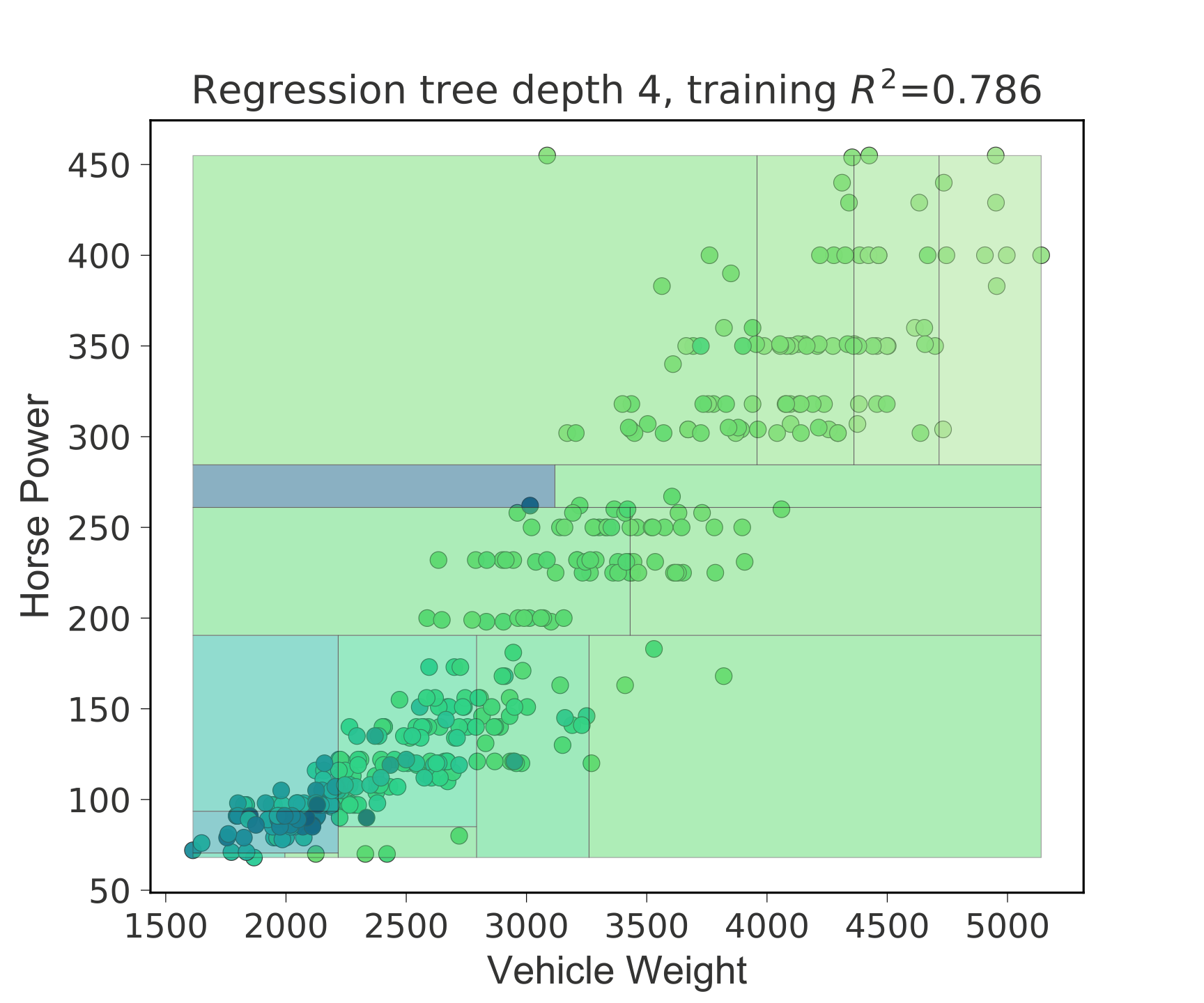 |
分类
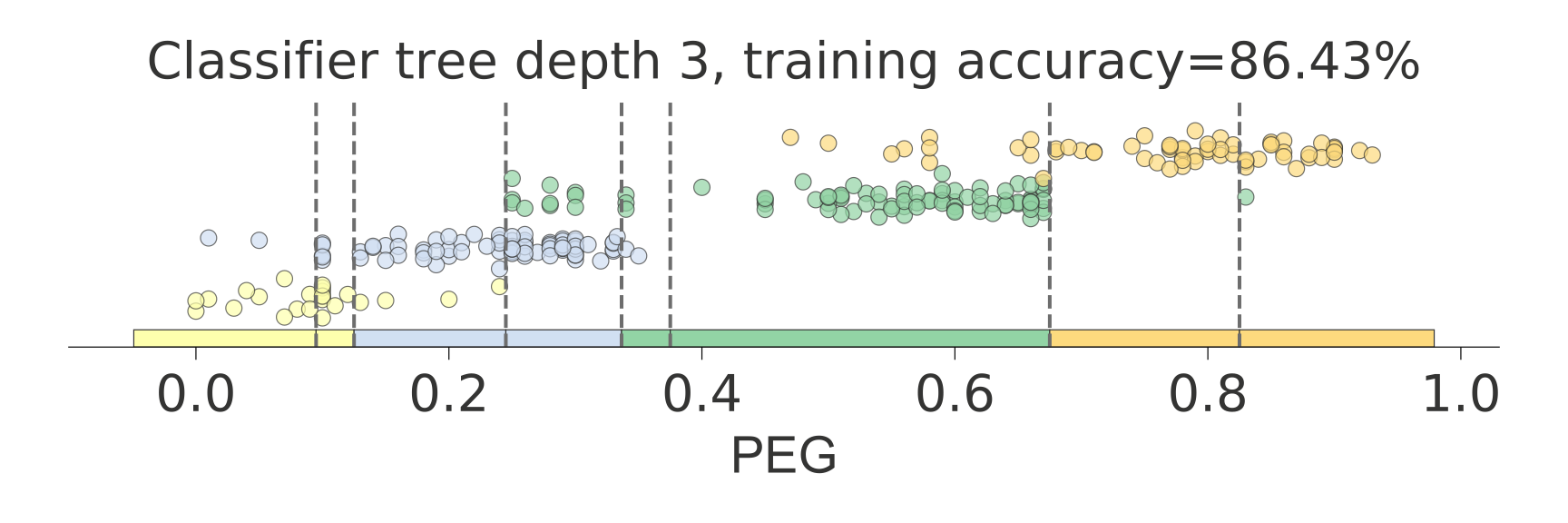 |
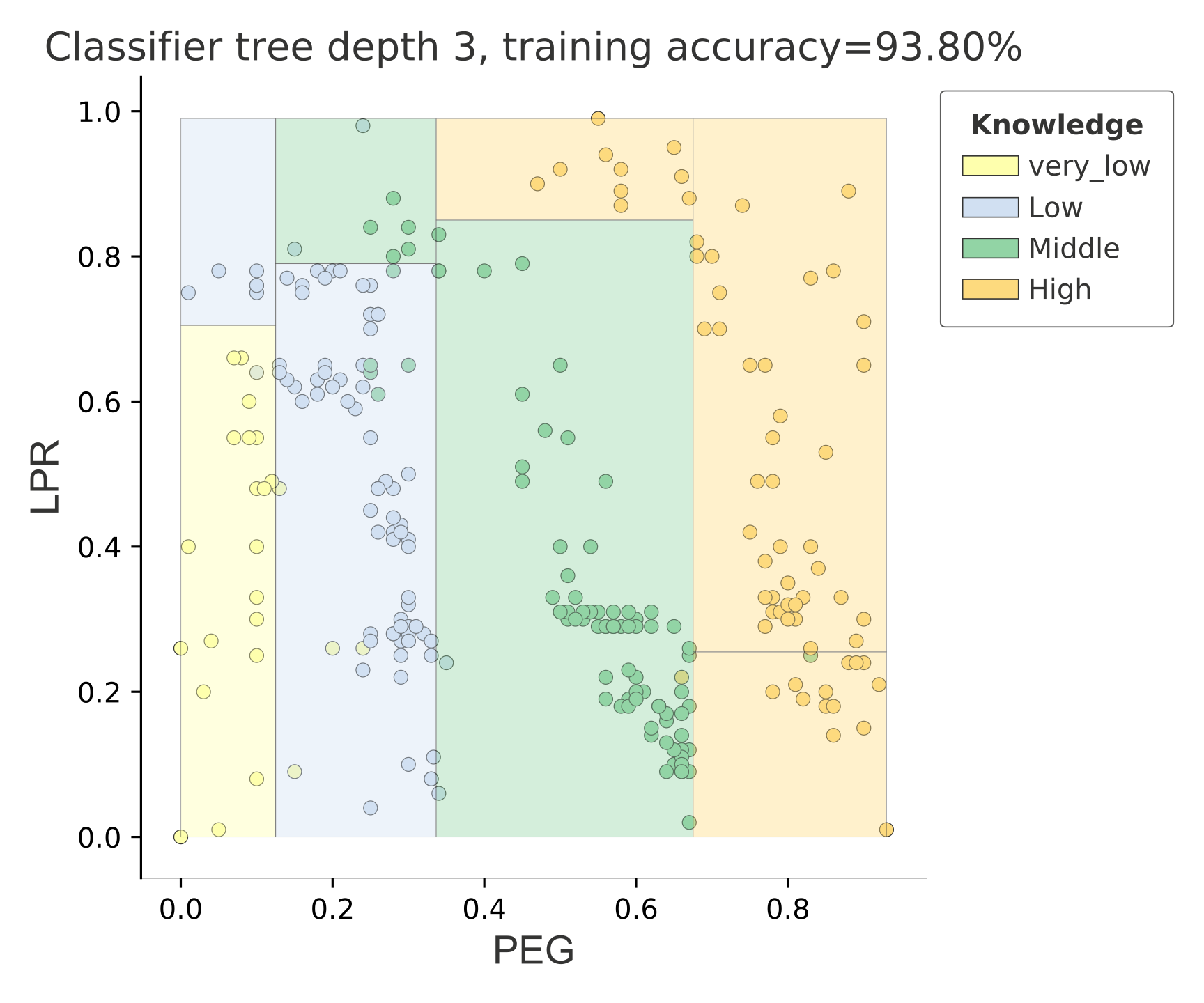 |
分类边界
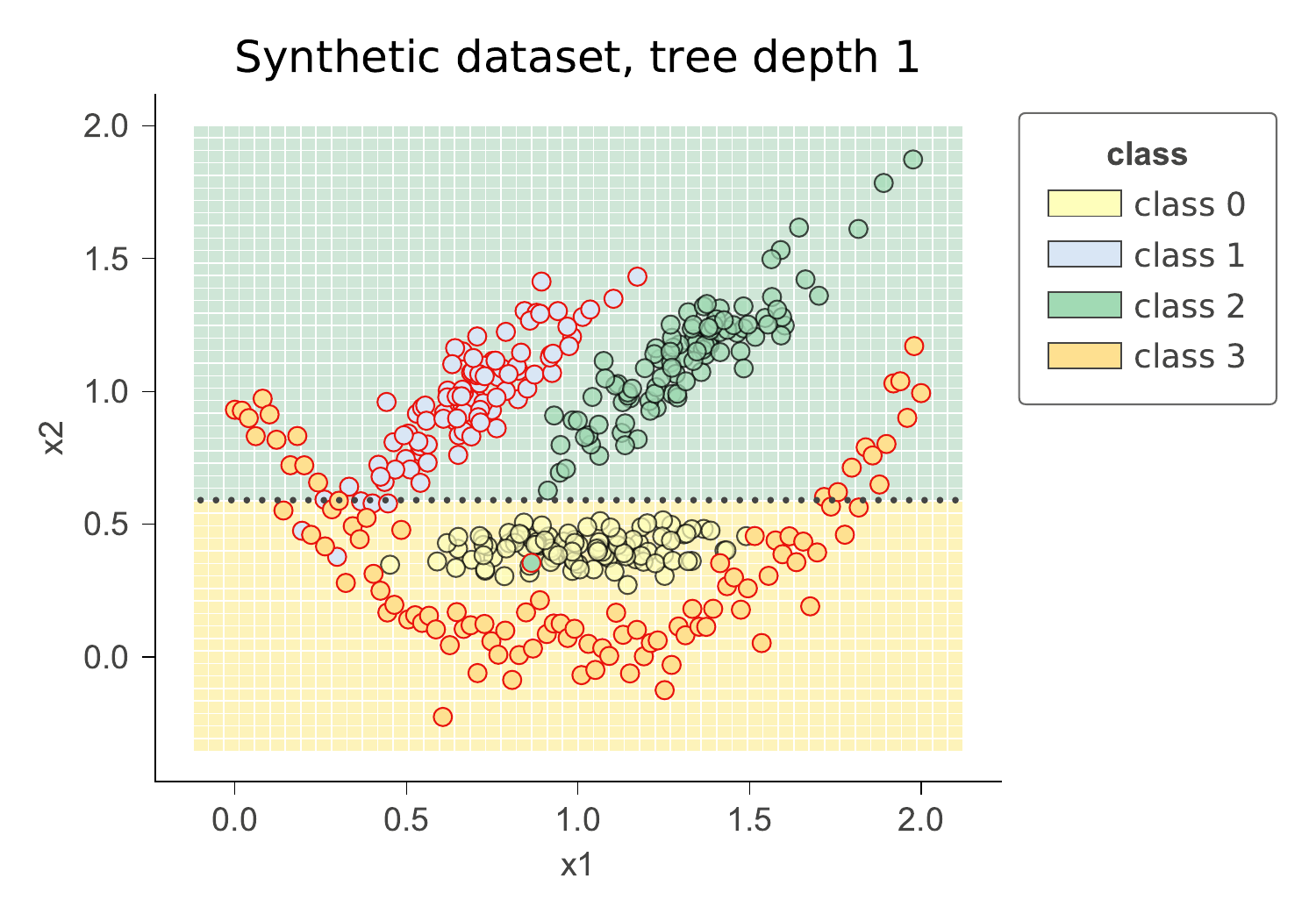
作为一项实用工具,dtreeviz 提供了 dtreeviz.decision_boundaries() 方法,用于展示分类器的一维和二维特征空间,包括表示概率的颜色、决策边界以及被错误分类的样本。值得注意的是,此方法并不局限于树模型,任何实现了 predict_proba() 方法的模型都可以使用。这意味着 scikit-learn 中的任何模型都适用(不过我们也使其能够与定义了 predict() 方法的 Keras 模型配合使用)。由于该方法不专门针对树模型,因此不会使用从 dtreeviz.model() 获取的适配器。更多信息请参阅 classifier-decision-boundaries.ipynb。
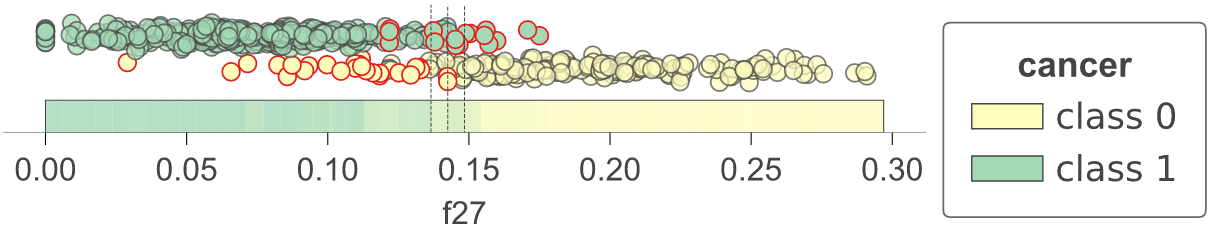 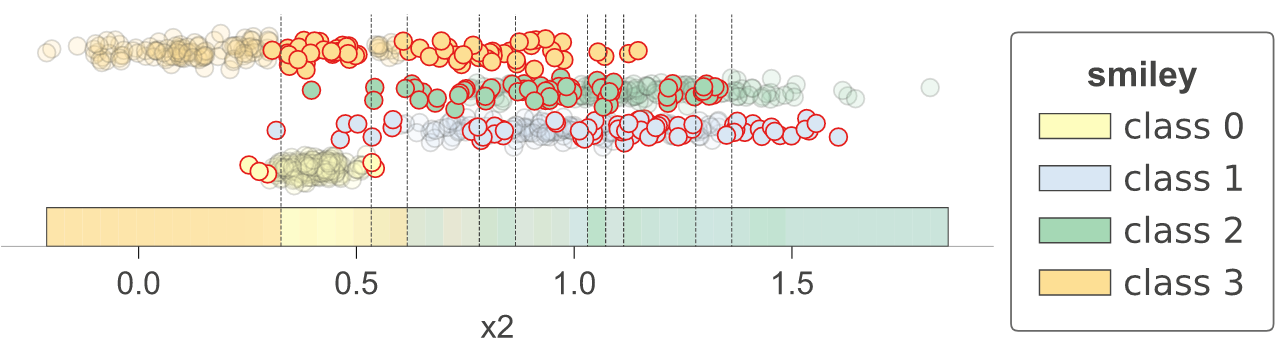 |
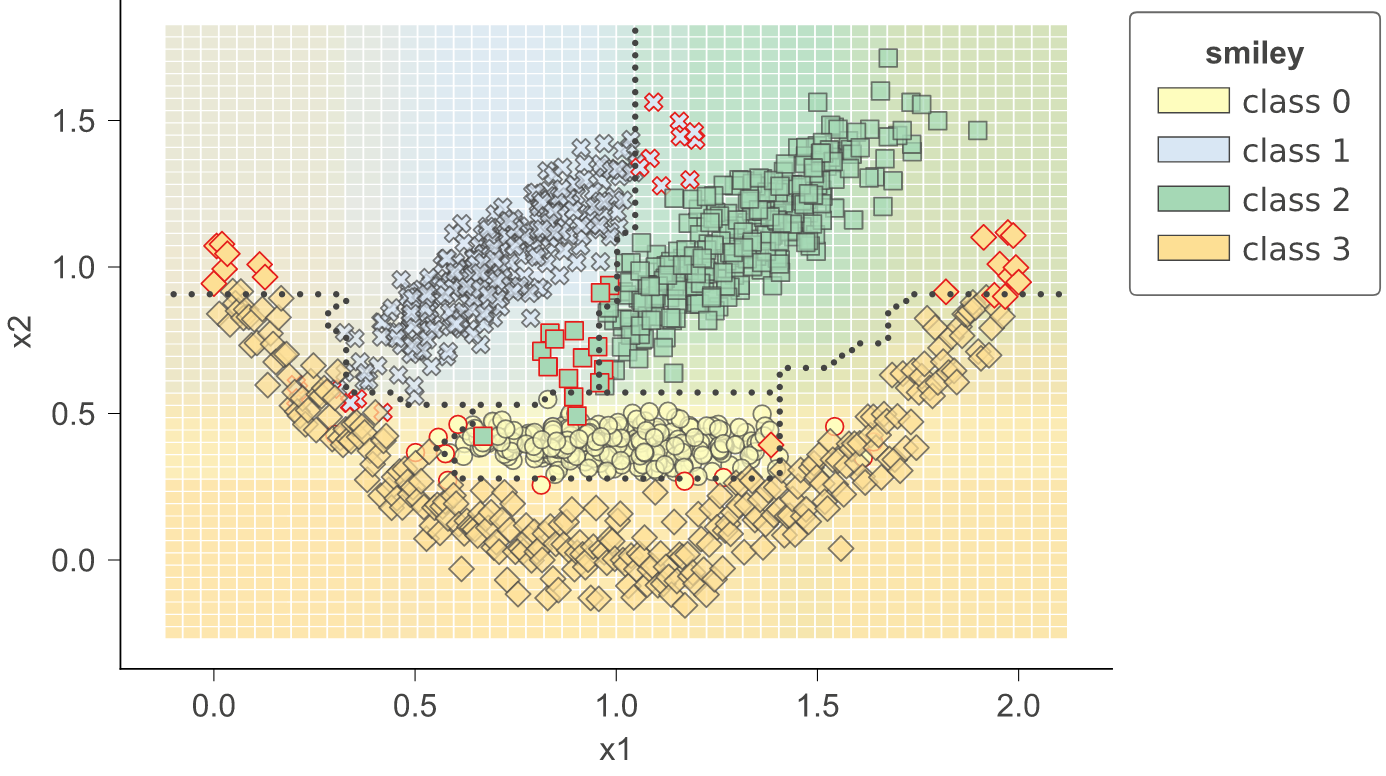 |
有时,查看随超参数变化的动画会很有帮助。如果您查阅笔记本 classifier-boundary-animations.ipynb,您将看到生成如下动画的代码(动画 PNG 文件):
 |
 |
快速入门
请参阅安装说明,然后查看您所使用的受支持机器学习库的特定笔记本:
- 基于 scikit-learn 的示例(Colab)
- 基于 LightGBM 的示例(Colab)
- 基于 Spark 的示例(Colab)
- 基于 TensorFlow 的示例(Colab)。另请参阅 tensorflow.org 博客中的使用 dtreeviz 可视化 TensorFlow 决策树森林
- 基于 XGBoost 的示例(Colab)
- 适用于任何 scikit-learn 模型的分类器决策边界.ipynb(Colab)
- 更改颜色笔记本(Colab)
- AI 驱动的树分析(scikit-learn)——使用 LLM 进行交互式聊天和解释
为了与这些不同的库进行互操作,dtreeviz 使用一个适配器对象,该对象通过函数 dtreeviz.model() 获取,用于提取可视化所需的相关模型信息。有了这样的适配器对象,您就可以使用相同的编程接口访问 dtreeviz 的所有功能。基本的 dtreeviz 使用流程如下:
- 导入 dtreeviz 和您的决策树库
- 获取数据并将其加载到内存中
- 使用您的决策树库训练分类器或回归器模型
- 通过
viz_model = dtreeviz.model(your_trained_model,...)获取 dtreeviz 适配器模型 - 调用 dtreeviz 函数,例如
viz_model.view()或viz_model.explain_prediction_path(sample_x)
示例
以下是一个完整的 Python 文件示例,它会在弹出窗口中显示如下树:

from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
import dtreeviz
iris = load_iris()
X = iris.data
y = iris.target
clf = DecisionTreeClassifier(max_depth=4)
clf.fit(X, y)
viz_model = dtreeviz.model(clf,
X_train=X, y_train=y,
feature_names=iris.feature_names,
target_name='iris',
class_names=iris.target_names)
v = viz_model.view() # 渲染为 SVG 到内部对象
v.show() # 弹出窗口
v.save("/tmp/iris.svg") # 可选地保存为 svg
在笔记本中,您可以直接内联渲染,而无需调用 show()。只需调用 view():
viz_model.view() # 在笔记本中,直接内联显示
AI 驱动的树分析
启用 AI 集成后,您可以使用 chat() 方法临时询问有关决策树模型的问题。AI 可以访问关于您的树结构、节点和训练数据的全面知识,从而回答以下问题:
- 树结构:整体架构、深度、节点数量、分裂标准以及树的类型(分类/回归)
- 树节点:分裂条件、特征使用情况、节点统计信息、样本分布以及内部节点的纯度指标
- 叶节点:预测结果、置信度分数、样本数量以及类别分布
- 训练数据集:特征统计信息、目标分布以及节点或叶节点内的数据特征
# 创建模型时启用 AI 聊天
viz_model = dtreeviz.model(tree_classifier,
X_train=dataset[features], y_train=dataset[target],
feature_names=features,
target_name=target, class_names=["perish", "survive"],
ai_chat=True,
ai_model="gpt-4.1-mini",
max_history_messages=10)
# 询问关于树的问题
viz_model.chat("请给我一个关于树结构的简短总结?")
viz_model.chat("哪些叶节点的预测置信度最低?")
此外,当启用 ai_chat=True 时,主要的可视化方法(如 view())会自动在视觉输出旁边包含由 LLM 生成的解释,从而为您提供决策树的图形和自然语言双重解读。
需要运行 pip install dtreeviz[ai] 并将 OpenAI API 密钥设置为 OPENAI_API_KEY 环境变量。更多示例请参阅AI 驱动的树分析笔记本。
安装
如果尚未安装,请在您的系统上安装 anaconda3。
您可能需要确认没有安装由 conda 提供的 graphviz 相关包,因为 dtreeviz 需要 pip 版本;您可以通过以下命令从 conda 环境中移除它们:
conda uninstall python-graphviz
conda uninstall graphviz
要安装(仅限 Python >=3.6),请执行以下操作(在 Windows 上使用 Anaconda Prompt!):
pip install dtreeviz # 安装用于 scikit-learn 的 dtreeviz
pip install dtreeviz[xgboost] # 安装 XGBoost 相关依赖
pip install dtreeviz[pyspark] # 安装 PySpark 相关依赖
pip install dtreeviz[lightgbm] # 安装 LightGBM 相关依赖
pip install dtreeviz[tensorflow_decision_forests] # 安装 TensorFlow 决策树森林相关依赖
pip install dtreeviz[ai] # 安装 AI 聊天/解释功能(需要 OpenAI API 密钥)
pip install dtreeviz[all] # 安装所有相关依赖
这也将引入 graphviz Python 库(>=0.9),我们正利用它来处理平台特定的任务。
局限性。 目前只能生成 SVG 文件,这减少了依赖项并大大简化了安装过程。
如果您有任何关于如何让 dtreeviz 在其他平台上更好地工作的建议,请发送电子邮件至 Terence。谢谢!
有关您特定平台的信息,请参阅以下小节。
Mac
请确保已安装最新版本的 Xcode 和命令行工具。如果 Xcode 已经安装,可以在终端中运行 xcode-select --install 来安装这些工具。此外,您还需要签署 Xcode 许可协议,可以通过在终端中运行 sudo xcodebuild -license 来完成。接下来展示的 Homebrew 安装步骤需要编译 Graphviz,因此必须正确配置 Xcode。
您需要 dot 可执行文件来使用 Graphviz。请确保安装的是最新版本(已在 macOS 10.13 和 10.14 上验证):
brew reinstall graphviz
为确保无误,请从任何 Anaconda 安装中移除 dot,例如:
rm ~/anaconda3/bin/dot
在终端中,以下命令应该能够正常运行:
dot -Tsvg
即它会静默等待输入而不报错。您可以按 Ctrl-C 返回到 shell 提示符。请确认您使用的是通过 Homebrew 安装的正确 dot:
$ which dot
/usr/local/bin/dot
$ ls -l $(which dot)
lrwxr-xr-x 1 parrt wheel 33 May 26 11:04 /usr/local/bin/dot@ -> ../Cellar/graphviz/2.40.1/bin/dot
$
局限性: Jupyter Notebook 存在一个 bug,无法正确显示 .svg 文件,但 Jupyter Lab 则没有这个问题。
Linux (Ubuntu 18.04)
要获取 dot 可执行文件,请执行以下命令:
sudo apt install graphviz
局限性: view() 方法可以弹出新窗口,并且图像会在 Jupyter Notebook 中内联显示,但在 Jupyter Lab 中则会因解析 SVG XML 出错而无法正常显示。此外,Notebook 中的图像会将我们使用的 Arial 字体替换为其他字体,导致部分文本重叠。在此平台上仅能生成 .svg 文件。
Windows 10
(请务必在所有平台上执行 pip install graphviz,并在 Windows 上通过 Anaconda Prompt 进行安装!)
下载 graphviz-2.38.msi,并更新您的 Path 环境变量。将 C:\Program Files (x86)\Graphviz2.38\bin 添加到用户路径,将 C:\Program Files (x86)\Graphviz2.38\bin\dot.exe 添加到系统路径。由于是 Windows 系统,更新环境变量后可能需要重启。您应在 Anaconda Prompt 中看到如下输出:
(base) C:\Users\Terence Parr>where dot
C:\Program Files (x86)\Graphviz2.38\bin\dot.exe
(请勿使用 conda install -c conda-forge python-graphviz,因为这会导致安装旧版本的 Graphviz Python 库。)
请在 Anaconda Prompt 中验证以下命令是否生效(注意是大写的 -V,而非小写的 -v):
dot -V
如果无效,则说明您的 Path 设置存在问题。我发现以下测试程序很有用。第一个程序用于检查 Python 是否能找到 dot:
import os
import subprocess
proc = subprocess.Popen(['dot','-V'])
print( os.getenv('Path') )
第二个版本的功能相同,但使用了 Graphviz Python 库的后台支持工具,这也是 dtreeviz 中所采用的方式:
import graphviz.backend as be
cmd = ["dot", "-V"]
stdout, stderr = be.run(cmd, capture_output=True, check=True, quiet=False)
print( stderr )
如果您在运行命令时遇到问题,可以尝试从 https://github.com/xflr6/graphviz/tree/master/graphviz 复制以下文件,并将其放置在 AppData\Local\Continuum\anaconda3\Lib\site-packages\graphviz 文件夹中。同时清空 __pycache__ 目录。
对于 Graphviz Windows 版本 8.0.5 和 Python 接口 v0.18+,您可以执行以下命令:
import graphviz.backend as be
cmd = ["dot", "-V"]
stdout = be.execute.run_check(cmd, capture_output=True,check=True,quiet=False)
print( stdout )
Jupyter Lab 和 Jupyter Notebook 都能很好地显示内联的 .svg 图像。
验证 Graphviz 安装
尝试创建一个名为 t.dot 的文本文件,内容为 digraph T { A -> B }(可以直接复制粘贴到文本编辑器中),然后在终端中运行以下命令:
dot -Tsvg -o t.svg t.dot
这将生成一个简单的 t.svg 文件,应能正常打开。如果 dot 报错,则 dtreeviz 的 Python 代码将无法正常工作。如果找不到 dot,则说明您未正确更新 PATH 环境变量,或 Graphviz 的安装存在其他问题。
局限性
最后,请不要使用 Internet Explorer 查看 .svg 文件,建议使用 Edge 浏览器,效果会更好。我怀疑 IE 是将 .svg 文件渲染为栅格图像而非矢量图像。在此平台上仅能生成 .svg 文件。
在本地安装 dtreeviz
请务必遵循上述安装指南。
为了进行测试,您需要使用 [dev] 附加项安装该库:
pip install dtreeviz[dev] # 安装开发依赖
在开发过程中,若需将 dtreeviz 库强制更新到本地 egg 缓存,可在 Windows 的 Anaconda Prompt 中执行以下命令:
python setup.py install -f
例如,在 Terence 的机器上,这会添加 /Users/parrt/anaconda3/lib/python3.6/site-packages/dtreeviz-2.3.2-py3.6.egg。
反馈
我们欢迎用户提供关于如何使用 dtreeviz、希望新增哪些功能等方面的信息,可通过 电子邮件(parrt@antlr.org) 或 GitHub 问题页面 与我们联系。
有用资源
- 如何可视化决策树
- 如何解释梯度提升
- 机器学习机制
- R2D3 的动画作品
- 机器学习视觉入门
- fast.ai 面向程序员的机器学习 MOOC
- Stef van den Elzen 的 决策树的交互式构建、分析与可视化
- 类似特征空间可视化的研究,见 迈向用户与计算机在分类任务中的有效协作,SIGKDD 2000
- BigML 决策树之美
- “SunBurst” 树形可视化方法:对用于展示层次结构的空间填充信息可视化技术的评估
许可证
本项目采用 MIT 许可证授权,详情请参阅 LICENSE。
版本历史
2.3.12025/12/272.32025/12/262.2.22023/07/132.2.12023/04/162.2.02023/02/202.1.42023/02/092.1.32023/01/292.1.22023/01/282.1.12023/01/222.1.02023/01/162.0.02022/12/271.4.12022/11/271.4.02022/10/221.3.72022/07/081.3.62022/04/291.3.52022/03/101.3.42022/03/081.3.32022/02/091.3.22021/11/101.3.12021/09/10常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。