learn-agentic-ai
learn-agentic-ai 是一个面向未来的开源学习项目,旨在帮助开发者掌握构建大规模“代理式 AI"(Agentic AI)系统的核心技能。它不仅仅教授如何让 AI 回答问题,更专注于训练 AI 自主规划、调用工具并执行复杂任务的能力。
该项目直面当前企业 AI 落地难的核心痛点:95% 的 AI 试点因缺乏正确的集成工作流和安全控制而失败。learn-agentic-ai 通过一套经过验证的云原生技术栈,解决了如何设计能稳定支撑千万级并发代理、且具备可观测性与成本控制的系统难题。
它特别适合希望从理论走向实战的 AI 工程师、架构师及研究人员,尤其是那些致力于开发高可靠性自动化应用或创业团队的成员。其独特亮点在于引入了 Dapr Agentic Cloud Ascent (DACA) 设计模式,深度融合了 Kubernetes 编排、Dapr 微服务原语、Ray 弹性计算以及 MCP、A2A 等前沿互操作协议。通过提供从基础概念到规模化部署的完整路径,learn-agentic-ai 帮助用户跨越技术鸿沟,构建真正能产生商业价值的智能代理系统。
使用场景
某大型跨境电商平台急需构建一个能自动处理百万级并发订单、协调库存与物流的智能代理集群,以应对大促期间的流量洪峰。
没有 learn-agentic-ai 时
- 架构脆弱难扩展:传统单体或简单微服务架构无法支撑千万级代理同时运行,一旦流量激增,系统极易崩溃且难以横向扩容。
- 协作混乱无标准:各个 AI 代理之间缺乏统一的通信协议(如 A2A)和工具调用标准(如 MCP),导致“数据孤岛”,代理间无法高效协同完成复杂任务。
- 状态管理易丢失:缺乏可靠的记忆机制和工作流引擎,长链路任务(如跨多国物流追踪)中容易丢失上下文,导致订单处理中断或重复执行。
- 试错成本极高:团队需从零摸索云原生代理架构,95% 的试点项目因不懂如何将 AI 融入现有工作流而失败,造成巨大的时间与资金浪费。
- 安全与审计缺失:缺乏内置的身份验证和可验证审计机制,自动化操作存在误删数据或违规执行的风险,无法满足企业合规要求。
使用 learn-agentic-ai 后
- 弹性伸缩稳如磐石:基于 Kubernetes + Dapr + Ray 的云原生栈,轻松实现代理集群的弹性扩缩容,稳定承载千万级并发请求而不宕机。
- 互操作性无缝衔接:遵循 MCP 和 A2A 开放协议,不同代理能像乐高积木一样标准化协作,自动打通 ERP、物流系统与支付网关。
- 持久记忆可靠执行:利用 Dapr Actors 和记忆模块,确保长流程任务的状态持久化,即使节点故障也能断点续传,保证订单 100% 准确交付。
- 落地路径清晰高效:直接复用经过验证的 DACA 设计模式与工作流模板,跳过盲目试错阶段,让小团队也能快速交付具有实际 ROI 的生产级应用。
- 内建信任安全合规:集成 NANDA 身份认证与审计标准,所有代理操作均可追溯且权限可控,让自动化决策在安全围栏内高效运行。
learn-agentic-ai 将原本高风险的 AI 试点转化为可规模化落地的生产引擎,让企业从“聊聊天”真正迈向“做成事”。
运行环境要求
- 未说明
未说明(文中提及生产环境需大量 GPU 支持高并发,但开发/学习环境建议使用 Minikube/kind 本地测试或利用云积分,未指定具体显卡型号或显存要求)
未说明

快速开始
使用 Dapr Agentic Cloud Ascent (DACA) 设计模式学习智能体 AI:从入门到规模化
本仓库是 Panaversity 认证智能体与机器人 AI 工程师 项目的一部分。您还可以在项目指南中查看认证及课程详情。此仓库提供了智能体 AI 和云相关课程的学习资料。
以下是一份精炼、专业的改写版本,既适合作为单页介绍,也可用于幻灯片展示——语言简洁有力,清晰传达核心价值,同时略带趣味性,避免显得过于官方或僵硬(绝无冒犯委员会之意 😄)。
我们的巴基斯坦智能体战略:四项行动假设
巴基斯坦必须针对将定义智能体 AI 时代的科技与人才,尽早做出明智布局——因为我们计划在全国乃至海外培养数百万名智能体 AI 开发者,并大规模孵化初创企业(目标宏大,但至少咖啡比后悔便宜)。
假设一 — 智能体 AI 是未来趋势
我们坚信,AI 的未来在于“智能体”:即能够自主规划、协调工具并采取行动以达成目标的系统,而不仅仅是给出答案(也就是从“聊天”走向“完成任务”——且最好不会破坏任何重要事物)。这一假设指导着我们的课程设计、工具选型以及投资方向。
假设二 — 云原生基石:Kubernetes × Dapr × Ray
对于大规模智能体系统的构建,我们押注于一套云原生技术栈:使用 Kubernetes 进行编排,借助 Dapr(Actor、工作流与代理组件)提供可靠的微服务基础模块,并利用 Ray 实现弹性分布式计算。三者协同工作,为持久、可观测且可水平扩展的智能体集群奠定了坚实基础。
假设三 — 真正的瓶颈在于“学习鸿沟”
大多数 AI 试点失败并非因为模型能力不足,而是团队缺乏将 AI 有效融入业务流程、管控机制和经济模型的方法。近期一篇 MIT 研究报道指出,约 95% 的企业生成式 AI 实施并未带来可量化的损益影响,主要原因在于问题选择不当及集成实践欠缺,而非模型本身的质量问题。为此,我们的项目专门围绕流程设计、安全防护机制以及以 ROI 为导向的交付方式展开培训,旨在填补这一空白。 MIT 报告称 95% 的 AI 试点失败让投资者惊慌,但真正应让高管层警惕的是这些试点失败的根本原因
假设四 — 网络正迈向“智能体化与互操作性”
下一代网络将由一系列通过开放协议协作的智能体组成——其中 MCP 提供标准化的工具与上下文访问接口,A2A 支持经过身份验证的智能体间协作,而 NANDA 则负责身份管理、授权及可验证的审计记录。这些新兴标准将推动跨应用、设备和云端的组合式自动化发展,使浏览器不再只是标签页的集合,而是具备信任与用户同意机制的结果编排器(终于可以少点标签页,多点实际成果了)。
对执行层面的意义
- 人才培养引擎: 实战导向的智能体模式训练(包括规划、工具使用、记忆与评估),结合流程设计与安全性考量,并紧密贴合真实行业场景(毕竟“Hello, World”并不能直接提升损益)。
- 参考架构: 基于 Kubernetes + Dapr + Ray 的蓝图方案,内置可观测性、安全防护措施及成本控制功能,便于小型团队快速部署,同时也满足大型组织的审计需求。
- 协议对接准备: 在智能体设计中提前考虑对 MCP/A2A/NANDA 协议的支持,确保随着标准逐步成熟,我们的解决方案能够实现无缝互操作(面向未来的布局远胜于盲目预测未来)。
若上述任一假设被证明有误,我们将迅速衡量、公开结果并果断调整策略——因为唯一不可饶恕的错误,就是不从中吸取教训。
本Panaversity倡议应对的关键挑战是:
“我们如何设计能够同时处理1000万个AI智能体而不出现故障的AI智能体系统?”
注:这一挑战更加严峻,因为我们必须引导学生在训练期间仅使用有限的财务资源来解决这个问题。
理论上,结合Dapr的Kubernetes可以在不发生故障的情况下支持一个包含1000万个并发智能体的智能体式AI系统。然而,要实现这一点,需要进行大量的优化、强大的基础设施以及精心的工程设计。尽管目前尚缺乏如此大规模的直接证据,但基于现有基准测试、Kubernetes的可扩展性以及Dapr的actor模型所做出的逻辑推断,表明这一目标是可行的,尤其是在经过严格调优和合理资源配置的情况下。
精简论证与证明逻辑:
Kubernetes的可扩展性:
- 证据:根据Kubernetes官方文档,单个集群最多可支持5,000个节点和150,000个Pod。实际案例中,PayPal曾将其集群扩展至4,000个节点和200,000个Pod(InfoQ,2023年),而KubeEdge则管理着100,000个边缘节点和100万个Pod(KubeEdge案例研究)。此外,OpenAI在其用于AI工作的2,500节点集群中也展示了Kubernetes能够处理计算密集型任务的能力(OpenAI博客,2022年)。
- 逻辑:对于1000万用户而言,一个由5,000至10,000个节点组成的集群(例如使用配备GPU的AWS g5实例)即可分担工作负载。每个节点可以运行数百个Pod,而Kubernetes的水平Pod自动伸缩功能(HPA)可以根据需求动态调整。通过调优etcd、使用高性能CNI如Cilium以及优化DNS配置,可以有效缓解API服务器和网络等方面的瓶颈问题。
Dapr在智能体式AI中的高效性:
- 证据:Dapr的actor模型支持每个CPU核心运行数千个虚拟actor,且延迟仅为数十毫秒级别(Dapr文档,2024年)。案例研究表明,Dapr能够处理数以百万计的事件,例如Tempestive的物联网平台每秒处理数十亿条消息(Dapr博客,2023年),以及DeFacto系统在Kubernetes上利用Kafka每秒处理3,700个事件(约每天3.2亿个事件)(微软案例研究,2022年)。
- 逻辑:智能体式AI依赖于有状态、低延迟的智能体。基于actor模型构建的Dapr Agent可以将1000万用户表示为分布在Kubernetes集群中的actor。Dapr的状态管理(如Redis)和发布/订阅消息机制(如Kafka)能够确保高效的协调与系统韧性,并通过自动重试机制防止故障发生。通过对状态存储和消息代理进行分片,系统可以扩展到每秒处理数百万次操作。
AI工作负载的处理:
- 证据:LLM推理框架如vLLM和TGI能够在每块GPU上每秒服务数千个请求(vLLM基准测试,2024年)。Kubernetes能够有效地编排GPU工作负载,例如NVIDIA的AI平台已成功扩展至数千块GPU(NVIDIA案例研究,2023年)。
- 逻辑:假设每位用户每秒产生1个请求,且每个请求需要0.01个GPU算力,则1000万用户大约需要10万个GPU。通过批处理、缓存和模型并行等技术,这一需求可以降低至约1万至2万个GPU,这在超大规模云环境中是完全可行的(例如AWS)。Kubernetes的资源调度功能可确保GPU资源得到最优利用。
网络与存储:
- 证据:EMQX在Kubernetes上经过调优后,能够处理100万个并发连接(EMQX博客,2024年)。C10M基准测试(2013年)则通过优化协议栈实现了1000万个连接。Dapr的状态存储(如Redis)能够支持每秒数百万次操作(Redis基准测试,2024年)。
- 逻辑:1000万连接需要约100至1,000 Gbps的带宽,现代云服务完全可以满足这一需求。高吞吐量数据库(如CockroachDB)和缓存系统(如Redis Cluster)能够处理1000万用户所需的10 TB状态数据(每位用户1 KB)。采用内核旁路技术(如DPDK)和基于eBPF的CNI(如Cilium)可以最大限度地降低网络延迟。
系统韧性与监控:
- 证据:Dapr的韧性策略(重试机制、熔断器等)以及Kubernetes的自我修复能力(Pod重启)能够确保系统的可靠性(Dapr文档,2024年)。Dapr集成的OpenTelemetry工具可以对数百万个智能体进行监控扩展(Prometheus案例研究,2023年)。
- 逻辑:实时指标(如延迟、错误率)和分布式追踪技术可以防止级联故障的发生。Kubernetes的存活探针和Dapr的工作流引擎能够在系统崩溃时迅速恢复,从而保证99.999%的可用性。
在约束条件下的可行性:
- 挑战:目前尚无关于在智能体式AI场景中使用Dapr与Kubernetes同时处理1000万并发用户的直接基准测试。此外,相关基础设施成本(例如1万个节点可能需要1000万至1亿美元)对于预算有限的情况来说极为高昂。
- 解决方案:建议使用开源工具(如Minikube、kind)进行本地测试,并鼓励学生申请云服务提供商的教育优惠额度(如AWS Educate)。可以通过Locust等工具在较小规模的集群上(例如100个节点)模拟1000万用户的行为,并据此推算结果。同时,应优化Dapr的actor放置策略以及Kubernetes的资源配额,以在有限的硬件条件下最大化效率。此外,还可以利用免费层级的数据库(如MongoDB Atlas)和消息代理(如RabbitMQ)来降低成本。
结论:结合Dapr的Kubernetes确实有能力在智能体式AI系统中支持1000万并发用户,这一结论得到了其成熟可扩展性、实际应用案例以及逻辑推演的支持。对于预算有限的学生而言,通过小规模模拟、开源工具和云服务优惠额度,这一问题是可以逐步攻克的;然而,若要实现生产级别的部署,则仍需超大规模的资源投入和专业团队的支持。
2025年最热门的智能体式AI趋势

Dapr智能体云上升(DACA)设计模式解决了1000万AI智能体的挑战
让我们深入了解并学习“Dapr智能体云上升(DACA)”——我们用于开发和部署全球规模多智能体系统的获奖设计模式。
执行摘要:Dapr 代理云上升(DACA)
Dapr 代理云上升(DACA)指南介绍了一种用于构建和部署复杂、可扩展且具备弹性的代理式 AI 系统的战略设计模式。针对现代 AI 开发中的复杂性,DACA 将 OpenAI Agents SDK 用于核心代理逻辑,结合模型上下文协议(MCP)实现标准化工具使用,并通过 Agent2Agent(A2A)协议实现无缝的代理间通信,所有这些都由 Dapr 的分布式能力提供支持。以 AI 首选和云首选原则为基础,DACA 推崇使用无状态、容器化的应用,部署在 Azure 容器应用(无服务器容器)或 Kubernetes 等平台上,从而实现从本地开发到全球规模生产的高效扩展,同时还可以利用免费层级的云服务和自托管的 LLM 来优化成本。该模式强调模块化、上下文感知和标准化通信,旨在构建一个由多种 AI 代理智能协作的 “代理世界”。最终,DACA 为开发者和架构师提供了一个强大、灵活且经济高效的框架,帮助他们从一开始就构建面向可扩展性和弹性的复杂云原生代理式 AI 应用程序。
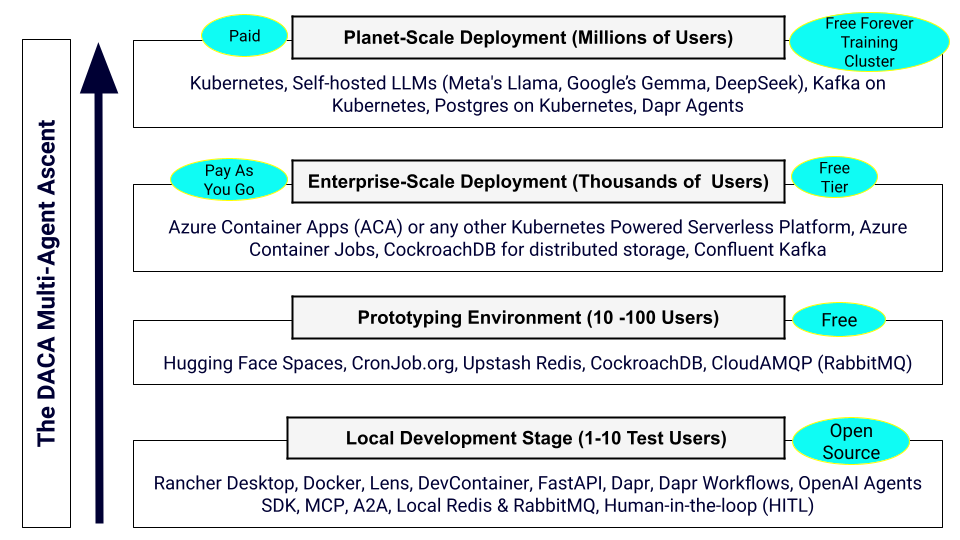
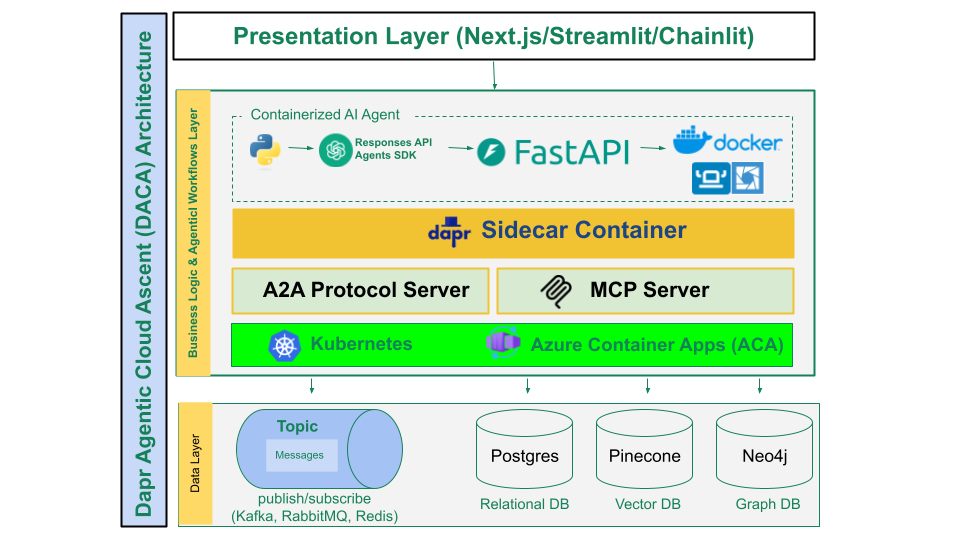
目标用户
- 代理式 AI 开发者及 AgentOps 专业人员
为什么 OpenAI Agents SDK 应该成为大多数用例中代理式开发的主要框架?
表 1:AI 代理框架抽象层次比较
| 框架 | 抽象层次 | 关键特性 | 学习曲线 | 控制水平 | 简单性 |
|---|---|---|---|---|---|
| OpenAI Agents SDK | 最低 | Python 优先,核心原语(代理、交接、护栏),直接控制 | 低 | 高 | 高 |
| CrewAI | 中等 | 基于角色的代理、团队、任务,注重协作 | 低至中等 | 中等 | 中等 |
| AutoGen | 高 | 对话型代理,灵活的对话模式,人机协同支持 | 中等 | 中等 | 中等 |
| Google ADK | 中等 | 多代理层级结构,Google Cloud 集成(Gemini、Vertex AI),丰富的工具生态系统,双向流媒体 | 中等 | 中高 | 中等 |
| LangGraph | 低至中等 | 基于图的工作流,节点、边,显式状态管理 | 极高 | 极高 | 低 |
| Dapr Agents | 中等 | 有状态虚拟演员,事件驱动的多代理工作流,Kubernetes 集成,50 多种数据连接器,内置弹性 | 中等 | 中高 | 中等 |
表格清晰地表明了为什么 OpenAI Agents SDK 应该成为大多数用例中代理式开发的主要框架:
- 它在简单性和易用性方面表现出色,是快速开发和广泛普及的最佳选择。
- 它提供了高度控制和最低限度的抽象,在不引入 LangGraph 等框架复杂性的情况下,为代理式开发提供了所需的灵活性。
- 在可用性和功能之间的平衡上,它优于大多数替代方案(CrewAI、AutoGen、Google ADK、Dapr Agents)。尽管 LangGraph 提供了更高的控制力,但其复杂性使其不太适合一般用途。
如果您的首要目标是易用性、灵活性和代理式开发中的快速迭代,那么根据表格显示,OpenAI Agents SDK 明显胜出。然而,如果您需要企业级功能(如 Dapr Agents)或对复杂工作流进行最大程度的控制(如 LangGraph),尽管这些选项会增加复杂性,您仍可以考虑它们。
DACA 代理式 AI 核心课程:
AI-201:代理式 AI 基础与 DACA AI 首选开发(14 周)
- 代理式与 DACA 理论 - 1 周
- UV 与 OpenAI Agents SDK - 5 周
- 代理式设计模式 - 2 周
- 记忆 [LangMem 和 mem0] 1 周
- Postgres/Redis(托管云)- 1 周
- FastAPI(基础)- 2 周
- 容器化(Rancher Desktop)- 1 周
- Hugging Face Docker Spaces - 1 周
注:这些视频仅供额外学习之用,并不涵盖现场课程教授的所有内容。
先决条件:成功完成 AI-101:现代 AI Python 编程——通往智能系统的起点
AI-202:DACA 云首选代理式 AI 开发(14 周)
- Rancher Desktop 与本地 Kubernetes - 4 周
- 高级 FastAPI 与 Kubernetes - 2 周
- Dapr [工作流、状态、发布/订阅、密钥] - 3 周
- CockRoachdb 和 RabbitMQ 托管服务 - 2 周
- 模型上下文协议 - 2 周
- 无服务器容器部署(ACA)- 2 周
先决条件:成功完成 AI-201
AI-301 DACA 行星规模分布式 AI 代理(14 周)
- 认证 Kubernetes 应用开发者(CKAD)- 4 周
- A2A 协议 - 2 周
- 语音代理 - 2 周
- Dapr Agents/Google ADK - 2 周
- 自主 LLM 托管 - 1 周
- LLM 微调 - 3 周
先决条件:成功完成 AI-201 和 AI-202
评估
测验 + 黑客马拉松(全部为现场形式)
- 高级现代 Python(包括 asyncio)[Q1]
- OpenAI Agents SDK(48 道多项选择题,2 小时)[01_ai_agents_first]
- 协议与设计模式(A2A 和 MCP)[05_ai_protocols]
- 黑客马拉松1 - 8 小时(使用上述测验内容)
- 容器化 + FastAPI [05_daca_agent_native_dev = 01 + 02 ]
- Kubernetes(Rancher Desktop)[模拟] [05_daca_agent_native_dev = 02 ]
- Dapr-1 - 状态、发布/订阅、绑定、调用 [05_daca_agent_native_dev = 03 ]
- Dapr-2 - 工作流、虚拟演员 [04_agent_native = 04, 05, 06]
- 黑客马拉松2 - 8 小时(代理原生初创项目)
- CKAD + DAPR + ArgoCD(模拟)[06_daca_deployment_guide + 07_ckad]
测验详情
智能体AI基础测验
总题数:48道单选题
时长:120分钟
难度等级:中级或高级(非初级)
这是一份结构严谨、内容全面的测验,能够准确评估对OpenAI Agents SDK的深入理解。然而,其难度远超一般的初级水平考核。
面向初学者的难度分析
该测验对初学者而言具有较大挑战性,主要原因如下:
技术深度:题目要求理解OpenAI Agents SDK的架构(如Agent、Tool、Handoff、Runner等模块)、Pydantic模型、异步编程以及提示工程等内容。这些主题对于刚接触AI或Python的新手来说属于较高阶的知识点。
概念复杂度:动态指令、上下文管理、错误处理及思维链式提示等概念,既涉及理论层面的理解,也要求具备实际应用能力,对智能体AI的整体架构有较深的认识。
代码分析:许多题目需要分析代码片段、理清执行流程并预测结果,这对Python编程能力和调试技巧提出了较高要求。
领域知识:虽然关于Markdown的题目相对简单,但大部分题目仍聚焦于SDK的特定功能,使得整套试题的专业性较强。
初学者面临的困难:对于仅有基础Python知识且缺乏AI经验的初学者而言,SDK中的Runner.run_sync、tool_choice、Pydantic验证等概念,以及异步编程和多智能体协作流程,都将是巨大的挑战。
难度评级:高级(不适合初学者)。若想在本测验中取得好成绩,初学者需先掌握Python、异步编程和大语言模型的基础知识,并接受专门的OpenAI Agents SDK培训。
要在这次测验中脱颖而出,建议重点理解OpenAI Agents SDK的核心组件与设计理念,例如其“以Python为中心”的编排设计、Agent与Tool的角色分工,以及通过“Handoff”机制实现多智能体协作的原理。同时,还需深入研究SDK如何管理智能体循环、处理工具调用与Pydantic模型的类型化输入输出,以及使用上下文对象的方式。此外,应熟悉动态指令、智能体克隆、工具执行过程中的错误处理,以及Runner.run_sync()与流式输出的区别等知识点。最后,务必复习提示工程的相关技巧,包括如何撰写清晰的指令、引导智能体的推理过程(如思维链式提示),以及通过角色设定和谨慎的提示策略来保护敏感数据。另外,请确保熟练掌握Markdown的基本语法,尤其是链接和图片的插入方法。
针对初学者的备考指南
本次OpenAI Agents SDK测验专为中级至高级学习者设计,需要充分的准备才能顺利通过。在参加此测试之前,务必扎实掌握Python编程基础,包括面向对象编程、async/await异步模式、装饰器及错误处理等核心内容。同时,需深入学习Pydantic模型的数据验证机制,理解字段定义、默认值及验证行为。请花大量时间研读OpenAI Agents SDK官方文档(https://openai.github.io/openai-agents-python/),重点关注Agent、Tool、Handoff、上下文管理以及智能体执行循环等核心概念。建议动手编写并分析使用@function_tool装饰器、Runner.run_sync()、智能体克隆及多智能体编排模式的代码。此外,还应回顾OpenAI提示工程手册中的相关技巧,特别是思维链式提示、系统消息设计以及敏感数据的处理方法。最后,务必熟悉Markdown的基本语法,用于插入链接和图片。建议至少预留2至3周时间系统学习上述内容,并完成SDK相关的实践练习。请将此次测验视为一项综合性考核,而非入门级的概念介绍,它要求考生对相关知识有全面而深入的理解。
测验覆盖范围:
https://openai.github.io/openai-agents-python/
https://cookbook.openai.com/examples/gpt4-1_prompting_guide
https://www.markdownguide.org/basic-syntax/
https://www.markdownguide.org/cheat-sheet/
https://github.com/panaversity/learn-agentic-ai/tree/main/01_ai_agents_first
可使用以下提示从LLM生成模拟测验以供练习:
请创建一份涵盖OpenAI Agents SDK的综合性测验。测验应包含足够数量的单选题,以全面考察所学内容;题目难度应达到研究生水平,既考查概念理解,又结合必要的代码分析。参考以下文档:
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。