epub_to_audiobook
epub_to_audiobook 是一款将 EPUB 电子书一键转换为有声书的开源工具,专为 Audiobookshelf 等本地听书平台优化。它解决了用户无法直接将静态电子书转化为高质量音频、难以在家庭媒体库中便捷管理章节的痛点,让阅读体验从“看”延伸至“听”。
这款工具非常适合希望建立个人有声图书馆的普通读者、Audiobookshelf 用户,以及喜欢折腾命令行或 Docker 的技术爱好者。无需复杂的音频编辑技能,只需简单配置即可生成带章节元数据的 MP3 文件,导入后能自动识别章节标题,极大提升了导航与收听体验。
其技术亮点在于灵活支持多种语音合成引擎:既可选用微软 Azure 和 OpenAI 的高自然度商用 API,也能使用完全免费的 EdgeTTS,甚至支持本地部署的 Piper 和 Kokoro 模型,兼顾音质、成本与隐私需求。此外,项目最近更新了 Web 图形界面,降低了使用门槛,让非开发者也能轻松上手。无论你想利用碎片时间“听”完经典名著,还是为视障朋友制作无障碍读物,epub_to_audiobook 都是一个高效、自由且可定制的解决方案。
使用场景
一位通勤时间较长的职场人士希望利用碎片时间“阅读”技术类 EPUB 电子书,但缺乏合适的有声资源。
没有 epub_to_audiobook 时
- 只能依赖人工朗读录制或昂贵的商业有声书平台,大量专业领域的 EPUB 书籍根本找不到对应的音频版本。
- 若尝试自行转换,往往得到单个巨大的音频文件,无法识别章节标题,导致在播放时难以定位具体内容,跳转极其不便。
- 手动分割音频并编辑元数据耗时耗力,且难以与自建的 Audiobookshelf 媒体库完美兼容,同步进度和封面显示经常出错。
- 可选的免费 TTS 工具音质机械生硬,长时间收听容易疲劳,而配置高质量语音引擎的技术门槛又过高。
使用 epub_to_audiobook 后
- 直接通过命令行或新增的 WebUI 界面,一键将本地 EPUB 书籍转换为高保真有声书,支持 Azure、OpenAI 等多种优质语音引擎。
- 自动解析原书结构,将每个章节独立生成 MP3 文件,并精准提取章节标题作为元数据,实现毫秒级章节跳转。
- 输出格式专为 Audiobookshelf 优化,导入后自动匹配封面、作者及章节信息,无缝融入个人媒体库,多设备同步流畅。
- 无需复杂的环境配置,利用 Docker 或简单的 Python 环境即可运行,让非技术人员也能轻松制作专属的高质量有声读物。
epub_to_audiobook 将静态的电子书瞬间转化为结构清晰、音质自然的个性化有声库,彻底释放了通勤与家务时间的学习潜力。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明
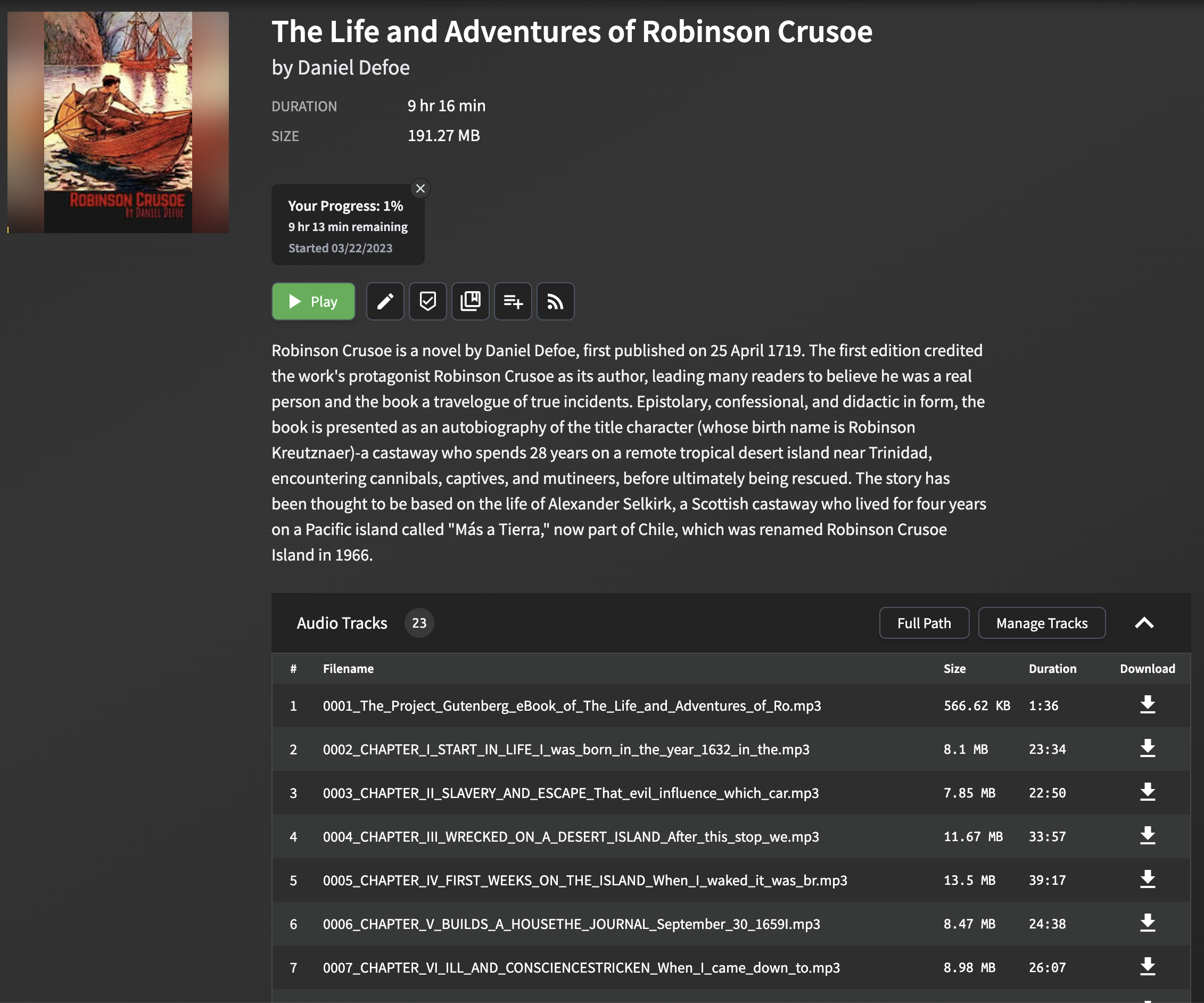
快速开始
EPUB 转有声书转换器 

如有任何问题或讨论,请加入我们的 Discord 服务器。您也可以在 DeepWiki 上提问关于该项目的问题。
本项目提供了一个命令行工具,用于将 EPUB 电子书转换为有声书。它现在支持 Microsoft Azure 文本转语音 API(或者 EdgeTTS)以及 OpenAI 文本转语音 API,以生成电子书中每一章的音频。输出的音频文件经过优化,可与 Audiobookshelf 配合使用。
最新更新
- 2025-05-23:为项目添加了网页界面 (WebUI)。
音频示例
如果您有兴趣试听由该工具生成的有声书样本,请查看下方链接。
- Azure TTS 示例
- OpenAI TTS 示例
- Edge TTS 示例:语音几乎与 Azure TTS 相同
- Piper TTS
- Kokoro TTS(使用时需通过本地 OpenAI 端点)
系统要求
- Python 3.10+ 或 Docker
- 使用 Azure TTS 时,需要拥有 Microsoft Azure 帐户,并具备访问 Microsoft Cognitive Services Speech Services 的权限。
- 使用 OpenAI TTS 时,需要 OpenAI 的 API 密钥。
- 如果您使用 Kokoro TTS,则不需要官方的 OpenAI 密钥,但需要在环境变量中设置一个占位值。(例如
export OPENAI_API_KEY='fake'),除非您使用下面提供的 docker-compose 文件。
- 如果您使用 Kokoro TTS,则不需要官方的 OpenAI 密钥,但需要在环境变量中设置一个占位值。(例如
- 使用 Edge TTS 时,无需 API 密钥。
- Piper TTS 可执行文件及模型。
Audiobookshelf 集成
本项目生成的有声书已针对 Audiobookshelf 进行优化。EPUB 文件中的每一章都会被转换为单独的 MP3 文件,并提取章节标题作为元数据嵌入其中。
章节标题
从 EPUB 文件中解析和提取章节标题可能具有挑战性,因为不同电子书的格式和结构可能存在很大差异。脚本采用了一种简单而有效的方法来提取章节标题,适用于大多数 EPUB 文件。该方法会解析 EPUB 文件,并在每个章节的 HTML 内容中查找 title 标签。如果未找到 title 标签,则会根据章节文本的前几句话生成一个备用标题。
请注意,这种方法可能无法完美适用于所有 EPUB 文件,尤其是那些格式复杂或不寻常的文件。然而,在大多数情况下,它提供了一种可靠的方式来提取章节标题,以便在 Audiobookshelf 中使用。
当您将生成的 MP3 文件导入 Audiobookshelf 时,章节标题将会显示出来,方便您在各章节之间导航,从而提升您的收听体验。
安装
克隆此仓库:
git clone https://github.com/p0n1/epub_to_audiobook.git cd epub_to_audiobook创建虚拟环境并激活:
python3 -m venv venv source venv/bin/activate安装所需的依赖项:
pip install -r requirements.txt注意:Python 3.14 需要使用本仓库中更新的依赖包。较旧的安装版本固定了
gradio==5.33.1,这可能会强制进行pydantic-core的源码构建,并在安装过程中因 PyO3 兼容性错误而失败。设置以下环境变量,填入您的 Azure 文本转语音 API 凭证,或者如果您使用 OpenAI TTS,则填写您的 OpenAI API 密钥:
export MS_TTS_KEY=<your_subscription_key> # 用于 Azure export MS_TTS_REGION=<your_region> # 用于 Azure export OPENAI_API_KEY=<your_openai_api_key> # 用于 OpenAI
网页界面 (WebUI)
对于喜欢图形化界面的用户,本项目包含一个基于 Gradio 构建的网页 UI。WebUI 提供了一种直观的方式来配置所有选项,并在无需使用命令行的情况下转换您的 EPUB 文件。
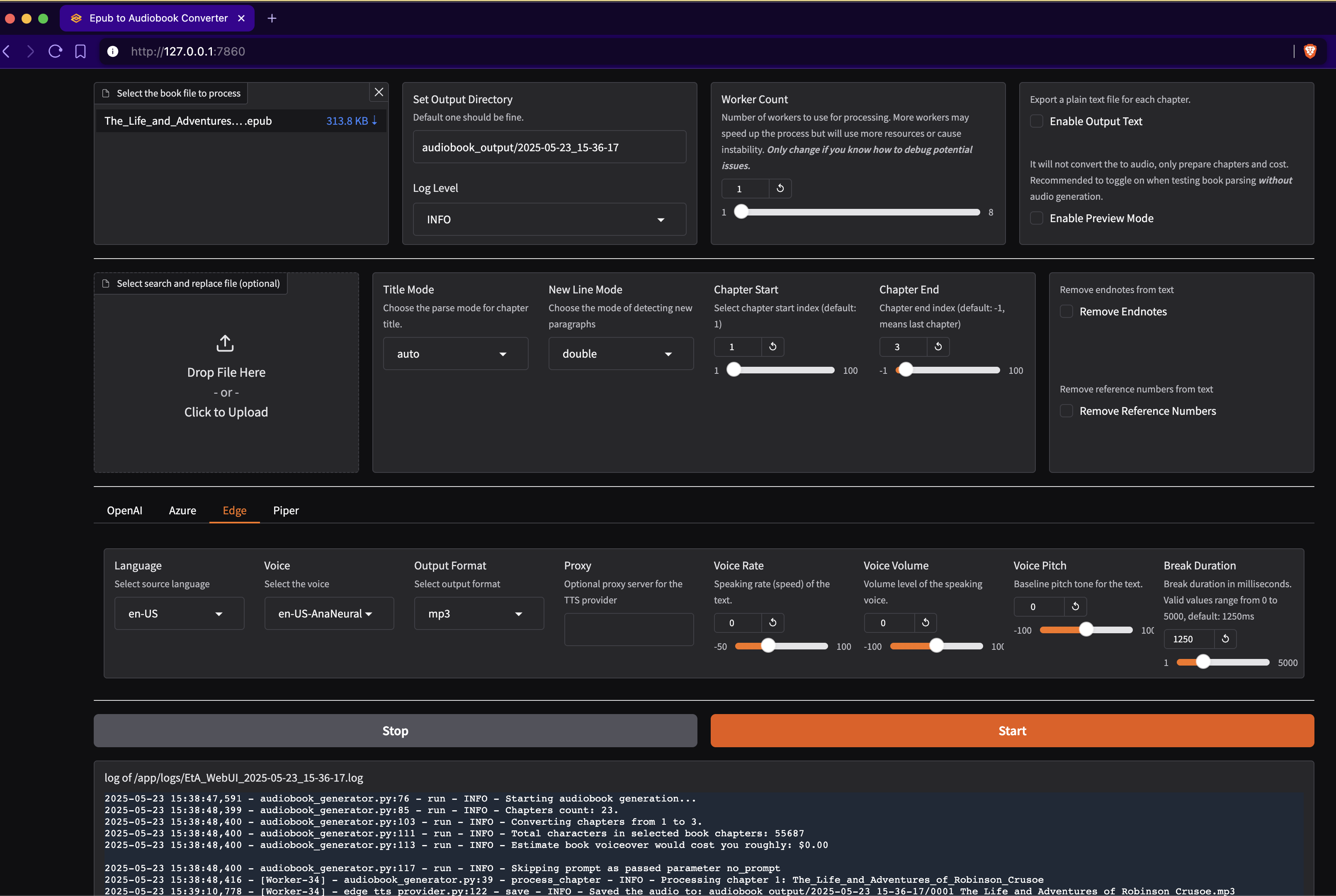
WebUI 的环境变量
WebUI 尊重与命令行工具相同的环境变量:
export MS_TTS_KEY=<your_subscription_key> # 用于 Azure TTS
export MS_TTS_REGION=<your_region> # 用于 Azure TTS
export OPENAI_API_KEY=<your_openai_api_key> # 用于 OpenAI TTS
export OPENAI_BASE_URL=<custom_endpoint> # 可选:用于自定义的 OpenAI 兼容端点
请确保在启动 WebUI 之前,已为您使用的服务正确设置环境变量。
启动 WebUI
请务必在启动 WebUI 之前完成 安装 步骤。
要启动网页界面,请运行:
python3 main_ui.py
默认情况下,WebUI 将在 http://127.0.0.1:7860 上可用。您可以自定义主机和端口:
python3 main_ui.py --host 127.0.0.1 --port 8080
完成后,记得在终端中按 Ctrl+C 来停止服务器。
WebUI 功能
网页界面提供:
- 文件上传:直接将 EPUB 文件拖放到浏览器中
- TTS 提供商选择:轻松切换 Azure、OpenAI、Edge 和 Piper TTS,并提供特定于提供商的选项
- 语音配置:下拉菜单可用于选择语言、声音和输出格式
- 高级设置:所有命令行选项均可通过网页界面访问
- 实时日志:可在浏览器中直接查看转换进度和日志
- 预览模式:无需生成音频即可测试您的设置
- 搜索与替换:上传文本替换文件以修正发音
使用 WebUI
- 使用文件选择器 上传你的 EPUB 文件
- 从选项卡中 选择你的 TTS 提供商(OpenAI、Azure、Edge 或 Piper)
- 配置提供商特定的设置:
- OpenAI:选择模型、语音、语速和格式
- Azure:选择语言、语音、格式和停顿时长
- Edge:设置语言、语音、速率、音量和音高
- Piper:配置本地或 Docker 部署,并选择语音选项
- 设置 输出目录,或使用默认的时间戳文件夹
- 如有需要,调整高级选项(章节范围、文本处理等)
- 点击 开始 以启动转换
- 通过集成的日志查看器 监控进度
在开始完整转换之前,你可以选择几个章节来预览音频。
使用 Docker 运行 WebUI(如果你熟悉 Docker 的最简单方式)
你也可以使用 Docker 来运行 WebUI。请使用提供的 docker-compose.webui.yml 文件,并确保用你的 TTS 提供商的 API 密钥编辑该文件。
# 使用你的 API 密钥编辑 docker-compose.webui.yml 文件
docker compose -f docker-compose.webui.yml up
WebUI 将可以通过 http://localhost:7860 或 http://127.0.0.1:7860 访问。
WebUI 的安全注意事项
WebUI 是一个在你的本地机器上运行的 Web 应用程序。目前它并未设计为可从公共互联网访问。系统中没有授权机制。因此,你不应将其暴露到公共互联网上,否则可能导致对你的 TTS 提供商的未授权访问。
使用方法
要将 EPUB 电子书转换为有声书,请运行以下命令,并使用 --tts 选项指定你选择的 TTS 提供商:
python3 main.py <输入文件> <输出文件夹> [选项]
要查看此脚本的最新选项说明,可以在终端中运行以下命令:
python3 main.py -h
用法:main.py [-h] [--tts {azure,openai,edge,piper}]
[--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}] [--preview]
[--no_prompt] [--language LANGUAGE]
[--newline_mode {single,double,none}]
[--title_mode {auto,tag_text,first_few}]
[--chapter_start CHAPTER_START] [--chapter_end CHAPTER_END]
[--output_text] [--remove_endnotes]
[--search_and_replace_file SEARCH_AND_REPLACE_FILE]
[--worker_count WORKER_COUNT]
[--voice_name VOICE_NAME] [--output_format OUTPUT_FORMAT]
[--model_name MODEL_NAME] [--voice_rate VOICE_RATE]
[--voice_volume VOICE_VOLUME] [--voice_pitch VOICE_PITCH]
[--proxy PROXY] [--break_duration BREAK_DURATION]
[--piper_path PIPER_PATH] [--piper_speaker PIPER_SPEAKER]
[--piper_sentence_silence PIPER_SENTENCE_SILENCE]
[--piper_length_scale PIPER_LENGTH_SCALE]
input_file output_folder
将文字书籍转换为有声书
位置参数:
input_file EPUB 文件的路径
output_folder 输出文件夹的路径
选项:
-h, --help 显示此帮助信息并退出
--tts {azure,openai,edge,piper}
选择TTS提供商(默认:azure)。azure:Azure 认知服务,openai:OpenAI TTS API。使用 azure 时,必须设置环境变量 MS_TTS_KEY 和 MS_TTS_REGION。使用 openai 时,必须设置环境变量 OPENAI_API_KEY。
--log {DEBUG,INFO,WARNING,ERROR,CRITICAL}
日志级别(默认:INFO),可选 DEBUG、INFO、WARNING、ERROR、CRITICAL
--preview 启用预览模式。在预览模式下,脚本不会将文本转换为语音,而是会打印章节索引、标题和字符数。
--no_prompt 在估算 TTS 的云成本后,不再询问用户是否继续。适用于脚本化操作。
--language LANGUAGE 文本转语音服务的语言(默认:en-US)。对于 Azure TTS(--tts=azure),请参阅 https://learn.microsoft.com/en-us/azure/ai-services/speech-service/language-support?tabs=tts#text-to-speech 查看支持的语言。对于 OpenAI TTS(--tts=openai),其 API 会自动检测语言。但设置此选项也有助于本工具以不同策略将文本分割成块,尤其适用于中文文本。对于中文书籍,请使用 zh-CN、zh-TW 或 zh-HK。
--newline_mode {single,double,none}
选择检测新段落的模式:“single”、“double”或“none”。“single”表示单个换行符,“double”表示连续两个换行符。“none”表示所有换行符都将被替换为空格,因此不会检测到段落。(默认:double,对大多数电子书有效,但对部分电子书可能检测到的段落数较少)
--title_mode {auto,tag_text,first_few}
选择章节标题的解析模式:“tag_text”会搜索“title”、“h1”、“h2”、“h3”标签作为标题;“first_few”则将前60个字符设为标题;“auto”会自动应用最适合当前章节的模式。
--chapter_start CHAPTER_START
章节起始索引(默认:1,从1开始)
--chapter_end CHAPTER_END
章节结束索引(默认:-1,表示到最后一章)
--output_text 启用输出文本功能。这将为每个指定的章节导出一个纯文本文件,并将其写入指定的输出文件夹。
--remove_endnotes 这将移除句末或句中的尾注编号。这对于学术类书籍非常有用。
--search_and_replace_file SEARCH_AND_REPLACE_FILE
包含每行一条正则替换规则的文件路径,用于修正发音等问题。格式为:<搜索>==<替换>。请注意,可能需要指定单词边界,以避免替换单词的一部分。
--worker_count WORKER_COUNT
指定用于生成有声书的并行工作进程数量。增加此值可以显著加快处理速度,因为多个章节可以同时处理。注意:章节可能不会按顺序处理,但这不会影响最终的有声书。
--voice_name VOICE_NAME
不同的 TTS 提供商有不同的语音名称,请查阅相应提供商的设置。
--output_format OUTPUT_FORMAT
文本转语音服务的输出格式。支持的格式取决于所选的 TTS 提供商。
--model_name MODEL_NAME
不同的 TTS 提供商有不同的神经网络模型名称。
OpenAI 特定选项:
--speed SPEED 生成音频的速度。取值范围为 0.25 至 4.0。默认值为 1.0。
--instructions INSTRUCTIONS
TTS 模型的指令。仅适用于 “gpt-4o-mini-tts” 模型。
Edge 特定选项:
--voice_rate VOICE_RATE
文本的语速。有效相对值范围为 -50%(--xxx='-50%')至 +100%。负值需使用 --arg=value 格式。
--voice_volume VOICE_VOLUME
说话声音量。有效相对值最低可达 -100%。负值需使用 --arg=value 格式。
--voice_pitch VOICE_PITCH
文本的基础音高。有效相对值如 -80Hz、+50Hz,音高变化应在原音频的 0.5 至 1.5 倍范围内。负值需使用 --arg=value 格式。
--proxy PROXY TTS 提供商的代理服务器。格式:http://[username:password@]proxy.server:port
Azure/Edge 特定选项:
--break_duration BREAK_DURATION
不同段落或章节之间的停顿时间,单位为毫秒(默认:1250,即1.25秒)。Azure TTS 的有效值范围为0至5000毫秒。
Piper 特定选项:
--piper_path PIPER_PATH
Piper TTS 可执行文件的路径。
--piper_speaker PIPER_SPEAKER
Piper 演讲者ID,用于多演讲者模型。
--piper_sentence_silence PIPER_SENTENCE_SILENCE
每句话后的静默秒数。
--piper_length_scale PIPER_LENGTH_SCALE
音素长度,即语速。
示例:
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder
执行上述命令将生成名为 output_folder 的目录,并使用默认的 TTS 提供器和语音将各章节的 MP3 文件保存到该目录中。生成完成后,您可以将这些音频文件导入 Audiobookshelf 或使用任何您喜欢的音频播放器进行播放。
预览模式
在将 EPUB 文件转换为有声书之前,您可以使用 --preview 选项获取每个章节的摘要。这将为您提供每个章节及总文本的字符数,而不会进行文本转语音处理。
示例:
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --preview
搜索与替换
您可能希望搜索并替换文本,以扩展缩写或帮助发音。可以通过指定一个搜索和替换文件来实现,该文件每行包含一个正则表达式搜索和替换规则,用 == 分隔:
示例:
search.conf:
# 这是一般结构
<搜索>==<替换>
# 这是注释
# 修正方位缩写
N\.E\.==north east
# 使用正则表达式时要小心,因为这也会匹配 Sally N. Smith
N\.==north
# 按照当地人的发音念“Barbadoes”
Barbadoes==Barbayduss
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --search_and_replace_file search.conf
示例:
python3 main.py examples/The_Life_and_Adventures_of_Robinson_Crusoe.epub output_folder --preview
使用 Docker
此工具提供 Docker 镜像,方便运行,无需管理 Python 依赖项。
首先,请确保您的系统已安装 Docker。
您可以从 GitHub Container Registry 拉取 Docker 镜像:
docker pull ghcr.io/p0n1/epub_to_audiobook:latest
然后,您可以使用以下命令运行该工具:
docker run -i -t --rm -v ./:/app -e MS_TTS_KEY=$MS_TTS_KEY -e MS_TTS_REGION=$MS_TTS_REGION ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts azure
对于 OpenAI,您可以运行:
docker run -i -t --rm -v ./:/app -e OPENAI_API_KEY=$OPENAI_API_KEY ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts openai
请将 $MS_TTS_KEY 和 $MS_TTS_REGION 替换为您 Azure 文本转语音 API 的凭据。将 $OPENAI_API_KEY 替换为您 OpenAI 的 API 密钥。将 your_book.epub 替换为输入 EPUB 文件的名称,将 audiobook_output 替换为您希望保存输出文件的目录名称。
-v ./:/app 选项会将当前目录(.)挂载到 Docker 容器中的 /app 目录。这样,工具就可以读取输入文件并将输出文件写入您的本地文件系统。
-i 和 -t 选项是必需的,用于启用交互模式并分配伪 TTY。
您还可以查看 此示例配置文件 以了解如何使用 Docker Compose。
Windows 用户友好指南
对于 Windows 用户,尤其是不熟悉命令行工具的用户,我们为您准备了专门的指南,帮助您轻松上手。
请参阅这份逐步指南,如果您遇到任何问题,请留言告诉我们。
如何获取 Azure 认知服务密钥?
- Azure 订阅 — 免费创建一个
- 在 Azure 门户中创建语音资源。
- 获取语音资源的密钥和区域。语音资源部署完成后,选择“转到资源”以查看和管理密钥。有关认知服务资源的更多信息,请参阅获取资源的密钥。
如何获取 OpenAI API 密钥?
✨ 关于 Edge TTS
Edge TTS 和 Azure TTS 几乎相同,区别在于 Edge TTS 不需要 API 密钥,因为它基于 Edge 的朗读功能,且参数稍有限制,例如自定义 SSML。
请访问 https://gist.github.com/BettyJJ/17cbaa1de96235a7f5773b8690a20462 查看支持的语音。
如果您想快速试用这个项目,强烈推荐使用 Edge TTS。
自定义语音和语言
您可以通过在运行脚本时传递 --voice_name 和 --language 选项来自定义文本转语音转换中使用的语音和语言。
Microsoft Azure 为文本转语音服务提供了多种语音和语言。有关可用选项的列表,请参阅 Microsoft Azure 文本转语音文档。
您还可以在 Azure TTS 语音库 中收听可用语音的样本,以帮助您为有声书选择最佳语音。
例如,如果您想使用英式英语女声进行转换,可以使用以下命令:
python3 main.py <input_file> <output_folder> --voice_name en-GB-LibbyNeural --language en-GB
对于 OpenAI TTS,您可以分别使用 --model_name、--voice_name 和 --output_format 来指定模型、语音和格式选项。
更多示例
以下是一些演示各种选项组合的示例:
使用 Azure TTS 的示例
使用默认设置的基本 Azure 转换
此命令将使用 Azure 的默认 TTS 设置将 EPUB 文件转换为有声书。python3 main.py "path/to/book.epub" "path/to/output/folder" --tts azure带有自定义语言、语音和日志级别 的 Azure 转换
将 EPUB 文件转换为有声书,并指定特定语音以及自定义的日志级别以便调试。python3 main.py "path/to/book.epub" "path/to/output/folder" --tts azure --language zh-CN --voice_name "zh-CN-YunyeNeural" --log DEBUG带有章节范围和停顿时间的 Azure 转换
将 EPUB 文件中指定范围的章节转换为有声书,并在段落之间设置自定义的停顿时间。python3 main.py "path/to/book.epub" "path/to/output/folder" --tts azure --chapter_start 5 --chapter_end 10 --break_duration "1500"
使用 OpenAI TTS 的示例
使用 OpenAI 默认设置的基本转换
此命令将使用 OpenAI 的默认 TTS 设置将 EPUB 文件转换为有声书。python3 main.py "path/to/book.epub" "path/to/output/folder" --tts openai使用高清模型和特定语音的 OpenAI 转换
使用高清 OpenAI 模型和指定的语音选项,将 EPUB 文件转换为有声书。python3 main.py "path/to/book.epub" "path/to/output/folder" --tts openai --model_name "tts-1-hd" --voice_name "fable"启用预览和文本输出的 OpenAI 转换
启用预览模式和文本输出,这将显示章节索引和标题,而不是进行转换,并且还会导出文本。python3 main.py "path/to/book.epub" "path/to/output/folder" --tts openai --preview --output_text
使用与 OpenAI 兼容的服务示例
可以使用与 OpenAI 兼容的服务,例如 matatonic/openedai-speech。在这种情况下,必须设置 OPENAI_BASE_URL 环境变量,否则它将默认使用标准的 OpenAI 服务。虽然兼容的服务可能不需要 API 密钥,但 OpenAI 客户端仍然需要,因此请确保将其设置为一个无效值。
如果您的 OpenAI 兼容服务运行在 http://127.0.0.1:8000 上,并且您已添加了一个名为 skippy 的自定义语音,则可以使用以下命令:
docker run -i -t --rm -v ./:/app -e OPENAI_BASE_URL=http://127.0.0.1:8000/v1 -e OPENAI_API_KEY=nope ghcr.io/p0n1/epub_to_audiobook your_book.epub audiobook_output --tts openai --voice_name=skippy --model_name=tts-1-hd
请向下滚动至下方的 Kokoro TTS 示例,以查看更具体的示例。
使用 Edge TTS 的示例
使用 Edge 默认设置的基本转换
此命令将使用 Edge 的默认 TTS 设置将 EPUB 文件转换为有声书。python3 main.py "path/to/book.epub" "path/to/output/folder" --tts edge使用自定义语言、语音和日志级别进行 Edge 转换
将 EPUB 文件转换为有声书,同时指定语音和自定义日志级别以便调试。python3 main.py "path/to/book.epub" "path/to/output/folder" --tts edge --language zh-CN --voice_name "zh-CN-YunxiNeural" --log DEBUG指定章节范围和停顿时间的 Edge 转换
将 EPUB 文件中指定范围的章节转换为有声书,并在段落之间设置自定义的停顿时间。python3 main.py "path/to/book.epub" "path/to/output/folder" --tts edge --chapter_start 5 --chapter_end 10 --break_duration "1500"
使用 Piper TTS 的示例
请确保已安装 Piper TTS,并拥有 ONNX 模型文件及相应的配置文件。更多信息请参阅 Piper TTS。您可以按照其说明安装 Piper TTS、下载模型和配置文件,先进行试用,然后再尝试以下示例。
此命令将使用最少的参数通过 Piper TTS 将 EPUB 文件转换为有声书。您始终需要指定一个 ONNX 模型文件,并且 piper 可执行文件需位于当前的 $PATH 中。
python3 main.py "path/to/book.epub" "path/to/output/folder" --tts piper --model_name <path_to>/en_US-libritts_r-medium.onnx
您可以通过使用 --piper_path 参数来指定自定义的 piper 可执行文件路径。
python3 main.py "path/to/book.epub" "path/to/output/folder" --tts piper --model_name <path_to>/en_US-libritts_r-medium.onnx --piper_path <path_to>/piper
某些模型支持多种语音,可通过 voice_name 参数进行指定。
python3 main.py "path/to/book.epub" "path/to/output/folder" --tts piper --model_name <path_to>/en_US-libritts_r-medium.onnx --piper_speaker 256
您还可以指定语速(piper_length_scale)和停顿时间(piper_sentence_silence)。
python3 main.py "path/to/book.epub" "path/to/output/folder" --tts piper --model_name <path_to>/en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5
Piper TTS 默认输出 wav 格式的文件(或原始音频),您可以通过 --output_format 参数指定任何合理的格式。opus 和 mp3 是在文件大小和兼容性方面不错的选择。
python3 main.py "path/to/book.epub" "path/to/output/folder" --tts piper --model_name <path_to>/en_US-libritts_r-medium.onnx --piper_speaker 256 --piper_length_scale 1.5 --piper_sentence_silence 0.5 --output_format opus
或者,您也可以使用以下步骤,在 Docker 容器中使用 Piper,从而简化本地运行流程。
- 确保您的系统上已安装 Docker Desktop。请访问 Docker 进行安装,或使用 homebrew 包管理器。
- 下载 Piper 模型和配置文件(详情请参阅 Piper 仓库),并将它们放置在本项目的顶层目录中的
piper_models文件夹内。 - 编辑 docker-compose 文件,进行如下修改:
- 在
piper容器中,将PIPER_VOICE环境变量设置为您下载的模型文件名称。 - 在
piper容器中,将volumes映射到您系统中 Piper 模型的实际位置(如果您使用了第 2 步中提供的目录,则可保持原样)。 - 在
epub_to_audiobook容器中,更新volumes映射,将<path/to/epub/dir/on/host>替换为您主机上 EPUB 文件的实际路径。
- 在
- 从项目根目录运行
PATH_TO_EPUB_FILE=./Your_epub_file.epub OUTPUT_DIR=$(pwd)/path/to/audiobook_output docker compose -f docker-compose.piper-example.yml up --build,请将占位符值和输出目录替换为您所需的 EPUB 源文件和音频输出路径。(务必保留 $(pwd)!)请注意,当前的 docker-compose 配置会自动启动整个流程,完全在容器内完成。如果您希望在容器外运行主 Python 进程,可以取消注释命令command: tail -f /dev/null,然后使用docker exec -it epub_to_audiobook /bin/bash连接到容器并手动运行 Python 脚本(更多详细信息请参阅 docker-compose 文件 中的注释)。
使用 Kokoro TTS 的示例
该脚本中记录的 Kokoro TTS 使用方法是通过一个与 OpenAI 兼容端点的 Docker 镜像来实现的。不过,由于这是一个“自托管”服务,你不需要获取实际的 API 密钥。这需要 Docker 环境,因此如果你的机器上尚未安装 Docker,请按照前面 Piper 部分中的 Docker 安装和设置说明进行操作。
要运行,可以在一个终端标签页中执行以下命令之一:
docker run -p 8880:8880 ghcr.io/remsky/kokoro-fastapi-cpu
或者,如果你的 GPU 能够帮助加速处理,可以运行:
docker run --gpus all -p 8880:8880 ghcr.io/remsky/kokoro-fastapi-gpu
然后在另一个标签页中运行:
export OPENAI_BASE_URL=http://localhost:8880/v1
export OPENAI_API_KEY="fake"
python main.py path/to/epub output-dir --tts openai --voice_name "af_bella(3)+af_alloy(1)" --model_name "tts-1" #你可以用其他任何语音名称替换此处。链接见下文。
请注意,传递 --model_name tts-1 参数是必需的,因为使用当前默认的 model_name 值会导致 Kokoro 出现问题。
另外,你也可以通过 为 Kokoro 准备的 Docker Compose 文件 来完成整个设置。
具体操作如下:用你喜欢的编辑器打开该文件,然后从仓库根目录运行:
PATH_TO_EPUB_FILE=./Your_epub_file.epub OUTPUT_DIR=$(pwd)/path/to/audiobook_output VOICE_NAME=Your_desired_voice docker compose -f docker-compose.kokoro-example.yml up --build
请将占位符值和输出目录分别替换为你想要的 EPUB 源文件、音频输出路径以及你选择的语音名称。
关于可用的语音列表,可以参考 这里,你还可以在 这里 听听这些语音的实际效果。
需要注意的是,当前 Docker Compose 配置会自动在容器内启动整个流程。如果你想在容器外运行主 Python 进程,可以取消注释 command: tail -f /dev/null 这一行,并使用 docker exec -it epub_to_audiobook /bin/bash 连接到容器,手动运行 Python 脚本(更多详情请参阅 Docker Compose 文件 中的注释)。
有关 Kokoro TTS 所使用的镜像的更多信息,请访问此 仓库。
故障排除
ModuleNotFoundError: 没有名为 'importlib_metadata' 的模块
这可能是因为你使用的 Python 版本低于 3.8。你可以尝试手动安装它:pip3 install importlib-metadata,或者升级到更高版本的 Python。
FileNotFoundError: [Errno 2] 没有这样的文件或目录: 'ffmpeg'
请确保你的系统 PATH 中可以找到 ffmpeg 可执行文件。如果你使用的是 macOS 并且安装了 Homebrew,可以运行 brew install ffmpeg;在 Ubuntu 上则可以运行 sudo apt install ffmpeg。
Piper TTS
如遇安装相关问题,请参考 Piper TTS 仓库。需要注意的是,如果通过 pip 安装 piper-tts,目前仅支持 Python 3.10。Mac 用户在使用下载的 二进制文件 时可能会遇到额外的挑战。有关 Mac 特定问题的更多信息,请查看 此议题 和 此拉取请求。
如果你在使用 Piper TTS 时遇到困难,也可以参考 此页面。
相关项目
- Epub to Audiobook (M4B): 将 EPUB 转换为 M4B 格式的有声书,使用 HuggingFace Spaces API 结合 StyleTTS2。
- Storyteller:一个用于自动同步电子书和有声书的自托管平台。
许可证
本项目采用 MIT 许可证授权。详细信息请参阅 LICENSE 文件。
版本历史
v0.8.72026/02/03v0.8.62026/02/03v0.8.52025/08/29v0.8.42025/07/25v0.8.32025/06/27v0.8.22025/06/11v0.8.12025/06/10v0.8.02025/05/23v0.6.12024/06/28v0.6.02024/06/28v0.5.12024/01/23v0.5.02024/01/11v0.4.32023/11/22v0.4.22023/11/15v0.4.12023/11/11v0.4.02023/11/10v0.3.02023/11/10v0.2.02023/09/20v0.1.02023/09/18常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
spec-kit
Spec Kit 是一款专为提升软件开发效率而设计的开源工具包,旨在帮助团队快速落地“规格驱动开发”(Spec-Driven Development)模式。传统开发中,需求文档往往与代码实现脱节,导致沟通成本高且结果不可控;而 Spec Kit 通过将规格说明书转化为可执行的指令,让 AI 直接依据明确的业务场景生成高质量代码,从而减少从零开始的随意编码,确保产出结果的可预测性。 该工具特别适合希望利用 AI 辅助编程的开发者、技术负责人及初创团队。无论是启动全新项目还是在现有工程中引入规范化流程,用户只需通过简单的命令行操作,即可初始化项目并集成主流的 AI 编程助手。其核心技术亮点在于“规格即代码”的理念,支持社区扩展与预设模板,允许用户根据特定技术栈定制开发流程。此外,Spec Kit 强调官方维护的安全性,提供稳定的版本管理,帮助开发者在享受 AI 红利的同时,依然牢牢掌握架构设计的主动权,真正实现从“凭感觉写代码”到“按规格建系统”的转变。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。