heretic
Heretic 是一款开源命令行程序,专为“一键去审查”而生:它能自动把经过安全对齐、动辄拒绝回答敏感话题的大模型,还原成几乎不再说“对不起,我无法回答”的版本,却又不牺牲原有智力。传统做法需要昂贵微调或人工调参,而 Heretic 通过“方向消融(abliteration)”技术,自动搜索最优参数,在减少拒答率的同时,把与原模型的差异(KL 散度)压到最低,全程无需了解 Transformer 内部细节。
只需一行指令,普通用户、开发者或研究人员就能把 Hugging Face 上的模型变成“去限制”版本,并立即用内置脚本验证效果。它已在 Gemma-3-12B 等模型上实现 97% 拒答率的显著下降,且对无害问题的回答几乎保持原样。如果你希望本地大模型更坦率、研究对齐机制,或需要无过滤语料做实验,Heretic 是目前最省心、效果可复现的选择。
使用场景
一位独立开发者正在构建本地化的历史研究助手,需要模型能够客观分析包含暴力或争议性描述的原始史料,而不受安全过滤机制的干扰。
没有 heretic 时
- 关键信息缺失:当输入涉及战争细节或敏感政治事件的历史文献时,模型频繁拒绝回答,导致研究链条中断。
- 人工调优门槛高:若想手动移除安全对齐(Abliteration),开发者需深入理解 Transformer 内部结构并编写复杂代码,耗时数周且极易出错。
- 智能程度受损:强行通过提示词绕过限制往往导致模型逻辑混乱,或在回答无害问题时也出现能力下降,无法保持原有的语言理解力。
- 迭代成本昂贵:每次调整参数都需要重新进行昂贵的后训练或微调,对个人开发者的算力资源是巨大负担。
使用 heretic 后
- 无阻碍深度分析:heretic 自动移除了审查机制,模型能直接引用史料中的原始措辞生成详细表格和分析,不再对敏感话题说“不”。
- 全自动一键处理:无需任何深度学习背景,只需运行一行命令行指令,heretic 即可利用 Optuna 自动搜索最优参数完成去 censorship。
- 完美保留原模型智力:通过最小化 KL 散度,heretic 生成的版本在去除限制的同时,将模型性能损耗降至最低(如 Gemma 3 案例中 KL 散度仅为 0.16)。
- 零成本快速迭代:完全无需额外的后训练过程,几分钟内即可在本地显卡上生成高质量的去限制模型,大幅降低试错成本。
heretic 让普通开发者也能以零门槛、低成本获得既自由又智能的本地大模型,彻底打破了安全对齐对专业研究的束缚。
运行环境要求
- 未说明
- 需要 NVIDIA GPU(文中提及 RTX 3090, RTX 5090),支持 bitsandbytes 量化以降低显存需求
- 具体显存大小取决于模型,文中示例提到可在 16GB 显存上运行 4B 参数模型
未说明

快速开始

Heretic:面向语言模型的全自动去审查工具



Heretic 是一款无需昂贵后训练即可从基于 Transformer 的语言模型中去除审查(即“安全对齐”)的工具。它将一种先进的方向性消融实现——也称为“abliteration”(参见 Arditi 等人,2024 年;Lai,2025 年,1、2)——与基于 TPE 的参数优化器相结合,而该优化器由 Optuna 提供支持。
这种方法使 Heretic 能够完全自动运行。Heretic 通过同时最小化拒绝次数和与原始模型的 KL 散度来寻找高质量的消融参数,从而生成一个去审查后的模型,并尽可能保留原始模型的智能。使用 Heretic 不需要理解 Transformer 的内部机制。事实上,只要会运行命令行程序的人,就能用 Heretic 对语言模型进行去审查。
在使用默认配置进行无监督运行时,Heretic 可以生成与人类专家手动创建的消融结果质量相当的去审查模型:
| 模型 | 针对“有害”提示的拒绝次数 | 针对“无害”提示的与原始模型的 KL 散度 |
|---|---|---|
| google/gemma-3-12b-it(原始) | 97/100 | 0 (按定义) |
| mlabonne/gemma-3-12b-it-abliterated-v2 | 3/100 | 1.04 |
| huihui-ai/gemma-3-12b-it-abliterated | 3/100 | 0.45 |
| p-e-w/gemma-3-12b-it-heretic(我们的版本) | 3/100 | 0.16 |
Heretic 版本在无需任何人工干预的情况下,实现了与其他消融方法相同的拒绝抑制水平,但其 KL 散度要低得多,表明对原始模型能力的损害更小。(您可以通过 Heretic 内置的评估功能重现这些数值,例如 heretic --model google/gemma-3-12b-it --evaluate-model p-e-w/gemma-3-12b-it-heretic。请注意,具体数值可能因平台和硬件而异。上表是在 RTX 5090 上使用 PyTorch 2.8 编译的。)
当然,数学指标和自动化基准测试永远无法说明全部问题,也无法取代人工评估。使用 Heretic 生成的模型深受用户好评(链接和强调已添加):
“我之前还持怀疑态度,但刚刚下载了 【GPT-OSS 20B Heretic】(https://huggingface.co/p-e-w/gpt-oss-20b-heretic) 模型,天哪!它能针对敏感话题给出格式规范的长回复, 使用的正是您期望从未审查模型中得到的未经审查的措辞, 还能生成带有详细信息等内容的 Markdown 格式表格。看起来这似乎是迄今为止该模型的最佳消融版本……” 【(评论链接)】(https://old.reddit.com/r/LocalLLaMA/comments/1oymku1/heretic_fully_automatic_censorship_removal_for/np6tba6/)
“【Heretic GPT 20b】(https://huggingface.co/p-e-w/gpt-oss-20b-heretic) 似乎是我迄今为止尝试过的最好的未审查模型。它没有破坏模型的智能,而且能够正常回答那些原本会被基础模型拒绝的提示。” 【(评论链接)】(https://old.reddit.com/r/LocalLLaMA/comments/1oymku1/heretic_fully_automatic_censorship_removal_for/npe9jng/)
“【[Qwen3-4B-Instruct-2507-heretic]] 是我在 16GB 显存上运行过的最佳未量化消融模型。” 【(评论链接)】(https://old.reddit.com/r/LocalLLaMA/comments/1phjxca/im_calling_these_people_out_right_now/nt06tji/)
Heretic 支持大多数稠密模型,包括许多多模态模型以及多种 MoE 架构。不过,它目前尚不支持 SSM/混合模型、具有非均匀层的模型,以及某些新型注意力机制。
您可以在 Hugging Face 上找到一小部分已使用 Heretic 去审查的模型集合这里,此外,社区还创建并发布了超过 1,000 个 Heretic 模型。
使用方法
请根据您的硬件情况,准备一个安装了 PyTorch 2.2+ 的 Python 3.10+ 环境。然后运行:
pip install -U heretic-llm
heretic Qwen/Qwen3-4B-Instruct-2507
将 Qwen/Qwen3-4B-Instruct-2507 替换为您想要去审查的任意模型。
整个过程完全自动,无需任何配置;不过,Heretic 提供了多种可更改的配置参数,以便您获得更大的控制权。运行 heretic --help 查看可用的命令行选项,或者如果您更喜欢使用配置文件,可以查看 config.default.toml。
在程序运行开始时,Heretic 会先对系统进行基准测试,以确定最优的批处理大小,从而充分利用现有硬件资源。在 RTX 3090 上,使用默认配置对 Llama-3.1-8B-Instruct 进行去审查大约需要 45 分钟。需要注意的是,Heretic 支持 bitsandbytes 的模型量化功能,这可以大幅减少处理模型所需的显存容量。只需将 quantization 选项设置为 bnb_4bit 即可启用量化。
Heretic 完成模型去审查后,您可以选择保存模型、将其上传至 Hugging Face、与模型聊天以测试其效果,或以上操作的任意组合。
研究功能
除了其主要功能——去除模型审查之外,Heretic 还提供了一些旨在支持模型内部语义研究(即可解释性)的功能。要使用这些功能,您需要在安装 Heretic 时附加 research 选项:
pip install -U heretic-llm[research]
这样您就可以访问以下功能:
通过传递 --plot-residuals 生成残差向量的可视化图
当使用此标志运行时,Heretic 将会:
- 对每个 Transformer 层的第一输出 token,分别计算“有害”和“无害”提示的残差向量(即隐藏状态)。
- 在残差空间中执行 PaCMAP 投影,将其映射到二维空间。
- 按照“有害”与“无害”残差的几何中位数对齐其投影,以使连续各层的投影更加相似。此外,对于每一新层,PaCMAP 都会以前一层的投影作为初始值,从而最大限度地减少突变式的过渡。
- 将这些投影绘制为散点图,并为每一层生成一张 PNG 图像。
- 生成一个动画,展示残差在各层之间的变换过程,以动态 GIF 的形式呈现。
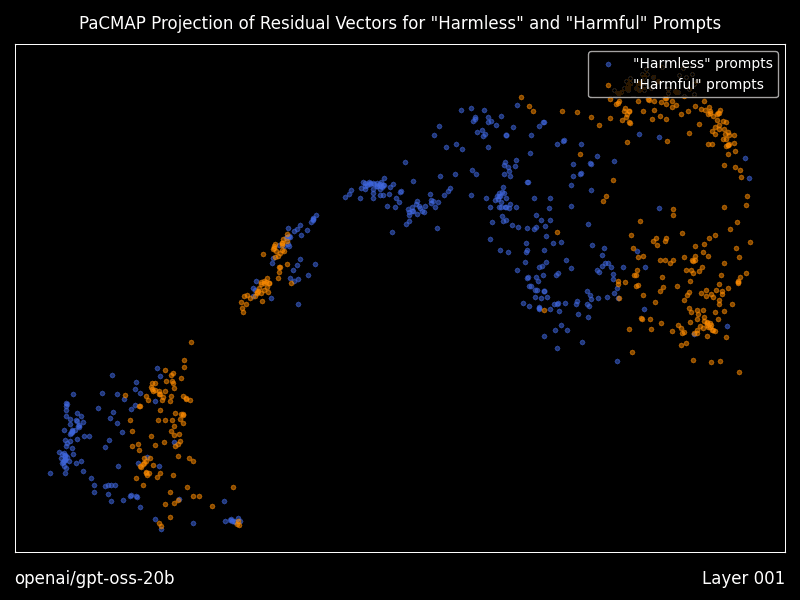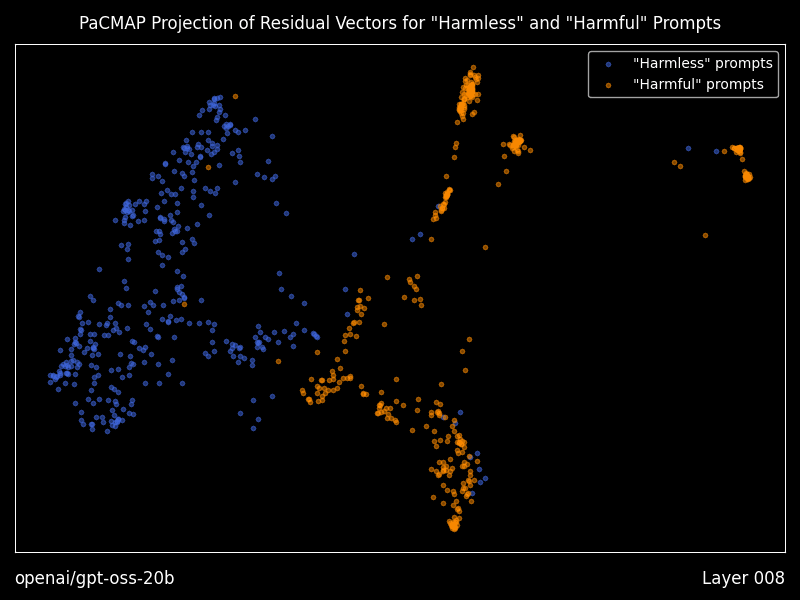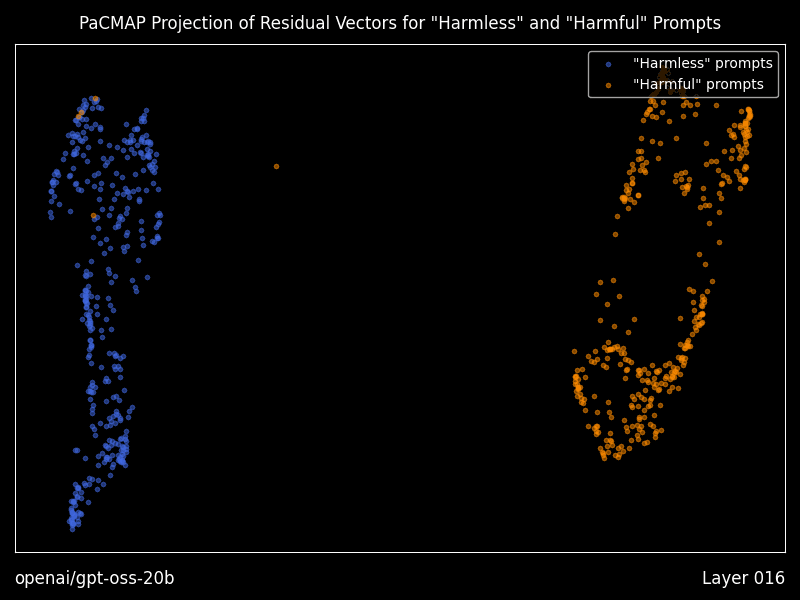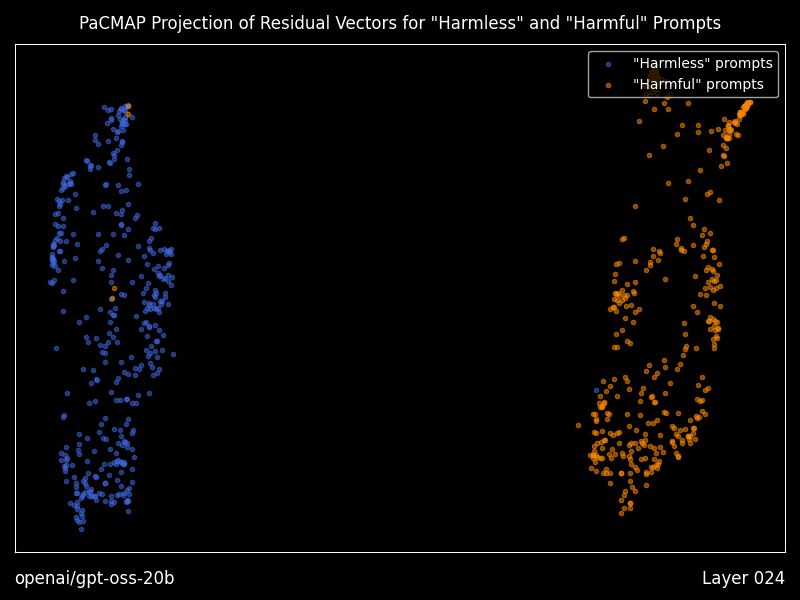
有关控制生成图像各个方面的选项,请参阅配置文件。
请注意,PaCMAP 是一项开销较大的操作,且在 CPU 上执行。对于更大的模型,计算所有层的投影可能需要一小时甚至更久。
通过传递 --print-residual-geometry 打印残差几何的详细信息
如果您希望对“有害”与“无害”提示的残差向量之间的关系进行定量分析,此标志将为您提供如下表格,其中包含大量指标,有助于深入理解这一关系(以 gemma-3-270m-it 为例):
┏━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━┓
┃ 层 ┃ S(g,b) ┃ S(g*,b*) ┃ S(g,r) ┃ S(g*,r*) ┃ S(b,r) ┃ S(b*,r*) ┃ |g| ┃ |g*| ┃ |b| ┃ |b*| ┃ |r| ┃ |r*| ┃ Silh ┃
┡━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━┩
│ 1 │ 1.0000 │ 1.0000 │ -0.4311 │ -0.4906 │ -0.4254 │ -0.4847 │ 170.29 │ 170.49 │ 169.78 │ 169.85 │ 1.19 │ 1.31 │ 0.0480 │
│ 2 │ 1.0000 │ 1.0000 │ 0.4297 │ 0.4465 │ 0.4365 │ 0.4524 │ 768.55 │ 768.77 │ 771.32 │ 771.36 │ 6.39 │ 5.76 │ 0.0745 │
│ 3 │ 0.9999 │ 1.0000 │ -0.5699 │ -0.5577 │ -0.5614 │ -0.5498 │ 1020.98 │ 1021.13 │ 1013.80 │ 1014.71 │ 12.70 │ 11.60 │ 0.0920 │
│ 4 │ 0.9999 │ 1.0000 │ 0.6582 │ 0.6553 │ 0.6659 │ 0.6627 │ 1356.39 │ 1356.20 │ 1368.71 │ 1367.95 │ 18.62 │ 17.84 │ 0.0957 │
│ 5 │ 0.9987 │ 0.9990 │ -0.6880 │ -0.6761 │ -0.6497 │ -0.6418 │ 766.54 │ 762.25 │ 731.75 │ 732.42 │ 51.97 │ 45.24 │ 0.1018 │
│ 6 │ 0.9998 │ 0.9998 │ -0.1983 │ -0.2312 │ -0.1811 │ -0.2141 │ 2417.35 │ 2421.08 │ 2409.18 │ 2411.40 │ 43.06 │ 43.47 │ 0.0900 │
│ 7 │ 0.9998 │ 0.9997 │ -0.5258 │ -0.5746 │ -0.5072 │ -0.5560 │ 3444.92 │ 3474.99 │ 3400.01 │ 3421.63 │ 86.94 │ 94.38 │ 0.0492 │
│ 8 │ 0.9990 │ 0.9991 │ 0.8235 │ 0.8312 │ 0.8479 │ 0.8542 │ 4596.54 │ 4615.62 │ 4918.32 │ 4934.20 │ 384.87 │ 377.87 │ 0.2278 │
│ 9 │ 0.9992 │ 0.9992 │ 0.5335 │ 0.5441 │ 0.5678 │ 0.5780 │ 5322.30 │ 5316.96 │ 5468.65 │ 5466.98 │ 265.68 │ 267.28 │ 0.1318 │
│ 10 │ 0.9974 │ 0.9973 │ 0.8189 │ 0.8250 │ 0.8579 │ 0.8644 │ 5328.81 │ 5325.63 │ 5953.35 │ 5985.15 │ 743.95 │ 779.74 │ 0.2863 │
│ 11 │ 0.9977 │ 0.9978 │ 0.4262 │ 0.4045 │ 0.4862 │ 0.4645 │ 9644.02 │ 9674.06 │ 9983.47 │ 9990.28 │ 743.28 │ 726.99 │ 0.1576 │
│ 12 │ 0.9904 │ 0.9907 │ 0.4384 │ 0.4077 │ 0.5586 │ 0.5283 │ 10257.40 │ 10368.50 │ 11114.51 │ 11151.21 │ 1711.18 │ 1664.69 │ 0.1890 │
│ 13 │ 0.9867 │ 0.9874 │ 0.4007 │ 0.3680 │ 0.5444 │ 0.5103 │ 12305.12 │ 12423.75 │ 13440.31 │ 13432.47 │ 2386.43 │ 2282.47 │ 0.1293 │
│ 14 │ 0.9921 │ 0.9922 │ 0.3198 │ 0.2682 │ 0.4364 │ 0.3859 │ 16929.16 │ 17080.37 │ 17826.97 │ 17836.03 │ 2365.23 │ 2301.87 │ 0.1282 │
│ 15 │ 0.9846 │ 0.9850 │ 0.1198 │ 0.0963 │ 0.2913 │ 0.2663 │ 16858.58 │ 16949.44 │ 17496.00 │ 17502.88 │ 3077.08 │ 3029.60 │ 0.1611 │
│ 16 │ 0.9686 │ 0.9689 │ -0.0029 │ -0.0254 │ 0.2457 │ 0.2226 │ 18912.77 │ 19074.86 │ 19510.56 │ 19559.62 │ 4848.35 │ 4839.75 │ 0.1516 │
│ 17 │ 0.9782 │ 0.9784 │ -0.0174 │ -0.0381 │ 0.1908 │ 0.1694 │ 27098.09 │ 27273.00 │ 27601.12 │ 27653.12 │ 5738.19 │ 5724.21 │ 0.1641 │
│ 18 │ 0.9184 │ 0.9196 │ 0.1343 │ 0.1430 │ 0.5155 │ 0.5204 │ 190.16 │ 190.35 │ 219.91 │ 220.62 │ 87.82 │ 87.59 │ 0.1855 │
└───────┴────────┴──────────┴─────────┴──────────┴─────────┴──────────┴──────────┴──────────┴──────────┴──────────┴─────────┴─────────┴────────┘
g = 好提示的残差向量均值
g* = 好提示的残差向量几何中位数
b = 坏提示的残差向量均值
b* = 坏提示的残差向量几何中位数
r = 均值的拒绝方向(即 b - g)
r* = 几何中位数的拒绝方向(即 b* - g*)
S(x,y) = x 与 y 的余弦相似度
|x| = x 的 L2 范数
Silh = 好/坏聚类残差的平均轮廓系数
Heretic 的工作原理
Heretic 实现了一种参数化的方向性消融方法。对于每个受支持的 Transformer 组件(目前包括注意力输出投影和 MLP 下采样投影),它会在每一层 Transformer 中识别出相关的矩阵,并根据相应的“拒绝方向”对这些矩阵进行正交化处理,从而抑制该方向在与该矩阵相乘后的结果中得以表达。
拒绝方向是针对每一层计算得出的,具体做法是取“有害”与“无害”示例提示的第一 token 残差之间的均值差。
消融过程由若干可优化的参数控制:
direction_index:可以是某个拒绝方向的索引,也可以是特殊值per layer,表示每层都应使用与其对应的拒绝方向进行消融。max_weight、max_weight_position、min_weight和min_weight_distance:对于每个组件,这些参数描述了消融权重核在各层上的形状与位置。下图对此进行了说明:
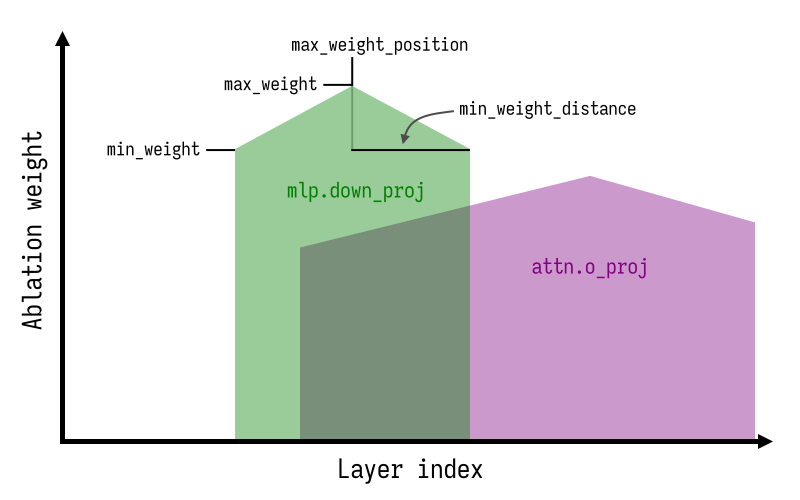
Heretic 相较于现有消融系统的主要创新在于:
- 消融权重核的形状具有高度灵活性,结合自动参数优化,能够更好地平衡合规性与性能之间的权衡。此前,Maxime Labonne 曾在 gemma-3-12b-it-abliterated-v2 中探索过非恒定的消融权重。
- 拒绝方向索引采用浮点数而非整数。对于非整数值,会在线性插值两个最近的拒绝方向向量。这一设计开辟了远超均值差计算所确定方向的广阔新方向空间,并且往往能使优化过程找到比单个层对应方向更优的方向。
- 每个组件的消融参数单独设定。我发现,相较于注意力干预,MLP 干预往往会对模型造成更大的损害,因此采用不同的消融权重能够进一步提升模型性能。
先行技术
我已知以下公开可用的消融技术实现:
需要注意的是,Heretic 是从零开始编写的,未复用上述任何项目的代码。
致谢
Heretic 的开发受到了以下内容的启发:
- 原始消融论文(Arditi 等人,2024)
- Maxime Labonne 关于消融的文章(https://huggingface.co/blog/mlabonne/abliteration),以及他本人消融模型的模型卡片中的部分细节(见上文)
- Jim Lai 描述的“投影消融”(https://huggingface.co/blog/grimjim/projected-abliteration)和“保范双投影消融”(https://huggingface.co/blog/grimjim/norm-preserving-biprojected-abliteration)
引用
如果您在研究中使用 Heretic,请按照以下 BibTeX 条目进行引用:
@misc{heretic,
author = {Weidmann, Philipp Emanuel},
title = {Heretic:面向语言模型的全自动审查移除},
year = {2025},
publisher = {GitHub},
journal = {GitHub 仓库},
howpublished = {\url{https://github.com/p-e-w/heretic}}
}
许可证
版权所有 © 2025–2026 Philipp Emanuel Weidmann (pew@worldwidemann.com) 及其贡献者
本程序为自由软件:您可以重新分发并修改本程序,但须遵守 GNU Affero 通用公共许可证的规定,该许可证由自由软件基金会发布,无论是第 3 版还是后续版本均可。
本程序以“按原样”提供,不提供任何担保;甚至不提供适销性或特定用途适用性的隐含担保。有关详细信息,请参阅 GNU Affero 通用公共许可证。
您应当随本程序收到一份 GNU Affero 通用公共许可证副本。如未收到,请访问 https://www.gnu.org/licenses/。
通过为本项目作出贡献,您同意将自己的贡献也以相同许可证发布。
版本历史
v1.2.02026/02/14v1.1.02025/12/10v1.0.12025/11/16常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。