awesome-model-based-RL
awesome-model-based-RL 是一个专为“基于模型的强化学习”(Model-Based RL)领域打造的精选资源库。它系统性地收集并整理了该方向的核心研究论文、经典算法分类、教程指南以及开源代码实现,旨在帮助从业者快速把握前沿动态。
在强化学习中,传统方法往往需要大量试错,而基于模型的方法通过构建环境模型来规划行动,能显著提升样本效率。然而,该领域文献浩如烟海且更新极快,研究者常面临资料分散、难以追踪最新成果的痛点。awesome-model-based-RL 正是为解决这一难题而生,它不仅持续收录来自 NeurIPS、ICML、ICLR 等顶级会议的最新论文(已更新至 2025 年),还提供了一份清晰的算法分类图谱,将复杂的技术路线梳理为“学习模型”与“利用模型”两大维度,帮助用户建立系统的知识框架。
这份资源特别适合人工智能研究人员、算法工程师以及对深度强化学习感兴趣的高校师生使用。无论是想要入门的新手,还是希望紧跟学术前沿的资深专家,都能在这里找到高质量的参考材料。其独特的价值在于持续的维护更新与结构化的知识整理,让探索高效强化学习之路变得更加清晰顺畅。
使用场景
某自动驾驶初创公司的算法团队正致力于开发基于模型的强化学习(MBRL)策略,以在仿真环境中高效训练车辆应对复杂路况。
没有 awesome-model-based-RL 时
- 文献检索如大海捞针:研究人员需手动在 arXiv、NeurIPS、ICML 等各大会议中筛选论文,耗时数周仍难以覆盖最新的前沿成果,极易遗漏关键突破。
- 技术路线梳理困难:面对“学习模型”与“利用模型”等不同流派,缺乏系统的分类指引,团队难以快速构建清晰的技术演进图谱,导致选型盲目。
- 复现成本高昂:找不到官方代码库或权威教程,新手往往需要从零摸索算法细节,大量时间浪费在调试基础环境而非核心创新上。
- 信息更新滞后:由于缺乏持续维护的渠道,团队无法及时获取如 2025 年最新顶会论文列表,技术栈容易与社区前沿脱节。
使用 awesome-model-based-RL 后
- 一站式获取前沿资源:团队直接查阅按年份和顶会(如 NeurIPS 2025、ICLR 2025)整理的论文清单,几分钟内即可锁定领域内最新的 SOTA 方法。
- 清晰的技术导航:借助仓库提供的算法分类图谱,研究人员迅速理清了 World Models、I2A 等经典与新兴算法的逻辑关系,精准定位适合自动驾驶场景的技术路线。
- 加速落地验证:通过集成的 Codebase 和 Tutorial 链接,工程师直接复用成熟的代码框架,将算法复现周期从数周缩短至几天,大幅降低试错成本。
- 同步社区脉搏:依托仓库的持续更新机制,团队能第一时间掌握每月新增的研究成果,确保技术方案始终处于行业领先地位。
awesome-model-based-RL 将原本分散、滞后的科研资源转化为结构化的知识引擎,极大提升了团队在模型基强化学习领域的研发效率与创新速度。
运行环境要求
未说明
未说明

快速开始
优秀的基于模型的强化学习
![]()



这是一个关于**基于模型的强化学习(mbrl)**的研究论文合集。 该仓库将持续更新,以跟踪基于模型强化学习领域的最新进展。
欢迎关注并点赞!
[2025.12.01] 新增:我们更新了基于模型强化学习的 NeurIPS 2025 论文列表! [2025.08.28] 我们更新了基于模型强化学习的 ICML 2025 论文列表。 [2025.02.06] 我们更新了基于模型强化学习的 ICLR 2025 论文列表。 [2024.10.27] 我们更新了基于模型强化学习的 NeurIPS 2024 论文列表。 [2024.05.20] 我们更新了基于模型强化学习的 ICML 2024 论文列表。 [2023.11.29] 我们更新了基于模型强化学习的 ICLR 2024 论文列表。 [2023.09.29] 我们更新了基于模型强化学习的 NeurIPS 2023 论文列表。 [2023.06.15] 我们更新了基于模型强化学习的 ICML 2023 论文列表。 [2023.02.05] 我们更新了基于模型强化学习的 ICLR 2023 论文列表。 [2022.11.03] 我们更新了基于模型强化学习的 NeurIPS 2022 论文列表。 [2022.07.06] 我们更新了基于模型强化学习的 ICML 2022 论文列表。 [2022.02.13] 我们更新了基于模型强化学习的 ICLR 2022 论文列表。 [2021.12.28] 我们发布了优秀的基于模型强化学习资源。
目录
基于模型强化学习算法分类
在开始本节之前,我们先声明一点:要绘制一个准确且全面的基于模型强化学习算法分类体系确实非常困难,因为算法的模块化特性很难用树状结构来完整表达。因此,我们将发布一系列相关博客,以更深入地介绍各种基于模型强化学习算法。
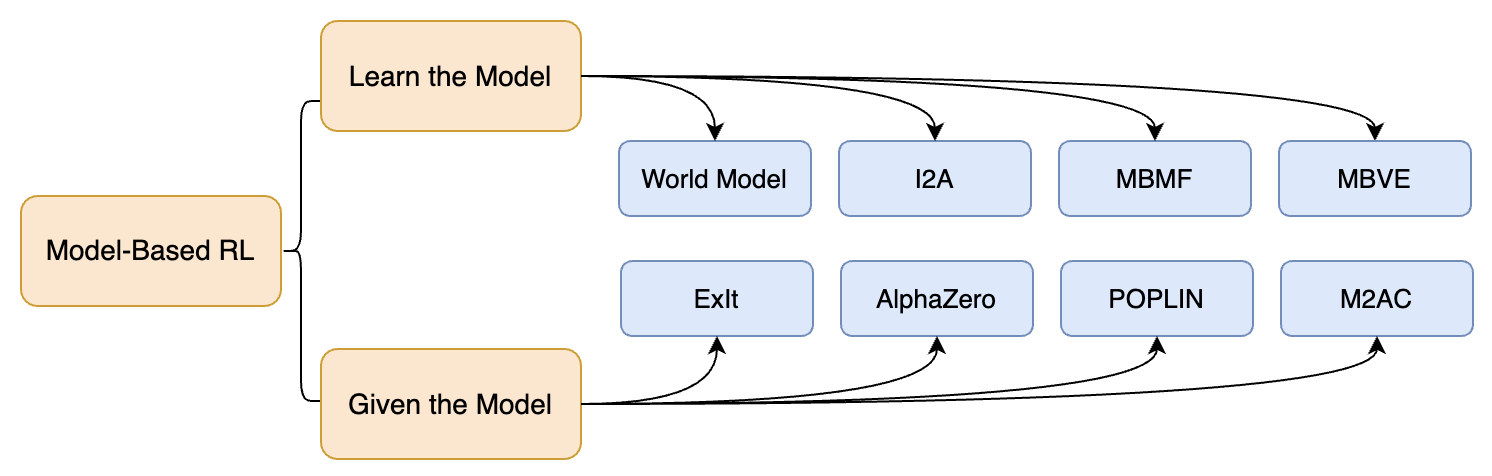
现代基于模型强化学习中一种非详尽但实用的算法分类。
我们简单地将“基于模型强化学习”分为两大类:“学习模型”和“给定模型”。
- “学习模型”主要关注如何构建环境模型。
- “给定模型”则侧重于如何利用已学习到的模型。
如上图所示,我们给出了一些示例,并附上了相关算法的链接。
[1] World Models:Ha 和 Schmidhuber,2018年
[2] I2A(想象增强智能体):Weber 等,2017年
[3] MBMF(结合无模型微调的基于模型强化学习):Nagabandi 等,2017年
[4] MBVE(基于模型的价值扩展):Feinberg 等,2018年
[5] ExIt(专家迭代):Anthony 等,2017年
[6] AlphaZero:Silver 等,2017年
[7] POPLIN(基于模型的策略规划):Wang 等,2019年
[8] M2AC(掩码式基于模型的演员-评论家):Pan 等,2020年
论文
格式:
- [标题](论文链接) [链接]
- 作者1、作者2和作者3
- 关键点:关键问题和见解
- OpenReview:可选
- 实验环境:实验使用的环境
经典基于模型的强化学习论文
展开/折叠
-
- 理查德·萨顿。ACM 1991
- 关键点:dyna架构
- 实验环境:无
-
- 马克·彼得·戴森罗斯特,卡尔·爱德华·拉斯穆森。ICML 2011
- 关键点:概率动力学模型
- 实验环境:倒立摆系统,机器人独轮车
-
- 谢尔盖·列维涅,弗拉季伦·科尔屯。ICML 2014
- 关键点:引导式策略搜索
- 实验环境:mujoco
-
- 尼古拉斯·海斯,格雷格·韦恩,大卫·西尔弗,蒂莫西·利利克拉普,尤瓦尔·塔萨,汤姆·埃雷兹。NIPS 2015
- 关键点:路径反向传播,真实轨迹上的梯度
- 实验环境:mujoco
-
- 欧俊赫,萨廷德·辛格,李洪洛克。NIPS 2017
- 关键点:价值预测模型
- 实验环境:收集领域,atari
-
- 雅各布·巴克曼,达尼雅尔·哈夫纳,乔治·塔克,尤金·布雷夫多,李洪洛克。NIPS 2018
- 关键点:集成模型与Q网络,价值扩展
- 实验环境:mujoco,roboschool
-
- 迈克尔·詹纳,贾斯汀·傅,马文·张,谢尔盖·列维涅。NeurIPS 2019
- 关键点:集成模型,sac,k-分支展开
- 实验环境:mujoco
-
- 周平,许华哲,李元智,田元东,特雷弗·达雷尔,马腾宇。ICLR 2019
- 关键点:差异界设计,多步ME-TRPO,熵正则化
- 实验环境:mujoco
-
- 塔纳德·库鲁塔奇,伊格纳西·克拉韦拉,严端,阿维夫·塔马尔,皮特·阿贝尔。ICLR 2018
- 关键点:集成模型,TRPO
- 实验环境:mujoco
-
- 达尼雅尔·哈夫纳,蒂莫西·利利克拉普,吉米·巴,穆罕默德·诺鲁齐。ICLR 2019
- 关键点:DreamerV1,潜在空间想象
- 实验环境:deepmind control suite,atari,deepmind lab
-
- 王婷武,吉米·巴。ICLR 2020
- 关键点:在动作空间和参数空间中进行基于模型的策略规划
- 实验环境:mujoco
-
- 朱利安·施里特维瑟,伊万尼斯·安东格卢,托马斯·休伯特,卡伦·西蒙扬,洛朗·西弗,西蒙·施密特,阿瑟·格茨,爱德华·洛克哈特,德米斯·哈萨比斯,托雷·格雷佩尔,蒂莫西·利利克拉普,大卫·西尔弗。Nature 2020
- 关键点:MCTS,价值等价
- 实验环境:国际象棋,将棋,围棋,atari
NeurIPS 2025
展开/折叠
-
- 米萨格·索尔塔尼,福雷斯特·阿戈斯蒂内利。NeurIPS 2025
- 关键点:视觉规划,对齐表征,离散潜在状态,启发式搜索
- 实验环境:魔方,推箱子
-
- 龙明生等人。NeurIPS 2025
- 关键点:世界模型训练,决策感知,可验证奖励
- 实验环境:文字游戏,机器人操作
-
- 微软研究院等。NeurIPS 2025
- 关键点:结构化世界模型,以物体为中心,物理建模
- 实验环境:物理交互,物体操作
-
- 匿名作者等。NeurIPS 2025
- 关键点:探索,扩散模型,合成经验,数据增强
- 实验环境:mujoco,稀疏奖励任务
-
- 李秀等人。NeurIPS 2025
- 关键点:多智能体MBRL,扩散启发,序列建模,联合分布
- 实验环境:SMAC,MPE
-
- 亚登·阿斯,程锐·邱,本杰明·昂格尔,董浩·康,马克斯·范德哈特,莱希·史,斯特利安·科罗斯,亚当·维尔曼,安德烈亚斯·克劳斯。NeurIPS 2025
- 关键点:安全的MBRL,模拟到现实,集成不确定性,鲁棒控制
- 实验环境:现实世界机器人,safety gym
-
- 施里尼瓦斯·拉马苏布拉马尼安,本杰明·弗里德,亚历山大·卡波内,杰夫·施奈德。NeurIPS 2025
- 关键点:模型误差,仿真引理,模型泛化
- 实验环境:DMC,Atari100k,HumanoidBench
ICML 2025
展开/折叠
提升用于数据高效强化学习的 Transformer 世界模型
- 作者:Antoine Dedieu、Joseph Ortiz、Xinghua Lou、Carter Wendelken、Wolfgang Lehrach、J Swaroop Guntupalli、Miguel Lazaro-Gredilla、Kevin Murphy
- 关键点:带预热的 Dyna 策略、最近邻补丁标记化、块教师强制
- OpenReview 评分:4, 4, 4, 3
- 实验环境:craftax-classic
-
- 作者:Brett Barkley、David Fridovich-Keil
- 关键点:Dyna 式算法在大多数 DMC 环境中会显著降低性能。
- OpenReview 评分:4, 4, 3, 2
- 实验环境:gym、DeepMind Control Suite
-
- 作者:Haotian Fu、Yixiang Sun、Michael L. Littman、George Konidaris
- 关键点:合成经验回放、通过探索恢复记忆
- OpenReview 评分:4, 3, 3, 3
- 实验环境:mini-grid、deepmind control suite
-
- 作者:Anh N Nhu、Sanghyun Son、Ming Lin
- 关键点:根据时间步长 ∆t 进行条件建模,并在多种不同的 ∆t 值上进行训练
- OpenReview 评分:4, 3, 3
- 实验环境:meta-world 控制任务、PDE 控制任务
-
- 作者:Minting Pan、Yitao Zheng、Jiajian Li、Yunbo Wang、Xiaokang Yang
- 关键点:行为抽象网络、分层世界模型
- OpenReview 评分:3, 3, 3, 2
- 实验环境:meta-world、carla、minedojo
-
- 作者:Dongsu Lee、Minhae Kwon
- 关键点:学习一种潜在抽象,从轨迹和状态空间的转移层面捕捉时间距离。
- OpenReview 评分:4, 3, 3, 2
- 实验环境:D4RL、AntMaze、FrankaKitchen、CALVIN、基于像素的 FrankaKitchen。
PIGDreamer:面向安全部分可观测强化学习的特权信息引导世界模型
- 作者:Dongchi Huang、Jiaqi WANG、Yang Li、Chunhe Xia、Tianle Zhang、Kaige Zhang
- 关键点:通过特权表示对齐和非对称的演员-评论家结构来利用特权信息
- OpenReview 评分:3, 3, 3
- 实验环境:safety gymnasium benchmark、guard benchmark
-
- 作者:Shangzhe Li、Zhiao Huang、Hao Su
- 关键点:无奖励世界模型、逆向软 Q 学习目标
- OpenReview 评分:4, 3, 3, 3
- 实验环境:DMControl、MyoSuite、ManiSkill2
-
- 作者:Yucen Wang、Rui Yu、Shenghua Wan、Le Gan、De-Chuan Zhan
- 关键点:将 FM 表征嵌入 WM 状态空间,基于模型的目标条件强化学习
- OpenReview 评分:4, 3, 3, 3
- 实验环境:DMControl、Kitchen、minecraft
-
- 作者:Zichen Liu、Guoji Fu、Chao Du、Wee Sun Lee、Min Lin
- 关键点:使用在线世界模型进行规划、后悔分析
- OpenReview 评分:4, 4, 4, 3
- 实验环境:ContinualBench
-
- 作者:Tim Pearce*、Tabish Rashid*、David Bignell、Raluca Georgescu、Sam Devlin、Katja Hofmann
- 关键点:规模定律、具身 AI、行为克隆、世界建模、分词器、架构
- 实验环境:Bleeding Edge、RT-1(机器人)、Atari、NetHack
-
- 作者:Gaoyue Zhou、Hengkai Pan、Yann LeCun、Lerrel Pinto
- 关键点:世界模型、离线学习、零样本规划、预训练视觉特征、任务无关推理
- 实验环境:Maze、Wall、Reach、Push-T、绳索操作、颗粒物操作
-
- 作者:Jonathan Richens、Tom Everitt、David Abel
- 关键点:世界模型、目标导向行为、无模型学习、策略分析、后悔界
- 实验环境:具有不同采样轨迹和目标深度的合成受控马尔可夫过程(cMP)环境
RobustZero:提升 MuZero 强化学习对状态扰动的鲁棒性
- 作者:Yushuai Li、Hengyu Liu、Torben Bach Pedersen、Yuqiang He、Kim Guldstrand Larsen、Lu Chen、Christian S. Jensen、Jiachen Xu、Tianyi Li
- 关键点:MuZero、鲁棒性、强化学习、状态扰动、自监督学习、适应性调整
- 实验环境:CartPole、Pendulum、IEEE 34-bus、IEEE 123-bus、IEEE 8500-node、Highway、Intersection、Racetrack、Hopper、Walker2d、HalfCheetah、Ant
-
- 作者:Maxime Burchi、Radu Timofte
- 关键点:基于模型的强化学习、世界模型、MaskGIT、空间潜在空间、Dreamer、Transformer、效率
- 实验环境:Crafter、Atari 100k
-
- 作者:Shaofeng Yin、Jialong Wu、Siqiao Huang、Xingjian Su、Xu He、Jianye Hao、Mingsheng Long
- 关键点:世界模型、异构环境、预训练、上下文学习、模型迁移、轨迹数据
- 实验环境:UniTraj(80 种不同环境)、D4RL(HalfCheetah、Hopper、Walker2D)、Cart-2-Pole、Cart-3-Pole
作为下一令牌预测基础的因果世界模型:在受控环境中探索 GPT
- 作者:Raanan Y. Rohekar、Yaniv Gurwicz、Sungduk Yu、Estelle Aflalo、Vasudev Lal
- 关键点:GPT、因果推断、注意力机制、结构化因果模型、零样本因果发现
- 实验环境:Othello、Chess
ICLR 2025
展开/折叠
-
- Maxime Burchi, Radu Timofte
- 关键词:基于模型的强化学习、Transformer 网络、对比预测编码
- 实验环境:Atari 100k 基准
-
- Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, Jiangmiao Pang
- 关键词:机器人操作、预训练、视觉预见、逆动力学、大规模机器人数据集
- 实验环境:LIBERO-LONG 基准、CALVIN ABC-D、真实世界任务
-
- Po-Wei Huang, Pei-Chiun Peng, Hung Guei, Ti-Rong Wu
- 关键词:选项、半马尔可夫决策过程、MuZero、蒙特卡洛树搜索、规划、强化学习
- 实验环境:Atari
-
- Claas A Voelcker, Marcel Hussing, Eric Eaton, Amir-massoud Farahmand, Igor Gilitschenski
- 关键词:强化学习、基于模型的强化学习、数据增强、高更新率
- 实验环境:DeepMind Control Suite
-
- Michael Matthews, Michael Beukman, Chris Lu, Jakob Nicolaus Foerster
- 关键词:强化学习、开放性、无监督环境设计、自动课程学习、基准
- 实验环境:2D 物理任务、机器人运动、抓取、视频游戏、经典强化学习环境
-
- Dixant Mittal, Liwei Kang, Wee Sun Lee
- 关键词:规划、推理、学习搜索、强化学习、大型语言模型
- 实验环境:24 点游戏、2D 格点导航、Procgen 游戏
-
- Jiajian Li, Qi Wang, Yunbo Wang, Xin Jin, Yang Li, Wenjun Zeng, Xiaokang Yang
- 关键词:强化学习、世界模型、视觉控制
- 实验环境:MineDojo
-
- Martin Klissarov, Mikael Henaff, Roberta Raileanu, Shagun Sodhani, Pascal Vincent, Amy Zhang, Pierre-Luc Bacon, Doina Precup, Marlos C. Machado, Pierluca D'Oro
- 关键词:层次化强化学习、强化学习、大型语言模型
- 实验环境:NetHack 学习环境 (NLE)
-
- Tai Hoang, Huy Le, Philipp Becker, Vien Anh Ngo, Gerhard Neumann
- 关键词:机器人操作、等变性、图神经网络、强化学习、可变形物体
- 实验环境:刚性插入、绳索操作、使用多个末端执行器进行布料操作
-
- Kehan Wen, Yutong Hu, Yao Mu, Lei Ke
- 关键词:离线到在线强化学习、基于模型的强化学习、掩码自编码、机器人学习
- 实验环境:D4RL、RoboMimic
-
- Rong-Xi Tan, Ke Xue, Shen-Huan Lyu, Haopu Shang, yaowang, Yaoyuan Wang, Fu Sheng, Chao Qian
- 关键词:基于模型的离线优化、黑箱优化、学习排序、学习优化
- 实验环境:涵盖多种优化场景的任务
-
- Zijing Shi, Meng Fang, Ling Chen
- 关键词:大型语言模型、蒙特卡洛树搜索、文本类游戏
- 实验环境:Jericho 基准
-
- Thomas Bush, Stephen Chung, Usman Anwar, Adrià Garriga-Alonso, David Krueger
- 关键词:强化学习、可解释性、规划、探针、无模型、机制性可解释性、推箱子
- 实验环境:推箱子
Drama:Mamba 加速的基于模型的强化学习具有样本和参数效率
- Wenlong Wang, Ivana Dusparic, Yucheng Shi, Ke Zhang, Vinny Cahill
- 关键词:Mamba-2、基于模型的强化学习、Mamba、状态空间模型
- 实验环境:Atari 100K
-
- Abdelhakim Benechehab, Youssef Attia El Hili, Ambroise Odonnat, Oussama Zekri, Albert Thomas, Giuseppe Paolo, Maurizio Filippone, Ievgen Redko, Balázs Kégl
- 关键词:基于模型的强化学习、大型语言模型、零样本学习、上下文学习
- 实验环境:D4RL、摆、HalfCheetah、Hopper
-
- Bernd Frauenknecht, Devdutt Subhasish, Friedrich Solowjow, Sebastian Trimpe
- 关键词:基于模型的强化学习、模型模拟、不确定性量化
- 实验环境:Gym MuJoCo
-
- Haoxin Lin, Yu-Yan Xu, Yihao Sun, Zhilong Zhang, Yi-Chen Li, Chengxing Jia, Junyin Ye, Jiaji Zhang, Yang Yu
- 关键词:基于模型的强化学习、任意步长动力学模型
- 实验环境:D4RL、NeoRL、Gym MuJoCo-v3
-
- Aidan Scannell, Mohammadreza Nakhaeinezhadfard, Kalle Kujanpää, Yi Zhao, Kevin Sebastian Luck, Arno Solin, Joni Pajarinen
- 关键词:强化学习、世界模型、表征学习、自监督学习、基于模型的强化学习、连续控制
- 实验环境:DeepMind 控制套件、Meta-World、Myosuite
NeurIPS 2024
展开/折叠
iVideoGPT:交互式 VideoGPT 是可扩展的世界模型
- 吴嘉龙、尹绍峰、冯宁雅、何旭、李栋、郝建业、龙明生
- 关键词:世界模型、视频生成模型、自回归 Transformer、强化学习、视频预测、视觉规划
- 实验环境:Meta-world
-
- 王子睿、邓悦、龙俊峰、张寅
- 关键词:强化学习、基于模型的强化学习、并行化、序列长度、世界模型、资格迹、样本效率
- 实验环境:Atari 100K、DMControl
-
- 菲利普·阿莫蒂拉、迪伦·J·福斯特、南江、阿克沙伊·克里希纳穆提、扎卡里亚·姆哈梅迪
- 关键词:强化学习、潜在动力学、统计模块化、算法模块化、可观测到潜在的约简、自预测模型
- 实验环境:无
-
- 马修·V·麦克法兰、埃丹·托莱多、唐纳尔·伯恩、保罗·达克沃斯、亚历山大·拉特尔
- 关键词:强化学习、RL、基于模型的强化学习、序贯蒙特卡洛、期望最大化、规划
- 实验环境:Brax、Boxoban、鲁比克魔方
-
- 黄扬儒、彭培熙、赵一凡、陈光耀、田永宏
- 关键词:多模态强化学习、视觉 RL、动力学建模、模态一致性、模态不一致性、DDM
- 实验环境:CARLA、DMControl
-
- 莫里茨·施奈德、罗伯特·克鲁格、纳鲁纳斯·瓦斯凯维丘斯、路易吉·帕尔米耶里、约什卡·博德克尔
- 关键词:强化学习、RL、基于模型的强化学习、表征学习、PVR、视觉表征
- 实验环境:DMC、ManiSkill2、Miniworld
-
- 姜涛、袁磊、李和、关聪、张宗章、于洋
- 关键词:多智能体强化学习、领域迁移
- 实验环境:D4RL
-
- 阿卜杜拉·阿克居尔、曼努埃尔·豪斯曼、梅利赫·坎德米尔
- 关键词:论文认为,基于不确定性的奖励惩罚会引入过度保守主义,可能导致因低估而产生次优策略。
- 实验环境:d4rl
-
- 曹正勋、温杜拉·贾亚瓦达纳、李思睿、凯茜·吴
- 关键词:贝叶斯优化、上下文 RL
- 实验环境:高斯过程、交通信号、生态驾驶、辅助自主、控制任务
通过表征复杂度的视角重新思考基于模型、基于策略和基于价值的强化学习
- 冯古浩、钟翰
- 关键词:RL 表征复杂度
- 实验环境:mujoco
ICML 2024
切换
-
- 马浩宇、吴嘉龙、冯宁雅、肖晨俊、李东、郝建业、王建民、龙明生
- 关键点:世界模型中的观测建模和奖励建模分析
- 实验环境:meta-world、rlbench、deepmind控制套件、atari 100k
-
- 赵钦林、王金东、张艺轩、金一乔、朱凯杰、陈浩、谢星
- 关键点:提出面向LLM智能体的竞争框架;构建模拟竞争环境
- 实验环境:一个仅包含餐厅和顾客的虚拟小镇
-
- 张仁昊、傅浩天、缪怡琳、乔治·科尼达里斯
- 关键点:离散-连续混合动作空间、带参数化动作的动力学模型、参数化动作的MPC
- 实验环境:platform, goal, hard goal, catch point, hard move
-
- 孙瑞翔、臧宏宇、李欣、里亚沙特·伊斯兰
- 关键点:改进的Dreamer架构、混合循环状态空间模型
- 实验环境:deepmind控制套件、分心版deepmind控制套件、mani-skill2
-
- 王宇辰、万圣华、甘乐、冯帅、詹德川
- 关键点:隐式动作生成器、动作条件分离的世界模型
- 实验环境:deepmind控制套件
-
- 保罗·马特斯、赖纳·施洛瑟、拉尔夫·赫布里希
- 关键点:状态空间模型、多层层次化想象、基于S5的世界模型
- 实验环境:atari 100k
-
- 利奥尔·科恩、王凯欣、康炳义、希·曼诺尔
- 关键点:基于像素的MBRL、基于token的世界模型、保留型环境模型
- 实验环境:atari 100k
-
- 哈尼·哈梅德、金秀彬、金东英、尹在植、安成镇
- 关键点:在战略梦中训练三种策略——高速公路策略、探索者策略和成就者策略,进而完成下游任务
- 实验环境:2D导航、3D迷宫导航、RoboKitchen
-
- 叶晨露、何佳凡、顾全全、张彤
- 关键点:对基于模型强化学习中对抗性破坏的理论分析,涵盖在线和离线设置
- 实验环境:无
-
- 洪茂、齐正玲、徐燕勋
- 关键点:基于模型的强化学习、POMDP
- 实验环境:无
ICLR 2024
切换
-
- 贾成兴、高晨晓、殷浩、张福祥、陈雄辉、许田、袁磊、张宗章、周志华、于洋
- 关键点:强化学习、基于模型的强化学习、离线强化学习
- OpenReview评分:8、8、8、6
- 实验环境:d4rl
-
- 阿尔纳布·库马尔·蒙达尔、西巴·斯马拉克·帕尼格拉希、赛·拉杰斯瓦尔、卡利姆·西迪奇、西亚马克·拉万巴赫什
- 关键点:Koopman理论、强化学习、动力系统、规划、长距离动力学预测模型、高效的前向动力学
- OpenReview评分:8、6、5、3
- 实验环境:mujoco
-
- 赵明德、萨法·阿尔维尔、哈姆·范·塞延、罗曼·拉罗什、多伊娜·普雷库普、约书亚·本吉奥
- 关键点:强化学习、规划、神经网络、时序差分学习、泛化、深度强化学习
- OpenReview评分:6、6、6、5
- 实验环境:MiniGrid-BabyAI框架
-
- Mohammad Reza Samsami、Artem Zholus、Janarthanan Rajendran、Sarath Chandar
- 关键点:基于DreamerV3的回忆与想象模块
- OpenReview评分:10、8、6
- 实验环境:bsuite、popgym、atari、deepmind控制套件、记忆迷宫
-
- Edward S. Hu、James Springer、Oleh Rybkin、Dinesh Jayaraman
- 关键点:基于DreamerV3的特权信息
- OpenReview评分:10、8、8、8
- 实验环境:gymnasium机器人学
-
- Nicklas Hansen、Hao Su、Xiaolong Wang
- 关键点:隐式世界模型、模型预测控制、通用型td-mpc2
- OpenReview评分:8、8、8、8
- 实验环境:deepmind控制套件、Meta-World、maniskill2、myosuite
-
- Minjun Sung、Sambhu Harimanas Karumanchi、Aditya Gahlawat、Naira Hovakimyan
- 关键点:L1自适应控制
- OpenReview评分:8、6、6、6
- 实验环境:mujoco
-
- Christian Gumbsch、Noor Sajid、Georg Martius、Martin V. Butz
- 关键点:上下文特定的循环状态空间模型、层次化世界模型
- OpenReview评分:8、6、6
- 实验环境:MiniHack、VisualPinPad、MultiWorld
-
- Lunjun Zhang、Yuwen Xiong、Ze Yang、Sergio Casas、Rui Hu、Raquel Urtasun
- 关键点:离散扩散;世界模型;自动驾驶
- OpenReview评分:10、8、6、6、6
- 实验环境:NuScenes、KITTI里程计、Argoverse2激光雷达
COPlanner:为基于模型的RL制定保守滚动但乐观探索的计划
- Xiyao Wang、Ruijie Zheng、Yanchao Sun、Ruonan Jia、Wichayaporn Wongkamjan、Huazhe Xu、Furong Huang
- 关键点:保守的世界模型滚动、乐观的环境探索
- OpenReview评分:6、6、6
- 实验环境:mujoco、deepmind控制套件
-
- Qihan Liu、Jianing Ye、Xiaoteng Ma、Jun Yang、Bin Liang、Chongjie Zhang
- 关键点:mcts、乐观搜索lambda、优势加权策略优化
- OpenReview评分:8、6、6、6
- 实验环境:smac
-
- Weikang Wan、Yufei Wang、Zackory Erickson、David Held
- 关键点:可微轨迹优化
- OpenReview评分:10、8、8、5
- 实验环境:deepmind控制套件、robomimic、maniskill
DMBP:基于扩散模型的预测器,用于对抗状态观测扰动的稳健离线强化学习
- Zhihe YANG、Yunjian Xu
- 关键点:条件扩散、离线RL
- OpenReview评分:8、8、6、6
- 实验环境:d4rl
-
- Zohar Rimon、Tom Jurgenson、Orr Krupnik、Gilad Adler、Aviv Tamar
- 关键点:基于dreamer的上下文元RL
- OpenReview评分:6、6、6、6
- 实验环境:点机器人导航、逃生室、Reacher Sparse
-
- Gaspard Lambrechts、Adrien Bolland、Damien Ernst
- 关键点:基于DreamerV3的知情世界模型
- OpenReview评分:6、6、6、5
- 实验环境:变化的登山路线、deepmind控制套件、pop gym、闪烁的atari和闪烁的控制
NeurIPS 2023
展开/折叠
-
- 赵子睿、李伟顺、许大卫
- 关键词:LLM-MCTS
- 实验环境:VirtualHome
描述、解释、规划与选择:基于 LLM 的交互式规划赋能开放世界多任务智能体
- 王子豪、蔡绍飞、陈冠州、刘安吉、马晓健(Shawn)、梁义涛
- 关键词:基于 LLM 的交互式规划方法
- 实验环境:Minecraft
-
- 吴嘉龙、马浩宇、邓超毅、龙鸣生
- 关键词:情境化世界模型
- 实验环境:CARLA、DeepMind 控制套件
-
- 何浩然、白晨嘉、徐康、杨卓然、张维安、王东、赵斌、李学龙
- 关键词:基于 GPT 的扩散模型用于规划和数据合成
- 实验环境:Meta-World、Maze2D
-
- 杨思哲、泽延杰、徐华哲
- 关键词:视角泛化、空间自适应编码器
- 实验环境:DeepMind 控制套件、Adroit、XArm
-
- 张申奥、刘博艺、王兆然、赵拓
- 关键词:基于模型的再参数化策略梯度方法、平滑正则化
- 实验环境:MuJoCo
RePo:通过正则化后验可预测性实现稳健的基于模型的强化学习
- 朱春宁、麦克斯·辛乔维茨、西丽·加迪普迪、阿比谢克·古普塔
- 关键词:视觉强化学习中的表征鲁棒性
- 实验环境:DeepMind 控制套件、ManiSkill
-
- 刘子昂、何杰夫、周耿耿、托比亚·马库奇、李飞飞、吴家俊、李云竹
- 关键词:网络稀疏化、ReLU 神经动力学的混合整数规划
- 实验环境:Gym, CartPole, Reacher
-
- 安德鲁·瓦根迈克尔、石冠雅、凯文·杰米森
- 关键词:非线性动力系统的最优样本复杂度
- 实验环境:仿射动力系统
-
- 莱纳特·特雷文、约纳斯·休博特、巴维亚、弗洛里安·多尔夫勒、安德烈亚斯·克劳斯
- 关键词:非线性常微分方程、后悔界、测量选择策略
- 实验环境:系统任务
通过最大化证据进行动作推理:仅凭观察利用世界模型实现零样本模仿
- 张兴远、菲利普·贝克-埃姆克、帕特里克·范德斯马赫特、马克西米利安·卡尔
- 关键词:预训练世界模型、仅基于观察的模仿学习
- 实验环境:DeepMind 控制套件
STORM:高效的基于随机 Transformer 的世界模型用于强化学习
- 张伟璞、王刚、孙健、袁业田、黄高
- 关键词:分类 VAE、Transformer 结构、DreamerV3
- 实验环境:Atari
ICML 2023
切换
-
- Zhiao Huang, Litian Liang, Zhan Ling, Xuanlin Li, Chuang Gan, Hao Su
- 关键词:多模态策略学习、重参数化策略梯度
- 实验环境:Meta-World、mujoco
-
- Xiyao Wang, Wichayaporn Wongkamjan, Ruonan Jia, Furong Huang
- 关键词:策略自适应模型学习、权重设计
- 实验环境:mujoco
-
- Seohong Park, Sergey Levine
- 关键词:可预测MDP抽象、解决模型利用问题
- 实验环境:mujoco
-
- Jacob C Walker, Eszter Vértes, Yazhe Li, Gabriel Dulac-Arnold, Ankesh Anand, Jessica Hamrick, Theophane Weber
- 主要见解:(1) 在无监督探索和/或微调过程中,基于模型的智能体是否具有优势?(2) 基于模型智能体的各个组件对下游任务学习有何贡献?(3) 基于模型的智能体如何应对无监督阶段与下游阶段之间的环境变化?
- 实验环境:Crafter、RoboDesk、Meta-World
-
- Anirudh Vemula, Yuda Song, Aarti Singh, J. Bagnell, Sanjiban Choudhury
- 关键词:目标不匹配、mbrl框架
- 实验环境:Helicopter、WideTree、线性动力系统、Maze、mujoco
-
- Kenny Young, Aditya Ramesh, Louis Kirsch, Jürgen Schmidhuber
- 关键词:经验回放、已学习模型泛化的时机与方式
- 实验环境:ProcMaze、ButtonGrid、PanFlute
-
- Souradip Chakraborty, Amrit Bedi, Alec Koppel, Mengdi Wang, Furong Huang, Dinesh Manocha
- 关键词:信息导向采样、核化施泰因散度
- 实验环境:DeepSea
-
- Paavo Parmas, Takuma Seno, Yuma Aoki
- 关键词:Dreamer的扩展、全传播计算图
- 实验环境:deepmind控制套件
-
- Guy Tennenholtz, Nadav Merlis, Lior Shani, Martin Mladenov, Craig Boutilier
- 关键词:非马尔可夫上下文动态、逻辑DCMDPs、理论分析、MuZero的扩展
- 实验环境:MovieLens数据集
-
- Yi Zhao, Wenshuai Zhao, Rinu Boney, Juho Kannala, Joni Pajarinen
- 关键词:表征学习、时序一致性
- 实验环境:deepmind控制套件
-
- Isaac Kauvar, Chris Doyle, Linqi Zhou, Nick Haber
- 关键词:DreamerV3的扩展、curiosity 回放、基于计数的回放、对抗性回放
- 实验环境:Crafter、deepmind控制套件
-
- Michal Nauman, Marek Cygan
- 关键词:偏差与方差、理论分析
- 实验环境:deepmind控制套件
-
- Remo Sasso, Michelangelo Conserva, Paulo Rauber
- 关键词:后验采样、持续价值网络
- 实验环境:atari
-
- Byeongchan Kim, Min-hwan Oh
- 关键词:计数估计、理论分析
- 实验环境:d4rl
ICLR 2023
切换
-
- Vincent Micheli, Eloi Alonso, François Fleuret
- 关键词:离散自编码器、基于Transformer的世界模型
- OpenReview评分:8, 8, 8, 8
- 实验环境:atari
-
- Jihwan Jeong, Xiaoyu Wang, Michael Gimelfarb, Hyunwoo Kim, Baher Abdulhai, Scott Sanner
- 关键词:基于模型的离线学习、贝叶斯后验价值估计
- OpenReview评分:8, 8, 6, 6
- 实验环境:d4rl
-
- Sheng Yue, Guanbo Wang, Wei Shao, Zhaofeng Zhang, Sen Lin, Ju Ren, Junshan Zhang
- 关键词:离线逆强化学习,奖励外推误差
- OpenReview评分:8, 8, 6, 6
- 实验环境:d4rl
-
- Zichen Liu, Siyi Li, Wee Sun Lee, Shuicheng YAN, Zhongwen Xu
- 关键词:离线强化学习,MuZero Unplugged分析,单步前瞻策略改进
- OpenReview评分:8, 6, 5
- 实验环境:atari数据集
-
- zhengyao jiang, Tianjun Zhang, Michael Janner, Yueying Li, Tim Rocktäschel, Edward Grefenstette, Yuandong Tian
- 关键词:使用VQ-VAE进行规划
- OpenReview评分:6, 6, 6, 6
- 实验环境:d4rl数据集
模型集成真的必要吗?通过带有Lipschitz正则化的值函数的单个模型实现基于模型的强化学习
- Ruijie Zheng, Xiyao Wang, Huazhe Xu, Furong Huang
- 关键词:Lipschitz正则化
- OpenReview评分:8, 8, 6, 6
- 实验环境:mujoco
-
- Nicklas Hansen, Yixin Lin, Hao Su, Xiaolong Wang, Vikash Kumar, Aravind Rajeswaran
- 关键词:三个阶段——策略预训练、目标导向探索、交互式学习
- OpenReview评分:8, 6, 6, 6
- 实验环境:adroit、meta-world、deepmind控制套件
简化基于模型的强化学习:用一个目标同时学习表征、潜在空间模型和策略
- Raj Ghugare, Homanga Bharadhwaj, Benjamin Eysenbach, Sergey Levine, Ruslan Salakhutdinov
- 关键词:对齐的潜在模型
- OpenReview评分:8, 6, 6, 6, 6
- 实验环境:mujoco
-
- Daniel Palenicek, Michael Lutter, Joao Carvalho, Jan Peters
- 关键词:更长的规划 horizon 在样本效率方面带来递减的回报
- OpenReview评分:8, 6, 6, 6
- 实验环境:brax
-
- Edward S. Hu, Richard Chang, Oleh Rybkin, Dinesh Jayaraman
- 关键词:基于采样的规划,为每个训练episode设定目标以直接优化内在探索奖励
- OpenReview评分:8, 8, 8, 8, 6
- 实验环境:point maze, walker, ant maze, 3-block stack
-
- Jinhua Zhu, Yue Wang, Lijun Wu, Tao Qin, Wengang Zhou, Tie-Yan Liu, Houqiang Li
- 关键词:深度可微分动态规划规划器
- OpenReview评分:8, 8, 8, 6
- 实验环境:mujoco
-
- Tongzheng Ren, Chenjun Xiao, Tianjun Zhang, Na Li, Zhaoran Wang, sujay sanghavi, Dale Schuurmans, Bo Dai
- 关键词:变分学习,表征学习
- OpenReview评分:8, 6, 6, 3
- 实验环境:mujoco、deepmind控制套件
-
- Yixuan Mei, Jiaxuan Gao, Weirui Ye, Shaohuai Liu, Yang Gao, Yi Wu
- 关键词:分布式基于模型的强化学习,加速EfficientZero
- OpenReview评分:6, 6, 5
- 实验环境:atari 100k
-
- Jan Robine, Marc Höftmann, Tobias Uelwer, Stefan Harmeling
- 关键词:自回归世界模型,Transformer-XL,平衡交叉熵损失,平衡数据集采样
- OpenReview评分:8, 6, 6, 6
- 实验环境:atari 100k
-
- Yifan Xu, Nicklas Hansen, Zirui Wang, Yung-Chieh Chan, Hao Su, Zhuowen Tu
- 关键词:离线多任务预训练,在线微调
- OpenReview评分:6, 6, 6, 6
- 实验环境:atari 100k
-
- Weirui Ye, Yunsheng Zhang, Pieter Abbeel, Yang Gao
- 关键词:无监督预训练,再用下游任务进行微调
- OpenReview评分:8, 6, 6, 5
- 实验环境:atari 100k
-
- Yifu Yuan, Jianye HAO, Fei Ni, Yao Mu, YAN ZHENG, Yujing Hu, Jinyi Liu, Yingfeng Chen, Changjie Fan
- 关键词:联合预训练多头动力学模型和无监督探索策略,再针对下游任务进行微调
- OpenReview评分:6, 6, 6, 6
- 实验环境:URLB基准测试
-
- Pietro Mazzaglia, Tim Verbelen, Bart Dhoedt, Alexandre Lacoste, Sai Rajeswar
- 关键词:世界模型、技能发现、技能学习、技能适应
- OpenReview评分:8, 8, 6, 6
- 实验环境:deepmind控制套件、Meta-World
NeurIPS 2022
切换
-
- Can Chen, Yingxue Zhang, Jie Fu, Xue Liu, Mark Coates
- 关键词:基于模型,离线
- OpenReview评分:7, 6, 5
- 实验环境:design-bench
-
- 杨申涛、张书健、冯一豪、周明远
- 关键词:基于模型、离线、边际重要性权重
- OpenReview评分:7, 6, 6, 5
- 实验环境:d4rl数据集
-
- 郭凯阳、邵云峰、耿彦辉
- 关键词:基于模型、离线
- OpenReview评分:8, 8, 7, 7
- 实验环境:d4rl数据集
在信任状态之前先双重检查:基于双向建模的自信感知离线强化学习
- 吕家飞、李修、陆宗庆
- 关键词:双重检查机制、双向建模、离线强化学习
- OpenReview评分:7, 6, 6
- 实验环境:d4rl数据集
-
- 于晓鹏、蒋杰川、张万鹏、姜浩斌、陆宗庆
- 关键词:多智能体、基于模型
- OpenReview评分:7, 6, 4, 3
- 实验环境:mpe、google research football
-
- 徐志伟、李大鹏、张彬、詹源、白云鹏、范国梁
- 关键词:多智能体、基于模型
- OpenReview评分:6, 5
- 实验环境:星际争霸II、Google Research Football、多智能体离散MuJoCo
-
- 西尔维乌·皮蒂斯、埃利奥特·克雷格、阿贾伊·曼德尔卡、阿尼梅什·加格
- 关键词:数据增强框架、离线强化学习
- OpenReview评分:7, 7, 7, 6
- 实验环境:2D导航、Hook-Sweep
-
- 季天英、罗宇、孙富春、景明轩、何丰熙、黄文兵
- 关键词:事件触发机制、约束模型转移下界优化
- OpenReview评分:6, 6, 5, 5
- 实验环境:mujoco
-
- 阿希什·贾扬特、沙拉布·巴特纳加尔
- 关键词:约束强化学习、基于模型
- OpenReview评分:7, 6, 5, 5
- 实验环境:safety gym
-
- 李恒格、孙晓林、郑子涵
- 关键词:攻击与防御、联邦学习、基于模型
- OpenReview评分:6, 6, 6, 5
- 实验环境:MNIST、FashionMNIST、EMNIST、CIFAR-10以及合成数据集
-
- 安东尼·胡、吉安卢卡·科拉多、尼古拉斯·格里菲斯、扎卡里·穆雷斯、科丽娜·古劳、哈德森·叶、亚历克斯·肯德尔、罗伯托·西波拉、杰米·肖顿
- 关键词:基于模型、模仿学习、自动驾驶
- OpenReview评分:7, 6, 6
- 实验环境:CARLA
-
- 韩琪、苏毅、阿维拉尔·库马尔、谢尔盖·列文
- 关键词:领域适应、不变目标模型、表示学习(与基于模型的强化学习无关)
- OpenReview评分:7, 6, 6, 5, 5
- 实验环境:design-bench
-
- 傅浩天、于尚群、迈克尔·利特曼、乔治·科尼达里斯
- 关键词:终身强化学习、变分贝叶斯
- OpenReview评分:7, 6, 6
- 实验环境:mujoco、meta-world
-
- 马克·里格特、布鲁诺·拉塞尔达、尼克·霍斯
- 关键词:离线强化学习、基于模型的强化学习、双人游戏、对抗性模型训练
- OpenReview评分:6, 6, 6, 4
- 实验环境:d4rl
-
- 张绍昂
- 关键词:后验采样强化学习、参考更新、约束性保守更新
- OpenReview评分:7, 7, 5, 5
- 实验环境:mujoco、N-Chain MDPs
-
- 武晨阳、李天赐、张宗章、于洋
- 关键词:面对不确定性时的乐观态度(OFU)、BOO后悔
- OpenReview评分:6, 6, 5
- 实验环境:RiverSwim、Chain、随机MDPs
-
- 阿莱克·阿加瓦尔、张彤
- 关键词:后验采样强化学习、贝尔曼误差解耦框架
- OpenReview评分:7, 7, 7, 6
- 实验环境:无
-
- Gene Li、Junbo Li、Nathan Srebro、Zhaoran Wang、Zhuoran Yang
- 关键词:乐观模型、分数匹配
- OpenReview评分:7, 7, 6
- 实验环境:无
-
- Danijar Hafner、Kuang-Huei Lee、Ian Fischer、Pieter Abbeel
- 关键词:层次化强化学习、长 horizon 任务、稀疏奖励任务
- OpenReview评分:6, 6, 5
- 实验环境:atari、deepmind control suite、deepmind lab、crafter
-
- Sahand Rezaei-Shoshtari、Rosie Zhao、Prakash Panangaden、David Meger、Doina Precup
- 关键词:同态策略梯度、连续 MDP 同态、松弛双模拟损失
- OpenReview评分:7, 7, 7
- 实验环境:deepmind control suite
ICML 2022
展开
-
- Fei Deng、Ingook Jang、Sungjin Ahn
- 关键词:dreamer、原型
- 实验环境:deepmind control suite
-
- Tongzhou Wang、Simon Du、Antonio Torralba、Phillip Isola、Amy Zhang、Yuandong Tian
- 关键词:表征学习、去噪模型
- 实验环境:deepmind control suite、RoboDesk
-
- Qi Wang、Herke van Hoof
- 关键词:图结构代理模型、元训练
- 实验环境:atari、mujoco
-
- Yi Wan、Ali Rahimi-Kalahroudi、Janarthanan Rajendran、Ida Momennejad、Sarath Chandar、Harm van Seijen
- 关键词:局部变化适应
- 实验环境:GridWorldLoCA、ReacherLoCA、MountaincarLoCA
-
- Pier Giuseppe Sessa、Maryam Kamgarpour、Andreas Krause
- 关键词:模型基元多智能体、置信区间
- 实验环境:SMART
-
- Shentao Yang、Yihao Feng、Shujian Zhang、Mingyuan Zhou
- 关键词:离线强化学习、模型基元强化学习、平稳分布正则化
- 实验环境:d4rl
Design-Bench:数据驱动的离线模型基元优化基准测试
- Brandon Trabucco、Xinyang Geng、Aviral Kumar、Sergey Levine
- 关键词:基准测试、离线 MBO
- 实验环境:Design-Bench 基准任务
-
- Nicklas Hansen、Hao Su、Xiaolong Wang
- 关键词:TD 学习、MPC
- 实验环境:deepmind control suite、Meta-World
ICLR 2022
展开/收起
-
- Cong Lu, Philip Ball, Jack Parker-Holder, Michael Osborne, Stephen J. Roberts
- 关键词:基于模型的离线、不确定性量化
- OpenReview评分:8, 8, 6, 6, 6
- 实验环境:d4rl 数据集
-
- Claas A Voelcker, Victor Liao, Animesh Garg, Amir-massoud Farahmand
- 关键词:价值梯度加权的模型损失
- OpenReview评分:8, 8, 6, 6
- 实验环境:mujoco
-
- Ioannis Antonoglou, Julian Schrittwieser, Sherjil Ozair, Thomas K Hubert, David Silver
- 关键词:MCTS、随机MuZero
- OpenReview评分:10, 8, 8, 5
- 实验环境:2048 游戏、西洋双陆棋、围棋
-
- Ivo Danihelka, Arthur Guez, Julian Schrittwieser, David Silver
- 关键词:Gumbel AlphaZero、Gumbel MuZero
- OpenReview评分:8, 8, 8, 6
- 实验环境:围棋、国际象棋、atari
-
- Sen Lin, Jialin Wan, Tengyu Xu, Yingbin Liang, Junshan Zhang
- 关键词:基于模型的离线元强化学习
- OpenReview评分:8, 6, 6, 6
- 实验环境:d4rl 数据集
-
- Homanga Bharadhwaj, Mohammad Babaeizadeh, Dumitru Erhan, Sergey Levine
- 关键词:互信息、视觉模型基础强化学习
- OpenReview评分:8, 8, 8, 6
- 实验环境:deepmind 控制套件、Kinetics 数据集
-
- Yanchao Sun, Ruijie Zheng, Xiyao Wang, Andrew E Cohen, Furong Huang
- 关键词:潜在动力学模型、迁移强化学习
- OpenReview评分:8, 6, 5, 5
- 实验环境:CartPole、Acrobot 和 Cheetah-Run、mujoco、3DBall
-
- Changmin Yu, Dong Li, Jianye HAO, Jun Wang, Neil Burgess
- 关键词:表示学习、通过回溯学习
- OpenReview评分:8, 6, 5, 3
- 实验环境:deepmind 控制套件
-
- Youngmin Oh, Jinwoo Shin, Eunho Yang, Sung Ju Hwang
- 关键词:优先经验回放、mbrl
- OpenReview评分:8, 8, 6, 5
- 实验环境:pybullet
-
- Arunkumar Byravan, Leonard Hasenclever, Piotr Trochim, Mehdi Mirza, Alessandro Davide Ialongo, Yuval Tassa, Jost Tobias Springenberg, Abbas Abdolmaleki, Nicolas Heess, Josh Merel, Martin Riedmiller
- 关键词:模型预测控制
- OpenReview评分:8, 6, 6, 6
- 实验环境:mujoco
-
- Chongchong Li, Yue Wang, Wei Chen, Yuting Liu, Zhi-Ming Ma, Tie-Yan Liu
- 关键词:双模型方法、分析模型误差和策略梯度
- OpenReview评分:8, 8, 6, 6
- 实验环境:mujoco
-
- Yijun Yang, Jing Jiang, Tianyi Zhou, Jie Ma, Yuhui Shi
- 关键词:基于模型的离线、模型回报与不确定性权衡
- OpenReview评分:8, 8, 6, 5
- 实验环境:d4rl 数据集
-
- Masatoshi Uehara, Wen Sun
- 关键词:基于模型的离线理论、PAC界
- OpenReview评分:8, 6, 6, 5
- 实验环境:无
-
- Edward S. Hu, Kun Huang, Oleh Rybkin, Dinesh Jayaraman
- 关键词:可在新机器人上迁移的世界模型
- OpenReview评分:8, 6, 6, 5
- 实验环境:mujoco、WidowX 和 Franka Panda 机器人
NeurIPS 2021
展开/折叠
-
- 作者:Tianhe Yu, Aviral Kumar, Rafael Rafailov, Aravind Rajeswaran, Sergey Levine, Chelsea Finn
- 关键点:离线强化学习,基于模型的强化学习,深度强化学习
- OpenReview评分:6, 7, 6, 8
- 实验环境:D4RL数据集
-
- 作者:Garrett Thomas, Yuping Luo, Tengyu Ma
- 关键点:安全RL,奖励惩罚,基于模型rollout的理论
- OpenReview评分:8, 6, 6
- 实验环境:MuJoCo
-
- 作者:Yao Mu, Yuzheng Zhuang, Bin Wang, Guangxiang Zhu, Wulong Liu, Jianyu Chen, Ping Luo, Shengbo Eben Li, Chongjie Zhang, Jianye HAO
- 关键点:Dreamer的扩展,预测可靠性权重
- OpenReview评分:6, 6, 6, 6
- 实验环境:DeepMind控制套件
-
- 作者:Hung Le, Thommen Karimpanal George, Majid Abdolshah, Truyen Tran, Svetha Venkatesh
- 关键点:基于模型,情景控制
- OpenReview评分:7, 7, 6, 6
- 实验环境:2D迷宫导航, CartPole、MountainCar和LunarLander, Atari, 3D导航:Gym-MiniWorld
-
- 作者:Mingde Zhao, Zhen Liu, Sitao Luan, Shuyuan Zhang, Doina Precup, Yoshua Bengio
- 关键点:MBRL,集合表示
- OpenReview评分:7, 7, 7, 6
- 实验环境:MiniGrid-BabyAI框架
-
- 作者:Weirui Ye, Shaohuai Liu, Thanard Kurutach, Pieter Abbeel, Yang Gao
- 关键点:MuZero,自监督一致性损失
- OpenReview评分:7, 7, 7, 5
- 实验环境:Atari 10万数据集, DeepMind控制套件
-
- 作者:Julian Schrittwieser, Thomas K Hubert, Amol Mandhane, Mohammadamin Barekatain, Ioannis Antonoglou, David Silver
- 关键点:MuZero,重新分析,离线
- OpenReview评分:8, 8, 7, 6
- 实验环境:Atari数据集、DeepMind控制套件数据集
-
- 作者:Gregory Farquhar, Kate Baumli, Zita Marinho, Angelos Filos, Matteo Hessel, Hado van Hasselt, David Silver
- 关键点:新的模型学习方式
- OpenReview评分:7, 7, 7, 6
- 实验环境:表格MDP、Sokoban、Atari
-
- 作者:Tianhe Yu, Garrett Thomas, Lantao Yu, Stefano Ermon, James Zou, Sergey Levine, Chelsea Finn, Tengyu Ma
- 关键点:基于模型,离线
- OpenReview暂无评分
- 实验环境:D4RL数据集,halfcheetah-jump和ant-angle
-
- 作者:Sihyun Yu, Sungsoo Ahn, Le Song, Jinwoo Shin
- 关键点:基于模型,离线
- OpenReview评分:7, 6, 6
- 实验环境:Design-Bench
-
- 作者:Jianhao Wang, Wenzhe Li, Haozhe Jiang, Guangxiang Zhu, Siyuan Li, Chongjie Zhang
- 关键点:基于模型,离线
- OpenReview评分:7, 6, 6, 5
- 实验环境:D4RL数据集
-
- 作者:Xiong-Hui Chen, Yang Yu, Qingyang Li, Fan-Ming Luo, Zhiwei Tony Qin, Shang Wenjie, Jieping Ye
- 关键点:基于模型,离线
- OpenReview评分:6, 6, 6, 4
- 实验环境:D4RL数据集
-
- 作者:Toru Hishinuma, Kei Senda
- 关键点:基于模型,离线,off-policy评估
- OpenReview评分:7, 6, 6, 6
- 实验环境:摆动、D4RL数据集
-
- 作者:Weitong Zhang, Dongruo Zhou, Quanquan Gu
- 关键点:学习理论,基于模型的免奖励RL,线性函数近似
- OpenReview评分:6, 6, 5, 5
- 实验环境:无
可证明的基于模型的非线性多臂老虎机与强化学习:摒弃乐观主义,拥抱虚拟曲率
- 作者:Kefan Dong, Jiaqi Yang, Tengyu Ma
- 关键点:学习理论,基于模型的多臂老虎机RL,非线性函数近似
- OpenReview评分:7, 7, 7, 6
- 实验环境:无
-
- 作者:Russell Mendonca, Oleh Rybkin, Kostas Daniilidis, Danijar Hafner, Deepak Pathak
- 关键点:无监督目标达成,目标条件强化学习
- OpenReview评分:6, 6, 6, 6, 6
- 实验环境:Walker、四足机器人、箱子、厨房
ICLR 2021
展开/收起
-
- 作者:松岛达也、古田博纪、松尾丰、Ofir Nachum、Shixiang Gu
- 关键词:基于模型、行为克隆(预热)、TRPO
- OpenReview评分:8, 7, 7, 5
- 实验环境:d4rl数据集
-
- 作者:Brandon Cui、Yinlam Chow、Mohammad Ghavamzadeh
- 关键词:表示学习、基于模型的软演员-评论家算法
- OpenReview评分:6, 6, 6
- 实验环境:平面系统、倒立摆——摆起、小车倒立摆、三连杆机械臂——摆起与平衡
-
- 作者:Danijar Hafner、Timothy Lillicrap、Mohammad Norouzi、Jimmy Ba
- 关键词:DreamerV2、多种技巧(多个分类变量、KL平衡等)
- OpenReview评分:9, 8, 5, 4
- 实验环境:Atari
-
- 作者:Stephen Tian、Suraj Nair、Frederik Ebert、Sudeep Dasari、Benjamin Eysenbach、Chelsea Finn、Sergey Levine
- 关键词:目标达成任务、动力学学习、距离学习(目标条件Q函数)
- OpenReview评分:7, 7, 7, 7
- 实验环境:sawyer、门滑动
-
- 作者:Arthur Argenson、Gabriel Dulac-Arnold
- 关键词:基于模型、离线
- OpenReview评分:8, 7, 5, 5
- 实验环境:RL Unplugged(RLU)、d4rl数据集
-
- 作者:Justin Fu、Sergey Levine
- 关键词:基于模型、离线
- OpenReview评分:8, 6, 6
- 实验环境:design-bench
-
- 作者:Jessica B. Hamrick、Abram L. Friesen、Feryal Behbahani、Arthur Guez、Fabio Viola、Sims Witherspoon、Thomas Anthony、Lars Buesing、Petar Veličković、Théophane Weber
- 关键词:讨论MuZero中的规划问题
- OpenReview评分:7, 7, 6, 5
- 实验环境:Atari、围棋、Deepmind控制套件
-
- 作者:Byung-Jun Lee、Jongmin Lee、Kee-Eung Kim
- 关键词:表示平衡MDP、基于模型、离线
- OpenReview评分:7, 7, 7, 6
- 实验环境:d4rl数据集
基于模型的微观数据强化学习:关键的模型属性是什么?应选择哪种模型?
- 作者:Balázs Kégl、Gabriel Hurtado、Albert Thomas
- 关键词:混合密度网络、异方差性
- OpenReview评分:7, 7, 7, 6, 5
- 实验环境:acrobot系统
ICML 2021
展开/收起
-
- 作者:Brandon Trabucco、Aviral Kumar、Xinyang Geng、Sergey Levine
- 关键词:保守目标模型、离线MRL
- 实验环境:design-bench
-
- 作者:Çağatay Yıldız、Markus Heinonen、Harri Lähdesmäki
- 关键词:连续时间
- 实验环境:单摆、小车倒立摆和acrobot
-
- 作者:Oleh Rybkin、Chuning Zhu、Anusha Nagabandi、Kostas Daniilidis、Igor Mordatch、Sergey Levine
- 关键词:潜在空间配点法
- 实验环境:稀疏的metaworld任务
-
- 作者:David A Bruns-Smith
- 关键词:最坏情况下的界
- 实验环境:ope-tools
-
- 作者:Matteo Hessel、Ivo Danihelka、Fabio Viola、Arthur Guez、Simon Schmitt、Laurent Sifre、Theophane Weber、David Silver、Hado van Hasselt
- 关键词:价值等价性
- 实验环境:Atari
-
- 作者:Sherjil Ozair、Yazhe Li、Ali Razavi、Ioannis Antonoglou、Aäron van den Oord、Oriol Vinyals
- 关键词:VQVAE、蒙特卡洛树搜索
- 实验环境:国际象棋数据集、DeepMind Lab
-
- 作者:Tung Nguyen、Rui Shu、Tuan Pham、Hung Bui、Stefano Ermon
- 关键词:带有RSSM的时序预测编码、潜在空间
- 实验环境:Deepmind控制套件
-
- 作者:Ying Fan、Yifei Ming
- 关键词:PSRL的后悔界、MPC
- 实验环境:连续的小车倒立摆、单摆摆起、mujoco
-
- 作者:Qinghua Liu、Tiancheng Yu、Yu Bai、Chi Jin
- 关键词:学习理论、多智能体、基于模型的自我对弈、双人零和马尔可夫博弈
- 实验环境:无
其他
-
- Pu Yuan, Niu Yazhe, Yang Zhenjie, Ren Jiyuan, Li Hongsheng, Liu Yu TMLR2025
- 关键词:世界模型、MCTS、基于模型的强化学习、Transformer、潜在规划、多任务学习
- 实验环境:Atari、DMControl、VisualMatch
-
- Wang Yuqi, He Jiawei, Fan Lue, Li Hongxin, Chen Yuntao, Zhang Zhaoxiang CVPR 2024
- 关键词:自动驾驶世界建模
- 实验环境:nuScenes
-
- Wu Philipp, Majumdar Arjun, Stone Kevin, Lin Yixin, Mordatch Igor, Abbeel Pieter, Rajeswaran Aravind ICLR 2023 Workshop RRL
- 关键词:离线RL、控制学习、序列建模
- 实验环境:d4rl
-
- Rigter Marc, Yamada Jun, Posner Ingmar Arxiv 2023
- 关键词:扩散模型、世界模型
- 实验环境:deepmind control suite、gridworld
-
- Luis Carlos E., Bottero Alessandro G., Vinogradska Julia, Berkenkamp Felix, Peters Jan Arxiv 2023
- 关键词:MBRL中的累积奖励不确定性估计
- 实验环境:mujoco
使用数据增强的基于模型的强化学习高效学习解决现实世界迷宫游戏
- Bi Thomas, D'Andrea Raffaello Arxiv 2023
- 关键词:数据增强、DreamerV3
- 实验环境:现实世界迷宫游戏
-
- Hafner Danijar, Pasukonis Jurgis, Ba Jimmy, Lillicrap Timothy Arxiv 2023
- 关键词:DreamerV3、世界模型的可扩展性
- 实验环境:deepmind control suite、atari、DMLab、minecraft
-
- Li Chuming, Jia Ruonan, Yao Jiawei, Liu Jie, Zhang Yinmin, Niu Yazhe, Yang Yaodong, Liu Yu, Ouyang Wanli IJCAI Workshop 2023
- 关键词:扩展的策略改进、模型正则化、规划定理
- 实验环境:mujoco
教程
代码库
贡献
我们的目标是让这个仓库变得更好。如果您有兴趣贡献,请参阅此处以获取贡献说明。
许可证
Awesome Model-Based RL 根据 Apache 2.0 许可证发布。
(返回顶部)
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。