awesome-exploration-rl
awesome-exploration-rl 是一个专注于强化学习(RL)中“探索方法”的精选资源库,旨在为研究者和开发者提供一份持续更新的高质量文献清单。在强化学习中,智能体需要在“探索未知”与“利用已知”之间找到平衡,这是决定算法成败的核心难题。特别是在那些需要数十甚至数百步才能达成目标的复杂环境中,如何高效地探索状态空间往往极具挑战性。awesome-exploration-rl 正是为了解决这一痛点而生,它系统性地梳理了该领域的前沿进展,帮助用户快速掌握如何提升智能体的探索效率。
这份资源库非常适合人工智能领域的研究人员、算法工程师以及正在深入学习强化学习的学生使用。无论你是希望追踪 NeurIPS、ICML、ICLR 等顶级会议的最新论文,还是寻找经典的基础理论参考,这里都能提供清晰的指引。其独特的技术亮点在于提供了一套清晰的方法分类体系:它将探索策略细分为“增强收集策略”(如动作选择扰动、状态选择引导等)和“增强训练策略”(如基于计数、预测、信息论或熵增的方法等)。这种结构化的整理方式,不仅让读者能直观理解不同算法的应用阶段和原理,还通过 MiniGrid 等环境的可视化示例,降低了理解硬探索任务的门槛。通过关注 awesome-exploration-rl,你可以紧跟 ERL 领域的发展前沿,为你的算法优化或学术研究提供坚实的理论支持和灵感来源。
使用场景
某AI实验室的研究员正在开发一款用于复杂迷宫导航的强化学习智能体,该任务属于典型的“硬探索”场景(如 MiniGrid-ObstructedMaze),要求智能体在数百步的长序列动作中找到唯一正确路径,这对探索与利用的平衡提出了极高要求。
没有 awesome-exploration-rl 时
- 文献检索效率低下:研究员需手动在 arXiv、NeurIPS 等各大顶会中筛选“探索策略”相关论文,面对海量且分散的资源,难以快速锁定最新前沿成果,耗费大量时间在信息搜集而非算法设计上。
- 技术选型缺乏体系:由于缺乏统一的分类标准,研究员难以厘清“基于计数的探索”与“基于信息论的探索”等方法的具体适用边界,容易盲目尝试不匹配当前场景的 SOTA 模型,导致实验方向偏差。
- 复现与对比困难:找不到权威的资源汇总,难以系统性地对比不同探索机制(如动作选择扰动 vs 状态选择引导)在特定环境下的表现,导致基线实验设计不完整,论文论证力度不足。
使用 awesome-exploration-rl 后
- 一站式获取前沿资源:通过该工具持续更新的列表,研究员能直接获取按年份(如 ICLR 2025、NeurIPS 2024)整理的精选论文,迅速掌握领域最新动态,将文献调研时间从数周缩短至数天。
- 清晰的技术路线指引:借助其提供的详细分类 taxonomy,研究员能明确区分“增强收集策略”与“增强训练策略”,根据迷宫导航的稀疏奖励特性,精准定位到“基于目标(Goal Based)”或“基于计数(Count Based)”的有效方法。
- 高效实验设计与验证:参考列表中提供的经典与最新算法示例,研究员能快速构建全面的基线对比实验,科学评估不同探索机制在长 horizon 任务中的有效性,显著提升研发迭代速度与论文质量。
awesome-exploration-rl 通过结构化的知识整理,帮助研究者从繁琐的信息噪音中解脱,专注于解决强化学习中核心的探索难题,极大提升了科研与工程落地的效率。
运行环境要求
未说明
未说明

快速开始
强化学习中的优秀探索方法
更新于 2025年12月2日
这里收集了关于**强化学习中的探索方法(ERL)**的研究论文。 该仓库将持续更新,以跟踪ERL领域的前沿进展。欢迎关注并点赞!
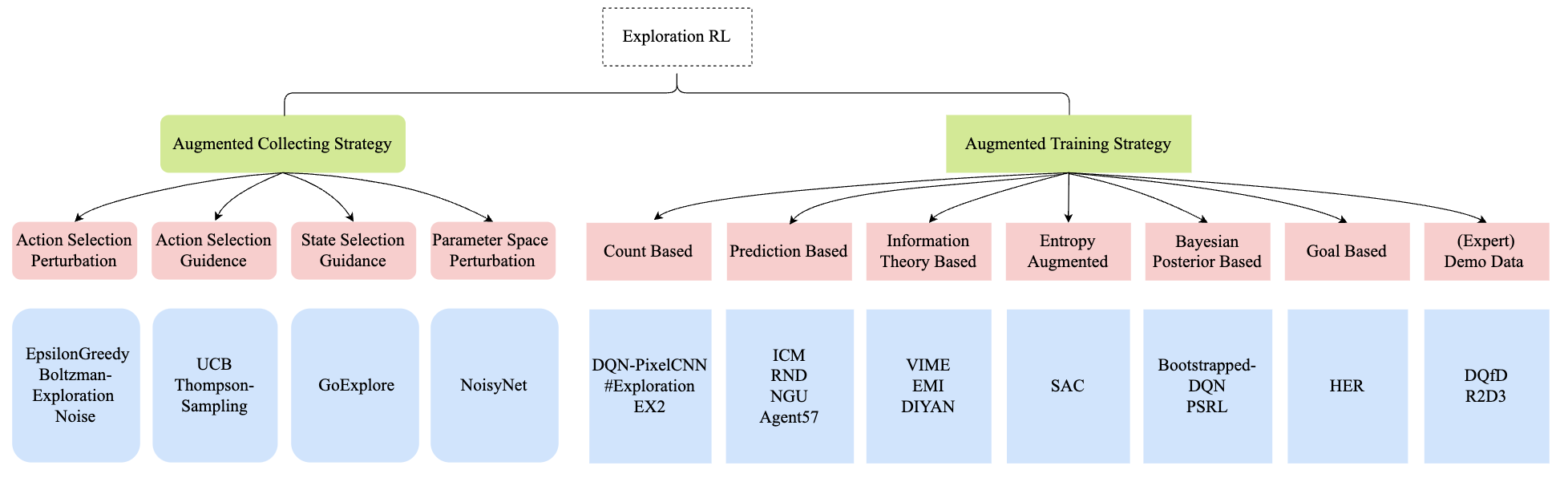
探索与利用之间的平衡是强化学习中最核心的问题之一。 为了帮助读者更直观地理解探索问题,我们在下方提供了一个来自MiniGrid的典型高难度探索环境的可视化示例。 在这个任务中,完成目标往往需要执行数十甚至数百步的动作序列,智能体必须充分探索不同的状态-动作空间, 才能学会达成目标所需的技能。

一个典型的高难度探索环境:MiniGrid-ObstructedMaze-Full-v0。
目录
探索型强化学习方法分类
(点击收起)
一般来说,我们可以将强化学习过程分为两个阶段:收集阶段和训练阶段。 在收集阶段,智能体根据当前策略选择动作,并与环境交互以收集有用的经验。 在训练阶段,智能体利用收集到的经验来更新当前策略,从而获得性能更好的策略。
根据探索组件被显式应用的阶段,我们将“探索型强化学习”方法简单地分为两大类:增强型收集策略和增强型训练策略:
增强型收集策略代表了在收集阶段常用的多种不同探索策略,我们进一步将其划分为四类:动作选择扰动动作选择引导状态选择引导参数空间扰动
增强型训练策略代表了在训练阶段常用的多种不同探索策略,我们进一步将其划分为七类:基于计数基于预测基于信息论熵增强基于贝叶斯后验基于目标(专家)演示数据
需要注意的是,这些类别之间可能存在重叠,一种算法可能同时属于多个类别。 关于RL中探索方法的其他详细综述,您可以参考Tianpei Yang等和Susan Amin等的相关研究。
以下是分类中提到的论文链接:
[1] Go-Explore: Adrien Ecoffet 等,2021年
[2] NoisyNet,Meire Fortunato 等,2018年
[3] DQN-PixelCNN: Marc G. Bellemare 等,2016年
[4] #Exploration Haoran Tang 等,2017年
[5] EX2: Justin Fu 等,2017年
[6] ICM: Deepak Pathak 等,2018年
[7] RND: Yuri Burda 等,2018年
[8] NGU: Adrià Puigdomènech Badia 等,2020年
[9] Agent57: Adrià Puigdomènech Badia 等,2020年
[10] VIME: Rein Houthooft 等,2016年
[11] EMI: Wang 等,2019年
[12] DIYAN: Benjamin Eysenbach 等,2019年
[13] SAC: Tuomas Haarnoja 等,2018年
[14] BootstrappedDQN: Ian Osband 等,2016年
[15] PSRL: Ian Osband 等,2013年
[16] HER Marcin Andrychowicz 等,2017年
[17] DQfD: Todd Hester 等,2018年
[18] R2D3: Caglar Gulcehre 等,2019年
论文
格式:
- [标题](论文链接) (发表形式,若公开则附上OpenReview评分)
- 作者1,作者2,作者3,...
- 关键:关键问题及见解
- 实验环境:实验使用的环境
NeurIPS 2025
(点击收起)
-
- 约纳坦·阿什拉格、乌里·科伦、米尔科·穆蒂、埃丝特·德尔曼、皮埃尔-吕克·培康、希·曼诺尔
- 关键词:鲁棒强化学习、风险规避型强化学习、正则化强化学习
- 实验环境:MiniGrid、MuJoCo
-
- 本杰明·席弗、马克·塞尔克
- 关键词:多臂老虎机、贝叶斯激励相容、探索
- 实验环境:多臂老虎机
LLM-Explorer:由大型语言模型驱动的插件式强化学习策略探索增强方法
- 郝千越、宋艺文、廖庆敏、袁健、李勇
- 关键词:强化学习、大型语言模型、策略探索
- 实验环境:Atari、MuJoCo
-
- 李秀源、吴珉焕
- 关键词:广义线性老虎机、上下文老虎机、汤普森采样、特征扰动
- 实验环境:合成数据、UCI数据集、MNIST
-
- 塞缪尔·麦克劳林·罗伯逊、陈唐德、戴博、戴尔·舒尔曼斯、查巴·塞佩斯瓦里、梅锦程
- 关键词:强化学习、策略梯度、收敛、老虎机
- 实验环境:多臂老虎机、ChainMDP、DeepSea、CartPole
-
- 查尔斯·阿尔纳尔、盖坦·纳罗兹尼亚克、维维安·卡班内斯、唐云浩、朱莉娅·肯佩、雷米·穆诺斯
- 关键词:强化学习、非策略RL、LLM微调、老虎机
- 实验环境:随机老虎机、MATH数据集
-
- 王立坤、张翔腾、王依诺、詹国建、王文轩、高浩宇、段景亮、李圣波
- 关键词:基于模型的强化学习、基于模型的探索、生成模型、世界模型
- 实验环境:OpenAI Gym、DMC
-
- 刘博恒、李子宇、段成华、刘宇田、王卓、李秀兴、李青、吴霞
- 关键词:开放式强化学习、受人脑启发的人工智能、认知架构
- 实验环境:MineDojo、Minecraft
-
- 安德烈亚斯·西奥菲卢、厄兹居尔·辛姆谢克
- 关键词:拉普拉斯算子、新颖性、强化学习、探索、特征向量、谱方法
- 实验环境:GridWorld
-
- 李哈林、吴珉焕
- 关键词:线性老虎机、贪婪选择
- 实验环境:多臂老虎机
-
- 张子涵、陈宇欣、李Jason D.、杜Simon Shaolei、杨琳、王若松
- 关键词:强化学习、线性MDP、部署效率
- 实验环境:无
-
- 潘一元、刘哲、王和生
- 关键词:多智能体强化学习、内在奖励、人工好奇心
- 实验环境:VMAS、Meltingpot、SMACv2
-
- 李英茹、徐嘉伟、王宝祥、罗志全
- 关键词:强化学习、集成采样、汤普森采样、探索、后验近似、可扩展计算
- 实验环境:线性老虎机、二次型老虎机、神经网络老虎机、基于GPT的上下文老虎机
-
- 斯科特·程、蔡孟瑜、洪定勇、马赫穆特·坎德米尔
- 关键词:AlphaZero、不确定性、探索
- 实验环境:围棋
从对偶视角看探索:价值激励的演员-评论家方法用于样本高效的在线强化学习
- 杨彤、戴博、肖林、迟跃杰
- 关键词:探索-利用权衡、演员-评论家、强化学习理论
- 实验环境:MuJoCo
-
- 李启阳、周志远、谢尔盖·莱文
- 关键词:强化学习、离线到在线RL、探索
- 实验环境:OGBench、robomimic
-
- 利安德·迪亚斯-博恩、马可·巴加泰拉、乔纳斯·休博特、安德烈亚斯·克劳斯
- 关键词:强化学习、测试时训练、测试时强化学习、稀疏奖励强化学习、目标选择、目标条件强化学习、探索、探索-利用权衡、上界置信区间
- 实验环境:antmaze、arm、pointmaze
-
- 伊奥内尔·霍苏、特赖安·雷贝迪亚、拉兹万·帕斯卡努
- 关键词:深度强化学习、宏动作、探索
- 实验环境:Atari、街头霸王II
-
- 周瑞阳、李硕哲、张艾米、刘乐琪
- 关键词:大型语言模型、自我提升、引导式探索、推理、具有可验证奖励的强化学习、自举法
- 实验环境:MATH、GSM8K、MATH-500
ICML 2025
(点击收起)
-
- 高世清、丁嘉鑫、傅罗毅、王新兵
- 关键词:约束强化学习、安全探索、低估偏差、内在成本、强化学习。
- 实验环境:safety-gymnasium、MuJoCo
-
- 法希姆·塔兹瓦尔、姜一丁、阿比塔·桑卡拉杰、苏迈塔·萨迪亚·拉赫曼、J·齐科·科尔特、杰夫·施奈德、罗斯·萨拉胡丁诺夫
- 关键词:LLM智能体、合成数据、多轮微调。
- 实验环境:二十问、猜城市、Wordle、元胞自动机、客户服务、谋杀之谜、Mastermind、海战棋、扫雷、老虎机最佳臂选择
-
- 尹在锡、赵贤书、白斗镇、约书亚·本吉奥、安成镇
- 关键词:扩散模型、MCTS、长期规划、离线强化学习、目标条件强化学习、推理时缩放。
- 实验环境:PointMaze、AntMaze、机械臂操作立方体、视觉PointMaze
-
- 朱庆林、赵润聪、严汉奇、何玉兰、陈宇东、桂琳
- 关键词:大型语言模型、推理、嵌入扰动、贝叶斯优化。
- 实验环境:无
-
- 王怡然、刘晨舒、李云帆、萨娜·阿马尼、周博磊、杨林峰
- 关键词:强化学习、探索、可证明高效、超参数鲁棒性。
- 实验环境:PointMaze、MuJoCo、MiniGrid
-
- 岳博、李健、刘贵良
- 关键词:逆向约束强化学习、探索算法、样本效率。
- 实验环境:PointMaze、GridWorld
-
- 澳森·A·阮、安里·古、迈克尔·P·韦尔曼
- 关键词:经验博弈论分析、均衡选择、博弈求解、策略探索。
- 实验环境:Harvest、讨价还价
-
- 董晓义、程健、张曦雪莉
- 关键词:扩散模型、在线强化学习、最大熵强化学习、软演员-评论家。
- 实验环境:Mujoco、AntMaze、DeepMind Control Suite
-
- 冯朗、谭伟豪、吕志毅、郑龙涛、徐海洋、颜明、黄飞、安博
- 关键词:视觉-语言模型、智能体、强化学习、在线微调、反事实。
- 实验环境:Android-in-the-Wild、Gym Cards、ALFWorld
-
- 奥努尔·切利克、李泽楚、丹尼斯·布莱辛、李戈、丹尼尔·帕列尼切克、扬·彼得斯、乔治娅·查尔瓦察基、格哈德·诺伊曼
- 关键词:强化学习、扩散模型、基于扩散的强化学习、最大熵强化学习。
- 实验环境:Mujoco、DeepMind Control Suite、Myo Suite
-
- 傅浩天、孙一翔、迈克尔·利特曼、乔治·科尼达里斯
- 关键词:深度强化学习、模型基强化学习、持续学习、世界模型。
- 实验环境:MiniGrid、DeepMind Control Suite
-
- 杨士敏、马丁·马格努松、约翰内斯·A·斯托克、托多尔·斯托亚诺夫
- 关键词:强化学习、基于新颖性的探索、软演员-评论家、稀疏奖励。
- 实验环境:2D导航、DeepMind Control Suite
-
- 艾伦·聂、苏易、常博、李乔纳森、奇埃德·H、黎光国、陈敏敏
- 关键词:探索、上下文强化学习、老虎机问题。
- 实验环境:多臂老虎机、上下文老虎机
-
- 马浩哲、李芳玲、林静宇、罗正定、武青荣、梁泽云
- 关键词:强化学习、奖励塑造、探索-利用平衡。
- 实验环境:Atari、VizDoom、MiniWorld
-
- 詹苏·桑恰克塔尔、克里斯蒂安·贡布施、安德烈·扎达扬丘克、帕维尔·科列夫、格奥尔格·马提乌斯
- 关键词:内在动机、探索、基础模型、模型基强化学习。
- 实验环境:MiniHack、Robodesk、宝可梦红版
-
- 安德鲁·瓦根梅克、周志远、谢尔盖·列维纳
- 关键词:上下文学习、探索、适应性智能体、行为模仿。
- 实验环境:D4RL AntMaze、D4RL Kitchen
-
- 马克斯·威尔科克森、李启阳、凯文·弗兰斯、谢尔盖·列维纳
- 关键词:离线转在线强化学习、无监督预训练、探索。
- 实验环境:D4RL、OGBench、视觉AntMaze
ICLR 2025
(点击收起)
-
- 姜宇华、刘启涵、杨一钦、马晓腾、钟典宇、胡浩、杨俊、梁斌、徐博、张冲杰、赵千川
- 关键词:情节新颖性、时间距离、探索、强化学习
- 实验环境:MiniGrid、MiniWorld、Craft、Maze、DMControl等。
Brain Bandit:一种基于生物学原理的神经网络,用于高效控制探索行为
- 蒋晨、安佳慧、刘雅婷、季妮
- 关键词:探索-利用、随机霍普菲尔德网络、汤普森采样、不确定性下的决策、脑启发算法、强化学习
- 实验环境:多臂老虎机(MAB)任务、MDP任务。
TOP-ERL:基于Transformer的离策略情节式强化学习
- 李戈、田东、周宏毅、蒋欣凯、鲁道夫·柳蒂科夫、格哈德·诺伊曼
- 关键词:动作序列的价值、强化学习、Transformer、机器人操作、运动基元
- 实验环境:机器人学习环境。
-
- 安东尼·GX-陈、肯尼思·马里诺、罗布·费格斯
- 关键词:强化学习、基于模型的强化学习、世界模型、探索、层次结构
- 实验环境:2D工艺制作、MiniHack环境。
MaxInfoRL:通过最大化信息增益提升强化学习中的探索能力
- 巴维亚·苏基贾、斯特利安·科罗斯、安德烈亚斯·克劳塞、皮特·阿贝尔、卡梅洛·斯费拉扎
- 关键词:强化学习、离策略方法中的探索、连续控制
- 实验环境:连续控制和视觉控制任务。
-
- 亚尔登·阿斯、巴维亚·苏基贾、莱纳特·特雷文、卡梅洛·斯费拉扎、斯特利安·科罗斯、安德烈亚斯·克劳塞
- 关键词:安全探索、约束马尔可夫决策过程、安全强化学习
- 实验环境:标准的安全深度强化学习基准。
只需一个目标就够了:无需奖励、示范或子目标,对比强化学习即可涌现技能与探索行为
- 格蕾丝·刘、迈克尔·唐、本杰明·艾森巴赫
- 关键词:探索、涌现技能、对比强化学习、开放性学习
- 实验环境:2D迷宫导航任务。
-
- 考斯图布·马尼、文森特·迈、查理·戈蒂耶、安妮·S·陈、萨默·B·纳什德、利亚姆·保尔
- 关键词:强化学习、安全探索、表征学习、归纳偏置
- 实验环境:AdroitHandPen、PointGoal1和PointButton1。
-
- 李天旭、朱坤
- 关键词:多智能体强化学习、探索、合作、轨迹熵最大化
- 实验环境:多个MARL基准。
-
- 赵海阳、于兴睿、大卫·马克·博森斯、伊沃·曾、关权权
- 关键词:强化学习、模仿学习、双重探索
- 实验环境:Atari、MuJoCo。
-
- 余伟、尹松恒、史蒂夫·伊斯特布鲁克、阿尼梅什·加格
- 关键词:可控视频生成、自我中心视频预测、世界模型
- 实验环境:RealEstate、Epic-Field。
NeurIPS 2024
(点击收起)
-
- Chengyang Ying, Zhongkai Hao, Xinning Zhou, Xuezhou Xu, Hang Su, Xingxing Zhang, Jun Zhu
- 关键词:跨化身强化学习、无监督探索、技能发现、内在奖励
- 实验环境:DeepMind Control Suite、Robosuite、Isaacgym,以及真实世界的运动任务
-
- Dengwei Zhao, Shikui Tu, Lei Xu
- 关键词:通过选择性采样构建动态OPEN集合,以探索有潜力的分支;理论与实证层面均提升了效率。
- 实验环境:逆合成规划(有机化学)、逻辑综合(IC设计)以及推箱子游戏。
-
- Gabriel Poesia, David Broman, Nick Haber, Noah Goodman
- 关键词:在自我改进的循环中联合学习证明形式化数学定理,并提出更难的可证猜想;利用依赖类型理论和事后重标记技术提升样本效率。
- 实验环境:命题逻辑、算术和群论。
-
- Shaoteng Liu, Haoqi Yuan, Minda Hu, Yanwei Li, Yukang Chen, Shu Liu, Zongqing Lu, Jiaya Jia
- 关键词:结合强化学习与大型语言模型的两层层次化框架;通过将高层规划的代码编写与低层动作的强化学习相结合,实现高效执行。
- 实验环境:Minecraft及MineDojo任务。
-
- Simone Parisi, Alireza Kazemipour, Michael Bowling
- 关键词:强化学习、部分可观性、乐观主义、探索
- 实验环境:表格型环境(含不可观测奖励与不含不可观测奖励)
-
- Yuanlin Duan, Guofeng Cui, He Zhu
- 关键词:目标条件强化学习、探索、潜在空间聚类
- 实验环境:多足蚂蚁迷宫、机械臂操作(杂乱桌面)、拟人化手部物体旋转
-
- David Yunis, Justin Jung, Falcon Dai, Matthew Walter
- 关键词:稀疏奖励强化学习、技能生成、分词、连续动作空间
- 实验环境:具有挑战性的稀疏奖励任务
-
- Arushi Jain, Josiah P. Hanna, Doina Precup
- 关键词:通用价值函数、强化学习、数据效率
- 实验环境:表格型设置、非线性函数近似、Mujoco环境(平稳与非平稳奖励信号)
-
- Kaichen Huang, Shenghua Wan, Minghao Shao, Hai-Hang Sun, Le Gan, Shuai Feng, De-Chuan Zhan
- 关键词:基于模型的强化学习、无监督强化学习(URL)、视觉干扰、双层优化
- 实验环境:运动任务、操纵任务
-
- Xianghua Zeng, Hao Peng, Angsheng Li
- 关键词:强化学习、结构信息、有效探索、内在奖励
- 实验环境:MiniGrid、MetaWorld、DeepMind Control Suite
-
- Hongyao Tang, Min Zhang, Chen Chen, Jianye Hao
- 关键词:强化学习、策略学习动力学、时间序列奇异值分解、低维空间
- 实验环境:MuJoCo、DeepMind Control Suite (DMC)、MinAtar
-
- Yiming Wang, Kaiyan Zhao, Furui Liu, Leong Hou U
- 关键词:强化学习、探索、内在奖励、基于度量的状态差异
- 实验环境:Atari、Minigrid、Robosuite、Habitat
- 代码
通过分层探索-利用权衡实现上下文MDP的离线Oracle高效学习
- Jian Qian, Haichen Hu, David Simchi-Levi
- 关键词:上下文马尔可夫决策过程(CMDPs)、离线密度估计、分层探索-利用权衡
- 实验环境:免奖励强化学习
ICML 2024
(点击收起)
Q-Star 遇见可扩展后验采样:通过超智能体桥接理论与实践
- 李英茹、徐嘉伟、韩磊、罗志全
- 关键词:集成方法、汤普森采样、可扩展探索、后悔分析、复杂度理论
- 实验环境:Atari、DeepSea
ACE:具有因果感知熵正则化的离策略Actor-Critic 算法
- 季天颖、梁勇远、曾燕、罗宇、徐国伟、郭嘉伟、郑睿杰、黄福荣、孙富春、许华哲
- 关键词:具有因果感知熵正则化的离策略Actor-Critic、探索、因果感知熵正则化
- 实验环境:MetaWorld、DeepMind Control Suite、Dexterous Hand、稀疏奖励
-
- 斯里纳特·V·马汉卡利、洪章伟、阿尤什·塞卡里、亚历山大·拉克林、普尔基特·阿格拉瓦尔
- 关键词:随机潜在探索、通过向原始任务奖励中添加结构化随机奖励来扰动奖励
- 实验环境:ATARI、ISAACGYM
-
- 杨凯、陶健、吕佳飞、李秀
- 关键词:奖励不一致性、分布式随机网络蒸馏、探索与反探索
- 实验环境:Atari、Adroit、Fetch 操控任务
-
- 尹英植、李刚博、安成洙、奥贞雪
- 关键词:广度优先探索、自适应网格、探索效率
- 实验环境:GridWorld、Atari、Procgen
-
- 斯特凡·西尔维乌斯·瓦格纳、斯特凡·哈梅林
- 关键词:以表征为中心的探索视角、聚类、预训练表征
- 实验环境:VizDoom 和 Habitat
通过状态占用正则化实现蒙特卡洛树搜索中可证明高效的长 horizon 探索
- 利亚姆·施拉姆、阿卜德斯拉姆·布拉里亚斯
- 关键词:蒙特卡洛树搜索、长 horizon 探索、状态占用正则化
- 实验环境:机器人导航问题
-
- 维克拉恩特·德瓦拉切拉、赛义德·穆罕默德·阿斯加里、郝博涛、本杰明·范·罗伊
- 关键词:探索、大型语言模型、高效探索
- 实验环境:语言任务
-
- 菲利普·阿莫蒂拉、迪伦·J·福斯特、阿克谢·克里希纳穆提
- 关键词:L1 覆盖、内在复杂度控制、高效规划、高效探索
- 实验环境:MountainCar
-
- 张俊凯、张伟彤、周东若、关权权
- 关键词:不确定性感知的内在奖励、无奖励探索、通用函数逼近
- 实验环境:DeepMind Control Suite
-
- 白晨嘉、杨如帅、张乔生、徐康、陈毅、肖婷、李学龙
- 关键词:约束型集成探索、无监督技能发现、基于状态原型的分区探索
- 实验环境:URLB 任务、迷宫
-
- 马蒂·费洛斯、布兰登·加里·卡普洛维茨、克里斯蒂安·施罗德·德·维特、希蒙·怀特森
- 关键词:贝叶斯探索网络、探索、不确定性估计
- 实验环境:一种新颖的搜救网格 MDP
-
- 里卡多·德·桑蒂、费德里科·阿兰加特·约瑟夫、诺亚·利尼格、米尔科·穆蒂、安德烈亚斯·克劳斯
- 关键词:几何主动探索、抽象、探索效率
- 实验环境:受科学发现问题启发的环境
-
- 马龙、王元飞、钟方伟、朱松纯、王一舟
- 关键词:同伴适应、上下文感知探索、快速适应
- 实验环境:竞争性(库恩扑克)、合作性(PO-Overcooked)或混合性(Predator-Prey-W)游戏
-
- 李欣然、刘子凡、陈世博、张军
- 关键词:个体贡献、内在探索、多智能体强化学习
- 实验环境:Google Research Football、SMAC
ICLR 2024
(点击收起)
-
- Alaa Saade, Steven Kapturowski, Daniele Calandriello, Charles Blundell, Pablo Sprechmann, Leopoldo Sarra, Oliver Groth, Michal Valko, Bilal Piot
- 关键点:基于聚类的在线密度估计实现稳健探索
- 实验环境:Atari、DM-HARD-8
-
- Cassidy Laidlaw, Banghua Zhu, Stuart Russell, Anca Dragan
- 关键点:随机环境、有效时 horizon、强化学习理论、实例相关界、理论的实证验证
- 实验环境:BRIDGE
-
- Guowei Xu, Ruijie Zheng, Yongyuan Liang, Xiyao Wang, Zhecheng Yuan, Tianying Ji, Yu Luo, Xiaoyu Liu, Jiaxin Yuan, Pu Hua, Shuzhen Li, Yanjie Ze, Hal Daumé III, Furong Huang, Huazhe Xu
- 关键点:视觉强化学习、休眠比率最小化、探索
- 实验环境:DeepMind Control Suite、MetaWorld 和 Adroit
-
- Seohong Park, Oleh Rybkin, Sergey Levine
- 关键点:无监督强化学习、度量感知抽象、可扩展探索
- 实验环境:基于状态的 Ant 和 HalfCheetah、Kitchen
-
- Tianbao Xie, Siheng Zhao, Chen Henry Wu, Yitao Liu, Qian Luo, Victor Zhong, Yanchao Yang, Tao Yu
- 关键点:奖励塑造、语言模型、基于文本的奖励塑造
- 实验环境:MUJOCO、MANISKILL2、METAWORLD
-
- Haoqi Yuan, Zhancun Mu, Feiyang Xie, Zongqing Lu
- 关键点:目标导向模型、预训练、样本效率
- 实验环境:Kitchen、Minecraft。
-
- Hyungho Na, Yunkyeong Seo, Il-chul Moon
- 关键点:周期性记忆、合作式多智能体、高效利用
- 实验环境:StarCraft II 和 Google Research Football
-
- Chang Chen, Fei Deng, Kenji Kawaguchi, Caglar Gulcehre, Sungjin Ahn
- 关键点:层次化规划、扩散、探索
- 实验环境:Maze2D 和 AntMaze
-
- Ziping Xu, Zifan Xu, Runxuan Jiang, Peter Stone, Ambuj Tewari
- 关键点:短视探索、多任务强化学习、多样化任务
- 实验环境:合成机器人控制环境
-
- Zhe Wu, Haofei Lu, Junliang Xing, You Wu, Renye Yan, Yaozhong Gan, Yuanchun Shi
- 关键点:外部知识、高效探索、强化学习
- 实验环境:BabyAI 和 MiniHack
-
- Zhenwen Dai, Federico Tomasi, Sina Ghiassian
- 关键点:上下文情境下的探索–利用权衡、强化学习、探索–利用权衡
- 实验环境:Dark Room、Dark Key-to-Door、偏置版 Dark Room。
Transformer 作为决策者:通过监督预训练实现可证明的上下文情境强化学习
- Licong Lin, Yu Bai, Song Mei
- 关键点:Transformer、决策者、上下文情境强化学习
- 实验环境:线性 bandit、伯努利 bandits。
-
- Dominik Schmidt, Minqi Jiang
- 关键点:从视频中恢复潜在动作信息、预训练
- 实验环境:Procgen
-
- Mingde Zhao, Safa Alver, Harm van Seijen, Romain Laroche, Doina Precup, Yoshua Bengio
- 关键点:时空抽象、层次化规划、任务/目标分解
- 实验环境:MiniGrid-BabyAI
NeurIPS 2023
(点击收起)
-
- 刘志涵、陆淼、熊伟、钟翰、胡浩、张申奥、郑思睿、杨竹然、王兆然
- 关键点:一个整合了估计和规划组件的单一目标函数,能够自动平衡探索与利用,实现次线性遗憾。
- 实验环境:稀疏奖励的MuJoCo
-
- 蒋一丁、J·齐科·科尔特、罗伯塔·赖莱阿努
- 关键点:探索、泛化、基于分布集成的探索方法。
- 实验环境:表格型上下文MDP、Procgen和Crafter
-
- 迈克尔·潘特、穆罕默德·巴尤米、尼克·霍斯、布鲁诺·拉塞尔达
- 关键点:结合MCTS的玻尔兹曼探索,最大熵目标下的最优动作并不一定对应于原始目标的最优动作,提出了两种改进算法。
- 实验环境:Frozen Lake环境、航海问题、围棋
-
- 马塞尔·托尔内·维拉塞维尔、马克斯·巴尔塞尔斯·伊·帕米耶斯、王子涵、萨梅德·戴赛、陈涛、普尔基特·阿格拉瓦尔、阿比谢克·古普塔
- 关键点:人机交互反馈、人类反馈与策略学习的分叉机制。
- 实验环境:Bandu、积木堆叠、厨房和推杆任务,以及四个房间和迷宫环境。
-
- 林拓、艾伦·贾布里
- 关键点:采用不同掩码分布进行伪似然估计。
- 实验环境:PixMC-Sparse、DeepMind Control Suite
-
- 李启阳、张杰森、迪比亚·戈什、张艾米、谢尔盖·列文
- 关键点:使用无奖励标签的先验数据,通过在线经验学习奖励模型,并以乐观奖励为未标注的先验数据打上标签。
- 实验环境:AntMaze领域、Adroit手部操作领域,以及一个视觉模拟的机器人操作领域。
-
- 张帅、李洪康、王萌、刘淼、陈品宇、卢松涛、刘思佳、穆鲁格桑、乔杜里
- 关键点:ε-贪心探索、收敛性、样本复杂度。
- 实验环境:数值实验
-
- 曹泰贤、韩承烨、李熙洙、李京宰、李正宇
- 关键点:分布强化学习、随机化风险准则、乐观探索。
- 实验环境:Atari 55款游戏。
-
- 李承宰、曹大瑟、朴宗海、金亨镇
- 关键点:课程式强化学习、量化世界模型。
- 实验环境:PointNMaze
-
- 渡边彰史、桥本亘、沈勋、桥本一宗
- 关键点:安全探索、广义形式、安全探索算法、安全探索元算法。
- 实验环境:网格世界和Safety Gym
-
- 俞昌珉、尼尔·伯吉斯、马尼什·萨哈尼、塞缪尔·J·格什曼
- 关键点:基于转移序列的回溯结构,结合前瞻与回溯信息。
- 实验环境:网格世界、MountainCar、Atari
-
- 金东英、申振宇、彼得·阿贝尔、徐永教
- 关键点:价值条件状态熵探索。
- 实验环境:MiniGrid、DeepMind Control Suite和Meta-World
-
- 王子昭、胡家恒、彼得·斯通、罗伯托·马丁-马丁
- 关键点:局部依赖关系、探索奖励、内在动机,鼓励发现实体间的新型交互。
- 实验环境:从二维网格世界到三维机器人任务。
ICML 2023
(点击收起)
情境马尔可夫决策过程中的全局与 episodic 奖励用于探索的研究
- 米卡埃尔·亨纳夫、蒋敏琪、罗伯塔·赖莱阿努
- 关键词:全局新颖性奖励、episodic 新颖性奖励、共享结构
- 实验环境:Mini-Hack 套件、Habitat 和蒙特祖玛的复仇
-
- 丹尼尔·贾雷特、科伦坦·塔莱克、弗洛朗·阿尔切、托马斯·梅斯纳、雷米·穆诺斯、米哈尔·瓦尔科
- 关键词:随机环境、将“噪声”与“新颖性”分离、BYOL-Hindsight
- 实验环境:Pycolab 迷宫、Atari、Bank Heist
-
- 雅什·钱达克、桑塔努·塔库尔、赵汉·丹尼尔·郭、唐云浩、雷米·穆诺斯、威尔·达布尼、黛安娜·博尔萨
- 关键词:奇异值分解、状态访问频率的相对大小、将该分解方法扩展到大规模领域
- 实验环境:DMLab-30、DM-Hard-8
-
- 黄志傲、梁立天、凌展、李轩林、甘创、苏浩
- 关键词:多模态策略参数化、最优轨迹的生成模型
- 实验环境: bandit、MetaWorld、2D 迷宫
-
- 萨姆·洛贝尔、阿希尔·巴加里亚、乔治·科尼达里斯
- 关键词:基于计数的探索、对 Rademacher 分布样本(或抛硬币)取平均
- 实验环境:Atari、D4RL、FETCH
-
- 达尼尔·蒂亚普金、丹尼斯·贝洛梅斯特尼、达尼埃莱·卡兰德里埃洛、埃里克·穆兰、雷米·穆诺斯、阿列克谢·瑙莫夫、皮埃尔·佩罗、唐云浩、米哈尔·瓦尔科、皮埃尔·梅纳尔
- 关键词:最大化访问熵、博弈论算法、轨迹熵
- 实验环境:Double Chain MDP
-
- 杜宇青、奥利维亚·沃特金斯、王子涵、克莱德里克·科拉斯、特雷弗·达雷尔、皮特·阿比尔、阿比舍克·古普塔、雅各布·安德烈亚斯
- 关键词:利用文本语料库中的背景知识来塑造探索行为,奖励智能体完成由语言模型根据当前状态描述所建议的目标。
- 实验环境:Crafter、Housekeep
具身智能体是否梦见像素化的羊?:基于语言指导的世界建模的具身决策
- 科尔比·诺丁汉、普里特维拉吉·阿曼纳布鲁卢、阿拉恩·苏尔、叶津·崔、汉娜内·哈吉希日齐、萨米尔·辛格、罗伊·福克斯
- 关键词:用于规划和探索的抽象世界模型(AWM)、LLM 引导的探索、梦阶段和醒阶段
- 实验环境:Minecraft
-
- 凯文·加卢勒德克、埃马纽埃尔·德尔安德拉莱亚
- 关键词:潜在 Go-Explore、学习得到的潜在表征
- 实验环境:2D 迷宫、panda-gym、Atari
-
- 傅瑶、彭润、李洪洛克
- 关键词:一种旨在最大化每步可达性扩展的 episodic 内在奖励
- 实验环境:Minigrid、DeepMind Control Suite
-
- 菲利普·J·鲍尔、劳拉·史密斯、伊利亚·科斯特里科夫、谢尔盖·列文
- 关键词:样本效率与探索、简单地将现有的 off-policy 方法应用于在线学习时的离线数据、影响性能的关键因素、一组建议
- 实验环境:D4RL AntMaze、Locomotion、Adroit
-
- 亚历山大·尼库林、弗拉季斯拉夫·库伦科夫、丹尼斯·塔拉索夫、谢尔盖·科列斯尼科夫
- 关键词:不确定性估计器、反探索奖励、特征线性调制
- 实验环境:D4RL
-
- 阿马尔·侯赛因、弗朗切斯科·贝拉尔迪内利、达里奥·帕卡尼亚
- 关键词:在任意游戏中,即使无法保证收敛到均衡点,探索如何影响强化学习动态?
- 实验环境:Network Shapley Game、Network Chakraborty Game、任意游戏
-
- 金宇俊、成英哲
- 关键词:自适应熵正则化框架、适当的探索熵水平、解耦的价值函数
- 实验环境:SMAC、多智能体 HalfCheetah
-
- 刘博尹、蒲志强、潘毅、易建强、梁艳艳、张杜
- 关键词:通过影响外部状态避免懒惰智能体、个体勤勉内在动机(IDI)与协作勤勉内在动机(CDI)、外部状态转移模型
- 实验环境:SMAC、Google Research Football
-
- 袁明琦、李博、金鑫、曾文俊
- 关键词:从预定义集合中选择塑造函数、一个内在奖励工具包
- 实验环境:MiniGrid、Procgen 和 DeepMind Control Suite
-
- 金宇俊、金正惠、成英哲
- 关键词:option-critic 模型、自适应选择最有效的探索策略
- 实验环境:MiniGrid 和 Atari
ICLR 2023
(点击收起)
可学习的行为控制:通过样本高效的行为选择打破雅达利人类世界纪录 (口头报告:10, 8, 8)
- 范家俊、庄宇正、刘岳成、郝建业、王斌、朱江成、王浩、夏树涛
- 关键词:可学习的行为控制、混合行为映射、统一的可学习行为选择流程、基于多臂老虎机的元控制器
- 实验环境:Atari
覆盖在在线强化学习中的作用 (口头报告:8, 8, 5)
- 谢腾阳、迪伦·J·福斯特、白宇、蒋楠、沙姆·M·卡卡德
- 关键词:覆盖条件、数据记录分布、样本高效探索、序列外推系数
- 实验环境:无
主动强化学习中的近最优策略识别 (口头报告:8,8,8)
- 李翔、维拉吉·梅塔、约翰内斯·基尔希纳、伊恩·查尔、威利·奈斯万格、杰夫·施奈德、安德烈亚斯·克劳塞、伊利雅·博古诺维奇
- 关键词:核化最小二乘值迭代,结合乐观与悲观策略进行主动探索
- 实验环境:Cartpole、导航、跟踪、旋转、Branin-Hoo、Hartmann
为探索规划目标 (亮点论文:8, 8, 8, 8, 6)
- 爱德华·S·胡、理查德·张、奥列·雷布金、迪内什·贾亚拉曼
- 关键词:目标条件化、规划探索目标、世界模型、基于采样的规划算法
- 实验环境:点迷宫、Walker、蚂蚁迷宫、三块堆叠
粉红噪声就够了:深度强化学习中的彩色噪声探索 (亮点论文:8, 8, 8)
- 欧诺·埃伯哈德、雅各布·霍伦斯坦、克里斯蒂娜·皮内里、格奥尔格·马提乌斯
- 关键词:连续动作空间、时间相关噪声、彩色噪声
- 实验环境:DeepMind Control Suite、Atari、Adroit手部套件
从专家那里学习进度 (亮点论文:8, 8, 6)
- 杰克·布鲁斯、安基特·阿南德、博格丹·马祖雷、罗布·费格斯
- 关键词:利用专家演示、长 horizon 任务、学习一个单调递增的函数来总结进度
- 实验环境:NetHack
DEP-RL:面向过度驱动和肌肉骨骼系统的具身强化学习探索 (亮点论文:10, 8, 8, 8)
- 皮埃尔·舒马赫、丹尼尔·豪夫勒、迪特·比希勒、辛·施密特、格奥尔格·马提乌斯
- 关键词:大型过度驱动动作空间、差分外在可塑性、状态空间覆盖式探索
- 实验环境:肌肉骨骼系统:torquearm、arm26、humanreacher、鸵鸟觅食、鸵鸟奔跑、人类奔跑、人类跳跃
是否存在零样本强化学习? (亮点论文:10, 8, 8,3)
- 阿迈德·图阿蒂、热雷米·拉潘、扬·奥利维耶
- 关键词:零样本强化学习智能体、将通用表征学习与探索解耦、使用拉普拉斯特征函数的SFs
- 实验环境:无监督RL和ExORL基准测试
以200倍更快的速度达到人类水平的雅达利游戏 (海报展示:8, 8, 3)
- 史蒂文·卡普图罗夫斯基、维克托·坎波斯、雷·姜、涅曼亚·拉基切维奇、哈多·范哈塞尔特、查尔斯·布伦德尔、阿德里亚·普伊格多梅内奇·巴迪亚
- 关键词:经验需求减少200倍、更鲁棒高效的智能体
- 实验环境:Atari 57款游戏
针对稀疏奖励领域的结构化探索:学习成就结构 (海报展示:8, 8, 5, 5)
- 周子涵、阿尼梅什·加格
- 关键词:基于成就的环境、恢复依赖图
- 实验环境:Crafter、TreeMaze
对于免奖励强化学习而言,安全探索几乎不会增加额外的样本复杂度 (海报展示:8, 8, 6, 6)
- 黄瑞泉、杨静、梁英斌
- 关键词:免奖励强化学习、通过最少轨迹数降低对估计模型的不确定性
- 实验环境:表格MDP、低秩MDP
潜在状态边缘化作为提升探索效率的低成本方法 (海报展示:6, 6, 6)
- 张丁怀、阿隆·库维尔、约书亚·本吉奥、郑钦青、艾米·张、陈奕廷
- 关键词:在MaxEnt框架下采用潜在变量策略、对潜在状态进行低成本边缘化
- 实验环境:DeepMind Control Suite
重新审视程序化生成环境中的好奇心驱动探索 (海报展示:8, 8, 5, 3, 3)
- 王凯欣、周匡齐、康炳义、冯嘉仕、颜水成
- 关键词:终身内在奖励与周期性内在奖励,所有终身-周期性组合的表现
- 实验环境:MiniGrid
MoDem:利用示范加速基于视觉模型的强化学习 (海报展示:8, 6, 6, 6)
- 尼克拉斯·汉森、林一新、苏浩、王小龙、维卡什·库马尔、阿拉文德·拉杰斯瓦兰
- 关键词:在模型学习中利用示范的关键要素
- 实验环境:Adroit、Meta-World、DeepMind Control Suite
简化基于模型的强化学习:用单一目标同时学习表征、隐空间模型和策略 (海报展示:8, 6, 6, 6, 6)
- 拉杰·古加雷、霍芒加·巴拉德瓦杰、本杰明·艾森巴赫、谢尔盖·莱文、罗斯·萨拉胡丁诺夫
- 关键词:这些辅助目标与强化学习目标的一致性、预期回报的下界
- 实验环境:基于模型的基准测试
EUCLID:迈向高效的多选动态模型无监督强化学习 (海报展示:6, 6, 6, 6)
- 袁益夫、郝建业、倪飞、穆瑶、郑彦、胡玉京、刘金毅、陈英峰、范昌杰
- 关键词:转移动态建模、多选动态模型、采样效率
- 实验环境:URLB
带有不完美在线示范的受保护策略优化 (口头报告:8, 8, 6, 5)
- 薛正海、彭正浩、李全义、刘志翰、周博磊
- 关键词:师生共享控制、安全保证与探索引导、基于轨迹的价值估计
- 实验环境:MetaDrive
NeurIPS 2022
(点击收起)
通过约束优化兑现内在奖励(海报:8, 7, 7)
- Eric Chen、Zhang-Wei Hong、Joni Pajarinen、Pulkit Agrawal
- 关键点:自动调整内在奖励的重要性,基于原则的约束策略优化方法
- 实验环境:Atari
你只活一次:基于学习奖励塑造的单次强化学习(海报:6, 6, 5, 5)
- Annie S. Chen、Archit Sharma、Sergey Levine、Chelsea Finn
- 关键点:单次强化学习,Q加权对抗性学习(QWALE),分布匹配策略
- 实验环境:桌面整理、Pointmass、修改版HalfCheetah、修改版Franka-Kitchen
通过结构化世界模型进行好奇探索实现零样本目标操作(海报:8, 7, 6)
- Cansu Sancaktar、Sebastian Blaes、Georg Martius
- 关键点:良好模型与良好探索之间的自我强化循环,通过基于模型的规划实现对下游任务的零样本泛化
- 实验环境:游乐场、Fetch Pick & Place Construction
基于模型的贝叶斯探索终身强化学习(海报:7, 6, 6)
- Haotian Fu、Shangqun Yu、Michael Littman、George Konidaris
- 关键点:层次化贝叶斯后验
- 实验环境:Mujoco和Meta-world的HiP-MDP版本
关于非线性强化学习中无奖励探索的统计效率(海报:7, 6, 5, 5)
- Jinglin Chen、Aditya Modi、Akshay Krishnamurthy、Nan Jiang、Alekh Agarwal
- 关键点:样本高效的无奖励探索,可探索性或可达性假设
- 实验环境:无
DOPE:双重乐观与悲观探索用于安全强化学习(海报:8, 7, 4)
- Archana Bura、Aria Hasanzadezonuzy、Dileep Kalathil、Srinivas Shakkottai、Jean-Francois Chamberland
- 关键点:基于模型的安全强化学习,有限 horizon 约束马尔可夫决策过程,带有保守约束的探索奖励(乐观与悲观结合)
- 实验环境:分解型 CMDP 环境
-
- Chenyang Wu、Tianci Li、Zongzhang Zhang、Yang Yu
- 关键点:面对不确定性时的乐观态度(OFU),贝叶斯乐观优化
- 实验环境:RiverSwim、Chain、随机 MDPs。
逆向强化学习中的主动探索(海报:7, 7, 7, 7)
- David Lindner、Andreas Krause、Giorgia Ramponi
- 关键点:主动探索未知环境和专家策略,无需环境的生成模型
- 实验环境:四条路径、随机 MDPs、双链、链、Gridworld
稀疏奖励下的探索引导奖励塑造强化学习(海报:6, 6, 4)
- Rati Devidze、Parameswaran Kamalaruban、Adish Singla
- 关键点:奖励塑造、内在奖励函数、基于探索的奖励加成。
- 实验环境:Chain、Room、Linek
蒙特卡洛增强演员-评论家算法:从次优示范中学习稀疏奖励深度强化学习(海报:6, 6, 5, 5)
- Albert Wilcox、Ashwin Balakrishna、Jules Dedieu、Wyame Benslimane、Daniel S. Brown、Ken Goldberg
- 关键点:无参数,标准 TD 目标与未来奖励蒙特卡洛估计值中的最大值。
- 实验环境:Pointmass 导航、方块提取、序列推动、开门、方块提升
激励组合多臂赌博机探索(海报:7, 6, 5, 3)
- Xinyan Hu、Dung Daniel Ngo、Aleksandrs Slivkins 和 Zhiwei Steven Wu
- 关键点:激励探索,大规模结构化动作集和高度相关的信念,组合半赌博机。
- 实验环境:无
ICML 2022
(点击收起)
从狄利克雷到鲁宾:无需奖励的强化学习中的乐观探索(口头报告)
- Daniil Tiapkin、Denis Belomestny、Eric Moulines、Alexey Naumov、Sergey Samsonov、Yunhao Tang、Michal Valko、Pierre Menard
- 关键点:Bayes-UCBVI、后悔界、Q值函数后验分布的分位数、狄利克雷加权和的反集中不等式
- 实验环境:简单的表格型网格世界环境,Atari
最大状态熵探索中非马尔可夫性的重要性(口头报告)
- Mirco Mutti、Riccardo De Santi、Marcello Restelli
- 关键点:最大状态熵探索,非马尔可夫性,有限样本 regime
- 实验环境:3State、River Swim
稀疏奖励目标条件强化学习中的相位式自模仿约简(亮点展示)
- Yunfei Li、Tian Gao、Jiaqi Yang、Huazhe Xu、Yi Wu
- 关键点:稀疏奖励目标条件 RL/SL 的相位式,任务约简
- 实验环境:Sawyer Push、Ant Maze、堆叠
汤普森采样用于(组合)纯探索(亮点展示)
- Siwei Wang、Jun Zhu
- 关键点:组合纯探索,汤普森采样,更低的复杂度
- 实验环境:组合式多臂赌博机
自主探索与多目标随机最短路径问题的近最优算法(亮点展示)
- Haoyuan Cai、Tengyu Ma、Simon Du
- 关键点:增量式自主探索,更强的样本复杂度界,多目标随机最短路径问题
- 实验环境:困难 MDP
安全探索用于高效策略评估和比较(亮点展示)
- Runzhe Wan、Branislav Kveton、Rui Song
- 关键点:为赌博机策略评估进行高效且安全的数据收集。
- 实验环境:多臂赌博机、上下文多臂赌博机、线性赌博机
ICLR 2022
(点击收起)
无监督强化学习的信息几何 (口头报告:8, 8, 8)
- Benjamin Eysenbach、Ruslan Salakhutdinov、Sergey Levine
- 关键词:无监督技能发现、互信息目标、对抗性选择的奖励函数
- 实验环境:无
智能体何时应该探索? (亮点论文:8, 8, 6, 6)
- Miruna Pislar、David Szepesvari、Georg Ostrovski、Diana Borsa、Tom Schaul
- 关键词:模式切换、非单一体的探索、情节内的探索
- 实验环境:Atari
通过乐观探索学习更多技能 (亮点论文:8, 8, 8, 6)
- DJ Strouse、Kate Baumli、David Warde-Farley、Vlad Mnih、Steven Hansen
- 关键词:判别器分歧内在奖励、信息增益辅助目标
- 实验环境:表格型网格世界、Atari
通过随机化回报分解学习长期奖励再分配 (亮点论文:8, 8, 8, 5)
- Zhizhou Ren、Ruihan Guo、Yuan Zhou、Jian Peng
- 关键词:稀疏且延迟的奖励、随机化回报分解
- 实验环境:MuJoCo
利用离线示范指导进行稀疏奖励强化学习 (亮点论文:8, 8, 8, 6, 6)
强化学习中基于生成式规划的时间协调探索 (亮点论文:8, 8, 8, 6)
在没有外部奖励的情况下学习强化学习中的利他行为 (亮点论文:8, 8, 6, 6)
用于可扩展探索的反集中置信奖金 (海报展示:8, 6, 5)
Lipschitz约束下的无监督技能发现 (海报展示:8, 6, 6, 6)
- Seohong Park、Jongwook Choi、Jaekyeom Kim、Honglak Lee、Gunhee Kim
- 关键词:无监督技能发现、Lipschitz约束
- 实验环境:MuJoCo
LIGS:用于多智能体学习的可学习内在奖励生成选择 (海报展示:8, 6, 5, 5)
文本游戏中用于战略探索的多阶段情节控制 (亮点论文:8, 8, 6, 6)
- Jens Tuyls、Shunyu Yao、Sham M. Kakade、Karthik R Narasimhan
- 关键词:多阶段方法、策略分解
- 实验环境:Jericho
关于强化学习中蒙特卡洛探索起点算法的收敛性 (海报展示:8, 8, 5, 5)
- Che Wang、Shuhan Yuan、Kai Shao、Keith Ross
- 关键词:蒙特卡洛探索起点、最优策略前馈MDP
- 实验环境:二十一点、悬崖漫步
NeurIPS 2021
(点击收起)
有趣对象、好奇智能体:学习任务无关的探索 (口头报告:9, 8, 8, 8)
深度强化学习中的战术性乐观与悲观 (海报展示:9, 7, 6, 6)
- Ted Moskovitz, Jack Parker-Holder, Aldo Pacchiano, Michael Arbel, Michael Jordan
- 关键词:战术性乐观与悲观估计、多臂赌博机问题
- 实验环境:MuJoCo
哪些互信息表征学习目标足以用于控制? (海报展示:7, 6, 6, 5)
- Kate Rakelly, Abhishek Gupta, Carlos Florensa, Sergey Levine
- 关键词:互信息目标、状态表征的充分性
- 实验环境:捕手、带抓取功能的捕手
关于每轮次一次反馈的强化学习理论 (海报展示:6, 5, 5, 4)
- Niladri S. Chatterji, Aldo Pacchiano, Peter L. Bartlett, Michael I. Jordan
- 关键词:二元反馈、亚线性遗憾
- 实验环境:无
MADE:通过最大化与已探索区域的偏离进行探索 (海报展示:7, 7, 6, 5)
- Tianjun Zhang, Paria Rashidinejad, Jiantao Jiao, Yuandong Tian, Joseph Gonzalez, Stuart Russell
- 关键词:最大化与已探索区域的偏离、内在奖励
- 实验环境:MiniGrid, DeepMind Control Suite
强化学习中的对抗性内在动机 (海报展示:7, 7, 6)
- Ishan Durugkar, Mauricio Tec, Scott Niekum, Peter Stone
- 关键词:Wasserstein-1距离、目标条件化、拟度量、对抗性内在动机
- 实验环境:网格世界、Fetch机器人(基于MuJoCo)
面向强化学习的信息导向奖励学习 (海报展示:9, 8, 7, 6)
- David Lindner, Matteo Turchetta, Sebastian Tschiatschek, Kamil Ciosek, Andreas Krause
- 关键词:专家查询、奖励的贝叶斯模型、最大化信息增益
- 实验环境:MuJoCo
用于鲁棒自监督探索的动态瓶颈 (海报展示:8, 6, 6, 6)
- Chenjia Bai, Lingxiao Wang, Lei Han, Animesh Garg, Jianye Hao, Peng Liu, Zhaoran Wang
- 关键词:动态瓶颈、信息增益
- 实验环境:Atari
用于高效探索的层次化技能 (海报展示:7, 6, 6, 6)
- Jonas Gehring, Gabriel Synnaeve, Andreas Krause, Nicolas Usunier
- 关键词:层次化技能学习、通用性与特异性的平衡、不同复杂度的技能
- 实验环境:障碍赛、林博舞、楼梯、GoalWall PoleBalance(基于MuJoCo)
多智能体竞争中的探索-利用:有限理性下的收敛 (亮点论文:8, 6, 6)
- Stefanos Leonardos, Georgios Piliouras, Kelly Spendlove
- 关键词:竞争性多智能体、游戏奖励与探索成本之间的平衡、独特的量化反应均衡
- 实验环境:双智能体重加权零和博弈
NovelD:简单而有效的探索准则 (海报展示:7, 6, 6, 6)
基于好奇心驱动探索的轮次式多智能体强化学习 (海报展示:7, 6, 6, 5)
- Lulu Zheng, Jiarui Chen, Jianhao Wang, Jiamin He, Yujing Hu, Yingfeng Chen, Changjie Fan, Yang Gao, Chongjie Zhang
- 关键词:轮次式多智能体、好奇心驱动的探索、预测误差、轮次记忆
- 实验环境:捕食者-猎物, StarCraft II
通过宏观目标在MOBA游戏中学习多样化策略 (海报展示:7, 6, 5, 5)
- Yiming Gao, Bei Shi, Xueying Du, Liang Wang, Guangwei Chen, Zhenjie Lian, Fuhao Qiu, Guonan Han, Weixuan Wang, Deheng Ye, Qiang Fu, Wei Yang, Lanxiao Huang
- 关键词:MOBA游戏、策略多样性、宏观目标引导框架、元控制器、人类示范
- 实验环境:王者荣耀
CIC:对比式内在控制用于无监督技能发现 (目前未被接受:8, 8, 6, 3)
- Michael Laskin, Hao Liu, Xue Bin Peng, Denis Yarats, Aravind Rajeswaran, Pieter Abbeel
- 关键词:互信息分解、粒子估计器、对比学习
- 实验环境:URLB
经典探索型强化学习论文
(点击收起)
- 利用置信区间进行探索-利用权衡 机器学习研究期刊,2002年
- Peter Auer
- 关键词:线性上下文赌博机
- 实验环境:无
基于上下文赌博机的个性化新闻文章推荐 WWW 2010
- Lihong Li, Wei Chu, John Langford, Robert E. Schapire
- 关键词:LinUCB
- 实验环境:雅虎首页今日模块数据集
(更)高效的强化学习:后验采样法 NeurIPS 2013
- Ian Osband, Benjamin Van Roy, Daniel Russo
- 关键词:先验分布、后验采样
- 实验环境:RiverSwim
汤普森采样的经验评估 NeurIPS 2011
- Olivier Chapelle, Lihong Li
- 关键词:汤普森采样、实验结果
- 实验环境:无
汤普森采样教程 arXiv 2017
- Daniel J. Russo, Benjamin Van Roy, Abbas Kazerouni, Ian Osband, Zheng Wen
- 关键词:汤普森采样
- 实验环境:无
统一基于计数的探索与内在动机 NeurIPS 2016
- Marc G. Bellemare, Sriram Srinivasan, Georg Ostrovski, Tom Schaul, David Saxton, Remi Munos
- 关键词:内在动机、密度模型、伪计数
- 实验环境:Atari
通过自举DQN进行深度探索 NeurIPS 2016
- Ian Osband, Charles Blundell, Alexander Pritzel, Benjamin Van Roy
- 关键词:时序扩展(或深度)探索、随机化价值函数、自举DQN
- 实验环境:Atari
VIME:变分信息最大化探索 NeurIPS 2016
- Rein Houthooft, Xi Chen, Yan Duan, John Schulman, Filip De Turck, Pieter Abbeel
- 关键词:信息增益最大化、环境动态信念、贝叶斯神经网络中的变分推断
- 实验环境:rllab
#Exploration:深度强化学习中基于计数的探索研究 NeurIPS 2017
EX2:用于深度强化学习的示例模型探索 NeurIPS 2017
事后经验回放 NeurIPS 2017
- Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, Pieter Abbeel, Wojciech Zaremba
- 关键词:事后经验回放、隐式课程
- 实验环境:推、滑动、拾取放置等物理机器人任务
由自监督预测驱动的 curiosity 探索 ICML 2017
从示范中学习深度Q学习 AAAI 2018
- Todd Hester, Matej Vecerik, Olivier Pietquin, Marc Lanctot, Tom Schaul, Bilal Piot, Dan Horgan, John Quan, Andrew Sendonaris, Gabriel Dulac-Arnold, Ian Osband, John Agapiou, Joel Z. Leibo, Audrunas Gruslys
- 关键词:将时序差分更新与对示范者行为的监督分类相结合
- 实验环境:Atari
用于探索的噪声网络 ICLR 2018
- Meire Fortunato, Mohammad Gheshlaghi Azar, Bilal Piot, Jacob Menick, Matteo Hessel, Ian Osband, Alex Graves, Volodymyr Mnih, Remi Munos, Demis Hassabis, Olivier Pietquin, Charles Blundell, Shane Legg
- 关键词:学习到的参数化噪声
- 实验环境:Atari
通过随机网络蒸馏进行探索 ICLR 2018
- Yuri Burda, Harrison Edwards, Amos Storkey, Oleg Klimov
- 关键词:随机网络蒸馏
- 实验环境:Atari
软演员-评论家:带有随机演员的离策略最大熵深度强化学习 ICML 2018
- Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, Sergey Levine
- 关键词:软演员-评论家、最大熵、策略迭代
- 实验环境:MuJoCo
大规模好奇心驱动学习研究 ICLR 2019
多样性就是一切:无需奖励函数即可学习技能 ICLR 2019
- Benjamin Eysenbach、Abhishek Gupta、Julian Ibarz、Sergey Levine
- 关键词:最大化信息论目标、无监督地涌现多样化技能
- 实验环境:MuJoCo
通过可达性实现的情节式好奇心 ICLR 2019
通过分歧进行自监督探索 ICML 2019
EMI:基于互信息的探索 ICML 2019
高效利用示范解决困难探索问题 arXiv 2019
- Caglar Gulcehre、Tom Le Paine、Bobak Shahriari、Misha Denil、Matt Hoffman、Hubert Soyer、Richard Tanburn、Steven Kapturowski、Neil Rabinowitz、Duncan Williams、Gabriel Barth-Maron、Ziyu Wang、Nando de Freitas
- 关键词:R2D2、高效利用示范、困难探索问题
- 实验环境:Atari
即使在悲观初始化下也能进行乐观探索 ICLR 2020
- Tabish Rashid、Bei Peng、Wendelin Böhmer、Shimon Whiteson
- 关键点:悲观初始化的Q值、基于计数的奖励项、在动作选择和自举过程中保持乐观
- 实验环境:随机链、迷宫、蒙特祖玛的复仇
RIDE:针对程序化生成环境的奖励驱动型探索 ICLR 2020
- Roberta Raileanu、Tim Rocktäschel
- 关键点:引导学习到的状态表示发生显著变化
- 实验环境:MiniGrid
永不放弃:学习有方向性的探索策略 ICLR 2020
- Adrià Puigdomènech Badia、Pablo Sprechmann、Alex Vitvitskyi、Daniel Guo、Bilal Piot、Steven Kapturowski、Olivier Tieleman、Martín Arjovsky、Alexander Pritzel、Andew Bolt、Charles Blundell
- 关键点:ICM+RND,不同强度的探索与利用平衡
- 实验环境:Atari
Agent57:超越Atari人类基准 ICML 2020
- Adrià Puigdomènech Badia、Bilal Piot、Steven Kapturowski、Pablo Sprechmann、Alex Vitvitskyi、Daniel Guo、Charles Blundell
- 关键点:参数化一组策略、自适应机制、状态-动作价值函数的参数化表示
- 实验环境:Atari、roboschool
基于UCB的探索的神经上下文多臂老虎机 ICML 2020
- Dongruo Zhou、Lihong Li、Quanquan Gu
- 关键点:随机上下文多臂老虎机、基于神经网络的随机特征、近似最优的遗憾保证
- 实验环境:上下文多臂老虎机、UCI机器学习库、MNIST
对剧集进行排序:一种针对程序化生成环境的简单探索方法 ICLR 2021
先返回再探索 Nature 2021
- Adrien Ecoffet、Joost Huizinga、Joel Lehman、Kenneth O. Stanley、Jeff Clune
- 关键点:脱离与偏离、记忆状态、返回并在此基础上进行探索
- 实验环境:Atari、抓取放置机器人任务
贡献
我们的目标是为对强化学习中探索方法感兴趣的人提供一份入门级论文指南。 如果您有兴趣参与贡献,请参阅此处以获取贡献说明。
许可证
Awesome Exploration RL 采用 Apache 2.0 许可证发布。
(回到顶部)
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。