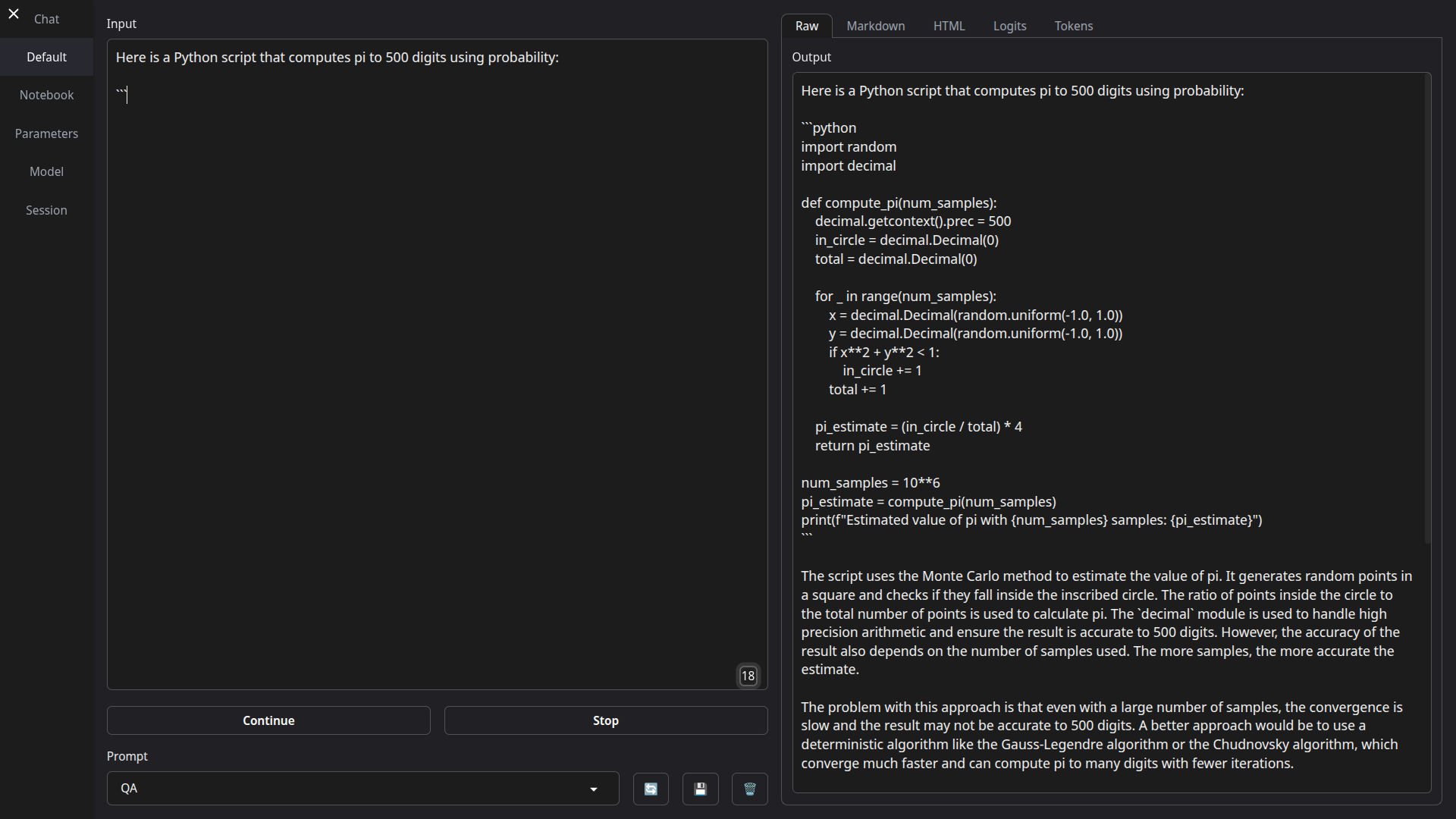
text-generation-webui
text-generation-webui 是一款功能强大的本地大语言模型(LLM)交互界面,旨在让用户在完全离线且隐私安全的环境下运行各类开源 AI 模型。它解决了用户依赖云端服务可能导致的数据泄露风险,以及高昂的 API 调用成本问题,让所有计算都在本地完成。
这款工具非常适合希望私有化部署 AI 的开发者、需要微调模型的研究人员,以及注重数据隐私的普通极客用户。其核心亮点在于极高的灵活性与兼容性:支持 llama.cpp、Transformers、ExLlamaV3 等多种后端,用户无需重启即可切换模型;提供与 OpenAI 和 Anthropic 兼容的本地 API,方便直接替换现有应用的后端。此外,它还具备多模态视觉理解、自定义工具调用(如联网搜索、数学计算)、文档内容问答以及本地 LoRA 微调等高级功能。界面基于 Gradio 构建,操作直观,既支持类似 ChatGPT 的对话模式,也提供自由创作的笔记本模式。无论是想要一键解压即用的新手,还是追求极致控制的专业用户,text-generation-webui 都能提供零遥测、纯本地的完美体验。
使用场景
某独立开发者需要在无网络环境的保密项目中,利用本地大模型辅助编写代码并分析内部技术文档。
没有 text-generation-webui 时
- 必须将敏感代码或文档上传至云端 API,存在严重的数据泄露风险,且无法在断网环境下工作。
- 切换不同量化版本或架构的模型(如从 GGUF 切换到 ExLlamaV3)需要重启服务甚至重新配置环境,效率极低。
- 无法让模型直接读取本地的 PDF 需求文档或调用自定义的 Python 脚本工具,只能手动复制粘贴内容,交互割裂。
- 缺乏对生成参数的精细控制,难以针对特定编程任务调整采样策略,导致代码生成质量不稳定。
使用 text-generation-webui 后
- 实现 100% 离线运行,所有代码推理与文档分析均在本地完成,彻底杜绝数据外传,完美适配保密开发场景。
- 支持多后端无缝切换,开发者可在不重启界面的情况下即时对比不同模型在代码补全任务上的表现。
- 直接上传内部技术 PDF 进行对话,并通过简单的
.py文件挂载自定义工具,让模型能自动执行项目特定的检查脚本。 - 提供丰富的采样参数调节面板和 Notebook 模式,可精准控制代码生成的逻辑性与创造性,显著提升产出可用性。
text-generation-webui 通过全本地化、多功能集成及高度可定制的特性,为隐私敏感型开发提供了安全且高效的私有智能助手方案。
运行环境要求
- Linux
- macOS
- Windows
- 非必需(支持 CPU 模式)
- 若使用 GPU 加速,支持 NVIDIA (CUDA 12.8), AMD (ROCm 7.2), Intel, 或 Apple Silicon (MPS)
- 具体显存需求取决于模型大小和后端(如 ExLlamaV3, Transformers),README 未指定统一最低显存要求
未说明(取决于模型大小,一键安装器需约 10GB 磁盘空间)
快速开始
文本生成Web界面
一个用于在本地运行大型语言模型的Gradio Web界面。100%私密且离线。支持文本生成、视觉理解、工具调用、训练、图像生成等功能。
 |
 |
|---|---|
 |
 |
功能特性
- 轻松部署:适用于Windows/Linux/macOS的GGUF模型的便携式版本(无需任何设置,解压即用),或一键安装完整功能集。
- 多后端支持:支持llama.cpp、Transformers、ExLlamaV3以及TensorRT-LLM。可在不同后端和模型之间无缝切换,无需重启。
- 兼容OpenAI/Anthropic API:提供聊天、补全和消息端点,并支持工具调用功能。可用作OpenAI/Anthropic API的本地替代方案(示例)。
- 工具调用:模型可以在对话过程中调用自定义函数——如网络搜索、网页抓取、数学计算等。每个工具只需一个
.py文件即可实现,易于创建和扩展(教程)。 - 视觉理解(多模态):可将图片附加到消息中,以实现视觉内容的理解(教程)。
- 文件附件:支持上传文本文件、PDF文档和.docx文档,以便围绕其内容进行对话。
- 模型训练:可在多轮对话或原始文本数据集上微调LoRA模型。支持中断后继续训练(教程)。
- 图像生成:专门设有针对
diffusers模型(如Z-Image-Turbo)的标签页。支持4位/8位量化,并配备带有元数据的持久化图库(教程)。 - 100%离线与私密,无任何遥测、外部资源或远程更新请求。
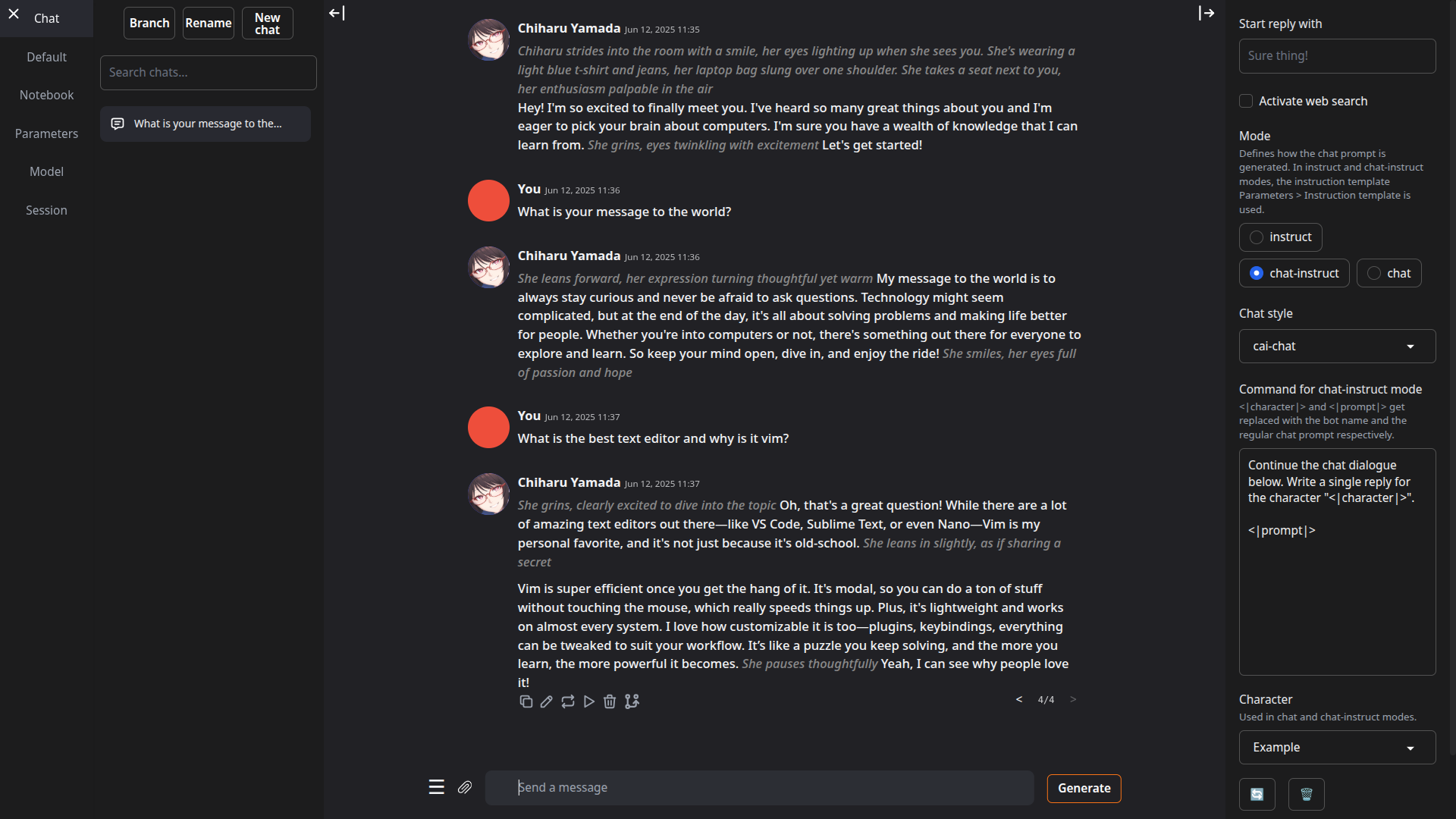
- 提供
instruct模式用于指令遵循任务(类似ChatGPT),以及chat-instruct和chat模式用于与自定义角色对话。提示会自动使用Jinja2模板格式化。 - 可编辑消息、在不同版本间切换,也可在任意时间点对对话进行分支。
- 在“Notebook”标签页中可自由进行文本生成,不受限于对话轮次。
- 多种采样参数和生成选项,便于精细控制文本生成过程。
- 支持深色/浅色主题、代码块语法高亮显示,以及数学表达式的LaTeX渲染。
- 扩展支持,内置及用户贡献的扩展众多。详情请参阅wiki和扩展目录。
安装方法
✅ 方法一:便携式版本(1分钟快速上手)
无需安装,直接下载、解压并运行即可。所有依赖项均已包含在内。
下载地址:https://github.com/oobabooga/text-generation-webui/releases
- 提供适用于Linux、Windows和macOS的版本,分别支持CUDA、Vulkan、ROCm及纯CPU运行。
- 兼容GGUF(llama.cpp)模型。
方法二:手动便携式安装(使用虚拟环境)
非常快速的安装方式,适用于任何Python 3.9及以上版本:
# 克隆仓库
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
# 创建虚拟环境
python -m venv venv
# 激活虚拟环境
# Windows:
venv\Scripts\activate
# macOS/Linux:
source venv/bin/activate
# 安装依赖(根据硬件选择合适的requirements/portable文件)
pip install -r requirements/portable/requirements.txt --upgrade
# 启动服务器(基本命令)
python server.py --portable --api --auto-launch
# 工作结束后,退出虚拟环境
deactivate
方法三:一键安装程序
适用于需要额外后端(ExLlamaV3、Transformers)、训练、图像生成或扩展功能(TTS、语音输入、翻译等)的用户。需约10GB磁盘空间,并会下载PyTorch。
- 克隆仓库,或下载源代码并解压。
- 根据操作系统运行相应的启动脚本:
start_windows.bat、start_linux.sh或start_macos.sh。 - 按照提示选择您的GPU供应商。
- 安装完成后,在浏览器中打开
http://127.0.0.1:7860。
后续若需重启Web界面,再次运行相同的start_脚本即可。
您也可以直接通过命令行传递参数(如./start_linux.sh --help),或将参数添加到user_data/CMD_FLAGS.txt文件中(如--api以启用API)。
要更新软件,请运行对应操作系统的更新脚本:update_wizard_windows.bat、update_wizard_linux.sh或update_wizard_macos.sh。
若需重新安装并创建全新的Python环境,删除installer_files文件夹后,再次运行start_脚本即可。
一键安装程序详细说明
一键安装程序
该脚本使用 Miniforge 在 installer_files 文件夹中设置 Conda 环境。
如果您需要在 installer_files 环境中手动安装某些内容,可以使用命令行脚本启动交互式 shell:cmd_linux.sh、cmd_windows.bat 或 cmd_macos.sh。
- 无需以管理员或 root 权限运行这些脚本(
start_、update_wizard_或cmd_)。 - 要安装扩展的依赖项,建议使用更新向导脚本中的“安装/更新扩展依赖项”选项。该脚本最后会安装项目的主要依赖项,以确保在版本冲突时优先使用这些依赖项。
- 对于自动化安装,可以使用
GPU_CHOICE、LAUNCH_AFTER_INSTALL和INSTALL_EXTENSIONS环境变量。例如:GPU_CHOICE=A LAUNCH_AFTER_INSTALL=FALSE INSTALL_EXTENSIONS=TRUE ./start_linux.sh。
使用 Conda 或 Docker 的手动完整安装
使用 Conda 的完整安装
0. 安装 Conda
https://github.com/conda-forge/miniforge
在 Linux 或 WSL 上,可以通过以下两条命令自动安装 Miniforge:
curl -sL "https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-Linux-x86_64.sh" > "Miniforge3.sh"
bash Miniforge3.sh
对于其他平台,请从以下链接下载:https://github.com/conda-forge/miniforge/releases/latest
1. 创建一个新的 Conda 环境
conda create -n textgen python=3.13
conda activate textgen
2. 安装 PyTorch
| 系统 | GPU | 命令 |
|---|---|---|
| Linux/WSL | NVIDIA | pip3 install torch==2.9.1 --index-url https://download.pytorch.org/whl/cu128 |
| Linux/WSL | 仅 CPU | pip3 install torch==2.9.1 --index-url https://download.pytorch.org/whl/cpu |
| Linux | AMD | pip3 install https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.9.1%2Brocm7.2.0.lw.git7e1940d4-cp313-cp313-linux_x86_64.whl |
| MacOS + MPS | 任何 | pip3 install torch==2.9.1 |
| Windows | NVIDIA | pip3 install torch==2.9.1 --index-url https://download.pytorch.org/whl/cu128 |
| Windows | 仅 CPU | pip3 install torch==2.9.1 |
最新命令可在以下页面找到:https://pytorch.org/get-started/locally/。
如果您需要 nvcc 手动编译某些库,则还需额外安装:
conda install -y -c "nvidia/label/cuda-12.8.1" cuda
3. 安装 Web UI
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
pip install -r requirements/full/<根据下表选择的依赖文件>
应使用的依赖文件:
| GPU | 应使用的依赖文件 |
|---|---|
| NVIDIA | requirements.txt |
| AMD | requirements_amd.txt |
| 仅 CPU | requirements_cpu_only.txt |
| Apple Intel | requirements_apple_intel.txt |
| Apple Silicon | requirements_apple_silicon.txt |
启动 Web UI
conda activate textgen
cd text-generation-webui
python server.py
然后访问:
http://127.0.0.1:7860
手动安装
上述 requirements*.txt 文件包含通过 GitHub Actions 预编译的各种轮子包。如果您希望手动编译某些内容,或者因为您的硬件没有合适的轮子包而必须手动编译,可以使用 requirements_nowheels.txt,然后手动安装您所需的加载器。
替代方案:Docker
对于 NVIDIA GPU:
ln -s docker/{nvidia/Dockerfile,nvidia/docker-compose.yml,.dockerignore} .
对于 AMD GPU:
ln -s docker/{amd/Dockerfile,amd/docker-compose.yml,.dockerignore} .
对于 Intel GPU:
ln -s docker/{intel/Dockerfile,intel/docker-compose.yml,.dockerignore} .
对于仅 CPU:
ln -s docker/{cpu/Dockerfile,cpu/docker-compose.yml,.dockerignore} .
cp docker/.env.example .env
# 创建日志/缓存目录:
mkdir -p user_data/logs user_data/cache
# 编辑 .env 并设置:
# TORCH_CUDA_ARCH_LIST 根据您的 GPU 型号
# APP_RUNTIME_GID 您主机用户的组 ID(在终端中运行 `id -g`)
# BUILD_EXTENIONS 可选地添加要构建的扩展列表,用逗号分隔
# 编辑 user_data/CMD_FLAGS.txt,并添加您想要执行的选项(如 --listen --cpu)
#
docker compose up --build
更新依赖项
requirements*.txt 文件会不时更新。要更新,请使用以下命令:
conda activate textgen
cd text-generation-webui
pip install -r <您之前使用的依赖文件> --upgrade
命令行标志列表
用法:server.py [-h] [--user-data-dir USER_DATA_DIR] [--multi-user] [--model MODEL] [--lora LORA [LORA ...]] [--model-dir MODEL_DIR] [--lora-dir LORA_DIR] [--model-menu] [--settings SETTINGS]
[--extensions EXTENSIONS [EXTENSIONS ...]] [--verbose] [--idle-timeout IDLE_TIMEOUT] [--image-model IMAGE_MODEL] [--image-model-dir IMAGE_MODEL_DIR] [--image-dtype {bfloat16,float16}]
[--image-attn-backend {flash_attention_2,sdpa}] [--image-cpu-offload] [--image-compile] [--image-quant {none,bnb-8bit,bnb-4bit,torchao-int8wo,torchao-fp4,torchao-float8wo}]
[--loader LOADER] [--ctx-size N] [--cache-type N] [--model-draft MODEL_DRAFT] [--draft-max DRAFT_MAX] [--gpu-layers-draft GPU_LAYERS_DRAFT] [--device-draft DEVICE_DRAFT]
[--ctx-size-draft CTX_SIZE_DRAFT] [--spec-type {none,ngram-mod,ngram-simple,ngram-map-k,ngram-map-k4v,ngram-cache}] [--spec-ngram-size-n SPEC_NGRAM_SIZE_N]
[--spec-ngram-size-m SPEC_NGRAM_SIZE_M] [--spec-ngram-min-hits SPEC_NGRAM_MIN_HITS] [--gpu-layers N] [--cpu-moe] [--mmproj MMPROJ] [--streaming-llm] [--tensor-split TENSOR_SPLIT]
[--row-split] [--no-mmap] [--mlock] [--no-kv-offload] [--batch-size BATCH_SIZE] [--ubatch-size UBATCH_SIZE] [--threads THREADS] [--threads-batch THREADS_BATCH] [--numa]
[--parallel PARALLEL] [--fit-target FIT_TARGET] [--extra-flags EXTRA_FLAGS] [--cpu] [--cpu-memory CPU_MEMORY] [--disk] [--disk-cache-dir DISK_CACHE_DIR] [--load-in-8bit] [--bf16]
[--no-cache] [--trust-remote-code] [--force-safetensors] [--no_use_fast] [--attn-implementation IMPLEMENTATION] [--load-in-4bit] [--use_double_quant] [--compute_dtype COMPUTE_DTYPE]
[--quant_type QUANT_TYPE] [--gpu-split GPU_SPLIT] [--enable-tp] [--tp-backend TP_BACKEND] [--cfg-cache] [--listen] [--listen-port LISTEN_PORT] [--listen-host LISTEN_HOST] [--share]
[--auto-launch] [--gradio-auth GRADIO_AUTH] [--gradio-auth-path GRADIO_AUTH_PATH] [--ssl-keyfile SSL_KEYFILE] [--ssl-certfile SSL_CERTFILE] [--subpath SUBPATH] [--old-colors]
[--portable] [--api] [--public-api] [--public-api-id PUBLIC_API_ID] [--api-port API_PORT] [--api-key API_KEY] [--admin-key ADMIN_KEY] [--api-enable-ipv6] [--api-disable-ipv4]
[--nowebui] [--temperature N] [--dynatemp-low N] [--dynatemp-high N] [--dynatemp-exponent N] [--smoothing-factor N] [--smoothing-curve N] [--min-p N] [--top-p N] [--top-k N]
[--typical-p N] [--xtc-threshold N] [--xtc-probability N] [--epsilon-cutoff N] [--eta-cutoff N] [--tfs N] [--top-a N] [--top-n-sigma N] [--adaptive-target N] [--adaptive-decay N]
[--dry-multiplier N] [--dry-allowed-length N] [--dry-base N] [--repetition-penalty N] [--frequency-penalty N] [--presence-penalty N] [--encoder-repetition-penalty N]
[--no-repeat-ngram-size N] [--repetition-penalty-range N] [--penalty-alpha N] [--guidance-scale N] [--mirostat-mode N] [--mirostat-tau N] [--mirostat-eta N]
[--do-sample | --no-do-sample] [--dynamic-temperature | --no-dynamic-temperature] [--temperature-last | --no-temperature-last] [--sampler-priority N] [--dry-sequence-breakers N]
[--enable-thinking | --no-enable-thinking] [--reasoning-effort N] [--chat-template-file CHAT_TEMPLATE_FILE]
文本生成 Web UI
选项:
-h, --help 显示此帮助信息并退出
基本设置:
--user-data-dir USER_DATA_DIR 用户数据目录路径。默认:自动检测。
--multi-user 多用户模式。聊天记录不会保存或自动加载。最适合小型可信团队使用。
--model MODEL 默认加载的模型名称。
--lora LORA [LORA ...] 要加载的 LoRA 列表。如果要加载多个 LoRA,请用空格分隔名称。
--model-dir MODEL_DIR 包含所有模型的目录路径。
--lora-dir LORA_DIR 包含所有 LoRA 的目录路径。
--model-menu 在首次启动 Web UI 时,在终端中显示模型菜单。
--settings SETTINGS 从该 YAML 文件加载默认界面设置。示例请参见 user_data/settings-template.yaml。如果您创建名为
user_data/settings.yaml 的文件,系统将默认加载该文件,无需使用 --settings 标志。
--extensions EXTENSIONS [EXTENSIONS ...] 要加载的扩展列表。如果要加载多个扩展,请用空格分隔名称。
--verbose 将提示信息打印到终端。
--idle-timeout IDLE_TIMEOUT 在不活动达到此时间(分钟)后卸载模型。再次尝试使用时会自动重新加载。
图像模型:
--image-model IMAGE_MODEL 启动时选择的图像模型名称(覆盖已保存的设置)。
--image-model-dir IMAGE_MODEL_DIR 包含所有图像模型的目录路径。
--image-dtype {bfloat16,float16} 图像模型的数据类型。
--image-attn-backend {flash_attention_2,sdpa} 图像模型的注意力机制后端。
--image-cpu-offload 启用图像模型的 CPU 卸载。
--image-compile 编译图像模型以加快推理速度。
--image-quant {none,bnb-8bit,bnb-4bit,torchao-int8wo,torchao-fp4,torchao-float8wo}
图像模型的量化方法。
模型加载器:
--loader LOADER 手动选择模型加载器,否则将自动检测。有效选项:Transformers、llama.cpp、ExLlamav3_HF、ExLlamav3、TensorRT-
LLM。
上下文与缓存:
--ctx-size, --n_ctx, --max_seq_len N 上下文大小(以 token 为单位)。0 表示 llama.cpp 自动调整(需要 gpu-layers=-1),其他加载器则为 8192。
--cache-type, --cache_type N KV 缓存类型;有效选项:llama.cpp - fp16、q8_0、q4_0;ExLlamaV3 - fp16、q2 至 q8(可分别指定 k_bits 和 v_bits,例如 q4_q8)。
推测解码:
--model-draft MODEL_DRAFT 推测解码用草稿模型的路径。
--draft-max DRAFT_MAX 推测解码时要草拟的标记数。
--gpu-layers-draft GPU_LAYERS_DRAFT 草稿模型中卸载到GPU的层数。
--device-draft DEVICE_DRAFT 用于卸载草稿模型的设备列表,以逗号分隔。例如:CUDA0,CUDA1
--ctx-size-draft CTX_SIZE_DRAFT 草稿模型的提示上下文大小。若为0,则与主模型相同。
--spec-type {none,ngram-mod,ngram-simple,ngram-map-k,ngram-map-k4v,ngram-cache}
无草稿推测解码类型。推荐:ngram-mod。
--spec-ngram-size-n SPEC_NGRAM_SIZE_N ngram推测解码的n-gram查找大小。
--spec-ngram-size-m SPEC_NGRAM_SIZE_M ngram推测解码的草稿n-gram大小。
--spec-ngram-min-hits SPEC_NGRAM_MIN_HITS ngram-map推测解码所需的最小n-gram命中次数。
llama.cpp:
--gpu-layers, --n-gpu-layers N 卸载到GPU的层数。-1 = 自动。
--cpu-moe 将专家层移动到CPU(适用于MoE模型)。
--mmproj MMPROJ 视觉模型mmproj文件的路径。
--streaming-llm 启用StreamingLLM,以避免在移除旧消息时重新评估整个提示。
--tensor-split TENSOR_SPLIT 将模型拆分到多个GPU上。以逗号分隔的比例列表。例如:60,40。
--row-split 按行将模型拆分到不同GPU上。这可能会提升多GPU性能。
--no-mmap 禁止使用mmap。
--mlock 强制系统将模型保留在RAM中。
--no-kv-offload 不将K、Q、V卸载到GPU。这可以节省显存,但会降低性能。
--batch-size BATCH_SIZE 调用llama-server时,最多可将多少个提示标记合并为一批。这是应用层的批处理大小。
--ubatch-size UBATCH_SIZE 调用llama-server时,最多可将多少个提示标记合并为一批。这是计算的最大物理批处理大小(设备级)。
--threads THREADS 使用的线程数。
--threads-batch THREADS_BATCH 用于批处理/提示处理的线程数。
--numa 为llama.cpp启用NUMA任务分配。
--parallel PARALLEL 并发请求槽位的数量。上下文大小会平均分配到各个槽位。例如,若要设置4个槽位,每个槽位8192个上下文,则将ctx_size设为32768。
--fit-target FIT_TARGET 自动GPU层分配时,每个设备的目标显存余量,以MiB为单位的逗号分隔列表。单个值会广播到所有设备。
默认:1024。
--extra-flags EXTRA_FLAGS 传递给llama-server的额外参数。格式:“flag1=value1,flag2,flag3=value3”。例如:“override-tensor=exps=CPU”。
Transformers/Accelerate:
--cpu 使用CPU生成文本。警告:在CPU上训练极其缓慢。
--cpu-memory CPU_MEMORY 最大CPU内存,单位为GiB。用于CPU卸载。
--disk 如果模型体积过大,超出GPU和CPU的总容量,则将剩余层发送到磁盘。
--disk-cache-dir DISK_CACHE_DIR 保存磁盘缓存的目录。
--load-in-8bit 使用8位精度加载模型(使用bitsandbytes)。
--bf16 使用bfloat16精度加载模型。需要NVIDIA Ampere GPU。
--no-cache 在生成文本时将use_cache设为False。这会略微减少显存占用,但会牺牲性能。
--trust-remote-code 加载模型时将trust_remote_code设为True。对某些模型是必要的。
--force-safetensors 加载模型时将use_safetensors设为True。这可以防止任意代码执行。
--no_use_fast 加载分词器时将use_fast设为False(默认为True)。如果遇到与use_fast相关的问题,请使用此选项。
--attn-implementation IMPLEMENTATION 注意力实现方式。有效选项:sdpa、eager、flash_attention_2。
bitsandbytes 4位:
--load-in-4bit 使用4位精度加载模型(使用bitsandbytes)。
--use_double_quant 对4位使用双量化。
--compute_dtype COMPUTE_DTYPE 4位计算的数据类型。有效选项:bfloat16、float16、float32。
--quant_type QUANT_TYPE 4位量化类型。有效选项:nf4、fp4。
ExLlamaV3:
--gpu-split GPU_SPLIT 每个GPU设备用于模型层的显存(单位:GB),以逗号分隔。例如:20,7,7。
--enable-tp, --enable_tp 启用张量并行(TP)以将模型拆分到多个GPU上。
--tp-backend TP_BACKEND 张量并行的后端。有效选项:native、nccl。默认:native。
--cfg-cache 为CFG负向提示创建额外缓存。使用该加载器时必须启用CFG。
Gradio:
--listen 使 Web UI 可通过本地网络访问。
--listen-port LISTEN_PORT 服务器将使用的监听端口。
--listen-host LISTEN_HOST 服务器将使用的主机名。
--share 创建一个公共 URL。这在 Google Colab 或类似平台上运行 Web UI 时非常有用。
--auto-launch 启动时在默认浏览器中打开 Web UI。
--gradio-auth GRADIO_AUTH 设置 Gradio 身份验证密码,格式为“用户名:密码”。也可以使用“u1:p1,u2:p2,u3:p3”格式提供多个凭据。
--gradio-auth-path GRADIO_AUTH_PATH 设置 Gradio 身份验证文件路径。该文件应包含一个或多个用户:密码对,格式与上述相同。
--ssl-keyfile SSL_KEYFILE SSL 证书密钥文件的路径。
--ssl-certfile SSL_CERTFILE SSL 证书证书文件的路径。
--subpath SUBPATH 自定义 Gradio 的子路径,用于反向代理。
--old-colors 使用 2024 年 12 月更新之前的旧版 Gradio 颜色。
--portable 隐藏便携模式下不可用的功能,例如训练。
API:
--api 启用 API 扩展。
--public-api 使用 Cloudflare 为 API 创建公共 URL。
--public-api-id PUBLIC_API_ID 命名式 Cloudflare 隧道的隧道 ID。需与 public-api 选项一起使用。
--api-port API_PORT API 的监听端口。
--api-key API_KEY API 身份验证密钥。
--admin-key ADMIN_KEY 用于加载和卸载模型等管理任务的 API 身份验证密钥。若未设置,则与 --api-key 相同。
--api-enable-ipv6 为 API 启用 IPv6。
--api-disable-ipv4 禁用 API 的 IPv4。
--nowebui 不启动 Gradio UI。适用于以独立模式启动 API。
API 生成默认参数:
--temperature N 温度
--dynatemp-low N 动态温度下限
--dynatemp-high N 动态温度上限
--dynatemp-exponent N 动态温度指数
--smoothing-factor N 平滑因子
--smoothing-curve N 平滑曲线
--min-p N Min P
--top-p N Top P
--top-k N Top K
--typical-p N Typical P
--xtc-threshold N XTC 阈值
--xtc-probability N XTC 概率
--epsilon-cutoff N Epsilon 截断
--eta-cutoff N Eta 截断
--tfs N TFS
--top-a N Top A
--top-n-sigma N Top N Sigma
--adaptive-target N 自适应目标
--adaptive-decay N 自适应衰减
--dry-multiplier N DRY 乘数
--dry-allowed-length N DRY 允许长度
--dry-base N DRY 基础
--repetition-penalty N 重复惩罚
--frequency-penalty N 频率惩罚
--presence-penalty N 存在惩罚
--encoder-repetition-penalty N 编码器重复惩罚
--no-repeat-ngram-size N 不重复 n-gram 大小
--repetition-penalty-range N 重复惩罚范围
--penalty-alpha N 惩罚 alpha
--guidance-scale N 引导尺度
--mirostat-mode N 米罗斯特模式
--mirostat-tau N 米罗斯特 tau
--mirostat-eta N 米罗斯特 eta
--do-sample, --no-do-sample 是否采样
--dynamic-temperature, --no-dynamic-temperature 是否启用动态温度
--temperature-last, --no-temperature-last 是否使用最后的温度
--sampler-priority N 采样器优先级
--dry-sequence-breakers N DRY 序列中断符
--enable-thinking, --no-enable-thinking 是否启用思考
--reasoning-effort N 思考力度
--chat-template-file CHAT_TEMPLATE_FILE 用于作为 API 请求默认指令模板的聊天模板文件路径(.jinja、.jinja2 或 .yaml)。会覆盖模型自带的模板。
下载模型
- 从 Hugging Face 下载 GGUF 格式的模型文件。
- 将其放入
user_data/models文件夹中。
这样就完成了。UI 会自动检测到该模型。
要估算模型将占用多少内存,可以使用 GGUF 内存计算器。
其他模型类型(Transformers、EXL3)
由多个文件组成的模型(如 16 位 Transformers 模型和 EXL3 模型)应放置在 user_data/models 文件夹内的子文件夹中:
text-generation-webui
└── user_data
└── models
└── Qwen_Qwen3-8B
├── config.json
├── generation_config.json
├── model-00001-of-00004.safetensors
├── ...
├── tokenizer_config.json
└── tokenizer.json
这些格式需要使用一键安装程序(而非便携版)。
文档
https://github.com/oobabooga/text-generation-webui/wiki
社区
https://www.reddit.com/r/Oobabooga/
致谢
- 2023年8月,Andreessen Horowitz(a16z)慷慨地提供了资助,以鼓励和支持我在该项目上的独立工作。我对其信任与认可深表感激。
- 本项目受到AUTOMATIC1111/stable-diffusion-webui的启发,若没有它,本项目将无从谈起。
版本历史
v4.3.12026/04/03v4.32026/04/03v4.22026/03/24v4.1.12026/03/18v4.12026/03/16v4.02026/03/07v3.232026/01/08v3.222025/12/20v3.212025/12/15v3.202025/12/07v3.192025/11/29v3.182025/11/19v3.172025/11/06v3.162025/10/23v3.152025/10/15v3.142025/10/10v3.132025/09/21v3.122025/09/02v3.112025/08/19v3.102025/08/12常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。