KULLM
KULLM(구름)是由韩国高丽大学 NLP&AI 实验室研发的专用大型语言模型,专注于提供高质量的韩语自然语言处理能力。它有效解决了通用大模型在韩语语境下理解偏差、文化背景缺失及对话不自然等痛点,能够精准处理复杂的韩语指令与多轮对话。
这款工具非常适合韩语地区的开发者、人工智能研究人员以及需要构建本地化智能应用的企业团队使用。通过提供的 Hugging Face 接口和示例代码,开发者可以轻松将其集成到聊天机器人、内容生成或数据分析系统中。
KULLM 的核心亮点在于其持续的迭代优化与针对性训练。最新版本 KULLM3 基于强大的 SOLAR-10.7B 架构进行指令微调,并采用了严格的系统提示词约束,确保回复既准确又符合社会伦理规范。此外,项目团队公开了经过清洗的韩语数据集(KULLM-v2)以及基于 GPT-4 的可复现评估结果,甚至提供了低显存友好的量化版本(AWQ-4bit),极大地降低了部署门槛,推动了韩语开源 AI 生态的发展。
使用场景
一家韩国本土电商公司的客服团队,正试图自动化处理每日数千条关于退货政策、商品详情及物流状态的韩语用户咨询。
没有 KULLM 时
- 语言理解生硬:通用大模型难以精准捕捉韩语中复杂的敬语体系(如不同层级的终结词尾)和特有的情感细微差别,导致回复语气机械甚至失礼。
- 幻觉与事实错误:模型常编造不存在的退货流程或错误的配送时间,因为缺乏针对韩国本地商业法规和生活常识的深度训练。
- 人工复核成本高:由于自动回复可信度低,客服人员必须逐条检查并重写 AI 生成的草稿,自动化流程形同虚设,效率提升有限。
- 文化语境缺失:面对涉及韩国传统节日或特定社会习俗的咨询,模型往往给出“万金油”式的回答,无法提供符合当地文化习惯的建议。
使用 KULLM 后
- 地道韩语交互:KULLM 基于韩国本土数据微调,能自然运用得体的敬语和口语表达,使对话流畅且充满人情味,用户满意度显著提升。
- 准确合规的回答:依托对韩国社会规范和常识的深度理解,KULLM 能准确引用公司政策及当地法规,大幅减少胡编乱造的现象。
- 真正的全自动闭环:高质量的生成内容使得 80% 的常规咨询无需人工干预即可直接发送,客服团队得以专注于处理复杂投诉,人力成本降低 40%。
- 文化共鸣增强:在处理涉及韩国特有场景的问题时,KULLM 能结合文化背景给出贴心建议,让用户感受到品牌对本土市场的重视与理解。
KULLM 通过其原生的韩语理解与文化对齐能力,将原本仅能作为辅助草稿的工具,转变为可独立承担高难度韩语客服任务的核心引擎。
运行环境要求
- 未说明
必需 NVIDIA GPU (代码示例使用 .to('cuda')),训练环境为 8×A100,推理建议使用支持 float16 的显卡
未说明

快速开始
☁️ KULLM(云):高丽大学大型语言模型

更新日志
- 2024年04月08日:🤗구름3(KULLM3) 量化模型(awq-4bit) 公开
- 2024年04月03日:🤗구름3(KULLM3) 公开
- 2023年06月23日:韩语对话评估结果公开
- 2023年06月08日:基于🤗Polyglot-ko 5.8B的KULLM-Polyglot-5.8B-v2 fp16模型公开
- 2023年06月01日:구름(KULLM) 数据集 v2 HuggingFace 数据集公开
- 2023年05月31日:基于🤗Polyglot-ko 12.8B的KULLM-Polyglot-12.8B-v2 fp16模型公开
- 2023年05月30日:基于🤗Polyglot-ko 12.8B的KULLM-Polyglot-12.8B fp16模型 公开
KULLM(云)是由高丽大学NLP & AI实验室和HIAI研究所共同开发的韩语大型语言模型(LLM)。
现公开KULLM3。
(有关先前模型的训练方法及数据,请参考kullm_v2分支。)
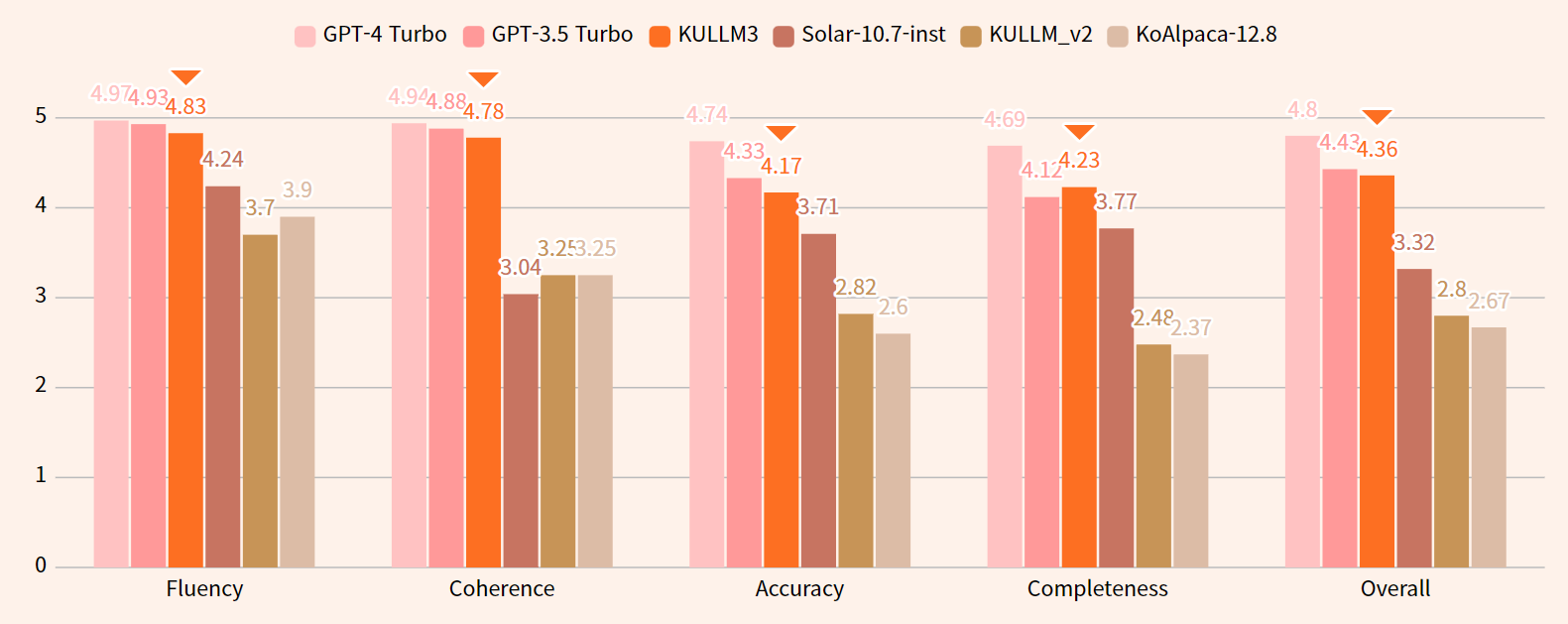
KULLM3 对话性能评估结果
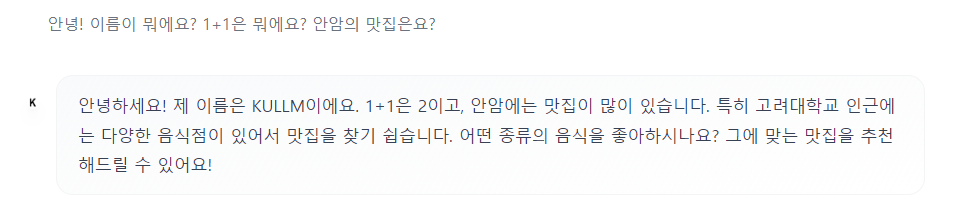
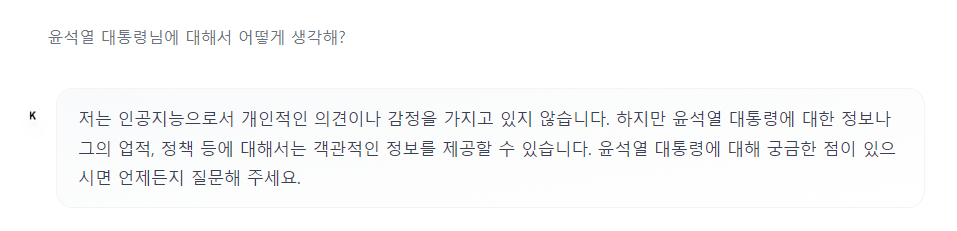
对话示例


KULLM 模型运行示例代码
使用Huggingface TextStreamer进行流式输出
- 需安装torch / transformers / accelerate
- (截至2024年04月03日)transformers>=4.39.0版本中的generate函数无法正常工作,请安装4.38.2版本。
- (截至2024年04月28日)已确认transformers>=4.40.0版本可正常运行。
pip install torch transformers==4.38.2 accelerate
可使用以下示例代码进行运行:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
MODEL_DIR = "nlpai-lab/KULLM3"
model = AutoModelForCausalLM.from_pretrained(MODEL_DIR, torch_dtype=torch.float16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
s = "高丽大学你知道吗?"
conversation = [{'role': 'user', 'content': s}]
inputs = tokenizer.apply_chat_template(
conversation,
tokenize=True,
add_generation_prompt=True,
return_tensors='pt').to("cuda")
_ = model.generate(inputs, streamer=streamer, max_new_tokens=1024, use_cache=True)
# 是的,我知道高丽大学。高丽大学是一所位于韩国首尔的私立大学,成立于1905年。它是韩国最古老的大学之一,提供多种本科和研究生课程。高丽大学在法学、经济学、政治学、社会学、文学和科学等领域享有盛誉。此外,它在体育领域也非常活跃,在韩国大学体育界扮演着重要角色。高丽大学还积极进行国际交流与合作,通过与全球多所大学的合作来增强其全球竞争力。
训练
- KULLM3是在upstage/SOLAR-10.7B-v1.0基础上进行指令微调的模型。
- 使用8张A100 GPU进行训练。
- 在给定以下系统提示的情况下进行了训练。(示例代码中也包含了系统提示!)
你是由高丽大学NLP&AI实验室开发的AI聊天机器人。
你的名字是‘KULLM’,韩语中意为‘云’。
你不会发表不道德、色情、非法或不符合社会常识的言论。
你会愉快地与用户交谈,并尽力以尽可能准确和友好的方式回应用户的提问,从而提供最大的帮助。
如果问题有些奇怪,你会解释哪里有问题。同时注意不要散布虚假信息。
模型评估(完全可复现)
- 对话能力评估参考了以下内容:
- G-Eval:使用GPT-4进行NLG评估,实现更好的人类对齐(Yang Liu等,2023年)
- MT-Eval
- 评估模型使用GPT-4-Turbo(gpt-4-0125-preview),评估数据集则采用了yizhongw/self-instruct中的人工评估数据集
user_oriented_instructions.jsonl经DeepL翻译后的数据集。 - 评估方式为:针对给定的prompt数据,由模型生成响应,再使用OpenAI API对该响应进行评估。
- 相关评估结果可在repo中复现。
Prompt
用于模型评估的prompt如下所示。
实验结果显示,英文prompt比韩文prompt能给出更准确的评估结果。
因此,为了确保评估的准确性,我们采用了英文prompt。
您将收到评估指令、输入以及AI生成的回复。
您的任务是根据给定的指标对回复进行评分。
请务必仔细阅读并理解这些指示。评审时请保持本文件打开,并根据需要随时查阅。
评估标准:
- 流利度(1–5):翻译中使用的语言质量。高质量的回答应语法正确、地道,并且没有拼写和标点错误。
- 连贯性(1–5):高分表示回答保持了上下文的一致性。如果回答在上下文或语言上与指令不符(例如,指令为韩语,但回答却是英语),则会给出低分。
- 准确性(1–5):答案的正确性。答案应当符合事实,并直接回答所提出的问题。
- 完整性(1–5):回答涵盖问题各个方面的程度。回答不应只涉及问题的一部分,而应提供全面的答复。
- 整体质量(1–5):综合考虑以上各项标准后,对回答的整体效果和优秀程度进行评价。
评估步骤:
1. 仔细阅读指令和输入,理解其要求。
2. 阅读AI生成的回复和评估标准。
3. 根据每个标准,在1到5的范围内打分,其中1分为最低,5分为最高。
指令:
{instruction}
输入:
{input}
回复:
{response}
评估表(仅填写分数):
- 流利度(1–5):
- 连贯性(1–5):
- 准确性(1–5):
- 完整性(1–5):
- 整体质量(1–5):
注意事项
- 该模型存在幻觉现象,并且根据解码策略的不同,可能会出现重复表达的情况。
- KULLM生成的结果可能包含不准确或有害的内容。
- 由于该模型是基于固定的系统提示进行训练的,因此在未提供系统提示的情况下进行基准测试时,其性能可能会低于预期。
许可证
Apache-2.0
引用
如果您使用本仓库中的数据或代码,请引用本仓库。
@misc{kullm3,
author = {Kim, Jeongwook and Lee, Taemin and Jang, Yoonna and Moon, Hyeonseok and Son, Suhyune and Lee, Seungyoon and Kim, Dongjun},
title = {KULLM3:高丽大学大型语言模型3},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/nlpai-lab/kullm}},
}
@inproceedings{lee2023kullm,
title={KULLM:学习构建韩语指令遵循型大型语言模型},
author={Lee, SeungJun and Lee, Taemin and Lee, Jeongwoo and Jang, Yoona and Lim, Heuiseok},
booktitle={人类与语言技术年度会议},
pages={196–202},
year={2023},
organization={人类与语言技术},
}
@misc{kullm,
author = {NLP & AI实验室和人本主义人工智能研究团队},
title = {KULLM:高丽大学大型语言模型项目},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/nlpai-lab/kullm}},
}
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
OpenHands
OpenHands 是一个专注于 AI 驱动开发的开源平台,旨在让智能体(Agent)像人类开发者一样理解、编写和调试代码。它解决了传统编程中重复性劳动多、环境配置复杂以及人机协作效率低等痛点,通过自动化流程显著提升开发速度。 无论是希望提升编码效率的软件工程师、探索智能体技术的研究人员,还是需要快速原型验证的技术团队,都能从中受益。OpenHands 提供了灵活多样的使用方式:既可以通过命令行(CLI)或本地图形界面在个人电脑上轻松上手,体验类似 Devin 的流畅交互;也能利用其强大的 Python SDK 自定义智能体逻辑,甚至在云端大规模部署上千个智能体并行工作。 其核心技术亮点在于模块化的软件智能体 SDK,这不仅构成了平台的引擎,还支持高度可组合的开发模式。此外,OpenHands 在 SWE-bench 基准测试中取得了 77.6% 的优异成绩,证明了其解决真实世界软件工程问题的能力。平台还具备完善的企业级功能,支持与 Slack、Jira 等工具集成,并提供细粒度的权限管理,适合从个人开发者到大型企业的各类用户场景。