chatgpt-telegram-bot
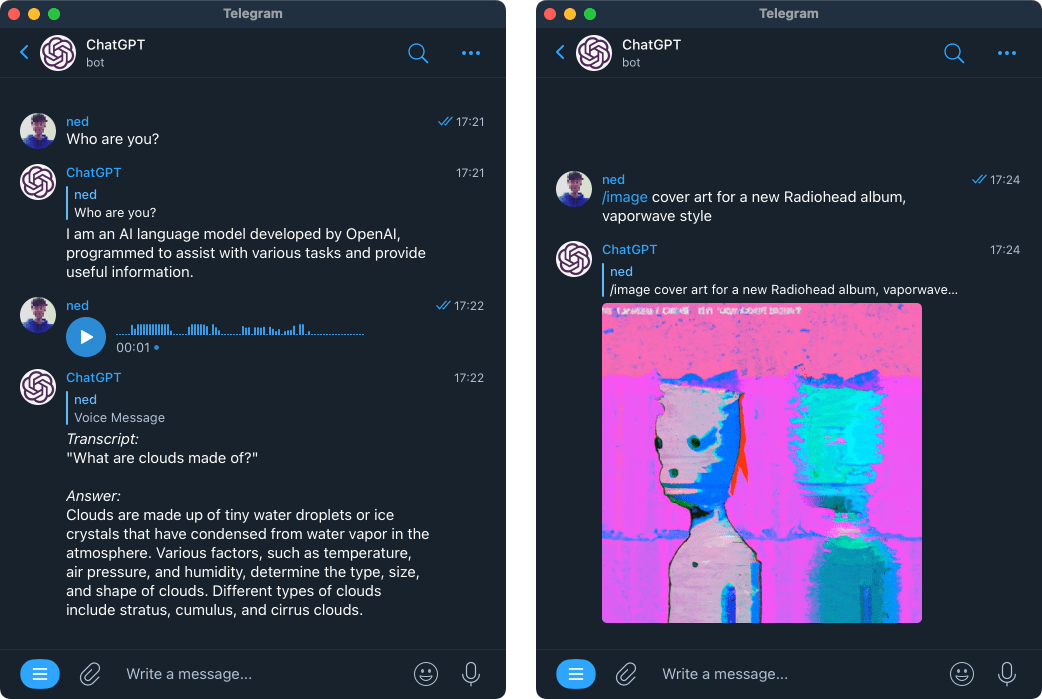
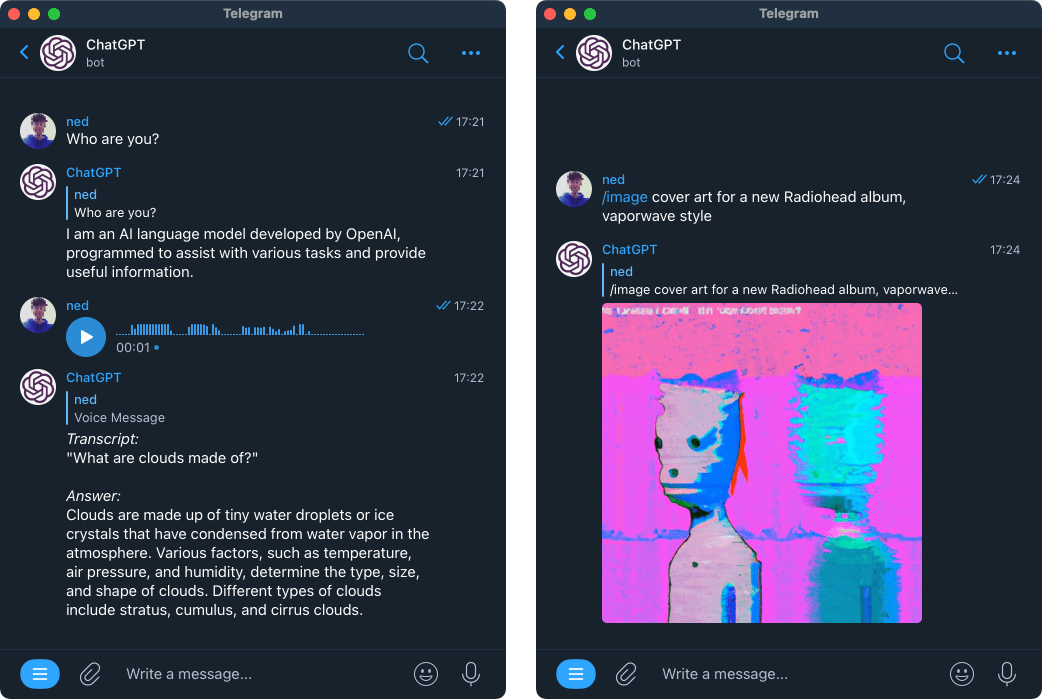
chatgpt-telegram-bot 是一款基于 Python 开发的开源机器人,旨在将 OpenAI 的强大能力无缝集成到 Telegram 聊天界面中。它不仅支持 ChatGPT 进行智能对话,还融合了 DALL·E 3 的图像生成、Whisper 的语音转文字以及最新的文本转语音和视觉识别功能,让用户在熟悉的聊天窗口中即可享受多模态的 AI 服务。
这款工具主要解决了用户希望在不切换应用的情况下,随时随地通过手机或电脑便捷访问先进 AI 模型的需求。它自动处理对话上下文总结以节省成本,并提供详细的用量统计与预算控制,有效避免了令牌超额消耗的问题。无论是个人日常助手搭建,还是小团队内部的知识库问答,它都能提供稳定且可定制的解决方案。
chatgpt-telegram-bot 非常适合具有一定技术基础的开发者、希望私有化部署 AI 服务的极客用户,以及需要为社群或团队快速构建智能助手的运营人员。其独特的技术亮点包括对 GPT-4o、o1 等最新模型的即时支持,丰富的插件系统(如天气查询、Spotify 联动),以及完善的权限管理和多语言本地化特性。只需简单的配置或通过 Docker 部署,即可拥有一个功能全面、响应流畅的专属 AI 伙伴。
使用场景
某跨国远程开发团队日常依赖 Telegram 进行即时沟通,需要在移动端快速解决代码报错、生成测试数据及查询技术文档。
没有 chatgpt-telegram-bot 时
- 成员遇到紧急 Bug 时,必须中断聊天流程,切换至浏览器打开网页版 ChatGPT,复制粘贴问题后再将答案传回群组,操作繁琐且打断思路。
- 语音站会中产生的灵感或报错描述无法直接转化为文本方案,必须手动转录或打字复述,导致信息流失和效率低下。
- 团队难以管控 API 使用成本,缺乏个人用量统计,常出现个别成员过度调用导致团队预算超支却无法追溯的情况。
- 需要绘图或查询实时天气等扩展功能时,不得不分别打开多个独立工具或网站,无法在单一对话窗口内完成闭环。
使用 chatgpt-telegram-bot 后
- 开发者直接在群聊中通过
/reset重置上下文或发送代码片段,机器人即刻返回带 Markdown 格式化的修复建议,实现“提问即解决”的无缝体验。 - 利用 Whisper 集成能力,成员直接发送语音消息即可自动转写并获取技术分析结果,甚至支持 GPT-4o 视觉模型直接解读截图中的报错日志。
- 管理员可配置用户预算与配额,并通过
/stats命令实时查看每位成员的 Token 消耗明细,有效防止资源滥用并优化成本分配。 - 通过插件系统,团队能在同一对话框内直接调用
/image生成原型图或查询外部 API,无需跳转即可满足编码、绘图及信息查询的多重需求。
chatgpt-telegram-bot 将强大的 AI 能力无缝嵌入团队现有的沟通流中,把碎片化的工具操作转化为高效的自然语言交互,显著提升了远程协作的响应速度与智能化水平。
运行环境要求
- 未说明
未说明
未说明
快速开始
ChatGPT Telegram 机器人
![]()
![]()
![]()
![]()
一个与 OpenAI 的 官方 ChatGPT、DALL·E 和 Whisper API 集成的 Telegram 机器人,用于提供回答。开箱即用,只需极少配置。
截图
演示
插件
特性
- 支持在回答中使用 Markdown 格式
- 使用
/reset命令重置对话 - 生成回复时显示打字提示
- 可通过指定允许用户列表来限制访问权限
- 支持 Docker 和代理
- 通过
/image命令使用 DALL·E 生成图像 - 使用 Whisper 转录音频和视频消息(可能需要 ffmpeg)
- 自动总结对话以避免过度消耗 token
- 按用户跟踪 token 使用情况 - 由 @AlexHTW 提供
- 通过
/stats命令获取个人 token 使用统计信息 - 由 @AlexHTW 提供 - 用户预算和访客预算 - 由 @AlexHTW 提供
- 流式支持
- GPT-4 支持
- 如果您有权访问 GPT-4 API,只需将
OPENAI_MODEL参数更改为gpt-4
- 如果您有权访问 GPT-4 API,只需将
- 本地化机器人语言
- 可用语言 :brazil: :cn: :finland: :de: :indonesia: :iran: :it: :malaysia: :netherlands: :poland: :ru: :saudi_arabia: :es: :taiwan: :tr: :ukraine: :gb: :uzbekistan: :vietnam: :israel:
- 改进的内联查询支持,适用于群组和私聊 - 由 @bugfloyd 提供
- 要使用此功能,请在 BotFather 中通过
/setinline命令为您的机器人启用内联查询
- 要使用此功能,请在 BotFather 中通过
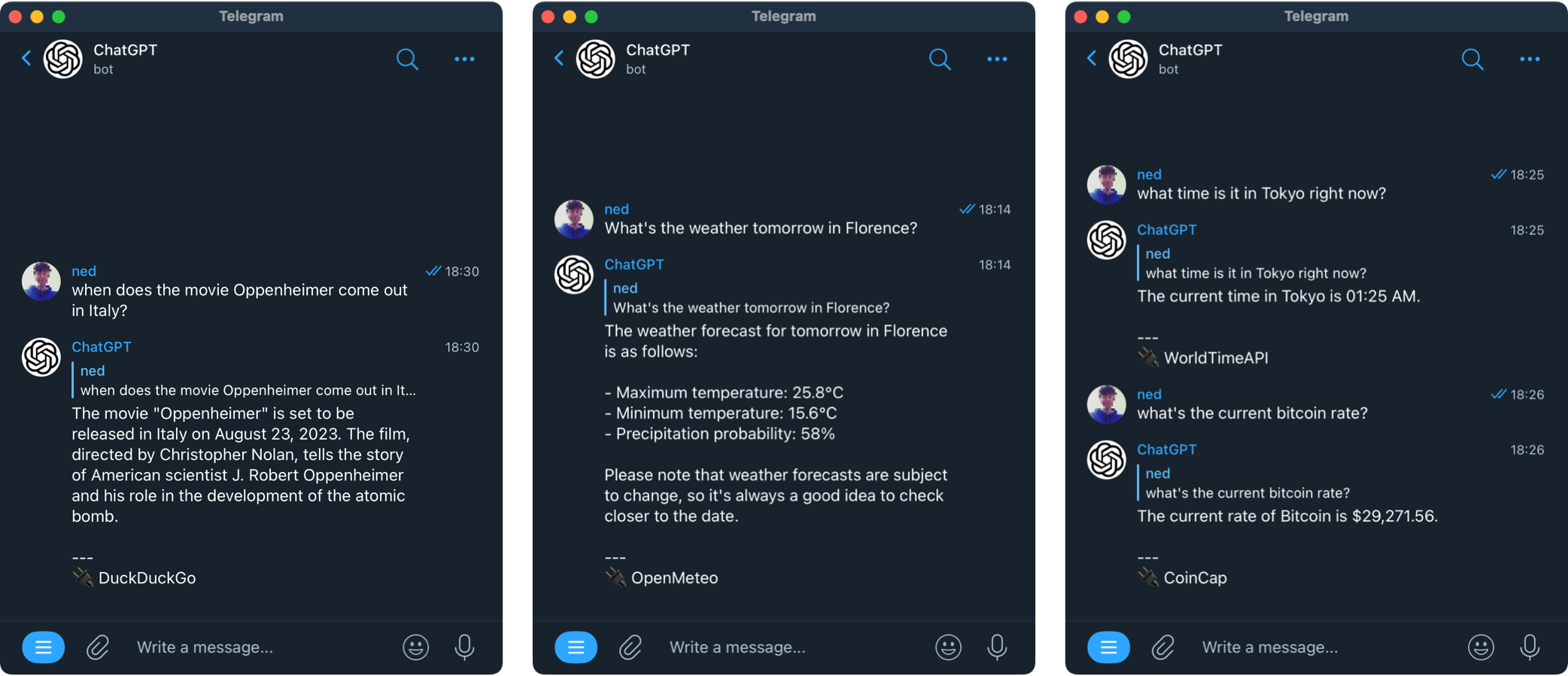
- 支持 2023 年 6 月 13 日宣布的新模型 (https://openai.com/blog/function-calling-and-other-api-updates)
- 支持 函数(插件),可通过第三方服务扩展机器人的功能
- 天气、Spotify、网页搜索、文本转语音等。有关可用插件的列表,请参阅 此处
- 支持非官方的 OpenAI 兼容 API - 由 @kristaller486 提供
- (新增!)支持 GPT-4 Turbo 和 DALL·E 3 [于 2023 年 11 月 6 日宣布] (https://openai.com/blog/new-models-and-developer-products-announced-at-devday) - 由 @AlexHTW 提供
- (新增!)文本转语音支持 [于 2023 年 11 月 6 日宣布] (https://platform.openai.com/docs/guides/text-to-speech) - 由 @gilcu3 提供
- (新增!)视觉支持 [于 2023 年 11 月 6 日宣布] (https://platform.openai.com/docs/guides/vision) - 由 @gilcu3 提供
- (新增!)GPT-4o 模型支持 [于 2024 年 5 月 12 日宣布] (https://openai.com/index/hello-gpt-4o/) - 由 @err09r 提供
- (新增!)o1 和 o1-mini 模型的初步支持
其他特性 - 需要帮助!
如果您想帮忙,请查看 问题 部分并贡献!如果您想协助翻译,请查看 翻译手册
欢迎随时提交 PR!
先决条件
- Python 3.9+
- 一个 Telegram 机器人及其令牌(请参阅 教程)
- 一个 OpenAI 账户(请参阅 配置 部分)
开始使用
配置
通过复制 .env.example 并将其重命名为 .env,然后根据需要编辑所需参数来自定义配置:
| 参数 | 描述 |
|---|---|
OPENAI_API_KEY |
您的 OpenAI API 密钥,可从 这里 获取 |
TELEGRAM_BOT_TOKEN |
您的 Telegram 机器人令牌,使用 BotFather 获取(请参阅 教程) |
ADMIN_USER_IDS |
管理员的 Telegram 用户 ID。这些用户可以访问特殊的管理命令、信息,并且没有预算限制。管理员 ID 不必添加到 ALLOWED_TELEGRAM_USER_IDS 中。注意:默认情况下无管理员 (-) |
ALLOWED_TELEGRAM_USER_IDS |
允许与机器人交互的 Telegram 用户 ID 列表,以逗号分隔(使用 getidsbot 查找您的用户 ID)。注意:默认情况下,所有人 都被允许 (*) |
可选配置
以下参数是可选的,可以在 .env 文件中设置:
预算
| 参数 | 描述 | 默认值 |
|---|---|---|
BUDGET_PERIOD |
决定所有预算适用的时间范围。可用周期:daily (每天重置预算)、monthly (每月1号重置预算)、all-time (永不重置预算)。更多信息请参阅预算手册 |
monthly |
USER_BUDGETS |
以逗号分隔的列表,为 ALLOWED_TELEGRAM_USER_IDS 列表中的每个用户设置自定义的 OpenAI API 费用使用上限(单位:美元)。对于 * 用户列表,将 USER_BUDGETS 的第一个值分配给每位用户。注意:默认情况下,对任何用户均不设置限制(*)。更多信息请参阅预算手册 |
* |
GUEST_BUDGET |
所有访客用户的使用上限金额(单位:美元)。访客用户是指不在 ALLOWED_TELEGRAM_USER_IDS 列表中的群聊用户。如果用户预算中未设置使用上限(即 USER_BUDGETS=*),则此值将被忽略。更多信息请参阅预算手册 |
100.0 |
TOKEN_PRICE |
每1000个 token 的美元价格,用于在使用统计中计算费用信息。数据来源:https://openai.com/pricing | 0.002 |
IMAGE_PRICES |
一个包含3个元素的逗号分隔列表,分别对应不同图像尺寸的价格:256x256、512x512 和 1024x1024。数据来源:https://openai.com/pricing |
0.016,0.018,0.02 |
TRANSCRIPTION_PRICE |
每分钟音频转录的美元价格。数据来源:https://openai.com/pricing | 0.006 |
VISION_TOKEN_PRICE |
每1000个 token 图像理解的美元价格。数据来源:https://openai.com/pricing | 0.01 |
TTS_PRICES |
一个包含两种文本转语音模型价格的逗号分隔列表:tts-1 和 tts-1-hd。数据来源:https://openai.com/pricing |
0.015,0.030 |
有关可能的预算配置,请查看预算手册。
其他可选配置选项
| 参数 | 描述 | 默认值 |
|---|---|---|
ENABLE_QUOTING |
是否在私聊中启用消息引用 | true |
ENABLE_IMAGE_GENERATION |
是否通过 /image 命令启用图像生成 |
true |
ENABLE_TRANSCRIPTION |
是否启用音频和视频消息的转录功能 | true |
ENABLE_TTS_GENERATION |
是否通过 /tts 命令启用文本转语音功能 |
true |
ENABLE_VISION |
在支持的模型中是否启用视觉功能 | true |
PROXY |
用于 OpenAI 和 Telegram 机器人代理(例如 http://localhost:8080) |
- |
OPENAI_PROXY |
仅用于 OpenAI 的代理(例如 http://localhost:8080) |
- |
TELEGRAM_PROXY |
仅用于 Telegram 机器人的代理(例如 http://localhost:8080) |
- |
OPENAI_MODEL |
用于生成回复的 OpenAI 模型。所有可用模型可在 这里 查看 | gpt-4o |
OPENAI_BASE_URL |
非官方 OpenAI 兼容 API 的端点 URL(例如 LocalAI 或 text-generation-webui) | 默认 OpenAI API URL |
ASSISTANT_PROMPT |
设置助手语气和行为的系统消息 | You are a helpful assistant. |
SHOW_USAGE |
是否在每次回复后显示 OpenAI token 使用情况信息 | false |
STREAM |
是否以流式方式返回响应。注意:若启用且 N_CHOICES 大于 1,则不兼容 |
true |
MAX_TOKENS |
ChatGPT API 返回的最大 token 数量上限 | GPT-3 为 1200,GPT-4 为 2400 |
VISION_MAX_TOKENS |
视觉模型返回的最大 token 数量上限 | gpt-4o 为 300 |
VISION_MODEL |
用于视觉到语音转换的模型。允许值:gpt-4o |
gpt-4o |
ENABLE_VISION_FOLLOW_UP_QUESTIONS |
若为 true,则在向机器人发送图片后,它将一直使用配置的 VISION_MODEL 直至对话结束。否则,它将使用 OPENAI_MODEL 继续对话。允许值:true 或 false |
true |
MAX_HISTORY_SIZE |
为避免过度消耗 token,内存中最多保留的消息数量,超过此数量时将对对话进行摘要处理 | 15 |
MAX_CONVERSATION_AGE_MINUTES |
对话自最后一条消息起最长持续时间(分钟),超过此时间将重置对话 | 180 |
VOICE_REPLY_WITH_TRANSCRIPT_ONLY |
是否仅用转录内容回复语音消息,还是同时提供基于转录内容的 ChatGPT 回复 | false |
VOICE_REPLY_PROMPTS |
由分号分隔的短语列表(如 Hi bot;Hello chat)。若转录内容以其中任一短语开头,则即使 VOICE_REPLY_WITH_TRANSCRIPT_ONLY 设置为 true,也会被视为提示语 |
- |
VISION_PROMPT |
一句短语(如 What is in this image)。视觉模型会将其作为提示来解读所上传的图片。若发送给机器人的图片带有说明文字,则该说明文字将覆盖此参数 |
What is in this image |
N_CHOICES |
对每条输入消息生成的回答数量。注意:若启用 STREAM,将此值设置为大于 1 将无法正常工作 |
1 |
TEMPERATURE |
介于 0 和 2 之间的数值。数值越高,输出越随机 | 1.0 |
PRESENCE_PENALTY |
介于 -2.0 和 2.0 之间的数值。正值会根据新 token 是否已出现在文本中对其惩罚 | 0.0 |
FREQUENCY_PENALTY |
介于 -2.0 和 2.0 之间的数值。正值会根据新 token 在文本中出现的频率对其进行惩罚 | 0.0 |
IMAGE_FORMAT |
Telegram 接收图片的模式。允许值:document 或 photo |
photo |
IMAGE_MODEL |
要使用的 DALL·E 模型。可用模型有 dall-e-2 和 dall-e-3,当前可用模型可在 这里 查看 |
dall-e-2 |
IMAGE_QUALITY |
DALL·E 图像的质量,仅适用于 dall-e-3 模型。可选值:standard 或 hd,请注意 定价差异。 |
standard |
IMAGE_STYLE |
DALL·E 图像生成的风格,仅适用于 dall-e-3 模型。可选值:vivid 或 natural。可用风格可在 这里 查看。 |
vivid |
IMAGE_SIZE |
DALL·E 生成的图片尺寸。对于 dall-e-2,必须是 256x256、512x512 或 1024x1024;对于 dall-e-3 模型,则必须是 1024x1024。 |
512x512 |
VISION_DETAIL |
视觉模型的细节参数,详见 Vision Guide。允许值:low 或 high |
auto |
GROUP_TRIGGER_KEYWORD |
若设置,群聊中的机器人仅会对以该关键词开头的消息做出回应 | - |
IGNORE_GROUP_TRANSCRIPTIONS |
若设置为 true,机器人将不会处理群聊中的转录内容 |
true |
IGNORE_GROUP_VISION |
若设置为 true,机器人将不会处理群聊中的视觉查询 |
true |
BOT_LANGUAGE |
机器人通用消息的语言。目前支持的语言有:en、de、ru、tr、it、fi、es、id、nl、zh-cn、zh-tw、vi、fa、pt-br、uk、ms、uz、ar。欢迎贡献更多语言翻译 |
en |
WHISPER_PROMPT |
为提高 Whisper 转录服务的准确性,尤其是针对特定名称或术语,可以设置自定义提示。Speech to text - Prompting | - |
TTS_VOICE |
要使用的文本转语音声音。允许值:alloy、echo、fable、onyx、nova 或 shimmer |
alloy |
TTS_MODEL |
要使用的文本转语音模型。允许值:tts-1 或 tts-1-hd |
tts-1 |
更多详情请查看官方 API 参考文档。
函数
| 参数 | 描述 | 默认值 |
|---|---|---|
ENABLE_FUNCTIONS |
是否使用函数(又称插件)。您可以此处了解更多关于函数的信息 | true(如果模型支持) |
FUNCTIONS_MAX_CONSECUTIVE_CALLS |
模型在单次响应中可连续调用的最大函数次数,超过此值将显示面向用户的消息 | 10 |
PLUGINS |
要启用的插件列表(完整列表见下文),例如:PLUGINS=wolfram,weather |
- |
SHOW_PLUGINS_USED |
是否显示本次响应中使用了哪些插件 | false |
可用插件
| 名称 | 描述 | 必需的环境变量 | 依赖 |
|---|---|---|---|
weather |
提供任何地点的每日天气及未来7天的预报(由Open-Meteo提供支持) | - | |
wolfram |
WolframAlpha 查询(由WolframAlpha提供支持) | WOLFRAM_APP_ID |
wolframalpha |
ddg_web_search |
网页搜索(由DuckDuckGo提供支持) | - | duckduckgo_search |
ddg_image_search |
图片或 GIF 搜索(由DuckDuckGo提供支持) | - | duckduckgo_search |
crypto |
实时加密货币汇率(由CoinCap提供支持)——由@stumpyfr开发 | - | |
spotify |
Spotify 热门歌曲/艺人、当前播放的歌曲以及内容搜索(由Spotify提供支持)。需要进行一次性授权。 | SPOTIFY_CLIENT_ID、SPOTIFY_CLIENT_SECRET、SPOTIFY_REDIRECT_URI |
spotipy |
worldtimeapi |
获取最新的世界时间(由WorldTimeAPI提供支持)——由@noriellecruz开发 | WORLDTIME_DEFAULT_TIMEZONE |
|
dice |
在聊天中发送一个骰子! | - | |
youtube_audio_extractor |
从 YouTube 视频中提取音频 | - | pytube |
deepl_translate |
将文本翻译成任意语言(由DeepL提供支持)——由@LedyBacer开发 | DEEPL_API_KEY |
|
gtts_text_to_speech |
文本转语音(由 Google Translate API 提供支持) | - | gtts |
whois |
查询 WHOIS 域名数据库——由@jnaskali开发 | - | whois |
webshot |
根据给定的 URL 或域名截取网站截图——由@noriellecruz开发 | - | |
auto_tts |
使用 OpenAI API 进行文本转语音——由@Jipok开发 | - |
环境变量
| 变量 | 描述 | 默认值 |
|---|---|---|
WOLFRAM_APP_ID |
Wolfram Alpha 应用程序 ID(仅 wolfram 插件需要,可在此获取) |
- |
SPOTIFY_CLIENT_ID |
Spotify 应用程序客户端 ID(仅 spotify 插件需要,可在开发者控制台找到) |
- |
SPOTIFY_CLIENT_SECRET |
Spotify 应用程序客户端密钥(仅 spotify 插件需要,可在开发者控制台找到) |
- |
SPOTIFY_REDIRECT_URI |
Spotify 应用程序重定向 URI(仅 spotify 插件需要,可在开发者控制台找到) |
- |
WORLDTIME_DEFAULT_TIMEZONE |
默认时区,例如 Europe/Rome(仅 worldtimeapi 插件需要,时区标识符可从这里获取) |
- |
DUCKDUCKGO_SAFESEARCH |
DuckDuckGo 安全搜索设置(on、off 或 moderate)(可选,适用于 ddg_web_search 和 ddg_image_search) |
moderate |
DEEPL_API_KEY |
DeepL API 密钥(deepl 插件需要,可在此获取) |
- |
安装
克隆仓库并进入项目目录:
git clone https://github.com/n3d1117/chatgpt-telegram-bot.git
cd chatgpt-telegram-bot
从源码安装
- 创建虚拟环境:
python -m venv venv
- 激活虚拟环境:
# 对于 Linux 或 macOS:
source venv/bin/activate
# 对于 Windows:
venv\Scripts\activate
- 使用
requirements.txt文件安装依赖项:
pip install -r requirements.txt
- 使用以下命令启动机器人:
python bot/main.py
使用 Docker Compose
运行以下命令以构建并运行 Docker 镜像:
docker compose up
即用型 Docker 镜像
您也可以使用 Docker Hub 上的 Docker 镜像:
docker pull n3d1117/chatgpt-telegram-bot:latest
docker run -it --env-file .env n3d1117/chatgpt-telegram-bot
或者使用 GitHub Container Registry:
docker pull ghcr.io/n3d1117/chatgpt-telegram-bot:latest
docker run -it --env-file .env ghcr.io/n3d1117/chatgpt-telegram-bot
手动构建 Docker 镜像
docker build -t chatgpt-telegram-bot .
docker run -it --env-file .env chatgpt-telegram-bot
Heroku
以下是使用 Heroku 部署的 Procfile 示例(感谢 err09r!):
worker: python -m venv venv && source venv/bin/activate && pip install -r requirements.txt && python bot/main.py
致谢
免责声明
本项目为个人项目,与 OpenAI 无任何关联。
许可证
本项目根据 GPL 2.0 许可证发布。更多信息请参阅仓库中包含的 LICENSE 文件。
版本历史
0.4.22024/12/280.4.12024/05/140.4.02023/12/110.3.12023/08/050.3.02023/08/040.2.62023/06/140.2.52023/04/220.2.42023/04/150.2.32023/04/080.2.22023/04/010.2.12023/03/260.2.02023/03/180.1.82023/03/170.1.72023/03/140.1.62023/03/110.1.52023/03/060.1.42023/03/050.1.32023/03/040.1.22023/03/030.1.12023/03/02常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。