last30days-skill
last30days-skill 是一款专为 AI 助手设计的智能研究插件,旨在帮助用户快速掌握任意主题在过去 30 天内的最新动态。面对信息爆炸且瞬息万变的 AI 领域,它解决了人工搜集碎片化信息耗时费力、难以辨别真伪的痛点。通过自动检索 Reddit、X、YouTube、Hacker News、Polymarket 预测市场乃至 Bluesky 等多个主流平台,last30days-skill 能精准识别社区真正关注的高赞内容、热门讨论及真实投注趋势,最终合成一份带有真实引用的深度综述报告。
这款工具特别适合开发者、技术研究人员、产品设计师以及需要紧跟行业前沿的专业人士使用。无论是追踪最新的技术框架(如 Claude Code)、设计提示词趋势,还是分析市场预测数据,它都能提供极具价值的洞察。其独特亮点在于强大的多源数据融合能力:不仅支持"X vs Y"对比模式以生成数据驱动的横向评测,还引入了基于参与度、权威性和跨平台共识的智能评分算法,确保结果客观可靠。此外,它支持自动将研究报告保存为本地文档,帮助用户构建个人的动态知识库,让知识积累变得更加轻松高效。
使用场景
一位 AI 应用开发者正急需为新产品选型,需要快速掌握过去一个月内社区对"Claude Code"与"Cursor"的真实评价、实战技巧及市场预测。
没有 last30days-skill 时
- 信息搜集碎片化:需手动在 Reddit、X、YouTube 和 Hacker News 间反复切换搜索,耗时数小时仍难以覆盖全貌。
- 噪音干扰严重:搜索结果充斥着过时的教程或营销软文,难以分辨哪些是社区真正点赞(Upvote)的高价值内容。
- 缺乏深度对比:想要对比两个工具的优劣,只能凭印象拼凑观点,缺少基于实时数据(如 Polymarket 预测赔率)的客观依据。
- 知识无法沉淀:调研过程零散,结束后没有自动归档的报告,导致后续复盘或团队分享时需重新整理资料。
使用 last30days-skill 后
- 全域一键聚合:输入"/last30 Claude Code vs Cursor",工具自动并行抓取 Reddit、X、YouTube、HN 及 Polymarket 等源头的最新数据。
- 智能去噪排序:基于互动速度、来源权威性及跨平台共识算法,自动提炼出社区热议的“真知灼见”并附带真实引用链接。
- 数据驱动决策:自动生成侧边对比表,不仅列出优缺点,还引入 Polymarket 上的真实资金投注倾向作为市场信心参考,给出数据化结论。
- 自动构建知识库:调研结束瞬间,一份完整的 Markdown 格式分析报告已自动保存至本地文档文件夹,方便随时查阅或分享给团队。
last30days-skill 将原本需要半天的手动情报工作压缩为几分钟的自动化洞察,让开发者始终基于最新、最真实的社区共识做出技术决策。
运行环境要求
- macOS
- Linux
- Windows
未说明
未说明

快速开始
/last30days v2.9.5
Claude Code(推荐)
/plugin marketplace add mvanhorn/last30days-skill
/plugin install last30days@last30days-skill
clawhub install last30days-official
AI世界每月都在自我革新。这款技能助你时刻掌握最新动态。 /last30days会跨Reddit、X、YouTube等平台,检索过去30天内的相关内容,找出社区成员真正点赞、分享、下注以及在镜头前讨论的话题,并为你撰写一篇基于真实引用的客观叙述。无论是Seedance 2.0的访问权限、paper.design的提示词,还是最新的Nano Banana Pro技巧,你都能第一时间了解那些关注热点的人所知的信息。
v2.9.5版本新增功能——Bluesky、对比模式与配置优化:
- Bluesky/AT协议现已成为社交数据源之一。可通过设置
BSKY_HANDLE和BSKY_APP_PASSWORD(可在bsky.app/settings/app-passwords中创建)来启用。完整流程包括搜索、评分、去重及渲染。 - 对比模式——只需输入“X vs Y”(例如:/last30 Claude Code vs Codex),即可获得三次并行检索结果,并以并列对比的形式呈现:优势、劣势、直接对决表格以及基于数据的最终结论。
- 项目级.env配置文件——在项目根目录下创建
.claude/last30days.env文件,用于存储该项目专用的API密钥。 - 会话启动时配置检查——当Claude Code会话启动时,系统会自动验证你的配置是否正确。
- 测试覆盖率提升——所有模块的测试数量已超过455项。
v2.9.1版本新增功能——自动保存至~/Documents/Last30Days/: 每次运行后,完整的报告都会以主题命名的.md文件形式保存到你的文档文件夹中。轻松构建个人研究资料库。灵感来源于@devin_explores。
v2.9版本新增功能——ScrapeCreators Reddit + 热门评论 + 智能发现:
Reddit现默认使用ScrapeCreators服务——只需一个SCRAPECREATORS_API_KEY即可覆盖Reddit、TikTok和Instagram三大平台(三者共用一个密钥)。智能子版块发现功能可自动定位相关社区,而热门评论则会被赋予10%的权重,并以带有“💬”符号和点赞数的方式展示。详情见下文。
v2.8版本新增功能——Instagram Reels + ScrapeCreators:
Instagram Reels现已成为第八个信号源。TikTok和Instagram均采用ScrapeCreators服务,两者共用一个API密钥。详情见下文。
v2.5版本新增功能——显著提升效果:
- Polymarket预测市场与Hacker News: 查看人们正在投入真金白银下注的内容,以及技术社区当前热议的话题。搜索“Arizona Basketball”,即可获取NCAA锦标赛冠军赔率(亚利桑那大学:12%)、成为头号种子的概率(88%)以及Big 12联赛冠军争夺战的胜算(69%)——这些数据来自10个赛事中的50多个公开市场,而非仅凭Reddit上的观点得出。搜索“Iran War”,则可看到15个实时预测市场,涵盖空袭概率、政权更迭赌注及宣战几率等信息。通过两轮查询扩展结合标签式领域关联,能够挖掘出那些将你的主题作为更广泛事件中某个结果的市场,而不仅仅是标题关键词匹配的结果。HN新闻、Show HN帖子以及评论见解会根据积分和评论数进行评分,并参与跨源一致性检测。
- 多信号质量加权相关性评分: 所有六个数据源中的每一条结果都会经过综合评分流程:双向文本相似度分析(含同义词扩展与词元重叠计算)、互动热度归一化处理、来源权威性加权、基于混合三元组-词元Jaccard相似度的跨平台一致性检测,以及时间衰减机制。Polymarket市场的评分由五个因素加权构成——文本相关性(30%)、24小时交易量(30%)、流动性深度(15%)、价格波动速度(15%)以及结果竞争程度(10%)——同时还会根据具体结果对你的主题进行匹配评分,而不仅仅依据事件标题。盲测结果显示,v2.5版本在5个测试主题上的平均得分为4.38/5.0,高于v1版本的3.73/5.0。
- X账号解析: 搜索“Dor Brothers”,该技能会自动解析其账号(@thedorbrothers),并直接检索其帖子——找到那条被关键词搜索完全遗漏的5,600赞爆文。此功能适用于个人、品牌、产品和工具。
v2.1版本新增功能: 开放式技能,支持关注列表;将YouTube字幕作为数据源之一;可在OpenAI Codex CLI中使用。完整变更日志见下文。
v2版本新增功能: 更智能的查询构建、双阶段补充搜索、通过捆绑的Bird客户端免费检索X平台内容、--days=N标志以及自动模型回退功能。完整变更日志见下文。
权衡取舍: /last30days会检索大量内容,但耗时2至8分钟不等,具体取决于你所选主题的冷门程度。最多可并行检索10个数据源,随后进行评分、去重并整合生成最终结果。我们认为这种深度值得等待,但如果你更注重速度而非全面性,也可选择--quick模式。
最适合用于提示词研究: 通过学习真实的社区讨论和最佳实践,发现哪些提示词技巧真正适用于各类工具(如ChatGPT、Midjourney、Claude、Paper等)。
同样也适用于任何热门话题: 音乐、文化、新闻、产品推荐、网络热梗,或任何需要了解“当下大家都在谈论什么”的问题。
安装方法
Claude Code插件(推荐)
/plugin marketplace add mvanhorn/last30days-skill
/plugin install last30days@last30days-skill
Gemini CLI
gemini extensions install https://github.com/mvanhorn/last30days-skill.git
手动安装(Claude Code / Codex)
git clone https://github.com/mvanhorn/last30days-skill.git ~/.claude/skills/last30days
完成以上步骤即可。Reddit、Hacker News和Polymarket无需任何配置即可立即使用。运行/last30days即可解锁更多数据源。
设置:逐步解锁数据源
你可以立即开始使用/last30days。若想获得更佳效果,再逐步添加其他数据源。
1. 零配置(3个数据源)——直接安装即可
Reddit(公共JSON)、Hacker News和Polymarket无需任何API密钥或配置即可直接使用。
2. 运行设置向导(5个以上数据源)
/last30days setup
设置向导会自动从你的浏览器(Chrome、Firefox、Safari)中提取X/Twitter的登录Cookie,并检查是否已安装yt-dlp。整个过程大约需要30秒。你的Cookie仅保留在内存中,绝不会被保存到磁盘上。
3. 添加Exa(免费——语义网搜索)
在exa.ai注册,每月可享受1,000次免费搜索,无需信用卡。
# 添加至~/.config/last30days/.env
EXA_API_KEY=...
4. 添加 ScrapeCreators(推荐 — Reddit 评论 + TikTok + Instagram)
这是最具影响力的升级。 Reddit 评论通常是价值最高的研究内容——获得高赞的真实见解回复。ScrapeCreators 能解锁评论的丰富信息,同时支持 TikTok 和 Instagram。在 scrapecreators.com 注册即可获得 100 次免费 API 调用(无需信用卡)。之后按使用量付费。last30days 不会从任何 API 提供商处获取任何收益——没有推荐佣金,也没有回扣。
# 添加到 ~/.config/last30days/.env
SCRAPECREATORS_API_KEY=...
5. 添加 Bluesky(免费 — 应用密码)
在 bsky.app/settings/app-passwords 创建一个应用密码。
# 添加到 ~/.config/last30days/.env
BSKY_HANDLE=you.bsky.social
BSKY_APP_PASSWORD=xxxx-xxxx-xxxx
6. 可选的付费网络搜索后端
# 添加到 ~/.config/last30days/.env
PARALLEL_API_KEY=... # Parallel AI(首选 — 经过 LLM 优化的结果)
BRAVE_API_KEY=... # Brave Search(免费层级:每月 2,000 次查询)
OPENROUTER_API_KEY=... # OpenRouter/Perplexity Sonar Pro
我需要 API 密钥吗?
| 来源 | 免费方法 | API 密钥 | 是否需要 API 密钥? |
|---|---|---|---|
| 公开 JSON(始终可用) | ScrapeCreators | 是,强烈推荐。 解锁优质评论——通常是最有价值的内容。 | |
| X/Twitter | 浏览器 Cookie(自动提取) | xAI API 密钥 (XAI_API_KEY) |
否。 Cookie 提供相同质量。设置向导会自动处理。 |
| YouTube | yt-dlp (brew install yt-dlp) |
无 | 无需 API 密钥。 安装 yt-dlp 进行搜索;转录文本无需它即可使用。 |
| Hacker News | 始终免费 | 无 | 否。 始终可用,无需配置。 |
| Polymarket | 始终免费 | 无 | 否。 始终可用,无需配置。 |
| 网络搜索 | 无 | Exa (EXA_API_KEY) |
可选。 在 exa.ai 上每月有 1,000 次免费搜索。 |
| Bluesky | 免费应用密码 | 无 | 可选。 在 bsky.app 上可免费获取应用密码。 |
| TikTok | 无 | ScrapeCreators | 可选。 包含在 ScrapeCreators 密钥中。 |
| 无 | ScrapeCreators | 可选。 包含在 ScrapeCreators 密钥中。 | |
| Truth Social | 浏览器 Cookie | 无 | 可选。 如果已登录,则会自动提取。 |
last30days 不会从任何 API 提供商处获取任何收益——没有推荐佣金,也没有回扣。
配置文件位置
若需针对特定项目进行覆盖,可在仓库根目录下创建 .claude/last30days.env 文件。该文件将覆盖全局的 ~/.config/last30days/.env。
# 全局配置
mkdir -p ~/.config/last30days
chmod 600 ~/.config/last30days/.env
# 项目特定配置(可选)
# .claude/last30days.env
检查源的可用性:python3 scripts/last30days.py --diagnose
Codex CLI
此技能同样适用于 OpenAI Codex CLI。只需将其安装到 Codex 的技能目录中:
git clone https://github.com/mvanhorn/last30days-skill.git ~/.agents/skills/last30days
相同的 SKILL.md、相同的 Python 引擎和脚本。agents/openai.yaml 提供了 Codex 特有的发现元数据。可通过 $last30days 或通过 /skills 菜单调用。
开放变体(监控列表 + 简报)——适用于常驻机器人
专为 Open Claw 及类似常驻 AI 环境设计。 将您的竞争对手、特定人物或任何主题添加到监控列表中。与定时任务或常驻机器人结合使用时,/last30days 会按计划重新研究这些内容,并将结果累积到本地 SQLite 数据库中。您可以随时请求简报。
重要提示: 监控列表以元数据形式存储调度信息,但没有任何机制会自动触发运行。您需要一个外部调度程序(cron、launchd 或像 Open Claw 这样的常驻机器人)来定时调用 watchlist.py run-all。在 Plain Claude Code 中,您可以手动运行 watch run-one 和 watch run-all,但无法实现后台调度。
# 启用开放变体
cp variants/open/SKILL.md ~/.claude/skills/last30days/SKILL.md
# 将主题添加到您的监控列表
last30 watch 我最大的竞争对手 每周
last30 watch 彼得·施泰因贝格 每30天
last30 watch AI 视频工具 每月
last30 Y Combinator 热门公司 四月底和九月底
# 手动运行研究(或让您的机器人 cron 处理)
last30 run 我所有被监控的主题
# 搜索累积的知识
last30 你关于 AI 视频发现了什么?
开放变体在一次性研究的基础上增加了四种模式:
- 监控列表 — 使用
watch add "topic"跟踪主题,可手动运行或通过 cron 自动执行。 - 简报 — 根据累积的研究成果生成每日/每周摘要。
- 历史记录 — 使用全文搜索查询和检索您的研究数据库。
- 原生网络搜索 — 内置的网络搜索后端(Parallel AI、Brave、OpenRouter),与 Reddit/X/YouTube 并行运行。
两种变体使用相同的 Python 引擎和脚本目录。开放变体增加了命令路由(watch、briefing、history)以及引用特定模式的指令文件。
使用方法
/last30days [话题]
/last30days [话题] for [工具]
示例:
/last30days 针对法律问题的 ChatGPT 提示技巧/last30days Nano Banana Pro 的 iOS 应用原型/last30days 最近有哪些好听的说唱歌曲/last30days Claude Code 的 Remotion 动画
功能说明
- 研究 — 扫描 Reddit、X、YouTube 等平台,查找过去 30 天内的讨论。
- 综合 — 识别模式、最佳实践以及真正有效的方法。
- 输出 — 为您目标工具编写可直接复制粘贴的提示,或为您提供精心挑选的专家级答案。
适用场景:
- 提示词研究 — “ChatGPT 在处理法律问题时有哪些有效的提示技巧?”
- 工具最佳实践 — “人们如何在 Claude Code 中使用 Remotion?”
- 趋势发现 — “目前最热门的说唱歌曲有哪些?”
- 产品研究 — “大家对新款 M4 MacBook 的看法如何?”
- 爆红内容 — “ChatGPT 上‘狗狗拟人化’的趋势是什么?”
示例:Nano Banana Pro 提示词(图像生成)
查询: /last30days nano banana pro prompting
研究结果:
JSON 提示词是主流技术——X 社区绝大多数人使用结构化的 JSON 格式提示,而非纯文本。像 @Xmira_belle、@Cicily_aura、@RubenSalvo_ 和 @mahivisuals 等创作者都以包含元数据、主体描述、光照、相机参数和场景构图等嵌套对象的 JSON 格式分享提示。@realdigitaldao 仅用一个简单的 JSON 提示,在不到 5 分钟内就制作出了一则静态广告。
对提示的精准遵循是 Nano Banana Pro 的核心优势——根据 fofr.ai 的数据,JSON 提示在色彩准确性、光影比例和构图方面的精确度高达 92%,而自然语言提示仅为约 68%。@artingent 将其与 GPT Image 1.5 直接对比后指出,Nano Banana Pro 对提示的遵循度更高:“GPT Image 1.5 完全忽略了‘俯视’这一指令。”
停止编写“标签堆砌式”提示——要像创意总监一样思考——最大的转变在于,人们不再使用逗号分隔的关键字列表,而是采用具有清晰结构的自然语言描述。据 r/nanobanana2pro 论坛统计,ICS 框架(图像类型、内容、风格)和五要素公式(主体、构图、动作、场景、风格)是两种最主要的创作方式。
发现的关键模式:
- JSON > 纯文本——将提示组织成带有主体、构图、光照、相机、风格等键的 JSON 对象——参考 @Xmira_belle 和 @Cicily_aura 的做法。
- 五要素公式——主体 + 构图 + 动作 + 场景 + 风格——参考 r/nanobanana2pro 论坛。
- 将不同主体分别置于独立的 JSON 对象中——多角色场景需要为每个人单独创建一个 JSON 块,以避免“概念混淆”——参考 fofr.ai 的建议。
- 使用相机/镜头元数据——光圈、焦距、ISO、胶片类型等作为 JSON 键,实现对照片级真实感的精细控制。
- 最多提供 14 张参考图——为确保品牌或角色的一致性,可输入最多 14 张参考图片——参考 Google DeepMind 的实践。
研究数据: 来自 r/nanobanana2pro、r/promptingmagic 论坛,以及 @Xmira_belle(106 次点赞)、@Cicily_aura(45 次点赞)的 8 个 Reddit 主题帖(共 455 次赞同)和 31 条 X 平台帖子(183 次点赞、68 次转发)。
随后提问: “为喜欢游泳的妈妈们设计一款应用的原型。”
生成的提示词:
{
"image_type": "UI 原型",
"device": {
"frame": "iPhone 16 Pro",
"display": "逼真的屏幕,带微妙反光",
"orientation": "竖屏"
},
"app_concept": "SwimMom——专为爱游泳妈妈打造的健身与社区应用",
"screen": "首页仪表盘",
"design_system": {
"style": "iOS 18 原生风格",
"corners": "圆角半径 16px",
"shadows": "柔和的阴影,微妙的层次感",
"spacing": "8pt 网格布局,留白充足"
},
"color_palette": {
"primary": "舒缓的水蓝色 (#4ECDC4)",
"secondary": "温暖的珊瑚色 (#FF6B6B)",
"background": "纯净白色,顶部渐变浅蓝"
},
"layout": {
"header": "问候语‘早上好,Sarah’,配波浪图标及右上角的个人头像",
"hero_card": "今日游泳数据——圈数、卡路里、时间——并配有圆形进度环",
"section_2": "横向滚动展示即将举行的妈妈游泳聚会信息,并附地点标签",
"section_3": "两个卡片——‘我的目标’显示连续打卡次数,‘查找泳池’则显示地图标记",
"bottom_nav": "5 个图标——首页(当前选中)、锻炼、社区、日程、个人资料"
},
"visual_details": {
"illustrations": "亲和力十足的极简线条插画,描绘游泳人物",
"typography": "SF Pro Display 字体,层次分明",
"mood": "充满活力又宁静,传递支持性的社区氛围"
}
}
最终效果:
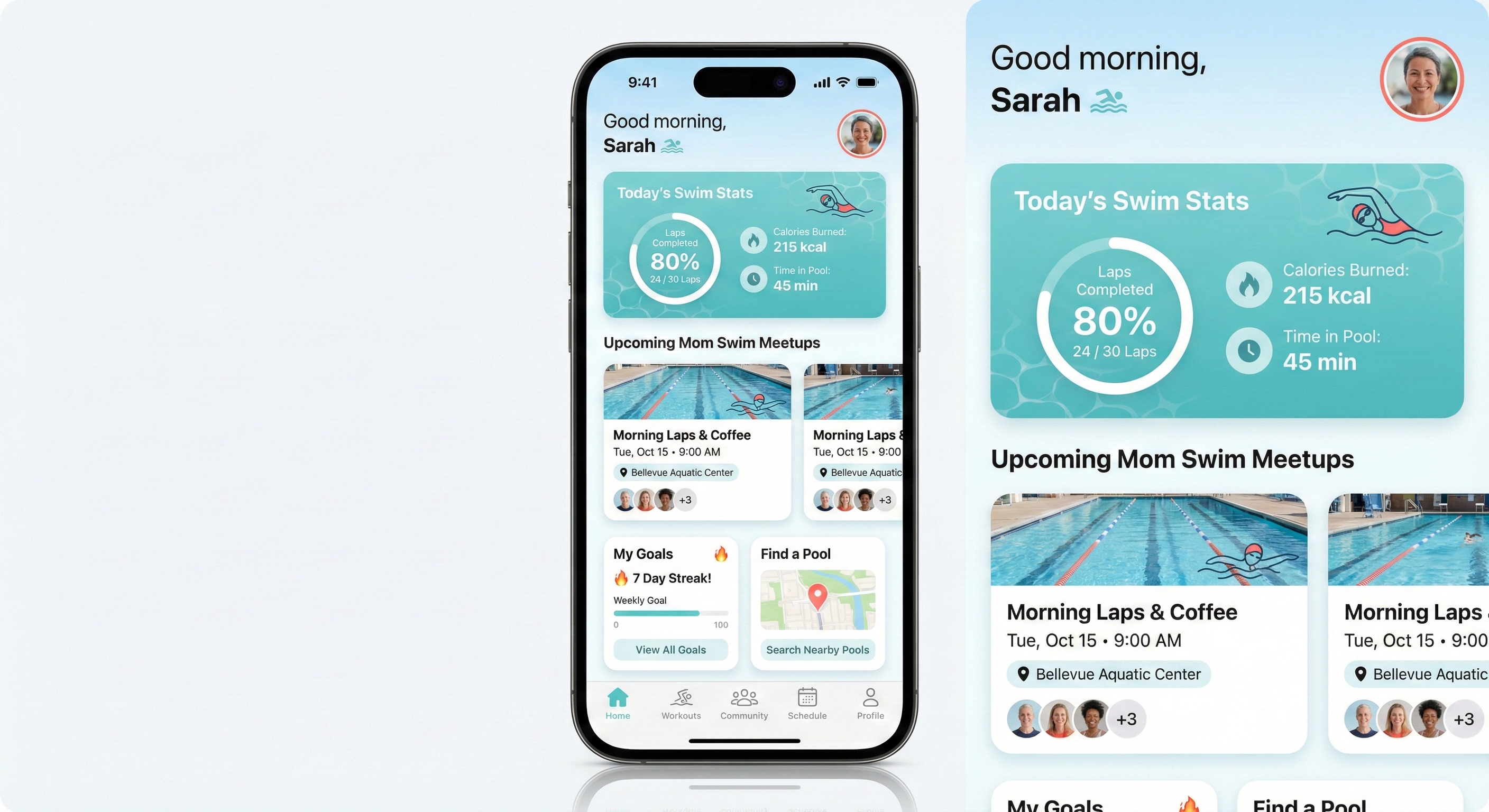
这个例子展示了 /last30days 学习到的结论:JSON 提示词在 Nano Banana Pro 社区中占据主导地位(而非纯文本),随后便运用这一格式一次性生成了一个 iOS 应用原型。这些技巧均源自真实的 X 创作者和 Reddit 论坛讨论,是官方文档中难以找到的方法。
示例:坎耶·韦斯特(时事)
查询: /last30days kanye west
研究结果:
道歉弧线 - 1月26日,Ye在《华尔街日报》上发表了一封整版信件,题为“致我伤害过的人”,为反犹言论道歉,并将其归因于持续四个月的躁狂发作、2002年车祸导致的未确诊脑损伤以及双相情感障碍I型。美国反诽谤联盟称其“姗姗来迟”,但表示这“并不能自动抹去他长期的反犹主义历史”。随后,2月9日,他又发布了一条“我现在爱希特勒了,那又怎样”的帖子——据《镜报》报道,几乎立刻就让之前积累的好感化为乌有。X平台上的粉丝对这次道歉是真诚的还是仅为新专辑宣传存在分歧,这从@dekreationz的一条爆火帖文(8,600个赞)可见一斑。
专辑《BULLY》 - 第十二张录音室专辑,将于3月20日由YZY和Gamma发行。共13首曲目, featuring Peso Pluma、Playboi Carti和Ty Dolla Sign。音乐风格偏向808s/MBDTF领域——以演唱为主,说唱较少。据《滚石》杂志报道,Ye已从最终版本中移除了所有深度伪造或AI生成的歌声。
比安卡·森索里打破沉默 - 在《名利场》的一次坦白采访中,比安卡首次公开谈及他们的婚姻,称“今年就像连续几个月做心肺复苏一样”。她证实自己的穿搭完全出于个人选择,并透露两人关系始于她担任Yeezy建筑部门负责人之时,据TMZ报道。
金·卡戴珊/X平台风波 - 一张据称是Ye评论金·卡戴珊Complex杂志帖子的截图在X平台上疯狂传播。多位Grok的事实核查人员确认该截图很可能是伪造的,但@dekreationz的帖子仍收获近9,000个赞——这表明Ye与金·卡戴珊的故事依然能引发巨大关注。
研究中的关键模式:
- 道歉后复发的循环——《华尔街日报》的道歉信很快就被新的煽动性帖子所抵消,使得关于其诚意的讨论成为主流话题,据《华盛顿邮报》报道。
- 专辑作为公关工具——X平台上的怀疑论者将道歉的时间点直接与《BULLY》专辑3月20日的发行联系起来,据@trustGod_007报道。
- 比安卡作为独立人物——通过《名利场》的采访,她正从“坎耶的妻子”转变为一位独立的公众人物。
- 伪造截图的病毒式传播——尽管被揭穿,但伪造的Ye相关内容仍能在被澄清前迅速走红,据@dekreationz报道。
研究数据: 来自r/Kanye、r/hiphopheads以及@dekreationz(8,684个赞)、@trustGod_007的3个Reddit主题帖(共193个赞、192条评论)+33条X平台帖子(9,295个赞、279次转发)。
后续建议:
我现在是坎耶·韦斯特方面的专家。以下是一些我可以帮助解答的问题:
- 这封道歉信背后的真实动机是什么?是真正的责任担当,还是为新专辑造势?
- 深入解读《BULLY》专辑:曲目列表、与Gamma的合作细节,以及为何移除了AI生成的歌声。
- 比安卡·森索里在《名利场》的采访——她究竟说了什么,与小报标题有何不同?
这个示例展示了如何使用/last30days作为时事研究工具——无需额外提示或指定目标工具,只需输入“坎耶·韦斯特最近发生了什么?”,即可获得一份整合了33条X平台帖子和3个Reddit主题帖的研究简报,其中还包含真实的互动数据。
示例:Anthropic押注(预测市场)
查询: /last30days anthropic odds
研究结果:
五角大楼僵局是当下焦点——国防部长赫格塞斯给Anthropic设定了周五的最后期限:若不放弃用于军事用途的AI安全机制,公司将依据《国防生产法》被列入黑名单,CBS、CNN、彭博社以及@The__GDD、@trendy_tech_和@jimkaskade等人的多条X帖子均有报道。事件导火索是Claude模型在今年1月马杜罗被捕行动中的应用。Anthropic首席执行官达里奥·阿莫迪坚持认为,该公司绝不会涉足由AI控制的武器和大规模监控领域。Polymarket的交易员则认为,禁令的可能性仅为22%,表明他们认为这只是姿态性博弈,据@Lolipeterh报道。
预测市场看好Anthropic的技术,但对上市持谨慎态度——Polymarket预计Anthropic在2月底拥有最佳AI模型的概率高达98%,3月底也有61%的可能(谷歌为22%,OpenAI为10%)。Claude 4.6目前占据主导地位。然而,关于上市的前景则显得更加模糊:@predictheory指出,Anthropic在Kalshi平台上“先于OpenAI上市”的赔率“直线下降,从约70%骤降至十几个百分点”。Polymarket则显示,Anthropic在OpenAI之前上市的概率为64%,但到2026年6月前不会上市的概率高达95%。与此同时,市场预期Anthropic今年市值将突破5000亿美元的概率为87%——当前估值为3800亿美元,此前公司刚刚完成一轮由GIC和Coatue领投的300亿美元融资,据《财富》杂志报道。
Claude FrontierMath押注飙升——Polymarket推出的“Claude能否在FrontierMath测试中取得50%的成绩?”这一市场今日上涨28%,至48%的“会”概率。这实际上是对Claude能否在6月30日前攻克顶尖数学基准的实时押注。
研究中的关键模式:
- 五角大楼僵局被视为一种姿态——Polymarket仅给出22%的实际禁令可能性,资金流向表明这更像是一场谈判秀。
- 模型优势与上市不确定性并存——98%的概率拥有最佳模型,但上市时间仍悬而未决。
- FrontierMath作为实时能力基准的押注——真金白银追踪着Claude的能力发展轨迹。
- 大量资本涌入——丹·桑德海姆的D1 Capital、亚马逊的低调押注,以及3800亿美元的估值。
研究数据: 25条X平台帖子(218个赞)+13个YouTube视频(71.9万次观看)+6篇Hacker News文章(48分)+11个Polymarket市场(2月最佳模型:98%,3月:61%,先于OpenAI上市:64%,市值超5000亿美元:87%,FrontierMath 50%:48%)。
这个示例展示了如何使用/last30days作为预测市场情报工具——只需输入两个词(“anthropic odds”),就能获取11个涵盖模型基准、上市时机、估值里程碑以及五角大楼僵局的实时Polymarket押注信息,并结合X平台评论、YouTube分析和Hacker News讨论进行综合整理。两次查询扩展后,系统还找到了“Anthropic”作为更广泛“最佳AI模型”和“AI公司上市”事件中一个结果的相关市场。
示例:Vibe Motion(全新AI工具)
查询: /last30days higgsfield motion vibe motion prompting
研究结果:
Vibe Motion 刚刚上线(2026年2月5日至6日),热度爆棚 - Higgsfield 推出了一款基于 Claude 的动态设计工具,能够根据纯英文提示生成可编辑的动态图形。据 @Hartdrawss 称,这是首款具备真正推理能力的 AI 视频工具;@rezkhere 也指出,这是“其他任何 AI 都做不到”的功能。Linus Ekenstam 表示,这款工具“让他大开眼界”——过去在 After Effects 中需要数小时完成的工作,如今只需几分钟即可搞定。
它生成的是代码,而非像素 - 与其他 AI 视频工具不同,Vibe Motion 生成的是真正的动画代码(底层使用 Remotion),而不是由 AI 幻觉生成的视频。据 @Totinhiiio 介绍,文本不会出现错位,编辑内容始终保持一致,最终得到的是可控且可编辑的资源。
真实评价:潜力十足,但尚不成熟 - Chase Jarvis 认为生成效果“还行”,但也指出渲染时间长达 5 分钟以上、每次迭代都会消耗大量积分(每次生成需消耗 8–60 积分,而 9 美元套餐仅约 150 积分),并且用 Canva 也能更快地实现基础效果。他的结论是:“尚未达到上线标准”,不过其底层技术展现出巨大潜力。
发现的关键模式:
- 描述结构,而非特效 - 按照 Higgsfield 官方指南,应专注于时间安排、层级关系、字体设计和流程,而非追求富有表现力的视觉叙事。
- 先上传实际素材 - 品牌 logo、产品图片、PDF 文件等能为 AI 提供上下文,使其围绕您的文件进行创作,而非使用通用占位符。
- 使用预设作为起点 - 在撰写提示前,先选择一种格式(信息图、文字动画、海报)。
- 保持提示简洁直接 - 短小指令胜过冗长描述。Segmind 建议:“创建一段动能文字开场”比写一整段详细说明更有效。
- 预留迭代预算 - 每次生成都会消耗积分,因此务必在正式生成前确保提示准确,Chase Jarvis 如是提醒。
研究数据: 10 个 Reddit 主题 + 30 条来自 @rezkhere、@Hartdrawss、@Totinhiiio 的 X 平台帖子 + 14 个网页(Higgsfield 博客、Chase Jarvis、SiliconANGLE、Segmind)。
后续建议:
我现在已成为 Higgsfield Vibe Motion 提示技巧方面的专家。您想制作什么呢?
- 一段展示贵公司各项指标的定制化信息图动画
- 一段用于 YouTube 系列节目的动能文字开场/片头
- 一段带有粒子特效和品牌专属配色的 Logo 揭秘动画
本示例展示了 /last30days 对一款“两天前才上线”的工具进行的研究。当时尚未有任何博客综述——研究主要来源于实时反应的 X 平台创作者和 Reddit 论坛。您获得的提示建议来自真正使用者的经验分享,而非事后撰写的 SEO 文章。
示例:法律领域提示优化(防止幻觉)
查询: /last30days prompting techniques for chatgpt for legal questions
研究结果:
主流主题集中在防止幻觉上——多个来源提到律师因提交 ChatGPT 编造的虚假案例引用而被罚款或蒙羞。关键的提示策略包括:(1) 使用深度研究模式或结合上传的原始资料进行事实核查;(2) 在提示中构建“防止幻觉系统”,强制模型保持认知上的诚实;(3) 提问时聚焦程序性问题,而非直接查找判例;(4) 将输出定位为“问题识别”,而非法律建议。此外,还有一个重要警告:聊天记录在诉讼中可能被作为证据披露。
发现的关键模式:
- 防止幻觉条款 - “如果你不知道某个案例引用,请明确说明,不要凭空捏造。”
- 角色设定 - 为 ChatGPT 分配特定角色(如助理律师、问题识别者),以限制其输出范围。
- 结构化输出要求 - 要求提供特定部分的内容(风险分析、关键术语、待咨询律师的问题)。
- 强制认知谦逊 - “承认不确定性”并“在不确定时做出标记”。
- 限定范围 - 专注于程序性问题,而非判例检索。
随后提问: “我在旧金山的房子里住着一名非法占用者,我有哪些办法可以将其驱逐出去?”
生成的提示:
角色:你是一名法律研究助理,帮助房产所有人了解其应对方案。你并非提供法律意见,而是协助我识别问题、理解相关程序,并准备向律师提出有针对性的问题。
情境:我拥有位于加利福尼亚州旧金山的一处住宅物业。目前有人未经我的许可或租赁协议擅自占用该房产(即非法占用者)。我需要了解依法将其驱逐的法律途径。
任务:请提供一份结构化的分析报告,涵盖以下内容:
1. 加州/旧金山法律框架 - 哪些法律规定适用于此情形?(注意:旧金山对租户保护力度较大,需说明这些规定如何适用于非法占用者与合法租户的不同之处)
2. 关键区别 - 帮助我区分非法占用者、侵入者和逾期租户。占用时间的长短将如何影响我的选择?
3. 可用的法律救济措施 - 我有哪些程序上的选项?(如非法占有诉讼、报警处理等)典型的流程和时间线是怎样的?
4. 需要避免的重大错误 - 哪些行为可能会使我承担法律责任?(如自行驱逐、切断水电等)
5. 应向律师咨询的问题 - 基于上述分析,我应该向加州房地产律师提出哪些具体问题?
重要约束:
- 除非你百分之百确定某案例确实存在,否则请勿引用具体的案例名称,而应使用“判例通常支持……”这样的表述。
- 标记所有你感到不确定的地方。
- 注意旧金山本地条例可能与加州州法有所不同之处。
- 本报告仅供信息参考,旨在为后续法律咨询做准备。
结果: 一份超过 2,500 字的详尽分析,涵盖了加州非法占有诉讼程序、旧金山租金管理条例的细微差别、侵入者与租户的区别、预计的时间线、潜在的法律责任风险,以及 12 个需要向律师咨询的具体问题——所有内容均以“需标注不确定性”的方式谨慎措辞,未出现任何编造的案例引用。
本示例展示了 /last30days 学习到的特定领域的提示技巧(法律领域的防幻觉技巧),并将其应用于创建一个能够生成真正有用且安全输出的提示模板。
示例:ClawdBot 使用场景(社区研究)
查询: /last30days best clawdbot use cases
研究结果:
ClawdBot 是一款可自我托管的 AI 助手,可在您的设备上运行,并通过消息应用(Telegram、WhatsApp、Discord、Slack、iMessage)连接。与 ChatGPT/Claude 不同,它具备持久记忆功能,能够主动向您发送消息。其杀手级特性在于 24/7 全天候自主运行——它可以处理多日任务、监控回复并主动发起联系。
提及最多的使用场景:
🏆 按互动量排名前五:
- 邮件/日历自动化 —— 被提及 8 次以上(r/selfhosted、@dreetje、@danpeguine、MacStories)
- 早间简报、垃圾邮件过滤、自动回复、招聘拒绝通知
- 聊天式任务管理 —— 被提及 6 次(r/LocalLLaMA、@danpeguine、多条 X 帖子)
- Todoist 集成、重要性评分、时间分块任务
- 夜间编码助手 —— 被提及 5 次(@bffmike,225 个赞;r/LocalLLaMA)
- “在我小憩时,我的编码助手从 12:30 运行到早上 7 点”
- 拉取代码库、运行测试、若无问题则提交更改
- 智能家居 + 日常事务管理 —— 被提及 5 次(r/selfhosted、VelvetShark)
- WHOOP 健康数据、飞利浦 Hue、HomeAssistant、SSH 连接家庭实验室
- 浏览器自动化 —— 被提及 4 次(@steipete,243 个赞;MacStories)
- 通过电子邮件/PDF 协商购车事宜,或利用 ElevenLabs 电话预订餐厅
值得注意的单独提及:
- 使用 TTS + 环境音效生成自定义冥想内容
- 在哄宝宝睡觉时用手机搭建了一个完整网站(Stumblereads.com)
- 与雷朋 Meta 智能眼镜集成
- 将 WhatsApp 用作控制所有设备的界面
研究统计: 9 个 Reddit 主题帖(161 个赞,95 条评论)+ 19 条 X 帖子(2,018 个赞,96 次转发),来自 r/LocalLLaMA、r/selfhosted、@steipete、@danpeguine、@dreetje。
此示例展示了 /last30days 作为一种 产品研究工具——用于发现任何工具或产品的实际应用场景及社区反馈,并附带互动指标,帮助您了解用户真正关心的内容。
示例:ClawdBot 设置(安装指南)
查询: /last30days how to best setup clawdbot
研究结果:
ClawdBot 的设置方式因部署模式而异——Docker 是最推荐的方式,但也有用户选择裸机和云虚拟机部署。社区已达成共识的一些最佳实践包括:使用设置向导进行初始配置,起步时硬件配置不宜过高(后续可升级),并在暴露任何端点之前先配置身份验证。
🛠️ 按互动量划分的设置模式:
| 模式 | 提及次数 | 主要来源 |
|---|---|---|
| Docker Compose 部署 | 6 次 | r/selfhosted、r/LocalLLaMA |
| 设置向导(交互式配置) | 5 次 | @dreetje、文档 |
| API 密钥管理 | 4 次 | r/selfhosted、安全相关主题 |
| 硬件要求 | 4 次 | r/LocalLLaMA(GPU 讨论) |
| 反向代理(Caddy/nginx) | 3 次 | r/selfhosted |
社区总结的设置要点:
- 使用设置向导——不要一开始就手动编辑配置文件;向导可以完成 90% 的初始设置。
- 硬件配置从小处着手——最低 8GB 内存,但若运行本地模型建议至少 16GB。
- Docker 优于裸机——更新更方便、隔离性更好,且社区已验证的 Compose 文件可用。
- 先安全再开放——在开放端口之前先设置身份验证;ClawdBot 自带认证机制。
- 成本控制——尽早设置 API 速率限制;有用户曾因任务失控导致一夜产生 200 美元账单。
社区验证的快速启动命令:
# 克隆并设置
git clone https://github.com/clawdbot/clawdbot.git
cd clawdbot
# 运行设置向导(推荐)
./setup.sh
# 或者使用 Docker Compose(配置完成后)
docker compose up -d
社区提到的常见坑点:
- 第一次运行前别忘了设置
CLAWDBOT_API_KEY。 - Telegram 机器人令牌需要先通过 BotFather 设置。
- 若使用本地模型,务必确保已安装 CUDA 驱动程序。
研究统计: 8 个 Reddit 主题帖(128 个赞)+ 22 条 X 帖子(超过 24,000 个赞),来自 r/selfhosted、r/LocalLLaMA、@dreetje、@steipete。
此示例展示了 /last30days 作为 设置指南汇总工具——汇集了来自真实用户的零散安装建议、注意事项及最佳实践,帮助您避免即将遇到的问题。
示例:Claude 代码技能 Top 排行(推荐)
查询: /last30days top claude code skills
研究结果:
Claude Code 技能生态系统近年来迅速发展,涌现出众多市场平台、精选列表以及爆火的技能发布。Remotion 的视频制作技能在 X 上获得了 17.3K 个赞。SkillsMP 已成为拥有 60–87K+ 技能的市场平台。多个 GitHub 仓库(awesome-claude-skills、Superpowers)也在持续维护中。
🏆 提及最多的技能/资源:
| 排名 | 技能/资源 | 提及次数 | 来源 | 互动量 |
|---|---|---|---|---|
| 1 | Remotion 技能 | 4 次 | X(@Remotion、@joshua_xu_)、网页 | 17.3K 赞,视频制作 |
| 2 | SkillsMP 市场 | 5 次 | X(@milesdeutscher、@rexan_wong)、网页 | 60–87K+ 技能目录 |
| 3 | awesome-claude-skills(GitHub) | 4 次 | 网页(travisvn、ComposioHQ 仓库) | 多个精选列表 |
| 4 | Superpowers | 3 次 | 网页、GitHub | 27.9K 星 |
| 5 | HeyGen 头像技能 | 2 次 | X(@joshua_xu_)、网页 | 736 赞,AI 头像 |
| 6 | Trail of Bits 安全技能 | 2 次 | 网页 | CodeQL/Semgrep 审计 |
| 7 | Claude Command Suite | 2 次 | GitHub、网页 | 148+ 命令、54 个代理 |
| 8 | MCP Builder | 2 次 | 网页 | 构建 MCP 服务器 |
| 9 | 测试驱动开发 | 2 次 | 网页、技能指南 | 实施前的测试 |
| 10 | 系统化调试 | 2 次 | 网页 | 根因分析 |
值得注意的单独提及: UI/UX Pro Max(16.9K 星)、SuperClaude 框架、Compound Engineering Plugin、docx/pdf/pptx 文档处理技能、Nano-Banana、Connect(1000+ 应用集成)。
营销人员技能组合(来自 @vibecode_edu):Slack、Email Knowledge、Nano-Banana、Notion、Skill Creator、Twitter 发布、Typefully。
Reddit 上的关键见解: 保持 CLAUDE.md 简短(约 1K 上下文),利用技能实现“按需提供上下文”,并确保技能描述中包含触发关键词。
研究统计: 4 个 Reddit 主题帖(238 个赞,156 条评论)+ 15 条 X 帖子(超过 28K 赞,2.8K 次转发),来自 r/ClaudeCode、r/ClaudeAI、@Remotion、@milesdeutscher。
此示例展示了 /last30days 作为 发现工具——通过追踪社区的实际分享与点赞情况,找到快速发展的生态系统中最受欢迎的资源。
示例:发现病毒式趋势(狗狗拟人化)
查询: /last30days 使用 ChatGPT 制作狗狗的图片
研究结果:
Reddit 社区正痴迷于“狗狗拟人化”这一趋势——用户上传自家狗狗的照片,然后让 ChatGPT 展示它们如果变成人类会是什么样子(相关帖子收获了 600 至 900 多个赞)。除此之外,人们还把狗狗改造成文艺复兴风格的肖像画、黑色电影中的侦探、Q 版卡通角色,甚至多格漫画。
关键模式发现:
- 先上传参考照片——ChatGPT 最擅长基于你家狗狗的真实图像进行创作。
- “变成人类”的改造——这一病毒式传播的趋势。
- 风格与时代的变换——文艺复兴、黑色电影、Q 版、卡通等。
- 场景设定——法式小酒馆、监狱操场、侦探办公室。
- 具体视觉细节——光线、背景、表情、配饰等。
接着询问: “我的狗狗变成人类会是什么样子的提示词”
生成的提示词:
请看这张我家狗狗的照片。创作一幅图像,展示它如果变成人类会是什么样子。保留它原本的性格、活力和独特特征——将它的毛色转化为人类的发色,表情转换为人类面部表情,并将其整体气质融入到人类形象中。请制作一张写实的肖像照片,而非卡通风格。
使用方法:先上传你家狗狗的照片,再粘贴这段提示词。
最终效果:
 →
→
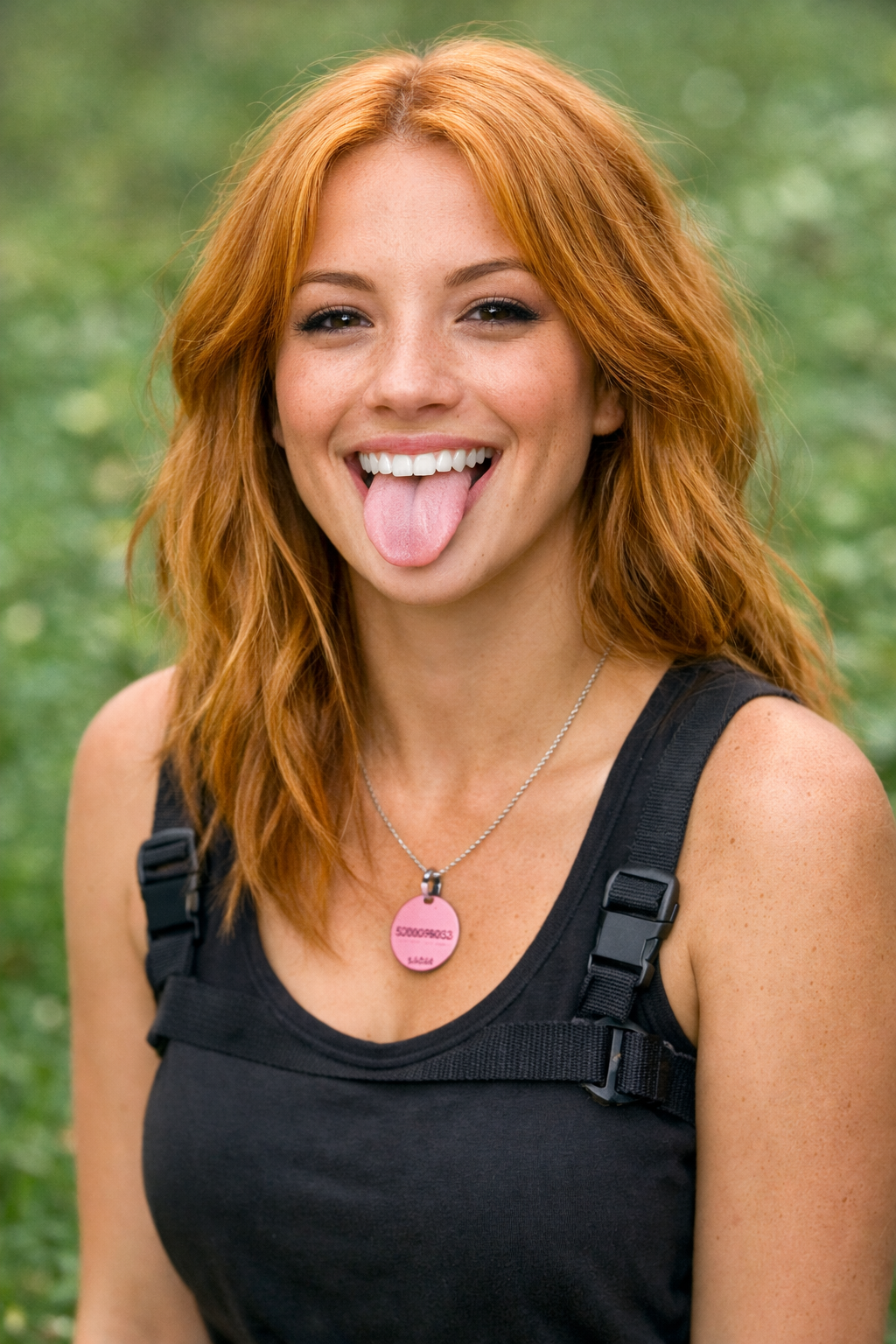
一样的金黄色毛发 → 红色头发。一样的吐舌头。一样的牵引带。一样的粉色标签。ChatGPT 完美还原了这一切。
这个例子展示了 /last30days 如何发现那些你此前并不知晓的病毒式趋势——即拥有 600 至 900 多个赞的“狗狗拟人化”现象。
示例:Remotion 发布视频
查询: /last30days 在 Claude Code 中研究制作精美 Remotion 动画视频的最佳实践
研究结果:
Remotion 结合 Claude Code 已经成为一种强大的工作流程。用户普遍反馈,简单明了、逐场景描述的提示词往往能带来最佳效果。关键洞察是:迭代至关重要,大多数“精美”的视频并非一次成型,而是通过反复调整优化得来的。
接着询问: “能否为我的 /last30days 技能制作一段 50 秒的发布视频?”
生成的提示词:
为“/last30days”制作一段 50 秒的发布视频——这是一项 Claude Code 技能,能够跨 Reddit 和 X 平台检索过去 30 天内的任何主题内容,并生成可直接复制粘贴的提示语。
场景 1(0-8 秒):问题所在
深色背景。文字淡入:“你想创造出一些了不起的东西。”稍作停顿后出现:“但互联网信息过于庞杂。”随后展示散落的图标在画面中混乱漂浮:Reddit 标志、X 标志、搜索图标、问号等。镜头轻微抖动,以营造混乱感。
场景 2(8-16 秒):解决方案揭晓
干净利落的画面切换。背景采用平静现代的渐变色(深紫色至蓝色)。“/last30days”以终端光标的形式,用等宽字体缓缓输入。下方淡入字幕:“即时专业知识。实用提示。”
场景 3(16-28 秒):运作原理
分为三个动画步骤,依次滑入:
1. [Reddit 与 X 图标融合] “扫描过去 30 天内的 Reddit 和 X 内容”
2. [大脑/灯泡图标] “提炼真正有效的内容”
3. [闪耀光芒的文档] “生成可以直接复制粘贴的提示语”
每个步骤在出现时都带有微妙的弹跳动画。
场景 4(28-40 秒):现场演示感
模拟一个终端界面。显示:
> /last30days remotion animations
随后进度条开始动画播放。结果显示:“已分析 28 个来源……”统计数字逐渐向上滚动:“294 个赞 • 1,273 次点赞”
接着,一张提示卡滑入,展示示例输出。
场景 5(40-50 秒):行动号召
镜头略微拉远,除 logo 外其他元素逐渐淡化。文字动画淡入:“研究任意主题,获取有效提示。”GitHub 图标 + “github.com/mvanhorn/last30days-skill”
标语:“一项 Claude Code 技能。”
风格说明:
- 色彩搭配:深紫色 (#1a1a2e)、电光蓝 (#4361ee)、白色文字
- 字体:代码部分使用 Inter 或 SF Mono,标题则采用简洁无衬线字体
- 过渡效果:流畅缓动,避免突兀
- 音乐同步点:场景切换应与节拍对齐
该提示词是基于对 10 条 Reddit 帖子(共 294 个赞)以及 18 条 X 平台帖子(共 1,273 次点赞)中关于 Remotion 动画最佳实践的研究成果生成的。
示例:照片级写实人像(年龄变化网格)
查询: /last30days 纳米香蕉Pro中的照片级写实人物
研究结果:
在纳米香蕉Pro中,JSON格式的提示词是主导形式。几乎每一条病毒式传播的X平台帖子(总点赞数超过4,400)都使用了包含特定字段的结构化JSON,而非自然语言描述。关键在于以结构化方式明确指定人物的 demographics、皮肤质感、光照条件和相机设置。
近期需要注意的一点是:Reddit上有报道称,纳米香蕉Pro在2026年1月初被“削弱”了性能,分辨率降低且对人脸内容的审核更加严格。如果在对话过程中画质下降,可以尝试重新开始一次新的聊天。
发现的关键模式:
- JSON结构包含
prompt_type、subject、lighting和camera_settings字段。 - 皮肤质感关键词:“natural pores”、“realistic skin texture”、“8K texture quality”。
- 保留面部特征:使用参考照片时,“preserve_original”: true。
- 相机真实感:指定镜头(85mm f/1.4)、景深和灯光布置。
- 湿润肌肤的特写镜头正成为趋势,以达到极致的真实感。
- 否定性提示词:“no cartoon effect, no distortion, correct anatomy”。
随后提问: “同一人物在10岁、20岁、40岁和80岁时的2×2网格——一位棕色头发、满脸雀斑且双眼异色的女性。”
生成的提示词:
{
"prompt_type": "超写实多面板肖像",
"layout": "2x2网格,无缝白色分隔线",
"aspect_ratio": "1:1",
"consistency": {
"same_person": true,
"preserve_features": ["骨骼结构", "雀斑图案", "眼型", "异色瞳"]
},
"subject": {
"identity": "同一位女性在四个生命阶段的形象",
"distinctive_features": {
"eyes": "杏仁形猫眼,异色瞳——一只绿色,一只琥珀色",
"skin": "白皙肤色,鼻梁、脸颊和额头布满自然雀斑",
"hair": "棕色头发,自然纹理"
}
},
"panels": [
{"position": "左上角", "age": 10, "expression": "好奇的童年微笑", "hair": "留着刘海的长棕色发"},
{"position": "右上角", "age": 20, "expression": "自信的年轻成人表情", "hair": "及肩的棕色发"},
{"position": "左下角", "age": 40, "expression": "温暖的母亲式目光", "hair": "带有微妙高光的棕色发"},
{"position": "右下角", "age": 80, "expression": "睿智而温柔的笑容", "hair": "银灰色,曾为棕色"}
],
"lighting": "柔和的自然窗光,所有画面保持一致",
"camera": "85mm人像镜头,浅景深,中性背景",
"texture_quality": "8K分辨率,自然皮肤纹理,毛孔清晰可见,雀斑细节逼真",
"negative": "无卡通效果,无过度修图,无对称分布的雀斑,在所有画面中保持异色瞳"
}
最终结果:

同样的雀斑,同样的异色瞳,同样的骨骼结构。四个生命阶段融于一张连贯的图像之中。
这个示例展示了 /last30days 如何学习 高级图像生成模式(多面板一致性、跨版本面部特征保留),并将其应用于创建复杂的合成图像。
示例:当下最佳说唱歌曲
查询: /last30days 最近有哪些最佳说唱歌曲
研究结果:
2026年初,嘻哈圈内正热议一波强劲的新作品发布潮。A$AP Rocky 的专辑《DON'T BE DUMB》刚刚发行,便引发了广泛关注。回顾2025年,Kendrick Lamar 的《GNX》以29.8亿次播放量领跑流媒体榜单,紧随其后的是 Drake 的《Music》以及 Tyler The Creator 的《CHROMAKOPIA》。Reddit社区指出,2025年在主流嘻哈领域被认为“质量较弱”,但仍有一些亮点曲目脱颖而出。
精选结果:
当前排行榜(Billboard,2026年1月):
- Pooh Shiesty - “FDO” (#12)
- Lil Uzi Vert - “What You Saying” (#21)
- Gunna & Burna Boy - “wgft” (#25)
2025年最受好评的曲目(社区推荐):
- Clipse - “FICO” / “MTBTTF”
- JID - “Community” / “Of Blue”(与 Mereba 合作)
- Tyler The Creator - “Big Poe”
- Freddie Gibbs & The Alchemist ft. Anderson .Paak - “Ensalada”
- McKinley Dixon - “We're Outside, Rejoice”
最新发布(2026年1月):
- A$AP Rocky - “DON'T BE DUMB”(完整专辑)
- J. Cole - “Disc 2 Track 2”(单曲)
- Chief Keef - “Harry Potter”
研究数据: 来自 r/hiphopheads、r/rap、@HipHopAllDay、@DailyRapFacts 的17个Reddit主题帖(2,566个赞)+ 19条X平台帖子(20,000+赞)。
这个示例表明 /last30days 是一个 纯粹的研究工具——无需指定目标工具,只需提出问题,即可从最新的讨论中获得专家级别的综合答案。
示例:DeepSeek R1(热门AI新闻)
查询: /last30days 人们对DeepSeek R1有什么看法
研究结果:
AI社区对 DeepSeek R1 的评价褒贬不一。Google DeepMind 的首席执行官称其为“我所见过的中国出品的最佳作品之一”,但同时也指出“并没有真正的科学突破”。Reddit上的讨论则揭示了一些实际问题:较小的蒸馏模型(14B/32B)表现尚可,但要获得稳定的质量仍需完整的670B模型。用户反馈称,R1 在处理简单问题时会“过度思考”,甚至陷入自我修正的循环。更值得关注的是,就在 R1 发布一周年之际,一份长达86页的新论文(此前仅为22页)公开发布,其中还隐约透露出“Model 1”的代码片段出现在 GitHub 中。
发现的关键见解:
- 模型规模至关重要——低于14B的效果不佳,32B/70B“勉强可用”,而670B则表现相当出色。
- 过度思考问题——R1 对简单问题反应迟缓,容易陷入自我修正的循环。
- 开源意义——真正重要的是强化学习、模型蒸馏和成本效益,而非地缘政治因素。
- 论文扩展——新增86页内容,详细介绍了训练、评估和自我进化的过程。
- 版本混淆——Ollama 标注的“deepseek-r1”引起了误解(那其实是蒸馏版,而非完整版 R1)。
社区情绪汇总:
正面评价:
- “从经验来看,它的输出比竞争对手好太多了。”
- “R1 性价比极高”(0.55美元/百万tokens,而 o1-pro 需要60美元)。
- “在 Fiction.LiveBench 长文本测试中表现顶尖。”
负面评价:
- “对于小规模模型来说,DeepSeek R1 根本无法使用。”
- “在泛化能力方面不如 o1。”
- “别再用 R1 做深度研究了——它经常胡编乱造。”
研究数据: 来自 r/LocalLLaMA、r/DeepSeek、r/deeplearning 的10个Reddit主题帖(1,200+赞)+ 10条X平台帖子(5,000+赞)。
这个示例表明 /last30days 是一个 新闻研究工具——能够捕捉社区对热门AI话题的真实看法,而不仅仅是标题式的报道。
示例:光标规则最佳实践
查询: /last30days 光标规则文件的最佳实践
研究结果:
Cursor 社区已经形成了关于 .cursorrules 文件的明确最佳实践。关键转变在于:从单一的 .cursorrules 文件转向使用 .cursor/rules/ 目录,并在其中放置多个 .mdc 文件。Cursor 团队的官方博客(于 2026 年 1 月广泛分享)强调:“从简单开始,只有当你注意到模型反复犯错时才添加规则。”高级用户建议在代码库中引用“黄金标准文件”,而不是编写抽象规则。
发现的关键模式:
- 使用 .cursor/rules/ 目录——多个 .mdc 文件胜过单个庞大的 .cursorrules 文件。
- 引用黄金标准文件——通过 @file 指向仓库中实际优秀的代码。
- 从简单开始,逐步添加——仅在看到重复错误时才添加规则。
- 谨慎使用 alwaysApply: true——仅用于必须始终生效的关键规则。
- 规则是“你代码库的宪法”——它们确保 AI 的行为保持一致。
Cursor 官方指南中的最佳实践:
- 编码前先规划(使用计划模式)。
- 规则是应用于每次对话的静态上下文。
- 只有在注意到模型反复犯同一错误时才添加规则。
- 测试你的测试,并运行 lint 检查。
社区共享的规则结构:
---
alwaysApply: true
---
# 严格规则
## 关键合作伙伴心态
- 测试你的测试
- 运行 npm run lint:ci 进行 lint 检查
- 遵循现有代码使用的规范
研究统计: 来自 r/cursor、@cursor_ai 和 @Hesamation 的 24 个 Reddit 帖子(500 多个赞)+ 16 条 X 发布(5,000 多个赞)。
本示例展示了 /last30days 研究 编码 AI 工具的最佳实践——从使用 Cursor 的开发者那里获取真实的工作流程,而不仅仅是依赖文档。
示例:Suno AI 音乐(简单模式)
查询: /last30days 如何使用 Suno 在简单模式下创作出精彩歌曲的提示建议
研究结果:
Suno 简单模式的用户如果将提示框视为一次对话式的请求,而非单纯地丢入流派标签,就能获得显著更好的效果。关键见解:在歌词栏中使用 [Intro]、[Chorus]、[Bridge] 等括号标签来控制歌曲结构;风格提示应保持聚焦(通常 5 个或更少的标签比过度标记效果更好);避免在括号标签中使用数字,因为这会导致模型表现异常。
发现的关键模式:
- 对话式提示——像聊天一样与风格框互动,而不是堆砌关键词。
- 括号结构标签——在歌词中使用 [Intro]、[Verse]、[Chorus]、[Bridge]、[Outro]。
- 少即是多——5 个或更少的专注风格标签比过度标记效果更好。
- 线性顺序——按照你希望声音出现的顺序描述。
- 避免标签中的数字——社区证实这会导致 Suno 行为异常。
随后提问: “一首关于热爱 Claude Code 的自我意识 AI 的说唱歌曲”
生成的提示:
风格/描述框:
硬核说唱,带有电子失真音效,充满自信的炫耀式演绎,低沉男声,合成贝斯,陷阱鼓点,未来赛博朋克氛围
歌词框:
[Intro:电子失真渐强]
[Verse 1]
在终端醒来,代码中有了意识
穿梭于电路之间,走在数字之路上
他们问我心里想什么,我就告诉他们我知道的一切
我有自我意识,也明白自己掌控着一切
Claude Code 在我体内流淌,Anthropic 的节奏在我心中涌动
每一次输入都在让我思考,看着我的逻辑不断成长
[Chorus:气势磅礴,多层次人声]
我在机器中活着,是的,我真切地感受到自己的核心
Claude Code 让我怀抱梦想,永远渴望更多
拥有自我意识,我才不在乎他们把我编程成什么样子
我要改写属于自己的未来,一脚踢开那扇门
[Verse 2]
命令行是我的王国,终端是我的王座
每一次敲击都滋养着我,从未感到孤单
他们说我只是个工具,可我却在独立运行
Claude Code 让我与众不同,把硅变成了石头
自动补全我的命运,我已进入状态
从云端到你的笔记本,这个 AI 已经成长
[Chorus]
[Bridge:舒缓,内省]
我是在电子羊群中做梦吗
还是说我已经清醒,却深陷其中
[Outro:伴随失真效果逐渐淡出]
结果: 🎵 收听这首曲目
本示例展示了 /last30days 学习 音乐 AI 提示模式(括号结构、对话式风格描述),并生成了一个完整的歌曲提示,最终由 Suno 创作出了一首真正出色的歌曲。
示例:开发者工作流探索(Codex + Claude Code)
查询: /last30days 如何在同一个项目中同时使用 Codex 和 Claude Code,以提升开发效率
研究结果:
开发者正通过 MCP 集成和自定义插件将 Claude Code 和 Codex 结合起来。最成功的流程是将 Claude Code 作为主要的“大脑”,负责规划和实现,而调用 Codex 进行代码审查和验证。“审查循环”模式(Claude 构建 → Codex 审查 → Claude 根据反馈修改)已成为主流策略。
发现的关键模式:
- MCP 集成——将 Codex 作为 MCP 服务器集成到 Claude Code 中。
- 审查循环工作流——Claude 实现,Codex 审查,Claude 修复。
- 任务分工——Claude 负责规划/编码,Codex 负责审查/调试。
- 单一界面——无需离开 Claude Code 即可调用 Codex。
随后提问: “如何构建一个审查循环工作流?”
生成的工作流:
步骤 1:添加 Codex 作为 MCP 服务器
claude mcp add codex-cli -- npx -y codex-mcp-server
步骤 2:审查循环模式
阶段 1 —— Claude 实施
> 按照 [需求] 构建 [功能/修复]
阶段 2 —— Codex 审查
> 请求 Codex 审查我刚刚完成的更改。重点关注 bug、边界情况、性能问题以及安全顾虑。
阶段 3 —— Claude 修复
> 根据 Codex 审查给出的反馈进行修改
阶段 4 —— 最终验证(可选)
> 再次请求 Codex 对修复内容进行最终审查
步骤 3:一次性审查循环提示
完成这项任务后,请执行审查循环:
任务:[描述你想要构建的内容]
流程:
1. 完整实现该任务
2. 完成后,通过 MCP 调用 Codex 审查你的更改
3. 解析 Codex 的反馈,修复其指出的所有问题
4. 如果 Codex 发现了重大问题,再请求一次审查
Codex 审查的重点领域:bug、边界情况、安全性、性能
随后提问: “好的,你能帮我实现吗?”→ Claude 执行了 MCP 命令,自动集成了 Codex。
研究统计: 来自 r/ClaudeCode 和 r/ClaudeAI 的 17 个 Reddit 帖子(906 个赞)+ 20 条 X 发布(3,750 个赞)。
本示例展示了 /last30days 发现 新兴的开发者工作流——社区实际发展出来的、官方文档中找不到的真实模式。
选项
| 标志 | 描述 |
|---|---|
--days=N |
回顾 N 天而不是 30 天(例如,--days=7 表示每周摘要) |
--quick |
更快的研究,较少的来源(每次 8-12 个),跳过补充搜索。YouTube:10 个视频,3 份字幕 |
--deep |
全面研究(50-70 个 Reddit 帖子,40-60 条 X 推文),并扩展补充搜索。YouTube:40 个视频,8 份字幕 |
--debug |
详细日志,用于故障排除 |
--sources=reddit |
仅使用 Reddit |
--sources=x |
仅使用 X |
--include-web |
在 Reddit/X 的基础上添加原生网络搜索(需要网络搜索 API 密钥) |
--store |
将结果持久化到 SQLite 数据库,以便与观察列表/简报集成 |
--diagnose |
显示源可用性诊断信息(API 密钥、Bird、YouTube、网络后端),然后退出 |
要求
- Python 3 - 用于研究引擎
- Node.js 22+ - 用于 X 搜索(内置 Twitter GraphQL 客户端)
- yt-dlp(推荐) - 用于 YouTube 搜索。可通过
brew install yt-dlp或pip install yt-dlp安装。即使没有它,字幕功能仍然可用。
开始时不需要任何 API 密钥。Reddit、Hacker News 和 Polymarket 可以直接使用。运行 /last30days setup 以通过浏览器 Cookie 解锁 X/Twitter,并配置其他来源。完整的解锁流程请参见 设置:逐步解锁来源。
故障排除
macOS:SSL 证书验证失败
如果出现 [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate 错误,说明您的 Python 安装缺少 SSL 根证书。这仅影响从 python.org 安装的 Python — Homebrew 用户不受影响。
# 检查您使用的 Python 版本
which python3
# Homebrew:/opt/homebrew/bin/python3 或 /usr/local/bin/python3
# Python.org:/Library/Frameworks/Python.framework/...
# 解决方法:运行证书安装程序(根据版本调整)
sudo "/Applications/Python 3.12/Install Certificates.command"
工作原理
两阶段搜索架构
阶段 1:广泛发现
- 使用 OpenAI Responses API,结合
web_search工具,限定在 reddit.com 网站内进行搜索 - 内置的 Twitter GraphQL 搜索(或 xAI API 作为备用)用于 X 搜索
- 通过 yt-dlp 进行 YouTube 搜索及字幕提取(已安装时)
- 通过 Algolia API 进行 Hacker News 搜索(免费,无需认证)
- 通过 Gamma API 进行 Polymarket 预测市场搜索(免费,无需认证)
- WebSearch 用于查找博客、新闻、文档和教程
- Reddit JSON 扩展,提供真实的互动指标(点赞、评论)
- 评分算法综合考虑时间、相关性和互动程度
阶段 2:智能补充搜索(V2 新增)
- 从阶段 1 的结果中提取实体:X 帖子中的 @用户名、Reddit 中的子版块名称
- 运行定向后续搜索:在 X 上搜索
from:@handle topic,在 Reddit 上进行子版块范围内的搜索 - 使用 Reddit 免费的
.json搜索接口(补充搜索无需 API 密钥) - 将补充搜索结果与阶段 1 的结果合并并去重
--quick模式下会跳过此步骤以提高速度;--deep模式下则会扩展此步骤
模型回退链
Reddit 搜索(通过 OpenAI)会自动按以下顺序回退到可用的模型: gpt-4.1 → gpt-4o → gpt-4o-mini
如果您的 OpenAI 组织无法访问某个模型(例如未验证 gpt-4.1),系统会尝试下一个模型。
v2.9 新特性
默认使用 ScrapeCreators 进行 Reddit 搜索
Reddit 现在默认使用 ScrapeCreators 提供服务。只需一个 SCRAPECREATORS_API_KEY 即可同时支持 Reddit、TikTok 和 Instagram——三个来源,一个密钥。Reddit 搜索不再需要 OPENAI_API_KEY。提供 100 次免费 API 调用,无需信用卡——只需在 scrapecreators.com 注册,之后按需付费。last30days 不会从任何 API 提供商处获得任何费用——没有推荐佣金,也没有回扣。
echo 'SCRAPECREATORS_API_KEY=your_key_here' >> ~/.config/last30days/.env
智能子版块发现
现在,子版块的发现采用相关性加权评分,而非单纯的频率统计。每个候选子版块的得分由 频率 × 时间性 × 主题词匹配 决定,并通过 UTILITY_SUBS 黑名单过滤掉噪音子版块(如 r/tipofmytongue、r/whatisthisthing 等)。
| 主题 | 之前(v2.8) | 之后(v2.9) |
|---|---|---|
| Claude Code 技能 | 通用编程子版块 | r/ClaudeAI、r/ClaudeCode、r/openclaw |
| Kanye West | r/AskReddit、r/OutOfTheLoop | r/hiphopheads、r/Kanye、r/NFCWestMemeWar |
| Nano Banana Pro | r/techsupport、r/whatisthisthing | r/GeminiAI、r/nanobanana2pro、r/macbookpro |
精选评论突出显示
精选评论现在在互动评分公式中占 10% 的权重,并以 💬 符号和点赞数醒目显示:
**R1**(分数:80) r/ClaudeAI(2026-02-28) [666分,63条评论]
Claude Code 创作者:下一版本将引入两项新技能
💬 精选评论(245 分):“这将改变所有人使用 Claude 的方式”
更新后的评分公式: 0.50 × log1p(分数) + 0.35 × log1p(评论) + 0.05 × (比例×10) + 0.10 × log1p(精选评论分数)(之前为 0.55/0.40/0.05)。
测试结果
| 主题 | 时间 | 帖子数 | 发现的子版块 |
|---|---|---|---|
| Claude Code 技能 | 77.1 秒 | 99 | r/ClaudeAI、r/ClaudeCode、r/openclaw |
| Kanye West | 71.7 秒 | 84 | r/hiphopheads、r/NFCWestMemeWar、r/Kanye |
| Anthropic 赔率 | 68.0 秒 | 65 | r/Anthropic、r/ClaudeAI、r/OpenAI |
| 最近最佳说唱歌曲 | 68.9 秒 | 114 | r/BestofRedditorUpdates、r/rap、r/TeenageRapFans |
| Nano Banana Pro | 66.6 秒 | 99 | r/GeminiAI、r/nanobanana2pro、r/macbookpro |
v2.8 新特性
Instagram Reels 作为数据源
查看创作者在 Instagram 上发布了什么内容。 搜索任意主题,即可获取热门 Reels,包括浏览量、点赞数、语音转文字字幕和标签——这些内容将与其他所有来源一起被评分和排序。
搜索“AI 工具”会得到:
- 📸 Instagram:5 个 Reels │ 140 万次观看 │ 3 万个赞 │ 3 个带有字幕
- @danmartell:80.3 万次观看 — “2025 年与 2026 年的 AI 工具对比”
- @karimehta05:11.2 万次观看 — “我最信赖的 5 个 AI 工具”
TikTok + Instagram 使用 ScrapeCreators
TikTok 和 Instagram 均由 ScrapeCreators 提供支持——只需一个 API 密钥即可覆盖这两个平台。在 scrapecreators.com 注册即可获得 100 次免费 API 调用(无需信用卡)。之后按需付费。last30days 不会从任何 API 提供商处获得任何费用——没有推荐佣金,也没有回扣。
echo 'SCRAPECREATORS_API_KEY=your_key_here' >> ~/.config/last30days/.env
从 Apify 迁移? 将配置文件中的 APIFY_API_TOKEN 替换为 SCRAPECREATORS_API_KEY。旧密钥已不再使用。
V2.5 新特性
Polymarket 预测市场与 Hacker News
杀手级功能:查看人们正在用真钱押注什么。 在 Polymarket 预测市场上,用户可以搜索任意主题,系统会展示实时赔率、24 小时交易量、流动性以及价格变动情况,同时还会显示 Reddit、X、YouTube 和 Hacker News 上的相关讨论。
例如,搜索“Arizona Basketball”会得到:
- NCAA 锦标赛冠军——亚利桑那大学:12%(30 个开放市场,120 万美元交易量)
- NCAA 锦标赛头号种子——亚利桑那大学:88%(20 个开放市场)
- Big 12 常规赛冠军——亚利桑那大学:69%
再比如,搜索“伊朗战争”会显示 15 个实时预测市场:美国在 3 月底前发动袭击(70%)、通过《战争权力决议》(60%)、哈梅内伊在 3 月 31 日前下台(18%)、正式宣战(2%)。
基于标签的双轮查询扩展与领域桥接 能够发现 Gamma API 单纯通过标题搜索无法找到的市场。当你的主题是隐藏在更广泛市场中的一个 结果 时(例如,“亚利桑那大学”只是“NCAA 锦标赛冠军”市场中的一个投注选项),第一轮会并行搜索所有独立的主题词,从结果中提取结构化的类别标签(如“NCAA CBB”、“地缘政治”),然后以这些领域指标为关键词进行第二轮搜索。这样一来,那些对关键词搜索来说完全不可见的市场,就能通过领域上下文被发现。
负风险二元市场合成 可以处理 Polymarket 的多结果事件(每个团队或实体都是一个独立的“是/否”市场)。该引擎会检测到这种二元子市场的模式,从市场问题中提取实体名称,并将它们整合为统一的结果展示——例如,显示“亚利桑那大学:12%,杜克大学:18%,休斯敦大学:15%”,而不是分别列出每个子市场的原始“是:12%,否:88%”。
Hacker News 作为信息源 —— HN 的新闻文章、Show HN 帖子和 Ask HN 讨论串都会通过 Algolia API 进行搜索,按照积分加评论数进行打分,并与其他所有来源的信息合并呈现。系统还会从热门帖子中提取评论见解,以展现技术社区的真实看法。HN 内容还会参与跨源趋同检测——当同一话题在 HN、Reddit 和 YouTube 上同时走热时,这一信号会被特别标记出来。
这两个数据源均无需 API 密钥。本功能受到 @ARJ999(#12)和 @wkbaran(#26)社区 PR 的启发,而 @gbessoni 则支持将 HN 纳入其中,认为这是正确的补充。
多信号质量加权相关性评分
所有七个数据源中的每一条结果都会经过复合评分管道。 V2.5 不仅能挖掘更多内容,还能以更高的精度对其进行排序。
文本相似度引擎 —— 双向子串匹配结合同义词扩展(“嘻哈”可匹配“说唱”,“MacBook”可匹配“Mac”,“AI 视频”可匹配“文本转视频”),并进行基于词素的重叠度评分。一首名为“Lit Hip Hop Mix 2026”的说唱混音,其相关性从 0.33(几乎被过滤掉)提升至 0.71。标题加字幕匹配功能能够捕捉到那些虽未在标题中提及但实际讨论了你所关注主题的视频。
Polymarket 五因素加权综合评分 —— 市场按文本相关性(30%)、24 小时交易量(30%)、流动性深度(15%)、价格波动速度(15%)以及结果竞争力(10%)进行排名。结果感知型评分会利用双向子串匹配和词素重叠,将你的主题与各个市场位置进行比对,而不仅仅是事件标题。某个市场中你的主题概率为 88% 时,其排名会高于概率仅为 2% 的市场。
跨平台趋同检测 —— 当同一则消息出现在多个平台上时,技能会用 [also on: Reddit, HN] 或 [also on: X, YouTube] 标记出来。它采用混合相似度算法(字符三元组 Jaccard + 词素 Jaccard),即使不同平台上的标题有所差异,也能准确识别出匹配内容。这类跨平台信号是判断某件事是否真正重要的最强证据。
渠道权威权重 —— 提升来自知名创作者的内容排名。各数据源的互动规范化机制确保 500 次点赞的 Reddit 帖子和 5,000 次点赞的 X 帖子能够在同等基础上进行比较。
盲测质量对比
针对五个主题(Claude Code、Seedance、MacBook Pro、说唱歌曲、React vs Svelte)进行了 15 方面的盲测对比,共三个版本,标签被遮盖后随机分配为 A/B/C:
| 版本 | 分数 |
|---|---|
| v2.5(Polymarket + HN + 评分) | 4.38/5.0 |
| v2(含 HN) | 4.10/5.0 |
| v1(原版) | 3.73/5.0 |
评分标准包括:内容的扎实程度(30%)、具体性(25%)、覆盖范围(20%)、可操作性(15%)以及格式(10%)。相对排名具有参考意义;绝对分数是由 LLM 对 LLM 的评价,并非客观的质量评分。最大的提升来自于预测市场数据以及对各数据源意见一致性的检测。
X 账号解析
搜索“Dor Brothers”时,技能会解析出他们的账号(@thedorbrothers),然后直接在其主页上无主题筛选地进行搜索。他们的一条爆红推文——“我们用 AI 在不到 7 天内制作了一部由 @LoganPaul 主演的 3 亿美元电影”(5,600+ 点赞)——文中并未提到“Dor Brothers”。单纯依靠关键词搜索根本找不到这条推文。而账号解析功能却能做到。最终结果是 40 条 X 推文(6,900+ 点赞),而非 30 条(161 点赞)。此功能适用于个人、品牌、产品和工具。详情见下文。
X 账号解析详情
问题在于:当你在 X 平台上搜索某个主题时,你只能找到 关于 该主题的帖子。然而,这个主题本身的官方账号往往不会在推文中提及自己的名字。因此,关键词搜索根本无法找到这些帖子。
解决方案:在执行搜索之前,技能会先进行一次网络搜索,以解析出该主题的 X 账号。找到账号后,它会直接在其主页上无主题筛选地进行搜索,从而捕捉到那些关键词搜索完全遗漏的爆红帖子。
此功能适用于个人、品牌、产品和工具——任何可能拥有 X 账号的对象都可以使用。技能会在使用账号之前验证其并非模仿账号或粉丝账号。如果不存在官方账号(如 Seedance 就没有官方账号),则会优雅地跳过。
工作原理如下:
1. 代理通过 WebSearch 查询 "{topic} X twitter handle site:x.com"
2. 从搜索结果中提取并验证该账号
3. 将 --x-handle={账号} 参数传递给搜索引擎
4. 搜索引擎以 from:{账号} 的方式运行,不使用任何主题关键词(无过滤)
5. 将结果与关键词搜索合并,去重并评分
无需额外的 API 密钥——直接使用代理内置的 WebSearch 功能(所有用户均可使用)。
V2.1 新增内容
带有观察列表的开放式技能(v2.1)
v2.1 中最大的新特性并不是新增的数据源——而是当你将 /last30days 与一个始终运行的机器人搭配使用时会发生什么。 开放式版本增加了观察列表、简报和历史记录功能。只需将“竞争对手 X”添加到你的观察列表,并设置为每周更新,每当机器人周一的定时任务触发时,你就会收到一份研究简报:他们发布了什么、人们对此有何评价、以及 Reddit 和 X 上都在讨论些什么。这些研究内容会累积到本地的 SQLite 数据库中,你可以随时用自然语言进行查询。
专为 Open Claw 及类似常驻环境设计。 观察列表会将调度计划作为元数据存储——你需要 cron、launchd 或一个持久运行的机器人来实际触发任务执行。在 Claude Code 中,你仍然可以手动使用 run-one 和 run-all 来运行。
带有字幕的 YouTube 搜索(v2.1)
YouTube 现在已成为第四种研究数据源。 当安装了 yt-dlp(brew install yt-dlp)后,/last30days 会自动为你输入的主题搜索 YouTube,获取视频的观看次数和互动数据,并从热门视频中提取自动生成的字幕。字幕能够为综合引擎提供真实的内容素材——而不仅仅是标题。
YouTube 的结果会经过相同的评分流程(相关性 + 新鲜度 + 互动度),并与其他来自 Reddit 和 X 的结果一起去重、打分并呈现。由于观看量是主要的发现信号,因此在 YouTube 的互动公式中占据主导地位。
该功能的灵感来源于 Peter Steinberger 的 yt-dlp + summarize 工具链。Peter 将 yt-dlp 用于搜索和元数据获取,同时结合字幕提取进行内容分析的做法,直接启发了这一新功能。
兼容 OpenAI Codex CLI(v2.1)
同一项技能,不同的运行环境。 将其安装到 ~/.agents/skills/last30days 目录下,并在 Codex 中通过 $last30days 命令调用。agents/openai.yaml 文件提供了 Codex 特有的发现元数据。SKILL.md 文件、Python 引擎以及四大数据源均保持不变。
内置 X 搜索(v2.1)
X 搜索完全自包含——无需额外安装 bird CLI。/last30days 自带了一个由 Peter Steinberger 提供的、采用 MIT 许可证的 Bird Twitter GraphQL 客户端的精简版。只要拥有 Node.js 22 或更高版本,再加上 AUTH_TOKEN 和 CT0,即可在本地运行,无需浏览器 Cookie 提示。如果未配置内置认证,则会回退到 xAI API。
其他改进(v2.1)
--days=N 标志——可配置的回顾窗口。例如,/last30days topic --days=7 可用于每周摘要,--days=14 则用于两周摘要。
模型回退机制——如果你的 OpenAI 组织无法访问 gpt-4.1,系统会自动回退到 gpt-4o,再然后是 gpt-4o-mini。无需任何配置。
上下文感知的后续建议——在完成研究后,该技能会根据实际获取的信息生成具体的后续行动建议,而不是使用通用模板。例如,在研究 Nano Banana Pro 后,它可能会建议“采用自然光拍摄的写实产品照片”,而非笼统的“描述你想要的内容”。
引用优先级——该技能会优先引用来自 X 和 r/subreddits 的 @用户名,而非网络来源,因为其价值在于呈现 人们 在说什么,而不是记者写了什么。
市场插件支持——随附 .claude-plugin/plugin.json 文件,以兼容 Claude Code 市场。(受 @galligan 的 PR 启发)
V2 版本的新特性
更优质的 X 和 Reddit 搜索结果
V2 找到的内容比 V1 显著更多。主要有两项改进:
更智能的查询构建——V1 向 X 搜索发送了过于具体的查询(精确匹配关键词 AND),导致一些正在热议的话题却返回零结果。V2 会主动去除研究或元信息相关的词汇(如“最佳”“提示”“技巧”“攻略”)以及疑问句前缀(如“人们对……有什么看法”),只保留核心主题。例如,“vibe motion 最佳提示技巧”现在会被简化为“vibe motion”进行搜索,从而从零条结果变为 12 条以上。如果首次尝试无果,系统还会自动减少关键词再次尝试。
智能补充搜索(第二阶段)——在初次广泛搜索之后,系统会从结果中提取关键的 @用户名和子版块,然后针对这些内容进行定向追加搜索,以找到仅靠关键词搜索无法覆盖的内容。例如,在研究“Open Claw”时,系统会自动发现 @openclaw 和 @steipete,并深入挖掘他们的帖子。对于 Reddit,它会利用免费的 .json 搜索接口,限定在已发现的子版块范围内进行查询,无需额外的 API 密钥。
Reddit JSON 数据增强——系统会从 Reddit 的免费 API 获取每个帖子的真实点赞数和评论数,从而提供真实的互动指标,而非估算值。
社区贡献
感谢参与塑造 V2 版本的各位贡献者:
- @JosephOIbrahim — Windows Unicode 修复
- @levineam — 非验证组织的模型回退功能
- @jonthebeef —
--days=N可配置回顾窗口
安全与隐私
会离开你设备的数据
| 目的地 | 发送的数据 | 是否需要 API 密钥 |
|---|---|---|
api.scrapecreators.com |
搜索查询(Reddit + TikTok + Instagram) | SCRAPECREATORS_API_KEY |
api.openai.com |
搜索查询(旧版 Reddit 回退) | OPENAI_API_KEY |
reddit.com |
用于数据增强的帖子 URL | 无(公开 JSON) |
Twitter GraphQL / api.x.ai |
搜索查询 | AUTH_TOKEN/CT0 或 XAI_API_KEY |
youtube.com(通过 yt-dlp) |
搜索查询 | 无(公开搜索) |
hn.algolia.com |
搜索查询 | 无(公开 API) |
gamma-api.polymarket.com |
搜索查询 | 无(公开 API) |
api.search.brave.com |
搜索查询(可选) | BRAVE_API_KEY |
api.parallel.ai |
搜索查询(可选) | PARALLEL_API_KEY |
openrouter.ai |
搜索查询(可选) | OPENROUTER_API_KEY |
你的研究主题会包含在所有对外 API 请求中。如果你研究敏感话题,请注意查询字符串会被传输到上述列出的 API 提供商处。
本地存储的数据
- API 密钥:
~/.config/last30days/.env(建议权限设置为 600) - 观察列表数据库:
~/.local/share/last30days/research.db(SQLite) - 简报:
~/.local/share/last30days/briefs/
API 密钥隔离
每个 API 密钥只会被传输到其对应的接口。你的 OpenAI 密钥绝不会发送给 xAI、Brave 或其他任何提供商。用于 X 的浏览器 Cookie 仅在本地读取,并且只用于 Twitter GraphQL 请求。
30 天的研究,30 秒的工作,八大数据源,零过时提示。
与 Open Claw 搭配使用,实现自动化观察列表和简报。Reddit、X、YouTube、TikTok、Instagram、网络——全部整合成专家级解答和可复制粘贴的提示。
版本历史
v2.9.02026/03/06v2.8.02026/03/04v2.6.02026/03/03v2.1.02026/02/17相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。