reversi-alpha-zero
reversi-alpha-zero 是一个基于 AlphaGo Zero 算法原理构建的黑白棋(Reversi)强化学习开源项目。它旨在解决传统博弈程序依赖人类专家棋谱或手工规则的问题,通过让 AI 在完全零知识的状态下自我对弈,从零开始自主探索并掌握高超的棋艺策略。
该项目非常适合对深度强化学习感兴趣的研究人员、AI 开发者以及希望深入理解 AlphaGo Zero 核心机制的技术爱好者使用。其独特的技术亮点在于完整复现了 AlphaGo Zero 的核心工作流,包含三个协同工作的模块:负责通过自我对弈生成训练数据的"self"模块、负责模型训练与迭代的"opt"模块,以及负责评估新模型性能以决定是否更新最佳模型的"eval"模块。此外,项目还提供了基于 wxPython 的图形界面,让用户能直观地与训练出的最强模型进行对战验证。依托 TensorFlow 和 Keras 框架,reversi-alpha-zero 为学习者提供了一个结构清晰、可复现的端到端实验环境,是研究无监督博弈智能的理想起点。
使用场景
某高校人工智能实验室的研究团队正致力于复现 AlphaGo Zero 算法,并计划将其迁移到黑白棋(Reversi)领域以验证强化学习在完全信息博弈中的泛化能力。
没有 reversi-alpha-zero 时
- 架构从零搭建:研究人员需手动编写自我对弈(Self-Play)、模型训练(Trainer)和评估(Evaluator)三个核心模块的交互逻辑,极易出现状态同步错误。
- 数据生成低效:缺乏自动化的对弈数据生成机制,团队只能依赖人工编写规则引擎或爬取少量历史棋谱,导致训练数据匮乏且多样性不足。
- 迭代验证困难:没有内置的“新一代模型 vs 最佳模型”自动评估流程,每次算法改进后需人工设计测试用例,难以量化模型是否真正进化。
- 环境配置繁琐:在 Windows 等复杂环境下,协调 TensorFlow、Keras 与特定 Python 版本的依赖关系耗时耗力,常因环境报错中断实验。
使用 reversi-alpha-zero 后
- 开箱即用架构:直接复用其成熟的
self、opt、eval三 worker 协作架构,研究重心可立即从工程实现转向算法策略优化。 - 自动化数据闭环:利用
self模块驱动 BestModel 进行高强度自我对弈,自动生成海量高质量 JSON 格式训练数据,彻底解决数据瓶颈。 - 智能模型迭代:通过
eval模块自动执行新模型与当前最强模型的对抗赛,仅当胜率提升时自动替换 BestModel,实现了无人值守的持续进化。 - 可视化对战调试:借助
play_gui图形界面,研究人员可实时观察模型决策过程并与最强模型人机对战,直观分析策略缺陷。
reversi-alpha-zero 将原本需要数周搭建的强化学习基础设施缩短为几小时的配置工作,让研究者能专注于探索算法边界而非重复造轮子。
运行环境要求
- Linux
- macOS
- Windows
- 非必需
- 支持 NVIDIA GPU (需安装 tensorflow-gpu),若无 GPU 可使用 CPU 版本 (tensorflow),但在训练时速度较慢
- 具体显卡型号、显存大小及 CUDA 版本未在文档中明确说明,但基于 TensorFlow 1.3.0 推测需较旧的 CUDA 版本 (如 CUDA 8.0/9.0)
未说明
快速开始
关于
基于AlphaGo Zero方法的黑白棋强化学习。
@mokemokechicken 的训练历史请参见挑战历史。
如果您能分享自己的成果,欢迎将其发布到性能报告中。
环境
- Python 3.6.3
- tensorflow-gpu: 1.3.0 (+)
- tensorflow==1.3.0 也可以,但速度非常慢。在使用
play_gui时,CPU 版本的 TensorFlow 就足够快了。
- tensorflow==1.3.0 也可以,但速度非常慢。在使用
- Keras: 2.0.8 (+)
模块
强化学习
这个 AlphaGo Zero 实现由三个工作进程组成:self、opt 和 eval。
self是自我对弈进程,通过使用最佳模型进行自我对弈来生成训练数据。opt是训练进程,用于训练模型并生成下一代模型。eval是评估进程,用于评估下一代模型是否优于当前的最佳模型。如果更好,则替换最佳模型。- 如果
config.play.use_newest_next_generation_model = True,则此进程将不再需要。(这是 AlphaZero 方法)
- 如果
评估
为了评估,您可以使用最佳模型与之对弈。
play_gui是使用 wxPython 与最佳模型对战的游戏界面。
数据
data/model/model_best_*: 最佳模型。data/model/next_generation/*: 下一代模型。data/play_data/play_*.json: 生成的训练数据。logs/main.log: 日志文件。
如果您想从头开始训练模型,请删除上述目录。
使用方法
设置
安装库
pip install -r requirements.txt
使用 Anaconda 安装库
cp requirements.txt conda-requirements.txt
- 注释掉
jedi、Keras、parso、python-dotenv、tensorflow-tensorboard、wxPython等库的行。 - 将
ipython-genutils、jupyter-*、prompt-toolkit等库中的-替换为_。
conda env create -f environment.yml
source activate reversi-a0
conda install --yes --file conda-requirements.txt
如果您想使用 GPU,
pip install tensorflow-gpu
设置环境变量
创建 .env 文件,并写入以下内容:
KERAS_BACKEND=tensorflow
Windows 设置
本说明由 @GCRhoads 提供,感谢!
必需:64位 Windows
此步骤已在 Windows 8.1 上验证。尚未在其他版本上测试。
注意:Windows 路径名使用反斜杠而非正斜杠。
如有必要,将“src\reversi_zero\agent\player.py”文件的第一行修改为: from asyncio.futures import Future
安装 64 位版本的 Python 3.5(32 位版本不满足要求)。您有两种选择:
注意: 由于某种原因,Python 3.5 和 Anaconda 都会被安装在一个隐藏文件夹中。要访问它们,您需要首先进入控制面板,选择文件夹选项,在“查看”选项卡中,点击“高级设置”部分中“显示隐藏的文件、文件夹或驱动器”旁边的圆圈。Anaconda 会安装在 C:\ProgramData\Anaconda3\ 目录下。而直接下载的 Python 则会安装在 (我认为是) C:\Users\<您的用户名>\AppData\Local\Program\Python\ 目录中。
安装 Visual C++ 2015 构建工具。 您可以安装完整的 Visual Studio 2015 版本(而不是微软试图强加给您的 2017 版本),但这将是一个庞大的下载和安装过程,其中大部分内容您并不需要。下载 Visual C++ 构建工具。双击下载的文件以运行安装程序。
将所有 f-string 替换为 string.format()。 该项目的 Python 源代码大量使用了 f-string,这是 Python 3.6 才引入的新特性。由于我们需要的是 Python 3.5(Windows 版本的 TensorFlow 要求),请使用编辑器的搜索功能找到每一个 f-string 的用法,并将其替换为 string.format()。
安装所需的库。 无论是从 Anaconda 提示符还是从您放置本项目的顶级文件夹中的命令窗口,输入以下命令:
pip install -r requirements.txt
- 安装 TensorFlow
如果您拥有与 TensorFlow 兼容的 GPU(请参阅 TensorFlow 官网上的兼容列表),那么安装 GPU 版本将使代码运行得更快。要安装 GPU 版本,请在 Anaconda 提示符或命令窗口中输入以下命令:
pip3 install --upgrade tensorflow-gpu
如果您没有兼容的 GPU,则只能使用较慢的仅 CPU 版本。要安装此版本,请在 Anaconda 提示符或命令窗口中输入以下命令:
pip3 install --upgrade tensorflow
- 设置环境变量。 创建一个
.env文件,并在其中写入以下内容:
KERAS_BACKEND=tensorflow
现在您就可以开始了。
最强模型
目前,“challenge 5 model”和“ch5 config”是我训练出的最强模型。如果您想使用它进行对弈,
rm -rf data/model/next_generation/
sh ./download_model.sh 5
# 以 wxPython GUI 运行
python src/reversi_zero/run.py play_gui -c config/ch5.yml
如果您想将其用作 NBoard 引擎(见下文“作为 NBoard2.0 引擎运行”),请使用命令 nboard_engine -c config/ch5.yml。
过往模型
如果您想使用 data/model/model_best_* 中的最佳模型,请先移除(或重命名)data/model/next_generation/ 目录。
下载已训练的最佳模型
例如,下载由下方挑战 1 训练的最佳模型:
sh ./download_best_model.sh
下载最新训练的模型
将挑战 2、3、4、5 训练的最新模型下载为最佳模型:
sh ./download_model.sh <版本>
例如:
sh ./download_model.sh 5
配置
“AlphaGo Zero”方法与“AlphaZero”方法
我认为“AlphaGo Zero”和“AlphaZero”的主要区别在于是否使用 eval 进程。可以通过配置来切换这两种方法。
AlphaGo Zero 方法
PlayConfig#use_newest_next_generation_model = FalsePlayWithHumanConfig#use_newest_next_generation_model = False- 执行
Evaluator进程以选择最佳模型。
AlphaZero 方法
PlayConfig#use_newest_next_generation_model = TruePlayWithHumanConfig#use_newest_next_generation_model = True- 不使用
Evaluator进程(最新的模型将被选为自我对弈的模型)。
自我对弈中的策略分布
在 DeepMind 的论文中,自我对弈保存的策略数据似乎按照 pow(N, 1/tau) 的比例分布。在对局中后期,tau 会变为 0,此时策略分布变为 one-hot 形式。
PlayDataConfig#save_policy_of_tau_1 = True 表示保存的策略始终使用 tau=1。
其他重要超参数(我认为)
如果你找到了一组好的参数,请在 GitHub 的 Issues 中分享!
PlayDataConfig
nb_game_in_file,max_file_num: 训练数据的最大游戏数量为nb_game_in_file * max_file_num。multi_process_num: 用于生成自我对弈数据的进程数。
PlayConfig, PlayWithHumanConfig
simulation_num_per_move:每步的 MCTS 次数。c_puct: MCTS 中价值网络和策略网络的平衡参数。resign_threshold: 投子阈值。parallel_search_num: MCTS 中速度与准确性的平衡参数(?)。prediction_queue_size应该等于或大于parallel_search_num。
dirichlet_alpha: 自我对弈中的随机参数。share_mtcs_info_in_self_play: 额外选项。如果为真,则在自我对弈的不同游戏中共享 MCTS 树节点信息。reset_mtcs_info_per_game: 共享 MCTS 信息的重置时机。
use_solver_turn,use_solver_turn_in_simulation: 从这一回合开始使用解算器。如果为None,则不使用。
TrainerConfig
wait_after_save_model_ratio: 如果大于 0,优化器会在每次保存模型后,等待相当于保存间隔比例的时间。这在你用同一块 GPU 同时运行“自我对弈”和“优化”时可能会很有用。
基本用法
要训练模型,需要依次执行“自我对弈”、“训练器”和“评估器”。
自我对弈
python src/reversi_zero/run.py self
执行时,自我对弈将使用最佳模型开始。如果最佳模型不存在,则会创建一个新的随机模型并将其设为最佳模型。
选项
--new: 创建新的最佳模型。-c config_yaml: 指定配置文件路径,以覆盖config.py的默认设置。
训练器
python src/reversi_zero/run.py opt
执行时,训练将开始。基础模型将从最近保存的下一代模型中加载。如果不存在,则使用最佳模型。训练后的模型将在每个 epoch 结束后每 2000 步(小批量)保存一次。
选项
-c config_yaml: 指定配置文件路径,以覆盖config.py的默认设置。--total-step: 指定总步数(小批量)。总步数会影响训练的学习率。
评估器
python src/reversi_zero/run.py eval
执行时,评估将开始。它通过进行约 200 场比赛来评估最佳模型和最新的下一代模型。如果下一代模型获胜,则它将成为最佳模型。
选项
-c config_yaml: 指定配置文件路径,以覆盖config.py的默认设置。
对弈
python src/reversi_zero/run.py play_gui
注意:Mac pyenv 环境
play_gui 使用 wxPython。如果你的 Python 环境是在没有 Framework 的情况下构建的,则无法执行。请尝试以下 pyenv 安装选项:
env PYTHON_CONFIGURE_OPTS="--enable-framework" pyenv install 3.6.3
对于 Anaconda 用户:
conda install python.app
pythonw src/reversi_zero/run.py play_gui
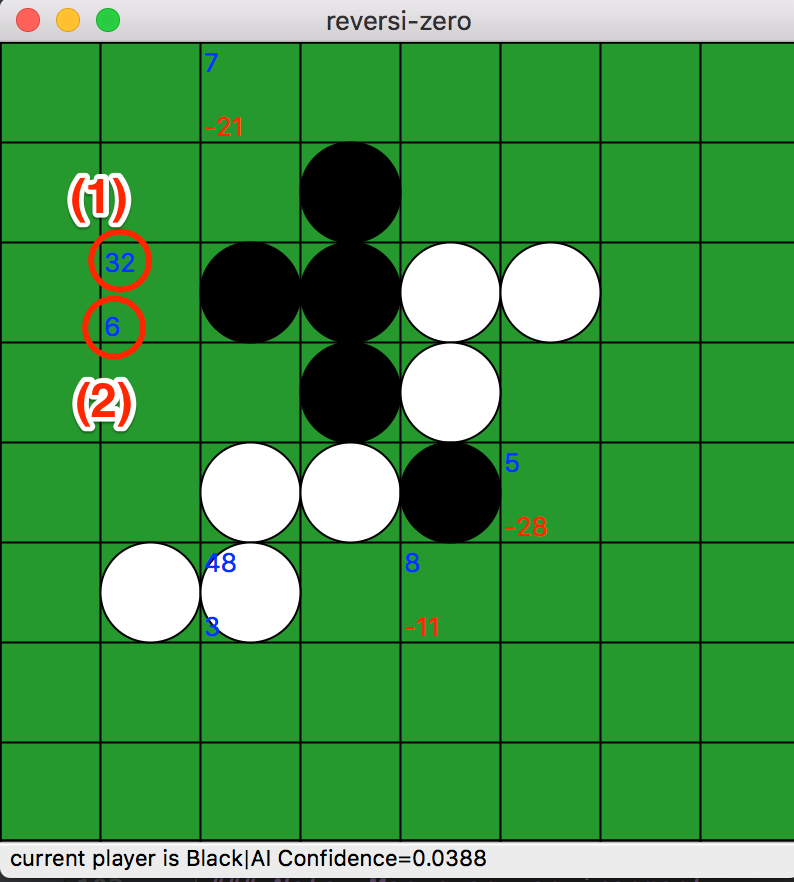
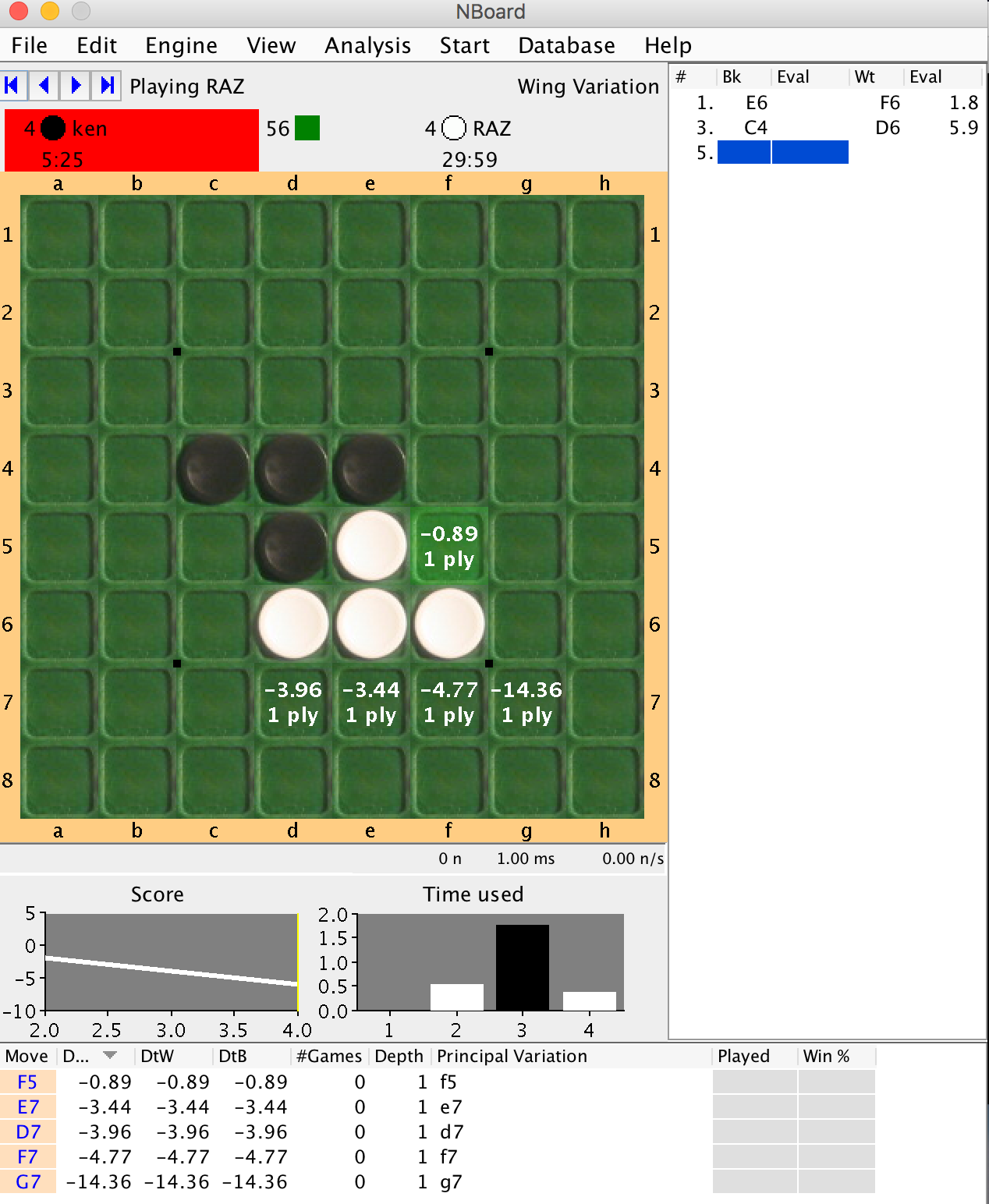
执行时,会显示一个普通的黑白棋棋盘,你可以与最佳模型对弈。在最佳模型走完一步后,棋盘上会显示一些数字。
- 左上角的数字 (1) 表示上次搜索的“访问次数 (=N(s,a))”。
- 左下角的数字 (2) 表示上次状态和走法的“AI 方面的 Q 值 (=Q(s,a))”。这些 Q 值被乘以 100。
作为 NBoard 2.0 引擎运行
NBoard 是一款非常好的黑白棋 GUI,并且拥有强大的黑白棋引擎,可在 Windows、Mac 和 Linux 上运行(需要 JRE)。
它可以添加实现 NBoard 协议 的外部引擎。
如何将本模型作为外部引擎添加到 NBoard
(0) 从命令行启动 NBoard(需要设置 PATH 等环境变量)
- 例如:
java -jar /Applications/NBoard/nboard-2.0.jar
- 例如:
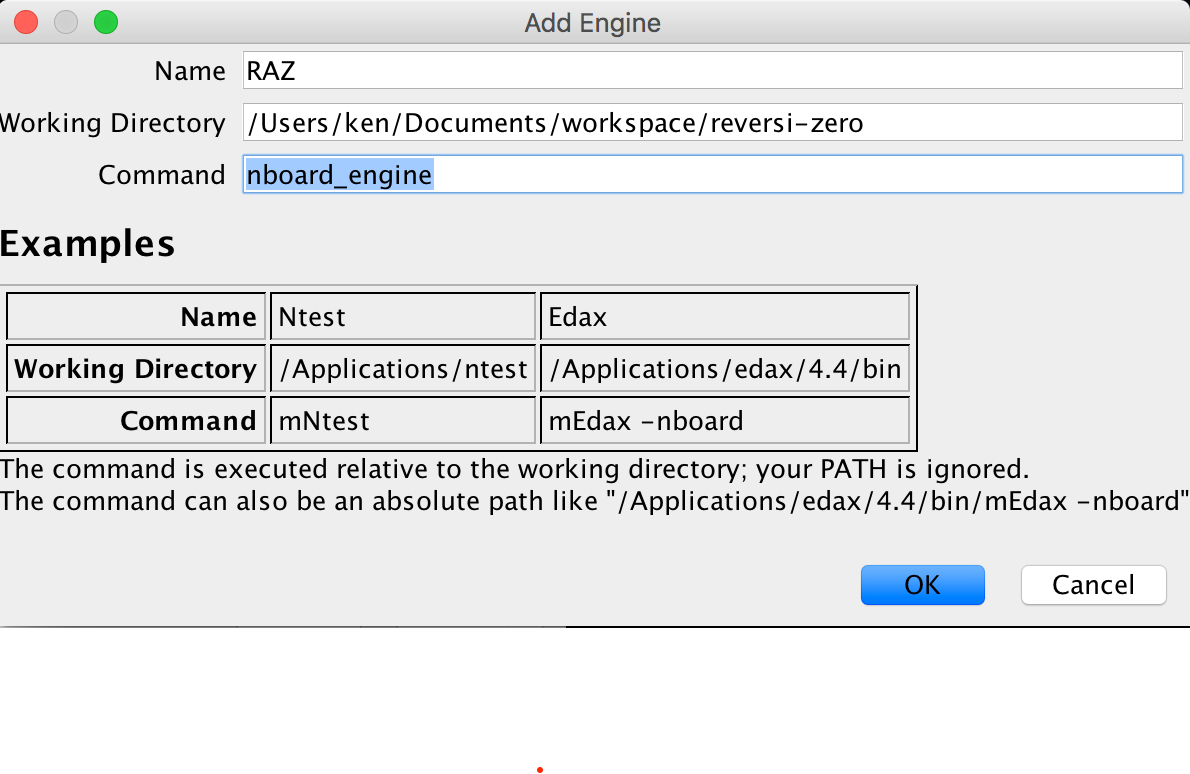
(1) 选择菜单
Engine -> Select Opponent...(2) 点击按钮
Add Engine(3) 设置参数:
Name=RAZ(例如)Working Directory= 本项目的路径Command=nboard_engine或bash nboard_engine。如果你想指定配置文件类型,可以使用nboard_engine -c config/ch5.yml。
(4) 将引擎等级 N 设置为
simulation_num_per_move=N*20。
评估你的模型的便捷方法
NBoard 似乎不能同时使用两个不同的引擎(可能)。不过,它可以分别选择对弈引擎和分析引擎。
因此,评估你的模型的一个便捷方法是:
- 将本模型设为对弈引擎(或分析引擎),另一个引擎设为分析引擎(或对弈引擎)。
- 打开菜单
View -> Highlight Best Move。 - 开始让“用户执黑棋”(或白棋)。
- 你只需选择分析引擎推荐的最佳走法即可。
我对作为分析引擎的 hint 协议不太有信心(存在一些奇怪的行为),但在我的环境中可以正常工作。
与其他黑白棋 AI 的自动评估
reversi-arena 是一个用于评估实现 NBoard 协议的黑白棋 AI 的系统。当需要与像 NTest 这样的强大 AI 进行大量对局时,这个系统非常有用。
在 TensorBoard 中查看训练日志
1. 安装 tensorboard
pip install tensorboard
2. 启动 tensorboard 并通过浏览器访问
tensorboard --logdir logs/tensorboard/
然后访问 http://<机器IP>:6006/。
故障排除
如果由于错误无法启动 tensorboard,请尝试创建一个仅包含 tensorflow 和 tensorboard 的新项目。
然后运行:
tensorboard --logdir <REVERSI 项目路径>/logs/tensorboard/
提示与备忘录
GPU 内存
在我的 GeForce GTX 1080 环境中,显存约为 8GB,因此有时会出现显存不足的情况。通常,显存不足只会导致警告,而不会引发错误。如果出现错误,请尝试修改 src/worker/{evaluate.py,optimize.py,self_play.py} 中的 per_process_gpu_memory_fraction:
tf_util.set_session_config(per_process_gpu_memory_fraction=0.2)
减少 batch_size 可以降低 opt 的内存使用量。可以尝试在 NormalConfig 中调整 TrainerConfig#batch_size。
训练速度
- CPU: 8 核 i7-7700K,主频 4.20GHz
- GPU: GeForce GTX 1080
- 自我对弈中一局游戏:约 10~20 秒(simulation_num_per_move = 100,thinking_loop = 1)。
- 训练中一步(小批量,batch size=512):约 1.8 秒。
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。