facechain
FaceChain 是一个基于深度学习的工具链,用于生成高质量的数字孪生人像。用户只需提供一张照片,即可在 10 秒内生成多种风格的人像作品,支持文本描述、图像修复等多种生成方式。它解决了传统人像生成中需要复杂训练流程、风格受限以及生成速度慢的问题,使得个性化人像创作更加高效和灵活。
FaceChain 适合开发者、研究人员以及对 AI 图像生成感兴趣的设计师使用。对于开发者来说,它提供了 Python 脚本和 Gradio 界面,便于集成与扩展;研究人员可以借助其开源代码和论文细节深入探索相关技术;设计师则能快速生成符合需求的高质量人像作品。
其独特之处在于 FACT(Face Adapter with deCoupled Training)技术,实现了无需训练即可生成多风格人像,同时兼容 ControlNet 和 LoRAs 等主流模型,显著提升了生成效率和可控性。此外,FaceChain 还支持一键调用多种风格,并提供自动训练脚本,方便用户扩展新风格。
使用场景
某影视公司特效团队正在为一部历史题材的电视剧制作虚拟角色,需要根据演员的照片生成多个不同风格的数字分身,用于不同场景和年代的演绎。
没有 facechain 时
- 需要依赖专业3D建模师手动创建每个角色的数字分身,耗时且成本高昂。
- 无法快速生成多种风格的虚拟形象,导致角色设计周期长、灵活性差。
- 对于非专业人员来说,缺乏直观的操作界面,学习成本高。
- 生成的图像质量不稳定,难以保持角色身份的一致性。
- 缺乏自动化流程,每次生成都需要重新训练模型或调整参数。
使用 facechain 后
- 只需上传一张演员照片,即可在10秒内生成多个风格各异的高质量数字分身。
- 支持一键调用多种风格模板,极大提升了角色设计的效率与多样性。
- 提供了用户友好的Gradio界面,非技术人员也能轻松操作。
- 生成的图像保持高度一致性,确保角色身份特征不被破坏。
- 自动化流程减少了人工干预,显著降低了开发和制作成本。
FaceChain 通过高效、灵活和易用的特性,大幅提升了影视特效团队在虚拟角色生成方面的生产力与创意实现能力。
运行环境要求
- Ubuntu 20.04
- CentOS 7.9
需要 NVIDIA GPU(如 A10 24G),显存 8GB+,CUDA 11.7+
建议 16GB+(使用 Jemalloc 可优化内存至 20GB 以下)

快速开始

FaceChain

新闻
- 我们的工作 FaceChain-MMID 已被《Pattern Recognition》期刊接受!(2025年5月30日 UTC)
- FaceChain-FACT 无训练肖像生成的更多技术细节可在论文中查看。(2024年10月17日 UTC)
- 我们的工作 TopoFR 已被 NeurIPS 2024 接受!(2024年9月26日 UTC)
- 我们提供新风格的训练脚本,支持自动为新风格 LoRa 进行训练并生成相应的风格提示,同时在“无限风格肖像生成”选项卡中实现一键调用!(2024年7月3日 UTC)
- 🚀🚀🚀 我们将 [FACT] 上线主分支,提供仅需10秒的惊人速度,并与标准即用型 LoRa 和 ControlNet 无缝集成,同时提升指令遵循能力!原基于训练的 FaceChain 已移至 (https://github.com/modelscope/facechain/tree/v3.0.0 )。(2024年5月28日 UTC)
- 我们的工作 FaceChain-ImagineID 和 FaceChain-SuDe 已被 CVPR 2024 接受!(2024年2月27日 UTC)
简介
如果您熟悉中文,可以阅读中文版本的README。
FaceChain 是一个用于生成身份保真的人像的新框架。在最新的 FaceChain FACT(带解耦训练的面部适配器)版本中,只需一张照片和10秒钟,您就能在不同场景下生成个性化肖像(现已支持多种风格!)。FaceChain 在肖像生成方面兼具高度可控性和真实性,包括文本到图像和修复填充等流程,并且可与 ControlNet 和 LoRa 无缝兼容。您可以通过 FaceChain 的 Python 脚本、熟悉的 Gradio 界面或 SD WebUI 来生成肖像。 FaceChain 由 ModelScope 提供技术支持。
ModelScope Studio 🤖 |API 🔥 | SD WebUI | HuggingFace Space 🤗


新闻
- 我们的工作 FaceChain-MMID 已被《Pattern Recognition》期刊接受!(2025年5月30日 UTC)
- FaceChain-FACT 无训练肖像生成的更多技术细节可在论文中查看。(2024年10月17日 UTC)
- 我们的工作 TopoFR 已被 NeurIPS 2024 接受!(2024年9月26日 UTC)
- 我们提供新风格的训练脚本,支持自动为新风格 LoRa 进行训练并生成相应的风格提示,同时在“无限风格肖像生成”选项卡中实现一键调用!(2024年7月3日 UTC)
- 🚀🚀🚀 我们将 [FACT] 上线,提供仅需10秒的惊人速度,并与标准即用型 LoRa 和 ControlNet 无缝集成,同时提升指令遵循能力!(2024年5月28日 UTC)
- 我们的工作 FaceChain-ImagineID 和 FaceChain-SuDe 已被 CVPR 2024 接受!(2024年2月27日 UTC)
- 🏆🏆🏆阿里巴巴年度优秀开源项目、阿里巴巴年度开源先锋(刘洋、孙百贵)。(2024年1月20日 UTC)
- 我们的工作 InfoBatch 与新加坡国立大学团队合作完成,已被 ICLR 2024 接受(口头报告)!(2024年1月16日 UTC)
- 🏆开放原子基金会2023年度快速成长开源项目奖。(2023年12月20日 UTC)
- 新增 SDXL 流程🔥🔥🔥,图像细节明显提升。(2023年11月22日 UTC)
- 支持超分辨率🔥🔥🔥,提供多种分辨率选择(512512、768768、10241024、20482048)。(2023年11月13日 UTC)
- 🏆FaceChain 已入选BenchCouncil Open100(2022-2023) 年度排名。(2023年11月8日 UTC)
- 新增虚拟试穿模块。(2023年10月27日 UTC)
- 推出 wanx 版本在线免费应用。(2023年10月26日 UTC)
- 🏆1024程序员节 AIGC 应用工具最具价值商业奖。(2023年10月24日 UTC)
- 支持 FaceChain 在 stable-diffusion-webui 中使用🔥🔥🔥。(2023年10月13日 UTC)
- 高性能单人及双人修复填充,简化用户界面。(2023年9月9日 UTC)
- 更多技术细节可在论文中查看。(2023年8月30日 UTC)
- 新增 Lora 训练的验证与集成功能,以及 InpaintTab(目前在 Gradio 中隐藏)。(2023年8月28日 UTC)
- 新增姿态控制模块。(2023年8月27日 UTC)
- 新增稳健的面部 Lora 训练模块,提升单张照片训练及风格 Lora 混合的效果。(2023年8月27日 UTC)
- HuggingFace Space 现已上线!您可通过 🤗 直接体验 FaceChain。(2023年8月25日 UTC)
- 新增超赞提示词!请参考:awesome-prompts-facechain。(2023年8月18日 UTC)
- 支持一系列新风格模型,实现即插即用。(2023年8月16日 UTC)
- 支持自定义提示词。(2023年8月16日 UTC)
- Colab 笔记本现已上线!您可通过
 直接体验 FaceChain。(2023年8月15日 UTC)
直接体验 FaceChain。(2023年8月15日 UTC)
待办事项
- 全身数字人
引用
如果您认为 FaceChain 和 FaceChain-FACT 对您的研究有所帮助,请在您的论文中引用它们。
@article{liu2023facechain,
title={FaceChain: 一个用于身份保留的人像生成平台},
author={刘洋、于成、尚磊、吴子恒、王兴军、赵宇泽、朱琳、程晨、陈伟涛、徐超、谢浩宇、姚远、周文梦、陈英达、谢轩松、孙百贵},
journal={arXiv 预印本 arXiv:2308.14256},
year={2023}
}
@article{yu2024facechain,
title={FaceChain-FACT:一种具有解耦训练的身份保留个性化面部适配器},
author={于成、谢浩宇、尚磊、刘洋、单俊、孙百贵、薄立峰},
journal={arXiv 预印本 arXiv:2410.12312},
year={2024}
}
安装
兼容性验证
我们已在以下环境中验证了端到端的运行:
- Python:py3.8、py3.10
- PyTorch:torch2.0.0、torch2.0.1
- CUDA:11.7
- cuDNN:8+
- 操作系统:Ubuntu 20.04、CentOS 7.9
- GPU:Nvidia-A10 24G
内存优化
建议安装 Jemalloc,以将内存占用从 30G 以上优化至 20G 以下。以下是 Modelscope Notebook 中安装 Jemalloc 的示例。
apt-get install -y libjemalloc-dev
export LD_PRELOAD=/lib/x86_64-linux-gnu/libjemalloc.so
安装指南
支持以下几种安装方式:
1. ModelScope Notebook【推荐】
ModelScope Notebook 提供免费版,允许 ModelScope 用户在最少配置下运行 FaceChain 应用程序,详情请参阅 ModelScope Notebook。
# 第一步:我的 Notebook -> PAI-DSW -> GPU 环境
# 注意:请使用:ubuntu20.04-py38-torch2.0.1-tf1.15.5-modelscope1.8.1
# 第二步:进入 Notebook 单元格,从 GitHub 克隆 FaceChain:
!GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git --depth 1
# 第三步:切换工作目录到 facechain,并安装依赖项:
import os
os.chdir('/mnt/workspace/facechain') # 您可以更改为您自己的路径
print(os.getcwd())
!pip3 install gradio==3.47.1
!pip3 install controlnet_aux==0.0.6
!pip3 install python-slugify
!pip3 install diffusers==0.29.0
!pip3 install peft==0.11.1
!pip3 install modelscope -U
!pip3 install datasets==2.16
# 第四步:启动应用服务,点击“公共 URL”或“本地 URL”,上传您的图片以
# 训练您自己的模型并生成您的数字孪生。
!python3 app.py
此外,您也可以购买一个 PAI-DSW 实例(使用 A10 资源),并选择 ModelScope 镜像来按照类似步骤运行 FaceChain。
2. Docker
如果您熟悉 Docker 的使用,我们推荐采用这种方式:
# 第一步:在本地或云端准备带有 GPU 的环境,建议使用阿里云 ECS,详情请参阅:https://www.aliyun.com/product/ecs
# 第二步:下载 Docker 镜像(有关安装 Docker 引擎的说明,请参阅 https://docs.docker.com/engine/install/)
# 针对中国大陆用户:
docker pull registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.7.1-py38-torch2.0.1-tf1.15.5-1.8.1
# 针对海外用户:
docker pull registry.us-west-1.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.7.1-py38-torch2.0.1-tf1.15.5-1.8.1
# 第三步:运行 Docker 容器
docker run -it --name facechain -p 7860:7860 --gpus all registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.7.1-py38-torch2.0.1-tf1.15.5-1.8.1 /bin/bash
# 注意:您可能需要安装 nvidia-container-runtime,具体操作如下:
# 1. 安装 nvidia-container-runtime:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
# 2. sudo systemctl restart docker
# 第四步:在 Docker 容器内安装 Gradio:
pip3 install gradio==3.47.1
pip3 install controlnet_aux==0.0.6
pip3 install python-slugify
pip3 install diffusers==0.29.0
pip3 install peft==0.11.1
pip3 install modelscope -U
pip3 install datasets==2.16
# 第五步:从 GitHub 克隆 FaceChain
GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git --depth 1
cd facechain
python3 app.py
# 注意:FaceChain 目前假设为单 GPU,如果您的环境有多个 GPU,请改用以下命令:
# CUDA_VISIBLE_DEVICES=0 python3 app.py
# 第六步
运行应用服务器:点击“公共 URL”--> 形式为:https://xxx.gradio.live
3. stable-diffusion-webui
选择“扩展选项卡”,然后选择“从 URL 安装”(官方插件集成已整合,目前请从 URL 安装)。
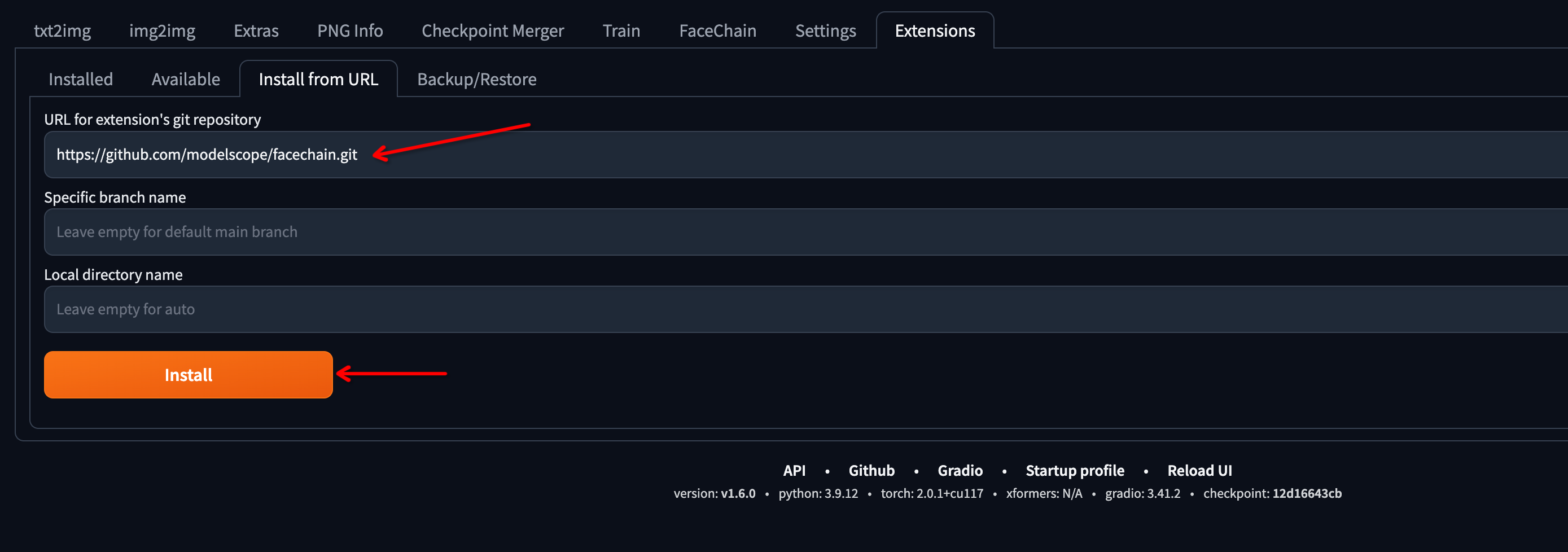
切换到“已安装”,勾选 FaceChain 插件,然后点击“应用并重启 UI”。安装依赖和下载模型可能需要一些时间。请确保正确安装了“CUDA Toolkit”,否则无法成功安装“mmcv”包。
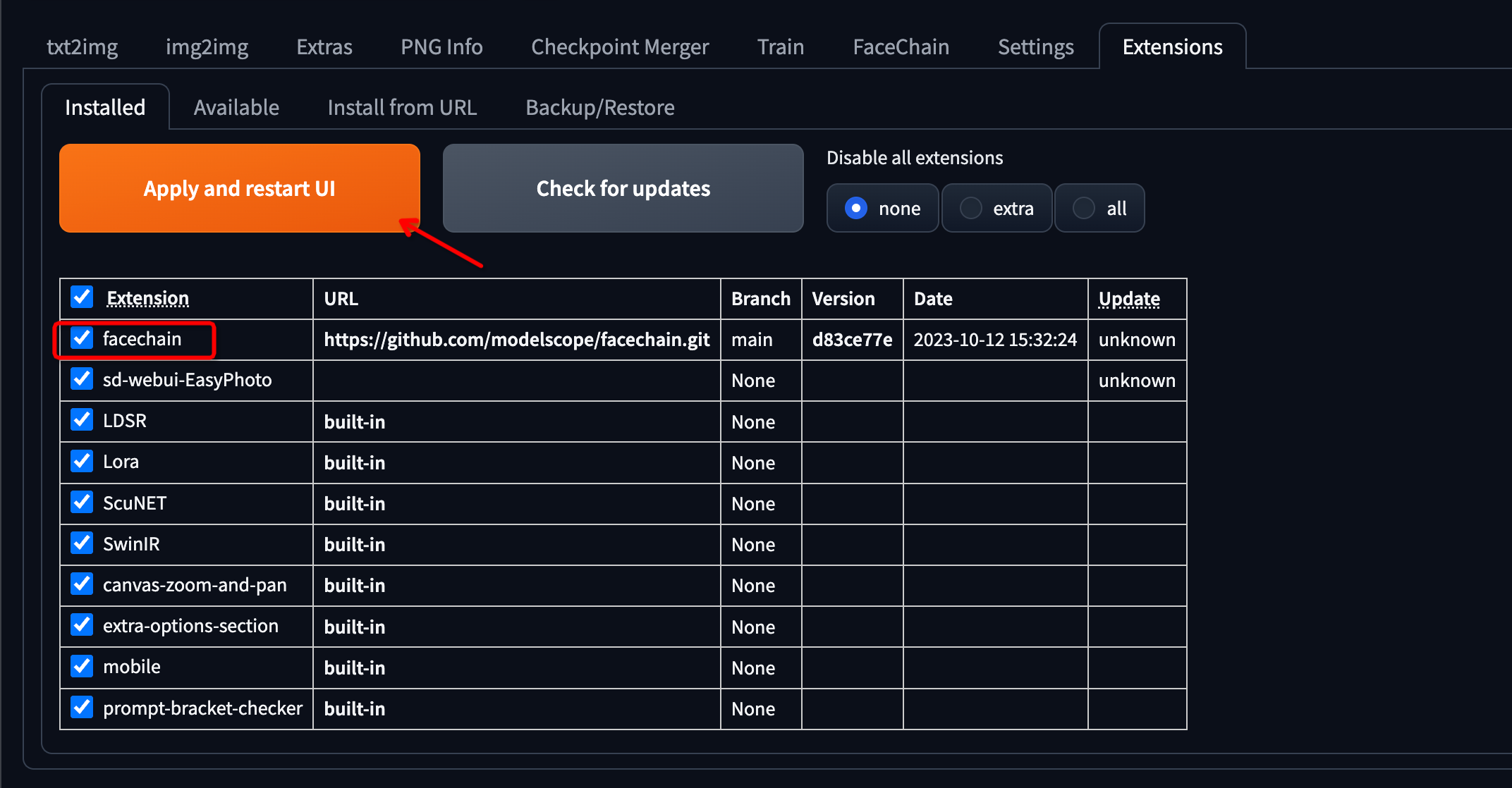
页面刷新后,若出现“FaceChain”选项卡,则表示安装成功。
脚本执行
FaceChain 支持在 Python 环境中直接推理。在进行无限风格人像生成推理时,请编辑 run_inference.py 中的代码:
# 使用姿态控制,默认为 False
use_pose_model = False
# 包含人像生成 ID 信息的输入图像路径
input_img_path = 'poses/man/pose2.png'
# 姿态控制图像的路径,仅在使用姿态控制时有效
pose_image = 'poses/man/pose1.png'
# 推理时生成的图像数量
num_generate = 5
# 风格模型的权重,详情请参见 styles
multiplier_style = 0.25
# 指定保存生成图像的文件夹,可根据需要修改此参数
output_dir = './generated'
# 所选基础模型的索引,详情请参见 facechain/constants.py
base_model_idx = 0
# 风格模型的索引,详情请参见 styles
style_idx = 0
然后执行:
python run_inference.py
您可以在 output_dir 中找到生成的个人数字图像照片。
在进行固定模板人像生成推理时,请编辑 run_inference_inpaint.py 中的代码。
# 模板图像中的人脸数量
num_faces = 1
# 用于修复的人脸索引,从左至右计数
selected_face = 1
# 修复强度,无需更改此参数
strength = 0.6
# 模板图像的路径
inpaint_img = 'poses/man/pose1.png'
# 包含人像生成 ID 信息的输入图像路径
input_img_path = 'poses/man/pose2.png'
# 推理时生成的图像数量
num_generate = 1
# 指定保存生成图像的文件夹,此参数可根据需要修改
output_dir = './generated_inpaint'
然后执行:
python run_inference_inpaint.py
您可以在 output_dir 文件夹中找到生成的个人数字图像照片。
算法介绍
AI人像生成的能力源自于像 Stable Diffusion 这样的大型生成模型及其微调技术。由于大型模型具有强大的泛化能力,因此可以通过在特定类型的数据和任务上进行微调来完成下游任务,同时保持模型整体的文本理解与图像生成能力。基于训练与无训练的 AI 人像生成技术基础在于将不同的微调任务应用于生成模型。目前,大多数现有的 AI 人像工具都采用“先训练后生成”的两阶段流程,其中微调任务是“生成固定角色 ID 的人像照片”,对应的训练数据则是该固定角色 ID 的多张图像。这种基于训练的流程效果取决于训练数据的规模,因此需要一定的图像数据支持和较长的训练时间,这也增加了用户的使用成本。
与基于训练的流程不同,无训练的流程将微调任务调整为“生成指定角色 ID 的人像照片”,即以角色 ID 图像(人脸照片)作为额外输入,输出则是一张保留输入 ID 的人像照片。这种流程将离线训练与在线推理完全分离,用户只需一张照片即可在短短 10 秒内直接基于微调后的模型生成人像,从而避免了大量数据和长时间训练所带来的成本。无训练 AI 人像生成的微调任务基于适配器模块。人脸照片通过一个权重固定的图像编码器和一个参数高效的特征投影层进行处理,以获得对齐的特征,随后通过类似于文本条件的注意力机制输入到 Stable Diffusion 的 U-Net 模型中。此时,人脸信息作为独立的分支条件与文本信息一同输入模型进行推理,从而使生成的图像能够保持 ID 的保真度。
基于人脸适配器的基本算法已经可以实现无训练的 AI 人像生成,但为了进一步提升其效果,仍需进行一些调整。现有的无训练人像工具普遍存在以下问题:人像图像质量较差、人像中的文本跟随与风格保留能力不足、人像面部的可控性和丰富性欠佳,以及与 ControlNet 和风格 Lora 等扩展的兼容性较差。为了解决这些问题,FaceChain 认为现有无训练 AI 人像工具的微调任务耦合了过多超出角色 ID 的信息,并提出了 FaceChain 人脸适配器解耦训练(FaceChain FACT),以解决上述问题。通过在数百万张人像数据上对 Stable Diffusion 模型进行微调,FaceChain FACT 能够实现针对指定角色 ID 的高质量人像生成。FaceChain FACT 的整个框架如下图所示。
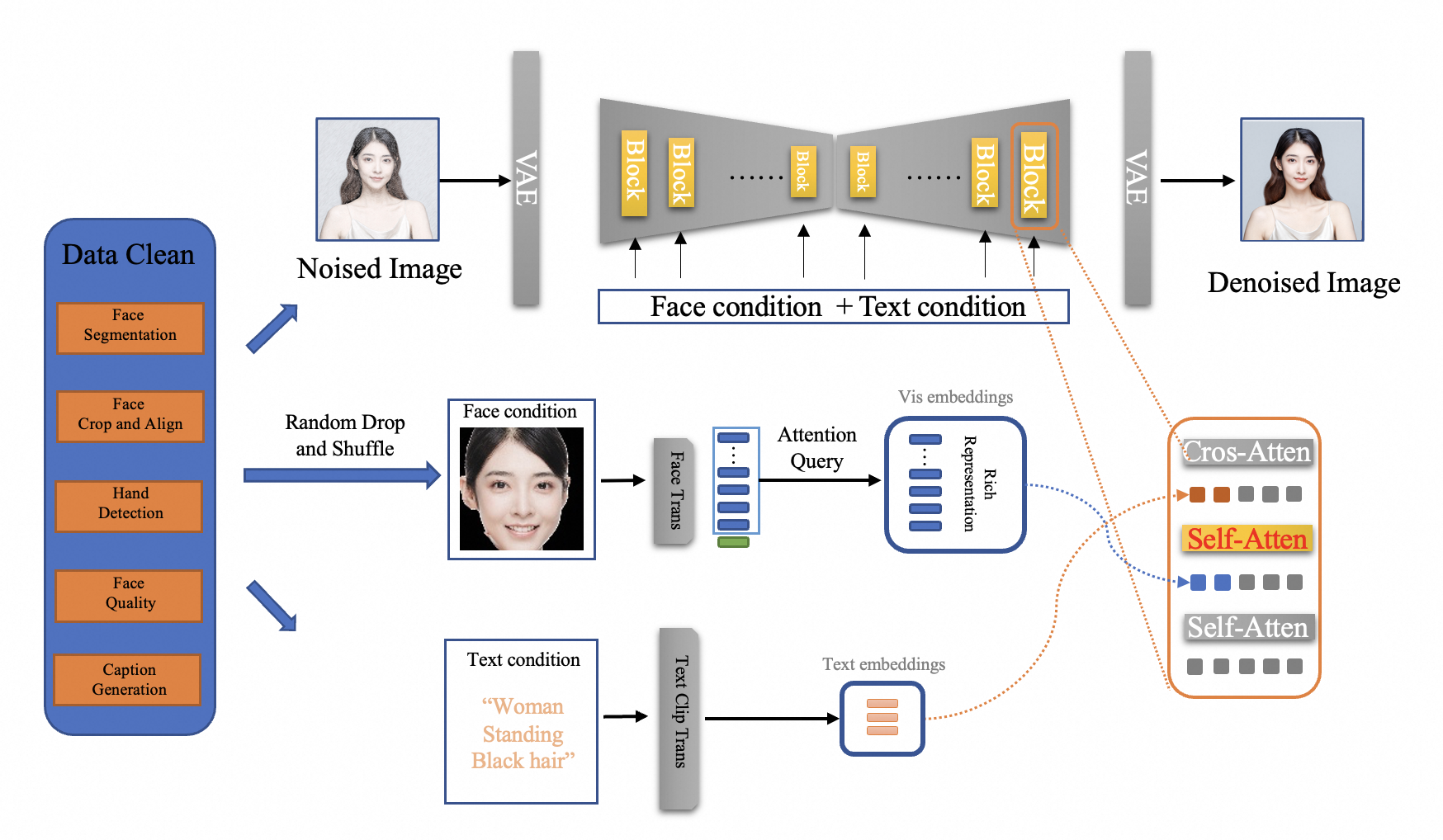
FaceChain FACT 的解耦训练包含两个部分:人脸与图像的解耦,以及 ID 与人脸的解耦。现有方法通常将去噪人像图像作为微调任务,这使得模型难以准确聚焦于人脸区域,从而影响基础 Stable Diffusion 模型的文生图能力。FaceChain FACT 借鉴了换脸算法的顺序处理与区域控制优势,从结构和训练策略两方面实现了人脸与图像解耦的微调方法。在结构上,不同于现有方法采用并行交叉注意力机制处理人脸与文本信息,FaceChain FACT 采用了顺序处理的方式,将一个独立的适配器层插入到原 Stable Diffusion 的各个模块中。这样一来,人脸适配就成为去噪过程中类似换脸的一个独立步骤,避免了人脸与文本条件之间的相互干扰。在训练策略上,除了原有的 MSE 损失函数外,FaceChain FACT 还引入了人脸适配增量正则化(FAIR)损失函数,通过控制适配器层中人脸适配步骤的特征增量,使其更加专注于人脸区域。在推理时,用户可以通过调整人脸适配器的权重灵活地调节生成效果,在保持 Stable Diffusion 文生图能力的同时,平衡人脸的保真度与泛化能力。FAIR 损失函数的公式如下:
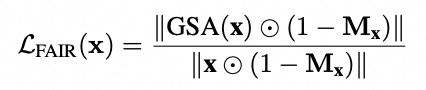
此外,针对生成人脸的可控性和丰富性较差的问题,FaceChain FACT 提出了 ID 与人脸解耦的训练方法,使整个人像生成过程仅保留角色 ID 而非完整的人脸。首先,为了更好地从人脸中提取 ID 信息并保留某些关键的面部细节,同时更好地适配 Stable Diffusion 的结构,FaceChain FACT 采用了一种名为 TransFace 的基于 Transformer 架构的人脸特征提取器,该模型已在大规模人脸数据集上进行了预训练。随后,将倒数第二层的所有 token 输入到一个简单的注意力查询模型中进行特征投影,从而确保提取出的 ID 特征符合上述要求。另外,在训练过程中,FaceChain FACT 还使用分类器自由引导(CFG)方法对同一 ID 的不同人像图像进行随机打乱与丢弃,这样就能保证用于去噪的输入人脸图像与目标图像可能来自不同但具有相同 ID 的人脸,从而进一步防止模型过度拟合人脸的非 ID 信息。因此,FaceChain FACT 具有与 FaceChain 大量精美风格的高度兼容性,具体表现如下。

模型列表
FaceChain 中使用的模型:
[1] 人脸识别模型 TransFace:https://www.modelscope.cn/models/iic/cv_vit_face-recognition
[2] 人脸检测模型 DamoFD:https://modelscope.cn/models/damo/cv_ddsar_face-detection_iclr23-damofd
[3] 人体分割模型 M2FP:https://modelscope.cn/models/damo/cv_resnet101_image-multiple-human-parsing
[4] 美肤修复模型 ABPN:https://www.modelscope.cn/models/damo/cv_unet_skin_retouching_torch
[5] 人脸融合模型:https://www.modelscope.cn/models/damo/cv_unet_face_fusion_torch
[6] FaceChain FACT 模型:https://www.modelscope.cn/models/yucheng1996/FaceChain-FACT
[7] 人脸属性识别模型 FairFace:https://modelscope.cn/models/damo/cv_resnet34_face-attribute-recognition_fairface
更多信息
ModelScope 库为构建 ModelScope 的模型生态系统提供了基础,包括将各类模型集成到 ModelScope 的接口与实现。
许可证
本项目采用 Apache 许可证(版本 2.0) 许可。
版本历史
v2.0.02023/12/19v1.2.02023/10/30v1.1.02023/10/30v1.0.02023/09/07常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。