ask-my-pdf
ask-my-pdf 是一个基于 GPT-3 构建的开源问答系统,旨在让用户能够直接对 PDF 文档内容进行自然语言提问并获取精准答案。它主要解决了从长篇技术手册、规则书或学术文献中快速查找特定信息的痛点,用户无需通读全文即可通过对话形式获取关键内容。虽然其设计初衷是辅助桌游玩家查询游戏规则,但同样适用于各类文档检索场景。
该工具特别适合开发者、研究人员以及需要频繁处理大量 PDF 文档的专业人士使用。对于希望本地部署私有知识库或探索检索增强生成(RAG)技术的开发者而言,ask-my-pdf 提供了清晰的代码实现参考。值得注意的是,该项目目前定位为概念验证(Proof of Concept),用户在体验时需自行配置 OpenAI API 密钥。
在技术层面,ask-my-pdf 创新性地结合了 RALM(上下文检索增强语言模型)与 HyDE(假设性文档嵌入)两项前沿学术成果。这种组合不仅提升了检索的相关性,还有效缓解了大模型可能产生的“幻觉”问题,使回答更加准确可靠。项目支持多种存储后端(如本地文件系统、S3、Redis),具备良好的扩展性与灵活性,是理解现代文档问答架构的优秀范例。
使用场景
桌游店老板李明正在为新员工培训,需要让他们快速掌握几十款复杂桌游的详尽规则,以便随时解答顾客的疑问。
没有 ask-my-pdf 时
- 面对厚达数十页的英文规则书,新员工必须逐字通读才能查找特定机制的说明,培训周期长达数周。
- 遇到顾客询问冷门细节(如“某张卡牌在三人局中的特殊结算顺序”)时,店员需手忙脚乱地翻阅纸质手册,导致服务体验下降。
- 不同员工对规则的理解存在主观偏差,口头传授容易产生信息遗漏或错误解读,引发客诉风险。
- 更新游戏规则或扩展包后,重新整理和分发知识给全员耗时耗力,信息同步严重滞后。
使用 ask-my-pdf 后
- 新员工只需将规则书 PDF 上传至 ask-my-pdf,即可通过自然语言提问瞬间获取精准答案,培训时间缩短至几天。
- 面对顾客的刁钻问题,店员直接输入问题,ask-my-pdf 基于 RALM 和 HyDE 技术从文档中定位并生成准确回复,响应速度提升至秒级。
- 所有回答均严格依据上传的官方文档生成,消除了人为记忆偏差,确保了对每位顾客解释的一致性和权威性。
- 每当发布新规则或扩展包,只需替换对应的 PDF 文件,ask-my-pdf 即刻拥有最新知识库,实现了团队知识的实时同步。
ask-my-pdf 通过将静态文档转化为可交互的智能问答系统,彻底解决了非结构化文档检索难、效率低的核心痛点。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明

快速开始
问我PDF
感谢您对我的应用感兴趣。请注意,这只是一个概念验证系统,可能包含错误或未完成的功能。如果您喜欢这个应用,可以❤️ 在Twitter上关注我,以获取最新消息和更新。
问我PDF - 基于GPT3构建的问答系统
🎲 该应用的主要用途是根据桌游说明书,帮助用户解答关于桌游规则的问题。虽然该应用也可以用于其他任务,但对我个人而言,协助用户解决桌游规则问题尤其有意义,因为我本人就是一位狂热的桌游爱好者。此外,即使模型可能出现幻觉,这种应用场景的风险也相对较低。
🌐 您可以通过Streamlit社区云访问该应用:https://ask-my-pdf.streamlit.app/。🔑 不过,要使用该应用,您需要拥有自己的OpenAI API密钥。
📄 该应用实现了以下学术论文:
上下文检索增强语言模型,又称RALM
无需相关性标签的精确零样本密集检索,又称HyDE(假设文档嵌入)
安装
克隆仓库:
git clone https://github.com/mobarski/ask-my-pdf安装依赖:
pip install -r ask-my-pdf/requirements.txt运行应用:
cd ask-my-pdf/srcrun.sh或run.bat
高层次文档
RALM + HyDE
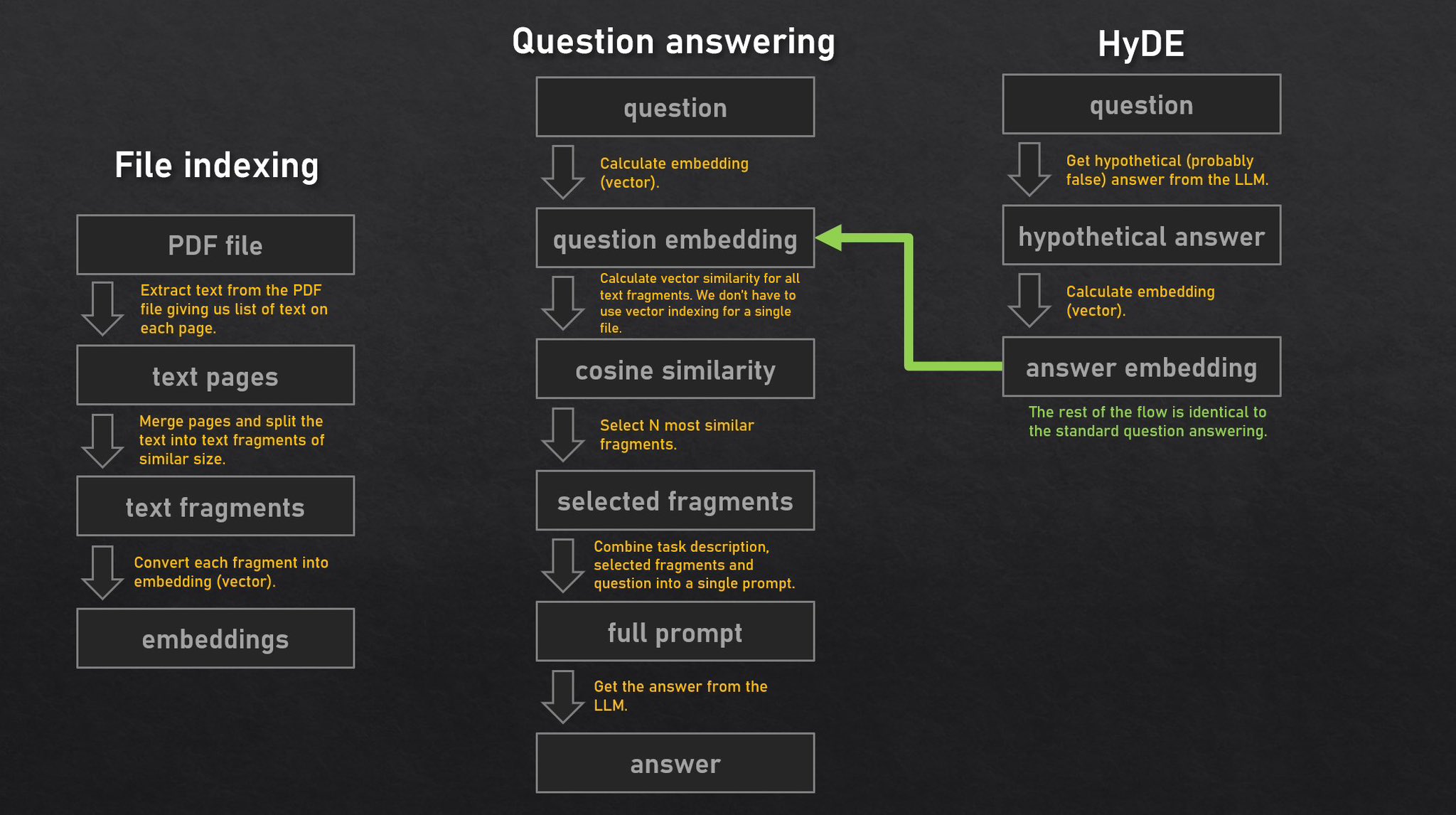
RALM + HyDE + 上下文

用于配置的环境变量
通用配置:
STORAGE_SALT - 从API密钥派生用户/文件夹名和加密密钥时使用的密码学盐,十六进制表示,长度为2–16个字符
STORAGE_MODE - 索引存储模式:S3、LOCAL、DICT(默认)
STATS_MODE - 使用统计信息存储模式:REDIS、DICT(默认)
FEEDBACK_MODE - 用户反馈存储模式:REDIS、NONE(默认)
CACHE_MODE - 嵌入缓存模式:S3、DISK、NONE(默认)
本地文件系统配置(存储/缓存):
STORAGE_PATH - 索引存储的目录路径
CACHE_PATH - 嵌入缓存的目录路径
S3配置(存储/缓存):
S3_REGION - 区域代码
S3_BUCKET - 存储桶名称
S3_SECRET - 秘密访问密钥
S3_KEY - 访问密钥
S3_URL - URL地址
S3_PREFIX - 对象名称前缀
S3_CACHE_BUCKET - 缓存存储桶名称
S3_CACHE_PREFIX - 缓存对象名称前缀
Redis配置(用于持久化使用统计/用户反馈):
- REDIS_URL - Redis数据库URL(redis[s]://:password@host:port/[db])
社区版相关选项:
OPENAI_KEY - 默认用户使用的API密钥
COMMUNITY_DAILY_USD - 默认用户的每日预算
COMMUNITY_USER - 默认用户的代码
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。