MusicGenreClassification
MusicGenreClassification 是一个基于深度学习的开源项目,能够仅凭 10 秒音频流就精准识别音乐流派。它致力于解决音频处理领域中流派分类难、优质数据获取成本高的问题。过去许多研究受限于版权或数据规模,往往难以取得理想效果。该项目创新性地结合了卷积神经网络(CNN)与大规模音频特征提取,成功实现了涵盖 10 个常见流派的分类任务,性能优于早期研究。
项目基于 Python 和 TensorFlow 构建,不仅展示了模型训练流程,还提供了关于如何合法获取音频数据的实用方案(如利用 MSD 数据集及第三方预览接口)。这使其成为深度学习开发者、音频算法研究人员以及学生群体的优秀学习资源。无论是想入门声音处理,还是探索音乐推荐系统的底层逻辑,MusicGenreClassification 都能提供有价值的技术参考和实践范例。
使用场景
某在线音乐社区的开发团队计划上线“智能混音”功能,急需对用户上传的 10 秒试听片段进行自动流派标记,以优化个性化推荐算法。
没有 MusicGenreClassification 时
- 依靠人工审核员逐一听辨音频风格,效率极其低下,无法应对海量用户上传数据。
- 公开可用的音乐数据集往往存在版权争议或规模过小,导致难以训练出高精度的专用模型。
- 通用图像分类模型直接迁移到音频任务效果不佳,在多流派区分度上表现严重不足。
- 自行构建声学特征提取 pipeline 技术门槛过高,团队容易陷入漫长的参数调优困境中。
使用 MusicGenreClassification 后
- 直接复用基于神经网络的成熟方案,仅需输入 10 秒音频流即可实时输出流派预测结果。
- 项目内置了针对大规模数据集优化的预处理逻辑,无需重复处理不同音质和采样率的兼容问题。
- 采用卷积神经网络替代传统方法,显著提升了十种流派同时分类时的整体准确率与鲁棒性。
- 原生支持 TensorFlow 框架,代码结构清晰,方便与现有的 Python 后端服务无缝集成部署。
核心价值:通过开箱即用的深度学习模型,大幅降低了音乐内容理解的技术门槛与开发周期。
运行环境要求
- 未说明
未说明
未说明

快速开始

MusicGenreClassification
深度学习(深度神经网络)与声音处理领域的学术研究,特拉维夫大学。
被 Medium 收录。
摘要
本文讨论了声音样本的音乐流派分类任务。
简介
当我决定从事声音处理领域的工作时,我认为流派分类是图像分类的平行问题。令我惊讶的是,我发现没有太多关于深度学习解决这一确切问题的作品。Tao Feng 来自伊利诺伊大学的论文 [1] 解决了这个分类问题。我从这篇论文中学到了很多,但老实说,他们展示的结果并不令人印象深刻。
所以我不得不寻找其他相关但不完全相同的论文。一篇非常有影响力的论文是《基于内容的音乐推荐》[2]。这篇论文是关于使用深度学习技术进行基于内容的音乐推荐。他们获取数据集的方式以及对声音进行的预处理真正启发了我的实现。此外,这篇论文最近出现在"Spotify"博客 [3] 上。Spotify 招募了一名深度学习实习生,他基于上述工作实现了一个音乐推荐引擎。他那简单却非常高效的网络让我认为 Tao 的 RBM(受限玻尔兹曼机)不是最佳方法,因此我的实现中包含了 CNN(卷积神经网络),就像 Spotify 博客中那样。一个非常重要的注意事项是,Tao 的工作仅发布了针对 2、3 和 4 类分类的结果。显然他在 2 类分类上取得了很好的结果,但他尝试分类的类别越多,结果就越差。我的工作对全部 10 个类别的挑战进行分类,这是一个更困难的任务。此项目的一个子任务是学习一个新的深度学习 SDK(软件开发工具包),我一直在等待机会学习 Google 的新 TensorFlow[4]。本项目用 Python 实现,机器学习部分使用 TensorFlow。
数据集
获取数据集可能是这项工作中最耗时的部分。处理音乐很麻烦,每个文件通常有几十 MB,录音的质量和参数多种多样(频率数量、每秒比特数等……)。但最大的痛点是版权问题,没有合法的著名歌曲数据集,因为它们需要付费。Tao 的论文基于一个名为 GTZAN[5] 的数据集。这个数据集相当小(每流派 100 首歌曲 x 10 个流派 = 总共 1,000 首歌曲),且版权许可存疑。在我看来,这是阻碍他获得更好结果的其中一个原因。所以,我寻找了更多可以从中学习的数据。最终我找到了 MSD[6] 数据集(Million Song Dataset,百万歌曲数据集)。它是一个免费提供的音频特征和元数据集合,包含一百万首当代流行音乐曲目。大约 280 GB 的纯元数据。MSD 之上有一个名为 tagtraum[7] 的项目,它将 MSD 歌曲分类为流派。现在的问题是如何获取声音本身,这就是我发挥创意的地方。我发现数据集中每首歌都有一个标签,是来自提供商 7Digital[8] 的 ID。7Digital 是一个音乐应用程序的 SaaS(软件即服务)提供商,它基本上让你付费流式传输音乐。我以开发者身份注册了 7Digital,在他们的批准之后,我可以访问他们的 API。尽管如此,任何歌曲流媒体都需要付费,但我发现他们允许用户在付费前预览随机 30 秒的歌曲。这对于我的深度学习任务来说已经足够了,所以我写了 previewDownloader.py 来下载 MSD 数据集中每首歌的 30 秒预览。不幸的是,我只有一台笔记本电脑用于这项任务,所以我只能满足于数据集的 1%(约 2.8GB)。
我正在分类的流派包括:
- blues(蓝调)
- classical(古典)
- country(乡村)
- disco(迪斯科)
- hiphop(嘻哈)
- jazz(爵士)
- metal(金属)
- pop(流行)
- reggae(雷鬼)
- rock(摇滚)
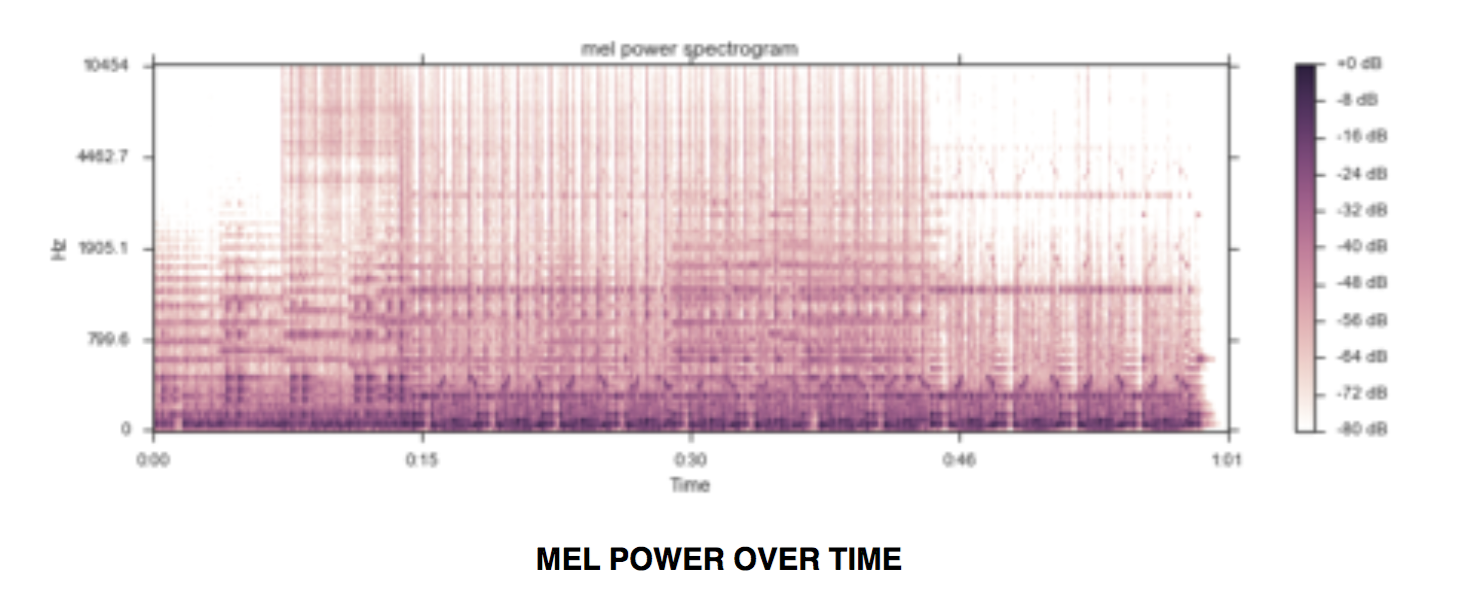
数据预处理
拥有大数据集是不够的,与图像任务相反,我不能直接在原始声音样本上工作。一个简单的计算:30 秒 × 22050 样本/秒 = 661500 长度的向量,这对传统的机器学习方法是沉重的负担。
遵循我阅读的所有论文并稍微研究声学分析后,很明显行业正在使用梅尔频率倒谱系数(MFCC)作为声音样本的特征向量,我使用了 librosa[9] 的实现。
MFCC 推导如下:
- 对信号的(加窗片段)进行傅里叶变换。
- 将上述获得的频谱功率映射到梅尔刻度,使用三角形重叠窗口。
- 取每个梅尔频率处的功率的对数。
- 对该梅尔对数功率列表进行离散余弦变换,将其视为信号。
- MFCC 是所得频谱的幅度。
我尝试了几种窗口大小和步长值,最好的结果是窗口大小为 100ms,步长为 40ms。
还有一点是,Tao 的论文使用了 MFCC 特征(步骤 5),而 Sander 使用了直接的梅尔频率(步骤 2)。
我尝试了这两种方法,发现仅使用梅尔频率可以获得极好的结果,但代价自然是训练时间。在继续构建网络之前,我想可视化预处理后的数据集,我通过 t-SNE[10] 算法实现了这一点。下面你可以看到 MFCC(步骤 5)和梅尔频率(步骤 2)的 t-SNE 图:
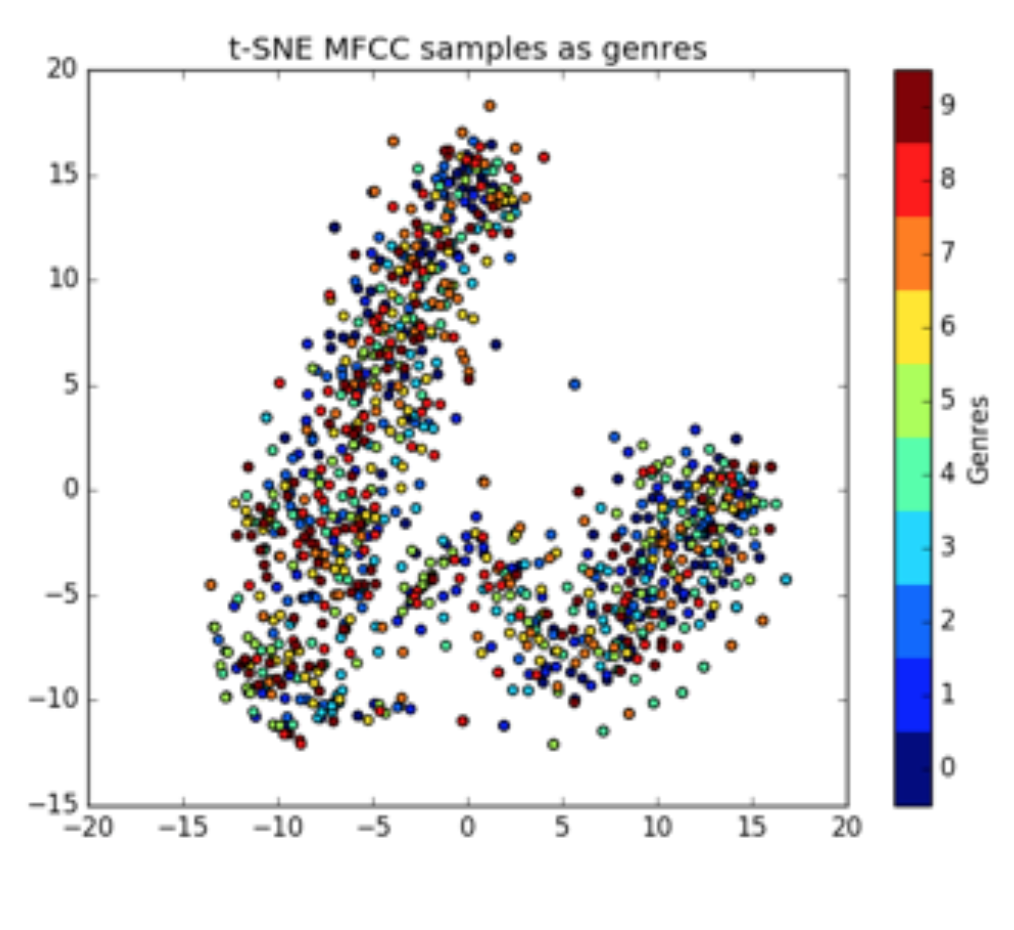
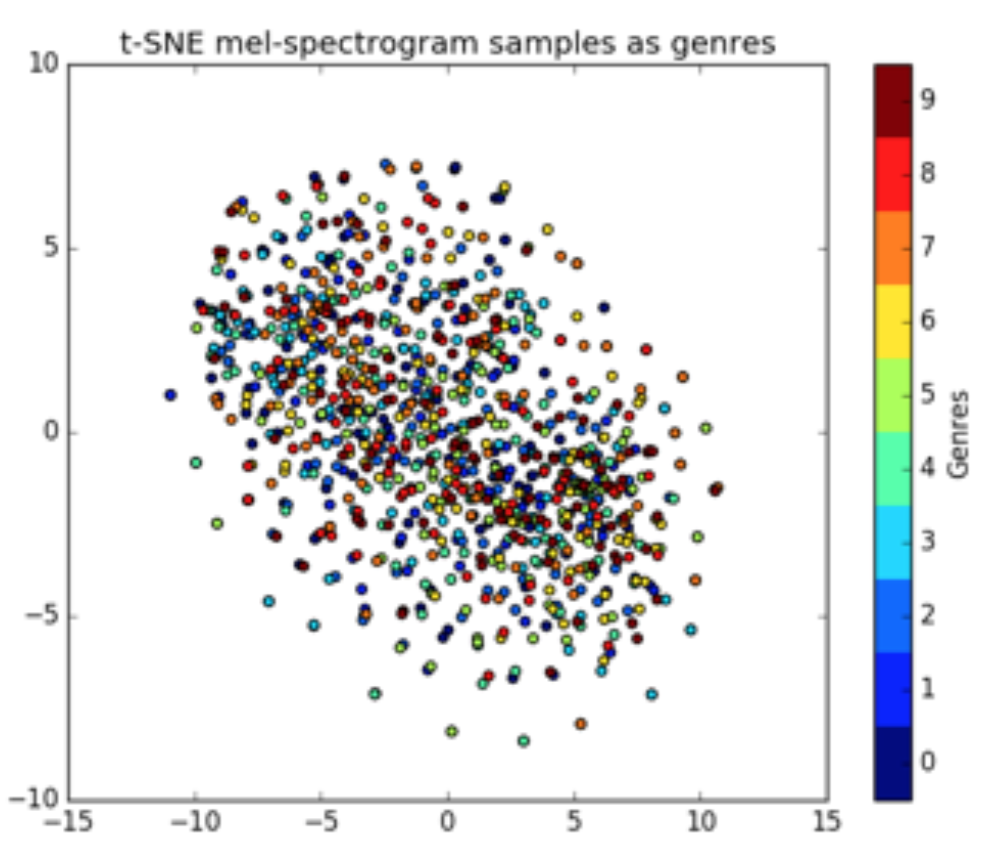
网络架构
在看到 Tao 和 Sander 得出的结果后,我决定采用卷积神经网络(Convolutional Neural Network, CNN)实现方案。该网络接收一个包含 599 个梅尔频率包(mel-frequency bins)的向量,每个包包含描述其窗口的 128 个频率。网络由 3 个隐藏层组成,层与层之间进行了最大池化(max pooling)。最后是一个全连接层(fully connected layer),然后是 Softmax,最终得到一个 10 维向量,对应我们的十个音乐流派类别。
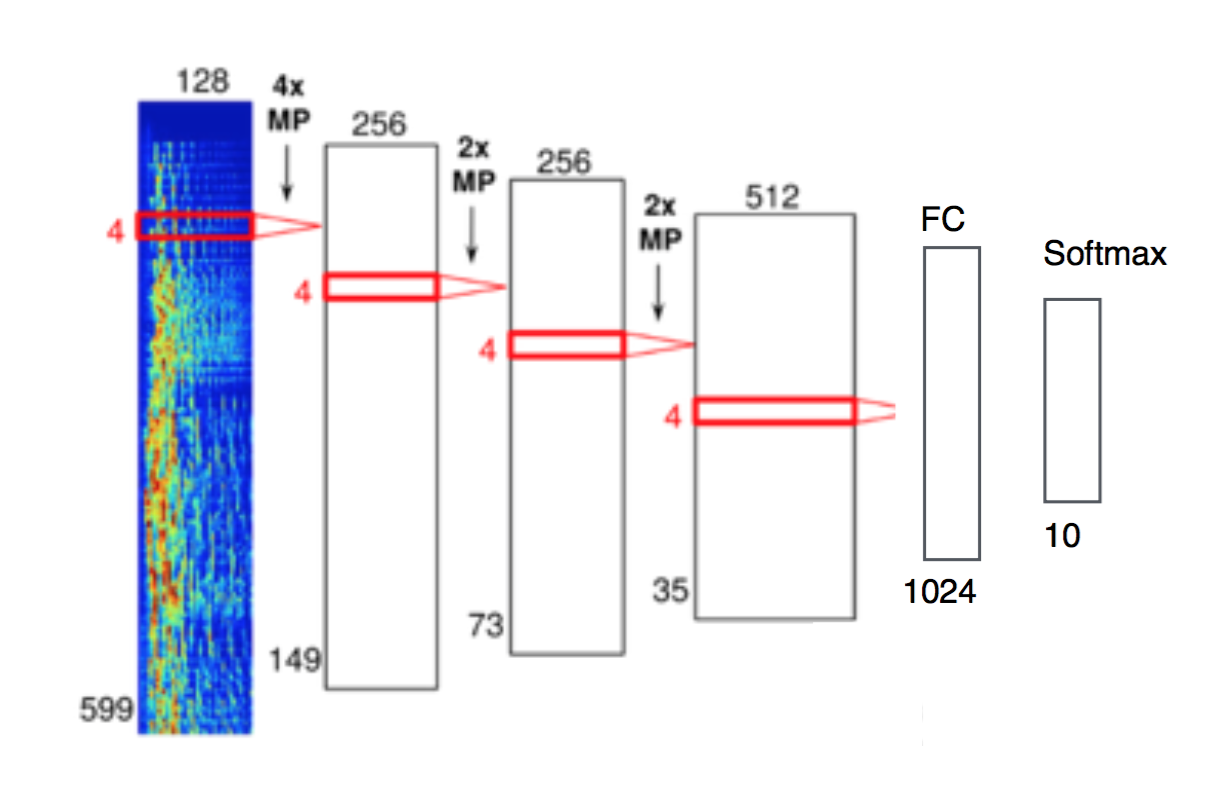
我还为 MFCC(梅尔频率倒谱系数)特征实现了另一个网络,而不是使用梅尔频率,唯一的区别在于尺寸(每个窗口 13 个频率,而不是 128 个)。
各种滤波器的可视化(来自 Sander 的论文):
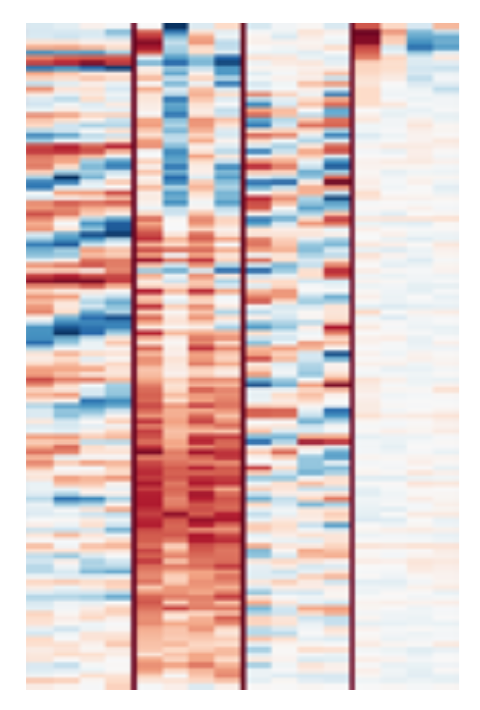
• 滤波器 14 似乎能捕捉颤音演唱。 • 滤波器 242 能捕捉某种回响环境音。 • 滤波器 250 能捕捉人声三度,即多个歌手唱同样的内容,但音符相差一个大三度(4 个半音) apart。 • 滤波器 253 能捕捉各种类型的低音鼓声音。
结果
正如我在引言中解释的那样,我工作所依据的论文并没有解决我遇到的确切问题,例如 Tao 的论文发布了针对分类 2、3 和 4 个类别(流派)的结果。

我在深度学习领域之外寻找了基准测试(benchmark),找到了一篇题为“音频分类与聚类的基准数据集”[11] 的论文。这篇论文评估了一个与我非常相似的任务,它分类的流派包括:蓝调(Blues)、电子(Electronic)、爵士(Jazz)、流行(Pop)、嘻哈(HipHop)、摇滚(Rock)、民谣(Folk)、另类(Alternative)、放克(Funk)。

我的结果:

代码
文档
• previewDownloader.py: 用法:python previewDownloader.py [MSD 数据路径] 此脚本遍历目录中的所有'.h5'文件,并从 7digital 下载 30 秒的样本。
• preproccess.py: 用法:python preproccess.py [MSD mp3 数据路径] 此脚本预处理声音文件。计算滑动窗口的 MFCC,并将结果保存为'.pp'文件。
• formatInput.py: 用法:python formatInput.py [MSD pp 数据路径] 该脚本遍历所有'.pp'文件,生成将用作神经网络输入的'data'和'labels'。此外,脚本在末尾输出一个 t-SNE 图表。
• train.py: 用法:python train.py 此脚本构建神经网络并用'data'和'labels'进行训练。完成后,它将保存'model.final'。
完整安装
- 从 https://www.dropbox.com/s/8ohx6m23co1qaz3/DataSet.zip?dl=0 下载数据集文件。
- 解压文件
- 将数据集文件放置在指定的目录结构中
参考文献
[1] Tao Feng, 音乐流派分类的深度学习,伊利诺伊大学。https://courses.engr.illinois.edu/ece544na/fa2014/Tao_Feng.pdf [2] Aaron van den Oord, Sander Dieleman, Benjamin Schrauwen, 基于内容的音乐推荐。http://papers.nips.cc/paper/5004-deep-content-based- music-recommendation.pdf [3] SANDER DIELEMAN, 使用深度学习在 Spotify 上推荐音乐,2014 年 8 月 05 日。http://benanne.github.io/2014/08/05/spotify-cnns.html [4] https://www.tensorflow.org [5] GTZAN 流派集合。http://marsyasweb.appspot.com/download/ data_sets/ [6] Thierry Bertin-Mahieux, Daniel P.W. Ellis, Brian Whitman, 和 Paul Lamere。百万歌曲数据集。In Proceedings of the 12th International Society for Music Information Retrieval Conference (ISMIR 2011), 2011. http:// labrosa.ee.columbia.edu/millionsong/ [7] Hendrik Schreiber。改进百万歌曲数据集的流派标注。In Proceedings of the 16th International Conference on Music Information Retrieval (IS- MIR), pages 241-247, 2015. http://www.tagtraum.com/msd_genre_datasets.html [8] https://www.7digital.com [9] https://github.com/bmcfee/librosa [10] http://scikit-learn.org/stable/modules/generated/sklearn.manifold.TSNE.html [11] Helge Homburg, Ingo Mierswa, Bu l̈ent Mo l̈ller, Katharina Morik 和 Michael Wurst, 音频分类与聚类的基准数据集,多特蒙德大学,人工智能部门。http://sfb876.tu-dortmund.de/PublicPublicationFiles/ homburg_etal_2005a.pdf
作者
Matan Lachmish 又名 The Big Fat Ninja ![]()
https://thebigfatninja.xyz
署名
图标由 Freepik 制作,来自 www.flaticon.com
许可证
MusicGenreClassification 采用 MIT 许可证。有关更多信息,请参阅 LICENSE 文件。
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。