mattergen
MatterGen 是一款用于设计无机材料的生成模型,能够覆盖整个元素周期表,并可根据多种材料特性进行微调,从而引导生成符合特定需求的新材料。它解决了传统材料设计中效率低、探索范围有限的问题,通过生成模型快速探索化学空间,帮助发现具有目标特性的新型材料。
这款工具特别适合材料科学领域的研究人员和开发者使用。研究人员可以用它来探索新材料的生成,而开发者则可以基于其代码库进行扩展或集成到其他应用中。普通用户可能需要一定的技术背景才能充分利用其功能。
MatterGen 的独特亮点在于其高度灵活性:不仅提供了一个基础的无条件生成模型,还支持针对化学系统、空间群、磁密度、带隙等多种材料属性的微调模型。此外,它还兼容主流硬件环境(如 CUDA 和 Apple Silicon),并提供了预训练模型和数据集,方便用户快速上手。无论是生成全新材料还是优化特定性能,MatterGen 都为材料设计领域带来了强大的助力。
使用场景
一位材料科学家正在为新型太阳能电池开发高效、稳定的无机材料,需要快速筛选出符合特定性能约束的候选材料。
没有 mattergen 时
- 材料设计完全依赖实验试错,周期长且成本高,可能需要数月甚至数年才能找到合适的材料。
- 筛选范围受限于已知材料数据库,难以探索全新化学组成或晶体结构。
- 针对特定性能(如带隙或磁性)优化时,缺乏系统性方法,只能手动调整参数进行有限尝试。
- 实验室资源有限,无法同时测试大量假设,导致研究效率低下。
- 跨团队协作困难,因为材料设计过程缺乏标准化和可复现性。
使用 mattergen 后
- 通过生成模型快速预测和设计新材料,将实验验证周期从数月缩短至数天或数周。
- 能够探索整个元素周期表范围内的全新化学组成和晶体结构,突破现有数据库的限制。
- 利用预训练模型(如
dft_band_gap或ml_bulk_modulus),直接生成满足特定性能约束的候选材料,显著提升优化效率。 - 批量生成多样化候选材料,支持实验室并行验证,最大化利用资源。
- 提供统一框架和可复现的结果,促进团队间协作与知识共享。
mattergen 的核心价值在于大幅加速新材料发现过程,同时降低成本和资源消耗,为材料科学创新提供强大助力。
运行环境要求
- Linux
需要支持 CUDA 的 NVIDIA GPU,显存未说明,CUDA 版本未说明
未说明

快速开始

![]()
![]()
MatterGen 是一个用于整个元素周期表范围内无机材料设计的生成模型,可以微调以引导生成满足各种属性约束的材料。
目录
安装
安装依赖项的最简单方法是通过 uv,这是一个快速的 Python 包和项目管理器。
可以通过以下命令安装 MatterGen 环境(假设您正在运行 Linux 并且拥有 CUDA GPU):
pip install uv
uv venv .venv --python 3.10
source .venv/bin/activate
uv pip install -e .
请注意,我们的数据集和模型检查点通过 Git Large File Storage (LFS) 提供在此存储库中。 要检查您的机器上是否安装了 LFS,请运行:
git lfs --version
如果输出类似 git-lfs/3.0.2 (GitHub; linux amd64; go 1.18.1) 的版本信息,则可以跳过以下步骤。
安装 Git LFS
如果您在克隆此存储库之前未安装 Git LFS,可以通过以下方式安装:
sudo apt install git-lfs
git lfs install
Apple Silicon
[!警告] 在 Apple Silicon 上运行 MatterGen 是实验性的。请自行承担风险使用。
此外,在任何训练或生成运行之前,您需要运行export PYTORCH_ENABLE_MPS_FALLBACK=1。
使用预训练模型开始
我们提供了 MatterGen 的无条件基础版本的检查点,以及针对这些属性微调的模型:
mattergen_base: 基于 Alex-MP-20 训练的无条件基础模型mp_20_base: 基于 MP-20 训练的无条件基础模型chemical_system: 基于化学系统条件微调的模型space_group: 基于空间群条件微调的模型dft_mag_density: 基于 DFT 磁密度条件微调的模型dft_band_gap: 基于 DFT 带隙条件微调的模型ml_bulk_modulus: 基于 ML 预测器预测的体积模量条件微调的模型dft_mag_density_hhi_score: 基于 DFT 磁密度和 HHI 分数联合条件微调的模型chemical_system_energy_above_hull: 基于化学系统和 DFT 能量高于凸包联合条件微调的模型
检查点位于 checkpoints/<model_name>,也可以在 Hugging Face 上获取。默认情况下,它们会在请求时从 Huggingface 下载。您也可以通过以下命令手动从 Git LFS 下载:
git lfs pull -I checkpoints/<model_name> --exclude=""
[!注意] 提供的检查点是使用此存储库重新训练的,因此与论文中使用的检查点不完全相同。结果可能会略有偏差。
生成材料
无条件生成
要从预训练的基础模型中采样,请运行以下命令:
export MODEL_NAME=mattergen_base
export RESULTS_PATH=results/ # 样本将写入此目录
# 生成 batch_size * num_batches 个样本
mattergen-generate $RESULTS_PATH --pretrained-name=$MODEL_NAME --batch_size=16 --num_batches 1
该脚本将在 $RESULTS_PATH 中写入以下文件:
generated_crystals_cif.zip: 包含每个生成结构的单个.cif文件的 ZIP 文件。generated_crystals.extxyz: 包含各个生成结构作为帧的单个文件。- 如果
--record-trajectories == True(默认值):generated_trajectories.zip: 包含每个生成结构的完整去噪轨迹的.extxyz文件的 ZIP 文件。
[!提示] 为了获得最佳效率,请将批处理大小增加到您的 GPU 可以承受的最大值,而不会耗尽内存。
[!注意] 要从您自己训练的模型中采样,请将
--pretrained-name=$MODEL_NAME替换为--model_path=$MODEL_PATH,并填写您的模型位置以替换$MODEL_PATH。
属性条件生成
使用微调模型,您可以根据目标属性生成材料。 例如,要从基于磁密度训练的模型中采样,可以运行以下命令:
export MODEL_NAME=dft_mag_density
export RESULTS_PATH="results/$MODEL_NAME/" # 样本将写入此目录,例如 `results/dft_mag_density`
# 使用目标磁密度为 0.15 生成条件样本
mattergen-generate $RESULTS_PATH --pretrained-name=$MODEL_NAME --batch_size=16 --properties_to_condition_on="{'dft_mag_density': 0.15}" --diffusion_guidance_factor=2.0
[!提示] 参数
--diffusion-guidance-factor对应于 classifier-free diffusion guidance 中的 $\gamma$ 参数。将其设置为零对应于无条件生成,进一步增加它往往会生成更符合输入属性值的样本,但会牺牲样本的多样性和真实性。
多属性条件生成
您还可以根据多个属性生成材料。例如,您可以使用位于 checkpoints/chemical_system_energy_above_hull 的预训练模型,根据化学系统和能量高于凸包进行生成,或者使用位于 checkpoints/dft_mag_density_hhi_score 的模型,根据 HHI 分数 和磁密度进行联合条件生成。
根据您的具体需求调整以下命令:
export MODEL_NAME=chemical_system_energy_above_hull
export RESULTS_PATH="results/$MODEL_NAME/" # 样本将写入此目录,例如 `results/dft_mag_density`
mattergen-generate $RESULTS_PATH --pretrained-name=$MODEL_NAME --batch_size=16 --properties_to_condition_on="{'energy_above_hull': 0.05, 'chemical_system': 'Li-O'}" --diffusion_guidance_factor=2.0
评估
一旦你生成了一个包含在 $RESULTS_PATH 中的结构列表(无论是使用 MatterGen 还是其他方法),你可以使用默认的 MatterSim 机器学习力场(MLFF,Machine Learning Force Field,请参见 仓库)对这些结构进行弛豫,并通过以下命令计算新颖性、独特性、稳定性(使用 MatterSim 估计的能量)及其他指标:
git lfs pull -I data-release/alex-mp/reference_MP2020correction.gz --exclude="" # 首先从 Git LFS 下载 MP2020 参考数据集
mattergen-evaluate --structures_path=$RESULTS_PATH --relax=True --structure_matcher='disordered' --save_as="$RESULTS_PATH/metrics.json"
如果你想在应用 TRI2024 校正方案时使用参考数据集(推荐),请改为运行以下命令:
git lfs pull -I data-release/alex-mp/reference_TRI2024correction.gz --exclude="" # 下载 TRI2024 参考数据集
mattergen-evaluate --structures_path=$RESULTS_PATH --relax=True --structure_matcher='disordered' --save_as="$RESULTS_PATH/metrics.json" --reference_dataset_path="data-release/alex-mp/reference_TRI2024correction.gz"
该脚本会将包含指标结果的 metrics.json 写入 $RESULTS_PATH 并将其打印到你的控制台。
[!重要] 此存储库中的评估脚本使用了 MatterSim,一种机器学习力场(MLFF),用于弛豫结构并通过 MatterSim 预测的能量评估其稳定性。虽然这种方法比基于密度泛函理论(DFT,Density Functional Theory)的评估快几个数量级,无需许可证即可运行评估,并且通常具有高精度,但仍有一些重要的注意事项:(1) 在 MatterGen 论文中,我们使用 DFT 来评估所有模型和基线生成的结构;(2) DFT 更加准确和可靠,尤其是在不太常见的化学体系中。因此,使用此评估代码获得的评估结果可能与 DFT 评估的结果不同;我们建议在得出结论之前,使用 DFT 确认通过 MLFF 获得的结果。
[!提示] 默认情况下,这会使用
MatterSim-v1-1M。如果你想使用更大的MatterSim-v1-5M模型,可以添加--potential_load_path="MatterSim-v1.0.0-5M.pth"参数。你还可以查看 MatterSim 仓库 获取模型的最新版本。
如果相反,你已经通过其他方式(例如 DFT)弛豫了结构并获得了弛豫后的总能量,则可以通过以下方式评估指标:
git lfs pull -I data-release/alex-mp/reference_MP2020correction.gz --exclude="" # 首先从 Git LFS 下载参考数据集
mattergen-evaluate --structures_path=$RESULTS_PATH --energies_path='energies.npy' --relax=False --structure_matcher='disordered' --save_as='metrics'
该脚本将尝试按照以下优先顺序从磁盘读取结构:
- 如果
$RESULTS_PATH指向一个.xyz或.extxyz文件,它将直接读取该文件,并假设每一帧是一个不同的结构。 - 如果
$RESULTS_PATH指向一个包含.cif文件的.zip文件,它将首先解压然后读取 cif 文件。 - 如果
$RESULTS_PATH指向一个目录,它将按照os.listdir中出现的顺序读取所有的.cif、.xyz或.extxyz文件。
在这里,我们期望 energies.npy 是一个 NumPy 数组,其中的条目为 float 类型的能量,顺序与从 $RESULTS_PATH 读取的结构相同。
[!重要] 对于任何超出与现有文献基准测试的任务,我们建议使用 TRI2024 校正方案和参考数据集。为此,请运行:
git lfs pull -I data-release/alex-mp/reference_TRI2024correction.gz --exclude="" # 首先从 Git LFS 下载参考数据集
mattergen-evaluate --structures_path=$RESULTS_PATH --energies_path='energies.npy' --relax=False --structure_matcher='disordered' --save_as='metrics' --energy_correction_scheme="TRI2024" --reference_dataset_path="data-release/alex-mp/reference_TRI2024correction.gz"
如果你想保存弛豫后的结构及其能量、力和应力,可以在脚本调用中添加 --structures_output_path=YOUR_PATH,如下所示:
mattergen-evaluate --structures_path=$RESULTS_PATH --relax=True --structure_matcher='disordered' --save_as='metrics' --structures_output_path="relaxed_structures.extxyz"
如果你想获取每个结构的指标(例如,每个晶体的 energy_above_hull 而不仅仅是平均值),可以添加 --save_detailed_as 来保存包含每个结构值的 JSON 文件:
mattergen-evaluate --structures_path=$RESULTS_PATH --relax=True --structure_matcher='disordered' --save_as='metrics.json' --save_detailed_as='detailed_metrics.json'
详细的指标文件包含每个结构的 energy_above_hull、self_consistent_energy_above_hull、stability、novelty、uniqueness 和其他指标的值。
基准测试
在 plot_benchmark_results.ipynb 中,我们提供了一个 Jupyter 笔记本来生成类似于论文中图 2e 和 2f 的图表。我们进一步提供了分析多个基线生成样本所得的指标结果,位于 benchmark/metrics。你可以通过将 mattergen-evaluate 生成的指标 JSON 文件复制到同一文件夹来添加你自己模型的结果。再次提醒,这些结果是通过 MatterSim 弛豫和能量获得的,因此结果将与通过 DFT 获得的结果不同(例如,如论文中的结果)。
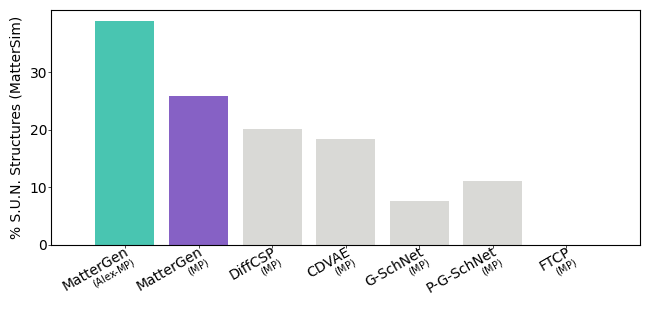
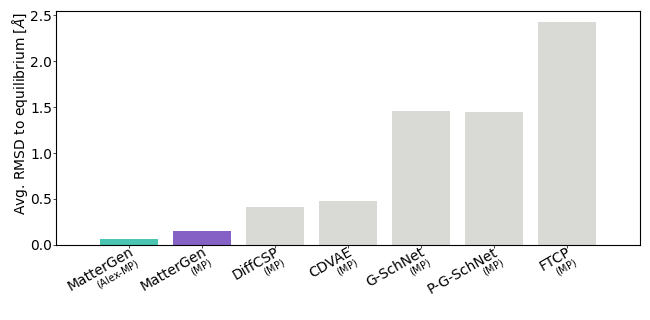
| 模型 | % S.U.N. | RMSD | % 稳定 | % 独特 | % 新颖 |
|---|---|---|---|---|---|
| MatterGen | 38.57 | 0.021 | 74.41 | 100.0 | 61.96 |
| MatterGen MP20 | 22.27 | 0.110 | 42.19 | 100.0 | 75.44 |
| DiffCSP Alex-MP-20 | 33.27 | 0.104 | 63.33 | 99.90 | 66.94 |
| DiffCSP MP20 | 12.71 | 0.232 | 36.23 | 100.0 | 70.73 |
| CDVAE | 13.99 | 0.359 | 19.31 | 100.0 | 92.00 |
| FTCP | 0.0 | 1.492 | 0.0 | 100.0 | 100.0 |
| G-SchNet | 0.98 | 1.347 | 1.63 | 100.0 | 98.23 |
| P-G-SchNet | 1.29 | 1.360 | 3.11 | 100.0 | 88.40 |
使用您自己的参考数据集进行评估
[!重要] 如果您计划使用 MatterSim(物质模拟器)来评估生成结构的稳定性,那么您提供的参考数据集必须包含与 MatterSim 兼容的能量值, 这意味着这些能量值应为根据 Materials Project(材料项目)兼容性方案计算的 DFT(密度泛函理论)能量,或者是直接通过 MatterSim 计算的能量。
如果您想使用自定义数据集进行评估,则首先需要将其序列化并保存,操作如下:
from mattergen.evaluation.reference.reference_dataset import ReferenceDataset
from mattergen.evaluation.reference.reference_dataset_serializer import LMDBGZSerializer
reference_dataset = ReferenceDataset.from_entries(name="my_reference_dataset", entries=entries)
LMDBGZSerializer().serialize(reference_dataset, "path_to_file.gz")
其中 entries 是一个包含结构-能量对的 pymatgen.entries.computed_entries.ComputedStructureEntry 对象列表。
默认情况下,我们在评估过程中会对所有输入结构应用 MaterialsProject2020Compatibility 能量校正方案,并假设参考数据集已使用相同的兼容性方案进行了预处理。
因此,除非您已经完成了此步骤,否则应按以下方式获取自定义参考数据集的 entries 对象:
from mattergen.evaluation.utils.vasprunlike import VasprunLike
from pymatgen.entries.compatibility import MaterialsProject2020Compatibility
entries = []
for structure, energy in zip(structures, energies)
vasprun_like = VasprunLike(structure=structure, energy=energy)
entries.append(vasprun_like.get_computed_entry(
inc_structure=True, energy_correction_scheme=MaterialsProject2020Compatibility()
))
[!注意] 由于 MaterialsProject2020Compatibility 方案存在一些已知问题,我们建议使用
TRI110Compatibility2024参考数据集和校正方案来评估基准测试之外材料的稳定性。 为此,请运行以下代码:
from mattergen.evaluation.utils.vasprunlike import VasprunLike
from mattergen.evaluation.reference.correction_schemes import TRI110Compatibility2024
entries = []
for structure, energy in zip(structures, energies)
vasprun_like = VasprunLike(structure=structure, energy=energy)
entries.append(vasprun_like.get_computed_entry(
inc_structure=True, energy_correction_scheme=TRI110Compatibility2024()
))
自行训练 MatterGen
在从头开始训练 MatterGen 之前,我们需要解压并预处理数据集文件。
预处理用于训练的数据集
您可以为 mp_20 数据集运行以下命令:
# 从 LFS 下载文件
git lfs pull -I data-release/mp-20/ --exclude=""
unzip data-release/mp-20/mp_20.zip -d datasets
csv-to-dataset --csv-folder datasets/mp_20/ --dataset-name mp_20 --cache-folder datasets/cache
您将在 datasets/cache/mp_20 中获得预处理后的数据文件。
要预处理我们的较大数据集 alex_mp_20,请运行:
# 从 LFS 下载文件
git lfs pull -I data-release/alex-mp/alex_mp_20.zip --exclude=""
unzip data-release/alex-mp/alex_mp_20.zip -d datasets
csv-to-dataset --csv-folder datasets/alex_mp_20/ --dataset-name alex_mp_20 --cache-folder datasets/cache
这将花费一些时间(约 1 小时)。您将在 datasets/cache/alex_mp_20 中获得预处理后的数据文件。
训练
您可以使用以下命令在 mp_20 数据集上训练 MatterGen 基础模型:
mattergen-train data_module=mp_20 ~trainer.logger
[!注意] 对于 Apple Silicon(苹果芯片)训练,请在上述命令中添加
~trainer.strategy trainer.accelerator=mps。
验证损失 (loss_val) 应在 360 个 epoch(约 80k 步)后达到 0.4。输出检查点可以在 outputs/singlerun/${now:%Y-%m-%d}/${now:%H-%M-%S} 找到。我们称此文件夹为 $MODEL_PATH 以供将来引用。
[!注意] 我们使用
hydra来配置训练和采样任务。分层配置可以在mattergen/conf下找到。接下来我们将使用hydra的配置覆盖功能通过 CLI 更新这些配置。有关配置覆盖语法的介绍,请参阅hydra文档。
[!提示] 默认情况下,我们通过
~trainer.logger配置覆盖禁用 Weights & Biases (W&B) 日志记录。您可以通过移除此覆盖来启用它。在mattergen/conf/trainer/default.yaml中,您可以输入您的 W&B 日志信息或指定您自己的日志记录器。
要在 alex_mp_20 数据集上训练 MatterGen 基础模型,请使用以下命令:
mattergen-train data_module=alex_mp_20 ~trainer.logger trainer.accumulate_grad_batches=4
[!注意] 对于 Apple Silicon 训练,请在上述命令中添加
~trainer.strategy trainer.accelerator=mps。
[!提示] 请注意,单个 GPU 的内存通常不足以支持 512 的批量大小,因此我们在 4 个批次上累积梯度。如果仍然内存不足,请进一步增加此值。
晶体结构预测
尽管这不是我们论文的重点,您也可以在晶体结构预测(CSP,Crystal Structure Prediction)模式下训练 MatterGen,在这种模式下,它在生成过程中不会去噪原子类型。
这使您能够基于特定化学式进行生成。您可以通过向 run.py 传递 --config-name=csp 来在此模式下训练 MatterGen。
要从此模型中采样,请向 generate.py 传递 --target_compositions=['{"<element1>": <number_of_element1_atoms>, "<element2>": <number_of_element2_atoms>, ..., "<elementN>": <number_of_elementN_atoms>}'] --sampling-config-name=csp。
例如,目标组成可以是 --target_compositions=['{"Na": 1, "Cl": 1}']。
在属性数据上进行微调
你可以使用以下命令对 MatterGen 基础模型(MatterGen base model)进行微调。
export PROPERTY=dft_mag_density
mattergen-finetune adapter.pretrained_name=mattergen_base data_module=mp_20 +lightning_module/diffusion_module/model/property_embeddings@adapter.adapter.property_embeddings_adapt.$PROPERTY=$PROPERTY ~trainer.logger data_module.properties=["$PROPERTY"]
dft_mag_density 表示用于微调的目标属性。你也可以通过替换 adapter.pretrained_name=mattergen_base 为 adapter.model_path=$MODEL_PATH 来微调你自己训练的模型,将 $MODEL_PATH 替换为你模型的实际路径。
[!注意] 如果在 Apple Silicon 上进行训练,请在上述命令中添加
~trainer.strategy trainer.accelerator=mps。
[!提示] 你可以选择数据集中可用的任何属性。支持的属性列表请参见
mattergen/conf/data_module/mp_20.yaml或mattergen/conf/data_module/alex_mp_20.yaml。你还可以添加自己的自定义属性数据。有关说明请参见下方。
多属性微调
你还可以对多个属性进行 MatterGen 微调。例如,要对 dft_mag_density 和 dft_band_gap 进行微调,可以使用以下命令。
export PROPERTY1=dft_mag_density
export PROPERTY2=dft_band_gap
export MODEL_NAME=mattergen_base
mattergen-finetune adapter.pretrained_name=$MODEL_NAME data_module=mp_20 +lightning_module/diffusion_module/model/property_embeddings@adapter.adapter.property_embeddings_adapt.$PROPERTY1=$PROPERTY1 +lightning_module/diffusion_module/model/property_embeddings@adapter.adapter.property_embeddings_adapt.$PROPERTY2=$PROPERTY2 ~trainer.logger data_module.properties=["$PROPERTY1","$PROPERTY2"]
[!提示] 按照以下方式添加更多属性:
- 添加覆盖项:
+lightning_module/diffusion_module/model/property_embeddings@adapter.adapter.property_embeddings_adapt.<my_property>=<my_property>- 将
<my_property>添加到data_module.properties=["$PROPERTY1","$PROPERTY2",...,<my_property>]覆盖项中。
[!注意] 如果在 Apple Silicon 上进行训练,请在上述命令中添加
~trainer.strategy trainer.accelerator=mps。
在你自己的属性数据上进行微调
你还可以在自己的属性数据上对 MatterGen 进行微调。本质上,你需要的是一个子集数据的属性值(通常是 float 类型),例如 alex_mp_20。按照以下步骤操作:
- 将你的属性名称添加到
mattergen/common/utils/globals.py文件中的PROPERTY_SOURCE_IDS列表中。 - 在你要训练的数据集(例如
datasets/alex_mp_20/train.csv和datasets/alex_mp_20/val.csv)中添加一个以此名称命名的新列(需要完成预处理步骤)。 - 重新运行 CSV 到数据集脚本
csv-to-dataset --csv-folder datasets/<MY_DATASET>/ --dataset-name <MY_DATASET> --cache-folder datasets/cache,将你的数据集名称替换为MY_DATASET。 - 在
mattergen/conf/lightning_module/diffusion_module/model/property_embeddings中添加一个<your_property>.yaml配置文件。如果你添加的是浮点值属性,可以复制现有的配置文件,例如dft_mag_density.yaml。更复杂的属性则需要创建自己的自定义PropertyEmbedding子类,例如参考space_group或chemical_system配置。 - 按照属性数据微调说明,并以与现有属性(如
dft_mag_density)相同的方式引用你自己的属性。
数据发布
我们提供了用于训练和评估 MatterGen 的数据集。更多详细信息和许可信息,请参阅 data-release 下的相应 README 文件。
训练数据集
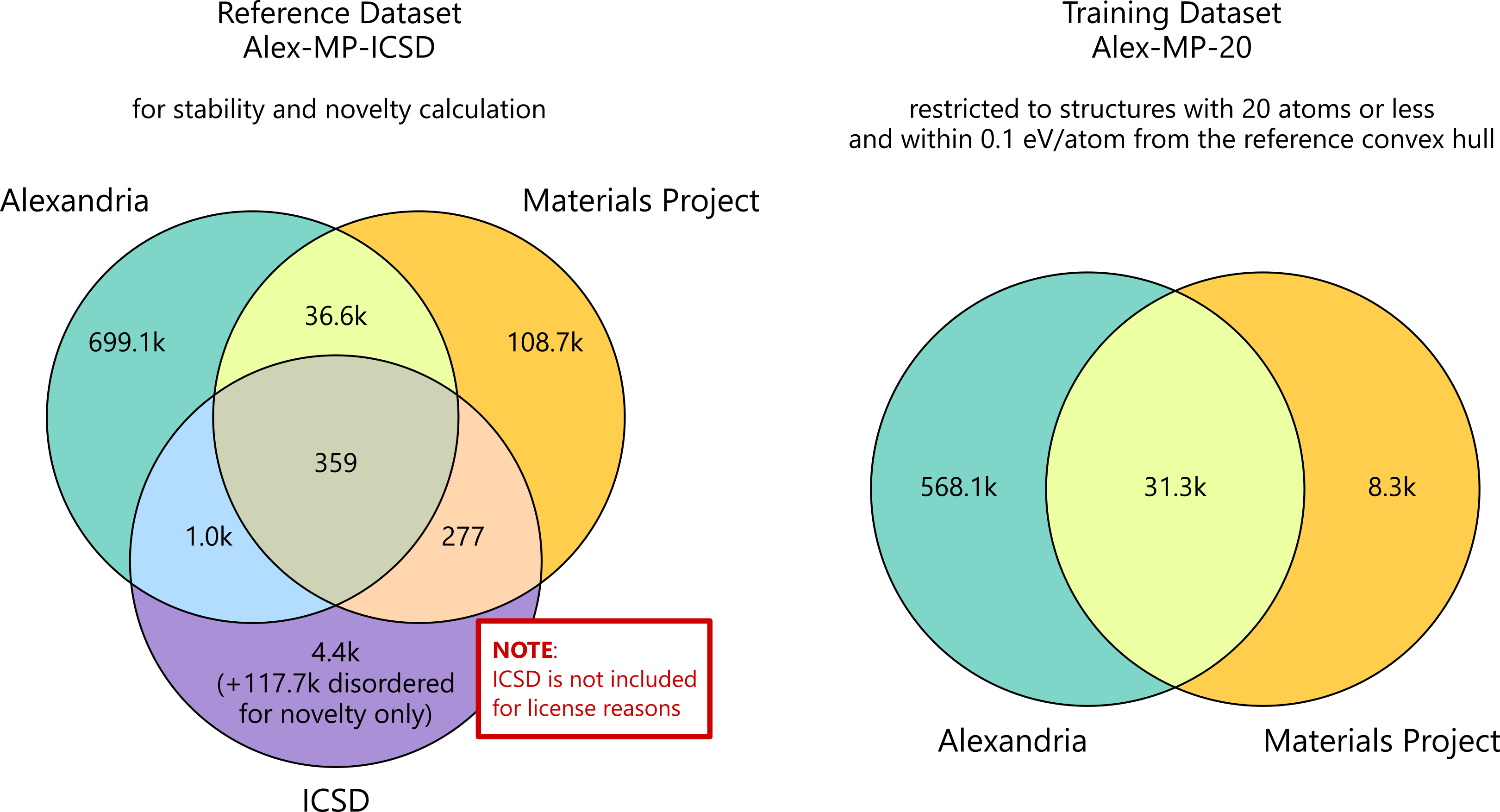
- MP-20 (Jain et al., 2013):包含 45k 种通用无机材料,包括大多数实验已知的、晶胞中原子数不超过 20 的材料。
- Alex-MP-20:由来自 MP-20 和 Alexandria (Schmidt et al. 2022) 的约 600k 种结构组成的训练数据集,晶胞内原子数最多为 20 且凸包能量低于 0.1 eV/atom。更多信息请参见下文的维恩图以及 MatterGen 论文。
参考数据集
我们进一步提供了 Alex-MP 参考数据集,可用于评估生成样本的新颖性和稳定性。 参考集包含 845,997 种结构及其 DFT 能量。有关训练和参考数据集组成的更多详细信息,请参见以下维恩图。
[!注意] 出于许可原因,我们无法分享 4.4k 有序 + 117.7k 无序 ICSD 结构,因此结果可能与论文中的有所不同。
CIF 文件和实验测量
data-release 目录还包含论文中展示的所有结构的 CIF 文件,以及论文中介绍的 TaCr2O6 样品的 XPS、XRD 和纳米压痕测量数据。
引用
如果你使用我们的代码、模型、数据或评估管道,请考虑引用我们的工作:
@article{MatterGen2025,
author = {Zeni, Claudio and Pinsler, Robert and Z{\"u}gner, Daniel and Fowler, Andrew and Horton, Matthew and Fu, Xiang and Wang, Zilong and Shysheya, Aliaksandra and Crabb{\'e}, Jonathan and Ueda, Shoko and Sordillo, Roberto and Sun, Lixin and Smith, Jake and Nguyen, Bichlien and Schulz, Hannes and Lewis, Sarah and Huang, Chin-Wei and Lu, Ziheng and Zhou, Yichi and Yang, Han and Hao, Hongxia and Li, Jielan and Yang, Chunlei and Li, Wenjie and Tomioka, Ryota and Xie, Tian},
journal = {Nature},
title = {A generative model for inorganic materials design},
year = {2025},
doi = {10.1038/s41586-025-08628-5},
}
商标
本项目可能包含某些项目、产品或服务的商标或标志。 Microsoft 商标或标志的授权使用需遵守并遵循 Microsoft 的商标和品牌指南。 在修改版本的项目中使用 Microsoft 商标或标志不得引起混淆或暗示 Microsoft 赞助。 任何第三方商标或标志的使用均需遵守这些第三方的政策。
负责任的人工智能透明性文档
负责任的人工智能透明性文档可以在这里找到 这里。
联系我们
如果您有任何这里未涵盖的问题,请在讨论区的问答部分提问。 如果您想报告错误或提出新功能,请使用模板创建一个问题和/或发起一个拉取请求。
版本历史
v1.0.32025/07/23v1.0.22025/07/23v1.0.12025/07/23v1.0.02025/01/17常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。