PhiCookBook
PhiCookBook 是微软官方推出的 Phi 系列小语言模型(SLM)实战指南,旨在帮助开发者快速上手并应用这些高性能开源模型。作为目前性价比极高的小语言模型家族,Phi 在语言理解、逻辑推理、代码生成及数学计算等多个基准测试中,表现不仅超越同体量模型,甚至媲美更大规模的模型。
许多开发者在资源受限的环境下,往往难以部署大型 AI 模型。PhiCookBook 通过提供丰富的动手示例和代码模板,解决了这一痛点,让用户能够轻松将 Phi 模型部署到云端或边缘设备,在有限的算力条件下构建高效的生成式 AI 应用。无论是进行多语言处理、文本对话,还是处理图像与音频任务,这里都能找到对应的实践方案。
这份资源特别适合软件开发者、AI 研究人员以及希望探索轻量级大模型应用的技术爱好者。其独特亮点在于提供了开箱即用的开发环境支持,用户可直接通过 GitHub Codespaces 或 VS Code 容器一键启动项目,无需繁琐配置。此外,社区还通过自动化工作流支持全球数十种语言的文档翻译,确保了内容的广泛可访问性与实时更新。无论你是想尝试最新的 SLM 技术,还是寻求低成本的高效 AI 解决方案,PhiCookBook 都是理想的入门起点。
使用场景
一家初创教育科技公司希望在低成本边缘设备(如树莓派)上部署一个支持多语言辅导和基础代码讲解的 AI 助教,但团队算力预算极其有限。
没有 PhiCookBook 时
- 模型选型困难:开发者在海量开源模型中难以快速找到既能在低算力设备运行,又具备优秀推理和编码能力的小型语言模型(SLM)。
- 环境配置繁琐:手动搭建推理环境耗时耗力,缺乏针对边缘设备优化的现成部署脚本,导致项目启动阶段就遭遇技术瓶颈。
- 多语言支持缺失:自行训练或微调模型以支持全球多种语言成本高昂,且难以保证小模型在非英语场景下的表现。
- 开发门槛高:缺乏具体的代码示例和最佳实践指南,团队成员需要从零摸索如何将模型集成到实际应用中,试错成本极高。
使用 PhiCookBook 后
- 精准模型匹配:直接获取微软官方推荐的 Phi 系列模型指南,确认其在同尺寸下推理与编码能力的领先地位,完美契合边缘计算需求。
- 一键快速启动:利用提供的 GitHub Codespaces 和 Dev Containers 配置,几分钟内即可在本地或云端复现完整的开发与运行环境。
- 原生多语言能力:借助仓库中覆盖全球数十种语言的自动化翻译文档和示例,轻松实现多语言辅导功能,无需额外训练。
- 实战代码参考:直接复用书中关于文本生成、逻辑推理及代码解释的动手示例,大幅缩短从概念验证到产品原型的开发周期。
PhiCookBook 让开发者能够以最低的成本和最快的速度,将微软顶尖的小型语言模型能力转化为落地的边缘 AI 应用。
运行环境要求
- Linux
- macOS
- Windows
- 非必需(支持 CPU 推理)
- 若使用 GPU 加速,支持 NVIDIA (CUDA)、Apple Silicon (MLX)、Intel (OpenVINO) 及 WebGPU
- 具体显存需求取决于模型版本(Phi-3/3.5/4)及量化程度,小模型可在低显存或集成显卡上运行
未说明(取决于具体模型大小和是否量化,边缘设备示例表明可在有限内存下运行)
快速开始
Phi 烹饪书:使用微软 Phi 模型的实战示例
![]()




![]()



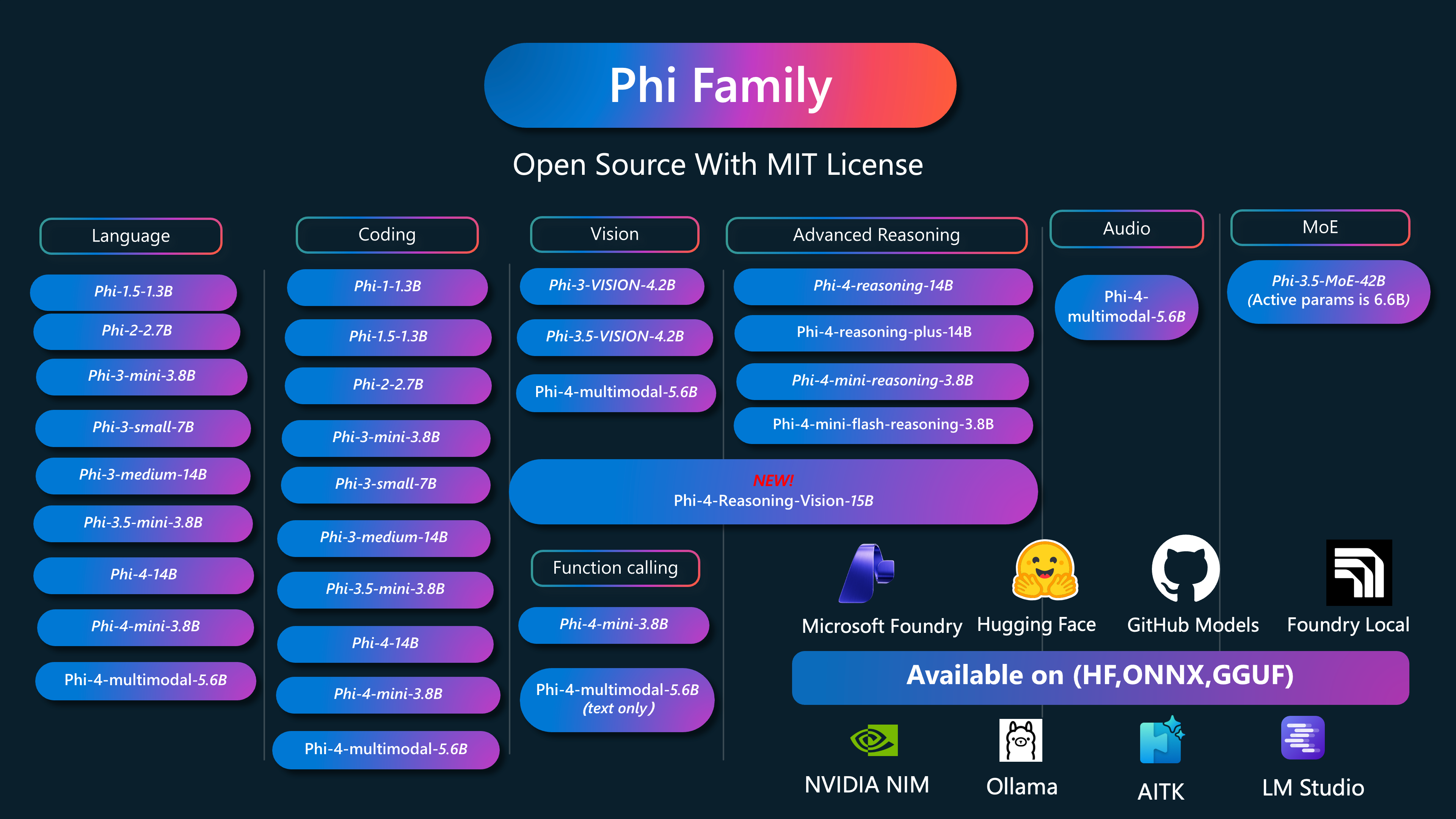
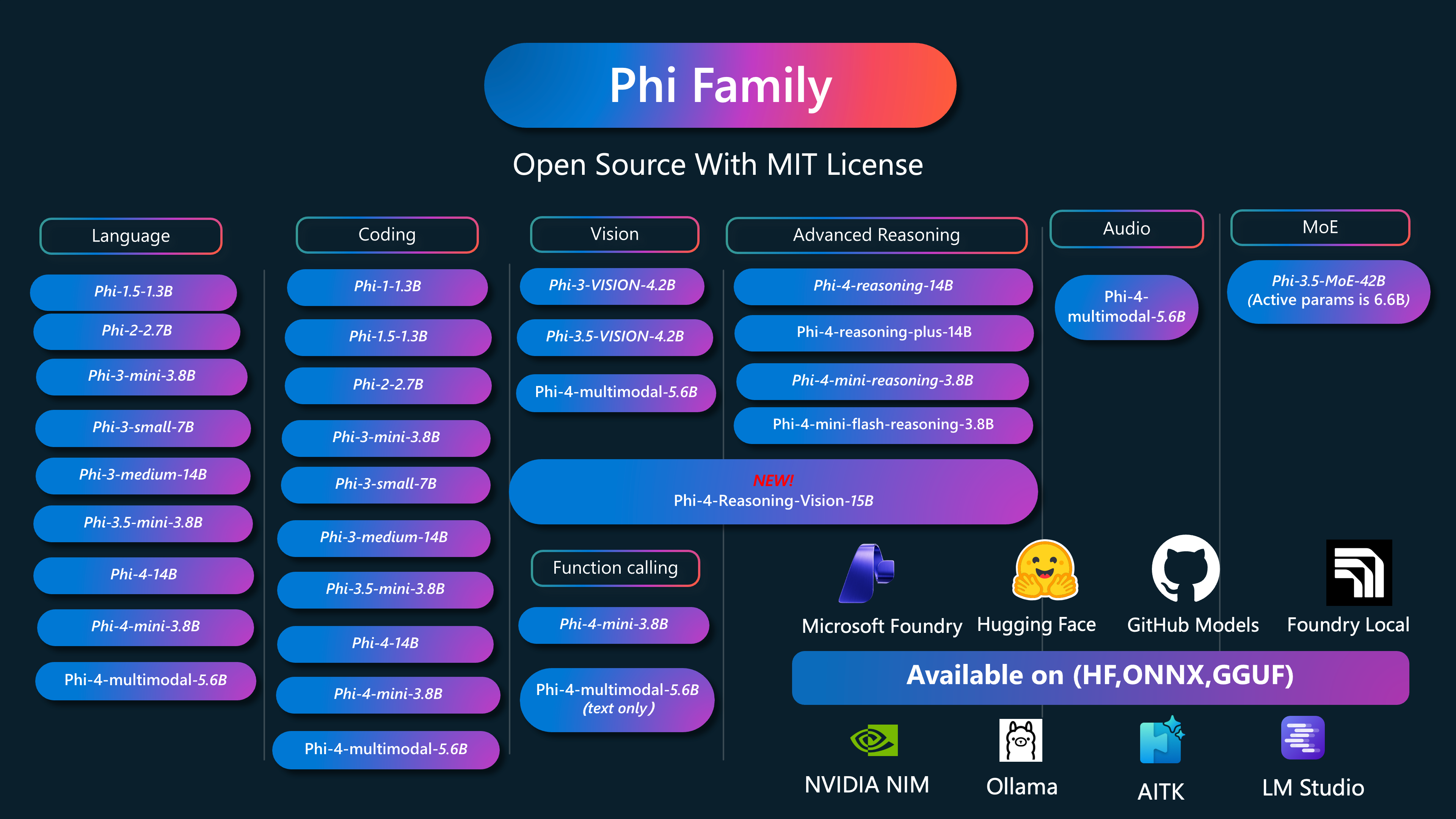
Phi 是由微软开发的一系列开源 AI 模型。
Phi 目前是最强大且最具成本效益的小型语言模型 (SLM),在多语言、推理、文本/聊天生成、编码、图像、音频等场景中均表现出色。
您可以将 Phi 部署到云端或边缘设备上,并且只需有限的计算资源即可轻松构建生成式 AI 应用程序。
请按照以下步骤开始使用这些资源:
- 分叉仓库:点击
- 克隆仓库:
git clone https://github.com/microsoft/PhiCookBook.git - 加入 Microsoft AI Discord 社区,与专家和开发者交流
🌐 多语言支持
通过 GitHub Action 支持(自动化且始终保持最新)
阿拉伯语 (Arabic) | 孟加拉语 (Bengali) | 保加利亚语 (Bulgarian) | 缅甸语 (Burmese) | 简体中文 (Chinese, Simplified) | 繁体中文(香港)(Chinese, Traditional, Hong Kong) | 繁体中文(澳门)(Chinese, Traditional, Macau) | 繁体中文(台湾)(Chinese, Traditional, Taiwan) | 克罗地亚语 (Croatian) | 捷克语 (Czech) | 丹麦语 (Danish) | 荷兰语 (Dutch) | 爱沙尼亚语 (Estonian) | 芬兰语 (Finnish) | 法语 (French) | 德语 (German) | 希腊语 (Greek) | 希伯来语 (Hebrew) | 印地语 (Hindi) | 匈牙利语 (Hungarian) | 印度尼西亚语 (Indonesian) | 意大利语 (Italian) | 日语 (Japanese) | 卡纳达语 (Kannada) | 韩语 (Korean) | 立陶宛语 (Lithuanian) | 马来语 (Malay) | 马拉雅拉姆语 (Malayalam) | 马拉地语 (Marathi) | 尼泊尔语 (Nepali) | 尼日利亚皮钦语 (Nigerian Pidgin) | 挪威语 (Norwegian) | 波斯语 (Persian, Farsi) | 波兰语 (Polish) | 巴西葡萄牙语 (Portuguese, Brazil) | 葡萄牙语 (Portugal) | 旁遮普语 (Gurmukhi) | 罗马尼亚语 (Romanian) | 俄语 (Russian) | 塞尔维亚语(西里尔字母)(Serbian, Cyrillic) | 斯洛伐克语 (Slovak) | 斯洛文尼亚语 (Slovenian) | 西班牙语 (Spanish) | 斯瓦希里语 (Swahili) | 瑞典语 (Swedish) | 他加禄语 (Tagalog, Filipino) | 泰米尔语 (Tamil) | 泰卢固语 (Telugu) | 泰语 (Thai) | 土耳其语 (Turkish) | 乌克兰语 (Ukrainian) | 乌尔都语 (Urdu) | 越南语 (Vietnamese)
更倾向于本地克隆吗?
此仓库包含 50 多种语言的翻译,这会显著增加下载大小。若想不包含翻译进行克隆,请使用稀疏检出功能:
Bash / macOS / Linux:
git clone --filter=blob:none --sparse https://github.com/microsoft/PhiCookBook.git cd PhiCookBook git sparse-checkout set --no-cone '/*' '!translations' '!translated_images'CMD(Windows):
git clone --filter=blob:none --sparse https://github.com/microsoft/PhiCookBook.git cd PhiCookBook git sparse-checkout set --no-cone "/*" "!translations" "!translated_images"这样可以快速下载所需内容,完成课程学习。
目录
引言
不同环境下的 Phi 推理
Phi 系列的推理
Phi 的评估
使用 Azure AI Search 的 RAG
Phi 应用开发示例
文本与聊天应用
- Phi-4 示例
- [📓] 使用 Phi-4-mini ONNX 模型进行聊天
- .NET 中使用本地 Phi-4 ONNX 模型进行聊天
- 使用语义核构建 .NET 控制台应用程序,与 Phi-4 ONNX 进行聊天
- Phi-3 / 3.5 示例
- 使用 Phi3、ONNX Runtime Web 和 WebGPU 在浏览器中实现本地聊天机器人
- OpenVino 聊天
- 多模型交互:Phi-3-mini 与 OpenAI Whisper
- MLFlow — 构建封装并使用 Phi-3 与 MLFlow
- 模型优化 — 如何使用 Olive 为 ONNX Runtime Web 优化 Phi-3-min 模型
- WinUI3 应用程序,搭载 Phi-3 mini-4k-instruct-onnx
- WinUI3 多模型 AI 驱动笔记应用示例
- 使用 Prompt flow 微调并集成自定义 Phi-3 模型
- 在 Microsoft Foundry 中使用 Prompt flow 微调并集成自定义 Phi-3 模型
- 在 Microsoft Foundry 中评估微调后的 Phi-3 / Phi-3.5 模型,重点关注微软的负责任 AI 原则
- [📓] Phi-3.5-mini-instruct 语言预测示例(中文/英文)
- Phi-3.5-Instruct WebGPU RAG 聊天机器人
- 利用 Windows GPU 创建基于 Prompt flow 的解决方案,结合 Phi-3.5-Instruct ONNX
- 使用 Microsoft Phi-3.5 tflite 开发 Android 应用程序
- 使用本地 ONNX Phi-3 模型的 Q&A .NET 示例,借助 Microsoft.ML.OnnxRuntime
- 使用语义核和 Phi-3 构建 .NET 控制台聊天应用程序
基于 Azure AI 推理 SDK 的代码示例
高级推理样本
Phi-4 样本
演示
视觉样本
- Phi-4 样本
- Phi-3 / 3.5 样本
推理-视觉样本
- Phi-4-Reasoning-Vision-15B
数学样本
- Phi-4-Mini-Flash-Reasoning-Instruct 样本 使用 Phi-4-Mini-Flash-Reasoning-Instruct 的数学演示
音频样本
MOE 样本
函数调用样本
- Phi-4 样本 🆕
多模态混合样本
- Phi-4 样本 🆕
微调 Phi 样本
- 微调场景
- 微调与 RAG
- 让 Phi-3 成为行业专家的微调
- 使用 VS Code 的 AI 工具包微调 Phi-3
- 使用 Azure Machine Learning Service 微调 Phi-3
- 使用 Lora 微调 Phi-3
- 使用 QLora 微调 Phi-3
- 使用 Microsoft Foundry 微调 Phi-3
- 使用 Azure ML CLI/SDK 微调 Phi-3
- 使用 Microsoft Olive 微调
- 使用 Microsoft Olive 的实践实验室
- 使用 Weights and Bias 微调 Phi-3-vision
- 使用 Apple MLX 框架微调 Phi-3
- 官方支持下的 Phi-3-vision 微调
- 使用 Kaito AKS 和 Azure Containers(官方支持)微调 Phi-3
- Phi-3 和 3.5 Vision 的微调
实践实验室
学术研究论文和出版物
使用 Phi 模型
Phi 在 Microsoft Foundry 上
您可以学习如何使用 Microsoft Phi,并在不同的硬件设备上构建端到端解决方案。要亲自体验 Phi,可以从试用这些模型开始,并使用 Microsoft Foundry Azure AI 模型目录,根据您的场景自定义 Phi。更多信息请参阅《Microsoft Foundry 入门》(/md/02.QuickStart/AzureAIFoundry_QuickStart.md)。
游乐场 每个模型都有一个专门的游乐场来测试该模型 Azure AI Playground。
Phi 在 GitHub Models 上
您可以学习如何使用 Microsoft Phi,并在不同的硬件设备上构建端到端解决方案。要亲自体验 Phi,可以从试用该模型开始,并使用 GitHub 模型目录,根据您的场景自定义 Phi。更多信息请参阅《GitHub 模型目录入门》(/md/02.QuickStart/GitHubModel_QuickStart.md)。
游乐场 每个模型都有一个专门的 游乐场来测试模型。
Phi 在 Hugging Face 上
您也可以在 Hugging Face 上找到该模型。
游乐场 Hugging Chat 游乐场
🎒 其他课程
我们的团队还制作了其他课程!请查看:
LangChain
Azure / Edge / MCP / Agents
生成式 AI 系列
核心学习
Copilot 系列
负责任的人工智能
微软致力于帮助客户负责任地使用我们的 AI 产品,分享我们的经验教训,并通过透明度说明和影响评估等工具建立基于信任的合作关系。这些资源中的许多都可以在 https://aka.ms/RAI 上找到。 微软在负责任的人工智能方面的做法以我们的 AI 原则为基础,即公平性、可靠性和安全性、隐私与安全性、包容性、透明度以及问责制。
像本示例中使用的大型自然语言、图像和语音模型一样,它们可能会以不公平、不可靠或冒犯性的方式运行,从而造成危害。请查阅 Azure OpenAI 服务透明度说明,以了解相关风险和限制。
缓解这些风险的推荐方法是在您的架构中加入一个安全系统,该系统能够检测并阻止有害行为。Azure AI 内容安全 提供了一个独立的保护层,能够在应用程序和服务中检测用户生成和 AI 生成的有害内容。Azure AI 内容安全包括文本和图像 API,使您能够检测有害内容。在 Microsoft Foundry 中,内容安全服务允许您查看、探索并试用用于检测不同模态下有害内容的示例代码。以下 快速入门文档 将指导您如何向该服务发出请求。
另一个需要考虑的方面是整体应用程序性能。对于多模态和多模型的应用程序,我们认为性能是指系统能够按照您和用户的期望运行,包括不产生有害输出。使用 性能、质量、风险和安全评估器 来评估整个应用程序的性能非常重要。您还可以使用 自定义评估器 创建并进行评估。
您可以在开发环境中使用 Azure AI 评估 SDK 对您的 AI 应用程序进行评估。无论您使用测试数据集还是目标,您的生成式 AI 应用程序生成的内容都将通过内置评估器或您选择的自定义评估器进行定量测量。要开始使用 Azure AI 评估 SDK 来评估您的系统,您可以按照 快速入门指南 操作。执行评估后,您可以在 Microsoft Foundry 中可视化结果。
商标
该项目可能包含项目、产品或服务的商标或徽标。微软商标或徽标的授权使用须遵守并遵循 微软商标与品牌指南。 在该项目的修改版本中使用微软商标或徽标时,不得引起混淆或暗示微软的赞助。任何第三方商标或徽标的使用均应遵守该第三方的相关政策。
获取帮助
如果您在构建 AI 应用程序时遇到困难或有任何疑问,请加入:
如果您在构建过程中遇到产品反馈或错误,请访问:
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。