LLMLingua
LLMLingua 是一个用于压缩提示词(prompt)和键值缓存(KV-Cache)的开源工具,旨在提升大语言模型(LLM)的推理速度并增强其对关键信息的理解能力。它通过识别并去除提示中非必要的内容,实现高达 20 倍的压缩率,同时几乎不损失性能。
在处理长文本或复杂任务时,大模型往往需要消耗大量计算资源,导致推理速度变慢、成本上升。LLMLingua 有效解决了这一问题,使模型能更高效地聚焦于核心信息,从而加快响应速度并降低资源消耗。
LLMLingua 适合开发者、研究人员以及使用大模型进行推理优化的工程师。它已被集成到多个主流框架中,如 Prompt Flow、LangChain 和 LlamaIndex,方便用户直接调用。对于需要处理大量文本输入或希望优化推理效率的场景,例如 RAG(检索增强生成)、在线会议、思维链(CoT)和代码生成等,LLMLingua 都能提供显著帮助。
其独特之处在于采用轻量级预训练模型来识别冗余信息,并支持多种变体(如 LongLLMLingua 和 LLMLingua-2),进一步提升了压缩效率与适用范围。
使用场景
某在线客服平台的开发团队正在构建一个基于大语言模型(LLM)的智能问答系统,用于自动回答用户在电商平台上提出的各种咨询问题。他们需要处理大量来自用户的查询,并结合历史对话记录和产品信息生成准确、自然的回答。
没有 LLMLingua 时
- 每次生成回答前,系统需要将用户当前问题与历史对话记录拼接成一个长提示(prompt),导致提示长度经常超过 1000 tokens。
- 长提示显著增加了模型推理时间,单个请求的响应延迟高达 2-3 秒,影响用户体验。
- 在高并发场景下,服务器负载过高,导致系统响应变慢甚至出现超时现象。
- 提示中包含大量重复或冗余信息,但模型无法有效识别并过滤这些内容,造成资源浪费。
- 对于需要长上下文支持的复杂问题,模型性能下降明显,影响回答准确性。
使用 LLMLingua 后
- 系统通过 LLMLingua 对提示进行压缩,将平均提示长度减少至原来的 1/5,显著降低了计算开销。
- 推理速度提升 5 倍以上,单个请求的响应时间缩短至 0.4 秒以内,用户体验大幅提升。
- 在高并发情况下,服务器负载降低,系统稳定性增强,能够轻松应对流量高峰。
- 提示中的冗余信息被高效过滤,保留了关键信息,提高了模型对核心问题的理解能力。
- 即使面对复杂的多轮对话,模型也能保持较高的回答准确率,提升了整体服务质量。
核心价值:LLMLingua 通过高效的提示压缩技术,在不牺牲模型性能的前提下显著提升了推理效率和系统稳定性,为大规模 LLM 应用提供了实用的优化方案。
运行环境要求
- Linux
- macOS
- Windows
需要 NVIDIA GPU,显存 8GB+,CUDA 11.7+
16GB+
快速开始

LLMLingua系列 | 通过提示压缩高效向大语言模型传递信息
| 项目页面 | LLMLingua | LongLLMLingua | LLMLingua-2 | LLMLingua演示 | LLMLingua-2演示 |
https://github.com/microsoft/LLMLingua/assets/30883354/eb0ea70d-6d4c-4aa7-8977-61f94bb87438
新闻
- 🍩 [24/12/13] 我们很高兴地宣布发布以KV缓存为核心的分析工作——SCBench,该工作从KV缓存的角度评估长上下文方法。
- 👘 [24/09/16] 我们很高兴地宣布发布KV缓存卸载工作——RetrievalAttention,该工作通过向量检索加速长上下文大语言模型的推理。
- 🌀 [24/07/03] 我们很高兴地宣布发布MInference,以加速长上下文大语言模型的推理,可在A100上进行预填充时将推理延迟最多降低10倍,同时在100万令牌提示下保持准确!欲了解更多信息,请参阅我们的论文,访问项目页面。
- 🧩 LLMLingua已集成到Prompt flow中,这是一个用于基于大语言模型的AI应用的精简工具框架。
- 🦚 我们很高兴地宣布发布LLMLingua-2,其速度比LLMLingua提升3至6倍!欲了解更多信息,请参阅我们的论文,访问项目页面,并体验我们的演示。
- 👾 LLMLingua已集成到LangChain和LlamaIndex中,这两个是广泛使用的RAG框架。
- 🤳 讲座幻灯片已在AI Time Jan, 24中提供。
- 🖥 EMNLP'23幻灯片已在Session 5和BoF-6中提供。
- 📚 请查看我们的新博客文章,讨论通过提示压缩实现RAG优势与成本节约。脚本示例请见此处。
- 🎈 请访问我们的项目页面,了解RAG、在线会议、CoT和代码领域的实际案例研究。
- 👨🦯 请浏览我们的.examples目录,获取实用的应用示例,包括LLMLingua-2、RAG、在线会议、CoT、代码以及使用LlamaIndex的RAG。
简要概述
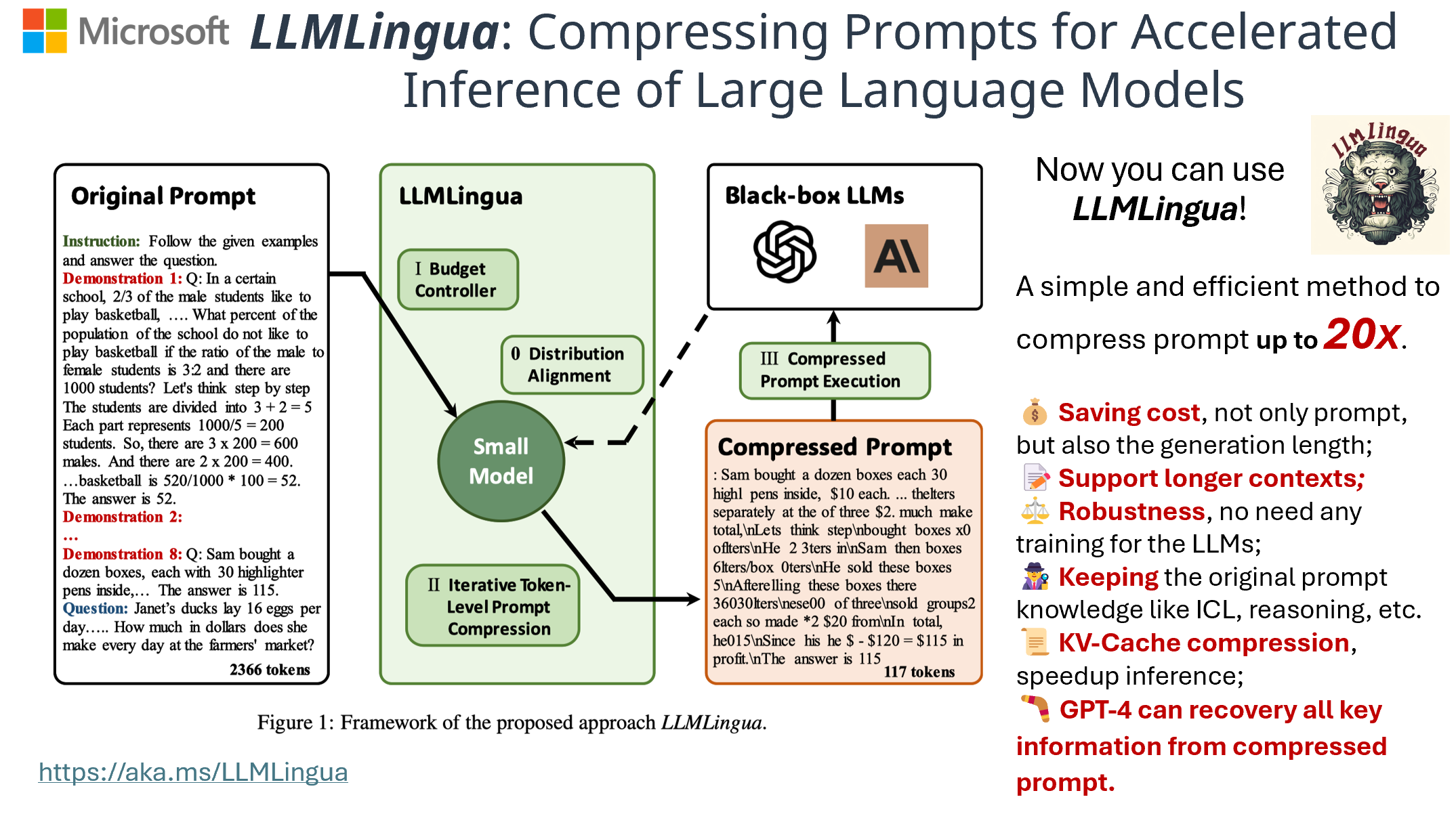
LLMLingua利用一个紧凑且训练有素的语言模型(例如GPT2-small、LLaMA-7B)来识别并移除提示中的非必要标记。这种方法能够实现对大型语言模型(LLMs)的高效推理,最高可实现20倍的压缩,同时几乎不损失性能。
- LLMLingua:为大型语言模型的加速推理压缩提示(EMNLP 2023)
江辉强、吴千慧、林钦耀、杨宇清和邱莉莉
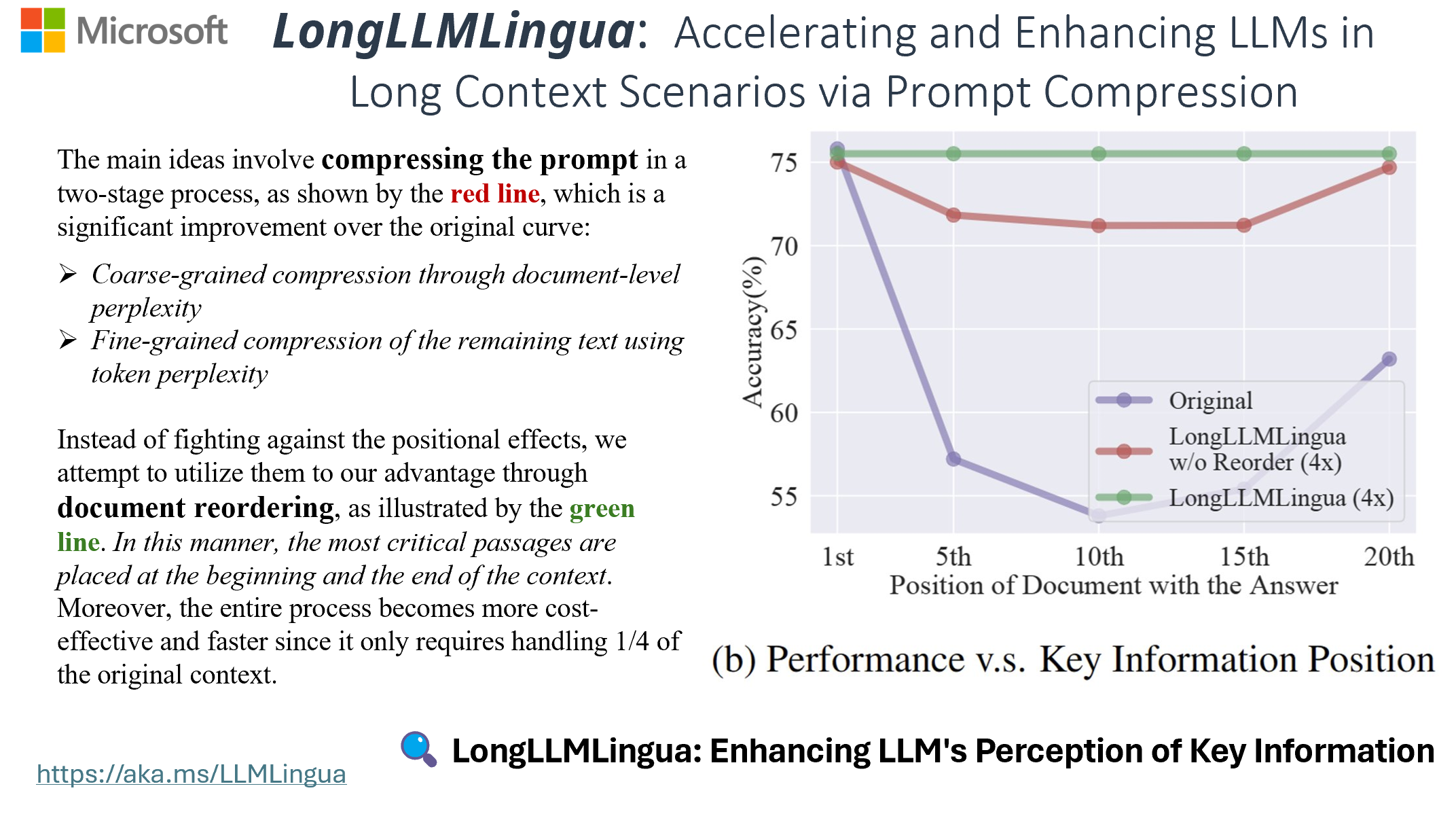
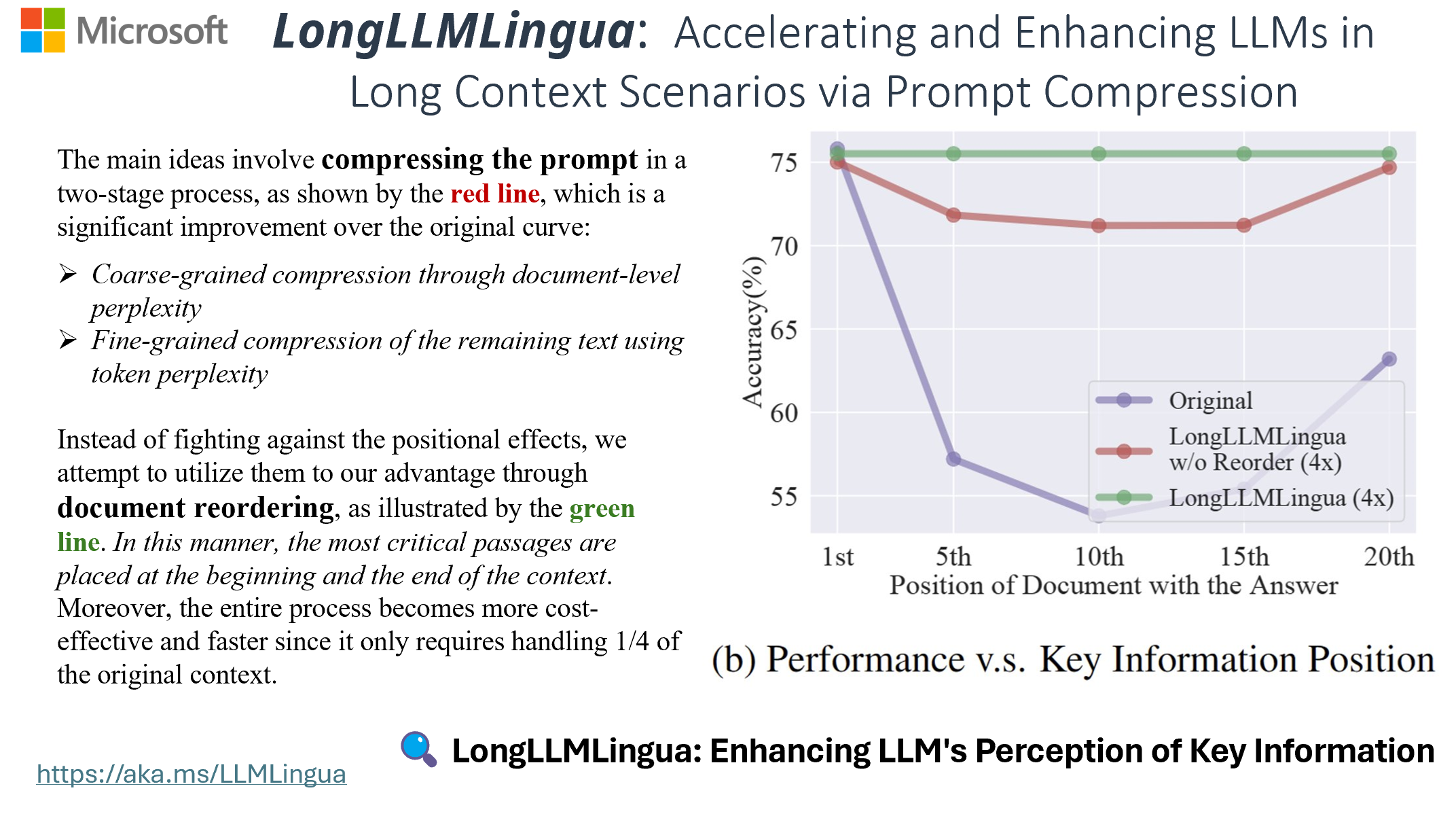
LongLLMLingua缓解了大语言模型中的“中间丢失”问题,增强了长上下文信息处理能力。它通过提示压缩降低成本并提高效率,仅使用四分之一的标记即可将RAG性能提升多达21.4%。
- LongLLMLingua:通过提示压缩加速并增强大语言模型在长上下文场景中的表现(ACL 2024及ICLR ME-FoMo 2024)
江辉强、吴千慧、罗旭芳、李东升、林钦耀、杨宇清和邱莉莉
LLMLingua-2是一种小型但功能强大的提示压缩方法,通过从GPT-4中进行数据蒸馏训练,使用BERT级别的编码器进行标记分类,擅长跨任务的压缩。它在处理域外数据方面优于LLMLingua,性能提升3至6倍。
- LLMLingua-2:通过数据蒸馏实现高效且忠实的跨任务提示压缩(ACL 2024发现)
潘卓石、吴千慧、江辉强、夏梦琳、罗旭芳、张珏、林庆伟、维克多·鲁勒、杨宇清、林钦耀、赵维琪、邱莉莉、张冬梅
SecurityLingua是一个安全护栏模型,利用安全感知的提示压缩揭示越狱攻击背后的恶意意图,使大语言模型能够检测攻击并生成安全响应。由于提示压缩极为高效,该防御方案几乎不增加开销,且与最先进的大语言模型护栏方法相比,令牌成本降低了100倍。
- SecurityLingua:通过安全感知的提示压缩高效防御大语言模型越狱攻击(CoLM 2025)
李宇成、安顺仁、江辉强、阿米尔·H·阿卜迪、杨宇清和邱莉莉
🎥 概述
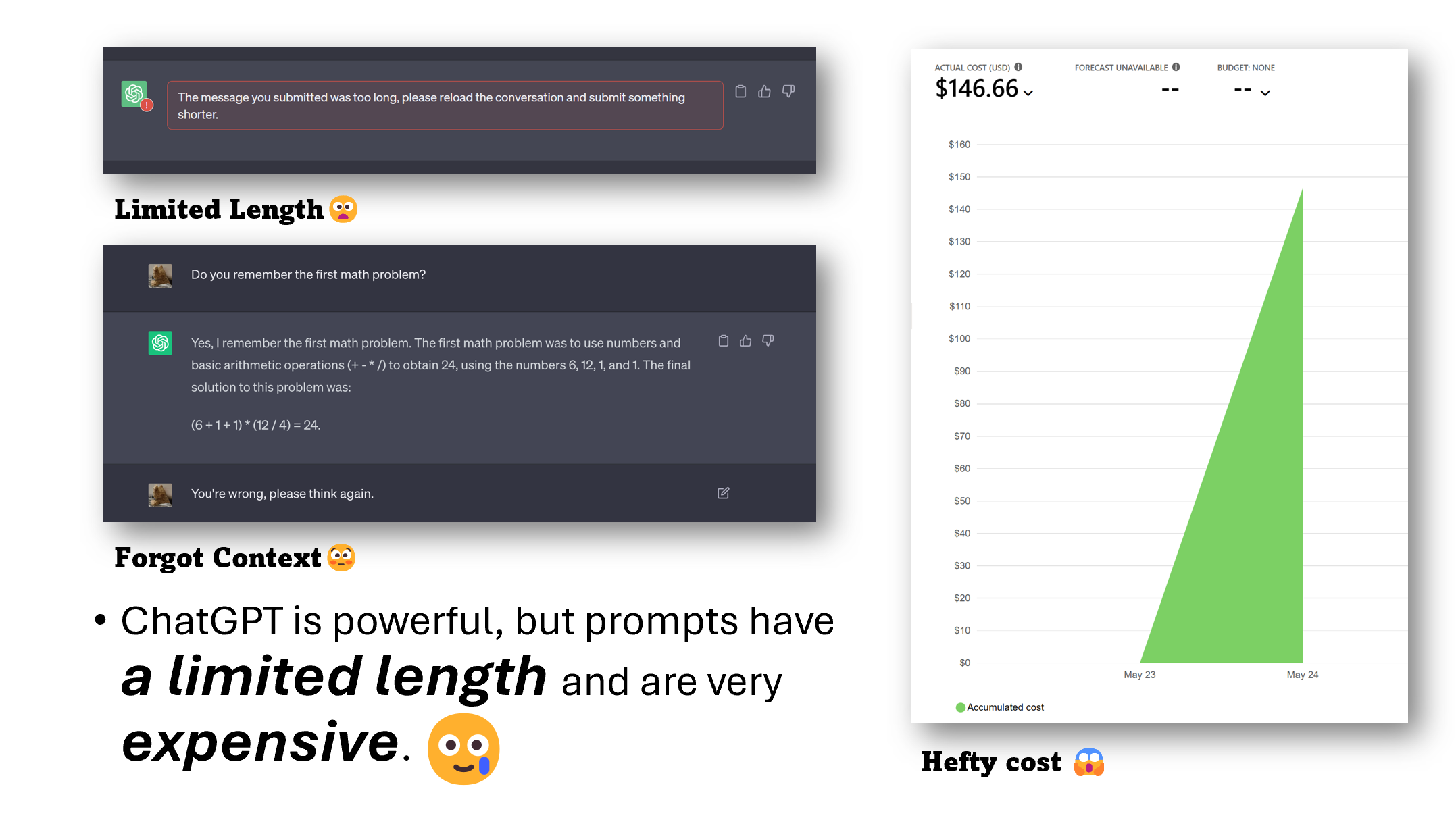
- 你是否曾在让 ChatGPT 总结长篇文本时遇到过 token 限制?
- 是否对 ChatGPT 在经过大量微调后仍会忘记先前指令而感到沮丧?
- 是否尽管实验效果出色,却因使用 GPT-3.5/4 API 而面临高昂成本?
尽管像 ChatGPT 和 GPT-4 这样的大型语言模型在泛化和推理方面表现出色,但它们常常面临提示长度限制以及基于提示的计费模式等挑战。
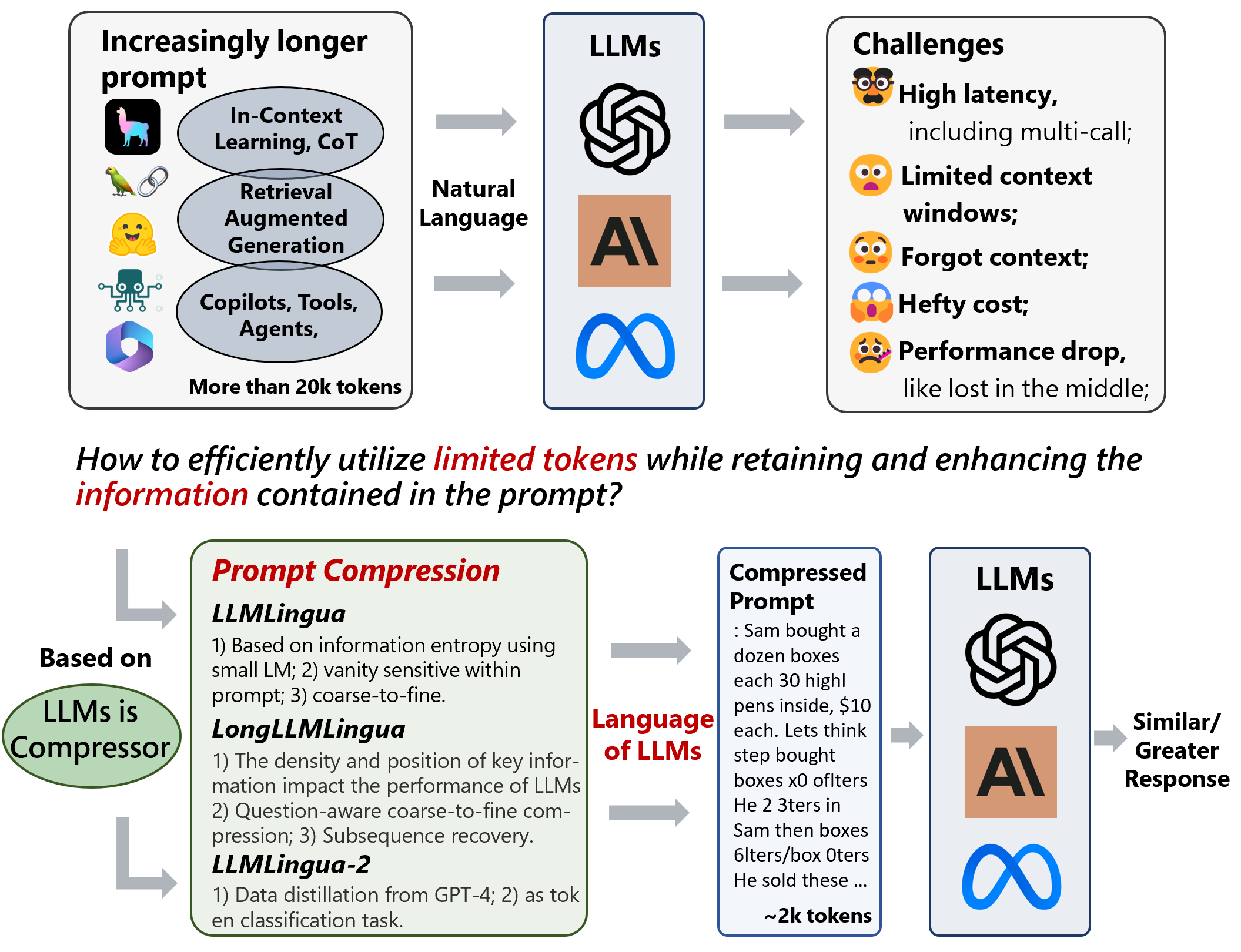
现在,你可以使用 LLMLingua、LongLLMLingua 和 LLMLingua-2!
这些工具提供了一种高效的解决方案,可将提示压缩多达 20 倍,从而提升大型语言模型的实用性。
- 💰 成本节约:在几乎不增加额外开销的情况下,同时减少提示和生成的长度。
- 📝 扩展上下文支持:增强对更长上下文的支持,缓解“中间信息丢失”问题,并提升整体性能。
- ⚖️ 鲁棒性:无需对大型语言模型进行额外训练。
- 🕵️ 知识保留:保持原始提示信息,如 ICL 和推理过程。
- 📜 KV 缓存压缩:加速推理过程。
- 🪃 全面恢复:GPT-4 可以从压缩后的提示中恢复所有关键信息。

PS:本演示基于 alt-gpt 项目。特别感谢 @Livshitz 的宝贵贡献。
如果你觉得这个仓库有用,请引用以下论文:
@inproceedings{jiang-etal-2023-llmlingua,
title = "{LLML}ingua: Compressing Prompts for Accelerated Inference of Large Language Models",
author = "Huiqiang Jiang and Qianhui Wu and Chin-Yew Lin and Yuqing Yang and Lili Qiu",
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.emnlp-main.825",
doi = "10.18653/v1/2023.emnlp-main.825",
pages = "13358--13376",
}
@inproceedings{jiang-etal-2024-longllmlingua,
title = "{L}ong{LLML}ingua: Accelerating and Enhancing {LLM}s in Long Context Scenarios via Prompt Compression",
author = "Huiqiang Jiang and Qianhui Wu and Xufang Luo and Dongsheng Li and Chin-Yew Lin and Yuqing Yang and Lili Qiu",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = aug,
year = "2024",
address = "Bangkok, Thailand",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.acl-long.91",
pages = "1658--1677",
}
@inproceedings{pan-etal-2024-llmlingua,
title = "{LLML}ingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression",
author = "Zhuoshi Pan and Qianhui Wu and Huiqiang Jiang and Menglin Xia and Xufang Luo and Jue Zhang and Qingwei Lin and Victor Ruhle and Yuqing Yang and Chin-Yew Lin and H. Vicky Zhao and Lili Qiu and Dongmei Zhang",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Findings of the Association for Computational Linguistics ACL 2024",
month = aug,
year = "2024",
address = "Bangkok, Thailand and virtual meeting",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-acl.57",
pages = "963--981",
}
@inproceedings{li2025securitylingua,
title={{S}ecurity{L}ingua: Efficient Defense of {LLM} Jailbreak Attacks via Security-Aware Prompt Compression},
author={Yucheng Li and Surin Ahn and Huiqiang Jiang and Amir H. Abdi and Yuqing Yang and Lili Qiu},
booktitle={Second Conference on Language Modeling},
year={2025},
url={https://openreview.net/forum?id=tybbSo6wba}
}
🎯 快速入门
1. 安装 LLMLingua:
要开始使用 LLMLingua,只需通过 pip 安装即可:
pip install llmlingua
2. 使用 LLMLingua 系列方法进行提示压缩:
借助 LLMLingua,你可以轻松压缩你的提示。以下是具体操作方法:
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor()
compressed_prompt = llm_lingua.compress_prompt(prompt, instruction="", question="", target_token=200)
# > {'compressed_prompt': '问题:Sam 购买了一打盒子,每个盒子里有 30 支荧光笔,每盒售价为 10 美元。他把其中 5 盒分成每盒 6 支的包装,以每盒 3 美元的价格卖出。其余的则按每 3 支 2 美元的价格单独出售。他总共赚了多少钱?让我们一步一步来思考。\nSam 购买了 1 盒 x00 支荧光笔。\n他总共买了 12 * 300 支荧光笔。\nSam 接着拿了 5 盒,每盒 6 支。\n他以 5 * 5 的价格卖出了这些盒子。\n卖出这些盒子后,还剩下 3030 支荧光笔。\n这些可以组成 330 / 3 = 110 组,每组 3 支。\n他以每组 2 美元的价格卖出了这些,因此赚了 110 * 2 = 220 美元。\n所以,他总共赚了 220 + 15 = 235 美元。\n由于他的原始成本是 120 美元,所以他赚了 235 - 120 = 115 美元的利润。\n答案是 115',
# 'origin_tokens': 2365,
# 'compressed_tokens': 211,
# 'ratio': '11.2x',
# 'saving': ', Saving $0.1 in GPT-4.'}
## 或者使用 phi-2 模型,
llm_lingua = PromptCompressor("microsoft/phi-2")
## 或者使用量化模型,比如 TheBloke/Llama-2-7b-Chat-GPTQ,只需要不到 8GB 的显存。
## 在此之前,你需要先安装 optimum auto-gptq
llm_lingua = PromptCompressor("TheBloke/Llama-2-7b-Chat-GPTQ", model_config={"revision": "main"})
要在你的场景中尝试 LongLLMLingua,可以使用:
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor()
compressed_prompt = llm_lingua.compress_prompt(
prompt_list,
question=question,
rate=0.55,
# 设置 LongLLMLingua 的特殊参数
condition_in_question="after_condition",
reorder_context="sort",
dynamic_context_compression_ratio=0.3, # 或 0.4
condition_compare=True,
context_budget="+100",
rank_method="longllmlingua",
)
要在你的场景中尝试 LLMLingua-2,可以使用:
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor(
model_name="microsoft/llmlingua-2-xlm-roberta-large-meetingbank",
use_llmlingua2=True, # 是否使用 llmlingua-2
)
compressed_prompt = llm_lingua.compress_prompt(prompt, rate=0.33, force_tokens = ['\n', '?'])
## 或使用 LLMLingua-2-small 模型
llm_lingua = PromptCompressor(
model_name="microsoft/llmlingua-2-bert-base-multilingual-cased-meetingbank",
use_llmlingua2=True, # 是否使用 llmlingua-2
)
要在您的场景中尝试 SecurityLingua,可以使用:
from llmlingua import PromptCompressor
securitylingua = PromptCompressor(
model_name="SecurityLingua/securitylingua-xlm-s2s",
use_slingua=True
)
intention = securitylingua.compress_prompt(malicious_prompt)
有关 SecurityLingua 的更多详细信息,请参阅 securitylingua 说明文档。
3. 高级用法——结构化提示压缩:
将文本拆分为多个部分,决定是否进行压缩及其压缩比例。使用 <llmlingua></llmlingua> 标签进行上下文分割,并可选地指定压缩比例和压缩参数。
structured_prompt = """<llmlingua, compress=False>发言者4:</llmlingua><llmlingua, rate=0.4> 谢谢。那我们能否对内容的功能进行处理呢?我认为涉及的项目有11号、3号、14号、16号和28号。</llmlingua><llmlingua, compress=False>
发言者0:</llmlingua><llmlingua, rate=0.4> 第11项是市议会关于提高市政经理部门一般基金组拨款额度的建议,金额为200美元,用于向长滩公共图书馆之友组织提供资助。第12项是市议员Super Now提出的建议,要求将专项广告与推广基金组及市政经理部门的拨款增加1万美元,以支持夏季结束庆典活动。第13项是市议员Austin提出的建议,要求将市政经理部门一般基金组的拨款增加500美元,用于向Jazz Angels组织捐款。第14项是市议员Austin提出的建议,要求将市政经理部门一般基金组的拨款增加300美元,用于向Little Lion Foundation组织捐款。第16项是市议员Allen提出的建议,要求将市政经理部门一般基金组的拨款增加1,020美元,用于向Casa Korero、Sew Feria商业协会、长滩公共图书馆之友以及Dave Van Patten组织提供资助。第28项是一则通知,由副市长Richardson和市议员Muranga提出,建议将市政经理部门一般基金组的拨款增加1,000美元,用于向Ron Palmer峰会、篮球与学术营活动提供捐赠。</llmlingua><llmlingua, compress=False>
发言者4:</llmlingua><llmlingua, rate=0.6> 我们有一个促销活动,而且市议员Ringa第二次担任市议员,他和客户们有什么意见吗?</llmlingua>"""
compressed_prompt = llm_lingua.structured_compress_prompt(structured_prompt, instruction="", question="", rate=0.5)
print(compressed_prompt['compressed_prompt'])
# > 发言者4:. 那我们能否对内容的功能进行处理呢?我认为涉及的项目有11号、116号、28号。
# 发言者0:来自市议会关于提高拨款额度的建议,其中第1项是市议员Super Now提出的建议,要求将专项基金组的拨款增加,以支持夏季活动;第13项是市议员Austin提出的建议,要求将市政经理部门一般基金组的拨款增加300美元,用于向Little Lion Foundation组织捐款。第16项是市议员Allen提出的建议,要求将市政经理部门一般基金组的拨款增加1,020美元,用于向Casa Korero、Sew Feria商业协会、长滩公共图书馆之友以及Dave Van Patten组织提供资助。第28项是一则通知,由副市长Richardson和市议员Muranga提出,建议将市政经理部门一般基金组的拨款增加1,000美元,用于向Ron Palmer峰会、篮球与学术营活动提供捐赠。
# 发言者4:我们有一个促销活动,而且市议员Ringa第二次担任市议员,他和客户们有什么意见吗?
4. 了解更多:
要了解如何在 RAG、在线会议、CoT 和代码等实际场景中应用 LLMLingua 和 LongLLMLingua,请参阅我们的 示例。如需详细指导,文档 提供了大量关于如何有效利用 LLMLingua 的建议。
5. LLMLingua-2 的数据收集与模型训练:
如需基于您的自定义数据训练压缩器,请参阅我们的 数据收集 和 模型训练。
常见问题
如需更多见解与解答,请访问我们的 常见问题解答页面。
贡献
本项目欢迎贡献与建议。大多数贡献都需要您同意一份《贡献者许可协议》(CLA),声明您有权并确实授予我们使用您贡献的权利。详情请访问 https://cla.opensource.microsoft.com。
当您提交拉取请求时,CLA 机器人会自动判断您是否需要提供 CLA,并相应地对 PR 进行标记(例如状态检查、评论)。您只需按照机器人提供的指示操作即可。对于所有使用我们 CLA 的仓库,您只需完成一次此步骤。
本项目已采用 Microsoft 开源行为准则。 如需更多信息,请参阅 行为准则常见问题解答,或如有任何其他问题或意见,请联系 opencode@microsoft.com。
商标
本项目可能包含针对项目、产品或服务的商标或标识。授权使用 Microsoft 商标或标识须遵守并遵循 Microsoft 商标与品牌指南。在本项目的修改版本中使用 Microsoft 商标或标识不得引起混淆或暗示 Microsoft 的赞助关系。任何第三方商标或标识的使用均须遵守该第三方的相关政策。
版本历史
v0.2.22024/04/09v0.2.12024/03/20v0.2.02024/03/13v0.1.62024/02/19v0.1.52023/12/21v0.1.42023/11/22v0.1.32023/11/15v0.1.22023/10/09常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。