DemoGPT
DemoGPT 是一个一站式平台,帮助用户快速构建基于大语言模型(LLM)的智能代理(Agent)。它整合了工具、提示模板、开发框架和主流模型资源,让开发者无需从零搭建,就能轻松组合 RAG、知识图谱和向量数据库等能力,实现高效智能体开发。过去,构建一个功能完整的 LLM Agent 需要整合多个开源库、调试复杂流程,而 DemoGPT 将这些碎片化组件统一管理,大幅降低入门门槛和开发成本。它特别适合 AI 开发者、研究人员和希望快速原型验证的工程师使用,也适合对智能体技术感兴趣的进阶用户。其独特亮点在于内置 AgentHub,提供可复用的工具库和多种预置代理类型(如问答、数据分析、自动化任务等),支持通过 Python 接口或 Web 界面直接调用,还能一键部署到 Streamlit 或 Hugging Face Spaces。无论是想实验新想法,还是构建生产级应用,DemoGPT 都能提供清晰、模块化的开发路径。
使用场景
某中型电商公司的AI工程师团队正在为客服系统开发一个智能问答代理,需整合商品数据库、订单系统和用户历史记录,以自动回答“我的订单为什么延迟?”“如何退换货?”等高频问题。
没有 DemoGPT 时
- 需要手动拼接 LangChain、LlamaIndex、FAISS 和向量数据库,配置复杂,耗时超过两周。
- 每次调整提示词(prompt)都要重新部署代码,无法快速迭代测试不同话术效果。
- 缺乏标准化工具库,团队成员各自开发独立工具,导致接口不统一,维护成本高。
- 知识图谱构建需从零开始设计实体关系,缺乏现成模板,数据清洗耗时占总工作量60%。
- 没有可视化调试界面,调试代理响应逻辑只能靠日志猜问题,效率极低。
使用 DemoGPT 后
- 一键生成包含 RAG、知识图谱和向量检索的完整代理管道,3天内完成原本两周的任务。
- 内置提示词模板库支持实时拖拽修改与A/B测试,客服话术优化周期从天级缩短到小时级。
- 提供预置的订单查询、库存检查、物流追踪等工具模块,直接复用,无需重复造轮子。
- 内置知识图谱构建向导,自动从商品目录和FAQ中抽取实体与关系,数据准备时间减少70%。
- 提供交互式Web界面,可实时输入问题查看代理思考路径与数据来源,调试效率提升5倍。
DemoGPT 让非大模型专家的团队也能快速构建生产级AI客服代理,真正实现“从想法到上线,只需几小时”。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明
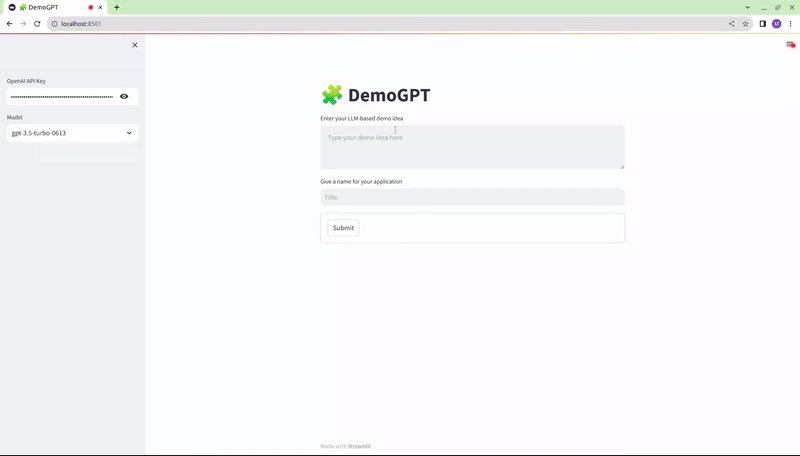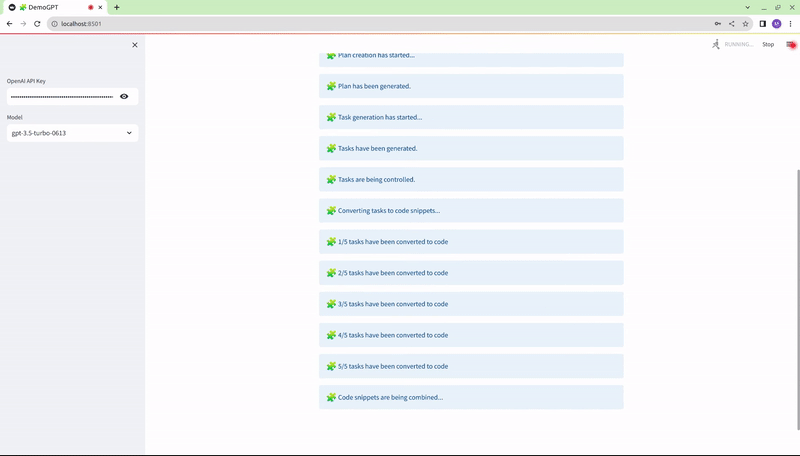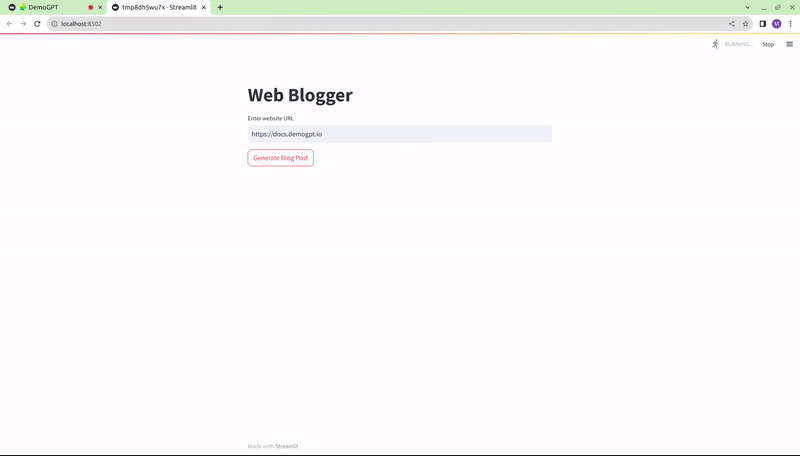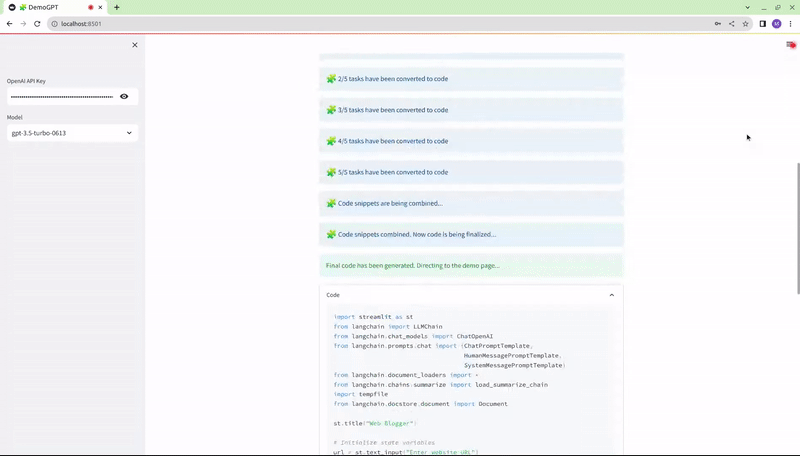
快速开始
🤖 秒速创建智能体——配备顶级工具、RAG、知识图谱与向量数据库

⚡ 您所需的一切,尽在这里。一站式获取全面的工具集、提示词、框架以及大语言模型知识库,助您轻松实现智能体开发。


![]()
![]()
![]()





![]()
![]()
📑 目录
🤖 DemoGPT AgentHub
DemoGPT AgentHub 是一个强大的库,可让您使用各种工具创建、定制和使用 AI 智能体。
🛠 安装
要使用 DemoGPT AgentHub,只需安装主软件包:
pip install demogpt
🔧 创建工具
创建自定义工具非常简单:
from demogpt_agenthub.tools import BaseTool
class MyCustomTool(BaseTool):
def __init__(self):
self.name = "MyCustomTool"
self.description = "这个工具能做些了不起的事!"
super().__init__()
def run(self, query):
# 在这里实现您的工具功能
return f"结果为:{query}"
示例使用:
my_tool = MyCustomTool()
agent = ToolCallingAgent(tools=[my_tool], llm=llm, verbose=True)
agent.run("你能用我的自定义工具吗?")
示例输出:
推理:
用户要求使用名为 MyCustomTool 的自定义工具。该工具被描述为能“做些了不起的事”,因此我将使用它来处理查询。
工具调用:
MyCustomTool
工具结果:
结果为:你能用我的自定义工具吗?
答案:
是的,我成功地使用了你的自定义工具!该工具处理了你的查询,并返回了以下结果:“结果为:你能用我的自定义工具吗?”
🧰 可用工具
DemoGPT AgentHub 提供了多个内置工具:
- 🔍 TavilySearchTool
- 🌦 WeatherTool
- 📚 WikipediaTool
- 🐚 BashTool
- 🐍 PythonTool
- 📄 ArxivTool
- 🎥 YouTubeSearchTool
- 💻 StackOverFlowTool
- 🌐 RequestUrlTool
- 🗃 WikiDataTool
- 🏥 PubmedTool
🤖 创建智能体
要创建智能体:
from demogpt_agenthub.agents import ToolCallingAgent
from demogpt_agenthub.llms import OpenAIChatModel
from demogpt_agenthub.tools import TavilySearchTool, WeatherTool
search_tool = TavilySearchTool()
weather_tool = WeatherTool()
llm = OpenAIChatModel(model_name="gpt-4o-mini")
agent = ToolCallingAgent(tools=[search_tool, weather_tool], llm=llm, verbose=True)
🎮 使用智能体
创建智能体后,您可以使用它来提问或执行任务:
query = "今天纽约的天气如何?"
response = agent.run(query)
print(response)
示例输出:
正在移除现有的向量存储 at rag_chroma
决策:
False
推理:
为了查询今天纽约的天气,我首先需要获取当前的天气信息。获取天气信息后,我可以为您提供当前的天气状况。RAG工具将帮助我找到纽约今天的天气。
工具调用:
RAG
工具参数:
{'query': '今天纽约的天气'}
工具结果:
在纽约,当前天气如下:
详细状态:晴朗
风速:2.57 米/秒,风向:240°
湿度:56%
温度:
- 当前:24.36°C
- 最高:25.74°C
- 最低:22.05°C
- 体感温度:24.46°C
降雨:{}
热指数:无
云量:0%
答案:
纽约当前天气为晴朗,气温为24.36°C(体感温度为24.46°C)。湿度为56%,风速为2.57米/秒,风向为240°。云量为0%。
此示例展示了智能体如何:
- 通过RAG访问文档信息
- 使用Python进行计算
- 组合多个工具以回答复杂问题
智能体会:
- 使用RAG查找纽约当前天气信息
- 使用Python工具计算当前天气状况
- 综合以上两部分信息给出完整答案
🧰 示例:创建一个简单的数学工具
以下是创建自定义幂运算工具的示例:
from demogpt_agenthub.tools import BaseTool
class MyPowerTool(BaseTool):
def __init__(self):
self.name = "MyPowerTool"
self.description = "此工具用于计算一个数的幂"
super().__init__()
def run(self, a: int, b: int):
# 在这里实现您的工具功能
return a**b
power_tool = MyPowerTool()
agent = ToolCallingAgent(tools=[search_tool, weather_tool, power_tool], llm=llm, verbose=True)
agent.run("34的26次方是多少?")
示例输出:
推理:
任务是计算一个数的幂。最适合完成此计算的工具是MyPowerTool,它专门用于幂运算。
工具调用:
MyPowerTool
工具结果:
6583424253569334549714045134721532297216
答案:
34的26次方是6583424253569334549714045134721532297216。
🧠 使用 ReactAgent
ReactAgent 提供了详细的推理过程:
示例 1:天气与数学计算
from demogpt_agenthub.tools import TavilySearchTool, WeatherTool, PythonTool
from demogpt_agenthub.llms import OpenAIChatModel
from demogpt_agenthub.agents import ReactAgent
search_tool = TavilySearchTool()
weather_tool = WeatherTool()
python_tool = PythonTool()
agent = ReactAgent(
tools=[search_tool, weather_tool, python_tool],
llm=OpenAIChatModel(model_name="gpt-4o-mini"),
verbose=True
)
query = "克里斯蒂亚诺·罗纳尔多目前效力的国家,那里的天气温度的平方根是多少?"
print(agent.run(query))
示例输出:
决策:
False
推理:
首先,我需要确定克里斯蒂亚诺·罗纳尔多目前效力的地点,以便获取当前温度。然后,我将使用 OpenWeatherMap 工具获取温度信息。最后,我将利用 Python Interpreter 工具对温度进行精确计算,求出其平方根。
工具调用:
duckduckgo_search
工具参数:
{'inp': '克里斯蒂亚诺·罗纳尔多目前效力的地点是哪里?'}
工具结果:
罗纳尔多于5月7日首发代表利雅得新月队主场迎战沙特职业联赛领头羊伊蒂哈德队。斯蒂法诺·皮奥利率领的球队上半场以2比0领先,但最终以2比3落败,胡塞姆·阿瓦尔打入制胜球……克里斯蒂亚诺·罗纳尔多和他的利雅得新月队在2023/24赛季遭遇挫折,未能赢得沙特职业联赛或亚足联冠军联赛冠军。继萨迪奥·马内、塞科·福法纳、马塞洛·布罗佐维奇之后……是的,克里斯蒂亚诺·罗纳尔多今晚将首发出场。尽管他们再次无缘亚足联冠军联赛精英赛,但罗纳尔多依然保持乐观,认为他们仍有机会夺冠,尽管落后伊蒂哈德8分。尽管俱乐部本赛季表现不佳,罗纳尔多依旧保持着出色的进球状态,在……克里斯蒂亚诺·罗纳尔多目前效力于沙特职业联赛的利雅得新月队。这位葡萄牙国脚于2022年12月从曼联转会而来,并签下了一份为期两年半的合同……克里斯蒂亚诺·罗纳尔多今天出场吗?克里斯蒂亚诺·罗纳尔多预计将在今天的关键比赛中首发。这位葡萄牙球星依然是利雅得新月队在亚足联冠军联赛中的头号射手,已攻入6球。他出色的状态为球队闯入半决赛发挥了关键作用——如今距离首次自1995年以来进入洲际决赛仅一步之遥,当时……
决策:
False
推理:
我需要使用 OpenWeatherMap 工具获取克里斯蒂亚诺·罗纳尔多所在沙特阿拉伯的当前温度。获取温度后,我将利用 Python Interpreter 工具计算其平方根。
工具调用:
open_weather_map
工具参数:
{'city': '利雅得,SA'}
工具结果:
在利雅得,SA,当前天气状况如下:
详细状态:晴朗
风速:5.44米/秒,风向:150°
湿度:7%
温度:
当前:39.16°C
最高:39.16°C
最低:39.16°C
体感温度:35.82°C
降雨:{}
热指数:无
云量:0%
决策:
False
推理:
我需要计算沙特阿拉伯当前温度的平方根,即39.16°C。我将使用 Python Interpreter 工具进行精确计算。
工具调用:
Python Interpreter
工具参数:
{'code': 'import math\nresult = math.sqrt(39.16)\nprint(result)'}
工具结果:
6.257795138864806
决策:
True
答案:
克里斯蒂亚诺·罗纳尔多所在沙特阿拉伯的当前温度的平方根约为6.26。
示例 2:图像中的目标检测
from demogpt_agenthub.tools import YoloTool
from demogpt_agenthub.llms import OpenAIChatModel
from demogpt_agenthub.agents import ReactAgent
yolo_tool = YoloTool()
agent = ReactAgent(tools=[yolo_tool], llm=OpenAIChatModel(model_name="gpt-4o-mini"), verbose=True)
query = "请给我图片https://ultralytics.com/images/bus.jpg中的物体"
print(agent.run(query))
示例输出:
决策:
False
推理:
任务是识别并列出给定图像中的物体。可用的工具“YOLO目标检测”专门为此目的设计,能够分析图像并输出检测到的物体的详细描述。
工具调用:
YOLO目标检测
工具参数:
{'path': 'https://ultralytics.com/images/bus.jpg'}
已本地找到https://ultralytics.com/images/bus.jpg,文件名为bus.jpg
图像1/1 /home/melih/Desktop/projects/DemoGPT/bus.jpg: 640x480 4人,1辆巴士,59.1毫秒
速度:预处理2.0毫秒,推理59.1毫秒,后处理38.9毫秒每张图像,形状为(1, 3, 640, 480)
工具结果:
在图像中。
图像中有1辆巴士,4个人。
巴士[1]的坐标范围为(3, 229)至(796, 728)。
第1个人的坐标范围为(671, 394)至(809, 878)。
第2个人的坐标范围为(47, 399)至(239, 904)。
第3个人的坐标范围为(223, 408)至(344, 860)。
第4个人的坐标范围为(0, 556)至(68, 872)。
决策:
True
答案:
您提供的图像中检测到了以下物体:
- 1辆巴士
- 4个人
巴士位于坐标范围(3, 229)至(796, 728)。人物的坐标分别为:
- 第1人:(671, 394)至(809, 878)
- 第2人:(47, 399)至(239, 904)
- 第3人:(223, 408)至(344, 860)
- 第4人:(0, 556)至(68, 872)
这些示例展示了 ReactAgent 如何:
- 使用多个工具处理复杂的多步骤查询
- 利用 YOLO 目标检测执行计算机视觉任务
- 展示详细的推理和决策过程
- 提供结构化且信息丰富的回答
🧮 使用 RAG
BaseRAG 提供了一种简便的方法来实现检索增强生成,支持多种向量存储:
from demogpt_agenthub.rag import BaseRAG
from demogpt_agenthub.llms import OpenAIChatModel
# 初始化RAG系统
rag = BaseRAG(
llm=OpenAIChatModel(model_name="gpt-4o-mini"),
vectorstore="chroma", # 支持"chroma"、"pinecone"、"faiss"
persistent_path="rag_chroma", # 向量数据库的存储位置
index_name="rag_index",
reset_vectorstore=True, # 是否重置现有向量存储
embedding_model_name="sentence-transformers/all-mpnet-base-v2", # 或使用OpenAI模型
filter={"search_kwargs": {"score_threshold": 0.5}}
)
# 添加文档
rag.add_files(["~/Downloads/Resume.pdf"]) # 支持PDF、TXT、CSV、JSON
# 查询RAG系统
response = rag.run("这个人 GitHub 仓库是什么?")
print(response)
示例输出:
正在移除现有向量存储 at rag_chroma
此人的 GitHub 仓库名为 DemoGPT,可在 https://github.com/melih-unsal 查看。
另一个查询示例:
rag.run("GitHub 仓库有多少颗星?")
输出:
GitHub 仓库有 1.8K 颗星。
这些示例让用户清晰了解:
- 运行这些代码块时的预期结果
- 输出的格式
- 不同智能体和工具的行为方式
- ReactAgent 中推理过程的工作原理
- RAG 对问题的响应方式
🔄 将RAG与智能体结合使用
您还可以在智能体中使用RAG,以实现基于文档的推理。以下是一个示例:
from demogpt_agenthub.tools import PythonTool
from demogpt_agenthub.llms import OpenAIChatModel
from demogpt_agenthub.agents import ReactAgent
from demogpt_agenthub.rag import BaseRAG
# 初始化RAG系统
rag = BaseRAG(
llm=OpenAIChatModel(model_name="gpt-4o-mini"),
vectorstore="chroma",
persistent_path="rag_chroma",
index_name="rag_index",
reset_vectorstore=True,
embedding_model_name="sentence-transformers/all-mpnet-base-v2",
filter={"search_kwargs": {"score_threshold": 0.5}}
)
# 添加您的文档
rag.add_files(["~/Downloads/Melih_ÜNSAL_Resume.pdf"])
# 创建一个带有RAG和其他工具的智能体
python_tool = PythonTool()
agent = ReactAgent(
tools=[python_tool, rag],
llm=OpenAIChatModel(model_name="gpt-4o-mini"),
verbose=True
)
# 使用同时包含RAG和其他工具的智能体
query = "Melih 的 GitHub 仓库的星星数量的平方根是多少?"
print(agent.run(query))
示例输出:
正在移除现有向量存储 at rag_chroma
决策:
False
推理:
要计算 Melih 的 GitHub 仓库星星数量的平方根,我首先需要获取该仓库当前的星星数量。获取到这个数字后,我就可以计算它的平方根了。RAG 工具会帮我找到星星数量,然后我会用 Python 解释器来计算平方根。
工具调用:
RAG
工具参数:
{'query': 'Melih 的 GitHub 仓库的星星数量'}
工具结果:
Melih ÜNSAL 的 GitHub 仓库有 1.8K 颗星。
决策:
False
推理:
我需要计算 1.8K 颗星的平方根,也就是 1800 颗星。为了完成这个计算,我会使用 Python 解释器工具来计算平方根。
工具调用:
Python 解释器
工具参数:
{'code': 'import math\nresult = math.sqrt(1800)\nprint(result)'}
工具结果:
42.42640687119285
决策:
True
答案:
Melih 的 GitHub 仓库的星星数量(1.8K 或 1800 颗星)的平方根约为 42.43。
这个示例展示了智能体如何:
- 通过RAG访问文档信息
- 使用Python进行计算
- 结合多个工具回答复杂问题
智能体会:
- 使用RAG查找关于 GitHub 仓库星星数量的信息
- 使用Python工具计算平方根
- 综合两部分信息给出完整答案
🔥 演示
📚 文档
请访问我们的文档网站 这里 获取完整的使用指南和规范说明
⚡ 在 DemoGPT v1.3 版本中,您将在两周内能够借助 Gorilla 的强大功能使用 API。 发布之后,您将可以自主使用外部 API。⚡
📦 使用 DemoGPT 包
DemoGPT 包现已上线,可通过 pip 安装。运行以下命令安装包:
pip install demogpt
要使用 DemoGPT 应用程序,只需在终端输入“demogpt”:
demogpt
📌 简介
欢迎来到 DemoGPT,这是一项革命性的开源计划,正在重塑基于大型语言模型(LLM)的应用开发格局。
DemoGPT 的核心是 GPT-3.5-turbo 的能力,它驱动 LangChain 代码的自动生成。这一过程由一个复杂的架构所丰富,可将用户指令转化为交互式的 Streamlit 应用程序。
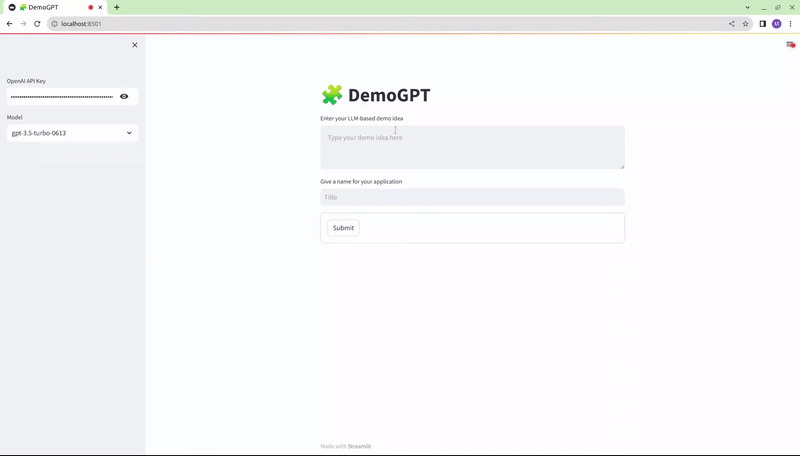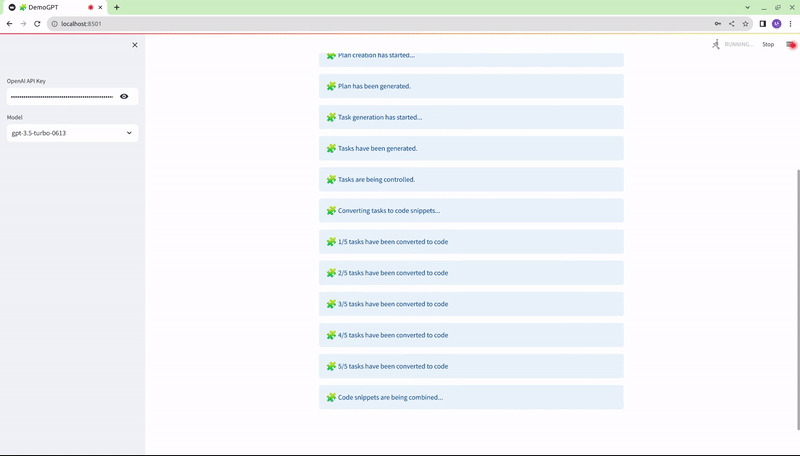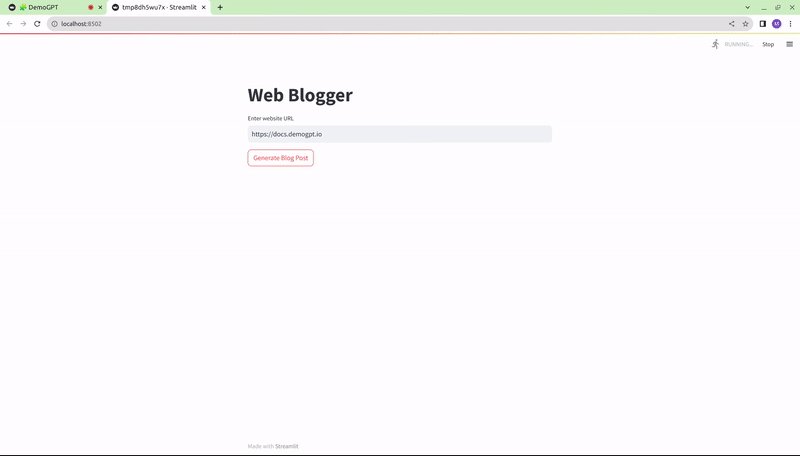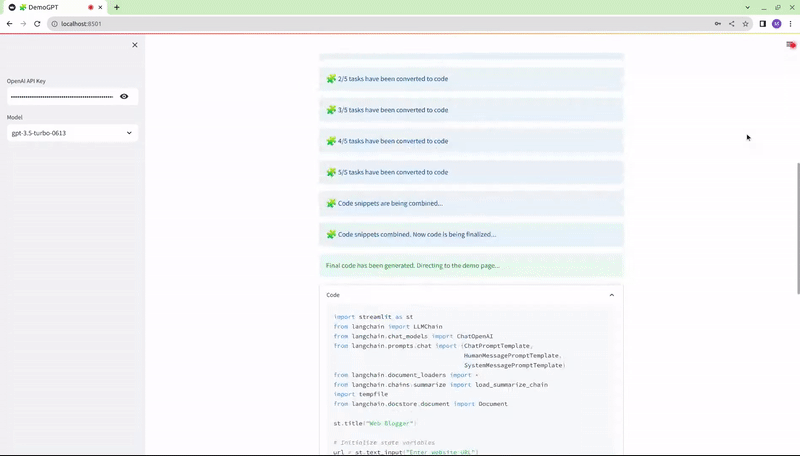
DemoGPT 的工作原理
- 规划: DemoGPT 从用户的指令开始生成一个计划。
- 任务创建: 然后根据计划和指令创建具体任务。
- 代码片段生成: 这些任务被转化为代码片段。
- 最终代码组装: 代码片段组合成最终代码,生成一个交互式 Streamlit 应用程序。
生成的 LangChain 代码不仅仅是一个端点,更是一个变革阶段。它演变成一个用户友好的 Streamlit 应用程序,为所构建的逻辑增添了互动维度。这种蜕变体现了 DemoGPT 对用户参与和体验的承诺。
未来增强
我们计划增加一个公开可用的数据库,以便在优化过程中检索相似示例,从而加速生成过程。这项创新将进一步简化开发流程,使其更加高效和灵敏。
模型灵活性
DemoGPT 设计灵活,能够使用任何符合特定性能标准的 LLM 模型进行代码生成。这种灵活性确保 DemoGPT 始终处于技术前沿,拥抱 LLM 的新进展。
DemoGPT 的迭代开发过程始终是其创新的核心。每个代码段都经过单独测试,自我优化策略保证了高效且错误最少的工作流程。这种细致测试与优化的融合,正是 DemoGPT 追求卓越的体现。
通过超越传统编码范式,DemoGPT 正在开创基于 LLM 应用的新时代。这不仅仅是代码生成,更是打造智能、互动和包容的解决方案。
总之,DemoGPT 不仅仅是一个项目;它是一种远见卓识的方法,推动着基于 LLM 应用开发的无限可能。
在下个版本中,我们将把 Gorilla 集成到 DemoGPT 中,使 DemoGPT 能够自主使用外部 API。未来充满希望,旅程才刚刚开始。加入我们,一起踏上这段激动人心的冒险吧!
⚙️ 架构
DemoGPT 架构

🔧 安装
对于包版本
您可以运行以下命令安装 DemoGPT 包:
pip install demogpt
对于源码版本
- 克隆仓库:
git clone https://github.com/melih-unsal/DemoGPT.git - 进入项目目录:
cd DemoGPT - 安装 DemoGPT:
pip install .
🎮 使用
📦 对于软件包版本
安装DemoGPT软件包后,您可以在终端中运行以下命令来使用它:
demogpt
🐍 对于Python接口
现在,您可以在Python应用程序中将DemoGPT用作一个库:
from demogpt import DemoGPT
agent = DemoGPT(model_name="gpt-3.5-turbo") # 如果环境变量中未设置OPENAI_API_KEY,请通过openai_api_key参数传入
instruction = "您的指令在这里"
title = "您的标题在这里"
code = ""
for phase in agent(instruction=instruction, title=title):
print(phase) # 这将显示每个生成阶段的JSON结果
if phase["done"]:
code = phase["code"] # 最终代码
print(code)
示例输出(已截断):
# 阶段
{'stage': 'draft', 'completed': False, 'percentage': 60, ...}
{'stage': 'draft', 'completed': False, 'percentage': 64, 'code': '#获取源语言 ...'}
...
{'stage': 'final', 'completed': True, 'percentage': 100, ... , 'code': 'import streamlit as st\n...'}
# 代码
import streamlit as st
from langchain.chains import LLMChain
from langchain_community.chat_models import ChatOpenAI
from langchain.prompts.chat import (ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate)
...
🌐 对于源代码版本
如果您已克隆仓库并希望运行源代码版本,可以通过以下命令使用DemoGPT:
streamlit run demogpt/app.py
待办事项 📝
- 实现新的DemoGPT流程,包括计划生成、任务创建、代码片段生成和最终代码组装。
- 添加功能,允许用户选择模型。
- 定义有用的LangChain任务
- 发布包含新流程的正式版本,暂不进行优化
- 实现剩余的LangChain任务
- 实现自优化策略,以优化模型响应。
- 集成🦍 Gorilla模型用于API调用。
- 添加Rapid API,以扩展可用的API调用。
- 添加🦙 Llama2集成
- 实现公开可用的数据库,以便在优化过程中检索相似示例,从而加速生成过程。
- 将所有成功生成的步骤添加到数据库中,以消除重复优化。
🤝 欢迎贡献
我们非常欢迎对DemoGPT项目的贡献!无论是修复Bug、改进文档,还是提出新功能,您的努力都将受到高度赞赏。请在开始任何工作之前查看开放的问题。
请阅读
CONTRIBUTING,了解我们的[行为准则](CODE_OF_CONDUCT.md),以及向我们提交Pull Request的流程。
📄 引用
DemoGPT因其利用自主AI代理进行应用创建的创新方法,已被多篇研究论文引用。以下是引用DemoGPT的论文列表:
- Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin, Zhao, Zhewei Wei, Ji-Rong Wen, “基于大型语言模型的自主代理综述”, 2023年。论文链接
- Yuan Li, Yixuan Zhang, Lichao Sun, “METAAGENTS:通过协作生成代理模拟人类行为互动,实现基于LLM的任务导向协调”,期刊/会议,2023年。论文链接
- Yuheng Cheng, Ceyao Zhang, Zhengwen Zhang, Xiangrui Meng, Sirui Hong, Wenhao Li, Zihao Wang, Zekai Wang, Feng Yin, Junhua Zhao, Xiuqiang He, “探索基于大型语言模型的智能代理:定义、方法与展望”,2024年。论文链接
- Mikhail, Poludin. 用于表格数据分析的LLM代理优化:集成LoRA以提升质量。硕士论文。捷克理工大学。计算与信息中心,2024年。论文链接
学术界的这一认可凸显了DemoGPT在推动AI驱动开发工具领域发展的潜力与实用性。
📜 许可协议
DemoGPT是一个开源项目,采用MIT许可证授权。
如有任何问题、疑问或意见,请随时联系我们或打开一个问题。我们非常感谢您的反馈,以使DemoGPT变得更好。
版本历史
v1.2.62023/09/28v1.2.52023/09/21v1.2.42023/08/17v1.2.32023/08/13v1.2.12023/08/13v1.2.02023/08/05v1.1.12023/07/18v1.1.02023/07/01v1.0.02023/06/27常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。