calvin
CALVIN 是一个开源的机器人操作任务学习基准工具,专注于通过自然语言指令指导机器人完成长时程复杂操作。它提供模拟环境和数据集,帮助研究人员训练机器人根据人类语言描述(如“把红色积木放进盒子”)自主规划多步骤动作序列,解决传统编程方式难以应对的动态复杂任务。
这个工具主要解决了现有机器人系统对精确编程的依赖问题。相比传统方法需要逐行编写操作代码,CALVIN 允许开发者通过语言指令定义任务目标,使机器人具备理解抽象指令并自主决策的能力。其数据集包含超过 40 小时的机械臂操作数据,涵盖物体抓取、堆叠、组装等典型场景,支持 RGB-D 图像、语言描述等多模态输入。
CALVIN 特别适合机器人算法研究者和 AI 开发者使用。研究人员可以基于其基准测试新算法的泛化能力,开发者则能快速验证语言驱动的机器人方案。技术亮点包括:支持长达 50 步的动作序列规划、兼容多种传感器配置(如双目视觉+力反馈)、采用 PyTorch Lightning 框架实现分布式训练加速。项目曾获 2022 年 IEEE 机器人领域最佳论文奖,配套提供调试数据集和完整训练流程示例,用户可快速搭建实验环境并复现基线模型。
使用场景
某工业自动化研发团队正在开发一款用于电子元件精密装配的六轴机械臂。该机械臂需要根据操作员的自然语言指令(如"先将电容插入PCB板第3焊点,再用镊子夹起电阻器放置到第5焊点")完成包含多个子步骤的复杂装配任务。
没有 calvin 时
- 任务分解困难:工程师需手动将自然语言指令拆解为数十个离散动作序列,耗时且易出错
- 训练数据匮乏:现有数据集仅包含简单抓取/放置动作,缺乏长时程多步骤操作的标注数据
- 模型泛化能力差:传统方法训练的模型在遇到新指令组合时成功率骤降至30%以下
- 调试效率低下:每次策略迭代需要重新录制完整操作视频,单次训练周期长达72小时
使用 calvin 后
- 自动任务编排:系统可将自然语言指令直接解析为包含15-30步的复合动作序列
- 数据集覆盖增强:内置的ABCD四类数据集包含2000+小时长时程装配任务,涵盖200+种语言指令变体
- 跨任务泛化提升:通过迁移学习,新指令的首次执行成功率提升至78%
- 训练效率倍增:共享内存数据加载使训练速度提升4倍,策略迭代周期缩短至8小时
核心价值:calvin通过提供标准化的长时程语言-视觉-动作联合训练框架,将复杂装配任务的开发周期从数月压缩至数周,同时显著提升机器人对非结构化指令的适应能力。
运行环境要求
- Linux
- macOS
需要 NVIDIA GPU,显存 8GB+
未说明
快速开始
CALVIN
![]()


![]()
CALVIN - 用于长时域机器人操作任务的语言条件策略学习基准
Oier Mees, Lukas Hermann, Erick Rosete, Wolfram Burgard
CALVIN 获得了2022年IEEE机器人与自动化快报(RA-L)最佳论文奖!
我们提出了 CALVIN (Composing Actions from Language and Vision,从语言和视觉生成动作),这是一个开源的模拟基准,用于学习长时域语言条件任务。我们的目标是开发能够通过机载传感器并仅通过人类语言指令解决多种机器人操作任务的智能体。与现有视觉-语言任务数据集相比,CALVIN任务在序列长度、动作空间和语言复杂度方面都有显著提升,并支持灵活的传感器套件配置。
:computer: 快速开始
首先将本仓库克隆到本地:
git clone --recurse-submodules https://github.com/mees/calvin.git
$ export CALVIN_ROOT=$(pwd)/calvin
安装依赖:
$ cd $CALVIN_ROOT
$ conda create -n calvin_venv python=3.8 # 或使用virtualenv
$ conda activate calvin_venv
$ sh install.sh
如果安装pyhash时遇到问题,可能需要将setuptools降级到58以下版本。
下载数据集(通过参数 D、ABC 或 ABCD 选择要下载的分割):
如果不想下载完整数据集,可以使用 debug 参数下载小规模调试数据集(1.3 GB)。
$ cd $CALVIN_ROOT/dataset
$ sh download_data.sh D | ABC | ABCD | debug
:weight_lifting_man: 训练基线智能体
训练基线模型:
$ cd $CALVIN_ROOT/calvin_models/calvin_agent
$ python training.py datamodule.root_data_dir=/path/to/dataset/ datamodule/datasets=vision_lang_shm
vision_lang_shm 选项会在训练开始时将CALVIN数据集加载到共享内存(shared memory),加快训练过程中的数据加载速度。共享内存缓存的准备需要一些时间(在我们的SLURM集群中约需20分钟)。
如果想使用原始数据加载器(例如调试时),只需用 datamodule/datasets=vision_lang 覆盖命令。
为了进一步加速,可以在训练时添加 ~callbacks/rollout 和 ~callbacks/rollout_lh 来禁用评估回调。
想要扩展到多GPU训练?只需指定 GPU数量,PyTorch Lightning(深度学习框架)会自动使用DDP进行训练。
在所有可用GPU上训练:
$ python training.py trainer.gpus=-1
如果使用Slurm集群,请参考此 指南。
你可以使用 Hydra(配置管理框架)的灵活覆盖系统修改超参数。
例如,使用静态相机和夹爪相机的RGB图像进行相对动作训练:
$ python training.py datamodule/observation_space=lang_rgb_static_gripper_rel_act model/perceptual_encoder=gripper_cam
使用两个相机的RGB-D数据训练:
$ python training.py datamodule/observation_space=lang_rgbd_both model/perceptual_encoder=RGBD_both
使用静态相机RGB图像和触觉观测进行绝对动作训练:
$ python training.py datamodule/observation_space=lang_rgb_static_tactile_abs_act model/perceptual_encoder=static_RGB_tactile
查看所有可用超参数:
$ python training.py --help
恢复训练只需覆盖hydra工作目录:
$ python training.py hydra.run.dir=runs/my_dir
:framed_picture: 感知观测
CALVIN 支持多种常用于视觉运动控制的传感器:
- 静态相机RGB图像 - 形状为
200x200x3。 - 静态相机深度图 - 形状为
200x200。 - 夹爪相机RGB图像 - 形状为
84x84x3。 - 夹爪相机深度图 - 形状为
84x84。 - 触觉图像 - 形状为
120x160x6。 - 本体感知状态 - 末端执行器位置(3),末端执行器欧拉角方向(3),夹爪宽度(1),关节位置(7),夹爪动作(1)。

:joystick: 动作空间
在CALVIN中,智能体必须执行闭环连续控制以跟随描述复杂机器人操作任务的非约束语言指令,以30Hz频率向机器人发送连续动作。
为了给研究人员和实践者提供实验不同动作空间的自由,CALVIN支持以下动作空间:
- 绝对笛卡尔位姿(absolute cartesian pose) - 末端执行器位置(3),末端执行器欧拉角方向(3),夹爪动作(1)。
- 相对笛卡尔位移(relative cartesian displacement) - 末端执行器位置(3),末端执行器欧拉角方向(3),夹爪动作(1)。
- 关节动作(joint action) - 关节位置(7),夹爪动作(1)。
更多信息请参考此详细 README。
:muscle: 评估:Calvin挑战赛
长周期多任务语言控制(LH-MTLC)
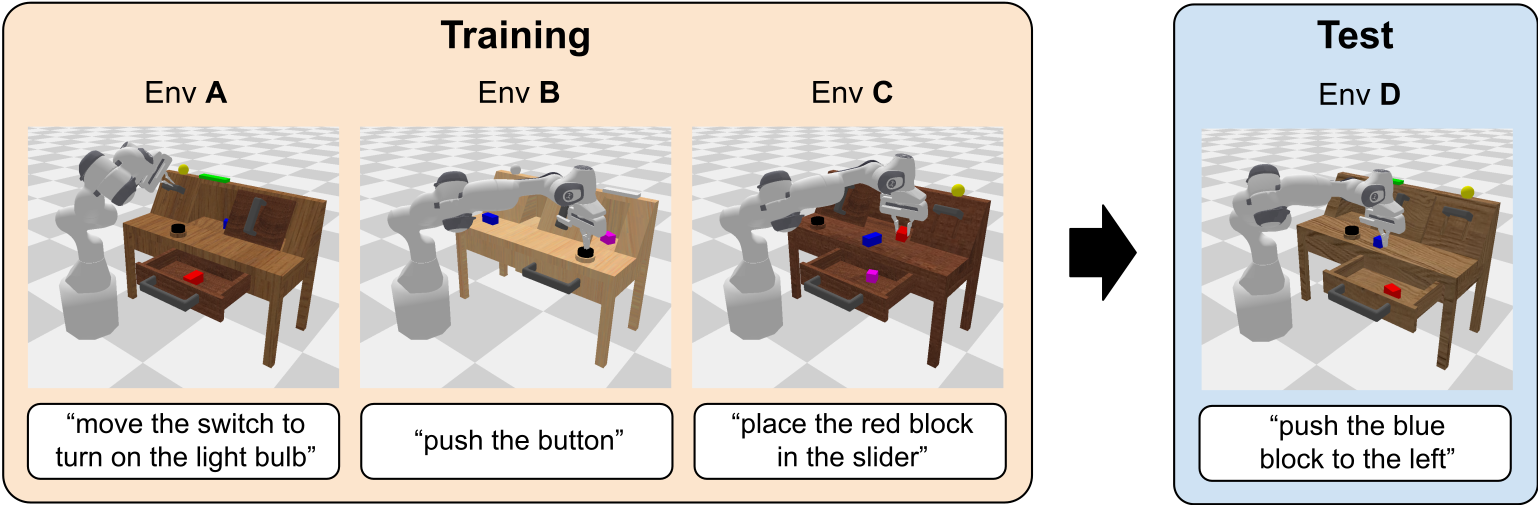
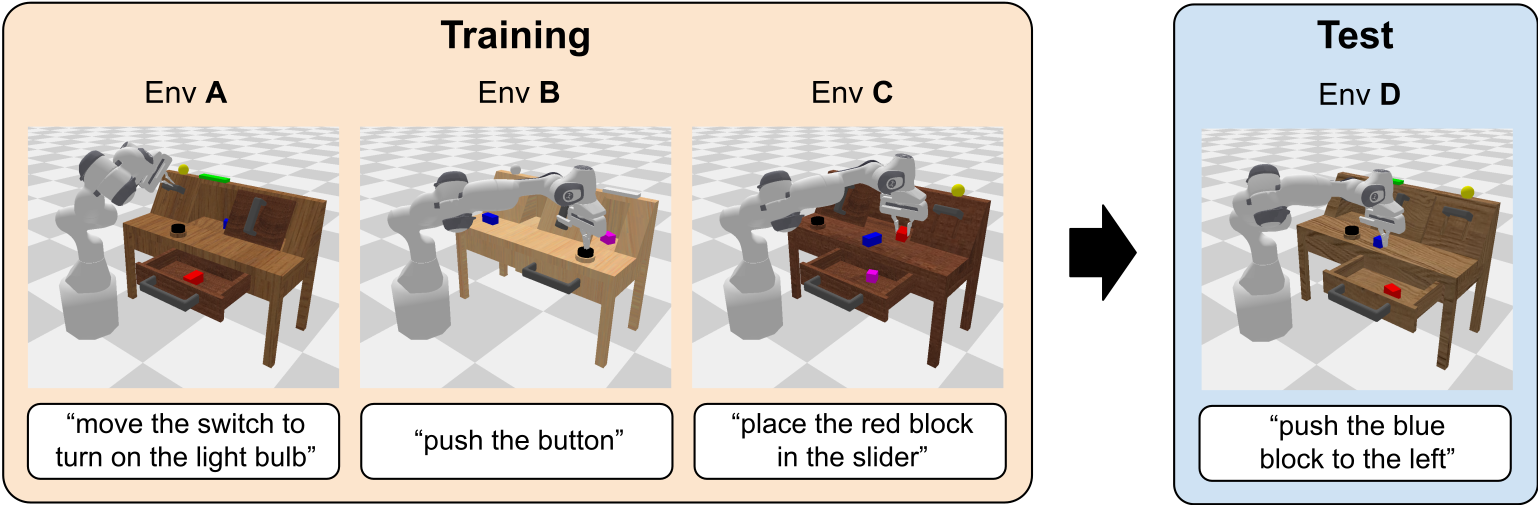
CALVIN基准测试(CALVIN benchmark)的目标是评估长周期语言条件连续控制策略的学习效果。在此设定中,单个智能体必须通过理解一系列无约束的语言表达来解决复杂的操作任务,例如“打开抽屉...拿起蓝色积木...现在将积木推入抽屉...现在打开滑动门”。
我们通过选择不同的传感器套件(sensor suite)和训练环境数量,提供具有不同难度评估模式的评估协议。为避免初始位置偏倚,机器人会在每次多步骤序列开始前重置到中立位置。
要评估训练好的CALVIN基线智能体,运行以下命令:
$ cd $CALVIN_ROOT/calvin_models/calvin_agent
$ python evaluation/evaluate_policy.py --dataset_path <PATH/TO/DATASET> --train_folder <PATH/TO/TRAINING/FOLDER>
可选参数:
--checkpoint <PATH/TO/CHECKPOINT>: 默认情况下,评估会加载训练日志目录中的最后一个检查点。您可以通过在评估命令中添加此参数指定其他检查点路径。--debug: 打印调试信息并可视化环境。
如果您想在CALVIN挑战中评估自己的模型架构,可以在evaluate_policy.py中实现CustomModel类作为智能体接口。需要实现以下方法:
- __init__(): 在评估开始时调用一次。
- reset(): 在每次评估序列开始时调用。
- step(obs, goal): 每个步骤调用并返回预测动作。
然后通过运行以下命令评估模型:
$ python evaluation/evaluate_policy.py --dataset_path <PATH/TO/DATASET> --custom_model
您也可以选择使用自己的语言模型,而非CALVIN提供的预计算语言嵌入(language embeddings)。为此,需要在evaluate_policy.py中实现CustomLangEmbeddings,并在评估命令中添加--custom_lang_embeddings参数。
多任务语言控制(MTLC)
或者,您可以评估不重置机器人中立位置的单任务策略。请注意此评估目前仅适用于我们的基线智能体。
$ python evaluation/evaluate_policy_singlestep.py --dataset_path <PATH/TO/DATASET> --train_folder <PATH/TO/TRAINING/FOLDER> [--checkpoint <PATH/TO/CHECKPOINT>] [--debug]
预训练模型
下载在D环境静态摄像头RGB图像上训练的MCIL模型检查点:
$ wget http://calvin.cs.uni-freiburg.de/model_weights/D_D_static_rgb_baseline.zip
$ unzip D_D_static_rgb_baseline.zip
:speech_balloon: 重新标注原始语言注释
您想尝试在CALVIN中使用新的语言模型学习语言条件策略吗?
我们提供了一个示例脚本,用于使用SBert提供的不同语言模型(如更大的MPNet (paraphrase-mpnet-base-v2) 或其对应的多语言模型 (paraphrase-multilingual-mpnet-base-v2))重新标注注释。支持的选项包括"mini"、"mpnet"和"multi"。如果想尝试不同的SBert模型,只需修改此处的模型名称。
cd $CALVIN_ROOT/calvin_models/calvin_agent
python utils/relabel_with_new_lang_model.py +path=$CALVIN_ROOT/dataset/task_D_D/ +name_folder=new_lang_model_folder model.nlp_model=mpnet
如果还想为训练集中的每个序列(来自相同任务注释)采样不同的语言注释,请在运行相同命令时添加参数reannotate=true。
📈 SOTA 模型(超越 CALVIN 基线的开源模型)
CALVIN 环境中超越 MCIL 基线的开源模型:
如需查看详细评估表现,请访问我们的 排行榜。
通过非结构化数据上的视觉可操作性进行语言接地
Oier Mees, Jessica Borja-Diaz, Wolfram Burgard
论文, 代码
FLOWER:通过高效的视觉-语言-动作流策略实现通用机器人策略的民主化
Moritz Reuss, Hongyi Zhou, Marcel Rühle, Ömer Erdinç Yağmurlu, Fabian Otto, Rudolf Lioutikov
论文, 代码
统一视觉-语言-动作模型(Unified Vision-Language-Action Model)
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xinlong Wang, Zhaoxiang Zhang
论文, 代码
预测性逆动力学模型:机器人操作的可扩展学习者
Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, Jiangmiao Pang
论文, 代码
扩散变换器策略:扩展扩散变换器用于通用视觉-语言-动作学习
Zhi Hou, Tianyi Zhang, Yuwen Xiong, Hengjun Pu, Chengyang Zhao, Ronglei Tong, Yu Qiao, Jifeng Dai, Yuntao Chen
论文, 代码
GR-MG:通过多模态目标条件策略利用部分标注数据
Peiyan Li, Hongtao Wu, Yan Huang, Chilam Cheang, Liang Wang, Tao Kong
论文, 代码
GHIL-Glue:通过过滤子目标图像实现分层控制
Kyle B Hatch, Ashwin Balakrishna, Oier Mees, Suraj Nair, Seohong Park, Blake Wulfe, Masha Itkina, Benjamin Eysenbach, Sergey Levine, Thomas Kollar, Benjamin Burchfiel
论文, 代码
具有专家去噪器混合的高效扩散变换器策略用于多任务学习
Moritz Reuss, Jyothish Pari, Pulkit Agrawal, Rudolf Lioutikov
论文, 代码
通过图像编辑将任务进度知识融入机器人操作的子目标生成
Xuhui Kang, Yen-Ling Kuo
论文, 代码
基于生成期望的闭环视觉运动控制用于机器人操作
Qingwen Bu, Jia Zeng, Li Chen, Yanchao Yang, Guyue Zhou, Junchi Yan, Ping Luo, Heming Cui, Yi Ma, Hongyang Li
论文, 代码
DeeR-VLA:动态推理多模态大语言模型用于高效机器人执行
Yang Yue, Yulin Wang, Bingyi Kang, Yizeng Han, Shenzhi Wang, Shiji Song, Jiashi Feng, Gao Huang
论文, 代码
RoboUniView:具有统一视图表示的视觉-语言模型用于机器人操作
Fanfan Liu, Feng Yan, Liming Zheng, Yiyang Huang, Chengjian Feng, Lin Ma
论文, 代码
多模态扩散变换器:从多模态目标学习通用行为
Moritz Reuss, Ömer Erdinç Yağmurlu, Fabian Wenzel, Rudolf Lioutikov
论文, 代码
3D 场景表示的扩散策略:3D扩散策略
Tsung-Wei Ke, Nikolaos Gkanatsios, Katerina Fragkiadaki
论文, 代码
解锁大规模视频生成预训练用于视觉机器人操作
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, Tao Kong
论文, 代码
视觉-语言基础模型作为有效的机器人模仿者
Xinghang Li, Minghuan Liu, Hanbo Zhang, Cunjun Yu, Jie Xu, Hongtao Wu, Chilam Cheang, Ya Jing, Weinan Zhang, Huaping Liu, Hang Li, and Tao Kong
论文, 代码
使用预训练图像编辑扩散模型实现零样本机器人操作
Kevin Black, Mitsuhiko Nakamoto, Pranav Atreya, Homer Walke, Chelsea Finn, Aviral Kumar, Sergey Levine
论文, 代码
语言控制扩散:通过空间、时间和任务高效扩展
Eddie Zhang, Yujie Lu, William Wang, Amy Zhang
论文, 代码
在非结构化数据上语言条件机器人模仿学习的关键因素
Oier Mees, Lukas Hermann, Wolfram Burgard
论文, 代码
基于基础技能先验的语言条件模仿学习(在非结构化数据下)
Hongkuan Zhou, Zhenshan Bing, Xiangtong Yao, Xiaojie Su, Chenguang Yang, Kai Huang, Alios Knoll
论文, 代码
请联系 Oier 添加您的模型。
在 CALVIN 中使用强化学习
您是否想尝试在 CALVIN 环境中针对不同操作任务使用强化学习代理? 我们提供了一个 Google Colab 来展示如何利用 CALVIN 任务指示器通过稀疏奖励学习 RL 代理。
常见问题解答 (FAQ)
为什么使用 EGL 渲染?
我们使用 EGL (Embedded-System Graphics Library,嵌入式图形库) 将子弹物理引擎的渲染从 CPU(默认方式)转移到 GPU,这样速度更快。
通过这种方式,我们可以在智能体训练过程中执行 rollout(轨迹回放)以跟踪其性能表现。
从 CPU 切换到 GPU 后,渲染的纹理会略有变化,因此如果你计划测试预训练模型,请注意这一点。
我在使用多块 GPU 训练时,为什么在 rollout 过程中出现 OOM 错误?
PyBullet 最近才添加了选择使用哪块 GPU 进行 EGL 渲染的选项(修复提交于 2021 年 10 月 22 日的 3c4cb80,详见 此处)。
如果你的 PyBullet 版本较旧,则无法选择 GPU,这会导致多 GPU 集群节点上的所有实例都分配到同一块 GPU,从而降低渲染速度并可能导致 OOM 错误。
修复方案引入了一个环境变量 EGL_VISIBLE_DEVICES(与 CUDA_VISIBLE_DEVICES 类似),允许你指定渲染所用的 GPU 设备。
但需要注意:在某些机器上,CUDA 和 EGL 的设备 ID 可能不匹配(例如 CUDA 设备 0 可能是 EGL 设备 3)。
我们在 calvin_env 的封装器中自动处理了这个问题,会查找对应的 EGL 设备 ID,因此你无需手动设置 EGL_VISIBLE_DEVICES,详见 此处。
我对记录的抓取任务不感兴趣,能否通过遥操作记录不同的演示数据?
可以,尽管目前尚未文档化,但所有通过 VR 头显记录数据的代码都已包含在 calvin_env 中,详见 https://github.com/mees/calvin_env/blob/main/calvin_env/vrdatacollector.py
更新日志 (Changelog)
2023年2月24日
- D 数据集中的
scene_info.npy文件有误。请注意我们已更新对应的校验和。请按以下方式替换:
cd task_D_D
wget http://calvin.cs.uni-freiburg.de/scene_info_fix/task_D_D_scene_info.zip
unzip task_D_D_scene_info.zip && rm task_D_D_scene_info.zip
2022年9月16日
- ABC 和 ABCD 数据集的重大错误:如果你在此日期前下载了这些数据集,需要执行以下修复:
- ABC 和 ABCD 数据集中语言标注错误。你可以从 这里 下载修正后的语言嵌入向量。
calvin_env中仅影响语言嵌入生成的错误。- ABC 和 ABCD 数据集中错误的
scene_info.npy文件。请按以下方式替换:
cd task_ABCD_D
wget http://calvin.cs.uni-freiburg.de/scene_info_fix/task_ABCD_D_scene_info.zip
unzip task_ABCD_D_scene_info.zip && rm task_ABCD_D_scene_info.zip
cd task_ABC_D
wget http://calvin.cs.uni-freiburg.de/scene_info_fix/task_ABC_D_scene_info.zip
unzip task_ABC_D_scene_info.zip && rm task_ABC_D_scene_info.zip
- 向数据集中添加了额外的语言嵌入向量。
2022年5月15日
- 添加了共享内存数据集加载器以加速训练。重构了数据加载类。
2022年2月7日
- 对长视野多步骤序列中的任务分布进行了小幅调整。
- 修改了推物和举升任务的成功判定标准。
- 在数据集的 hydra 配置中为机器人设置了
use_nullspace: true。如果你在此日期前下载了数据集,请编辑以下路径中的文件:<PATH_TO_DATASET>/training/.hydra/merged_config.yaml和<PATH_TO_DATASET>/validation/.hydra/merged_config.yaml。 - 将
model.decoder重命名为model.action_decoder。
2022年1月10日
- 评估方式的重大变更,使用不同的环境初始状态。
引用
如果你发现本数据集或代码有用,请引用以下文献:
@article{mees2022calvin,
author = {Oier Mees and Lukas Hermann and Erick Rosete-Beas and Wolfram Burgard},
title = {CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks},
journal={IEEE Robotics and Automation Letters (RA-L)},
volume={7},
number={3},
pages={7327-7334},
year={2022}
}
许可证
MIT License
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。