llm-min.txt
llm-min.txt 是一款专为大语言模型(LLM)设计的文档压缩工具,旨在解决 AI 编程助手因知识截止而无法获取最新技术库信息的问题。当前主流的解决方案(如 llms.txt)往往文件过大,容易超出 AI 的上下文窗口限制,或者依赖不透明的外部服务。llm-min.txt 借鉴了 Web 开发中"min.js"的理念,将冗长的技术文档进行极致精简,去除冗余内容,仅保留机器阅读所需的核心信息。
通过这种“机器优先”的压缩格式,llm-min.txt 能在大幅减少 Token 消耗的同时,确保 AI 准确理解最新的 API 变更和功能特性,从而生成更可靠、与时俱进的代码建议。它特别适合开发者、技术研究人员以及经常使用 AI 编程辅助工具(如 Cursor、GitHub Copilot)的用户。无论是维护开源项目还是探索新技术栈,llm-min.txt 都能帮助用户轻松构建轻量级、高精度的上下文环境,让 AI 真正“读懂”最新文档,填补知识鸿沟。
使用场景
某后端团队正基于最新版的 FastAPI 框架开发高并发微服务,急需让 AI 编程助手生成符合最新语法的异步中间件代码。
没有 llm-min.txt 时
- 知识滞后导致代码报错:AI 模型因训练数据截止较早,生成的代码仍使用已废弃的同步写法,导致项目启动失败。
- 上下文窗口被撑爆:试图通过粘贴完整的官方文档或巨大的
llms-full.txt文件来补充知识,却因内容超过 80 万 token 直接超出 AI 的处理上限。 - 信息检索效率低下:文档中充斥大量人类可读但机器无关的排版、示例和冗余描述,AI 难以在海量文本中精准定位核心 API 定义。
- 黑盒依赖不可控:依赖外部黑盒服务动态抓取文档,无法确定其是否包含了刚刚发布的紧急补丁说明,存在安全隐患。
使用 llm-min.txt 后
- 即时同步最新特性:llm-min.txt 将技术文档压缩为类似
min.js的机器最优格式,让 AI 瞬间掌握 FastAPI 最新的异步中间件规范,生成代码一次通过。 - 极致压缩节省算力:通过剔除所有非必要元素,文档体积大幅缩小,轻松放入 AI 的上下文窗口,无需担心长度限制。
- 高密度信息直达核心:保留纯粹的结构化定义与逻辑关系,去除了自然语言噪音,使 AI 能更准确地理解参数类型与调用链路。
- 透明可控的知识源:团队可直接针对任意开源包生成专用的 llm-min.txt 文件,确保 AI 引用的永远是本地最新、最准确的文档版本。
llm-min.txt 通过“文档压缩”理念,彻底解决了 AI 编程中知识过时与上下文受限的双重难题,让大模型真正具备实时演进的开发能力。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明
快速开始
llm-min.txt: Min.js Style Compression of Tech Docs for LLM Context 🤖
![]()
📜 Table of Contents
- llm-min.txt: Min.js Style Compression of Tech Docs for LLM Context 🤖
- 📜 Table of Contents
- What is
llm-min.txtand Why is it Important? - Understanding
llm-min.txt: A Machine-Optimized Format 🧩 - Does it Really Work? Visualizing the Impact
- Quick Start 🚀
- Output Directory Structure 📂
- Choosing the Right AI Model (Why Gemini) 🧠
- How it Works: A Look Inside (src/llm_min) ⚙️
- What's Next? Future Plans 🔮
- Common Questions (FAQ) ❓
- Want to Help? Contributing 🤝
- License 📜
What is llm-min.txt and Why is it Important?
If you've ever used an AI coding assistant (like GitHub Copilot, Cursor, or others powered by Large Language Models - LLMs), you've likely encountered situations where they don't know about the latest updates to programming libraries. This knowledge gap exists because AI models have a "knowledge cutoff" – a point beyond which they haven't learned new information. Since software evolves rapidly, this limitation can lead to outdated recommendations and broken code.
Several innovative approaches have emerged to address this challenge:
 llms.txt
A community-driven initiative where contributors create reference files (
llms.txt
A community-driven initiative where contributors create reference files (llms.txt) containing up-to-date library information specifically formatted for AI consumption. Context7
A service that dynamically provides contextual information to AIs, often by intelligently summarizing documentation.
Context7
A service that dynamically provides contextual information to AIs, often by intelligently summarizing documentation.
While these solutions are valuable, they face certain limitations:
llms.txtfiles can become extraordinarily large – some exceeding 800,000 tokens (word fragments). This size can overwhelm many AI systems' context windows.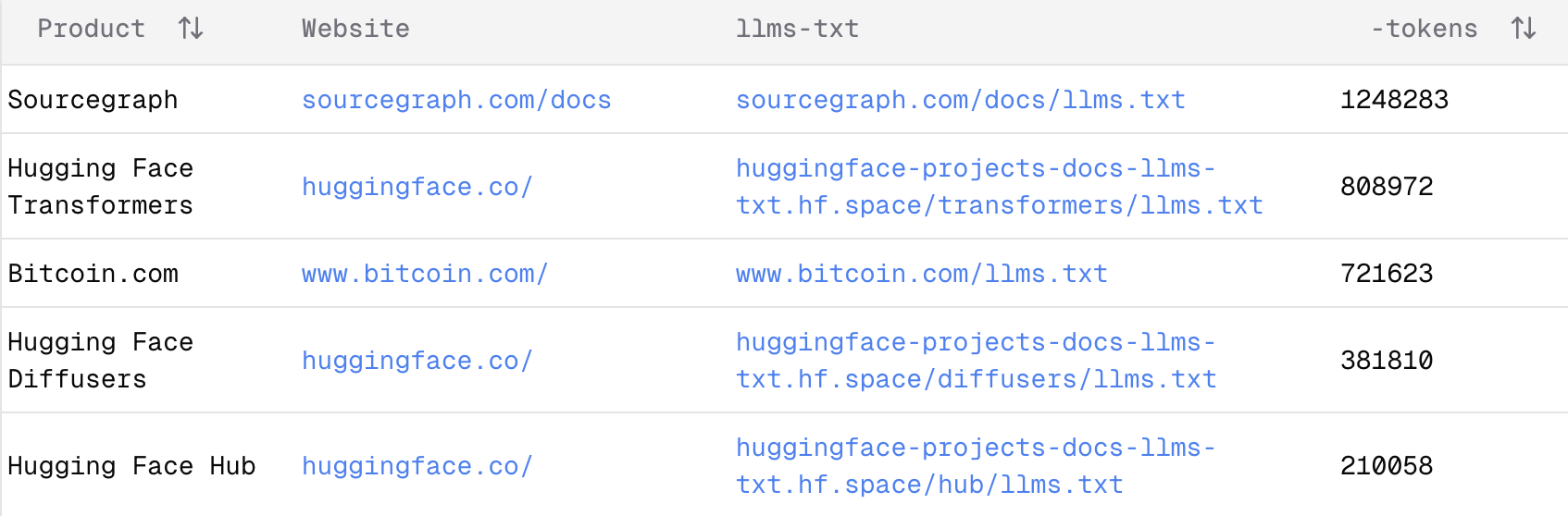
Many shorter
llms.txtvariants simply contain links to official documentation, requiring the AI to fetch and process those documents separately. Even the comprehensive versions (llms-full.txt) often exceed what most AI assistants can process at once. Additionally, these files may not always reflect the absolute latest documentation.Context7operates somewhat as a "black box" – while useful, its precise information selection methodology isn't fully transparent to users. It primarily works with GitHub code repositories or existingllms.txtfiles, rather than any arbitrary software package.
llm-min.txt offers a fresh approach:
Inspired by min.js files in web development (JavaScript with unnecessary elements removed), llm-min.txt adopts a similar philosophy for technical documentation. Instead of feeding an AI a massive, verbose manual, we leverage another AI to distill that documentation into a super-condensed, highly structured summary. The resulting llm-min.txt file captures only the most essential information needed to understand a library's usage, packaged in a format optimized for AI assistants rather than human readers.
Modern AI reasoning capabilities excel at this distillation process, creating remarkably efficient knowledge representations that deliver maximum value with minimal token consumption.
Understanding llm-min.txt: A Machine-Optimized Format 🧩
The llm-min.txt file utilizes the Structured Knowledge Format (SKF) – a compact, machine-optimized format designed for efficient AI parsing rather than human readability. This format organizes technical information into distinct, highly structured sections with precise relationships.
Key Elements of the SKF Format:
Header Metadata: Every file begins with essential contextual information:
# IntegratedKnowledgeManifest_SKF: Format identifier and version# SourceDocs: [...]: Original documentation sources# GenerationTimestamp: ...: Creation timestamp# PrimaryNamespace: ...: Top-level package/namespace, critical for understanding import paths
Three Core Structured Sections: The content is organized into distinct functional categories:
# SECTION: DEFINITIONS (Prefix: D): Describes the static aspects of the library:- Canonical component definitions with unique global IDs (e.g.,
D001:G001_MyClass) - Namespace paths relative to
PrimaryNamespace - Method signatures with parameters and return types
- Properties/fields with types and access modifiers
- Static relationships like inheritance or interface implementation
- Important: This section effectively serves as the glossary for the file, as the traditional glossary (
Gsection) is used during generation but deliberately omitted from the final output to save space.
- Canonical component definitions with unique global IDs (e.g.,
# SECTION: INTERACTIONS (Prefix: I): Captures dynamic behaviors within the library:- Method invocations (
INVOKES) - Component usage patterns (
USES_COMPONENT) - Event production/consumption
- Error raising and handling logic, with references to specific error types
- Method invocations (
# SECTION: USAGE_PATTERNS (Prefix: U): Provides concrete usage examples:- Common workflows for core functionality
- Step-by-step sequences involving object creation, configuration, method invocation, and error handling
- Each pattern has a descriptive name (e.g.,
U_BasicCrawl) with numbered steps (U_BasicCrawl.1,U_BasicCrawl.2)
Line-Based Structure: Each item appears on its own line following precise formatting conventions that enable reliable machine parsing.
Example SKF Format (Simplified):
# 集成知识清单_SKF/1.4 LA
# 源文档: [example-lib-docs]
# 生成时间戳: 2024-05-28T12:00:00Z
# 主命名空间: example_lib
# 第一部分:定义(前缀:D)
# 主要定义格式: Dxxx:Gxxx_Entity [DEF_TYP] [NAMESPACE "relative.path"] [OPERATIONS {op1:RetT(p1N:p1T)}] [ATTRIBUTES {attr1:AttrT1}] ("注释")
# ---
D001:G001_Greeter [组件定义] [NAMESPACE "."] [OPERATIONS {greet:Str(name:Str)}] ("一个简单的问候类")
D002:G002_AppConfig [组件定义] [NAMESPACE "config"] [ATTRIBUTES {debug_mode:Bool("只读")}] ("应用程序配置")
# ---
# 第二部分:交互(前缀:I)
# 格式: Ixxx:源引用 INT_VERB 目标引用或字面量 ("备注_条件_错误(Gxxx_ErrorType)")
# ---
I001:G001_Greeter.greet 调用 G003_Logger.log ("记录问候活动")
# ---
# 第三部分:使用模式(前缀:U)
# 格式: U_Name:模式标题关键词
# U_Name.N:[参与者或引用] 动作关键词 (涉及目标或数据的引用) -> [结果或状态变化涉及的引用]
# ---
U_BasicGreeting:基本用户问候
U_BasicGreeting.1:[用户] 创建 (G001_Greeter) -> [greeter_instance]
U_BasicGreeting.2:[greeter_instance] 调用 (greet name='Alice') -> [greeting_message]
# ---
# 清单结束
llm-min-guideline.md 文件(与 llm-min.txt 同时生成)提供了详细的解码说明和模式定义,使 AI 能够正确解析 SKF 格式。它作为关键的配套文档,解释了文件中使用的符号、字段含义以及关系类型。
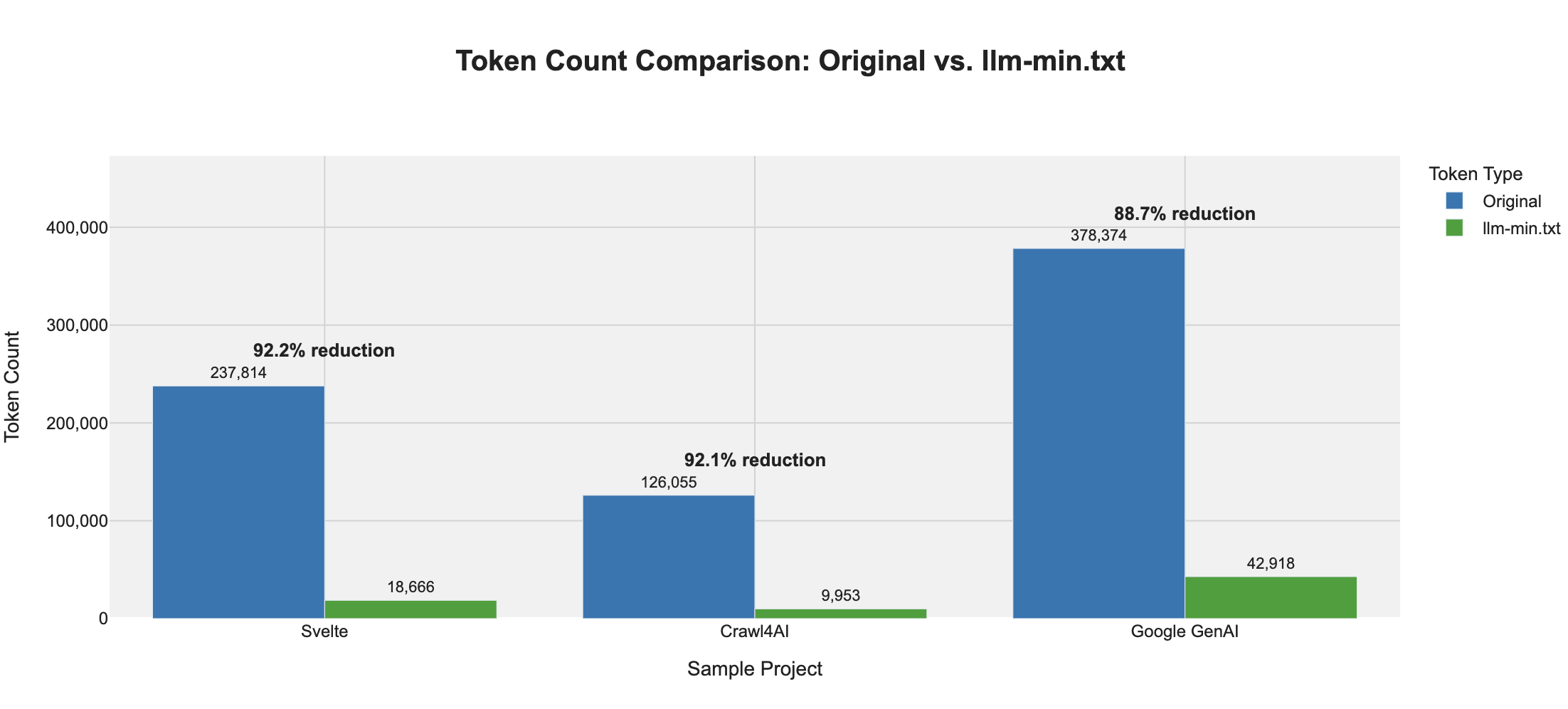
真的有效吗?可视化其效果
llm-min.txt 在大幅减少 token 数量的同时,保留了 AI 助手所需的核心知识。下图比较了原始库文档(llm-full.txt)与压缩后的 llm-min.txt 版本之间的 token 数量:
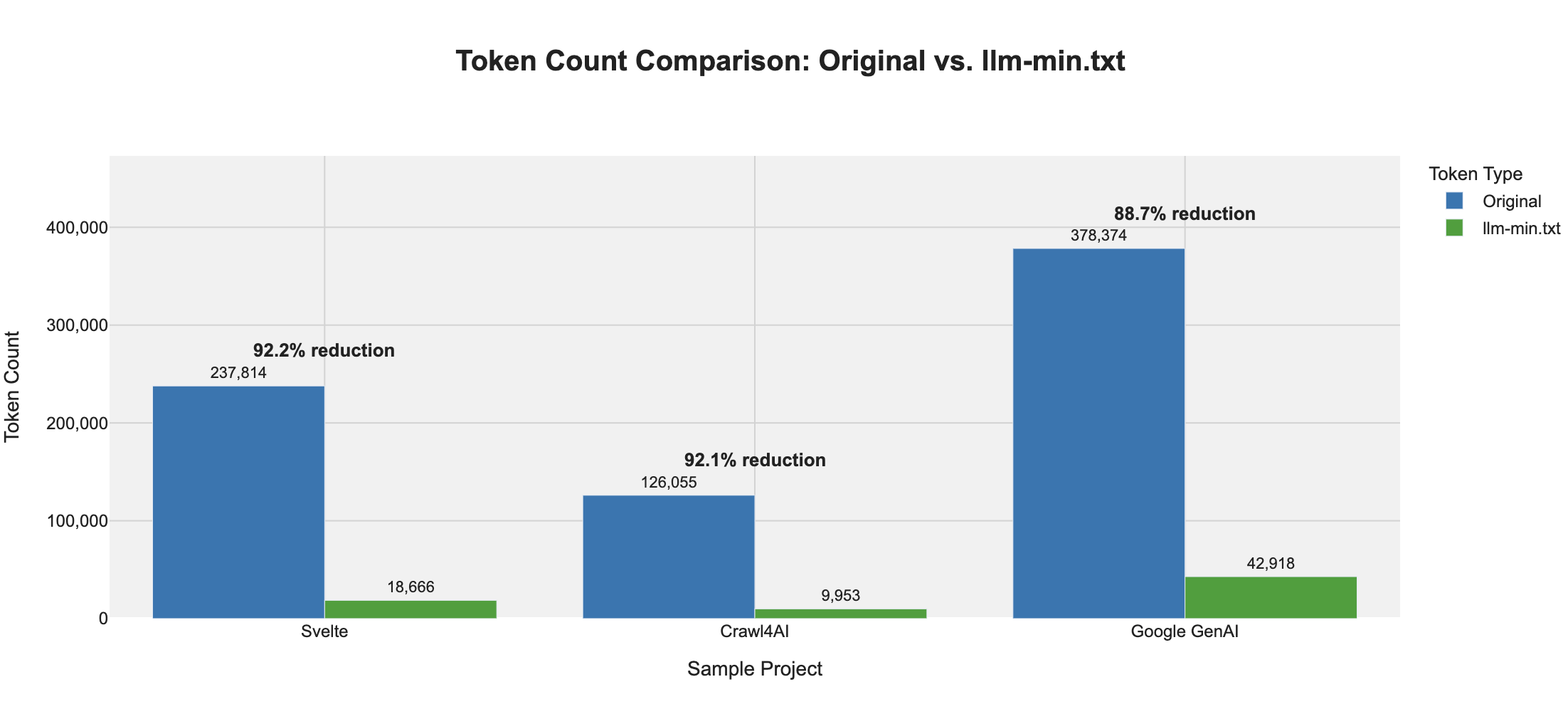
结果显示,token 减少幅度通常在 90% 至 95% 之间,某些情况下甚至超过 97%。这种极致的压缩结合高度结构化的 SKF 格式,使得 AI 工具能够比处理原始文本更高效地摄入和处理库文档。
在我们的示例目录中,您可以亲自查看这些令人印象深刻的成果:
sample/crawl4ai/llm-full.txt: 原始文档(未压缩)sample/crawl4ai/llm-min.txt: 压缩后的 SKF 表示sample/crawl4ai/llm-min-guideline.md: 格式解码器配套文件,也可参见 llm-min-guideline.md
大多数压缩后的文件仅包含约 10,000 个 token,完全在现代 AI 助手的处理能力范围内。
如何使用?
只需在您的 AI 驱动 IDE 的对话中引用这些文件,您的助手便会立即获得关于该库的详细知识:
性能如何?
进行基准测试是必要的,但非常困难。LLM 代码生成具有随机性,生成代码的质量取决于诸多因素。例如,crawl4ai、google-genai 和 svelte 这些软件包目前仍难以被 LLM 正确生成代码。而使用 llm-min 将显著提高代码生成的成功率。
快速入门 🚀
开始使用 llm-min 非常简单:
1. 安装:
对于普通用户(推荐):
pip install llm-min # 安装所需的浏览器自动化工具 playwright install对于贡献者和开发者:
# 克隆仓库(如果尚未完成) # git clone https://github.com/your-repo/llm-min.git # cd llm-min # 创建并激活虚拟环境 python -m venv .venv source .venv/bin/activate # 在 Windows 上:.venv\Scripts\activate # 使用 UV 安装依赖项(比 pip 更快) uv sync uv pip install -e . # 可选:设置 pre-commit 钩子以保证代码质量 # uv pip install pre-commit # pre-commit install
2. 设置你的 Gemini API 密钥:🔑
llm-min 使用 Google 的 Gemini AI 来生成压缩后的文档。你需要一个 Gemini API 密钥才能继续:
最佳实践: 将你的密钥值设置为名为
GEMINI_API_KEY的环境变量:# Linux/macOS export GEMINI_API_KEY=your_api_key_here # Windows(命令提示符) set GEMINI_API_KEY=your_api_key_here # Windows(PowerShell) $env:GEMINI_API_KEY="your_api_key_here"替代方案: 直接通过
--gemini-api-key命令行选项提供你的密钥。
你可以在 Google AI Studio 或 Google Cloud 控制台获取 Gemini API 密钥。
3. 生成你的第一个 llm-min.txt 文件:💻
从以下输入源中选择一个:
| 输入源选项 | 短选项 | 类型 | 功能 |
|---|---|---|---|
--input-folder |
-i |
DIRECTORY |
📁 处理本地文档文件。 递归扫描指定目录中的 .md、.txt 和 .rst 文件。使用此选项时会跳过网页爬取。 |
--package |
-pkg |
TEXT |
📦 处理 Python 包。 自动查找并爬取该包的文档网站。 |
--doc-url |
-u |
TEXT |
🌐 处理文档网站。 直接爬取指定的 URL。 |
| 配置选项 | 短选项 | 类型 | 功能 |
|---|---|---|---|
--output-dir |
-o |
DIRECTORY |
保存生成文件的目录(默认:llm_min_docs)。 |
--output-name |
-n |
TEXT |
为 output-dir 内的子文件夹指定自定义名称。 |
--library-version |
-V |
TEXT |
指定库版本(在使用 --input-folder 或 --doc-url 时有用)。 |
--max-crawl-pages |
-p |
INTEGER |
最多读取的网页数量(默认:200;0 表示无限制)。仅适用于网页爬取。 |
--max-crawl-depth |
-D |
INTEGER |
在网站上跟随链接的最大深度(默认:3)。仅适用于网页爬取。 |
--chunk-size |
-c |
INTEGER |
每次传递给 AI 的文本量(默认:0,启用自适应分块)。如果为 0,llm-min 会自动确定最佳大小。 |
--gemini-api-key |
-k |
TEXT |
你的 Gemini API 密钥(如果未设置为环境变量)。 |
--gemini-model |
-m |
TEXT |
要使用的 Gemini 模型(默认:gemini-2.5-flash-lite-preview-06-17)。 |
--force-reprocess |
即使存在 llm-full.txt 也强制重新处理,并忽略中间文件。 |
||
--save-fragments |
BOOLEAN |
保存中间片段以便调试和重试(默认:True)。 | |
--verbose |
-v |
在运行时显示更详细的日志信息。 |
示例命令:
# 📦 处理 "typer" Python 包,保存到 "my_docs" 文件夹
llm-min -pkg "typer" -o my_docs -p 50
# 🌐 处理 FastAPI 文档网站
llm-min -u "https://fastapi.tiangolo.com/" -o my_docs -p 50
# 📁 处理本地文件夹中的文档文件
llm-min -i "./docs" -o my_docs
# 📁 处理本地文件,自定义输出名称和版本
llm-min -i "./my-project-docs" -o my_docs -n "my-project" -V "1.2.3"
# 📁 处理项目的整个文档目录结构
llm-min -i "/path/to/project/documentation" -o project_docs --verbose
本地文件夹处理详情: 📁
当使用 --input-folder 时,llm-min 会:
- 递归扫描指定目录中的文档文件
- 处理扩展名为
.md(Markdown)、.txt(纯文本)、.rst(reStructuredText)的文件 - 将所有找到的文件合并成一个内容流
- 完全跳过网页爬取(从而更快且无需互联网连接)
- 将原始合并内容保存为
llm-full.txt,并生成压缩后的llm-min.txt
这特别适用于:
- 内部/专有文档,这些文档无法在线获取
- 本地项目文档,你正在开发的文档
- 离线处理,当互联网访问受限时
- 自定义格式的文档
4. 在 Python 中的程序化使用: 🐍
你也可以直接将 llm-min 集成到你的 Python 应用程序中:
from llm_min import LLMMinGenerator
import os
# 用于 AI 处理的配置
llm_config = {
"api_key": os.environ.get("GEMINI_API_KEY"), # 使用环境变量
"model_name": "gemini-2.5-flash-lite-preview-06-17", # 推荐模型
"chunk_size": 600000, # 每次 AI 处理的字符数
"max_crawl_pages": 200, # 最大爬取页面数(仅限网页爬取)
"max_crawl_depth": 3, # 链接跟随深度(仅限网页爬取)
}
# 初始化生成器(输出文件将保存到 ./my_output_docs/[source_name]/)
generator = LLMMinGenerator(output_dir="./my_output_docs", llm_config=llm_config)
# 📦 为 Python 包生成 llm-min.txt
try:
generator.generate_from_package("requests")
print("✅ 成功创建了 'requests' 的文档!")
except Exception as e:
print(f"❌ 处理 'requests' 时出错:{e}")
# 🌐 从文档 URL 生成 llm-min.txt
try:
generator.generate_from_url("https://fastapi.tiangolo.com/")
print("✅ 成功处理了 FastAPI 文档!")
except Exception as e:
print(f"❌ 处理 URL 时出错:{e}")
# 📁 从本地文档文件生成 llm-min.txt
try:
# 读取并合并本地文件夹中的所有文档文件
import pathlib
docs_folder = pathlib.Path("./my-project-docs")
# 收集支持的文件类型内容
content = ""
for ext in [".md", ".txt", ".rst"]:
for file_path in docs_folder.rglob(f"*{ext}"):
with open(file_path, encoding="utf-8") as f:
content += f"# 文件: {file_path.name}\n\n"
content += f.read() + "\n\n---\n\n"
# 处理合并后的内容
generator.generate_from_text(
input_content=content,
source_name="my-project",
library_version="1.0.0" # 可选
)
print("✅ 成功处理了本地文档!")
except Exception as e:
print(f"❌ 处理本地文件时出错:{e}")
如需查看完整的命令行选项列表,请运行:
llm-min --help
输出目录结构 📂
当 llm-min 完成处理后,会创建如下整齐的目录结构:
your_chosen_output_dir/
└── name_of_package_or_website/
├── llm-full.txt # 完整文档文本(原始内容)
├── llm-min.txt # 压缩后的 SKF/1.4 LA 结构化摘要
└── llm-min-guideline.md # 用于 AI 解读的重要格式说明文档
例如,运行 llm-min -pkg "requests" -o my_llm_docs 后,将生成:
my_llm_docs/
└── requests/
├── llm-full.txt # 原始文档
├── llm-min.txt # 压缩后的 SKF 格式(D、I、U 部分)
└── llm-min-guideline.md # 格式解码说明
重要提示: llm-min-guideline.md 文件是 llm-min.txt 的关键配套文件。它提供了详细的模式定义和格式说明,AI 需要这些信息才能正确解读结构化数据。在使用 llm-min.txt 与 AI 助手交互时,务必同时提供此指南文件。
选择合适的 AI 模型(为何推荐 Gemini) 🧠
llm-min 使用 Google 的 Gemini 系列 AI 模型进行文档处理。虽然您可以通过 --gemini-model 选项指定特定的 Gemini 模型,但我们强烈建议使用默认设置:gemini-2.5-flash-lite-preview-06-17。
该模型在文档压缩方面具备以下优势,能够实现最佳效果:
高级推理能力: 在理解复杂的技术文档以及提取 SKF 格式所需的关键结构关系方面表现出色。
超大上下文窗口: 具备 100 万标记的输入容量,可一次性处理大量文档内容,从而实现更连贯、更全面的分析。
成本效益高: 相较于其他大上下文模型,其性能与价格比更为理想。
默认模型经过精心挑选,能够在广泛的文档风格和技术领域中为 llm-min 的压缩流程带来最佳结果。
工作原理:内部解析(src/llm_min)⚙️
llm-min 工具采用一套复杂的多阶段流程,将冗长的文档转换为紧凑且针对机器优化的 SKF 清单:
输入处理: 根据您的命令行选项,
llm-min会从相应来源收集文档:- 包(
--package "requests"): 自动发现并抓取该包的文档网站 - URL(
--doc-url "https://..."): 直接抓取指定的文档网站 - 本地文件夹(
--input-folder "./docs"): 递归扫描.md、.txt和.rst文件,并合并其内容
- 包(
文本准备: 收集到的文档会被清理并分割成易于处理的小块。原始文本会以
llm-full.txt的形式保留。三步 AI 分析流水线(Gemini): 这是生成 SKF 清单的核心部分,由
compacter.py中的compact_content_to_structured_text函数协调完成:步骤 1:全局术语表生成(仅内部使用):
- 每个文档块都会使用
SKF_PROMPT_CALL1_GLOSSARY_TEMPLATE提示词进行分析,以识别关键的技术实体,并生成带有临时GxxxID 的“块内”术语表片段。 - 这些片段会通过
SKF_PROMPT_CALL1_5_MERGE_GLOSSARY_TEMPLATE提示词合并,解决重复项并创建统一的实体列表。 - 随后,
re_id_glossary_items函数会为这些合并后的实体分配全局连续的GxxxID(G001、G002 等)。 - 该全局术语表在整个过程中会保留在内存中,但不会包含在最终的
llm-min.txt输出中,以节省空间。
- 每个文档块都会使用
步骤 2:定义与交互(D & I)生成:
- 对于第一个文档块(或当只有一个块时),AI 会结合全局术语表,使用
SKF_PROMPT_CALL2_DETAILS_SINGLE_CHUNK_TEMPLATE生成初始的 D 和 I 条目。 - 对于后续块,则使用
SKF_PROMPT_CALL2_DETAILS_ITERATIVE_TEMPLATE,同时提供全局术语表和先前生成的 D&I 条目作为上下文,以避免重复。 - 随着每个块的处理,新识别的 D 和 I 条目会被累积起来,并被赋予全局连续的 ID(D001、D002 等以及 I001、I002 等)。
- 对于第一个文档块(或当只有一个块时),AI 会结合全局术语表,使用
步骤 3:使用模式(U)生成:
- 类似于步骤 2,第一个块使用
SKF_PROMPT_CALL3_USAGE_SINGLE_CHUNK_TEMPLATE,接收全局术语表、所有已累积的 D&I 条目以及当前块的文本。 - 后续块则使用
SKF_PROMPT_CALL3_USAGE_ITERATIVE_TEMPLATE,额外接收之前生成的 U 条目,以便延续模式并避免重复。 - 使用模式会被赋予描述性名称(如
U_BasicNetworkFetch),并包含编号步骤(如U_BasicNetworkFetch.1、U_BasicNetworkFetch.2)。
- 类似于步骤 2,第一个块使用
最终组装: 完整的
llm-min.txt文件通过以下内容组合而成:- SKF 清单头部(协议版本、源文档、时间戳、主命名空间)
- 累积的“DEFINITIONS”部分
- 累积的“INTERACTIONS”部分
- 累积的“USAGE_PATTERNS”部分
- 最终的
# END_OF_MANIFEST标记
概念性流程概览:
用户输入 → 文档收集 → 文本处理 → AI 步骤 1:术语表 → 内存中的全局 → AI 步骤 2:D&I → 累积的 D&I
(CLI/Python) (包/URL) (分块) (提取 + 合并) 术语表(Gxxx) (按块) (Dxxx、Ixxx)
↓
┌─────────────────────────────────────────────────────────────────────────────────────────────────┐ ↓
↓ ↑ ↓
最终 SKF 清单 ← 组装 ← 累积的使用 ← AI 步骤 3:使用 ← 全局术语表 + 累积的 D&I
(llm-min.txt) (D,I,U) 模式(U_Name.N) (按块) (生成有效 U 条目的必要上下文)
这种多阶段方法确保了 SKF 清单的全面性,避免了跨块内容的重复,并保持了实体、定义、交互和使用模式之间的一致性引用。
下一步?未来计划 🔮
我们正在探索几个令人兴奋的方向来进一步发展 llm-min:
预生成文件的公共仓库 🌐 如果能建立一个中央枢纽,供社区共享和发现常用库的
llm-min.txt文件,这将非常有价值。这样可以省去用户反复生成这些文件的麻烦,并确保信息的一致性和高质量。主要挑战包括质量控制、版本管理和托管基础设施成本。基于代码的文档推断 💻 一种有趣的可能性是利用源代码分析(通过抽象语法树)自动生成或补充文档摘要。尽管初步实验表明这在技术上颇具挑战性,尤其是对于具有动态行为的复杂库而言,但这仍然是一个很有前景的研究方向,有望实现更精确的文档生成。
模型控制协议集成 🤔 尽管从技术上可行,但将
llm-min实现为 MCP 服务器并不完全符合我们当前的设计理念。llm-min.txt的优势在于提供可靠、静态的上下文——这是一种确定性的参考,能够降低动态 AI 集成有时带来的不确定性。我们正在密切关注用户需求,以判断未来是否可以通过服务器端方式提供价值。
我们欢迎社区对这些潜在方向提出宝贵意见!
常见问题 (FAQ) ❓
问:生成 llm-min.txt 文件是否需要具备推理能力的模型? 🧠
答:是的,生成 llm-min.txt 文件需要像 Gemini 这样具有强大推理能力的模型。这一过程涉及复杂的信息提取、实体关系映射以及结构化知识表示。不过,一旦生成,llm-min.txt 文件就可以被任何具备良好编码能力的模型(例如 Claude 3.5 Sonnet)有效使用,以回答与特定库相关的问题。
问:llm-min.txt 是否保留了原始文档中的所有信息? 📚
答:不是。llm-min.txt 明确设计为一种有损压缩格式。它优先保留与编程相关的细节(类、方法、参数、返回类型、核心使用模式),而有意省略说明性文字、概念讨论及次要信息。正是这种有选择性的信息保留,才使得令牌数量大幅减少,同时仍能维持 AI 助手所需的基本技术参考信息。
问:为什么生成 llm-min.txt 文件需要花费时间? ⏱️
答:创建 llm-min.txt 文件涉及一个复杂的多阶段 AI 流程:
- 收集并预处理文档;
- 分析每个代码块以识别实体(生成术语表);
- 整合各代码块中的实体;
- 从每个代码块中提取详细定义和交互信息;
- 生成具有代表性的使用模式。
这一密集型过程可能需要数分钟,尤其是对于大型库而言。然而,一旦生成,生成的 llm-min.txt 文件可以无限期重复使用,为 AI 助手提供更快捷的参考信息。
问:我收到了“Gemini 生成因 MAX_TOKENS 限制而停止”的错误提示,该怎么办? 🛑
答:此错误表明 Gemini 模型在处理特别密集或复杂的文档代码块时达到了其输出限制。您可以尝试减小 --chunk-size 参数值(例如从 600,000 字符降至 300,000 字符),以便让模型每次处理较小的批次。虽然这可能会因更多独立调用而导致 API 费用略有增加,但通常可以解决令牌限制错误。
问:生成一个 llm-min.txt 文件的典型费用是多少? 💰
答:处理成本因文档大小和复杂度而异,但对于中等规模的库,预计 Gemini API 的费用将在 0.01 至 1.00 美元 之间。影响成本的主要因素包括:
- 文档总大小;
- 处理的代码块数量;
- 库结构的复杂程度;
- 所选的 Gemini 模型。
有关当前定价详情,请参阅 Google Cloud AI 定价页面。
问:我能否在没有互联网连接的情况下处理本地文档文件? 📁
答:可以!--input-folder 选项非常适合离线处理。使用此选项时,llm-min 将:
- 完全跳过网络爬取(无需互联网即可收集内容);
- 仅在压缩过程中需要访问互联网以调用 Gemini API;
- 递归支持任意目录结构中的
.md、.txt和.rst文件; - 可用于处理内部或专有文档,这些文档并未公开发布在网上。
这使其成为处理私有文档、本地开发文档,或在互联网连接受限情况下工作的理想选择。
问:你是用代码来完成这个项目的吗? 🤖
答:是的,当然。该项目是使用 Roocode 并结合名为 Rooroo 的自定义配置开发的。
想帮忙吗?贡献力量 🤝
我们欢迎各位为使 llm-min 更加完善而做出贡献!🎉
无论您是报告 bug、提出功能建议,还是通过拉取请求提交代码更改,您的参与都将帮助改进这款工具,造福所有人。请查看我们的 GitHub 仓库,了解贡献指南和当前的开放问题。
许可证 📜
本项目采用 MIT 许可证授权。完整详情请参阅 LICENSE 文件。
版本历史
v0.2.42025/06/01相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。