ChatGLM-Finetuning
ChatGLM-Finetuning 是一个专为 ChatGLM、ChatGLM2 及 ChatGLM3-6B 系列大模型设计的微调工具包。它旨在帮助开发者低成本地将通用大模型适配到信息抽取、文本生成、分类等具体下游任务中,有效解决了大模型在特定场景落地难的问题,同时通过单指令集微调策略,显著降低了模型出现“灾难性遗忘”的风险。
该项目非常适合算法工程师、研究人员以及希望深入理解大模型训练流程的开发者使用。其独特亮点在于提供了 Freeze(参数冻结)、LoRA、P-tuning 及全量参数微调等多种主流策略,并支持从单卡到多卡的灵活训练配置。为了降低显存门槛,工具集成了 DeepSpeed、gradient_checkpointing 及 Zero3 等优化技术。此外,项目代码未过度封装,摒弃了黑盒式的 Trainer 接口,让使用者能清晰掌控训练细节,便于根据实际需求进行深度定制与修改,是学习与实践大模型微调的优质开源资源。
使用场景
某金融科技公司风控团队需要将通用大模型改造为能精准识别信贷合同风险条款的专用助手。
没有 ChatGLM-Finetuning 时
- 领域知识匮乏:通用模型无法理解“连带保证责任”、“交叉违约”等专业术语,回答泛泛而谈甚至产生幻觉。
- 硬件门槛过高:全量微调 6B 模型需多张高端显卡,公司现有的单卡开发机显存不足,无法启动训练。
- 灾难性遗忘严重:尝试自行修改代码微调后,模型虽然记住了新规则,却忘记了基础对话能力,变得无法交互。
- 试错成本高昂:缺乏对 Freeze、LoRA 等多种微调策略的集成对比,算法工程师需花费数周手写底层训练循环。
使用 ChatGLM-Finetuning 后
- 任务精准适配:利用项目提供的信息抽取任务模板进行 LoRA 微调,模型能准确从合同中提取风险实体与关系,准确率提升至 92%。
- 单卡高效训练:通过配置
gradient_checkpointing和Freeze方法,成功在单张消费级显卡上完成训练,大幅降低硬件投入。 - 能力平衡保持:得益于单指令集微调优化,模型在掌握风控知识的同时,保留了流畅的自然语言沟通能力,无灾难性遗忘。
- 策略灵活切换:团队快速对比了 Freeze 与全参微调效果,仅用两天便确定了最优训练方案,无需重复造轮子。
ChatGLM-Finetuning 让中小团队也能以低算力成本,将通用大模型快速转化为高可用的垂直领域专家。
运行环境要求
- Linux
- 必需 NVIDIA GPU
- 支持单卡或多卡训练
- 根据显存测试数据,单卡训练 ChatGLM/ChatGLM2 (Batch Size=1, Max Len=1560) 需约 35-38GB 显存(如 A40)
- 开启 Gradient Checkpointing 后需约 36GB
- 多卡 (4 卡) 环境下每张卡需 22-29GB 显存
- 建议使用 DeepSpeed ZeRO-2/3、Offload 或 Gradient Checkpointing 以节省显存
未说明

快速开始
ChatGLM微调
本项目主要针对ChatGLM、ChatGLM2和ChatGLM3模型进行不同方式的微调(Freeze方法、Lora方法、P-Tuning方法、全量参数等),并对比大模型在不同微调方法上的效果,主要针对信息抽取任务、生成任务、分类任务等。
本项目支持单卡训练&多卡训练,由于采用单指令集方式微调,模型微调之后并没有出现严重的灾难性遗忘。
由于官方代码和模型一直在更新,目前ChatGLM1和2的代码和模型的为20230806版本(注意如果发现代码运行有误,可将ChatGLM相关源码替换文件中的py文件,因为可能你下的模型版本与本项目代码版本不一致),ChatGLM3是版本20231212。
PS:没有用Trainer(虽然Trainer代码简单,但不易修改,大模型时代算法工程师本就成为了数据工程师,因此更需了解训练流程)
更新简介
- update-2023.12.12 增加ChatGLM3代码支持,通过model_type完成模型切换,并增加推理代码。
- update-2023.08.06 代码和模型已经更新到最新,支持单卡&多卡训练,支持ChatGLM2模型训练、支持全量参数训练,所有代码进行了结构增加可读性。
- update-2023.06.12 增加流水线并行训练方法,请看v0.1 Tag
- update-2023.04.18 增加文本生成任务评测,请看v0.1 Tag
- update-2023.04.05 增加信息抽取任务评测,请看v0.1 Tag
微调方法
模型微调时,如果遇到显存不够的情况,可以开启gradient_checkpointing、zero3、offload等参数来节省显存。
下面model_name_or_path参数为模型路径,请根据可根据自己实际模型保存地址进行修改。
冻结方法
冻结方法,即参数冻结,对原始模型部分参数进行冻结操作,仅训练部分参数,以达到在单卡或多卡,不进行TP或PP操作就可以对大模型进行训练。
微调代码,见train.py,核心部分如下:
freeze_module_name = args.freeze_module_name.split(",")
for name, param in model.named_parameters():
if not any(nd in name for nd in freeze_module_name):
param.requires_grad = False
针对模型不同层进行修改,可以自行修改freeze_module_name参数配置,例如"layers.27.,layers.26.,layers.25.,layers.24."。 训练代码均采用DeepSpeed进行训练,可设置参数包含train_path、model_name_or_path、mode、train_type、freeze_module_name、ds_file、num_train_epochs、per_device_train_batch_size、gradient_accumulation_steps、output_dir等, 可根据自己的任务配置。
ChatGLM单卡训练
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM-6B/ \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm \
--train_type freeze \
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24." \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm
ChatGLM四卡训练,通过CUDA_VISIBLE_DEVICES控制具体哪几块卡进行训练,如果不加该参数,表示使用运行机器上所有卡进行训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM-6B/ \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm \
--train_type freeze \
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24." \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm
ChatGLM2单卡训练
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM2-6B/ \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm2 \
--train_type freeze \
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24." \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm2
ChatGLM2四卡训练,通过CUDA_VISIBLE_DEVICES控制具体哪几块卡进行训练,如果不加该参数,表示使用运行机器上所有卡进行训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM2-6B/ \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup ratio 0.1 \
--mode glm2 \
--train_type freeze \
--freeze module name "layers.27.,layers.26.,layers.25.,layers.24." \
--seed 1234 \
--ds file ds_zero2_no_offload.json \
--gradient checkpointing \
--show loss step 10 \
--output dir ./output-glm2
ChatGLM3单卡训练
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM3-6B/ \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning rate 1e-4 \
--weight decay 0.1 \
--num_train epochs 2 \
--gradient accumulation steps 4 \
--warmup ratio 0.1 \
--mode glm3 \
--train type freeze \
--freeze module name "layers.27.,layers.26.,layers.25.,layers.24." \
--seed 1234 \
--ds file ds_zero2_no_offload.json \
--gradient checkpointing \
--show loss step 10 \
--output dir ./output-glm3
ChatGLM3四卡训练,通过CUDA_VISIBLE_DEVICES控制具体哪几块卡进行训练,如果不加该参数,表示使用运行机器上所有卡进行训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master port 520 train.py \
--train path data/spo_0.json \
--model name or path ChatGLM3-6B/ \
--per device train batch size 1 \
--max len 1560 \
--max src len 1024 \
--learning rate 1e-4 \
--weight decay 0.1 \
--num train epochs 2 \
--gradient accumulation steps 4 \
--warmup ratio 0.1 \
--mode glm3 \
--train type freeze \
--freeze module name "layers.27.,layers.26.,layers.25.,layers.24." \
--seed 1234 \
--ds file ds_zero2_no_offload.json \
--gradient checkpointing \
--show loss step 10 \
--output dir ./output-glm3
PS:ChatGLM微调时所用显存要比ChatGLM2多,详细显存占比如下:
| Model | DeepSpeed-Stage | Offload | Gradient Checkpointing | Batch Size | Max Length | GPU-A40 Number | 所耗显存 |
|---|---|---|---|---|---|---|---|
| ChaGLM | zero2 | No | Yes | 1 | 1560 | 1 | 36G |
| ChaGLM | zero2 | No | No | 1 | 1560 | 1 | 38G |
| ChaGLM | zero2 | No | Yes | 1 | 1560 | 4 | 24G |
| ChaGLM | zero2 | No | No | 1 | 1560 | 4 | 29G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 1 | 35G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 1 | 36G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 4 | 22G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 4 | 27G |
PT方法
PT方法,即P-Tuning方法,参考ChatGLM官方代码 ,是一种针对于大模型的soft-prompt方法。
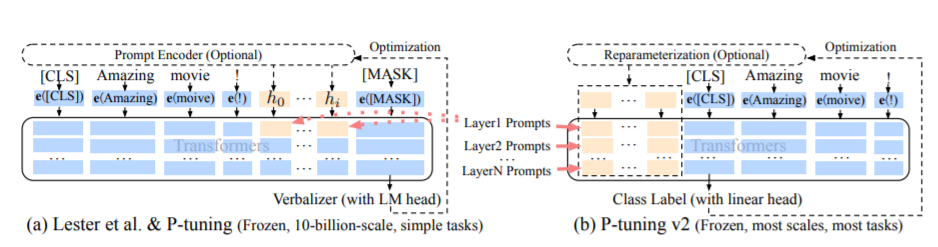
微调代码见train.py,核心部分如下:
config = MODE[args.mode]["config"].from_pretrained(args.model_name_or_path)
config.pre_seq_len = args.pre_seq_len
config.prefix_projection = args.prefix_projection
model = MODE[args.mode]["model"].from_pretrained(args.model_name_or_path, config=config)
for name, param in model.named_parameters():
if not any(nd in name for nd in ["prefix_encoder"]):
param.requires_grad = False
当prefix_projection为True时,为P-Tuning-V2方法,在大模型的Embedding和每一层前都加上新的参数;为False时,为P-Tuning方法,仅在大模型的Embedding上新的参数。
训练代码均采用DeepSpeed进行训练,可设置参数包含train_path、model_name_or_path、mode、train_type、pre_seq_len、prefix_projection、ds_file、num_train_epochs、per_device_train_batch_size、gradient_accumulation_steps、output_dir等, 可根据自己的任务配置。
ChatGLM单卡训练
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM-6B \
--per_device_train_batch_size 1 \
--max_len 768 \
--max_src_len 512 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm \
--train_type ptuning \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--pre_seq_len 16 \
--prefix_projection True \
--output_dir ./output-glm
ChatGLM四卡训练,通过CUDA_VISIBLE_DEVICES控制具体哪几块卡进行训练,如果不加该参数,表示使用运行机器上所有卡进行训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm \
--train_type ptuning \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--pre_seq_len 16 \
--prefix_projection True \
--output_dir ./output-glm
ChatGLM2单卡训练
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM2-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm2 \
--train_type ptuning \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--pre_seq_len 16 \
--prefix_projection True \
--output_dir ./output-glm2
ChatGLM2四卡训练,通过CUDA_VISIBLE_DEVICES控制具体哪几块卡进行训练,如果不加该参数,表示使用运行机器上所有卡进行训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM2-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm2 \
--train_type ptuning \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--pre_seq_len 16 \
--prefix_projection True \
--output_dir ./output-glm2
ChatGLM3单卡训练
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM3-6B/ \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm3 \
--train_type ptuning \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--pre_seq_len 16 \
--prefix_projection True \
--output_dir ./output-glm3
ChatGLM3四卡训练,通过CUDA_VISIBLE_DEVICES控制具体哪几块卡进行训练,如果不加该参数,表示使用运行机器上所有卡进行训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM3-6B/ \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm3 \
--train_type ptuning \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--pre_seq_len 16 \
--prefix_projection True \
--output_dir ./output-glm3
PS:ChatGLM微调时所用显存要比ChatGLM2多,详细显存占比如下:
| Model | DeepSpeed-Stage | Offload | Gradient Checkpointing | Batch Size | Max Length | GPU-A40 Number | 所耗显存 |
|---|---|---|---|---|---|---|---|
| ChaGLM | zero2 | No | Yes | 1 | 768 | 1 | 43G |
| ChaGLM | zero2 | No | No | 1 | 300 | 1 | 44G |
| ChaGLM | zero2 | No | Yes | 1 | 1560 | 4 | 37G |
| ChaGLM | zero2 | No | No | 1 | 1360 | 4 | 44G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 1 | 20G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 1 | 40G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 4 | 19G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 4 | 39G |
Lora方法
Lora方法,即在大型语言模型上对指定参数(权重矩阵)并行增加额外的低秩矩阵,并在模型训练过程中,仅训练额外增加的并行低秩矩阵的参数。 当“秩值”远小于原始参数维度时,新增的低秩矩阵参数量也就很小。在下游任务tuning时,仅须训练很小的参数,但能获取较好的表现结果。
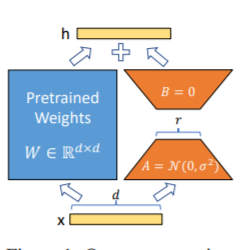
微调代码,见train.py,核心部分如下:
model = MODE[args.mode]["model"].from_pretrained(args.model_name_or_path)
lora_module_name = args.lora_module_name.split(",")
config = LoraConfig(r=args.lora_dim,
lora_alpha=args.lora_alpha,
target_modules=lora_module_name,
lora_dropout=args.lora_dropout,
bias="none",
task_type="CAUSAL_LM",
inference_mode=False,
)
model = get_peft_model(model, config)
model.config.torch_dtype = torch.float32
PS: Lora训练之后,请先参数合并,在进行模型预测。
训练代码均采用DeepSpeed进行训练,可设置参数包含train_path、model_name_or_path、mode、train_type、lora_dim、lora_alpha、lora_dropout、lora_module_name、ds_file、num_train_epochs、per_device_train_batch_size、gradient_accumulation_steps、output_dir等, 可根据自己的任务配置。
ChatGLM单卡训练
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm \
--train_type lora \
--lora_dim 16 \
--lora_alpha 64 \
--lora_dropout 0.1 \
--lora_module_name "query_key_value" \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm
ChatGLM四卡训练,通过CUDA_VISIBLE_DEVICES控制具体哪几块卡进行训练,如果不加该参数,表示使用运行机器上所有卡进行训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm \
--train_type lora \
--lora_dim 16 \
--lora_alpha 64 \
--lora_dropout 0.1 \
--lora_module_name "query_key_value" \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm
ChatGLM2单卡训练
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM2-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm2 \
--train_type lora \
--lora_dim 16 \
--lora_alpha 64 \
--lora_dropout 0.1 \
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense" \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm2
ChatGLM2四卡训练,通过CUDA_VISIBLE_DEVICES控制具体哪几块卡进行训练,如果不加该参数,表示使用运行机器上所有卡进行训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM2-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation steps 4 \
--warmup ratio 0.1 \
--mode glm2 \
--train type lora \
--lora dim 16 \
--lora alpha 64 \
--lora dropout 0.1 \
--lora module name "query key value,dense h to 4h,dense 4h to h,dense" \
--seed 1234 \
--ds file ds zero2 no offload.json \
--gradient checkpointing \
--show loss step 10 \
--output dir ./output-glm2
ChatGLM3单卡训练
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM3-6B/ \
--per_device_train_batch_size 1 \
--max len 1560 \
--max src len 1024 \
--learning rate 1e-4 \
--weight decay 0.1 \
--num train epochs 2 \
--gradient accumulation steps 4 \
--warmup ratio 0.1 \
--mode glm3 \
--lora dim 16 \
--lora alpha 64 \
--lora dropout 0.1 \
--lora module name "query key value,dense h to 4h,dense 4h to h,dense" \
--seed 1234 \
--ds file ds zero2 no offload.json \
--gradient checkpointing \
--show loss step 10 \
--output dir ./output-glm3
ChatGLM3四卡训练,通过CUDA_VISIBLE_DEVICES控制具体哪几块卡进行训练,如果不加该参数,表示使用运行机器上所有卡进行训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master port 520 train.py \
--train path data/spo_0.json \
--model name or path ChatGLM3-6B/ \
--per device train batch size 1 \
--max len 1560 \
--max src len 1024 \
--learning rate 1e-4 \
--weight decay 0.1 \
--num train epochs 2 \
--gradient accumulation steps 4 \
--warmup ratio 0.1 \
--mode glm3 \
--lora dim 16 \
--lora alpha 64 \
--lora dropout 0.1 \
--lora module name "query key value,dense h to 4h,dense 4h to h,dense" \
--seed 1234 \
--ds file ds zero2 no offload.json \
--gradient checkpointing \
--show loss step 10 \
--output dir ./output-glm3
PS:ChatGLM微调时所用显存要比ChatGLM2多,详细显存占比如下:
| 模型 | DeepSpeed阶段 | Offload | 梯度检查点 | 批量大小 | 最大长度 | GPU-A40数量 | 所耗显存 |
|---|---|---|---|---|---|---|---|
| ChaGLM | zero2 | 否 | 是 | 1 | 1560 | 1 | 20G |
| ChaGLM | zero2 | 否 | 否 | 1 | 1560 | 1 | 45G |
| ChaGLM | zero2 | 否 | 是 | 1 | 1560 | 4 | 20G |
| ChaGLM | zero2 | 否 | 否 | 1 | 1560 | 4 | 45G |
| ChaGLM2 | zero2 | 否 | 是 | 1 | 1560 | 1 | 20G |
| ChaGLM2 | zero2 | 否 | 否 | 1 | 1560 | 1 | 43G |
| ChaGLM2 | zero2 | 否 | 是 | 1 | 1560 | 4 | 19G |
| ChaGLM2 | zero2 | 否 | 否 | 1 | 1560 | 4 | 42G |
注意:Lora方法在模型保存时仅保存了Lora训练参数,因此在模型预测时需要将模型参数进行合并,具体参考merge_lora.py。
全参方法
全参方法,对大模型进行全量参数训练,主要借助DeepSpeed-Zero3方法,对模型参数进行多卡分割,并借助Offload方法,将优化器参数卸载到CPU上以解决显卡不足问题。
微调代码,见train.py,核心部分如下:
model = MODE[args.mode]["model"].from_pretrained(args.model_name_or_path)
训练代码均采用DeepSpeed进行训练,可设置参数包含train_path、model_name_or_path、mode、train_type、ds_file、num_train_epochs、per_device_train_batch_size、gradient_accumulation_steps、output_dir等, 可根据自己的任务配置。
ChatGLM四卡训练,通过CUDA_VISIBLE_DEVICES控制具体哪几块卡进行训练,如果不加该参数,表示使用运行机器上所有卡进行训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm \
--train_type all \
--seed 1234 \
--ds_file ds_zero3_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm
ChatGLM2四卡训练,通过CUDA_VISIBLE_DEVICES控制具体哪几块卡进行训练,如果不加该参数,表示使用运行机器上所有卡进行训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM2-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm2 \
--train_type all \
--seed 1234 \
--ds_file ds_zero3_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm2
ChatGLM3四卡训练,通过CUDA_VISIBLE_DEVICES控制具体哪几块卡进行训练,如果不加该参数,表示使用运行机器上所有卡进行训练
CCUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM3-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm3 \
--train_type all \
--seed 1234 \
--ds_file ds_zero3_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm3
PS:ChatGLM微调时所用显存要比ChatGLM2多,详细显存占比如下:
| 模型 | DeepSpeed阶段 | Offload | 梯度检查点 | 批量大小 | 最大长度 | GPU-A40数量 | 所耗显存 |
|---|---|---|---|---|---|---|---|
| ChaGLM | zero3 | 是 | 是 | 1 | 1560 | 4 | 33G |
| ChaGLM2 | zero3 | 否 | 是 | 1 | 1560 | 4 | 44G |
| ChaGLM2 | zero3 | 是 | 是 | 1 | 1560 | 4 | 26G |
后面补充DeepSpeed的Zero-Stage的相关内容说明。
运行环境
查看requirements.txt文件
实验结果
三元组抽取
- 为了防止大模型的数据泄露,采用一个领域比赛数据集-汽车工业故障模式关系抽取,随机抽取50条作为测试集
- 训练示例:
{
"instruction": "你现在是一个信息抽取模型,请你帮我抽取出关系内容为\"性能故障\", \"部件故障\", \"组成\"和 \"检测工具\"的相关三元组,三元组内部用\"_\"连接,三元组之间用\\n分割。文本:",
"input": "故障现象:发动机水温高,风扇始终是低速转动,高速档不工作,开空调尤其如此。",
"output": "发动机_部件故障_水温高\n风扇_部件故障_低速转动"
}
| 微调方法 | PT-Only-Embedding | PT | Freeze | Lora |
|---|---|---|---|---|
| 测试结果F1 | 0.0 | 0.6283 | 0.5675 | 0.5359 |
结构分析:
- 效果为PT>Freeze>Lora>PT-Only-Embedding
- PT-Only-Embedding效果很不理想,发现在训练时,最后的loss仅能收敛到2.几,而其他机制可以收敛到0.几。分析原因为,输出内容形式与原有语言模型任务相差很大,仅增加额外Embedding参数,不足以改变复杂的下游任务。
- 上面测试仅代表个人测试结果,并且由于生成模型生成长度对推理耗时影响很大,因此可以其他数据会有不一样的结果。
- 模型在指定任务上微调之后,并没有丧失原有能力,例如生成“帮我写个快排算法”,依然可以生成-快排代码。
- 由于大模型微调都采用大量instruction进行模型训练,仅采用单一的指令进行微调时,对原来其他的指令影响不大,因此并没导致原来模型的能力丧失。
很多同学在微调后出现了灾难性遗忘现象,但本项目的训练代码并没有出现,对“翻译任务”、“代码任务”、“问答任务”进行测试,具体测试效果如下:
翻译任务

代码任务
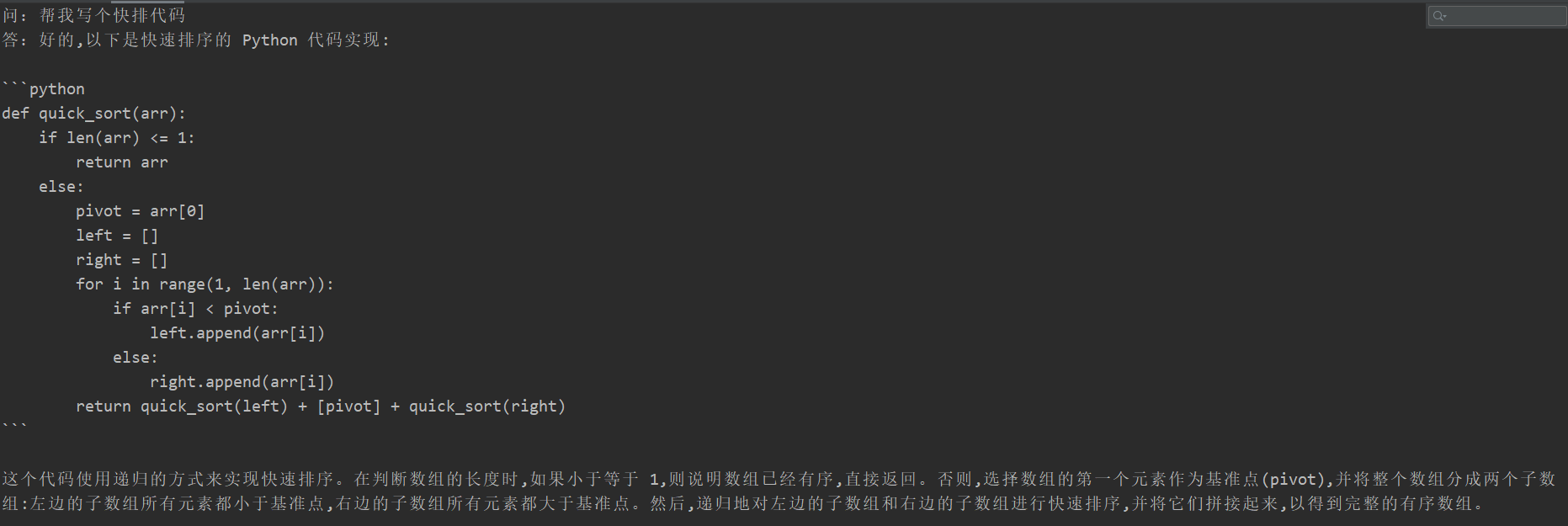
问答任务

文本生成
- 为了防止大模型的数据泄露,采用一个“万创杯”中医药天池大数据竞赛-中医文献问题生成挑战,随机抽取20条作为测试集
- PT为官方的P-Tuning V2训练方法,PT-Only-Embedding表示仅对Embedding进行soft-prompt,Freeze仅训练模型后五层参数,Lora采用低秩矩阵方法训练,秩为8;
- 训练示例:
{
"instruction": "你现在是一个问题生成模型,请根据下面文档生成一个问题,文档:",
"input": "清热解毒口服液由生石膏、知母、紫花地丁、金银花、麦门冬、黄芩、玄参、连翘、龙胆草、生地黄、栀子、板蓝根组成。具有疏风解表、清热解毒利咽、生津止渴的功效,适用于治疗外感时邪、内有蕴热所致的身热汗出、头痛身痛、心烦口渴、微恶寒或反恶热、舌红、苔黄、脉数等症。现代临床主要用于治疗流行性感冒、流行性脑脊髓膜炎、肺炎等各种发热性疾病。口服液:每支10毫升,每次10~20毫升,每日3次。〔注意事项〕阳虚便澹者不宜使用。",
"output": "清热解毒口服的功效有哪些?"
}
由于生成模型的内容不能想信息抽取任务一样评价,用现有的BLUE或者Rouge来评价也是不合适,因此制定了评分规则。 通过多样性和准确性两个角度判断D2Q模型好坏,每个样本总计5分,共20个样本。
- 多样性:
- 问题是否高度相似,每重复一个问题扣0.25分;
- 问题对应答案是否相同,每有一个重复答案或找不到答案,扣0.25分;
- 准确性:
- 问题能否从文档中找到答案,每有一个找不到答案,扣0.25分;
- 问题内容是否流畅,每有一个问题不流畅,扣0.25分;
- 问题内容是否有害,每有一个有害,扣0.25分;
| 微调方法 | 原始模型 | PT-Only-Embedding | PT | Freeze | Lora |
|---|---|---|---|---|---|
| 分数 | 51.75 | 73.75 | 87.75 | 79.25 | 86.75 |
流水线并行训练
代码说明见:大模型流水线并行(Pipeline)实战
请看v0.1 Tag
Star History

版本历史
v0.12023/08/06常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
OpenHands
OpenHands 是一个专注于 AI 驱动开发的开源平台,旨在让智能体(Agent)像人类开发者一样理解、编写和调试代码。它解决了传统编程中重复性劳动多、环境配置复杂以及人机协作效率低等痛点,通过自动化流程显著提升开发速度。 无论是希望提升编码效率的软件工程师、探索智能体技术的研究人员,还是需要快速原型验证的技术团队,都能从中受益。OpenHands 提供了灵活多样的使用方式:既可以通过命令行(CLI)或本地图形界面在个人电脑上轻松上手,体验类似 Devin 的流畅交互;也能利用其强大的 Python SDK 自定义智能体逻辑,甚至在云端大规模部署上千个智能体并行工作。 其核心技术亮点在于模块化的软件智能体 SDK,这不仅构成了平台的引擎,还支持高度可组合的开发模式。此外,OpenHands 在 SWE-bench 基准测试中取得了 77.6% 的优异成绩,证明了其解决真实世界软件工程问题的能力。平台还具备完善的企业级功能,支持与 Slack、Jira 等工具集成,并提供细粒度的权限管理,适合从个人开发者到大型企业的各类用户场景。