SoraWatermarkCleaner
SoraWatermarkCleaner 是一款基于深度学习技术的高效工具,旨在快速、高质量地移除由 Sora2 模型生成的视频中的水印。它通过自动化流程解决了 AI 视频内容中水印干扰视觉体验及后续创作的痛点,让视频画面更加纯净自然。
该工具特别适合需要处理 Sora 生成视频的设计师、视频创作者以及普通用户。对于希望一键去除水印而不必深入技术细节的用户,项目还提供了便捷的在线托管服务;而对于开发者或研究人员,它支持本地部署、批量处理及 Docker 容器化运行,甚至开放了标注数据集以供自定义训练。
在技术实现上,SoraWatermarkCleaner 采用了双模块架构:首先利用定制的 YOLOv11s 模型精准定位水印位置,随后结合 LaMa 修复算法进行智能填充与擦除。这种纯深度学习驱动的方法不仅保证了处理速度,还有效维持了视频的时间一致性,避免了传统修复中常见的闪烁问题。值得注意的是,随着 OpenAI 暂停 Sora 模型的更新,该项目已进入归档状态,但其核心去水印思路已延伸至新项目 DeMark-World,可支持更多类型的 AI 视频去水印需求。
使用场景
一家数字营销机构的设计师正在为高端客户制作基于 Sora2 生成的概念宣传片,需要在最终交付前去除视频角落的品牌水印以确保画面纯净。
没有 SoraWatermarkCleaner 时
- 手动修图效率极低:设计师不得不逐帧导出视频,在 Photoshop 中利用内容识别填充手动擦除水印,处理一段 10 秒的视频需耗费数小时。
- 画面出现闪烁伪影:传统静态去水印方法无法理解视频的时间连续性,导致去除区域在播放时出现明显的抖动和闪烁,破坏观影体验。
- 边缘残留痕迹明显:简单的高斯模糊或裁剪会损失画幅或留下模糊边界,无法满足高端商业交付对画质的严苛要求。
- 批量处理能力缺失:面对客户突然增加的多版本修改需求,缺乏自动化脚本支持,团队只能加班进行重复性劳动。
使用 SoraWatermarkCleaner 后
- 全流程自动化处理:利用内置的 YOLOv11s 检测模型与 Lama 修复算法,一键即可自动定位并清除水印,将数小时的工作缩短至几分钟。
- 完美保持时间一致性:基于深度学习的视频修复技术确保了帧间连贯性,彻底消除了去除区域的闪烁现象,画面过渡自然流畅。
- 高保真画质还原:智能算法能根据周围像素精准重构背景细节,即使在复杂动态场景下也能实现无痕修复,达到广播级播出标准。
- 轻松应对批量任务:支持批量处理模式,设计师可同时将多个渲染片段投入队列,快速响应客户的紧急改稿需求。
SoraWatermarkCleaner 通过深度学习技术将繁琐的视频去水印工作转化为秒级的自动化流程,在保障影视级画质的同时极大释放了创意生产力。
运行环境要求
- Windows
- Linux
- macOS
- E2FGVI_HQ 模型必需 NVIDIA GPU (支持 CUDA)
- LAMA 模型可在 CPU/MPS 运行但速度极慢
- Docker 部署明确要求 CUDA-capable GPU
- 未明确具体显存大小,但镜像含 PyTorch 且较大,建议具备 CUDA 加速能力
未说明
快速开始
SoraWatermarkCleaner
重要提示
该项目已被归档。 OpenAI 已经停止了 Sora 视频生成模型的开发,因此本项目将不再维护。不过,您可以查看 DeMark-World — 它提供了一种通用的方法,可以去除由 Veo、Runway 等其他模型生成的视频中的水印。
本项目提供了一种优雅的方式来移除 Sora2 生成视频中的 Sora 水印。
| 案例1(25秒) | |
| 案例2(10秒) | |
| 案例3(10秒) |
商业托管服务与赞助
如果您更倾向于一键式在线服务,而不是在本地运行所有操作,您可以使用这里的托管 Sora 水印移除工具:
👉 https://www.sorawatermarkremover.ai/
SoraWatermarkRemover 在后台运行 SoraWatermarkCleaner,并提供 GPU 加速处理、基于积分的定价以及简便的网页界面。该服务为 SoraWatermarkCleaner 的持续开发和维护提供了资金支持。
⭐️:
我很高兴地发布了 DeMark-World — 据我所知,这是首个能够移除任何 AI 生成视频中水印的模型。
我们还提供了一个可以在不产生闪烁的情况下保持时间一致性的模型!
我们现在支持批量处理。
对于带有用户名的新水印,YOLO 权重已经更新,请尝试新版本的水印检测模型,它应该会表现得更好。
我们已将标注好的数据集上传至 Hugging Face,请查看这个 数据集。您可以自由地训练自己的自定义检测模型,或改进我们的模型!
现在提供了一键式便携版 — Windows 用户可从这里下载,无需安装。
现已支持 Docker Compose 部署 — 使用一条命令即可开始部署。注意:该镜像需要 CUDA,并且由于 NVIDIA 库和 PyTorch 的存在,体积较大(约 20 GB)。
💝 如果您觉得这个项目有帮助,请考虑通过给我买杯咖啡来支持开发!
1. 方法
SoraWatermarkCleaner(以下简称 SoraWm)由两部分组成:
SoraWaterMarkDetector:我们训练了一个 YOLOv11s 版本来检测 Sora 水印。(感谢 YOLO!)
WaterMarkCleaner:我们在去除水印时参考了 iopaint 的实现,使用了 LAMA 模型。
我们的 SoraWm 完全由深度学习驱动,在许多生成的视频中都能取得良好的效果。
2. 安装
进行视频处理需要 FFmpeg,请先安装它。我们强烈建议使用 uv 来安装环境:
- 安装:
uv sync
环境将被安装到
.venv目录下,您可以使用以下命令激活环境:source .venv/bin/activate
- 下载预训练模型:
训练好的 YOLO 权重将存储在 resources 目录下的 best.pt 文件中。它将自动从 https://github.com/linkedlist771/SoraWatermarkCleaner/releases/download/V0.0.1/best.pt 下载。LAMA 模型则从 https://github.com/Sanster/models/releases/download/add_big_lama/big-lama.pt 下载,并存储在 PyTorch 的缓存目录中。这两个下载都是自动进行的,如果失败,请检查您的网络连接。
- 批量处理
使用
cli.py进行批量处理
python cli.py [-h] -i INPUT -o OUTPUT [-p PATTERN] [-m MODEL] [--quiet]
示例:
# 处理输入文件夹中的所有 .mp4 文件
python cli.py -i /path/to/input -o /path/to/output
# 处理所有 .mov 文件
python cli.py -i /path/to/input -o /path/to/output --pattern "*.mov"
# 处理所有视频文件(mp4、mov、avi)
python cli.py -i /path/to/input -o /path/to/output --pattern "*.{mp4,mov,avi}"
# 使用 e2fgvi_hq 模型以获得时间一致的结果(速度较慢,需要 CUDA)
python cli.py -i /path/to/input -o /path/to/output --model e2fgvi_hq
# 在 SoraWm 处理过程中不显示 Tqdm 进度条。
python cli.py -i /path/to/input -o /path/to/output --quiet
3. 一键式便携版
对于那些希望使用即开即用解决方案而无需手动安装的用户,我们提供了一个包含所有预配置依赖项的 一键式便携分发版。
下载链接
Google Drive:
百度网盘(适用于中国用户):
功能特点
- ✅ 无需安装
- ✅ 包含所有依赖项
- ✅ 预配置环境
- ✅ 开箱即用
只需下载、解压并运行即可!
4. 性能优化
我们提供了多种选项来加速处理:
| 检测器 | 批量 | 清理器 | TorchCompile | Bf16 | 时间(秒) | 加速比 |
|---|---|---|---|---|---|---|
| YOLO | × | LAMA | × | × | 44.33 | - |
| YOLO | × | E2FGVI | × | × | 142.42 | 1.00× |
| YOLO | × | E2FGVI | ✓ | × | 117.19 | 1.22× |
| YOLO | 4 | E2FGVI | ✓ | × | 82.63 | 1.72× |
| YOLO | 4 | E2FGVI | ✓ | ✓ | 58.60 | 2.43× |
加速比是相对于 E2FGVI 基线计算的。LAMA 使用不同的清理方法,因此无法直接比较。
- YOLO 批量检测:默认批量大小为 4(
detect_batch_size=4),启用批量推理进行水印检测,可提升约 40% 的速度。 - TorchCompile(仅适用于 E2FGVI):默认启用(
enable_torch_compile=True),可提升约 22% 的速度。 - Bf16 推理(仅适用于 E2FGVI):通过设置
use_bf16=True启用(默认为 False),最高可实现 2.43 倍的速度提升。注意:质量可能会略有下降,首次推理会较慢(约 90 秒),因为需要编译开销;后续运行会快得多(约 58 秒),因为已缓存中间结果。
您可以在初始化 SoraWM 时自定义这些设置:
from sorawm.core import SoraWM
from sorawm.schemas import CleanerType
# LAMA 配合批量检测(快速)
sora_wm = SoraWM(
cleaner_type=CleanerType.LAMA,
detect_batch_size=4 # 默认:4
)
# E2FGVI_HQ 配合所有优化(时间一致性)
sora_wm = SoraWM(
cleaner_type=CleanerType.E2FGVI_HQ,
enable_torch_compile=True, # 默认:True
detect_batch_size=8 # 自定义批量大小
)
# E2FGVI_HQ 配合 bf16 以获得最大速度(可能略微影响质量)
sora_wm = SoraWM(
cleaner_type=CleanerType.E2FGVI_HQ,
enable_torch_compile=True,
detect_batch_size=4,
use_bf16=True # 启用 bfloat16 推理
)
5. 示例
要进行基本使用,只需尝试 example.py:
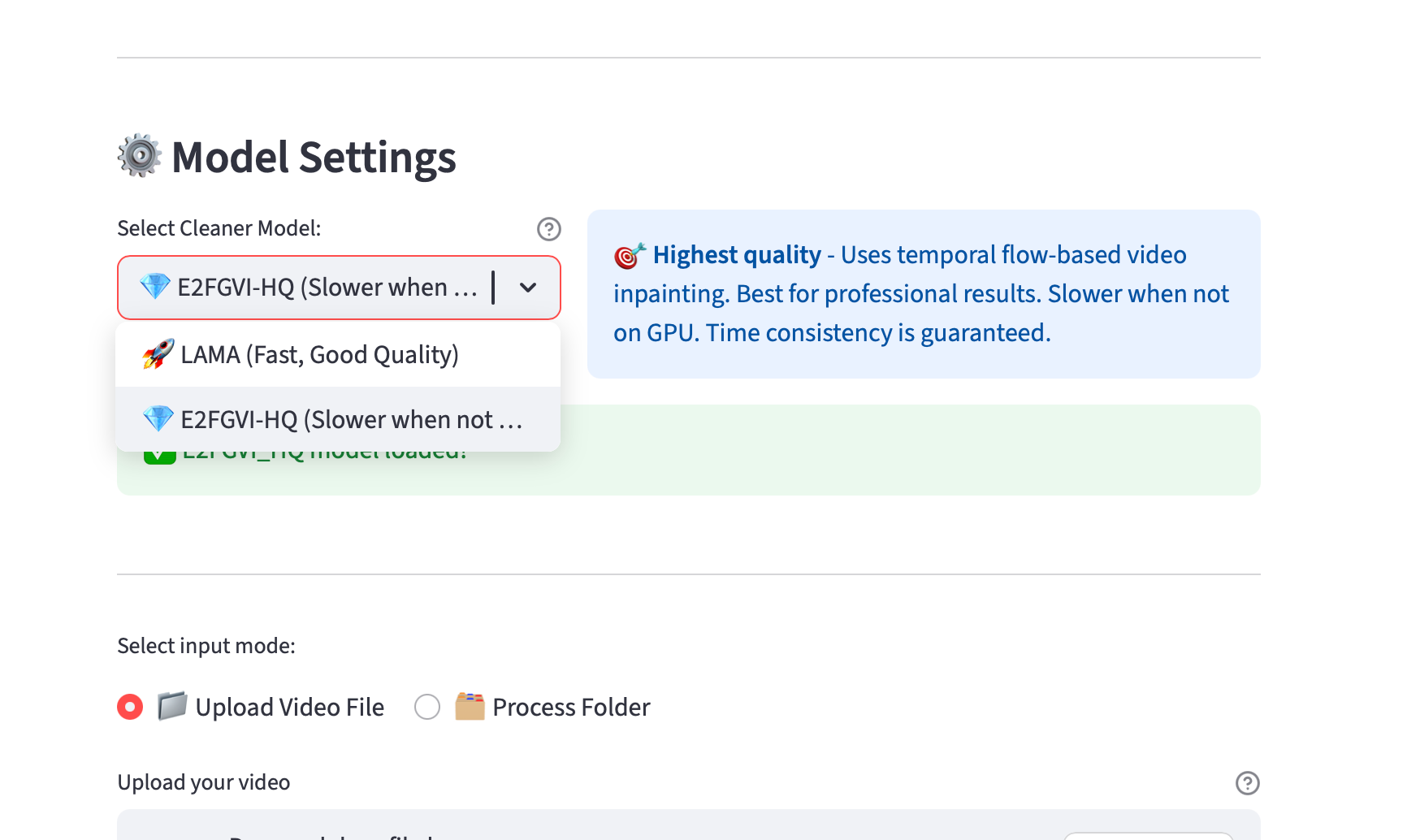
我们提供两种模型来去除水印。LAMA 速度快,但清理区域可能会出现闪烁现象,而 E2FGVI_HQ 则在这一点上有所妥协——它仅在 CUDA 环境下表现良好,在 CPU 或 MPS 上则非常缓慢。
from pathlib import Path
from sorawm.core import SoraWM
from sorawm.schemas import CleanerType
if __name__ == "__main__":
input_video_path = Path("resources/dog_vs_sam.mp4")
output_video_path = Path("outputs/sora_watermark_removed")
# 1. LAMA 速度快且质量较好,但时间一致性较差。
sora_wm = SoraWM(cleaner_type=CleanerType.LAMA)
sora_wm.run(input_video_path, Path(f"{output_video_path}_lama.mp4"))
# 2. E2FGVI_HQ 可确保时间一致性,但在无 CUDA 设备的情况下会非常慢。
sora_wm = SoraWM(cleaner_type=CleanerType.E2FGVI_HQ)
sora_wm.run(input_video_path, Path(f"{output_video_path}_e2fgvi_hq.mp4"))
我们还提供了一个基于 Streamlit 的交互式网页,您可以尝试以下命令:
我们也在此处提供了切换功能。
streamlit run app.py
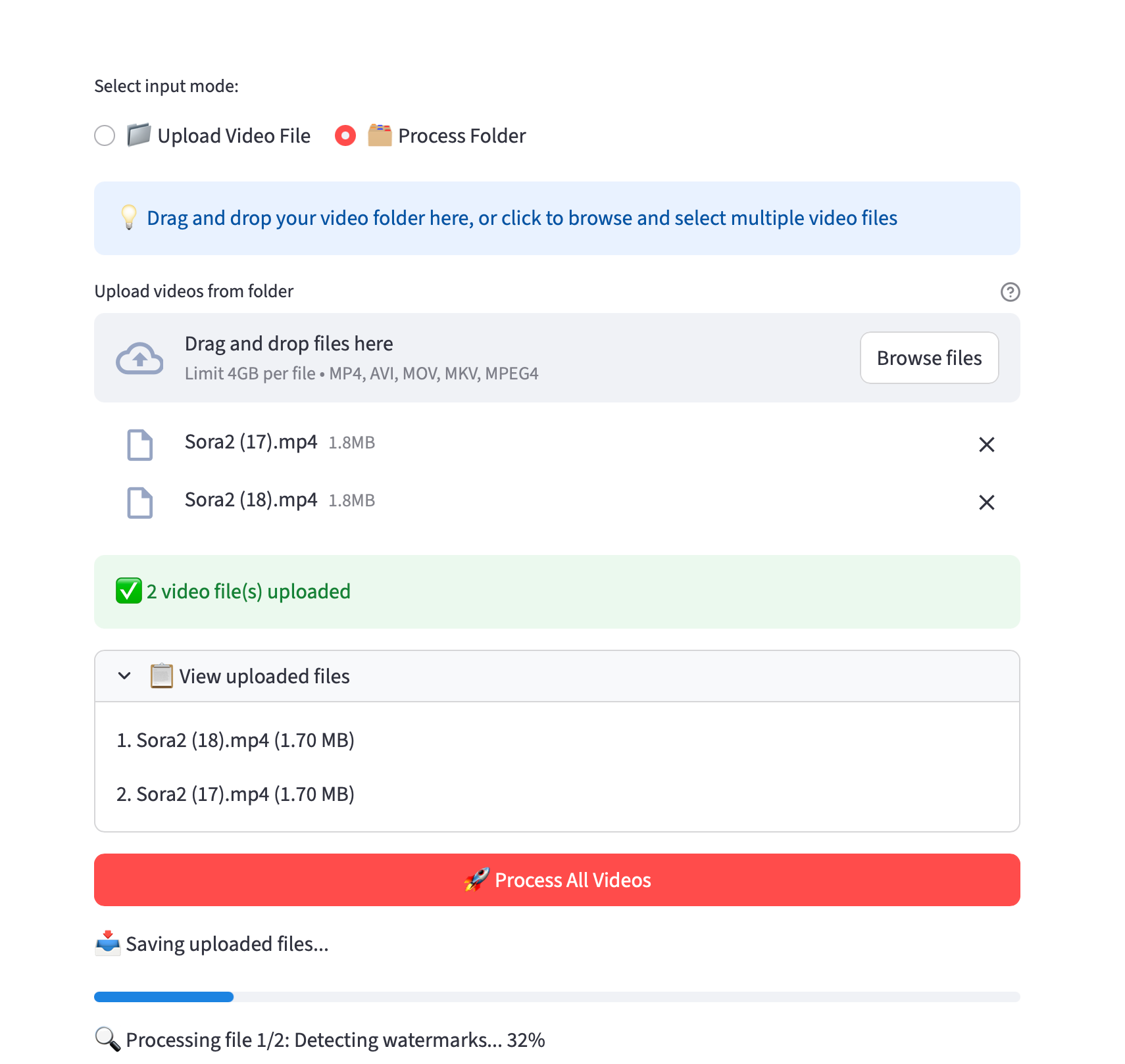
同时支持批量处理,现在您可以拖动文件夹或选择多个文件进行处理。
6. Docker Compose 部署
部署 SoraWatermarkCleaner 最简单的方式是使用 Docker Compose。
注意: Docker 镜像(
llinkedlist/sorawm:latest)需要 CUDA,并包含 NVIDIA 库和 PyTorch,因此体积较大(约 20 GB)。首次拉取镜像可能需要较长时间,具体取决于您的网络速度。
先决条件:
- 已安装 Docker 和 NVIDIA Container Toolkit
- 具备 CUDA 功能的 GPU
启动服务:
docker compose up -d
这将:
- 从 Docker Hub 拉取镜像(仅首次,请耐心等待,约 20 GB)
- 将当前目录挂载到容器内的
/workspace - 将模型权重缓存到
./.cache目录中,以便在重启时无需重新下载 - 在端口 8501 上暴露 Streamlit UI
您可以通过 http://localhost:8501 访问 Streamlit UI。
7. Web 服务器
在这里,我们提供一个基于 FastAPI 的 Web 服务器,可以快速将此水印移除工具转化为一项服务。
我们还为该服务器提供了一个前端界面,您可以按如下步骤尝试:
cd frontend && bun install && bun run build
然后启动服务器,前端界面将直接在根路径上可用:
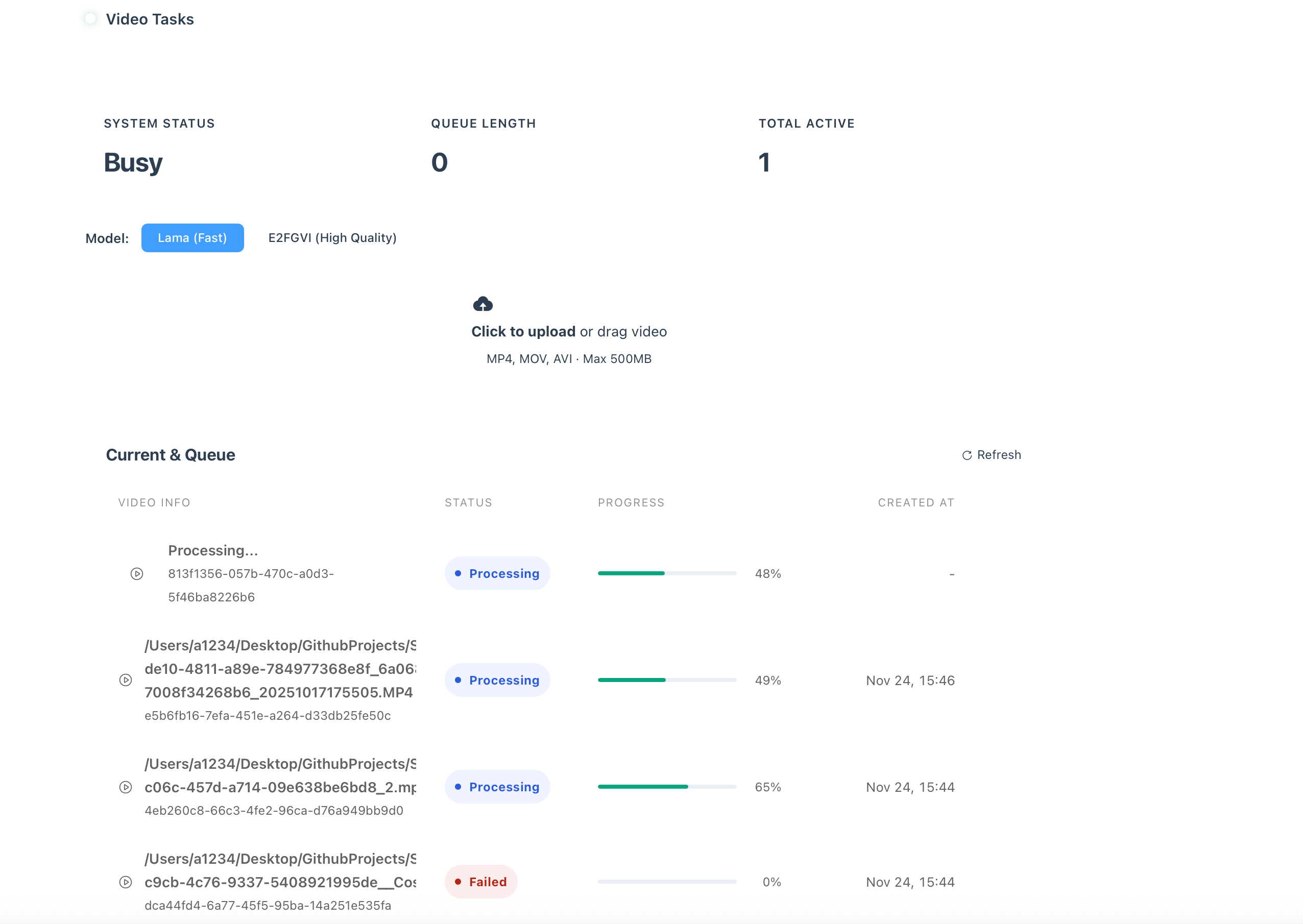
任务状态会被记录下来,即使服务器宕机也可以从中断的地方继续。
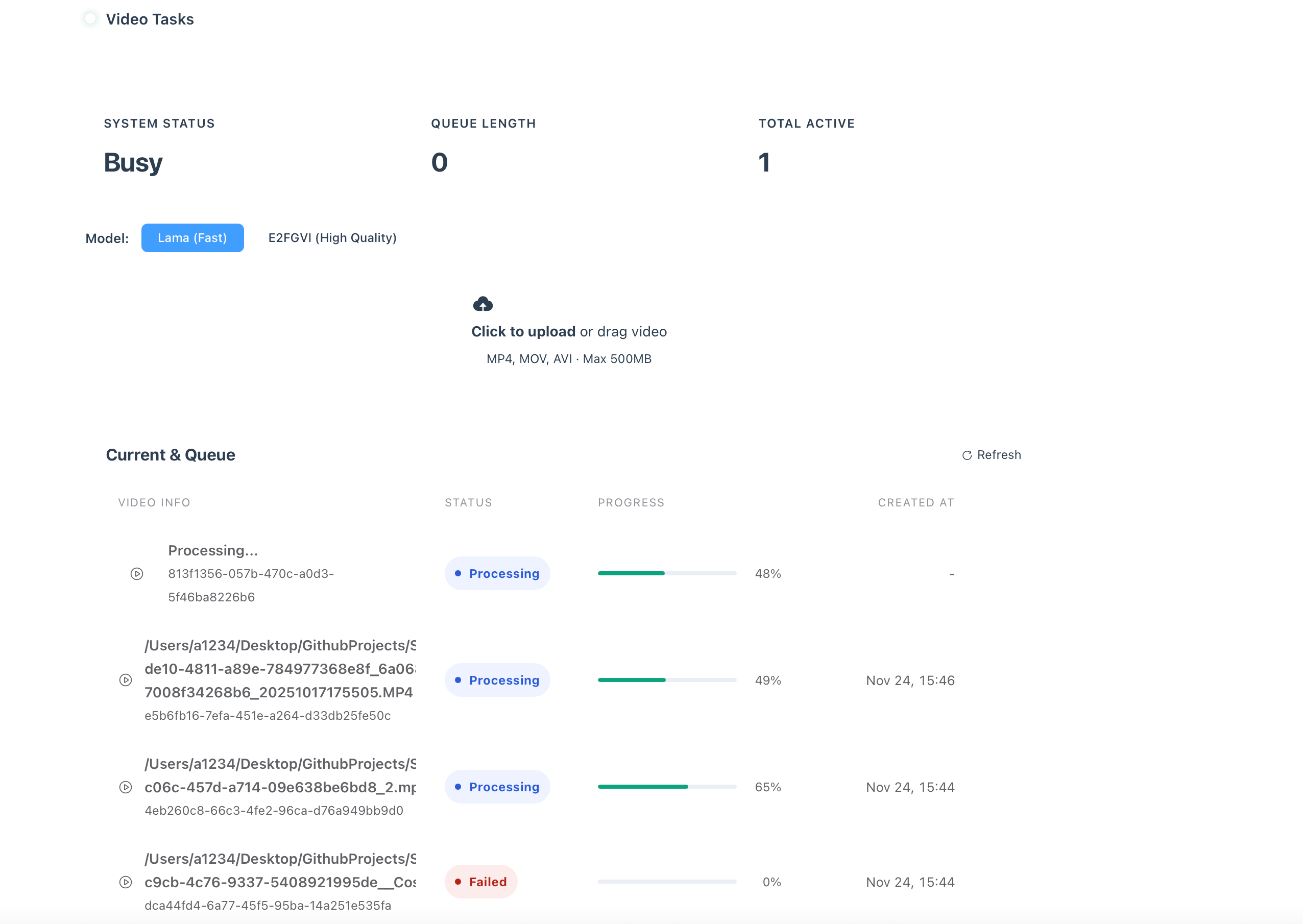
只需运行:
python start_server.py
Web 服务器将在端口 5344 上启动。
您可以查看 FastAPI 文档 以获取更多详细信息。
共有三条可用路由:
submit_remove_task
上传视频后,将返回一个任务 ID,视频将立即开始处理。
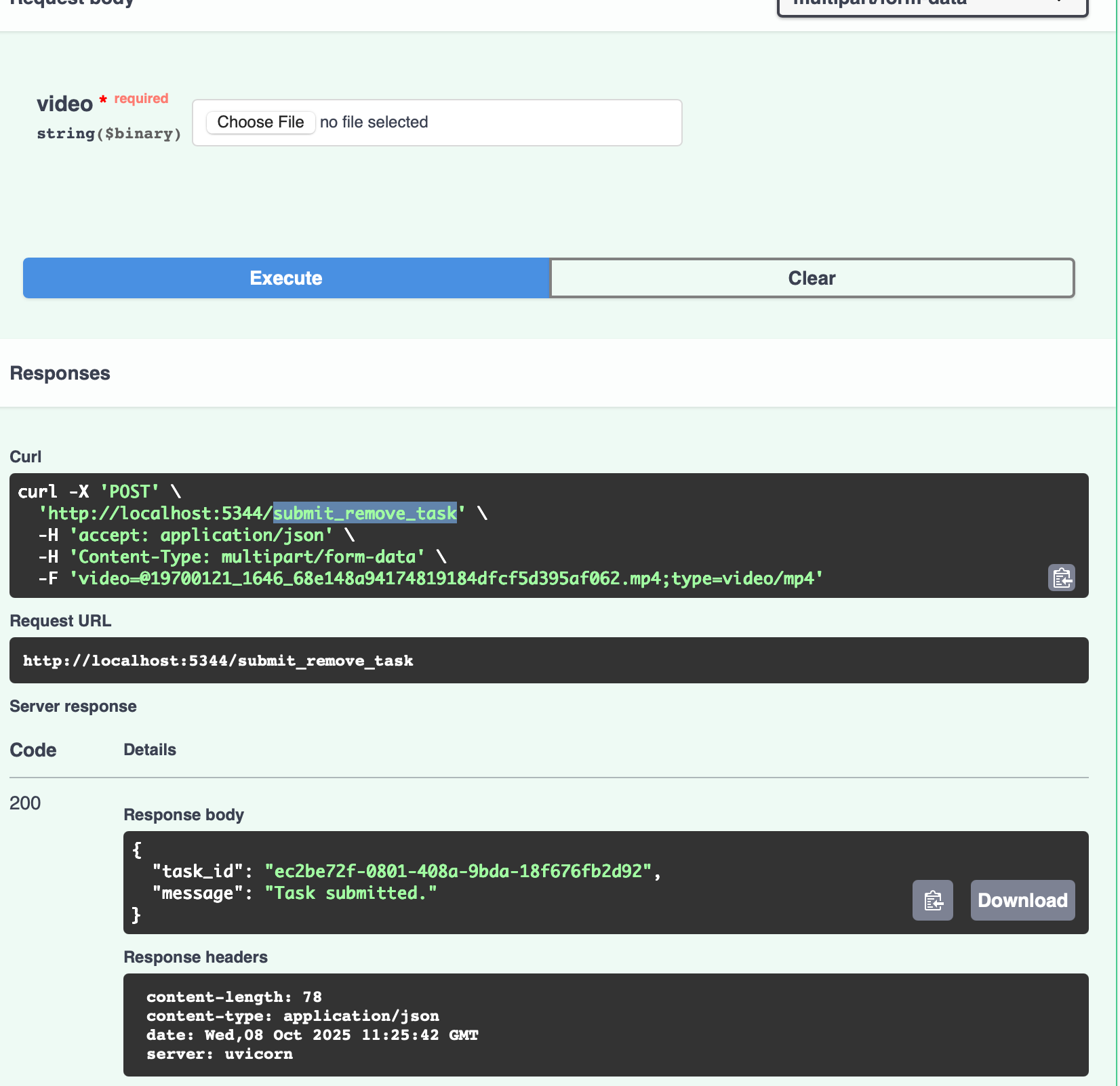
- get_results
您可以使用上述获得的任务 ID 来检查任务状态。
它会显示视频处理完成的百分比。
一旦完成,返回的数据将包含一个 下载链接。
- download
您可以使用第 2 步中的 下载链接 来获取清理后的视频。
8. 数据集
我们已将标注好的数据集上传至 Hugging Face,请访问:https://huggingface.co/datasets/LLinked/sora-watermark-dataset。欢迎训练您自己的自定义检测模型,或改进我们的模型!
9. API
打包成 Cog 并 发布到 Replicate,以便于通过简单的 API 进行使用。
10. 许可证
Apache 许可证
11. 引用
如果您使用本项目,请引用以下内容:
@misc{sorawatermarkcleaner2025,
author = {linkedlist771},
title = {SoraWatermarkCleaner},
year = {2025},
url = {https://github.com/linkedlist771/SoraWatermarkCleaner}
}
12. 致谢
- IOPaint 提供了 LAMA 的实现
- Ultralytics YOLO 提供了目标检测功能
版本历史
V0.0.52026/03/10V0.0.42026/01/08V0.0.32025/11/18v0.0.22025/10/17V0.0.12025/10/05常见问题
相似工具推荐
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
MoneyPrinterTurbo
MoneyPrinterTurbo 是一款利用 AI 大模型技术,帮助用户一键生成高清短视频的开源工具。只需输入一个视频主题或关键词,它就能全自动完成从文案创作、素材匹配、字幕合成到背景音乐搭配的全过程,最终输出完整的竖屏或横屏短视频。 这款工具主要解决了传统视频制作流程繁琐、门槛高以及素材版权复杂等痛点。无论是需要快速产出内容的自媒体创作者,还是希望尝试视频生成的普通用户,无需具备专业的剪辑技能或昂贵的硬件配置(普通电脑即可运行),都能轻松上手。同时,其清晰的 MVC 架构和对多种主流大模型(如 DeepSeek、Moonshot、通义千问等)的广泛支持,也使其成为开发者进行二次开发或技术研究的理想底座。 MoneyPrinterTurbo 的独特亮点在于其高度的灵活性与本地化友好性。它不仅支持中英文双语及多种语音合成,允许用户精细调整字幕样式和画面比例,还特别优化了国内网络环境下的模型接入方案,让用户无需依赖 VPN 即可使用高性能国产大模型。此外,工具提供批量生成模式,可一次性产出多个版本供用户择优,极大地提升了内容创作的效率与质量。
oh-my-openagent
oh-my-openagent(简称 omo)是一款强大的开源智能体编排框架,前身名为 oh-my-opencode。它致力于打破单一模型供应商的生态壁垒,解决开发者在构建 AI 应用时面临的“厂商锁定”难题。不同于仅依赖特定模型的封闭方案,omo 倡导开放市场理念,支持灵活调度多种主流大模型:利用 Claude、Kimi 或 GLM 进行任务编排,调用 GPT 处理复杂推理,借助 Minimax 提升响应速度,或发挥 Gemini 的创意优势。 这款工具特别适合希望摆脱平台限制、追求极致性能与成本平衡的开发者及研究人员使用。通过统一接口,用户可以轻松组合不同模型的长处,构建更高效、更具适应性的智能体系统。其独特的技术亮点在于“全模型兼容”架构,让用户不再受制于某一家公司的策略变动或定价调整,真正实现对前沿模型资源的自由驾驭。无论是构建自动化编码助手,还是开发多步骤任务处理流程,oh-my-openagent 都能提供灵活且稳健的基础设施支持,助力用户在快速演进的 AI 生态中保持技术主动权。
tabby
Tabby 是一款可私有化部署的开源 AI 编程助手,旨在为开发团队提供 GitHub Copilot 的安全替代方案。它核心解决了代码辅助过程中的数据隐私顾虑与云端依赖问题,让企业能够在完全掌控数据的前提下享受智能代码补全、聊天问答及上下文理解带来的效率提升。 这款工具特别适合注重代码安全的企业开发团队、希望本地化运行大模型的科研机构,以及拥有消费级显卡的个人开发者。Tabby 的最大亮点在于其“开箱即用”的自包含架构,无需配置复杂的数据库或依赖云服务即可快速启动。同时,它对硬件十分友好,支持在普通的消费级 GPU 上流畅运行,大幅降低了部署门槛。此外,Tabby 提供了标准的 OpenAPI 接口,能轻松集成到现有的云 IDE 或内部开发流程中,并支持通过 REST API 接入自定义文档以增强知识上下文。从代码自动补全到基于 Git 仓库的智能问答,Tabby 致力于成为开发者身边懂业务、守安全的智能伙伴。
generative-models
Generative Models 是 Stability AI 推出的开源项目,核心亮点在于最新发布的 Stable Video 4D 2.0(SV4D 2.0)。这是一个先进的视频转 4D 扩散模型,旨在解决从单一视角视频中生成高保真、多视角动态 3D 资产的技术难题。传统方法往往难以处理物体自遮挡或背景杂乱的情况,且生成的动态细节容易模糊,而 SV4D 2.0 通过改进的架构,显著提升了运动中的画面锐度与时空一致性,无需依赖额外的多视角参考图即可稳健地合成新颖视角的视频。 该项目特别适合计算机视觉研究人员、AI 开发者以及从事 3D 内容创作的设计师使用。对于研究者,它提供了探索 4D 生成前沿的完整代码与训练权重;对于开发者,其支持自动回归生成长视频及低显存优化选项,便于集成与调试;对于设计师,它能将简单的物体运动视频快速转化为可用于游戏或影视的多视角 4D 素材。技术层面,SV4D 2.0 支持一次性生成 12 帧视频对应 4 个相机视角(或 5 帧对应 8 视角),分辨率达 576x576,并能更好地泛化至真实世界场景。用户只需准备一段白底或经简单抠图处理的物体运动视频,