chatglm.cpp
chatglm.cpp 是一个基于 C++ 开发的高效推理框架,专为在个人电脑(如 MacBook、Windows 或 Linux 主机)上本地运行清华智谱 AI 系列的 ChatGLM 及 GLM-4 大模型而设计。它解决了大型语言模型通常依赖昂贵 GPU 服务器、难以在普通硬件上流畅运行的痛点,让用户无需联网即可在本地实现隐私安全、低延迟的实时对话体验。
这款工具非常适合希望在本地部署大模型的开发者、研究人员,以及关注数据隐私的普通用户。其核心亮点在于纯 C++ 实现并依托 ggml 库,能够像 llama.cpp 一样高效工作。通过支持 int4/int8 量化技术,它大幅降低了内存占用并加速了 CPU 推理过程,同时优化了键值缓存与并行计算能力。此外,chatglm.cpp 还兼容 P-Tuning v2 和 LoRA 微调模型,支持打字机效果的流式输出,并提供 Python 绑定、Web 演示及 API 服务等多种扩展方式。无论是 x86/ARM 架构的 CPU,还是 NVIDIA 与 Apple Silicon 的 GPU,都能获得良好的性能支持,让大模型应用真正变得轻量且触手可及。
使用场景
一位拥有 MacBook Pro 的独立开发者,希望在本地离线环境中快速部署一个支持中文对话的智能客服原型,用于测试私有数据下的回答效果。
没有 chatglm.cpp 时
- 硬件门槛高:运行原版 ChatGLM-6B 通常需要配备大显存 NVIDIA 显卡,普通笔记本无法承载,必须租用昂贵的云端 GPU 服务器。
- 环境配置繁琐:需要安装庞大的 PyTorch 框架及各类依赖库,版本冲突频繁,在 macOS 上配置 CUDA 替代方案更是耗时耗力。
- 推理速度慢:在未量化的浮点精度下,首字生成延迟高,多轮对话时显存占用迅速飙升,导致交互体验卡顿甚至崩溃。
- 隐私与成本顾虑:数据需上传至云端或依赖外部 API,存在隐私泄露风险,且按 Token 计费的模式让高频测试成本难以控制。
使用 chatglm.cpp 后
- 原生苹果芯片加速:直接利用 MacBook 的 Apple Silicon GPU 进行推理,无需额外显卡,纯 C++ 实现让内存占用降低 70% 以上。
- 极简部署流程:通过一行命令即可将 Hugging Face 模型转换为 int4 量化格式,配合 Python 绑定快速启动,几分钟内完成环境搭建。
- 流畅实时交互:得益于优化的 KV 缓存和并行计算,即使在 CPU 模式下也能实现“打字机”效果的流式输出,响应速度满足实时对话需求。
- 完全离线安全:所有计算均在本地完成,敏感业务数据不出设备,且一次性转换后可无限次免费调用,彻底消除云端费用。
chatglm.cpp 让高性能中文大模型真正跑在了开发者的笔记本电脑上,实现了低成本、高隐私且极速的本地化 AI 应用落地。
运行环境要求
- Linux
- macOS
- Windows
- 非必需
- 支持 NVIDIA GPU (需开启 CUDA)、Apple Silicon GPU (需开启 Metal) 或仅使用 CPU 推理
- 未明确指定具体显存大小要求,但建议视觉模型 (GLM-4V) 在 GPU 上运行以避免 CPU 过慢
未说明 (取决于模型大小及量化等级,int4/int8 量化旨在降低内存需求)
快速开始
ChatGLM.cpp
![]()
![]()


基于 ChatGLM-6B、ChatGLM2-6B、ChatGLM3 和 GLM-4(V) 的 C++ 实现,可在您的 MacBook 上进行实时对话。
特性
亮点:
- 基于 ggml 的纯 C++ 实现,工作方式与 llama.cpp 相同。
- 通过 int4/int8 量化、优化的 KV 缓存和并行计算,实现加速且内存高效的 CPU 推理。
- 支持 P-Tuning v2 和 LoRA 微调模型。
- 具有打字机效果的流式生成。
- 提供 Python 绑定、Web 演示、API 服务器等多种可能性。
支持矩阵:
- 硬件:x86/arm CPU、NVIDIA GPU、Apple Silicon GPU
- 平台:Linux、MacOS、Windows
- 模型:ChatGLM-6B、ChatGLM2-6B、ChatGLM3、GLM-4(V)、CodeGeeX2
快速入门
准备工作
将 ChatGLM.cpp 仓库克隆到本地:
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp
如果您在克隆仓库时忘记使用 --recursive 标志,请在 chatglm.cpp 文件夹中运行以下命令:
git submodule update --init --recursive
模型量化
安装加载和量化 Hugging Face 模型所需的必要包:
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece
使用 convert.py 将 ChatGLM-6B 转换为量化后的 GGML 格式。例如,要将 fp16 原始模型转换为 q4_0(量化为 int4)GGML 模型,运行:
python3 chatglm_cpp/convert.py -i THUDM/chatglm-6b -t q4_0 -o models/chatglm-ggml.bin
原始模型 (-i <model_name_or_path>) 可以是 Hugging Face 模型名称,也可以是你预先下载的模型的本地路径。目前支持的模型包括:
- ChatGLM-6B:
THUDM/chatglm-6b、THUDM/chatglm-6b-int8、THUDM/chatglm-6b-int4 - ChatGLM2-6B:
THUDM/chatglm2-6b、THUDM/chatglm2-6b-int4、THUDM/chatglm2-6b-32k、THUDM/chatglm2-6b-32k-int4 - ChatGLM3-6B:
THUDM/chatglm3-6b、THUDM/chatglm3-6b-32k、THUDM/chatglm3-6b-128k、THUDM/chatglm3-6b-base - ChatGLM4(V)-9B:
THUDM/glm-4-9b-chat、THUDM/glm-4-9b-chat-1m、THUDM/glm-4-9b、THUDM/glm-4v-9b - CodeGeeX2:
THUDM/codegeex2-6b、THUDM/codegeex2-6b-int4
您可以自由尝试以下任何一种量化类型,只需指定 -t <type>:
| 类型 | 精度 | 对称 |
|---|---|---|
q4_0 |
int4 | true |
q4_1 |
int4 | false |
q5_0 |
int5 | true |
q5_1 |
int5 | false |
q8_0 |
int8 | true |
f16 |
半精度 | |
f32 |
浮点数 |
对于 LoRA 模型,添加 -l <lora_model_name_or_path> 标志,即可将 LoRA 权重合并到基础模型中。例如,运行 python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml-lora.bin -l shibing624/chatglm3-6b-csc-chinese-lora,即可合并来自 Hugging Face 的公开 LoRA 权重。
对于使用 官方微调脚本 的 P-Tuning v2 模型,convert.py 会自动检测额外的权重。如果输出权重列表中包含 past_key_values,则表示 P-Tuning 检查点已成功转换。
构建与运行
使用 CMake 编译项目:
cmake -B build
cmake --build build -j --config Release
现在您可以通过运行以下命令与量化后的 ChatGLM-6B 模型对话:
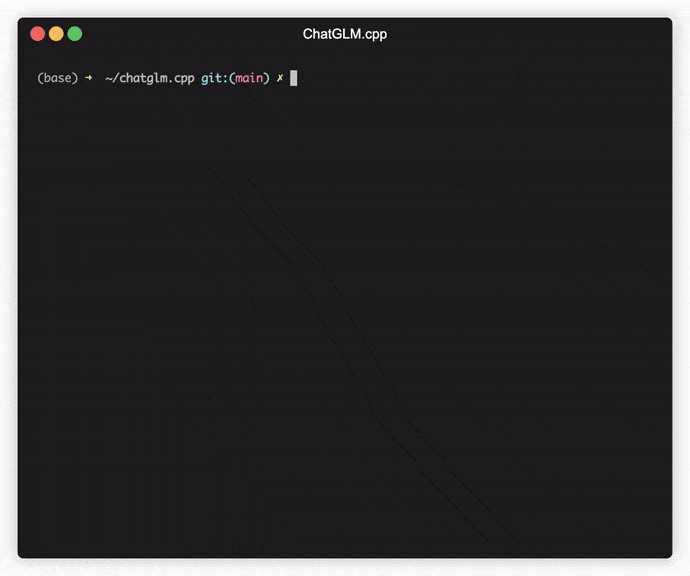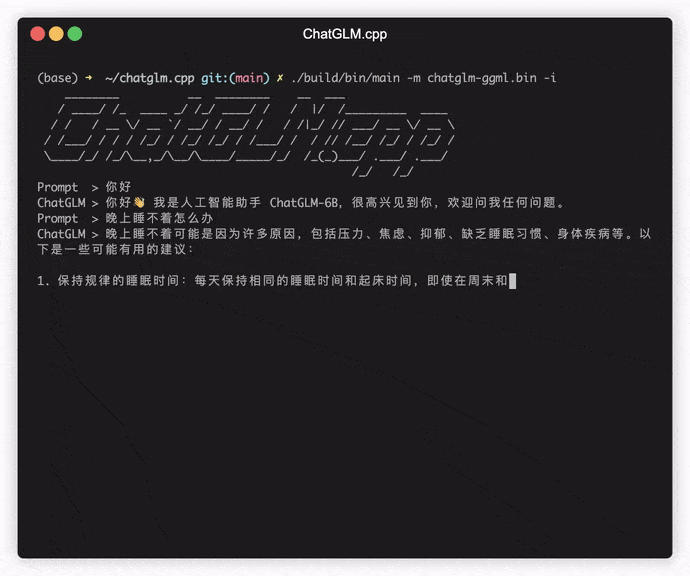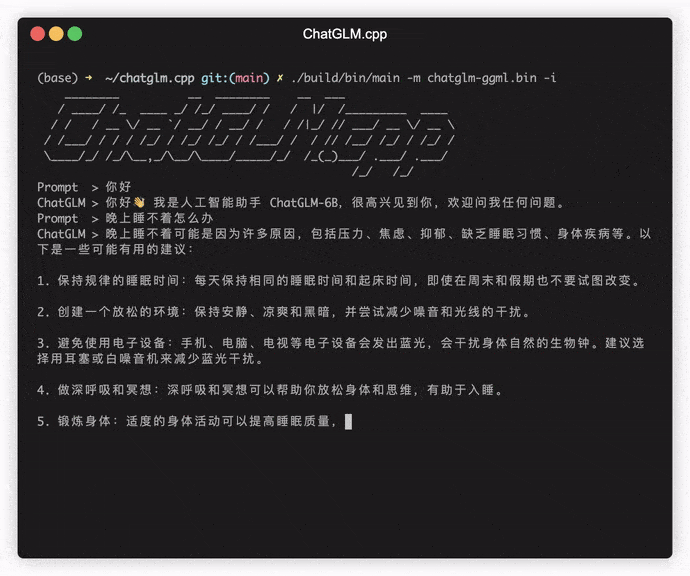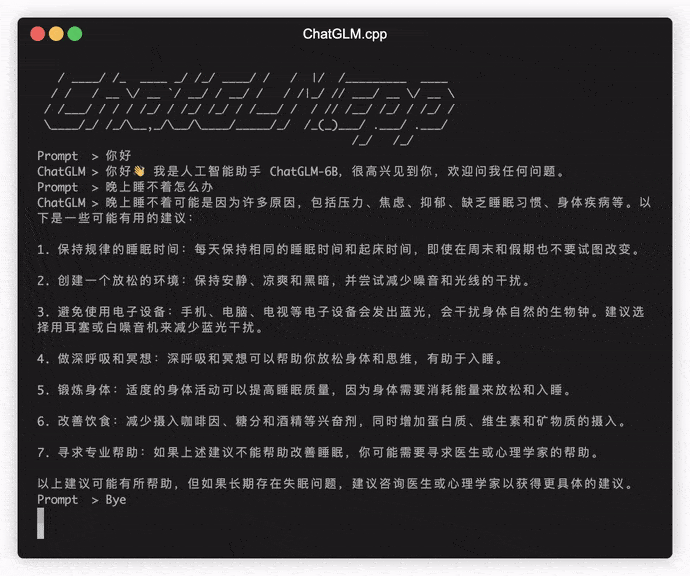
./build/bin/main -m models/chatglm-ggml.bin -p 你好
# 你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
若要在交互模式下运行模型,请添加 -i 标志。例如:
./build/bin/main -m models/chatglm-ggml.bin -i
在交互模式下,您的聊天记录将作为下一轮对话的上下文。
运行 ./build/bin/main -h 以了解更多选项!
尝试其他模型
ChatGLM2-6B
python3 chatglm_cpp/convert.py -i THUDM/chatglm2-6b -t q4_0 -o models/chatglm2-ggml.bin
./build/bin/main -m models/chatglm2-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。
ChatGLM3-6B
ChatGLM3-6B 在对话模式的基础上进一步支持函数调用和代码解释器功能。
对话模式:
python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml.bin
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好👋!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。
设置系统提示词:
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 -s "你是一个由智谱 AI 训练的大语言模型 ChatGLM3。请仔细遵循用户的指示,并以 Markdown 格式作答。"
# 你好👋!我是 ChatGLM3,有什么问题可以帮您解答吗?
函数调用:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/function_call.txt -i
系统 > 请尽你所能回答以下问题。你可以使用以下工具:...
提示 > 生成一个随机数
ChatGLM3 > random_number_generator
```python
tool_call(seed=42, range=(0, 100))
```
工具调用 > 请手动调用函数 `random_number_generator`,参数为 `tool_call(seed=42, range=(0, 100))`,并将结果提供在下方。
观测值 > 23
ChatGLM3 > 根据您的要求,我使用随机数生成器API生成了一个随机数。根据API返回结果,生成的随机数为23。
代码解释器:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/code_interpreter.txt -i
系统 > 你是一位智能AI助手,你叫ChatGLM,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。
提示 > 列出100以内的所有质数
ChatGLM3 > 好的,我会为您列出100以内的所有质数。
```python
def is_prime(n):
"""检查一个数是否为质数。"""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes_upto_100 = [i for i in range(2, 101) if is_prime(i)]
primes_upto_100
```
代码解释器 > 请手动运行代码,并将结果提供在下方。
观测值 > [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
ChatGLM3 > 100以内的所有质数为:
$$
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97
$$
ChatGLM4-9B
聊天模式:
python3 chatglm_cpp/convert.py -i THUDM/glm-4-9b-chat -t q4_0 -o models/chatglm4-ggml.bin
./build/bin/main -m models/chatglm4-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好👋!有什么可以帮助你的吗?
ChatGLM4V-9B

你可以使用 -vt <vision_type> 来设置视觉编码器的量化类型。建议在GPU上运行GLM4V,因为即使采用4位量化,视觉编码在CPU上也会非常缓慢。
python3 chatglm_cpp/convert.py -i THUDM/glm-4v-9b -t q4_0 -vt q4_0 -o models/chatglm4v-ggml.bin
./build/bin/main -m models/chatglm4v-ggml.bin --image https://oss.gittoolsai.com/images/li-plus_chatglm.cpp_readme_f52c51021b38.jpg -p "这张图片有什么不寻常的地方" --temp 0
# 这张图片中不寻常的地方在于,男子正在一辆黄色出租车后面熨衣服。通常情况下,熨衣是在家中或洗衣店进行的,而不是在车辆上。此外,出租车在行驶中,男子却能够稳定地熨衣,这增加了场景的荒诞感。
CodeGeeX2
$ python3 chatglm_cpp/convert.py -i THUDM/codegeex2-6b -t q4_0 -o models/codegeex2-ggml.bin
$ ./build/bin/main -m models/codegeex2-ggml.bin --temp 0 --mode generate -p "\
# language: Python
# write a bubble sort function
"
def bubble_sort(lst):
for i in range(len(lst) - 1):
for j in range(len(lst) - 1 - i):
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
return lst
print(bubble_sort([5, 4, 3, 2, 1]))
使用BLAS
BLAS库可以集成进来进一步加速矩阵乘法。然而,在某些情况下,使用BLAS可能会导致性能下降。是否启用BLAS应取决于基准测试的结果。
Accelerate框架
Accelerate框架在macOS上会自动启用。若要禁用它,需添加CMake标志 -DGGML_NO_ACCELERATE=ON。
OpenBLAS
OpenBLAS可以在CPU上提供加速。添加CMake标志 -DGGML_OPENBLAS=ON 即可启用。
cmake -B build -DGGML_OPENBLAS=ON && cmake --build build -j
CUDA
CUDA可以在NVIDIA GPU上加速模型推理。添加CMake标志 -DGGML_CUDA=ON 即可启用。
cmake -B build -DGGML_CUDA=ON && cmake --build build -j
默认情况下,所有内核都会针对所有可能的CUDA架构进行编译,这需要一些时间。若要在特定类型的设备上运行,可以指定 CMAKE_CUDA_ARCHITECTURES 来加快nvcc编译速度。例如:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="80" # 用于A100
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="70;75" # 兼容V100和T4
要了解你的GPU设备的CUDA架构,可以查看NVIDIA GPU计算能力。
Metal
MPS(Metal性能着色器)允许计算在强大的Apple Silicon GPU上运行。添加CMake标志 -DGGML_METAL=ON 即可启用。
cmake -B build -DGGML_METAL=ON && cmake --build build -j
Python绑定
Python绑定提供了与原始Hugging Face ChatGLM(2)-6B类似的高级chat和stream_chat接口。
安装
推荐从PyPI安装:这将在你的平台上触发编译。
pip install -U chatglm-cpp
若要在NVIDIA GPU上启用CUDA:
CMAKE_ARGS="-DGGML_CUDA=ON" pip install -U chatglm-cpp
若要在Apple硅芯片设备上启用Metal:
CMAKE_ARGS="-DGGML_METAL=ON" pip install -U chatglm-cpp
你也可以从源码安装。为获得加速效果,需添加相应的CMAKE_ARGS。
# 从GitHub上托管的最新源码安装
pip install git+https://github.com/li-plus/chatglm.cpp.git@main
# 或者在 Git 克隆仓库后,从本地源安装
pip install .
适用于 Linux / MacOS / Windows 的 CPU 后端预编译轮子已在 release 中发布。对于 CUDA / Metal 后端,请从源代码或源码分发包进行编译。
使用预先转换的 GGML 模型
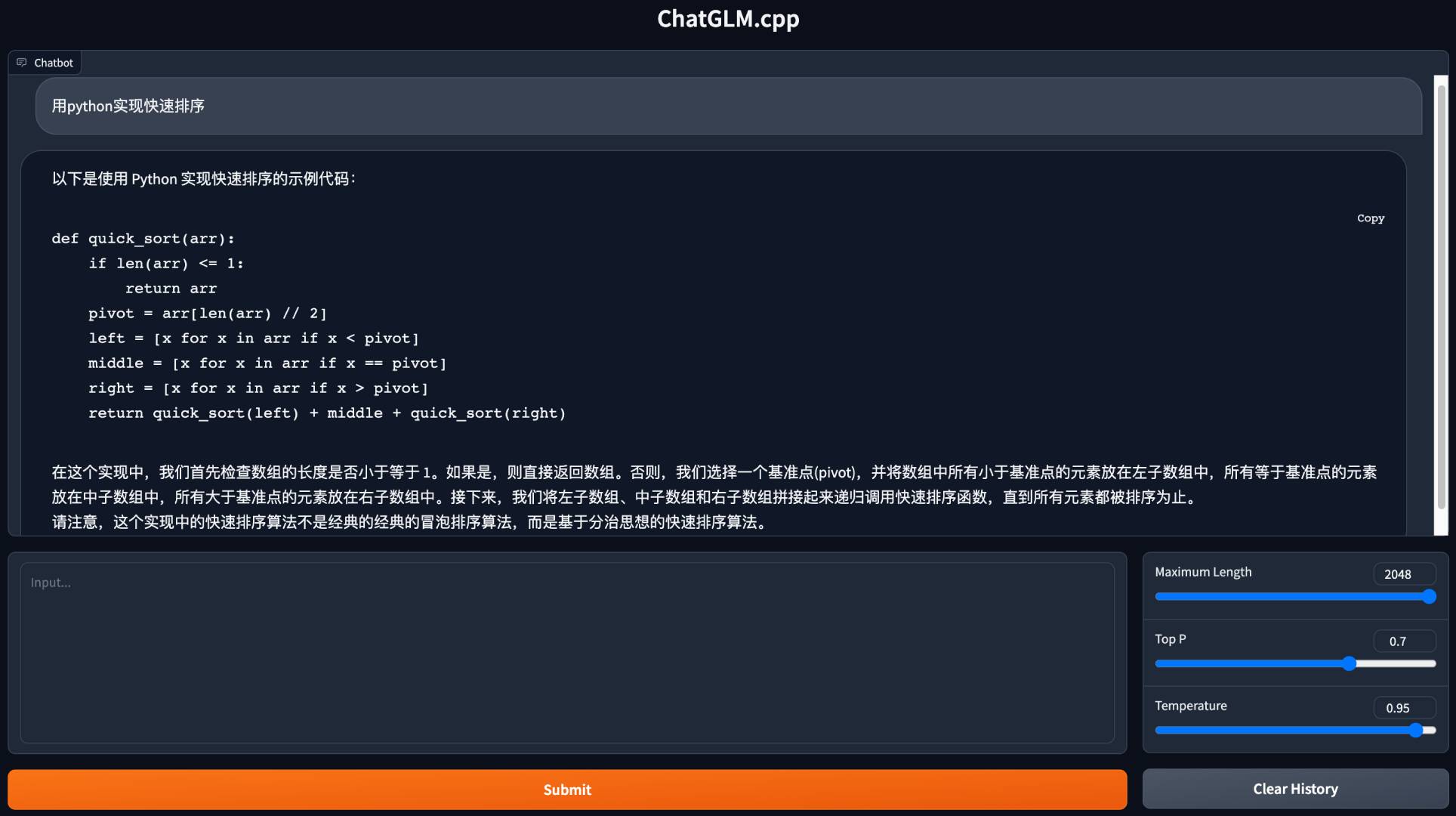
以下是一个简单的示例,使用 chatglm_cpp.Pipeline 加载 GGML 模型并与之对话。首先进入 examples 文件夹(cd examples),然后启动 Python 交互式 shell:
>>> import chatglm_cpp
>>>
>>> pipeline = chatglm_cpp.Pipeline("../models/chatglm-ggml.bin")
>>> pipeline.chat([chatglm_cpp.ChatMessage(role="user", content="你好")])
ChatMessage(role="assistant", content="你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。", tool_calls=[])
若需以流式方式对话,请运行以下 Python 示例:
python3 cli_demo.py -m ../models/chatglm-ggml.bin -i
在浏览器中启动 Web 演示以进行对话:
python3 web_demo.py -m ../models/chatglm-ggml.bin
其他模型:
ChatGLM2-6B
python3 cli_demo.py -m ../models/chatglm2-ggml.bin -p 你好 --temp 0.8 --top_p 0.8 # CLI 演示
python3 web_demo.py -m ../models/chatglm2-ggml.bin --temp 0.8 --top_p 0.8 # Web 演示
ChatGLM3-6B
CLI 演示
聊天模式:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin -p 你好 --temp 0.8 --top_p 0.8
函数调用:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/function_call.txt -i
代码解释器:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/code_interpreter.txt -i
Web 演示
安装 Python 依赖项及用于代码解释器的 IPython 内核。
pip install streamlit jupyter_client ipython ipykernel
ipython kernel install --name chatglm3-demo --user
启动 Web 演示:
streamlit run chatglm3_demo.py
| 函数调用 | 代码解释器 |
|---|---|
 |
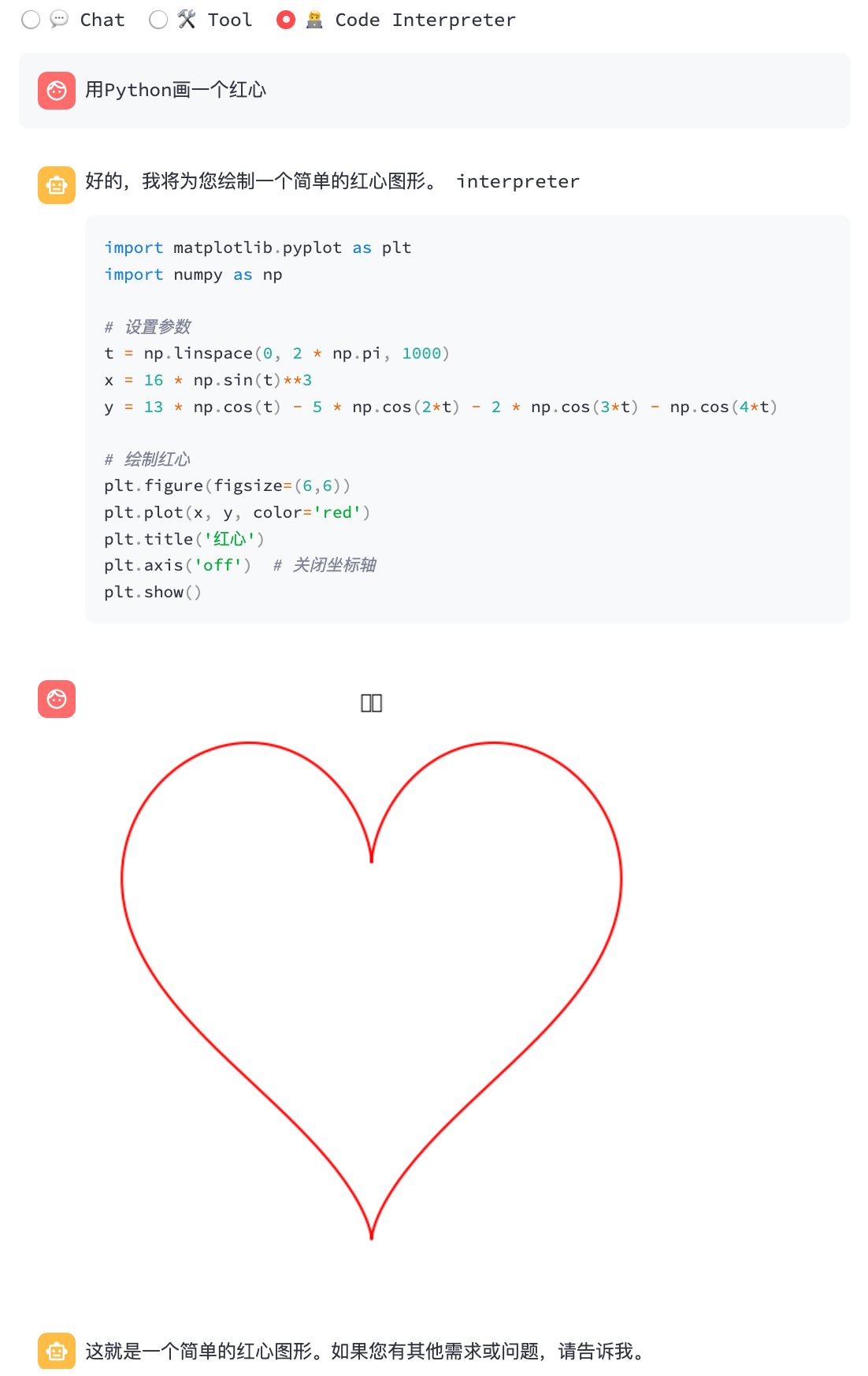 |
ChatGLM4-9B
聊天模式:
python3 cli_demo.py -m ../models/chatglm4-ggml.bin -p 你好 --temp 0.8 --top_p 0.8
ChatGLM4V-9B
聊天模式:
python3 cli_demo.py -m ../models/chatglm4v-ggml.bin --image 03-Confusing-Pictures.jpg -p "这张图片有什么不寻常之处" --temp 0
CodeGeeX2
# CLI 演示
python3 cli_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --mode generate -p "\
# language: Python
# write a bubble sort function
"
# Web 演示
python3 web_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --max_length 512 --mode generate --plain
在运行时转换 Hugging Face LLMs
有时提前转换并保存中间 GGML 模型可能不太方便。这里提供一种直接从原始 Hugging Face 模型加载、在一分钟内将其量化为 GGML 模型并开始服务的方法。您只需将 GGML 模型路径替换为 Hugging Face 模型名称或路径即可。
>>> import chatglm_cpp
>>>
>>> pipeline = chatglm_cpp.Pipeline("THUDM/chatglm-6b", dtype="q4_0")
Loading checkpoint shards: 100%|██████████████████████████████████| 8/8 [00:10<00:00, 1.27s/it]
Processing model states: 100%|████████████████████████████████| 339/339 [00:23<00:00, 14.73it/s]
...
>>> pipeline.chat([chatglm_cpp.ChatMessage(role="user", content="你好")])
ChatMessage(role="assistant", content="你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。", tool_calls=[])
同样地,在任何示例脚本中将 GGML 模型路径替换为 Hugging Face 模型,即可正常工作。例如:
python3 cli_demo.py -m THUDM/chatglm-6b -p 你好 -i
API 服务器
我们支持多种类型的 API 服务器,以便与流行的前端集成。可通过以下命令安装额外依赖:
pip install 'chatglm-cpp[api]'
请记得添加相应的 CMAKE_ARGS 以启用加速。
LangChain API
启动 LangChain 的 API 服务器:
MODEL=./models/chatglm2-ggml.bin uvicorn chatglm_cpp.langchain_api:app --host 127.0.0.1 --port 8000
使用 curl 测试 API 端点:
curl http://127.0.0.1:8000 -H 'Content-Type: application/json' -d '{"prompt": "你好"}'
结合 LangChain 使用:
>>> from langchain.llms import ChatGLM
>>>
>>> llm = ChatGLM(endpoint_url="http://127.0.0.1:8000")
>>> llm.predict("你好")
'你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'
更多选项请参阅 examples/langchain_client.py 和 LangChain ChatGLM 集成。
OpenAI API
启动兼容 OpenAI 聊天完成协议的 API 服务器:
MODEL=./models/chatglm3-ggml.bin uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000
使用 curl 测试您的端点:
curl http://127.0.0.1:8000/v1/chat/completions -H 'Content-Type: application/json' \
-d '{"messages": [{"role": "user", "content": "你好"}]}'
使用 OpenAI 客户端与您的模型对话:
>>> from openai import OpenAI
>>>
>>> client = OpenAI(base_url="http://127.0.0.1:8000/v1")
>>> response = client.chat.completions.create(model="default-model", messages=[{"role": "user", "content": "你好"}])
>>> response.choices[0].message.content
'你好👋!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。'
如需流式响应,请查看示例客户端脚本:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --stream --prompt 你好
工具调用也同样支持:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --tool_call --prompt 上海天气怎么样
请求 GLM4V 并附带图像输入:
# 使用本地图像文件请求
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片" \
--image https://oss.gittoolsai.com/images/li-plus_chatglm.cpp_readme_f52c51021b38.jpg --temp 0
# 使用图像 URL 请求
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片" \
--image https://www.barnorama.com/wp-content/uploads/2016/12/03-Confusing-Pictures.jpg --temp 0
借助此 API 服务器作为后端,ChatGLM.cpp 模型可以无缝集成到任何使用 OpenAI 风格 API 的前端中,包括 mckaywrigley/chatbot-ui、fuergaosi233/wechat-chatgpt、Yidadaa/ChatGPT-Next-Web 等。
使用 Docker
选项 1:本地构建
在本地构建 Docker 镜像,并启动容器以在 CPU 上运行推理:
docker build . --network=host -t chatglm.cpp
# C++ 示例
docker run -it --rm -v $PWD/models:/chatglm.cpp/models chatglm.cpp ./build/bin/main -m models/chatglm-ggml.bin -p "你好"
# Python 示例
docker run -it --rm -v $PWD/models:/chatglm.cpp/models chatglm.cpp python3 examples/cli_demo.py -m models/chatglm-ggml.bin -p "你好"
# LangChain API 服务器
docker run -it --rm -v $PWD/models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp \
uvicorn chatglm_cpp.langchain_api:app --host 0.0.0.0 --port 8000
# OpenAI API 服务器
docker run -it --rm -v $PWD/models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp \
uvicorn chatglm_cpp.openai_api:app --host 0.0.0.0 --port 8000
若需支持 CUDA,请确保已安装 nvidia-docker。然后运行以下命令:
docker build . --network=host -t chatglm.cpp-cuda \
--build-arg BASE_IMAGE=nvidia/cuda:12.2.0-devel-ubuntu20.04 \
--build-arg CMAKE_ARGS="-DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=80"
docker run -it --rm --gpus all -v $PWD/models:/chatglm.cpp/models chatglm.cpp-cuda \
./build/bin/main -m models/chatglm-ggml.bin -p "你好"
选项 2:使用预构建镜像
用于 CPU 推理的预构建镜像已发布在 Docker Hub 和 GitHub Container Registry (GHCR) 上。
从 Docker Hub 拉取并运行示例:
docker run -it --rm -v $PWD/models:/chatglm.cpp/models liplusx/chatglm.cpp:main \
./build/bin/main -m models/chatglm-ggml.bin -p "你好"
从 GHCR 拉取并运行示例:
docker run -it --rm -v $PWD/models:/chatglm.cpp/models ghcr.io/li-plus/chatglm.cpp:main \
./build/bin/main -m models/chatglm-ggml.bin -p "你好"
预构建镜像也支持 Python 示例和 API 服务器,使用方法与 选项 1 相同。
性能
环境:
- CPU 后端性能是在一台配备 Intel(R) Xeon(R) Platinum 8260 CPU @ 2.40GHz 的 Linux 服务器上,使用 16 个线程进行测量。
- CUDA 后端性能是在一块 V100-SXM2-32GB GPU 上,使用 1 个线程进行测量。
- MPS 后端性能是在 Apple M2 Ultra 设备上,使用 1 个线程进行测量。
ChatGLM-6B:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| ms/标记(CPU @ Platinum 8260) | 74 | 77 | 86 | 89 | 114 | 189 |
| ms/标记(CUDA @ V100 SXM2) | 8.1 | 8.7 | 9.4 | 9.5 | 12.0 | 19.1 |
| ms/标记(MPS @ M2 Ultra) | 11.5 | 12.3 | N/A | N/A | 16.1 | 24.4 |
| 文件大小 | 3.3G | 3.7G | 4.0G | 4.4G | 6.2G | 12G |
| 内存占用 | 4.0G | 4.4G | 4.7G | 5.1G | 6.9G | 13G |
ChatGLM2-6B / ChatGLM3-6B / CodeGeeX2:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| ms/标记(CPU @ Platinum 8260) | 64 | 71 | 79 | 83 | 106 | 189 |
| ms/标记(CUDA @ V100 SXM2) | 7.9 | 8.3 | 9.2 | 9.2 | 11.7 | 18.5 |
| ms/标记(MPS @ M2 Ultra) | 10.0 | 10.8 | N/A | N/A | 14.5 | 22.2 |
| 文件大小 | 3.3G | 3.7G | 4.0G | 4.4G | 6.2G | 12G |
| 内存占用 | 3.4G | 3.8G | 4.1G | 4.5G | 6.2G | 12G |
ChatGLM4-9B:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| ms/标记(CPU @ Platinum 8260) | 105 | 105 | 122 | 134 | 158 | 279 |
| ms/标记(CUDA @ V100 SXM2) | 12.1 | 12.5 | 13.8 | 13.9 | 17.7 | 27.7 |
| ms/标记(MPS @ M2 Ultra) | 14.4 | 15.3 | 19.6 | 20.1 | 20.7 | 32.4 |
| 文件大小 | 5.0G | 5.5G | 6.1G | 6.6G | 9.4G | 18G |
模型质量
我们通过在 WikiText-2 测试数据集上评估困惑度来衡量模型质量,采用 https://huggingface.co/docs/transformers/perplexity 中的滑动窗口策略。较低的困惑度通常表示模型表现更好。
从 链接 下载并解压数据集。使用步长为 512、最大输入长度为 2048 的方式计算困惑度:
./build/bin/perplexity -m models/chatglm3-base-ggml.bin -f wikitext-2-raw/wiki.test.raw -s 512 -l 2048
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| ChatGLM3-6B-Base | 6.215 | 6.188 | 6.006 | 6.022 | 5.971 | 5.972 |
| ChatGLM4-9B-Base | 6.834 | 6.780 | 6.645 | 6.624 | 6.576 | 6.577 |
开发
单元测试与基准测试
要执行单元测试,需添加 CMake 标志 -DCHATGLM_ENABLE_TESTING=ON 以启用测试功能。重新编译并运行单元测试(包括基准测试):
mkdir -p build && cd build
cmake .. -DCHATGLM_ENABLE_TESTING=ON && make -j
./bin/chatglm_test
仅进行基准测试:
./bin/chatglm_test --gtest_filter='Benchmark.*'
代码格式化
要在 build 文件夹内格式化代码,运行 make lint。请确保已预先安装 clang-format、black 和 isort。
性能分析
要检测性能瓶颈,可添加 CMake 标志 -DGGML_PERF=ON:
cmake .. -DGGML_PERF=ON && make -j
这将在运行模型时打印每次图操作的耗时信息。
致谢
- 本项目深受 @ggerganov 的 llama.cpp 启发,并基于其 NN 库 ggml 构建。
- 感谢 @THUDM 提供的优秀 ChatGLM-6B、ChatGLM2-6B、ChatGLM3 和 GLM-4,以及他们发布的模型源代码和检查点。
版本历史
v0.4.22024/07/31v0.4.12024/07/25v0.4.02024/06/21v0.3.42024/06/14v0.3.32024/06/13v0.3.22024/04/24v0.3.12024/01/20v0.3.02023/11/22v0.2.102023/10/30v0.2.92023/10/22v0.2.82023/10/10v0.2.72023/09/28v0.2.62023/08/31v0.2.52023/08/22v0.2.42023/08/11v0.2.32023/08/07v0.2.22023/07/30v0.2.12023/07/22v0.2.02023/07/08常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
gpt4all
GPT4All 是一款让普通电脑也能轻松运行大型语言模型(LLM)的开源工具。它的核心目标是打破算力壁垒,让用户无需依赖昂贵的显卡(GPU)或云端 API,即可在普通的笔记本电脑和台式机上私密、离线地部署和使用大模型。 对于担心数据隐私、希望完全掌控本地数据的企业用户、研究人员以及技术爱好者来说,GPT4All 提供了理想的解决方案。它解决了传统大模型必须联网调用或需要高端硬件才能运行的痛点,让日常设备也能成为强大的 AI 助手。无论是希望构建本地知识库的开发者,还是单纯想体验私有化 AI 聊天的普通用户,都能从中受益。 技术上,GPT4All 基于高效的 `llama.cpp` 后端,支持多种主流模型架构(包括最新的 DeepSeek R1 蒸馏模型),并采用 GGUF 格式优化推理速度。它不仅提供界面友好的桌面客户端,支持 Windows、macOS 和 Linux 等多平台一键安装,还为开发者提供了便捷的 Python 库,可轻松集成到 LangChain 等生态中。通过简单的下载和配置,用户即可立即开始探索本地大模型的无限可能。