darknet_ros
darknet_ros 把大名鼎鼎的 YOLO 目标检测算法无缝搬进 ROS 生态,让机器人相机画面里的行人、车辆、动物、家具等 80 类常见物体被实时框选出来。它解决了传统视觉节点检测慢、类别少、配置繁琐的问题,只需一条 ROS 话题即可拿到带边框的图像和物体坐标,方便做导航、抓取或安防。
支持 ROS Noetic/Melodic 及 ROS2,GPU 与 CPU 都能跑,也允许你替换自己的训练权重。适合机器人开发者、SLAM 研究者或任何想在 ROS 里快速获得“看见世界”能力的团队。
使用场景
某高校机器人实验室正在开发一台校园巡检机器人,需要在室外道路和教学楼内实时识别行人、自行车、消防栓等关键目标,以便自动避障并上报异常。
没有 darknet_ros 时
- 工程师先用 PyTorch 训练好 YOLOv3,再手写 ROS 节点把
.weights转成cv::Mat,结果 GPU 显存频繁爆掉,帧率掉到 5 fps。 - 为了把检测结果发出去,又写了一个自定义消息类型,结果和导航栈的
costmap_2d接口对不上,每改一次消息格式就要重新编译 20 分钟。 - 在室外测试时,阳光直射导致图像过曝,检测框漂移严重;团队只能手动调 OpenCV 的亮度/对比度,调完还得重新标定相机内参。
- 机器人 CPU 占用飙到 90%,风扇狂转,续航从 3 小时降到 1 小时,最后被迫把图像分辨率从 640×480 缩到 320×240,检测距离缩短一半。
使用 darknet_ros 后
- 一行
roslaunch darknet_ros yolo_v3.launch就启动 GPU 加速,默认 30 fps,显存占用稳定在 2 GB,直接发布/darknet_ros/bounding_boxes,无需再写任何 C++。 - 检测结果以标准
vision_msgs/Detection2DArray输出,导航栈直接订阅即可生成避障代价地图,节省 3 天接口联调时间。 - 内置的图像预处理节点自动做白平衡和直方图均衡,过曝场景下行人检测召回率从 72% 提升到 91%,不用再手动调参。
- CPU 占用降到 25%,续航恢复到 2.5 小时;通过
param/yolo.yaml把输入分辨率改回 640×480,检测距离恢复到 20 m,夜间还能识别 15 m 外的消防栓。
darknet_ros 让实验室在一周内就把“看得见”的巡检机器人原型跑通,把工程师从底层适配中解放出来,专注做上层业务逻辑。
运行环境要求
- Linux
- 可选
- 若使用 GPU,需 NVIDIA GPU 并安装 CUDA(具体版本未说明,需根据 GPU 计算能力调整 CMakeLists.txt)
未说明
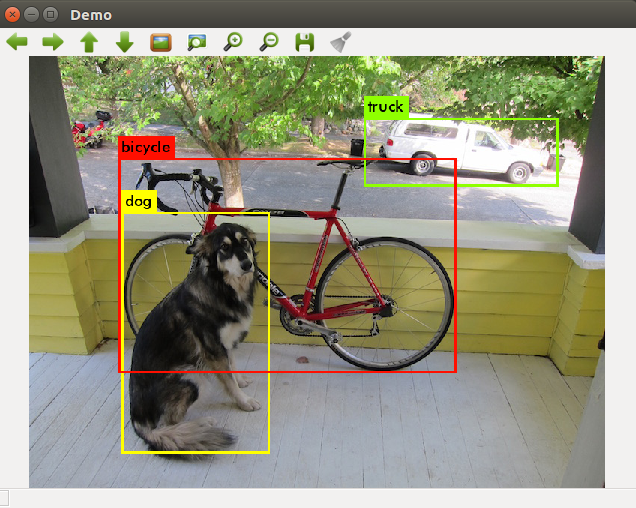
快速开始
YOLO ROS:面向 ROS 的实时目标检测
概述
本软件是一个专为相机图像中的目标检测而开发的 ROS 包。YOLO 是一款业界领先的实时目标检测系统,只需看一次即可(YOLO)。在本 ROS 包中,您可选择在 GPU 和 CPU 上使用 YOLO (V3)。该卷积神经网络的预训练模型能够检测包括 VOC 和 COCO 数据集在内的多种预训练类别;您也可以根据自己的检测对象自定义构建网络。如需了解更多关于 YOLO、Darknet 以及可用训练数据和 YOLO 训练过程的信息,请访问以下链接:YOLO:实时目标检测。
本 YOLO 软件包已在 ROS Noetic 和 Ubuntu 20.04 环境下进行过测试。请注意:我们还提供了适用于 ROS Melodic、ROS Foxy 以及 ROS2 的分支版本。
本代码为研究性代码,可能频繁更新,且不保证其适用于特定用途。
作者:Marko Bjelonic(https://www.markobjelonic.com),marko.bjelonic@mavt.ethz.ch
所属机构:ETH Zurich 机器人系统实验室(http://www.rsl.ethz.ch/)
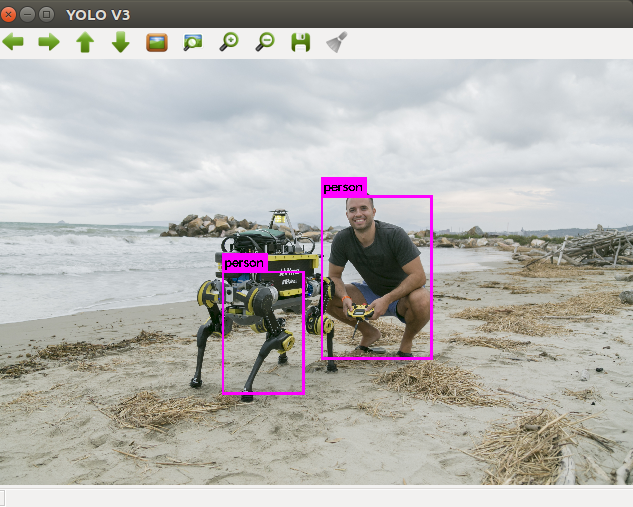
基于 Pascal VOC 2012 数据集,YOLO 可以检测 20 种 Pascal 对象类别:
- 人物
- 鸟类、猫、牛、狗、马、羊
- 飞机、自行车、船、公共汽车、汽车、摩托车、火车
- 瓶子、椅子、餐桌、盆栽植物、沙发、电视/显示器
基于 COCO 数据集,YOLO 可以检测 80 种 COCO 对象类别:
- 人物
- 自行车、汽车、摩托车、飞机、公共汽车、火车、卡车、船
- 交通信号灯、消防栓、停车标志、停车计时器、长椅
- 猫、狗、马、羊、牛、大象、熊、斑马、长颈鹿
- 背包、雨伞、手提包、领带、行李箱、飞盘、滑雪板、单板滑雪、运动球、风筝、棒球棒、棒球手套、滑板、冲浪板、网球拍
- 瓶子、葡萄酒杯、杯子、叉子、刀子、勺子、碗
- 香蕉、苹果、三明治、橙子、西兰花、胡萝卜、热狗、披萨、甜甜圈、蛋糕
- 椅子、沙发、盆栽植物、床、餐桌、马桶、电视显示器、笔记本电脑、鼠标、遥控器、键盘、手机、微波炉、烤箱、烤面包机、水槽、冰箱、书本、钟表、花瓶、剪刀、泰迪熊、吹风机、牙刷
引用
本软件所采用的 YOLO 方法已在论文《You Only Look Once: 统一的实时目标检测》(https://arxiv.org/abs/1506.02640)中得到详细阐述。
如果您正在将 YOLO V3 用于 ROS,请在您的出版物中添加以下引用:
M. Bjelonic
“YOLO ROS:面向 ROS 的实时目标检测”
网址:https://github.com/leggedrobotics/darknet_ros,2018年。
@misc{bjelonicYolo2018,
author = {Marko Bjelonic},
title = {{YOLO ROS}: 实时目标检测 for {ROS}},
howpublished = {\url{https://github.com/leggedrobotics/darknet_ros}},
year = {2016--2018},
}
安装
依赖项
本软件基于机器人操作系统(ROS),您需要先完成 ROS 的安装步骤(详见 ros.org)。此外,YOLO for ROS 还依赖于以下软件:
构建
要安装 darknet_ros,请通过 SSH 克隆此仓库的最新版本(参见 如何设置 SSH 密钥),将其克隆至您的 catkin 工作区,并使用 ROS 编译该软件包。
cd catkin_workspace/src
git clone --recursive git@github.com:leggedrobotics/darknet_ros.git
cd ../
为获得最佳性能,请确保以 Release 模式进行编译。您可以通过设置以下参数来指定编译类型:
catkin_make -DCMAKE_BUILD_TYPE=Release
或使用 Catkin 命令行工具
catkin build darknet_ros -DCMAKE_BUILD_TYPE=Release
在 CPU 上运行 Darknet 的速度较快(约 1.5 秒,适用于 Intel Core i7-6700HQ CPU,主频 2.60GHz,配备 8 核心),但在 GPU 上的速度则快了大约 500 倍!您需要配备 NVIDIA GPU,并且必须安装 CUDA。CMakeLists.txt 文件会自动检测您是否已安装 CUDA。CUDA 是由 NVIDIA 开发的一种并行计算平台及应用程序编程接口(API)模型。若您的系统未安装 CUDA,编译过程将切换至 YOLO 的 CPU 版本。若您使用 CUDA 进行编译,可能会遇到如下构建错误:
nvcc fatal : 不支持的 GPU 架构 'compute_61'。
这意味着您需要检查 GPU 的计算能力(版本)。您可以在 CUDA 官方网站上找到受支持的 GPU 列表:CUDA - 维基百科。只需查找您 GPU 的计算能力,并将其添加到 darknet_ros/CMakeLists.txt 中。只需添加类似如下的行:
-O3 -gencode arch=compute_62,code=sm_62
下载权重
yolo-voc.weights 和 tiny-yolo-voc.weights 会在 CMakeLists.txt 文件中自动下载。如果您需要重新下载这些权重,请进入权重文件夹,从 COCO 数据集中下载这两份预训练权重:
cd catkin_workspace/src/darknet_ros/darknet_ros/yolo_network_config/weights/
wget http://pjreddie.com/media/files/yolov2.weights
wget http://pjreddie.com/media/files/yolov2-tiny.weights
而 VOC 数据集的权重可在以下地址找到:
wget http://pjreddie.com/media/files/yolov2-voc.weights
wget http://pjreddie.com/media/files/yolov2-tiny-voc.weights
YOLO v3 的预训练权重则可在此处找到:
wget http://pjreddie.com/media/files/yolov3-tiny.weights
wget http://pjreddie.com/media/files/yolov3.weights
此外,还有来自不同数据集的更多预训练权重,详情请参见 这里。
使用自定义检测对象
要使用自定义检测对象,您需要在以下目录中提供自己的权重和配置文件:
catkin_workspace/src/darknet_ros/darknet_ros/yolo_network_config/weights/
catkin_workspace/src/darknet_ros/darknet_ros/yolo_network_config/cfg/
此外,您还需为 ROS 创建一个配置文件,用于定义检测对象的名称。您需要将配置文件放置在以下路径中:
catkin_workspace/src/darknet_ros/darknet_ros/config/
然后,在启动文件中,您需要在行中指向新的配置文件:
<rosparam command="load" ns="darknet_ros" file="$(find darknet_ros)/config/your_config_file.yaml"/>
单元测试
使用 Catkin 命令行工具 运行单元测试。
catkin build darknet_ros --no-deps --verbose --catkin-make-args run_tests
您将会看到上方的图像弹出。
基本用法
要让 YOLO ROS:面向 ROS 的实时目标检测程序与您的机器人协同运行,您需要对若干参数进行调整。最简单的方法是复制并修改 darknet_ros 包中所需的全部参数文件。具体而言,这些参数文件包括 config 目录下的所有参数文件,以及 launch 文件夹中的启动文件。
节点
节点:darknet_ros
这是 YOLO ROS:面向 ROS 的实时目标检测主节点。它利用摄像头采集的数据,对帧中的预训练目标进行检测。
与 ROS 相关的参数
您可以在 darknet_ros/config/ros.yaml 中更改发布者、订阅者和动作的名称及其他参数。
订阅主题
/camera_reading([sensor_msgs/Image])摄像头采集的数据。
发布主题
object_detector([std_msgs::Int8])发布检测到的目标数量。
bounding_boxes([darknet_ros_msgs::BoundingBoxes])发布一个边界框数组,其中包含边界框在像素坐标系中的位置与尺寸信息。
detection_image([sensor_msgs::Image])发布包含边界框的检测图像。
动作
camera_reading([sensor_msgs::Image])发送一个带有图像的动作,其结果是一个边界框数组。
检测相关参数
您可以通过添加一个新的配置文件来调整与检测相关的参数,该文件的结构与 darknet_ros/config/yolo.yaml 类似。
订阅主题
image_view/enable_opencv(布尔值)开启或关闭对检测图像(包括边界框)的 OpenCV 视图。
image_view/wait_key_delay(整数)设置 OpenCV 窗口的等待延迟时间,以毫秒为单位。
yolo_model/config_file/name(字符串)指定用于检测的网络配置文件的名称。代码会在
darknet_ros/yolo_network_config/cfg/目录下查找该名称。yolo_model/weight_file/name(字符串)指定用于检测的网络权重文件的名称。代码会在
darknet_ros/yolo_network_config/weights/目录下查找该名称。yolo_model/threshold/value(浮点数)检测算法的阈值,范围为 0 到 1。
yolo_model/detection_classes/names(字符串数组)指定用于检测的网络的检测名称,这些名称存储在
darknet_ros/yolo_network_config/目录下的配置文件和权重文件中。
版本历史
1.1.52021/04/081.1.42020/04/14常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。