Attention-Augmented-Conv2d
Attention-Augmented-Conv2d 是一个基于 PyTorch 实现的开源项目,旨在复现论文《Attention Augmented Convolutional Networks》中提出的注意力增强卷积网络。传统卷积神经网络擅长提取局部特征,但在捕捉图像全局依赖关系上存在局限;该工具通过将自注意力机制与标准卷积操作相结合,让模型在保留局部感知能力的同时,也能“看见”并理解图像的全局上下文信息,从而提升视觉任务的表现。
该项目主要解决了原始论文仅提供 TensorFlow 版本的问题,为广大的 PyTorch 用户提供了便捷、高效的实现方案。它特别适合深度学习研究人员和开发者使用,尤其是那些希望在图像分类、目标检测等任务中探索注意力机制与卷积融合效果的工程师。
技术亮点方面,Attention-Augmented-Conv2d 不仅完整还原了论文核心算法,还贴心地增加了相对位置编码(relative position encoding)的支持,并修复了相关参数学习的关键问题。此外,它对填充(padding)和多步长(stride)设置进行了优化,使其接口风格与 PyTorch 原生的 nn.Conv2d 高度一致,降低了上手门槛。代码中内置的参数断言检查也能帮助用户避免常见的配置错误,确保实验的稳定性。无论是进行学术研究还是工业级模型迭代,这都是一个值得尝试的强力组件。
使用场景
某医疗影像初创团队正在开发基于 PyTorch 的肺部 CT 结节检测系统,需要在有限的显存资源下提升模型对微小病灶的识别精度。
没有 Attention-Augmented-Conv2d 时
- 传统卷积神经网络(CNN)受限于固定感受野,难以捕捉结节与周围血管的全局上下文关联,导致假阳性率高。
- 若强行引入标准自注意力机制(Self-Attention),计算复杂度随图像分辨率平方级增长,显存迅速溢出,无法处理高分辨率 CT 切片。
- 为了平衡性能与资源,开发者被迫在“局部特征提取”和“全局关系建模”之间做妥协,模型架构调整繁琐且效果不稳定。
- 在 TensorFlow 原版论文代码基础上进行 PyTorch 迁移时,需手动重写复杂的相对位置编码逻辑,容易因参数维度不匹配(如
dk、Nh整除问题)引发调试灾难。
使用 Attention-Augmented-Conv2d 后
- 该工具将卷积的局部性与注意力的全局性融合,使模型既能精准定位结节边缘,又能理解其与肺叶结构的长距离依赖,显著降低误报。
- 通过并行化设计,它在保持线性计算复杂度的同时实现了全局感知,无需牺牲输入分辨率即可在单张 GPU 上流畅训练。
- 开发者可直接替换原有的
nn.Conv2d层,灵活配置relative=True模式以自动学习相对位置偏置(key_rel_w/h),快速验证不同架构假设。 - 内置的参数断言机制(如检查
stride与shape的匹配关系)提前拦截维度错误,将原本数小时的移植调试时间缩短至分钟级。
Attention-Augmented-Conv2d 通过高效融合局部与全局特征,让资源受限下的医疗影像高精度检测成为可能,同时极大降低了前沿算法的工程落地门槛。
运行环境要求
- 未说明
非必需(代码自动检测并使用 CUDA,若无则回退至 CPU),具体型号和显存未说明,依赖已安装的 PyTorch CUDA 版本
未说明

快速开始
使用 PyTorch 实现注意力增强卷积网络
- 论文中是用 TensorFlow 实现的,所以我用 PyTorch 重新实现了一遍。
更新(2019年5月11日)
修复了在使用
relative=True模式时,无法找到key_rel_w和key_rel_h作为可学习参数的问题。在
relative = True模式下,可以看到key_rel_w和key_rel_h是可学习的参数。而在relative = False模式下,则无需担心shape参数。示例:
relative=True,步幅为1,shape=32
import torch
from attention_augmented_conv import AugmentedConv
use_cuda = torch.cuda.is_available()
device = torch.device('cuda' if use_cuda else 'cpu')
tmp = torch.randn((16, 3, 32, 32)).to(device)
augmented_conv1 = AugmentedConv(in_channels=3, out_channels=20, kernel_size=3, dk=40, dv=4, Nh=4, relative=True, stride=1, shape=32).to(device)
conv_out1 = augmented_conv1(tmp)
print(conv_out1.shape) # (16, 20, 32, 32)
for name, param in augmented_conv1.named_parameters():
print('parameter name: ', name)
从参数名称中可以看出,确实存在
key_rel_w和key_rel_h。示例:
relative=True,步幅为2,shape=16
import torch
from attention_augmented_conv import AugmentedConv
use_cuda = torch.cuda.is_available()
device = torch.device('cuda' if use_cuda else 'cpu')
tmp = torch.randn((16, 3, 32, 32)).to(device)
augmented_conv1 = AugmentedConv(in_channels=3, out_channels=20, kernel_size=3, dk=40, dv=4, Nh=4, relative=True, stride=2, shape=16).to(device)
conv_out1 = augmented_conv1(tmp)
print(conv_out1.shape) # (16, 20, 16, 16)
- 需要注意的是,在使用
relative = True模式时,步幅乘以shape的结果应等于输入图像的尺寸。例如,如果输入是(16, 3, 32, 32),且步幅为2,则shape应设置为16。
更新(2019年5月2日)
我为“AugmentedConv”部分添加了填充功能。
使用方式与
nn.conv2d相同。下面也会附上示例。
示例:
relative=False,步幅为1
import torch
from attention_augmented_conv import AugmentedConv
use_cuda = torch.cuda.is_available()
device = torch.device('cuda' if use_cuda else 'cpu')
temp_input = torch.randn((16, 3, 32, 32)).to(device)
augmented_conv = AugmentedConv(in_channels=3, out_channels=20, kernel_size=3, dk=40, dv=4, Nh=1, relative=False,stride=1).to(device)
conv_out = augmented_conv(tmp)
print(conv_out.shape) # (16, 20, 32, 32),(batch_size, out_channels, height, width)
- 示例:
relative=False,步幅为2
import torch
from attention_augmented_conv import AugmentedConv
use_cuda = torch.cuda.isAvailable()
device = torch.device('cuda' if use_cuda else 'cpu')
temp_input = torch.randn((16, 3, 32, 32)).to(device)
augmented_conv = AugmentedConv(in_channels=3, out_channels=20,kernel_size=3,dk=40,dv=4,Nh=1,relative=False,stride=2).to(device)
conv_out = augmented_conv(tmp)
print(conv_out.shape) # (16, 20,16,16),(batch_size,out_channels,height,width)
- 我为参数(
dk、dv、Nh)添加了断言检查。
assert self.Nh != 0, "integer division or modulo by zero, Nh >= 1"
assert self.dk % self.Nh == 0, "dk should be divided by Nh. (example: out_channels: 20, dk: 40, Nh: 4)"
assert self.dv % self.Nh == 0, "dv should be divided by Nh. (example: out_channels: 20, dv: 4, Nh: 4)"
assert stride in [1, 2], str(stride) + " Up to 2 strides are allowed."
我发布了两种版本的“注意力增强卷积”
- 论文版本在此处:https://github.com/leaderj1001/Attention-Augmented-Conv2d/blob/master/attention_augmented_conv.py
- AA-Wide-ResNet 版本在此处:https://github.com/leaderj1001/Attention-Augmented-Conv2d/blob/master/AA-Wide-ResNet/attention_augmented_conv.py
参考资料
论文
- 注意力增强卷积网络论文
- 作者:Irwan Bello、Barret Zoph、Ashish Vaswani、Jonathon Shlens
- Quoc V.Le Google Brain
Wide-ResNet
- GitHub 地址
- 谢谢!
方法
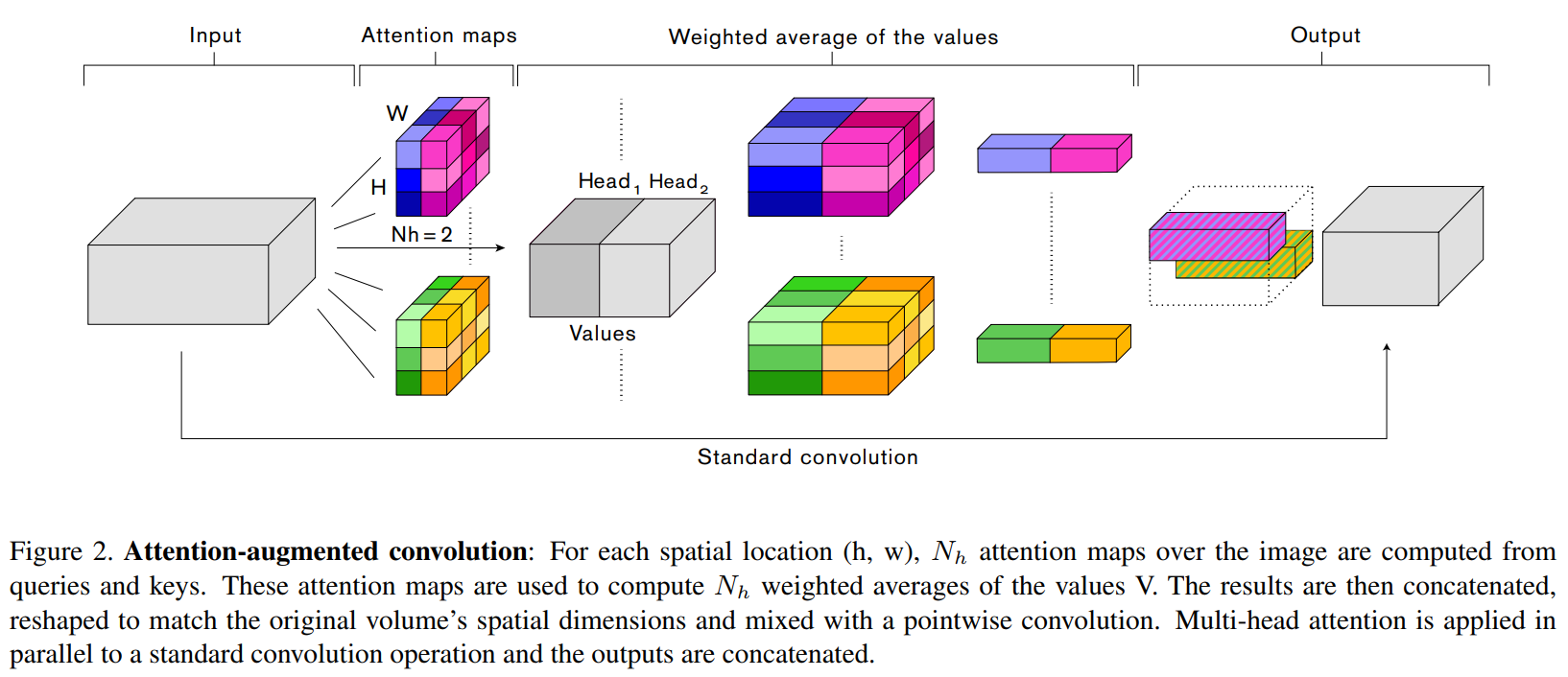
输入参数
在论文中,
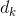 和
和 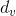 是通过以下公式计算得到的。
是通过以下公式计算得到的。
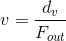 ,
, 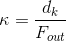
论文中关于参数的实验
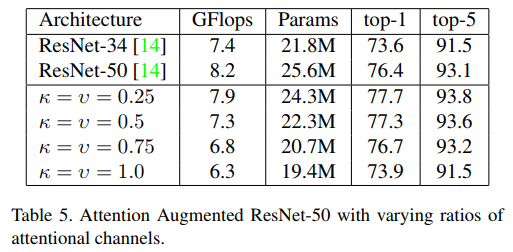
实验
- 论文中提到,他们通过在所有残差块的第一层卷积中加入相对注意力机制来增强 Wide-ResNet-28-10,使用 Nh=8 头,κ=2,υ=0.2,并且每个头的键至少有 20 维。
| 数据集 | 模型 | 准确率 | 轮数 | 训练时间 |
|---|---|---|---|---|
| CIFAR-10 | Wide-ResNet 28x10(正在进行中) | |||
| CIFAR-100 | Wide-ResNet 28x10(正在进行中) | |||
| CIFAR-100 | 仅3层卷积(通道数:64、128、192) | 61.6% | 100 | 22分钟 |
| CIFAR-100 | 仅3层注意力增强卷积(通道数:64、128、192) | 59.82% | 35 | 2小时23分钟 |
- 我没有足够的 GPU,因此训练起来非常困难。
- 我只是想看看这种方法(注意力增强卷积层)是否可行,所以会尝试一下 ResNet。
- 上述结果显示,不同方法之间存在很大的时间差异。我会再深入思考这一部分。
- 我注意到
torch.einsum函数执行速度较慢。链接 - 当我运行该链接中的示例代码时,结果如下:
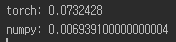
- 使用 CUDA
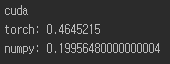
时间复杂度
- 我比较了“relative = True”和“relative = False”的时间复杂度。
- 我将对比这两种不同取值(
relative=True和relative=False)的性能。 - 此外,我还会考虑如何降低“relative = True”情况下的时间复杂度。

依赖项
- tqdm==4.31.1
- torch==1.0.1
- torchvision==0.2.2
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。