TensorRT-YOLO
TensorRT-YOLO 是一款专为 NVIDIA 设备打造的高效 YOLO 系列模型推理部署工具。它旨在解决开发者在将 YOLO 模型从训练环境迁移到实际生产时面临的部署复杂、推理速度慢以及环境配置繁琐等痛点。
无论是从事计算机视觉算法研究的科研人员,还是需要将目标检测、实例分割、姿态估计等功能落地到边缘设备或服务器的工程师,都能通过 TensorRT-YOLO 获得“开箱即用”的体验。该工具不仅支持从 YOLOv3 到最新 YOLO26 及 YOLO-World 等多种变体,还覆盖了分类、旋转检测等丰富场景。
其核心技术亮点在于深度集成了 TensorRT 插件以加速后处理,并利用自定义 CUDA 核函数与 CUDA 图技术优化前处理和整体推理流程,显著提升了运行效率。此外,TensorRT-YOLO 提供了简洁的 C++ 和 Python 接口,支持多 Context 并行推理,且在 C++ 端实现了零第三方依赖的单头文件调用,极大简化了集成难度。配合完善的 Docker 支持和跨平台兼容性(涵盖 x86 与 ARM 架构),它能帮助用户轻松实现高性能、低延迟的模型部署。
使用场景
某智慧交通团队需要在 NVIDIA Jetson Orin 边缘设备上部署实时车辆检测系统,以监控路口违章行为并即时报警。
没有 TensorRT-YOLO 时
- 推理延迟高:直接使用 PyTorch 原生模型推理,帧率仅维持在 15 FPS 左右,无法满足 30 FPS 的实时流畅监控需求,导致关键违章瞬间漏检。
- 开发配置繁琐:手动编写 CUDA 核函数优化 LetterBox 预处理和后处理 NMS 算法耗时数周,且难以保证与训练端的像素级精度对齐,偶发检测框偏移。
- 资源调度困难:缺乏多路视频流并行处理能力,单卡只能勉强支撑一路高清视频分析,硬件算力利用率极低,无法规模化部署。
- 环境依赖复杂:项目强依赖特定版本的第三方库,跨设备迁移时常因环境冲突导致部署失败,运维成本高昂。
使用 TensorRT-YOLO 后
- 性能极致飞跃:利用 TensorRT-YOLO 集成的 CUDA 图技术和自定义插件,推理速度飙升至 65+ FPS,延迟降低 70%,轻松实现多路视频实时无卡顿分析。
- 精度完美对齐:内置复刻的 LetterBox 预处理确保像素误差为 0,后处理由高效插件自动完成,无需手动调优即可复现训练端精度,检测框稳定可靠。
- 并发能力增强:通过多 Context 并行推理机制,单张 Orin 板卡可同时处理 4 路 1080P 视频流,最大化挖掘硬件潜能,显著降低单路监控成本。
- 部署开箱即用:仅需引入单个
trtyolo.hpp头文件或调用 Python 模块,零第三方依赖即可完成集成,配合 Docker 一键部署,将原本数周的工程化周期缩短至半天。
TensorRT-YOLO 通过将复杂的底层加速技术封装为极简接口,让开发者在边缘端也能轻松获得服务器级的推理性能与稳定性。
运行环境要求
- Linux
- Windows
需要 NVIDIA GPU (支持 x86 和 ARM 架构),需安装 CUDA Toolkit ≥ 11.0.1 和 TensorRT ≥ 8.6.1
未说明

快速开始
English | 简体中文




![]()
🚀 TensorRT-YOLO 是一款专为 NVIDIA 设备设计的易用灵活、极致高效的YOLO系列推理部署工具。项目不仅集成了 TensorRT 插件以增强后处理效果,还使用了 CUDA 核函数以及 CUDA 图来加速推理。TensorRT-YOLO 提供了 C++ 和 Python 推理的支持,旨在提供📦开箱即用的部署体验。包括 目标检测、实例分割、图像分类、姿态识别、旋转目标检测、视频分析等任务场景,满足开发者多场景的部署需求。


🌠 过去更新
🔥 实战课程|TensorRT × Triton Inference Server 模型部署
- 平台: BiliBili 课堂 | 微信公众号 🚀 HOT
- 团队: laugh12321 | 不归牛顿管的熊猫
- 🛠 硬核专题:
▸ 自定义插件开发(含Plugin注册全流程)
▸ CUDA Graph 原理与工程实践
▸ Triton Inference Server 部署技巧
2026-03-20: 添加对 YOLO26 的支持,包括分类、定向边界框、姿态估计以及实例分割。🌟 NEW
2026-01-07: 添加对 YOLO-Master 的支持,包括分类、定向边界框、姿态估计以及实例分割。🌟 NEW
2025-10-05:精度完美对齐,CUDA 完美复刻 LetterBox,绝大多数情况下像素误差为 0。Python 模块重大重构,易用性大幅提升。🌟 NEW
2025-06-09: C++仅引单头文件
trtyolo.hpp,零第三方依赖(使用模块时无需链接 CUDA 和 TensorRT),增加对带图像间距(Pitch)数据结构的支持,详见 B站。🌟 NEW2025-04-19: 添加对 YOLO-World, YOLOE 的支持,包括分类、定向边界框、姿态估计以及实例分割,详见 B站。🌟 NEW
2025-03-29: 添加对 YOLO12 的支持,包括分类、定向边界框、姿态估计以及实例分割,详见 issues。🌟 NEW
✨ 主要特性
🎯 多样化的 YOLO 支持
- 全面兼容:支持 YOLOv3 至 YOLO26,以及 YOLO-World、YOLO-Master 等多种变体,满足多样化需求,详见 🖥️ 模型支持列表。
- 灵活切换:提供简洁易用的接口,支持不同版本 YOLO 模型的快速切换。🌟 NEW
- 多场景应用:提供丰富的示例代码,涵盖Detect、Segment、Classify、Pose、OBB等多种应用场景。
🚀 性能优化
- CUDA 加速:通过 CUDA 核函数优化前处理流程,并采用 CUDA 图技术加速推理过程。
- TensorRT 集成:深度集成 TensorRT 插件,显著加速后处理,提升整体推理效率。
- 多 Context 推理:支持多 Context 并行推理,最大化硬件资源利用率。🌟 NEW
- 显存管理优化:适配多架构显存优化策略(如 Jetson 的 Zero Copy 模式),提升显存效率。🌟 NEW
🛠️ 易用性
- 开箱即用:提供全面的 C++ 和 Python 推理支持,满足不同开发者需求。
- CLI 工具:命令行界面简洁直观,并支持自动识别模型结构,无需复杂配置。
- Docker 支持:提供 Docker 一键部署方案,简化环境配置与部署流程。
- 无第三方依赖:全部功能使用标准库实现,无需额外依赖,简化部署流程。
- 部署便捷:提供动态库编译支持,方便调用和部署。
🌐 兼容性
- 多平台支持:全面兼容 Windows、Linux、ARM、x86 等多种操作系统与硬件平台。
- TensorRT 兼容:完美适配 TensorRT 10.x 版本,确保与最新技术生态无缝衔接。
🔧 灵活配置
- 预处理参数自定义:支持多种预处理参数灵活配置,包括 通道交换 (SwapRB)、归一化参数、边界值填充。🌟 NEW
💨 快速开始
1. 前置依赖
- CUDA:推荐版本 ≥ 11.0.1
- TensorRT:推荐版本 ≥ 8.6.1
- 操作系统:Linux (x86_64 或 arm)(推荐);Windows 亦可支持
[!NOTE]
如果您在 Windows 下进行开发,可以参考以下配置指南:
2. 编译安装
首先,克隆 TensorRT-YOLO 仓库:
git clone https://github.com/laugh12321/TensorRT-YOLO
cd TensorRT-YOLO
然后使用 CMake,可以按照以下步骤操作:
pip install "pybind11[global]" # 安装 pybind11,用于生成 Python 绑定
cmake -S . -B build -D TRT_PATH=/your/tensorrt/dir -D BUILD_PYTHON=ON -D CMAKE_INSTALL_PREFIX=/your/tensorrt-yolo/install/dir
cmake --build build -j$(nproc) --config Release --target install
执行上述指令后,tensorrt-yolo 库将被安装到指定的 CMAKE_INSTALL_PREFIX 路径中。其中,include 文件夹中包含头文件,lib 文件夹中包含 trtyolo 动态库和 custom_plugins 动态库(仅在使用 trtexec 构建 OBB、Segment 或 Pose 模型时需要)。如果在编译时启用了 BUILD_PYTHON 选项,则还会在 trtyolo/libs 路径下生成相应的 Python 绑定文件。
[!NOTE]
在使用 C++ 动态库之前,请确保将指定的CMAKE_INSTALL_PREFIX路径添加到环境变量中,以便 CMake 的find_package能够找到tensorrt-yolo-config.cmake文件。可以通过以下命令完成此操作:export PATH=$PATH:/your/tensorrt-yolo/install/dir # linux $env:PATH = "$env:PATH;C:\your\tensorrt-yolo\install\dir;C:\your\tensorrt-yolo\install\dir\bin" # windows
如果您希望在 Python 上体验与 C++ 相同的推理速度,则编译时需开启 BUILD_PYTHON 选项,然后再按照以下步骤操作:
pip install --upgrade build
python -m build --wheel
pip install dist/trtyolo-6.*-py3-none-any.whl
3. 模型转换
- 使用项目配套的
trtyolo-export工具包,将已经导出的 YOLO 系列 ONNX 模型转换为兼容 TensorRT-YOLO 推理的输出结构并构建为 TensorRT 引擎。
4. 推理示例
使用 Python 进行推理:
import cv2 import supervision as sv from trtyolo import TRTYOLO # -------------------- 初始化模型 -------------------- # 注意:task参数需与导出时指定的任务类型一致("detect"、"segment"、"classify"、"pose"、"obb") # profile参数开启后,会在推理时计算性能指标,调用 model.profile() 可获取 # swap_rb参数开启后,会在推理前交换通道顺序(确保模型输入时RGB) model = TRTYOLO("yolo11n-with-plugin.engine", task="detect", profile=True, swap_rb=True) # -------------------- 加载测试图片并推理 -------------------- image = cv2.imread("test_image.jpg") result = model.predict(image) print(f"==> result: {result}") # -------------------- 可视化结果 -------------------- box_annotator = sv.BoxAnnotator() annotated_frame = box_annotator.annotate(scene=image.copy(), detections=result) # -------------------- 性能评估 -------------------- throughput, cpu_latency, gpu_latency = model.profile() print(throughput) print(cpu_latency) print(gpu_latency) # -------------------- 克隆模型 -------------------- # 克隆模型实例(适用于多线程场景) cloned_model = model.clone() # 创建独立副本,避免资源竞争 # 验证克隆模型推理一致性 cloned_result = cloned_model.predict(input_img) print(f"==> cloned_result: {cloned_result}")使用 C++ 进行推理:
#include <memory> #include <opencv2/opencv.hpp> #include "trtyolo.hpp" int main() { try { // -------------------- 初始化配置 -------------------- trtyolo::InferOption option; option.enableSwapRB(); // BGR->RGB转换 // 特殊模型参数设置示例 // const std::vector<float> mean{0.485f, 0.456f, 0.406f}; // const std::vector<float> std{0.229f, 0.224f, 0.225f}; // option.setNormalizeParams(mean, std); // -------------------- 模型初始化 -------------------- // ClassifyModel、DetectModel、OBBModel、SegmentModel 和 PoseModel 分别对应于图像分类、检测、方向边界框、分割和姿态估计模型 auto detector = std::make_unique<trtyolo::DetectModel>( "yolo11n-with-plugin.engine", // 模型路径 option // 推理设置 ); // -------------------- 数据加载 -------------------- cv::Mat cv_image = cv::imread("test_image.jpg"); if (cv_image.empty()) { throw std::runtime_error("无法加载测试图片"); } // 封装图像数据(不复制像素数据) trtyolo::Image input_image( cv_image.data, // 像素数据指针 cv_image.cols, // 图像宽度 cv_image.rows // 图像高度 ); // -------------------- 执行推理 -------------------- trtyolo::DetectRes result = detector->predict(input_image); std::cout << result << std::endl; // -------------------- 结果可视化(示意) -------------------- // 实际开发需实现可视化逻辑,示例: // cv::Mat vis_image = visualize_detections(cv_image, result); // cv::imwrite("vis_result.jpg", vis_image); // -------------------- 模型克隆演示 -------------------- auto cloned_detector = detector->clone(); // 创建独立实例 trtyolo::DetectRes cloned_result = cloned_detector->predict(input_image); // 验证结果一致性 std::cout << cloned_result << std::endl; } catch (const std::exception& e) { std::cerr << "程序异常: " << e.what() << std::endl; return EXIT_FAILURE; } return EXIT_SUCCESS; }
5.推理流程图
以下是predict方法的流程图,展示了从输入图片到输出结果的完整流程:
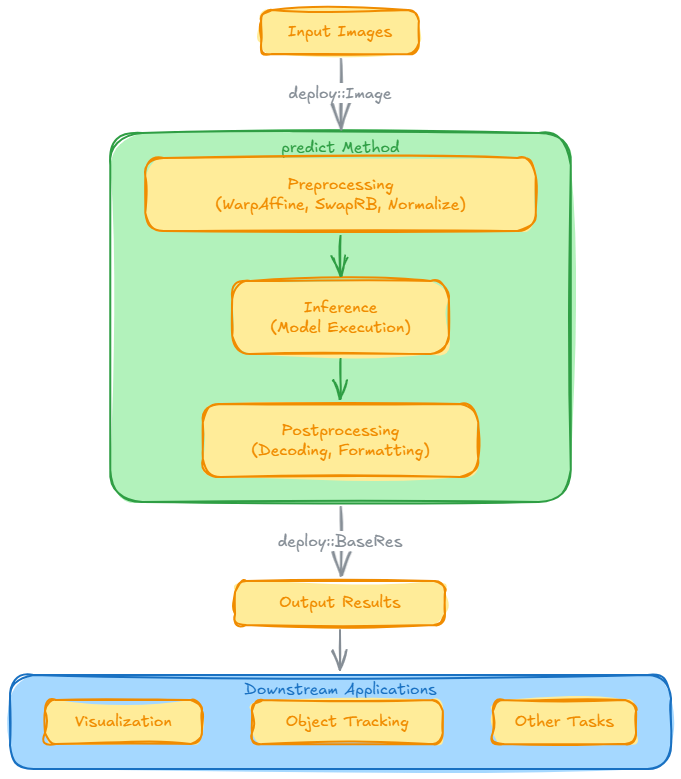
只需将待推理的图片传递给 predict 方法,predict 内部会自动完成预处理、模型推理和后处理,并输出推理结果,这些结果可进一步应用于下游任务(如可视化、目标跟踪等)。
更多部署案例请参考模型部署示例 .
🌟 赞助与支持
开源不易,如果本项目对你有所帮助,欢迎通过赞助支持作者。你的支持是开发者持续维护的最大动力!

🙏 衷心感谢以下支持者与赞助商的无私支持:
[!NOTE]
以下是 GitHub Actions 自动生成的赞助者列表,每日更新 ✨。

📄 许可证
TensorRT-YOLO采用 GPL-3.0许可证,这个OSI 批准的开源许可证非常适合学生和爱好者,可以推动开放的协作和知识分享。请查看LICENSE 文件以了解更多细节。
感谢您选择使用 TensorRT-YOLO,我们鼓励开放的协作和知识分享,同时也希望您遵守开源许可的相关规定。
📞 联系方式
对于 TensorRT-YOLO 的错误报告和功能请求,请访问 GitHub Issues!
给项目点亮 ⭐ Star 可以帮助我们优先关注你的需求,加快响应速度~
🙏 致谢

🌟 Star History

版本历史
v6.4.02025/12/12v6.3.22025/09/25v6.3.12025/09/10v6.3.02025/07/14v6.2.02025/05/30v6.1.02025/04/25v6.0.02025/01/26v5.0.02024/11/21v4.02024/07/05v3.02024/04/23v2.02024/03/23v1.02024/02/28相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。