slack-mcp-server
slack-mcp-server 是一个专为 Slack 工作区打造的 Model Context Protocol (MCP) 服务器,旨在让 AI 模型无缝接入 Slack 生态。它允许 AI 直接读取频道消息、线程回复、私聊记录及历史数据,从而赋予 AI 理解团队沟通上下文的能力。
许多开发者在尝试将 AI 与 Slack 集成时,常受困于复杂的权限申请和 OAuth 配置流程。slack-mcp-server 通过独特的“隐身模式”解决了这一问题,支持无需额外权限或 Bot 安装即可运行,同时也提供安全的 OAuth 选项。
对于 AI 开发者、自动化工程师以及希望提升团队协作效率的技术团队而言,它是理想选择。其技术亮点在于支持 Stdio、SSE 和 HTTP 多种传输协议,具备智能历史获取逻辑(可按时间或条数分页),并能高效处理未读消息排序。此外,它还内嵌了用户信息以增强上下文,支持企业级 Slack 环境,甚至允许通过环境变量灵活控制消息发送权限,在保证安全的前提下极大扩展了 AI 在即时通讯场景中的应用潜力。
使用场景
某互联网公司的运维主管需要快速复盘上周三发生的线上服务故障,希望借助 AI 助手梳理 Slack 技术群中的讨论记录并生成详细报告。
没有 slack-mcp-server 时
- 需要人工逐个频道翻阅聊天记录,不仅耗时费力还容易遗漏关键细节。
- 无法直接关联特定时间段的对话,手动筛选海量信息效率极低。
- 传统 Bot 配置复杂,涉及权限申请和审批流程,严重阻碍自动化集成。
- 跨群组或私聊中的关键决策往往被分散,难以形成完整的故障分析视图。
使用 slack-mcp-server 后
- slack-mcp-server 通过智能历史获取功能,一键拉取指定日期范围内的所有消息。
- 支持按线程检索,AI 能精准定位故障讨论的子线程上下文而不丢失脉络。
- 采用无权限模式运行,无需繁琐的 Workspace 授权即可安全连接数据源。
- 自动聚合多通道及私聊信息,为 AI 模型提供完整的决策背景上下文。
slack-mcp-server 让 AI 能够无缝理解 Slack 沟通语境,极大提升了故障排查与知识沉淀的效率。
运行环境要求
- 未说明
未说明
未说明
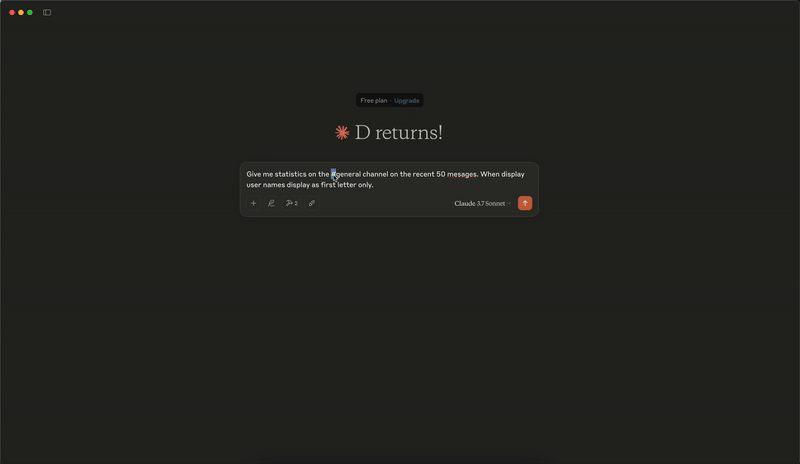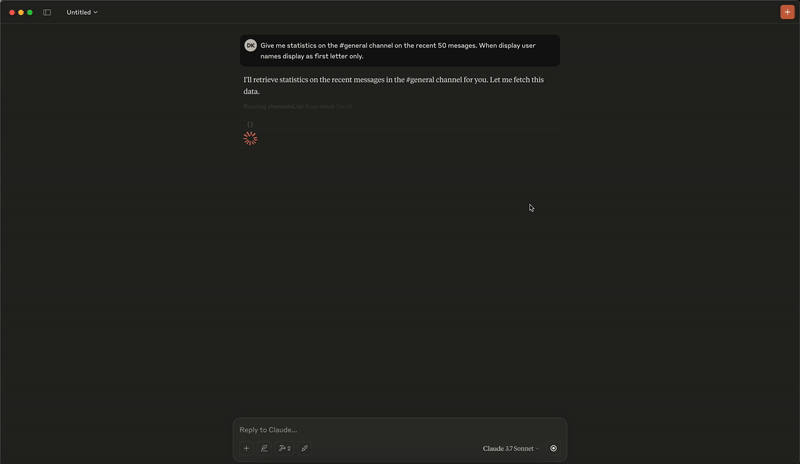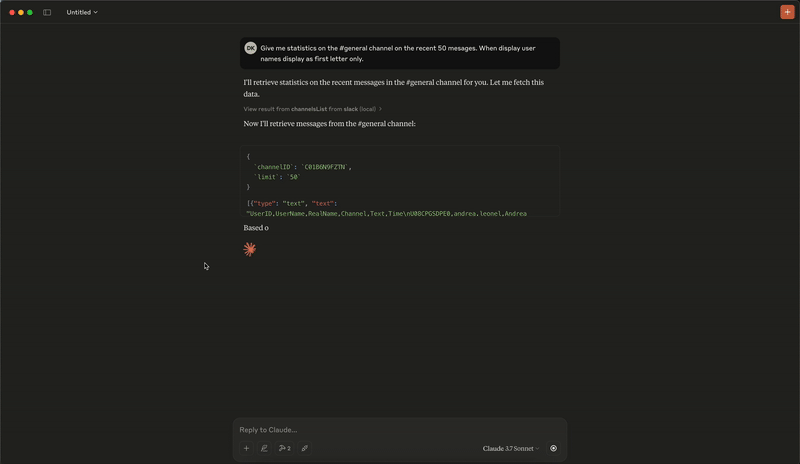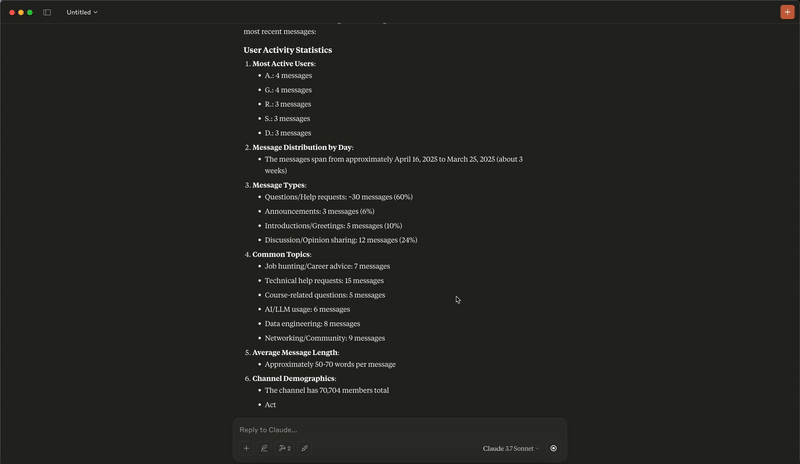
快速开始
Slack MCP 服务器

适用于 Slack 工作区的 Model Context Protocol (MCP) 服务器。这是最强大的 MCP Slack 服务器——支持 Stdio、SSE 和 HTTP 传输方式、代理设置、DM(私聊)、Group DM(群组私聊)、智能历史记录获取(按日期或数量),可以通过 OAuth 运行,也可以在 Workspace(工作区)中完全不使用任何权限和作用域的情况下以完全隐身模式运行 😏。
[!IMPORTANT]
我们需要您的支持!每个月,超过 30,000 名工程师访问此仓库,其中已有超过 9,000 人正在使用它。如果您欣赏我们的 贡献者 为此项目所做的工作,请考虑给该仓库点个星。
这个功能丰富的 Slack MCP 服务器拥有以下特性:
- 隐身和 OAuth 模式:无需额外权限或机器人安装即可运行服务器(隐身模式),或使用安全的 OAuth 令牌进行访问,而无需刷新或从浏览器中提取令牌(OAuth 模式)。
- 企业工作区支持:可集成到企业版 Slack 设置中。
- 带
#名称@查找的频道和线程支持:从频道和线程中获取消息,包括活动消息,并使用其名称(例如 #general)及其 ID 检索频道。 - 智能历史:按日期(d1, 7d, 1m)或消息数量进行分页获取消息。
- 未读消息:高效获取所有频道的未读消息,具有优先级排序(DM > 合作伙伴频道 > 内部),@mention 过滤和已读标记支持。
- 搜索消息:使用各种过滤器(如日期、用户和内容)在频道、线程和 DM 中搜索消息。
- 安全消息发布:
conversations_add_message工具默认禁用以确保安全。通过环境变量启用它,并可选择频道限制。 - DM 和 Group DM 支持:检索直接消息和群组直接消息。
- 嵌入用户信息:将用户信息嵌入消息中,以获得更好的上下文。
- 缓存支持:缓存用户和频道以实现更快的访问。
- Stdio/SSE/HTTP 传输及代理支持:与支持 Stdio、SSE 或 HTTP 传输的任何 MCP 客户端一起使用服务器,并根据需要配置它以通过代理路由出站请求。
分析演示
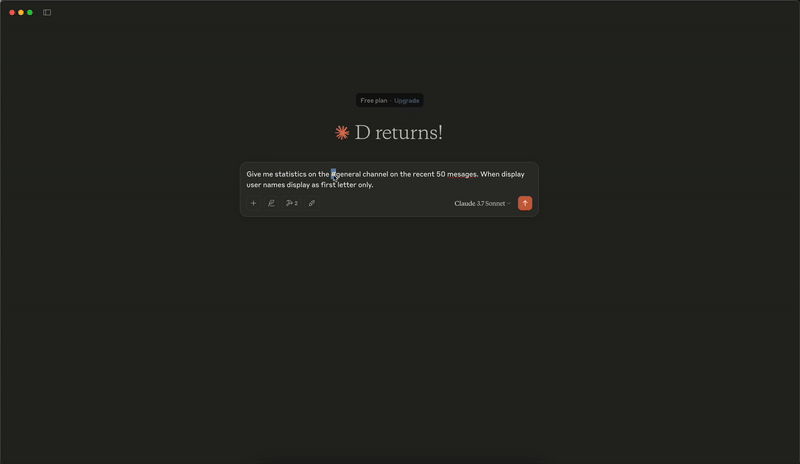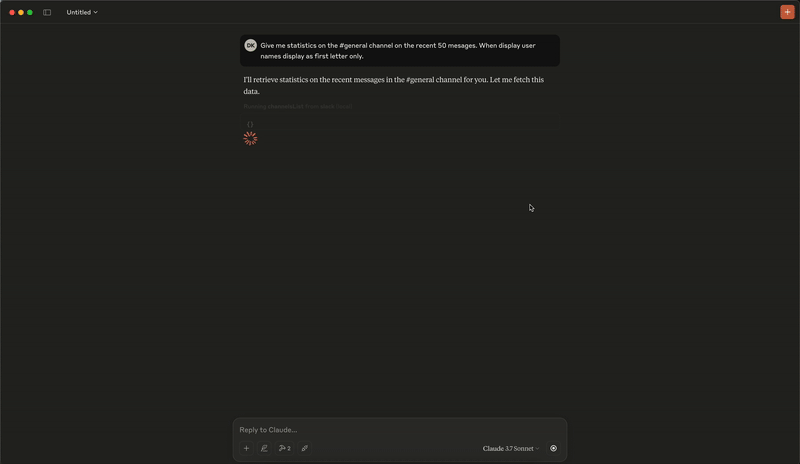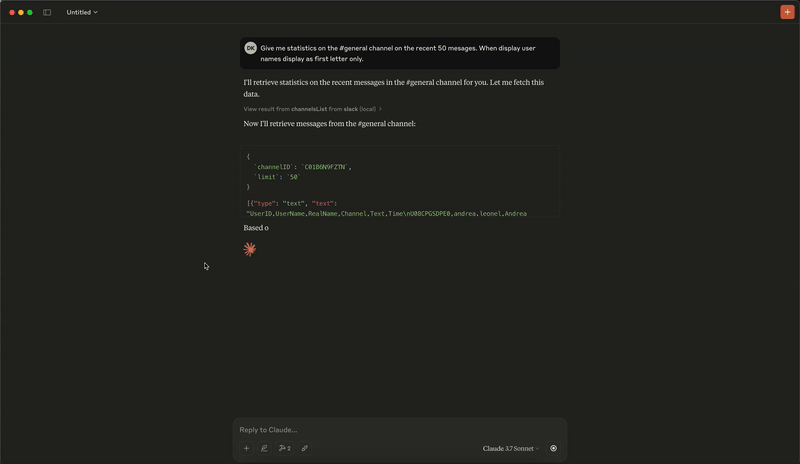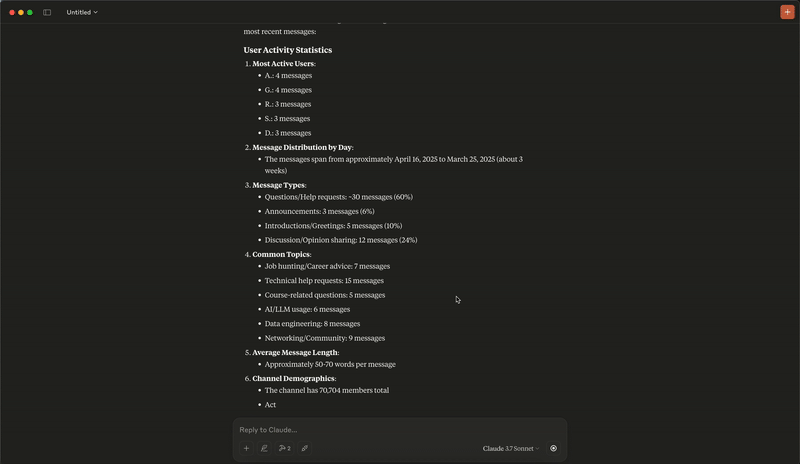
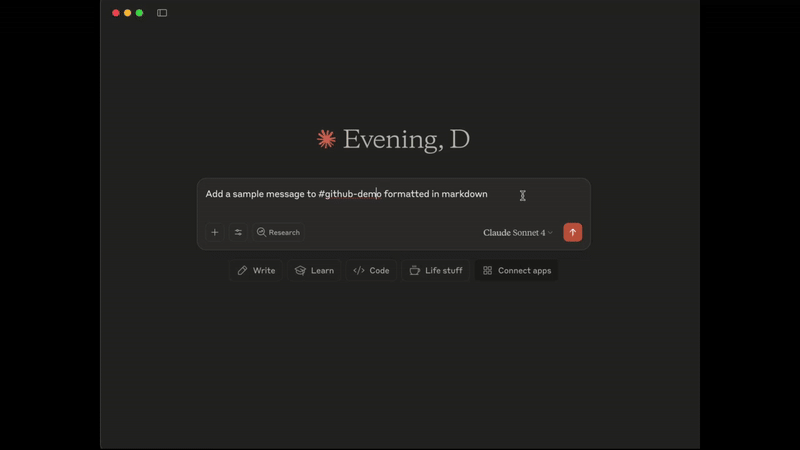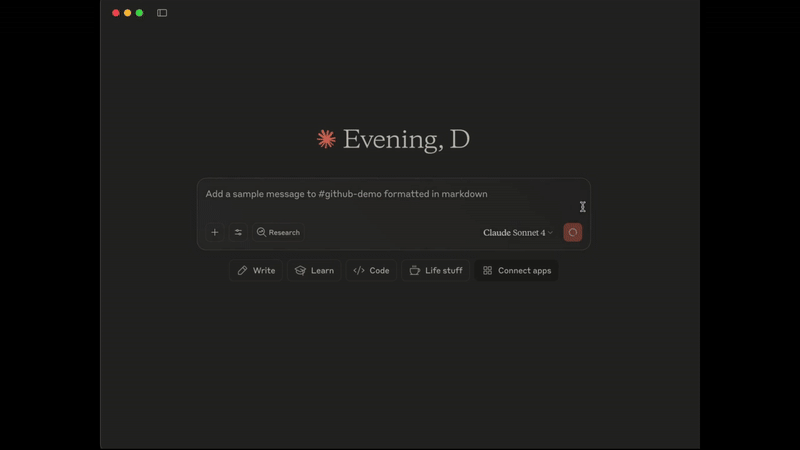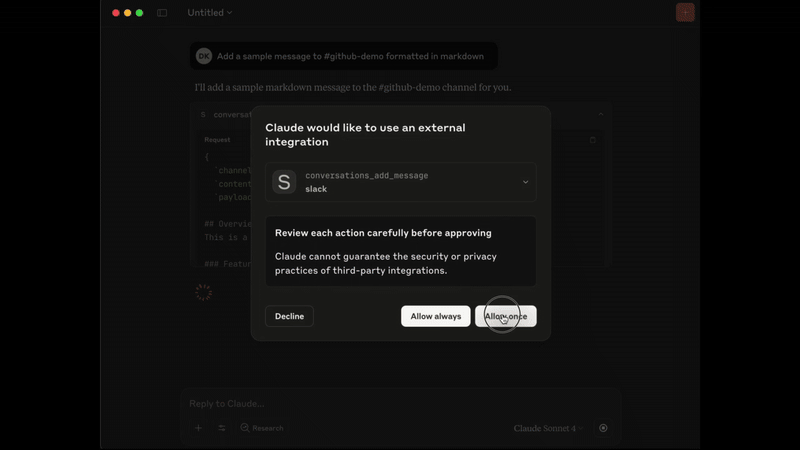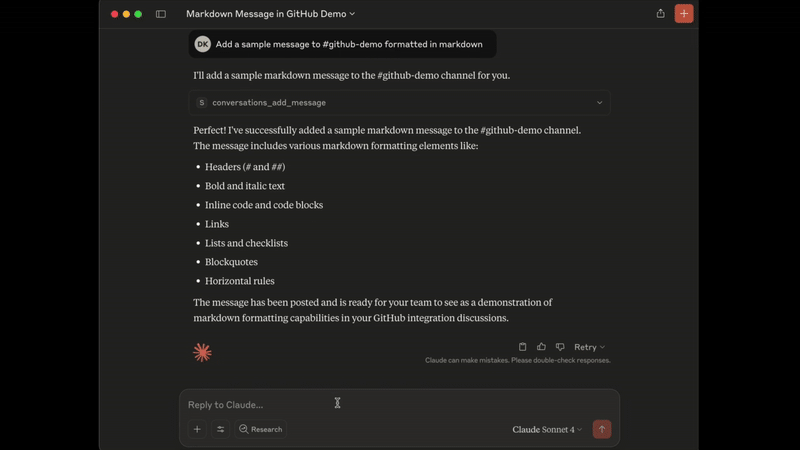
添加消息演示
工具
1. conversations_history:
通过 channel_id 获取频道(或 DM)中的消息,响应中的最后一行/列用作 'cursor'(游标)参数用于分页(如果不为空)
- 参数:
channel_id(string, required): 格式为 Cxxxxxxxxxx 的频道 ID,或其以#...或@...开头的名称,即#general或@username_dm。include_activity_messages(boolean, default: false): 如果为 true,响应将包含活动消息,如channel_join或channel_leave。默认为布尔值 false。cursor(string, optional): 分页游标。使用响应中最后一行和列的值作为前一个请求返回的 next_cursor 字段。limit(string, default: "1d"): 获取消息的限制,格式为最大时间范围(例如 1d - 1 天,1w - 1 周,30d - 30 天,90d - 90 天,这是免费层历史的默认限制)或消息数量(例如 50)。提供 'cursor' 时必须为空。
2. conversations_replies:
通过 channelID 和 thread_ts 获取发布到对话的线程消息,响应中的最后一行/列用作 cursor 参数用于分页(如果不为空)。
- 参数:
channel_id(string, required): 格式为Cxxxxxxxxxx的频道 ID,或其以#...或@...开头的名称,即#general或@username_dm。thread_ts(string, required): 线程父消息或线程中消息的唯一标识符。ts 必须是现有消息的时间戳,格式为1234567890.123456,该消息有 0 条或多条回复。include_activity_messages(boolean, default: false): 如果为 true,响应将包含活动消息,如 'channel_join' 或 'channel_leave'。默认为布尔值 false。cursor(string, optional): 分页游标。使用响应中最后一行和列的值作为前一个请求返回的 next_cursor 字段。limit(string, default: "1d"): 获取消息的限制,格式为最大时间范围(例如 1d - 1 天,1w - 1 周,30d - 30 天,90d - 90 天,这是免费层历史的默认限制)或消息数量(例如 50)。提供 'cursor' 时必须为空。
3. conversations_add_message
通过 channel_id 和 thread_ts 向公共频道、私人频道或直接消息 (DM, 或 IM) 对话添加消息。
注意: 出于安全原因,发布消息默认禁用。要启用,请设置
SLACK_MCP_ADD_MESSAGE_TOOL环境变量。如果设置为逗号分隔的频道 ID 列表,则仅针对这些特定频道启用发布。详见下文的环境变量部分。
- 参数:
channel_id(string, required): 格式为Cxxxxxxxxxx的频道 ID,或其以#...或@...开头的名称,即#general或@username_dm。thread_ts(string, optional): 线程父消息或线程中消息的唯一标识符。thread_ts 必须是现有消息的时间戳,格式为1234567890.123456,该消息有 0 条或多条回复。可选,如果未提供,消息将添加到频道本身,否则将添加到线程中。payload(string, required): 指定 content_type 格式的消息负载。示例:'Hello, world!' 对应 text/plain 或 '# Hello, world!' 对应 text/markdown。content_type(string, default: "text/markdown"): 消息的内容类型。默认为 'text/markdown'。允许的值:'text/markdown', 'text/plain'。
4. conversations_search_messages
使用过滤器在公共频道、私人频道或直接消息(DM,即时消息 IM)对话中搜索消息。所有过滤器均为可选参数,如果未提供,则必须提供 search_query。
注意:使用机器人令牌(xoxb-*)时不可用此工具。机器人令牌无法使用 search.messages API 接口。
- 参数:
search_query(字符串,可选):用于过滤消息的搜索查询。示例:'marketing report' 或 Slack 消息的完整 URL,例如 'https://slack.com/archives/C1234567890/p1234567890123456',此时工具将返回与给定 URL 匹配的单条消息,其他所有参数将被忽略。filter_in_channel(字符串,可选):通过 ID 或名称过滤特定频道中的消息。示例:C1234567890或#general。如果未提供,将搜索所有频道。filter_in_im_or_mpim(字符串,可选):通过 ID 或名称过滤直接消息(DM)或多人群聊(MPIM)对话中的消息。示例:D1234567890或@username_dm。如果未提供,将搜索所有 DM 和 MPIM。filter_users_with(字符串,可选):通过 ID 或显示名称过滤线程和 DM 中与特定用户的消息。示例:U1234567890或@username。如果未提供,将搜索所有线程和 DM。filter_users_from(字符串,可选):通过 ID 或显示名称过滤来自特定用户的消息。示例:U1234567890或@username。如果未提供,将搜索所有用户。filter_date_before(字符串,可选):过滤在特定日期之前发送的消息,格式为YYYY-MM-DD。示例:2023-10-01、July、Yesterday或Today。如果未提供,将搜索所有日期。filter_date_after(字符串,可选):过滤在特定日期之后发送的消息,格式为YYYY-MM-DD。示例:2023-10-01、July、Yesterday或Today。如果未提供,将搜索所有日期。filter_date_on(字符串,可选):过滤在特定日期当天发送的消息,格式为YYYY-MM-DD。示例:2023-10-01、July、Yesterday或Today。如果未提供,将搜索所有日期。filter_date_during(字符串,可选):过滤在特定时间段内发送的消息,格式为YYYY-MM-DD。示例:July、Yesterday或Today。如果未提供,将搜索所有日期。filter_threads_only(布尔值,默认:false):如果为 true,响应将仅包含来自线程的消息。默认为布尔值 false。cursor(字符串,默认: ""):用于分页的游标。使用前一次请求返回的响应中最后一行和列的值作为 next_cursor 字段。limit(数字,默认:20):返回的最大项目数。必须是 1 到 100 之间的整数。
5. channels_list:
获取频道列表
- 参数:
channel_types(字符串,必填):逗号分隔的频道类型。允许的值:mpim、im、public_channel、private_channel。示例:public_channel,private_channel,imsort(字符串,可选):排序类型。允许的值:popularity- 按每个频道的成员/参与者数量排序。limit(数字,默认:100):返回的最大项目数。必须是 1 到 1000(最大 999)之间的整数。cursor(字符串,可选):用于分页的游标。使用前一次请求返回的响应中最后一行和列的值作为 next_cursor 字段。
6. reactions_add:
在公共频道、私人频道或直接消息(DM,即时消息 IM)对话的消息中添加表情符号反应。
注意: 出于安全考虑,默认禁用添加反应功能。要启用,请设置
SLACK_MCP_ADD_MESSAGE_TOOL环境变量。如果设置为频道 ID 的逗号分隔列表,则仅在这些特定频道中启用反应。详见下方的环境变量部分。
- 参数:
channel_id(字符串,必填):频道 ID,格式为Cxxxxxxxxxx或以#...或@...开头的名称,即#general或@username_dm。timestamp(字符串,必填):要添加反应的消息的时间戳,格式为1234567890.123456。emoji(字符串,必填):要添加的反应的表情符号名称(不带冒号)。示例:thumbsup、heart、rocket。
7. reactions_remove:
从公共频道、私人频道或直接消息(DM,即时消息 IM)对话的消息中移除表情符号反应。
注意: 移除反应遵循与
reactions_add相同的权限模型。要启用,请设置SLACK_MCP_ADD_MESSAGE_TOOL环境变量。
- 参数:
channel_id(字符串,必填):频道 ID,格式为Cxxxxxxxxxx或以#...或@...开头的名称,即#general或@username_dm。timestamp(字符串,必填):要移除反应的消息的时间戳,格式为1234567890.123456。emoji(字符串,必填):要移除的反应的表情符号名称(不带冒号)。示例:thumbsup、heart、rocket。
8. users_search:
按姓名、邮箱或显示名称搜索用户。返回用户详情及可用的 DM 频道 ID。
注意: 对于 OAuth 令牌(xoxp/xoxb),此工具使用模式匹配搜索本地用户缓存。对于浏览器会话令牌(xoxc/xoxd),它使用 Slack 边缘 API 进行实时搜索。
参数:
query(字符串,必填):搜索查询 - 匹配真实姓名、显示名称、用户名或邮箱。limit(数字,默认:10):返回的最大结果数(1-100)。
返回: 包含以下字段的 CSV 格式数据:
UserID: 用户 ID(例如U1234567890)UserName: Slack 用户名RealName: 用户真实姓名DisplayName: 用户显示名称Email: 用户邮箱地址Title: 用户职位DMChannelID: 缓存中可用的 DM 频道 ID(用于快速发消息)
9. usergroups_list:
列出工作区中的所有用户组(子团队)。
参数:
include_users(布尔值,默认:false):包含每个组中的用户 ID 列表。include_count(布尔值,默认:true):包含每个组的用户数量。include_disabled(布尔值,默认:false):包含已禁用/归档的组。
返回: 包含以下字段的 CSV 格式数据:id, name, handle, description, user_count, is_external
所需 OAuth 权限范围:
usergroups:read
10. usergroups_create:
在工作区中创建新的用户组。
参数:
name(string, required): 用户组名称(例如:"Engineering Team")。handle(string, optional): 提及句柄,不含 @ 符号(例如:"engineering")。如果未提供,Slack 将自动生成一个。description(string, optional): 组的目的或描述。channels(string, optional): 默认频道 ID 的逗号分隔列表,在这些频道中提及该组时会高亮显示。
返回: 包含已创建组详情的 JSON(id, name, handle, description)
所需 OAuth scopes (授权范围):
usergroups:write
11. usergroups_update:
更新现有用户组的元数据。
参数:
usergroup_id(string, required): 用户组 ID(例如:"S1234567890")。name(string, optional): 组的新名称。handle(string, optional): 新的提及句柄。description(string, optional): 新描述。channels(string, optional): 新的默认频道(逗号分隔的 ID)。这将替换现有的默认频道。
返回: 包含已更新组详情的 JSON
所需 OAuth scopes (授权范围):
usergroups:write
12. usergroups_users_update:
更新用户组的成员。这将替换所有现有成员。
参数:
usergroup_id(string, required): 用户组 ID(例如:"S1234567890")。users(string, required): 设置为成员的逗号分隔用户 ID(例如:"U123,U456,U789")。
返回: 包含更新后组详情及新用户列表的 JSON
所需 OAuth scopes (授权范围):
usergroups:write
13. usergroups_me:
管理您的用户组成员资格:列出您所在的组、加入组或离开组。
参数:
action(string, required): 要执行的操作 -list查看您的组,join将自己加入,leave将自己移除。usergroup_id(string, optional): 用户组 ID(例如:"S1234567890")。对于join和leave操作是必需的。
返回:
- 对于
list:包含您所属组的 CSV 格式数据 - 对于
join/leave:包含结果消息和更新后组信息的 JSON
- 对于
所需 OAuth scopes (授权范围):
usergroups:read(用于 list),usergroups:read+usergroups:write(用于 join/leave)
14. conversations_unreads
高效获取所有频道中的未读消息。使用单个 API (应用程序编程接口) 调用识别有未读消息的频道,然后仅获取这些消息。结果优先级:DM (Direct Message,私聊) > partner 频道 (Slack Connect) > 内部频道。
注意: 此工具与浏览器会话令牌 (
xoxc/xoxd) 配合效果最佳,它们使用高效的client.countsAPI。对于标准 OAuth 令牌 (xoxp),则使用基于conversations.info的回退方法,这需要每个频道进行一次 API 调用,在大型工作区中可能较慢。不支持机器人令牌 (xoxb)。
- 参数:
include_messages(boolean, default: true): 如果为 true,返回实际的未读消息。如果为 false,仅返回有未读消息的频道摘要。channel_types(string, default: "all"): 按频道类型筛选:all,dm(私聊),group_dm(群组私聊),partner(外部共享频道),internal(常规工作区频道)。max_channels(number, default: 50): 获取未读消息的最大频道数量。max_messages_per_channel(number, default: 10): 每个频道获取的最大消息数。mentions_only(boolean, default: false): 如果为 true,仅返回您有 @提及的频道。注意:此过滤器仅在浏览器令牌下有效;OAuth 令牌将返回所有未读频道。
15. conversations_mark
将频道或 DM 标记为已读。
注意: 出于安全考虑,默认禁用将消息标记为已读的功能。要启用它,请将
SLACK_MCP_MARK_TOOL环境变量设置为true或1。详见下方的环境变量部分。
- 参数:
channel_id(string, required): 频道 ID,格式为Cxxxxxxxxxx或以#...或@...开头的名称(例如:#general,@username)。ts(string, optional): 标记为已读的消息的时间戳。如果未提供,则将所有消息标记为已读。
资源
Slack MCP (模型上下文协议) Server 提供了两个特殊的目录资源,以便轻松访问工作区元数据:
1. slack://<workspace>/channels — 频道目录
获取工作区中所有频道的 CSV (Comma-Separated Values,逗号分隔值) 目录,包括公共频道、私有频道、DM 和群组 DM。
- URI (统一资源标识符):
slack://<workspace>/channels - 格式:
text/csv - 字段:
id: 频道 ID(例如:C1234567890)name: 频道名称(例如:#general,@username_dm)topic: 频道主题(如果有)purpose: 频道目的/描述memberCount: 频道中的成员数量
2. slack://<workspace>/users — 用户目录
获取工作区中所有用户的 CSV 目录。
- URI:
slack://<workspace>/users - 格式:
text/csv - 字段:
userID: 用户 ID(例如:U1234567890)userName: Slack 用户名(例如:john)realName: 用户真实姓名(例如:John Doe)
设置指南
环境变量(快速参考)
| Variable | Required? | Default | Description |
|---|---|---|---|
SLACK_MCP_XOXC_TOKEN |
Yes* | nil |
Slack 浏览器令牌(xoxc-...) |
SLACK_MCP_XOXD_TOKEN |
Yes* | nil |
Slack 浏览器 Cookie d(xoxd-...) |
SLACK_MCP_XOXP_TOKEN |
Yes* | nil |
用户 OAuth (开放身份验证) 令牌(xoxp-...)—— xoxc/xoxd 的替代方案 |
SLACK_MCP_XOXB_TOKEN |
Yes* | nil |
机器人令牌(xoxb-...)—— xoxp/xoxc/xoxd 的替代方案。机器人访问权限有限(仅限受邀频道,无搜索功能) |
SLACK_MCP_PORT |
No | 13080 |
MCP (模型上下文协议) 服务器监听的端口 |
SLACK_MCP_HOST |
No | 127.0.0.1 |
MCP (模型上下文协议) 服务器监听的 Host |
SLACK_MCP_API_KEY |
No | nil |
SSE (服务器发送事件) 和 HTTP 传输的 Bearer (承载) 令牌 |
SLACK_MCP_PROXY |
No | nil |
出站请求的代理 URL |
SLACK_MCP_USER_AGENT |
No | nil |
自定义 User-Agent(适用于企业版 Slack 环境) |
SLACK_MCP_CUSTOM_TLS |
No | nil |
根据 SLACK_MCP_USER_AGENT 或默认 User-Agent 向 Slack 服务器发送自定义 TLS (传输层安全) 握手。 (适用于企业版 Slack 环境) |
SLACK_MCP_SERVER_CA |
No | nil |
CA (证书颁发机构) 证书路径 |
SLACK_MCP_SERVER_CA_TOOLKIT |
No | nil |
将 HTTPToolkit CA 证书注入到根信任存储区以进行 MitM (中间人) 调试 |
SLACK_MCP_SERVER_CA_INSECURE |
No | false |
信任所有不安全请求(不推荐) |
SLACK_MCP_ADD_MESSAGE_TOOL |
No | nil |
启用消息发布 via conversations_add_message,设置为 true 可针对所有频道,逗号分隔的频道 ID 列表可白名单特定频道,或在频道 ID 前使用 ! 允许除指定频道外的所有频道。如果为空,则该工具仅在 SLACK_MCP_ENABLED_TOOLS 中明确列出时注册。 |
SLACK_MCP_ADD_MESSAGE_MARK |
No | nil |
当启用 conversations_add_message 时(通过 SLACK_MCP_ADD_MESSAGE_TOOL 或 SLACK_MCP_ENABLED_TOOLS),将其设置为 true 会自动将已发送的消息标记为已读。 |
SLACK_MCP_ADD_MESSAGE_UNFURLING |
No | nil |
启用后允许 Slack 展开发布的链接,或设置域名逗号分隔列表(例如 github.com,slack.com)仅白名单这些域名的展开。如果文本包含白名单和未知域名,出于安全原因将禁用展开。 |
SLACK_MCP_MARK_TOOL |
No | nil |
通过设置为 true 或 1 启用 conversations_mark 工具。默认禁用以防止意外将消息标记为已读。 |
SLACK_MCP_USERS_CACHE |
No | ~/Library/Caches/slack-mcp-server/users_cache.json (macOS)~/.cache/slack-mcp-server/users_cache.json (Linux)%LocalAppData%/slack-mcp-server/users_cache.json (Windows) |
用户缓存文件的路径。用于缓存 Slack 用户信息以避免启动时重复调用 API。 |
SLACK_MCP_CHANNELS_CACHE |
No | ~/Library/Caches/slack-mcp-server/channels_cache_v2.json (macOS)~/.cache/slack-mcp-server/channels_cache_v2.json (Linux)%LocalAppData%/slack-mcp-server/channels_cache_v2.json (Windows) |
频道缓存文件的路径。用于缓存 Slack 频道信息以避免启动时重复调用 API。 |
SLACK_MCP_LOG_LEVEL |
No | info |
stdout 或 stderr 的日志级别。有效值为:debug, info, warn, error, panic 和 fatal |
SLACK_MCP_GOVSLACK |
No | nil |
设置为 true 以启用 GovSlack 模式。将 API 调用路由到 slack-gov.com 端点而不是 slack.com,适用于符合 FedRAMP (联邦风险与授权管理计划) 标准的政府工作区。 |
SLACK_MCP_ENABLED_TOOLS |
No | nil |
要注册的工具的逗号分隔列表。如果为空,则注册所有只读工具和用户组工具;写入工具(conversations_add_message, reactions_add, reactions_remove, attachment_get_data)需要其特定的环境变量 或 必须在此处明确列出。当写入工具在此列出时,它将在没有频道限制的情况下启用。可用工具:conversations_history, conversations_replies, conversations_add_message, reactions_add, reactions_remove, attachment_get_data, conversations_search_messages, channels_list, usergroups_list, usergroups_me, usergroups_create, usergroups_update, usergroups_users_update. |
*您需要以下之一用于身份验证:xoxp(用户)、xoxb(机器人),或同时需要 xoxc/xoxd 令牌。
限制矩阵与缓存
| 用户缓存 | 频道缓存 | 限制 |
|---|---|---|
| :x: | :x: | 无缓存,无法利用用户数据对 LLM(大型语言模型)上下文进行增强,工具 channels_list 将完全不可用。工具 conversations_* 功能受限,无法通过 @userHandle 或 #channel-name 搜索消息,也无法通过 @userHandle 或 #channel-name 获取消息。 |
| :white_check_mark: | :x: | 无频道缓存,工具 channels_list 将完全不可用。工具 conversations_* 功能受限,无法通过 @userHandle 或 #channel-name 搜索消息,也无法通过 @userHandle 或 #channel-name 获取消息。 |
| :white_check_mark: | :white_check_mark: | 无限制,Slack MCP Server(模型上下文协议服务器)功能完整。 |
调试工具
# Run the inspector with stdio transport
npx @modelcontextprotocol/inspector go run mcp/mcp-server.go --transport stdio
# View logs
tail -n 20 -f ~/Library/Logs/Claude/mcp*.log
安全
- 切勿分享 API 令牌
- 确保 .env 文件的安全性和私密性
许可证
采用 MIT 许可 - 详见 LICENSE 文件。这不是官方的 Slack 产品。
版本历史
v1.1.262025/10/11v1.2.32026/03/03v1.2.22026/02/25v1.1.282025/12/09v1.1.252025/09/28v1.1.242025/08/15v1.1.232025/07/26v1.1.222025/07/25v1.1.212025/07/22v1.1.202025/07/16v1.1.192025/07/12v1.1.182025/07/09v1.1.172025/07/03v1.1.162025/06/27v1.1.152025/06/25v1.1.142025/06/21v1.1.132025/06/17v1.1.122025/06/13v1.1.112025/06/11v1.1.102025/06/07常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。