ComfyUI-WanVideoWrapper
ComfyUI-WanVideoWrapper 是专为 ComfyUI 设计的扩展节点包,旨在支持 WanVideo(如 Wan2.1)及相关模型的运行与实验。它主要解决了原生 ComfyUI 对新模型或特定功能(如 ATI 节点)支持滞后或实现复杂的问题,让开发者能快速在独立环境中测试和集成最新技术,而无需等待核心代码更新。
该工具特别适合具备一定技术背景的开发者、研究人员及高级 AI 爱好者使用。作为作者的“个人沙盒”,它允许用户灵活探索新发布的视频生成模型,同时也提供了补丁节点,方便将这些实验性功能融入原生工作流。
在技术亮点方面,ComfyUI-WanVideoWrapper 近期重点优化了显存(VRAM)管理。通过减少了对 torch.compile 的依赖,提升了运行稳定性;同时改进了未合并 LoRA 权重的处理机制,将其作为模块缓冲区的一部分,从而支持更高效的块交换(block swap)和异步卸载功能。虽然这可能在特定配置下增加显存占用,但通过调整交换块数量即可有效平衡。此外,作者还提供了清理 Triton 缓存的指南,以解决 Windows 环境下因编译缓存导致的显存异常问题。这是一个持续迭代中的开源项目,适合希望紧跟前沿模型动态的用户尝试。
使用场景
一位独立动画开发者试图在单张 12GB 显存的显卡上,利用最新的 Wan2.1 模型生成带有特定角色风格(LoRA)的高清短视频。
没有 ComfyUI-WanVideoWrapper 时
- 显存瞬间爆满:加载未合并的 LoRA 权重时,模型强制占用大量 VRAM,导致生成任务直接因内存不足(OOM)而崩溃。
- 编译加速失效:由于 LoRA 加载机制导致计算图断裂,无法启用
torch.compile加速,视频生成速度极慢。 - 显存管理僵化:缺乏灵活的块交换(Block Swap)机制,无法通过调整交换块数量来平衡显存占用与生成速度。
- 环境调试困难:在 Windows 环境下,旧的 Triton 缓存常导致首次运行显存异常激增,排查和清理过程繁琐且容易出错。
使用 ComfyUI-WanVideoWrapper 后
- 显存高效利用:LoRA 权重被智能分配为模块缓冲区并融入块交换逻辑,显著降低基础显存占用,使 12GB 显卡也能流畅运行大模型。
- 无缝加速支持:修复了计算图断裂问题,完美兼容
torch.compile,大幅缩短视频渲染等待时间。 - 灵活的资源调配:用户可根据 LoRA 大小动态增加交换块数量(如多换 2 个块),精准补偿显存增量,实现性能与容量的最佳平衡。
- 稳定的运行体验:内置针对 Windows 平台的显存优化策略,有效规避了因缓存导致的初次运行显存激增问题,工作流更加稳定可靠。
ComfyUI-WanVideoWrapper 通过重构显存管理机制,让消费级显卡也能低成本、高效率地驾驭先进的 WanVideo 视频生成模型。
运行环境要求
- Windows
- Linux
- macOS
- 必需 NVIDIA GPU
- 显存需求取决于模型大小和是否启用块交换(Block Swap):1.3B 模型在特定配置下可低于 5GB
- 14B 模型配合 LoRA 使用时,若未启用块交换需显著增加显存(示例中提及增加 500MB+),建议大显存显卡(如 RTX 3090/4090 或更高)
- 支持 torch.compile 优化但非强制
未说明(建议充足以加载未合并的 LoRA 权重,具体取决于模型规模)
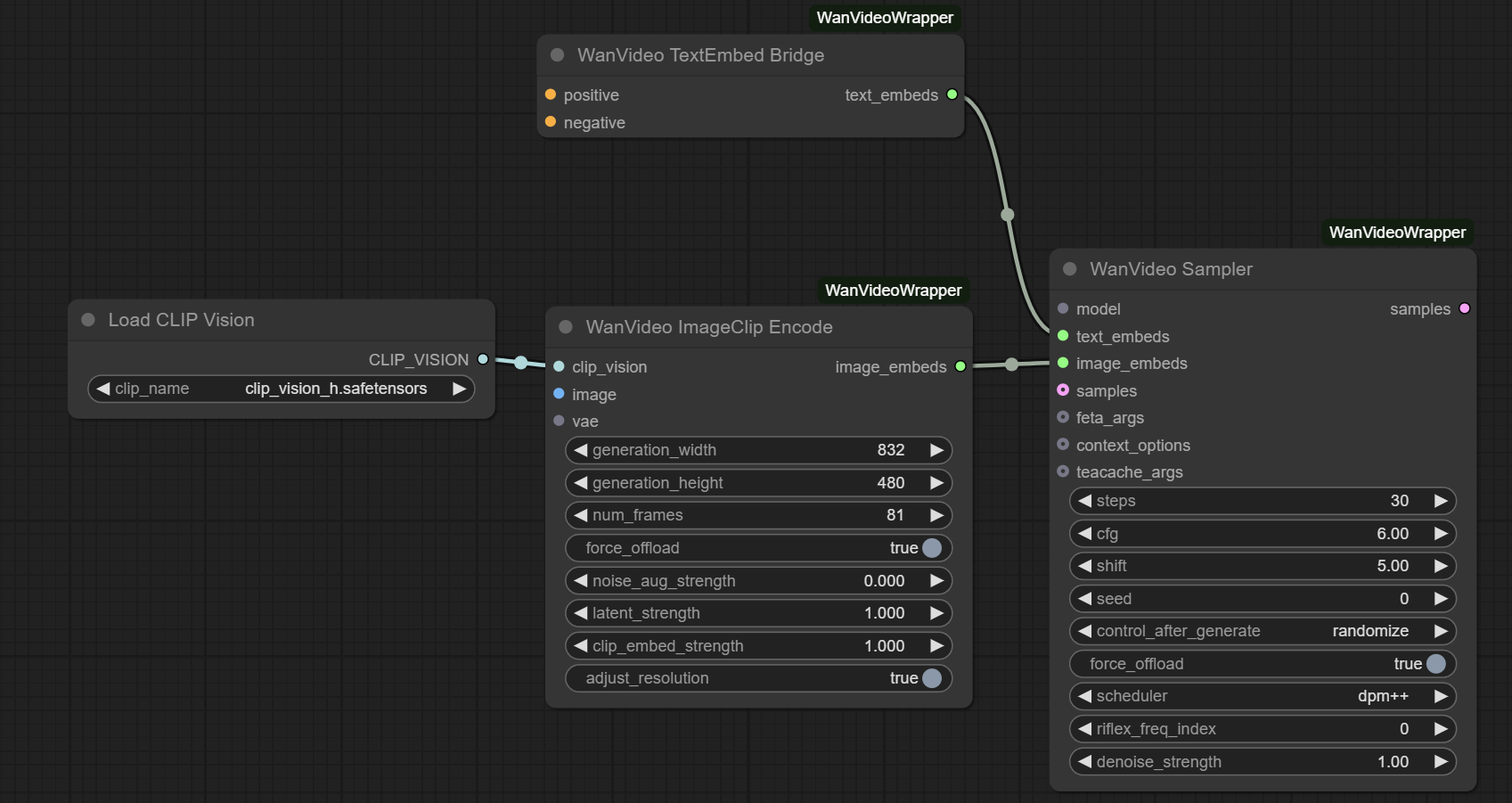
快速开始
适用于 WanVideo 及相关模型的 ComfyUI 封装节点。
内存使用更新(再次)
为了提升显存效率,我已尽量减少对 torch.compile 的依赖,因此即使不使用它,系统也能更好地运行。此外,我还找到了一些绕过方法来解决在启用编译时首次运行会大幅增加显存占用的问题——这个问题曾经让我困扰不已。
可能影响旧工作流内存使用的更新通知
在最近的一次更新中,我对未合并 LoRA 权重的处理方式进行了调整:
此前由于我的疏忽,这些权重在每次使用时都会从 RAM 加载到显存中,这不仅效率低下,还使得在应用 LoRA 时难以使用 torch.compile,从而导致在使用未合并 LoRA 时必须中断计算图。
现在,LoRA 权重会被作为缓冲区分配给对应的模块,这样它们就成为模型块的一部分,并遵循块交换机制,统一了卸载逻辑,使 LoRA 权重也能受益于异步卸载的预取功能。不过,这也意味着如果你没有启用块交换功能,显存占用将会增加,因为 LoRA 权重会与模型其他部分一同驻留在显存中。
如果你启用了块交换功能,LoRA 权重会随其他模型块一起被交换出显存,但此时每个块的大小会变大,因此你可能需要多交换几个块来弥补这一变化。
举例说明:假设你使用了一个 1GB 的未合并 LoRA,在一个 14B 参数量的模型上交换 20 个块。我们可以将 LoRA 的大小除以块的数量,单个块的大小会增加 25MB,20 个块则总共增加 500MB,因此你的显存占用会比之前多出 500MB。为了补偿这一点,你可以再额外交换 2 个块。
与 torch.compile 相关的另一项显存问题
每当对模型代码进行修改并启用 torch.compile 后,常常会出现显存方面的问题。这可能是由于你使用的 PyTorch 或 Triton 版本较旧,缺少最新的编译修复补丁,也可能是旧的 Triton 缓存所致,这种情况在 Windows 系统中尤为常见。其表现形式是:当输入尺寸发生变化时,首次运行可能会导致显存占用大幅增加,而再次运行后问题通常就会消失,且一旦缓存建立,后续便不会再出现类似情况。值得注意的是,我只在 Windows 系统中遇到过此类问题。
要清除 Triton 缓存,你可以删除以下默认路径下的文件夹内容:
C:\Users\<用户名>\.triton
C:\Users\<用户名>\AppData\Local\Temp\torchinductor_<用户名>
注意:由于大量机器人或误以为这是视频生成服务的人频繁发帖,目前我已禁止新账号提交问题。
正在持续开发中(长期进行)
既然 WanVideo 已经原生支持,为什么还要使用自定义节点呢?
简短回答:除非某些模型或功能尚未在原生版本中提供,否则没有必要使用自定义节点。
详细回答:由于 ComfyUI 核心代码较为复杂,加之我个人编程经验有限,在许多情况下,将新模型和功能直接实现为独立的封装节点反而更加简单快捷。因此,这种方式可以让我快速测试各种功能。我将此项目视为自己的实验环境(当然也对所有人开放),无需担心兼容性等问题。不过,这也意味着这段代码始终处于开发状态,难免会出现各种问题。另外,并非所有新模型都值得将其整合到 ComfyUI 核心中,尽管我也开发了一些适配节点,以便在原生工作流中使用它们,例如本封装中提供的 ATI 节点。我们的目标并不是与原生功能竞争,甚至也不是为了提供所有功能的替代方案。综上所述(显然这不是推销话术),我非常感谢大家使用这些节点来探索 WanVideo 的最新发布内容及更多可能性。
安装步骤
- 将本仓库克隆到
custom_nodes文件夹中。 - 安装依赖:
pip install -r requirements.txt或者,如果你使用的是便携式安装包,请在ComfyUI_windows_portable文件夹下执行以下命令:
python_embeded\python.exe -m pip install -r ComfyUI\custom_nodes\ComfyUI-WanVideoWrapper\requirements.txt
模型
https://huggingface.co/Kijai/WanVideo_comfy/tree/main
fp8 缩放模型(个人推荐):
https://huggingface.co/Kijai/WanVideo_comfy_fp8_scaled
文本编码器放置于 ComfyUI/models/text_encoders
CLIP 视觉模型放置于 ComfyUI/models/clip_vision
Transformer(主视频模型)放置于 ComfyUI/models/diffusion_models
VAE 放置于 ComfyUI/models/vae
你也可以使用原生的 ComfyUI 文本编码和 CLIP 视觉加载器,并配合封装器来替代原始模型:
GGUF 模型现在也可以在主模型加载器中加载。
支持的额外模型:
SkyReels:https://huggingface.co/collections/Skywork/skyreels-v2-6801b1b93df627d441d0d0d9
WanVideoFun:https://huggingface.co/collections/alibaba-pai/wan21-fun-v11-680f514c89fe7b4df9d44f17
ReCamMaster:https://github.com/KwaiVGI/ReCamMaster
VACE:https://github.com/ali-vilab/VACE
Phantom:https://huggingface.co/bytedance-research/Phantom
ATI:https://huggingface.co/bytedance-research/ATI
Uni3C:https://github.com/alibaba-damo-academy/Uni3C
MiniMaxRemover:https://huggingface.co/zibojia/minimax-remover
MAGREF:https://huggingface.co/MAGREF-Video/MAGREF
FantasyTalking:https://github.com/Fantasy-AMAP/fantasy-talking
FantasyPortrait:https://github.com/Fantasy-AMAP/fantasy-portrait
MultiTalk:https://github.com/MeiGen-AI/MultiTalk
EchoShot:https://github.com/D2I-ai/EchoShot
Stand-In:https://github.com/WeChatCV/Stand-In
HuMo:https://github.com/Phantom-video/HuMo
WanAnimate:https://github.com/Wan-Video/Wan2.2/tree/main/wan/modules/animate
Lynx:https://github.com/bytedance/lynx
MoCha:https://github.com/Orange-3DV-Team/MoCha
UniLumos:https://github.com/alibaba-damo-academy/Lumos-Custom
Bindweave:https://github.com/bytedance/BindWeave
无需训练的技术:
TimeToMove:https://github.com/time-to-move/TTM
SteadyDancer:https://github.com/MCG-NJU/SteadyDancer
One-to-all-Animation:https://github.com/ssj9596/One-to-All-Animation
SCAIL:https://github.com/zai-org/SCAIL
虽然不完全是 Wan 模型,但足够接近,可以与现有代码库配合使用:
LongCat-Video:https://meituan-longcat.github.io/LongCat-Video/
示例:
WanAnimate:
https://github.com/user-attachments/assets/f370b001-0f98-4c4c-bcb5-cfad0b330697
https://github.com/user-attachments/assets/c58a12c2-13ba-4af8-8041-e283dbef197e
TeaCache(使用旧版临时 WIP 简易版本 I2V):
请注意,新版本的阈值应提高 10 倍。
使用系数时,0.25–0.30 的范围效果较好,起始步数可设为 0;若采用更激进的阈值,则建议稍晚开始,以避免早期可能出现的跳步现象,因为这通常会破坏动作流畅性。
https://github.com/user-attachments/assets/504a9a50-3337-43d2-97b8-8e1661f29f46
上下文窗口测试:
使用 81 帧的窗口大小,重叠 16 帧,处理 1025 帧。借助 13 亿参数的 T2V 模型,该任务在 5090 显卡上仅占用不到 5GB 显存,生成耗时约 10 分钟:
https://github.com/user-attachments/assets/89b393af-cf1b-49ae-aa29-23e57f65911e
首次测试分辨率为 512×512×81。
使用 20/40 块卸载时,约占用 16GB 显存。
https://github.com/user-attachments/assets/fa6d0a4f-4a4d-4de5-84a4-877cc37b715f
Vid2vid 示例:
使用 140 亿参数的 T2V 模型:
https://github.com/user-attachments/assets/ef228b8a-a13a-4327-8a1b-1eb343cf00d8
使用 13 亿参数的 T2V 模型:
https://github.com/user-attachments/assets/4f35ba84-da7a-4d5b-97ee-9641296f391e
常见问题
相似工具推荐
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
OpenHands
OpenHands 是一个专注于 AI 驱动开发的开源平台,旨在让智能体(Agent)像人类开发者一样理解、编写和调试代码。它解决了传统编程中重复性劳动多、环境配置复杂以及人机协作效率低等痛点,通过自动化流程显著提升开发速度。 无论是希望提升编码效率的软件工程师、探索智能体技术的研究人员,还是需要快速原型验证的技术团队,都能从中受益。OpenHands 提供了灵活多样的使用方式:既可以通过命令行(CLI)或本地图形界面在个人电脑上轻松上手,体验类似 Devin 的流畅交互;也能利用其强大的 Python SDK 自定义智能体逻辑,甚至在云端大规模部署上千个智能体并行工作。 其核心技术亮点在于模块化的软件智能体 SDK,这不仅构成了平台的引擎,还支持高度可组合的开发模式。此外,OpenHands 在 SWE-bench 基准测试中取得了 77.6% 的优异成绩,证明了其解决真实世界软件工程问题的能力。平台还具备完善的企业级功能,支持与 Slack、Jira 等工具集成,并提供细粒度的权限管理,适合从个人开发者到大型企业的各类用户场景。
gstack
gstack 是 Y Combinator CEO Garry Tan 亲自开源的一套 AI 工程化配置,旨在将 Claude Code 升级为你的虚拟工程团队。面对单人开发难以兼顾产品战略、架构设计、代码审查及质量测试的挑战,gstack 提供了一套标准化解决方案,帮助开发者实现堪比二十人团队的高效产出。 这套配置特别适合希望提升交付效率的创始人、技术负责人,以及初次尝试 Claude Code 的开发者。gstack 的核心亮点在于内置了 15 个具有明确职责的 AI 角色工具,涵盖 CEO、设计师、工程经理、QA 等职能。用户只需通过简单的斜杠命令(如 `/review` 进行代码审查、`/qa` 执行测试、`/plan-ceo-review` 规划功能),即可自动化处理从需求分析到部署上线的全链路任务。 所有操作基于 Markdown 和斜杠命令,无需复杂配置,完全免费且遵循 MIT 协议。gstack 不仅是一套工具集,更是一种现代化的软件工厂实践,让单人开发者也能拥有严谨的工程流程。
gpt4free
gpt4free 是一个由社区驱动的开源项目,旨在聚合多种可访问的大型语言模型(LLM)和媒体生成接口,让用户能更灵活、便捷地使用前沿 AI 能力。它解决了直接调用各类模型时面临的接口分散、门槛高或成本昂贵等痛点,通过统一的标准将不同提供商的资源整合在一起。 无论是希望快速集成 AI 功能的开发者、需要多模型对比测试的研究人员,还是想免费体验最新技术的普通用户,都能从中受益。gpt4free 提供了丰富的使用方式:既包含易于上手的 Python 和 JavaScript 客户端库,也支持部署本地图形界面(GUI),更提供了兼容 OpenAI 标准的 REST API,方便无缝替换现有应用后端。 其技术亮点在于强大的多提供商支持架构,能够动态调度包括 Opus、Gemini、DeepSeek 等多种主流模型资源,并支持 Docker 一键部署及本地推理。项目秉持社区优先原则,在降低使用门槛的同时,也为贡献者提供了扩展新接口的便利框架,是探索和利用多样化 AI 资源的实用工具。