ComfyUI-Hunyuan3DWrapper
ComfyUI-Hunyuan3DWrapper 是腾讯混元 3D-2(Hunyuan3D-2)模型在 ComfyUI 平台上的专用集成插件。它让用户能够直接在熟悉的节点式工作流中,利用强大的混元 3D-2 算法,将文本或图像提示快速转化为高质量的 3D 资产,并支持后续的纹理生成与网格优化。
该工具主要解决了前沿 3D 生成大模型部署门槛高、难以与现有创作流程融合的问题。通过封装复杂的底层依赖和推理逻辑,它免去了用户手动配置繁琐环境的痛苦,同时提供了自动下载模型和可视化预览功能。其技术亮点在于针对纹理生成部分进行了深度优化,提供了预编译的加速模块以提升渲染效率,并可选集成 BPT 等先进算法来进一步提升几何细节表现。
这款插件特别适合已经在使用 ComfyUI 进行 AI 绘画或 3D 创作的设计师、数字艺术家,以及希望快速验证 3D 生成效果的研究人员。对于具备一定动手能力的开发者,它也开放了源码编译接口以适应特定系统环境。虽然安装过程涉及部分环境配置,但它成功将顶尖的 3D 生成能力带入了大众化的创作工作流,是探索 AI 3D 内容生产的有力助手。
使用场景
某独立游戏开发者需要为即将上线的奇幻 RPG 项目快速批量生成高细节的 3D 怪物资产,以填补美术资源缺口。
没有 ComfyUI-Hunyuan3DWrapper 时
- 流程割裂严重:开发者需在多个独立软件间手动切换,先跑文本生成模型,再导出中间文件导入另一工具进行网格生成,最后单独处理贴图,耗时且易出错。
- 纹理质量低下:缺乏高效的顶点修复(vertex inpainting)机制,生成的 3D 模型表面常出现明显的拉伸、空洞或接缝,需人工在 Blender 中花费数小时修补 UV。
- 硬件门槛过高:原生的 Hunyuan3D-2 部署复杂,依赖特定的编译环境和 CUDA 版本,普通开发机常因缺少
Python.h或编译失败而无法运行。 - 迭代成本高昂:调整一个提示词意味着重跑整个断裂的流程,无法在统一界面中实时预览形状与贴图的生成效果,严重拖慢创作节奏。
使用 ComfyUI-Hunyuan3DWrapper 后
- 工作流一体化:直接在 ComfyUI 节点图中串联从文本到最终带贴图模型的全流程,利用自动下载的 Diffusers 模型和封装好的推理节点,实现“一键式”生成。
- 自动化纹理修复:调用内置编译好的
mesh_processor扩展,自动执行高性能的顶点修复算法,显著减少模型表面的纹理瑕疵,无需手动干预 UV 展开。 - 开箱即用体验:预置了适配 Windows 11 及特定 PyTorch 版本的
.whl轮子文件,规避了复杂的底层编译步骤,让开发者能迅速在本地环境启动高性能推理。 - 高效迭代优化:结合可选的 BPT 模块提升形状生成精度,并在同一画布上即时对比不同参数下的 3D 产出,将单个资产的制作周期从天级缩短至分钟级。
ComfyUI-Hunyuan3DWrapper 通过将复杂的 3D 生成链路标准化与自动化,让中小团队也能低成本地构建高质量 3D 资产生产线。
运行环境要求
- Windows
需要 NVIDIA GPU,预编译版本支持 CUDA 12.4 和 CUDA 12.6 (cu124/cu126),需配合 PyTorch 使用
未说明

快速开始
Hunyuan3D-2 的 ComfyUI 封装
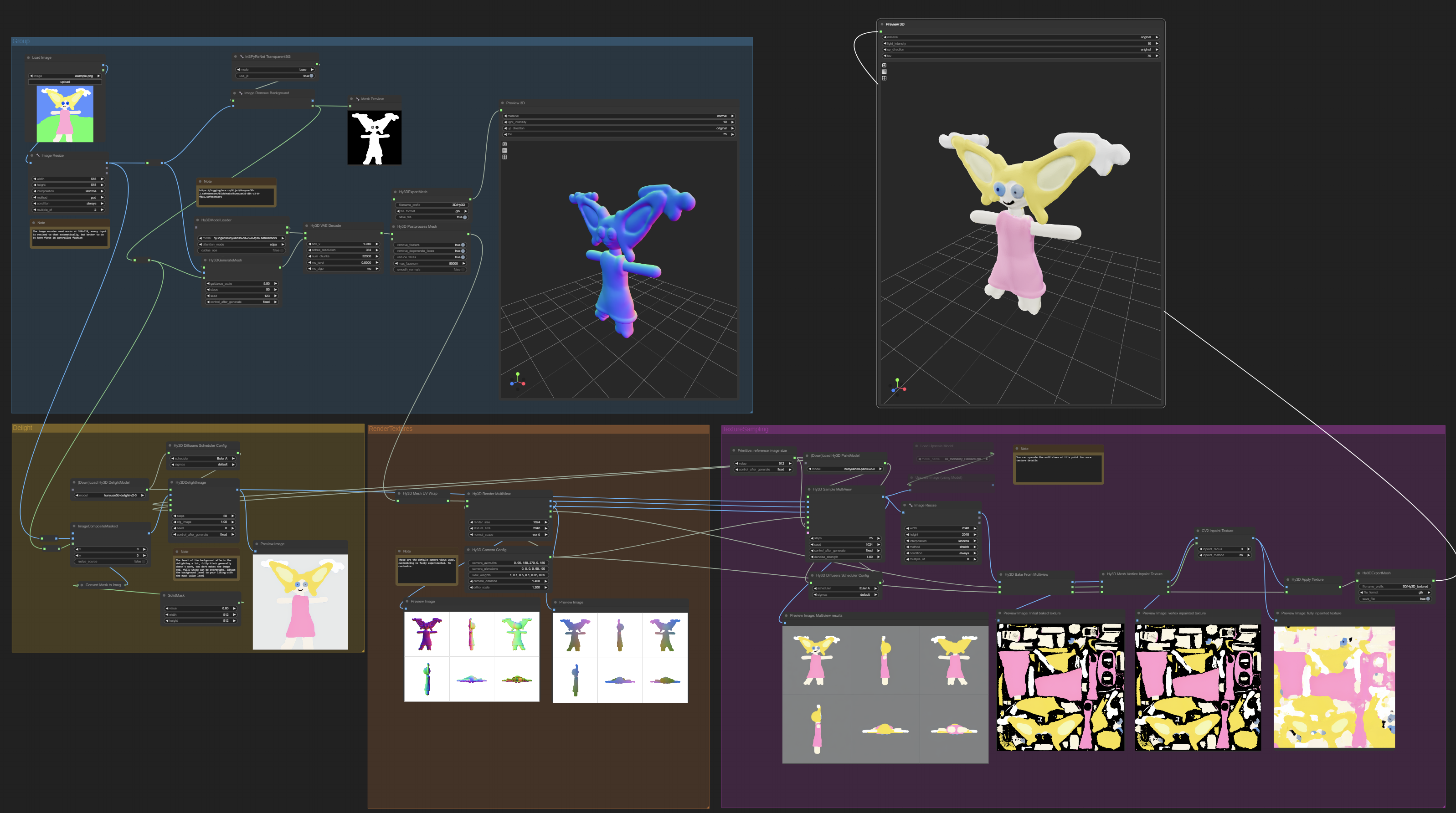
模型
主模型(原始版本):https://huggingface.co/tencent/Hunyuan3D-2/blob/main/hunyuan3d-dit-v2-0/model.ckpt
转换为 .safetensors 格式:https://huggingface.co/Kijai/Hunyuan3D-2_safetensors
请将其放置于 ComfyUI/models/diffusion_models/ 目录下。
其余模型均为 Diffusers 模型,因此目前通过封装并自动下载的方式提供。此外,Preview3D 节点还需要使用非常新的 ComfyUI 版本。
安装
在您的 Python 环境中安装依赖:
pip install -r requirements.txt
或者使用便携版:
python_embeded\python.exe -m pip install -r ComfyUI\custom_nodes\ComfyUI-Hunyuan3DWrapper\requirements.txt
对于 texturegen 部分,需要进行编译。我已经将光栅器的编译结果打包成 wheel 文件,并将 mesh_processor 编译为 .pyd 文件(已放置到位),这些文件是针对以下环境编译的:
Windows 11 Python 3.12 cu126(也可兼容 torch 124 构建版本)
您可以运行:pip install wheels\custom_rasterizer-0.1-cp312-cp312-win_amd64.whl
或者使用便携版(在 ComfyUI_windows_portable 文件夹中):
python_embeded\python.exe -m pip install ComfyUI\custom_nodes\ComfyUI-Hunyuan3DWrapper\wheels\custom_rasterizer-0.1-cp312-cp312-win_amd64.whl
Windows 11 Python 3.12 PyTorch 2.6.0 + cu126
当前最新便携版已更新为使用 PyTorch 2.6.0,为此您应使用新的 wheel 文件:
python_embeded\python.exe -m pip install ComfyUI\custom_nodes\ComfyUI-Hunyuan3DWrapper\wheels\custom_rasterizer-0.1.0+torch260.cuda126-cp312-cp312-win_amd64.whl
经测试,该版本可在最新的 ComfyUI 便携版中正常运行。
如果上述方法无效,或没有适合您系统的 wheel 文件,则需要自行编译:
光栅器的构建与安装:
cd hy3dgen/texgen/custom_rasterizer
python setup.py install
如果您使用的是便携版 ComfyUI: 例如(请根据您系统中的路径调整):
cd C:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-Hunyuan3DWrapper\hy3dgen\texgen\custom_rasterizer
C:\ComfyUI_windows_portable\python_embeded\python.exe -m pip install .
如果出现关于 Python.h 缺失的错误,请参考此处的说明,因为这是相同的编译问题(您不需要 Triton 本身):
或者使用 python setup.py bdist_wheel 命令构建,这会生成一个 .whl 文件到 dist 子目录中,然后您可以将其 pip 安装到您的 Python 环境中。
最终结果需要在您的 Python 环境的 site-packages 文件夹中生成 custom_rasterizer_kernel*.pyd 文件和 custom_rasterizer 文件夹。
对于 mesh_processor 扩展,构建命令如下:
cd hy3dgen/texgen/differentiable_renderer
python_embeded\python.exe setup.py build_ext --inplace
该文件应位于同一目录中。它仅用于顶点修复功能;如果该文件不存在,则会回退到 CPU 上运行,速度会慢很多。顶点修复功能位于单独的节点上,在最坏情况下可以直接跳过,但缺点是纹理填充效果会较差。
同样地,使用便携版时,请使用内置的 Python 解释器来执行相关命令。
更新:
新增 BPT
此功能有一些较高的要求,完全可选,请根据自身情况决定是否安装
cd ComfyUI-Hunyuan3DWrapper\hy3dgen\shapegen\bpt
pip install -r requirements.txt
使用便携版 ComfyUI 的安装方法:
从便携版的根目录运行:
python_embeded\python.exe -m pip install -r ComfyUI\custom_nodes\ComfyUI-Hunyuan3DWrapper\hy3dgen\shapegen\bpt\requirements.txt
下载权重:https://huggingface.co/whaohan/bpt/blob/refs%2Fpr%2F1/bpt-8-16-500m.pt
将 bpt-8-16-500m.pt 复制到 ComfyUI-Hunyuan3DWrapper-main\hy3dgen\shapegen\bpt 目录下。
Xatlas 升级流程,用于修复高多边形网格的 UV 展开问题
python_embeded\python.exe -m pip uninstall xatlas
在便携版的根目录(ComfyUI_windows_portable)中:
git clone --recursive https://github.com/mworchel/xatlas-python.git
cd .\xatlas-python\extern
删除 xatlas 文件夹
git clone --recursive https://github.com/jpcy/xatlas
在 xatlas-python\extern\xatlas\source\xatlas 中修改 xatlas.cpp
将第 6774 行的 #if 0 改为 //#if 0
将第 6778 行的 #endif 改为 //#endif
最后返回便携版的根目录(ComfyUI_windows_portable):
.\python_embeded\python.exe -m pip install .\xatlas-python\
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。