WavTokenizer
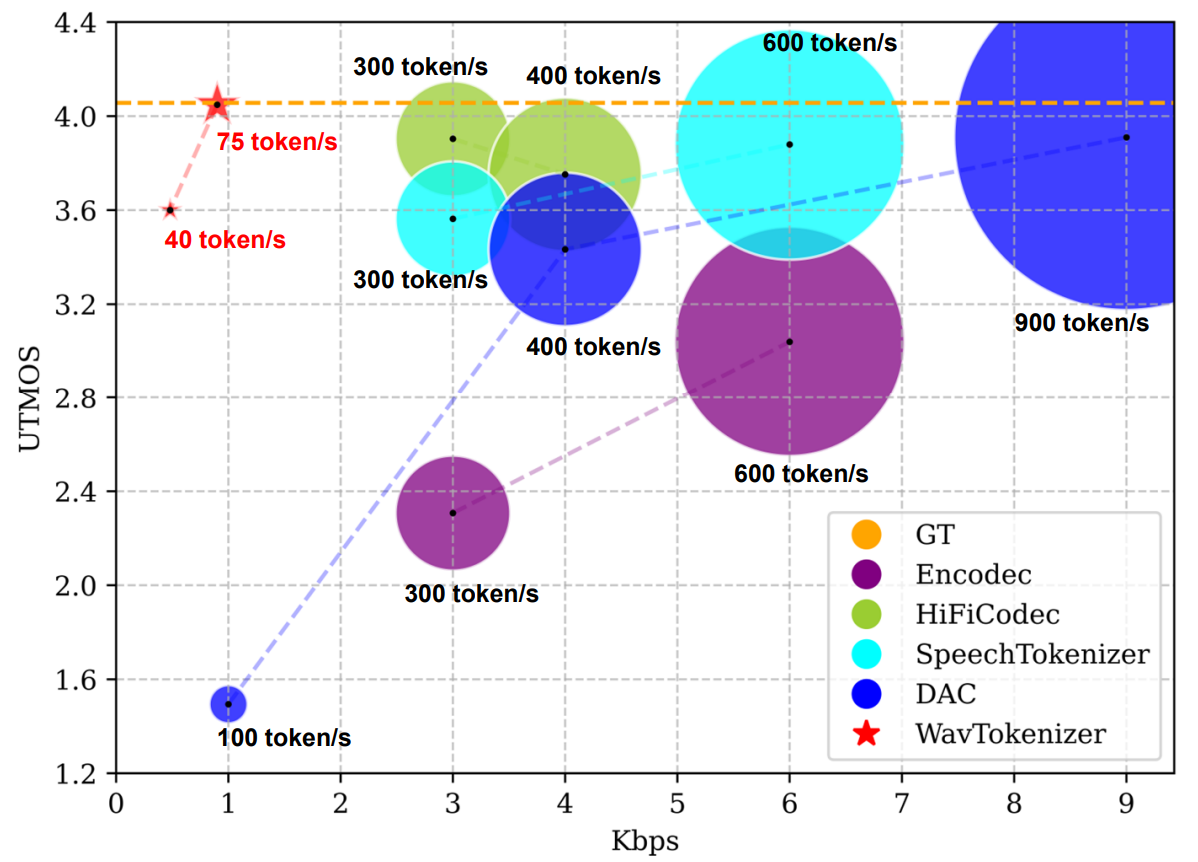
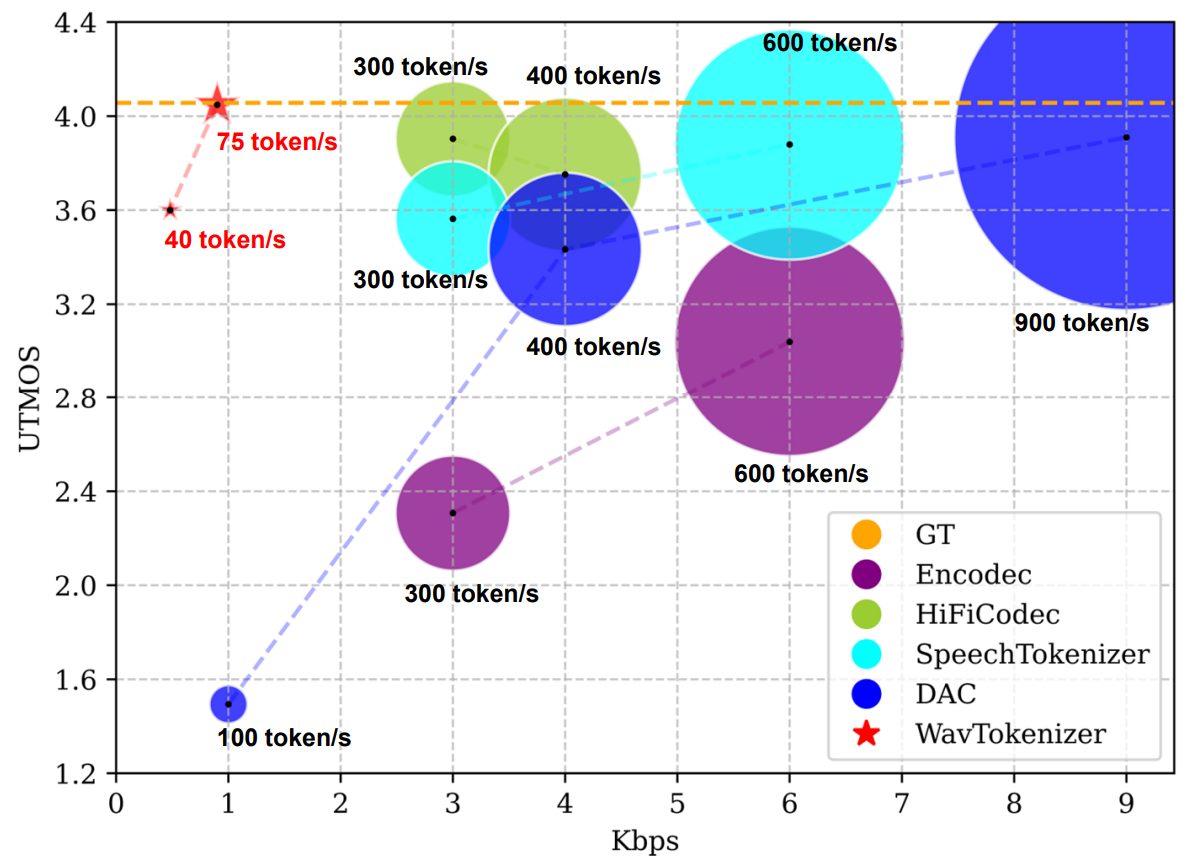
WavTokenizer 是一款专为音频语言模型设计的最先进(SOTA)离散声学编解码器,已入选 ICLR 2025。它的核心功能是将语音、音乐及各类音频信号高效压缩为极少量的离散令牌(tokens),最低仅需每秒 40 个令牌即可高质量还原原始声音。
传统音频处理模型往往面临数据量大、计算成本高或重建音质受损的难题。WavTokenizer 通过创新的架构,在大幅降低数据维度的同时,依然保留了丰富的语义信息并实现了卓越的音频重建效果。这种“高压缩、高保真”的特性,使其成为构建类似 GPT-4o 等下一代多模态音频大模型的理想基石,能有效降低训练与推理的资源门槛。
该工具主要面向人工智能研究人员、音频算法开发者以及大模型架构师。对于希望探索高效音频表征学习、开发语音生成应用或优化现有音频流水线的技术团队而言,WavTokenizer 提供了开箱即用的预训练模型(涵盖 Medium 和 Large 版本)及便捷的 Python 接口,支持从音频编码、离散码本生成到解码还原的全流程操作,是连接底层音频信号与上层语言模型的高效桥梁。
使用场景
某语音大模型初创团队正在构建类似 GPT-4o 的多模态助手,需要处理海量的演讲录音与背景音乐数据以训练音频语言模型。
没有 WavTokenizer 时
- 算力成本高昂:传统声学编码器每秒需生成数百个 token,导致序列过长,训练显存占用极大,难以在有限预算下扩展数据集规模。
- 语义信息丢失:现有压缩方案往往过度牺牲音质或忽略深层语义,使得模型难以理解音频中的复杂指令或情感色彩。
- 重建效果失真:在低码率下还原音频时,人声和音乐经常出现机械感或噪点,严重影响最终产品的听感体验。
- 多场景适配困难:缺乏统一的高效接口,针对语音、音乐等不同音频类型需维护多套预处理流程,开发效率低下。
使用 WavTokenizer 后
- 训练效率倍增:凭借每秒仅 40 个 token 的极致压缩率,WavTokenizer 将输入序列长度缩减至原来的几分之一,显著降低显存需求并加速模型收敛。
- 语义理解增强:生成的离散编码富含深层语义信息,让大模型能更精准地捕捉音频中的逻辑意图,提升对话交互的智能度。
- 高保真还原:即使在极低码率下,WavTokenizer 仍能实现高质量的音频重建,确保输出的人声清晰自然、音乐细节丰富。
- 统一处理流程:一套模型即可完美覆盖语音、音乐及通用音频场景,简化了数据流水线,让团队能专注于核心算法迭代。
WavTokenizer 通过极致的压缩效率与卓越的语义保持能力,为音频大模型的规模化落地扫清了数据与算力的双重障碍。
运行环境要求
- 未说明
未说明 (代码示例默认使用 CPU,但作为深度学习音频模型,训练或高性能推理通常建议配备 NVIDIA GPU)
未说明
快速开始
WavTokenizer
用于音频语言建模的每秒四十个标记的最先进离散编解码器模型
![]()
🎉🎉 使用 WavTokenizer,你只需每秒40个标记就能表示语音、音乐和音频!
🎉🎉 使用 WavTokenizer,你可以获得强大的重建效果。
🎉🎉 WavTokenizer 拥有丰富的语义信息,专为 GPT-4o 等音频语言模型而设计。
🔥 新闻
- 2025年2月25日: 我们更新了 WavTokenizer 的 ICLR 2025 准备版本,并在 huggingface 上发布了 WavTokenizer-large-v2 检查点。
- 2024年10月22日: 我们在 arXiv 上更新了 WavTokenizer,并发布了 WavTokenizer-Large 检查点。
- 2024年9月9日: 我们在 huggingface 上发布了 WavTokenizer-medium 检查点。
- 2024年8月31日: 我们在 arXiv 上发布了 WavTokenizer。
安装
要使用 WavTokenizer,可以按照以下步骤安装:
conda create -n wavtokenizer python=3.9
conda activate wavtokenizer
pip install -r requirements.txt
推理
第一部分:从原始 WAV 文件重建音频
from encoder.utils import convert_audio
import torchaudio
import torch
from decoder.pretrained import WavTokenizer
device=torch.device('cpu')
config_path = "./configs/xxx.yaml"
model_path = "./xxx.ckpt"
audio_outpath = "xxx"
wavtokenizer = WavTokenizer.from_pretrained0802(config_path, model_path)
wavtokenizer = wavtokenizer.to(device)
wav, sr = torchaudio.load(audio_path)
wav = convert_audio(wav, sr, 24000, 1)
bandwidth_id = torch.tensor([0])
wav=wav.to(device)
features,discrete_code= wavtokenizer.encode_infer(wav, bandwidth_id=bandwidth_id)
audio_out = wavtokenizer.decode(features, bandwidth_id=bandwidth_id)
torchaudio.save(audio_outpath, audio_out, sample_rate=24000, encoding='PCM_S', bits_per_sample=16)
第二部分:生成离散编解码器代码
from encoder.utils import convert_audio
import torchaudio
import torch
from decoder.pretrained import WavTokenizer
device=torch.device('cpu')
config_path = "./configs/xxx.yaml"
model_path = "./xxx.ckpt"
wavtokenizer = WavTokenizer.from_pretrained0802(config_path, model_path)
wavtokenizer = wavtokenizer.to(device)
wav, sr = torchaudio.load(audio_path)
wav = convert_audio(wav, sr, 24000, 1)
bandwidth_id = torch.tensor([0])
wav=wav.to(device)
_,discrete_code= wavtokenizer.encode_infer(wav, bandwidth_id=bandwidth_id)
print(discrete_code)
第三部分:通过编解码器重建音频
# audio_tokens [n_q,1,t]/[n_q,t]
features = wavtokenizer.codes_to_features(audio_tokens)
bandwidth_id = torch.tensor([0])
audio_out = wavtokenizer.decode(features, bandwidth_id=bandwidth_id)
可用模型
🤗 Huggingface 模型库链接。
| 模型名称 | HuggingFace | 数据集 | 标记/秒 | 领域 | 开源 |
|---|---|---|---|---|---|
| WavTokenizer-small-600-24k-4096 | 🤗 | LibriTTS | 40 | 语音 | √ |
| WavTokenizer-small-320-24k-4096 | 🤗 | LibriTTS | 75 | 语音 | √ |
| WavTokenizer-medium-320-24k-4096 | 🤗 | 10000 小时 | 75 | 语音、音频、音乐 | √ |
| WavTokenizer-large-600-24k-4096 | 🤗 | 80000 小时 | 40 | 语音、音频、音乐 | √ |
| WavTokenizer-large-320-24k-4096 | 🤗 | 80000 小时 | 75 | 语音、音频、音乐 | √ |
训练
第一步:准备训练数据集
# 将数据处理成类似 ./data/demo.txt 的格式
第二步:修改配置文件
# ./configs/xxx.yaml
# 修改 batch_size、filelist_path、save_dir、device 等参数的值
第三步:开始训练过程
有关自定义训练流程的详细信息,请参阅 Pytorch Lightning 文档。
cd ./WavTokenizer
python train.py fit --config ./configs/xxx.yaml
引用
如果这段代码对您的研究有所帮助,请引用我们的工作——Language-Codec 和 WavTokenizer:
@article{ji2024wavtokenizer,
title={Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling},
author={Ji, Shengpeng and Jiang, Ziyue and Wang, Wen and Chen, Yifu and Fang, Minghui and Zuo, Jialong and Yang, Qian and Cheng, Xize and Wang, Zehan and Li, Ruiqi and others},
journal={arXiv preprint arXiv:2408.16532},
year={2024}
}
@article{ji2024language,
title={Language-codec: Reducing the gaps between discrete codec representation and speech language models},
author={Ji, Shengpeng and Fang, Minghui and Jiang, Ziyue and Huang, Rongjie and Zuo, Jialung and Wang, Shulei and Zhao, Zhou},
journal={arXiv preprint arXiv:2402.12208},
year={2024}
}
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
spec-kit
Spec Kit 是一款专为提升软件开发效率而设计的开源工具包,旨在帮助团队快速落地“规格驱动开发”(Spec-Driven Development)模式。传统开发中,需求文档往往与代码实现脱节,导致沟通成本高且结果不可控;而 Spec Kit 通过将规格说明书转化为可执行的指令,让 AI 直接依据明确的业务场景生成高质量代码,从而减少从零开始的随意编码,确保产出结果的可预测性。 该工具特别适合希望利用 AI 辅助编程的开发者、技术负责人及初创团队。无论是启动全新项目还是在现有工程中引入规范化流程,用户只需通过简单的命令行操作,即可初始化项目并集成主流的 AI 编程助手。其核心技术亮点在于“规格即代码”的理念,支持社区扩展与预设模板,允许用户根据特定技术栈定制开发流程。此外,Spec Kit 强调官方维护的安全性,提供稳定的版本管理,帮助开发者在享受 AI 红利的同时,依然牢牢掌握架构设计的主动权,真正实现从“凭感觉写代码”到“按规格建系统”的转变。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。