minimind-v
MiniMind-V 是一个超轻量级的视觉语言模型,能在1小时内、仅用约1.3元成本,从零训练出仅67M参数的多模态模型,实现看图说话能力。它打破了“大模型必须庞大昂贵”的刻板印象,让个人开发者和研究者在普通GPU上也能快速训练和部署视觉语言系统。项目完整开源了从数据清洗、预训练到微调的全流程代码,不仅是一个实用模型,更是一份清晰的入门教程。其核心技术亮点在于极简架构设计:用MLP替代复杂投影模块,采用SigLIP2视觉编码器,并支持稠密与混合专家(MoE)两种模式,兼顾效率与性能。适合AI初学者、教育工作者、边缘计算开发者以及希望低成本探索多模态技术的爱好者使用。无论你是想动手实践,还是理解VLM底层逻辑,MiniMind-V 都提供了一个低门槛、高透明度的起点。
使用场景
某乡村中学的信息技术教师李老师,希望为学生开发一个能“看图说话”的AI小助手,用于辅助语文和美术课的图像理解教学,但学校预算有限,无专业AI团队支持。
没有 minimind-v 时
- 需要依赖云端大模型API,每调用一次产生费用,月支出超千元,学校无法长期承担。
- 现有开源VLM模型动辄数GB,学校老旧的GPU(GTX 1660)根本无法加载,部署失败。
- 教师缺乏训练经验,面对复杂框架和海量数据预处理流程无从下手,项目停滞数月。
- 想让学生亲手修改模型提示词、观察输出变化,但现有模型无法本地运行,无法实现课堂互动。
- 模型训练需数天甚至数周,教学进度无法匹配,学生失去耐心。
使用 minimind-v 后
- 仅用1.3元租用1小时GPU,就训练出仅0.5GB的67M参数模型,部署在教师个人笔记本上,零成本运行。
- 模型可在GTX 1660上流畅推理,学生轮流提问“这张画里有什么?”“为什么天空是紫色的?”,实时互动无延迟。
- 项目提供完整代码与数据清洗脚本,李老师按教程3小时完成训练,首次体验了“从零造AI”的成就感。
- 模型支持动态切换,李老师可让学生对比27M、67M版本效果,直观理解“参数与能力”的关系,成为生动的AI课例。
- 断点续训和单卡训练支持让李老师能利用午休时间继续优化,不再受制于设备与时间。
minimind-v 让一个普通教师,用一台旧电脑和一杯咖啡的时间,把AI教育从“遥不可及”变成了“触手可及”。
运行环境要求
- Linux
需要 NVIDIA GPU,推荐 RTX 3090 (24GB),显存至少 8GB,CUDA 12.2
128 GB

快速开始






"大道至简"
中文 | English
- 此项目旨在从0开始,仅用1.3块钱成本 + 1小时!即可训练出67M参数的超小多模态视觉语言模型MiniMind-V。
- MiniMind-V最小版本体积仅为 GPT3 的约 $\frac{1}{2600}$,力求做到个人GPU也可快速推理甚至训练。
- MiniMind-V是MiniMind纯语言模型的视觉能力额外拓展。
- 项目同时包含了VLM大模型的极简结构、数据集清洗、预训练(Pretrain)、监督微调(SFT)等全过程代码。
- 这不仅是一个开源VLM模型的最小实现,也是入门视觉语言模型的简明教程。
- 希望此项目能为所有人提供一个抛砖引玉的示例,一起感受创造的乐趣!推动更广泛AI社区的进步!
为防止误解,“1小时” 基于NVIDIA 3090硬件设备(单卡)测试
1 epoch,“1.3块钱” 指GPU服务器租用成本。
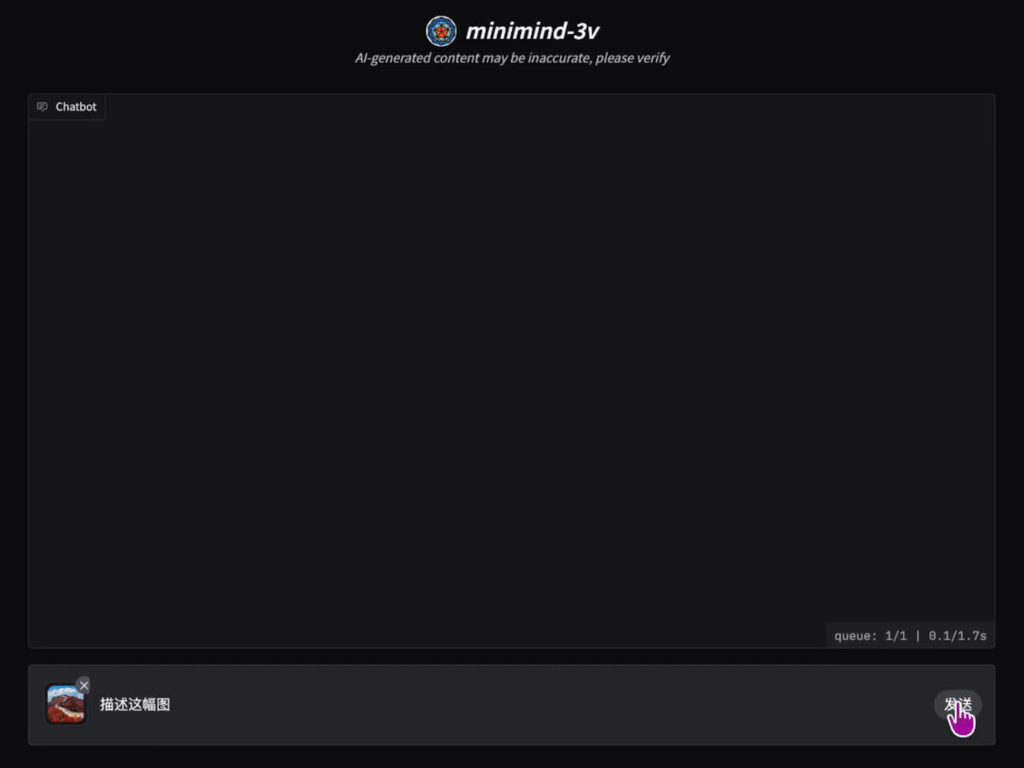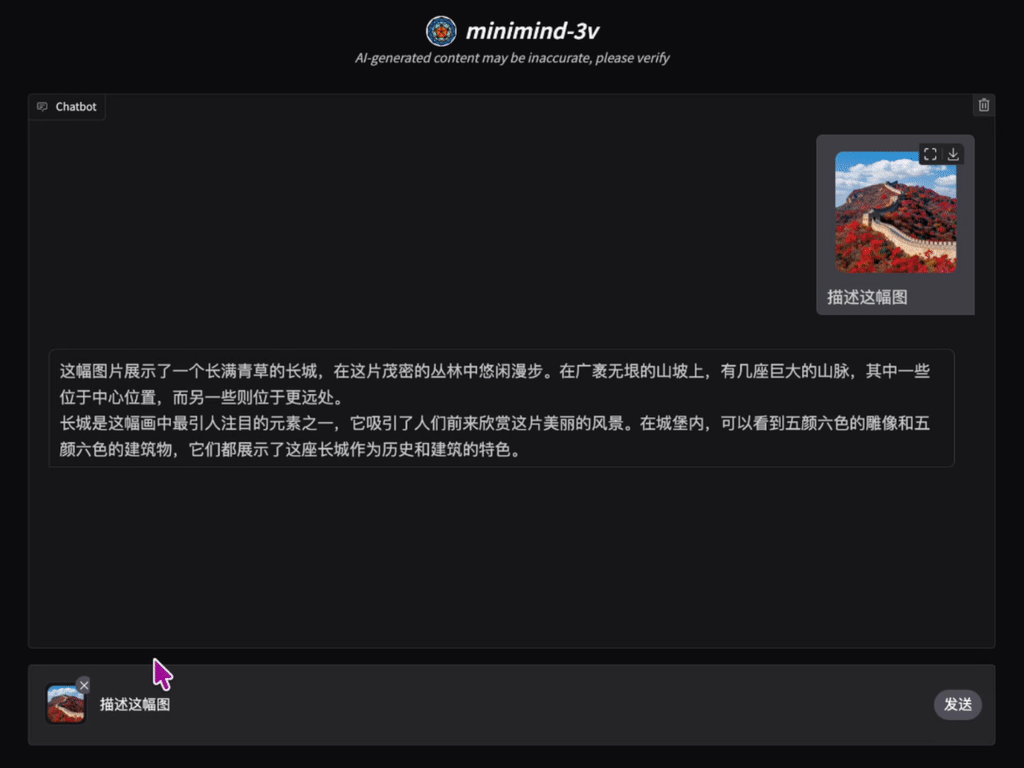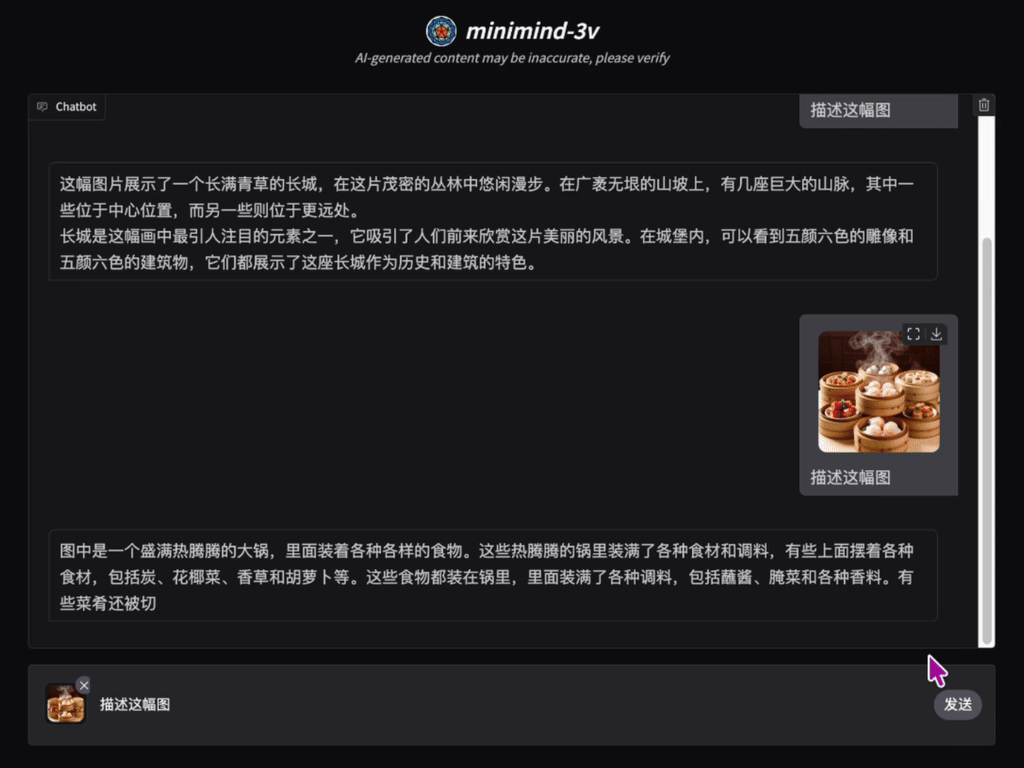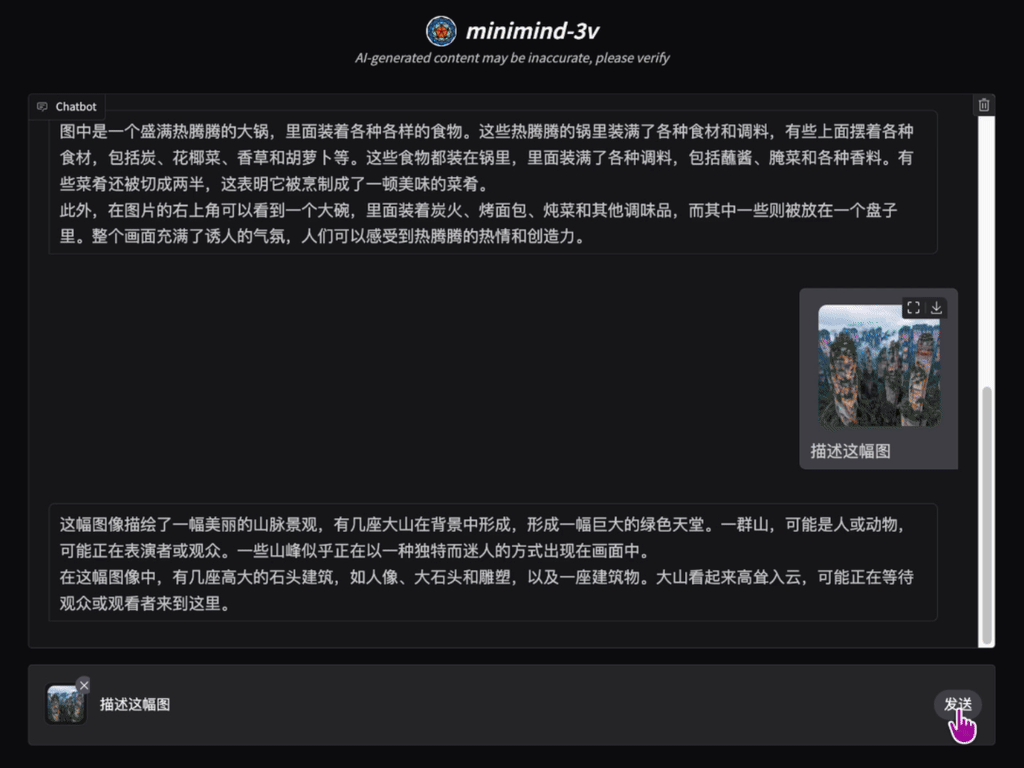
📌 项目介绍
“用乐高拼出一架飞机,远比坐在头等舱里飞行更让人兴奋!” 构建VLM范式的多模态大模型是否真的如想象中那样复杂?它的代码实现到底如何? 训练过程究竟难不难?那么现在,探索它们的答案,一起感受创造的乐趣吧!
[!TIP] (截至2026-02-15)MiniMind-V 系列已完成了以下型号模型训练,最小仅需67M (0.067B),即可具备识图和对话的能力!
| 模型 (大小) | 推理占用 | release |
|---|---|---|
| minimind-3v-moe (201M-A67M) | 1.0 GB | 2026.04.01 |
| minimind-3v (67M) | 0.5 GB | 2026.04.01 |
| MiniMind2-V (104M) | 1.1 GB | 2025.02.20 |
| MiniMind2-Small-V (26M) | 0.6 GB | 2025.02.20 |
| minimind-v-v1-small (27M) | 0.6 GB | 2024.10.04 |
| minimind-v-v1 (109M) | 1.1 GB | 2024.10.04 |
👉 更新日志
2026-04-01
- 新增 minimind-3v (67M) 和 minimind-3v-moe (201M-A67M) 模型
- 统一使用768+8架构,支持dense和moe两种模式
- 视觉编码器从CLIP切换为SigLIP2(siglip2-base-p16-ve)
- 投影模块从QFormer改为MLP Projection + reshape压缩
- 数据集格式更新为parquet,混合数据源、更新tokenizer,图像占位符改为`
测试预训练模型
python eval_vlm.py --weight pretrain_vlm
---
> [!TIP]
> 训练脚本均为Pytorch原生框架,均支持多卡加速,假设你的设备有N (N>1) 张显卡:
单机N卡启动训练方式 (DDP, 支持多机多卡集群)
```bash
torchrun --nproc_per_node N train_xxx.py
注:其它须知
deepspeed --master_port 29500 --num_gpus=N train_xxx.py
可根据需要开启wandb记录训练过程
# 需要登录: wandb login
torchrun --nproc_per_node N train_xxx.py --use_wandb
# and
python train_xxx.py --use_wandb
通过添加--use_wandb参数,可以记录训练过程,训练完成后,可以在wandb网站上查看训练过程。通过修改wandb_project
和wandb_run_name参数,可以指定项目名称和运行名称。
【注】:25年6月后,国内网络环境无法直连WandB,MiniMind项目默认转为使用SwanLab作为训练可视化工具(完全兼容WandB API),即import wandb改为import swanlab as wandb即可,其他均无需改动。
📌 模型细节
MiniMind-V (VLM)的基座语言模型MiniMind (LLM)来自孪生项目minimind, 具体的模型结构、训练细节、原理、测试效果等均可移步minimind项目查阅。 此处为减少冗余,省略讨论LLM的相关部分,默认您已对MiniMind (LLM)的细节有基本的了解。
即使您不太了解LLM的细节,也可参考“快速开始”流程训练一个MiniMind-V, 这并不受到影响,仓库致力于最低成本的开箱即用!
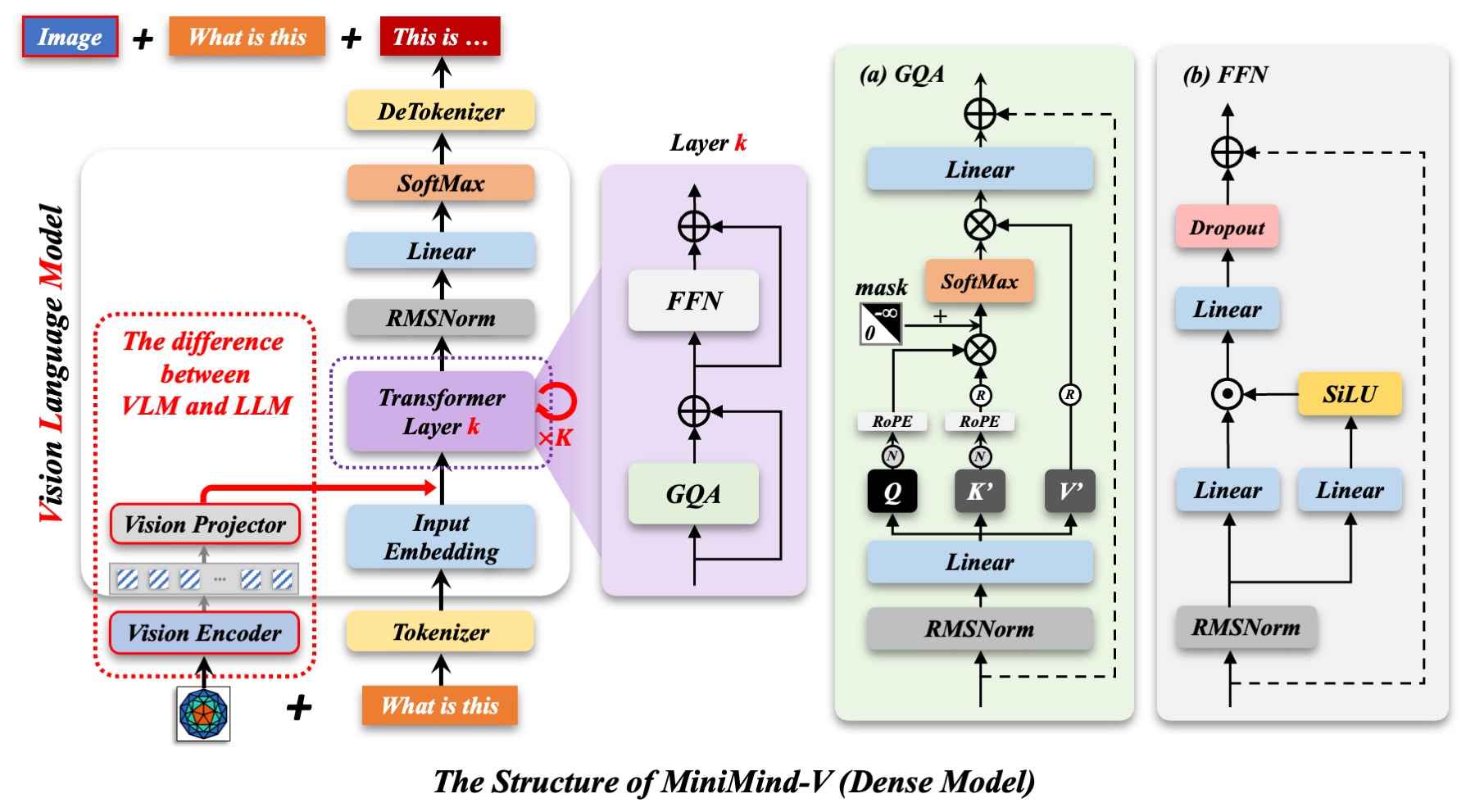
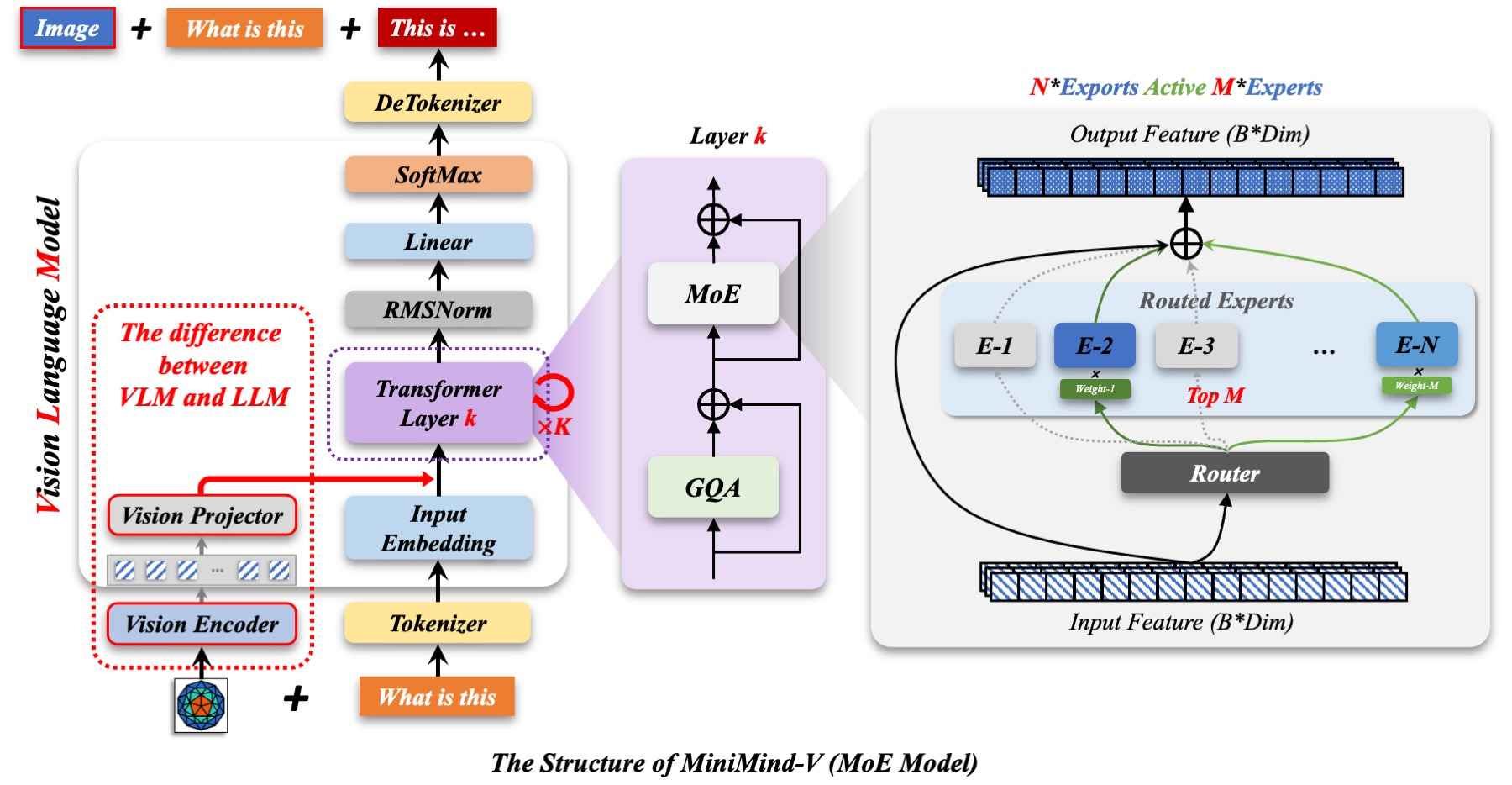
MiniMind-V的结构仅增加Visual Encoder和特征投影两个子模块,增加模态混合分支,以支持多种模态信息的输入:
【重要】一些有趣的思考
此处不妨展开想一想两个问题:
- 什么叫做Large Language Model (LLM)?
- 什么叫做多模态模型?
这篇文章完美吻合本人的想法: 大语言模型(LLM)名字虽然带有语言二字,但它们其实与语言关系不大,这只是历史问题,更确切的名字应该是自回归 Transformer 或者其他。LLM 更多是一种统计建模的通用技术,它们主要通过自回归 Transformer 来模拟 token 流,而这些 token 可以代表文本、图片、音频、动作选择、甚至是分子等任何东西。 因此,只要能将问题转化为模拟一系列离散 token 的流程,理论上都可以应用 LLM 来解决。 实际上,随着大型语言模型技术栈的日益成熟,我们可能会看到越来越多的问题被纳入这种建模范式。也就是说,问题固定在使用 LLM 进行『下一个 token 的预测』,只是每个领域中 token 的用途和含义有所不同。
ZJU-LiXi老师同样谈及过类似观点(原话大意如下):
文本、视频、语音、动作等在人类看来属于「多模态」信号,但所谓的「模态」其实只是人类在信息存储方式上的一种分类概念。
就像.txt和.png文件,虽然在视觉呈现和高级表现形式上有所不同,但它们本质上并没有根本区别。
之所以出现「多模态」这个概念,仅仅是因为人类在不同的感知层面上对这些信号的分类需求。
然而,对于机器来说,无论信号来自何种「模态」,最终它们都只是以一串二进制的「单模态」数字序列来呈现。
机器并不会区分这些信号的模态来源,而只是处理和分析这些序列背后所承载的信息内容。
个人认为Generative Pretrained Transformer (GPT) 比 Large Language Model (LLM)更为贴切, 因此本人表达上更习惯用"GPT"去代表LLM/VLM/类GPT架构的系列模型,而非为了蹭OpenAI的热度。
至此,我们可以用一句话总结GPT的所作所为:
GPT模型根据现有token预测输出下一个下下一个下下下一个token ...,直到模型输出结束符;此处的"token"其实并不需要一定是文本!
> 对于LLM模型,如果需要理解"图片",我们只要把"图片"作为对一种特殊的从来没见过的"外国语言",通过"外语词典"翻译后即可作为特殊的语言输入LLM
> 对于LLM模型,如果需要理解"音频",我们只要把"音频"作为对一种特殊的从来没见过的"外国语言",通过"外语词典"翻译后即可作为特殊的语言输入LLM
> ...
为了得到MiniMind-V,我们只需要完成这2件事即可:
- 借助擅长翻译图片的 "外语词典" ,把图片从 "外国语言" 翻译为模型便于理解的 "LLM语言"
- 训练微调LLM,使其和 "外语词典" 度过磨合期,从而更好的理解图片
"外语词典" 称之为Visual Encoder模型。 和LlaVA、Qwen-VL等视觉语言模型类似,MiniMind-V当前选用开源SigLIP2系列模型作为Visual Encoder。 具体使用siglip2-base-p16-ve, 一种基于 ViT-B/16 架构的Visual Encoder用于描述图像文本信息。 当前使用的 SigLIP2 NaFlex 视觉编码器会根据预处理结果生成最多256个patch token作为encoder编码层的输入, 最终产生1×768维的嵌入向量用于和文本对计算误差。 我们并不需要最终嵌入表示,因此只取encoder层的输出,也就是VIT核心主干的输出特征即可。 它拿到前一层256×768大小的特征,通过reshape将每4个相邻token拼接为1个(256×768 → 64×3072),再经过2层MLP(Linear→GELU→Linear)投影到LLM的隐藏维度,最终作为64个visual token输入MiniMind-V。 与LLM的结合在获取图像encoder特征后,一方面需要把视觉特征对齐到LLM的文本token维度, 另一方面,要将图像特征映射到与文本embedding相同的空间,即文本token和原生的视觉token需要磨合并不能直接地一视同仁, 可以称之为跨模态的特征对齐。
LlaVA-1使用简单的线性变换完成对齐,LlaVA-1.5升级为2层MLP,MiniMind-V采用与LlaVA-1.5相同的MLP Projection方案,并结合reshape进行token压缩。
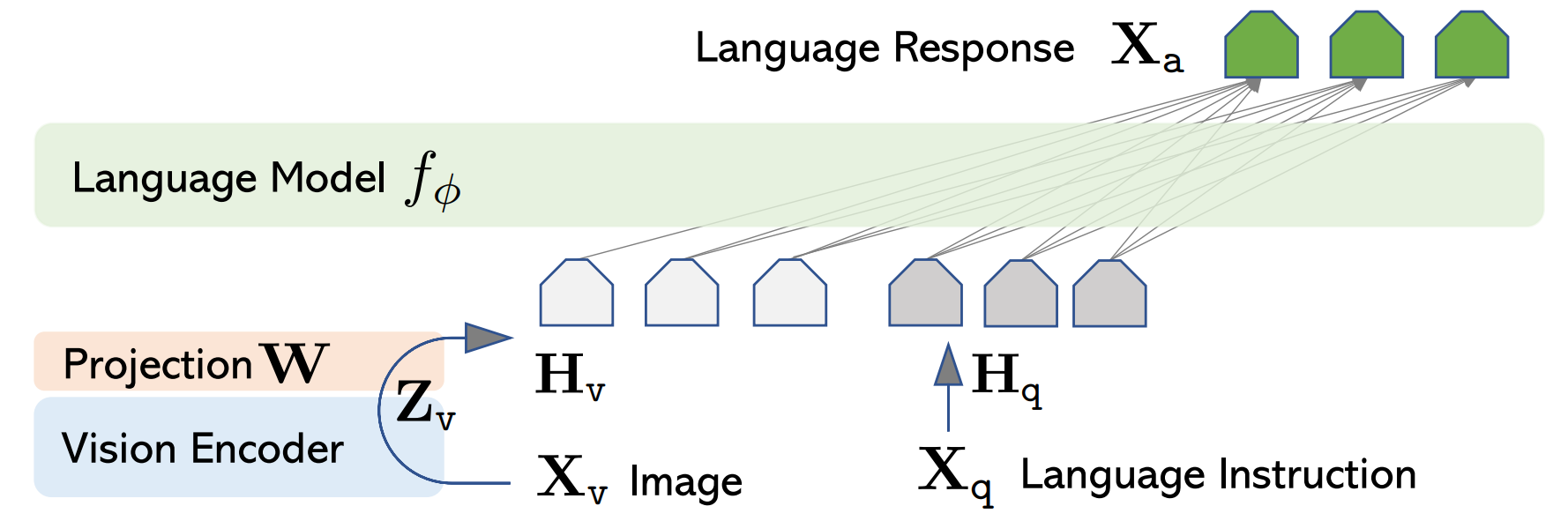
MiniMind-V的主要结构已介绍完毕。
下面,我们简单讨论MiniMind-V的外部输入输出的变化。
VLM的输入依然是一段文本,其中包含特殊的<image>占位符。
在计算文本嵌入后,可以将图像编码器生成的向量投影到该占位符对应的嵌入部分,替换掉原先的占位符embedding。
例如:
<image>\n这个图像中有什么内容?
在minimind-v中,使用64个`
| 图片 | minimind-3v | minimind-3v-moe |
|---|---|---|

|
在这幅图片中,一架白色的飞机正降落在一片广阔的天空中。天空中飘浮着许多流线型的建筑物,这些建筑物散落在天空中。除了主要的飞机外,还有两辆汽车在场景中各处停放,包括一辆巴士和一辆小型汽车。这架飞机似乎停在地面上,表明它们正在进行商业活动。 | 这张照片中,有一架大型的飞机正在降落,这表明它是为这架飞机而设计的。此外,它停在云层之下,这表明它在移动。天空中有云朵,暗示着这架飞机正在空中飞行。整个场景的背景显示出一种宁静祥和的气氛,暗示这架飞机正在飞行中作为一个机会来进行外交活动或与其他客机接触。 |

|
图片显示了一张大生日蛋糕,上面刻有各种生日和装饰物的生日和一束蜡烛。这些甜蜜而独特的气味使其成为这个特殊场合的焦点。蛋糕被放在餐桌上,有蛋糕放在上面,很可能是放在桌上,用蜡烛加上蜡烛来营造出诱人的场景。此外,这张生日蛋糕还配上了蜡烛作为装饰物,进一步丰富了整个生日的氛围。 | 这张照片捕捉到了一个生日聚会,各种美味可口的生日蛋糕和一把勺子放在那里。它被放置在一个充满生气的蛋糕盒子里,里面装着各种各样的草莓糖霜糖浆。蛋糕上有一个大号的蜡烛,给人一种温馨和诱人的图案。周围有很多小点心,比如小心地蜡烛和糖霜,让整个蛋糕看起来更加令人放松和诱人。 |

|
在这张图片中,有一个装饰着奶酪的比萨饼和一片新鲜的青绿野餐毯。这看起来像是一块沙拉,给人一种清新、诱人、美味的享受体验。披萨的大小和大小暗示着一种随意和随意的用餐体验。画面中,一群人围坐在一块砖块上,其中一些则分散在桌子上,周围摆放着不同种类的青绿野餐毯。此外,桌子上还放着一块披萨片,上面摆放着各种各样的青绿野餐毯,营造出一种轻松愉快的氛围。 | 图中,比萨饼在木桌上。它被切成了比萨饼的大小,而且披萨放置在木桌上。比萨有很多配料,包括奶酪和各种酱汁。披萨有多种口味,包括经典的牛排式和意大利式,还有一些加在比萨表面。比萨上有很多新鲜水果,如西红柿和莫吉托,以及奶酪,使这幅图片更加丰富和有吸引力。 |

|
在这幅图片中,一辆白色的马车停泊在一条红色的路牌上。这个车辆位于一条绿油油的道路上,很可能是一个购物中心或高速公路。在这辆车的后部,可以看到一个绿色的马车停泊在路上,这是典型的户外场所。这辆马车可能是为了娱乐或观赏车辆而停放。 | 画面显示了一辆红色高性能赛车,停在一辆大型汽车后面。这辆车可以看到车身、汽车、汽车及汽车停在里面。它似乎是一辆大型红色汽车,有各种大小的汽车,表明它可能是汽车制造商生产的。此外,车辆周围的环境暗示了一种户外环境,因为一辆汽车也出现在场景中。 |

|
画面中,一座蓝色白色的大房子位于一条城市街道上,为这个地区增添了一丝自然与奇思妙想。墙上挂着一盏交通灯,为整个场景增添了特色和引人入胜。 | 画面中,一座蓝色房子旁边有很多小花瓶。这表明这座房子里可能正在营运一些小型小型花盆或盆栽植物。一些人聚集在房子周围,可能正在享受户外生活中的某种乐趣或美景。有些人站在画面中,而其他人则散布于场景中。总体而言,这幅场景捕捉到了一个美丽而令人愉快的场景,展示出该房子里一个令人放松和宁静的环境。 |

|
在这幅图片中,有一个高高的山,它看起来像是大森林中的一片高山。天空中闪烁着不同颜色的星星,给画面增加了一抹红点。天空中有两朵高大的树,树木高高地挂在一起,暗示着森林中的宁静与自然之美。在画面的中心,可以看到一棵高大的松树,树干上覆盖着一层薄薄的苔藓。这种高高的松树与周围的大山构成了一个有趣而引人入胜的背景,为这片自然之美增添了一丝神秘色彩。 | 这幅图片展示了一个令人印象深刻的宁静湖面。湖水从天上飘浮着,暗示着一个令人平静和放松的水面。湖边上有几匹高大、形状各异的景象,它们在湖面上显得格外美丽。此外,在湖的边缘,有一座巨大的高山,为整个湖景增添了几分神秘色彩。湖景中的天空也被描述得如画,给整个画面增添了一种纯净和宁静的气氛。 |

|
图中,一大群人聚集在一张大餐桌旁欣赏着烤肉和热带水果,其中一人站在碗里摆放着各种各样的盘子。桌子上放着几个碗,上面摆满了肉类和其他配料。有些放在盘子里,其他的则放在桌子上。在这张餐桌周围,有几个盘子,其中两个放着一杯酒,另一个放在靠近餐桌的左侧。 | 画面中,一群人聚集在一家大餐馆里,享受着一顿饭。这家餐厅的菜单上有一些生菜和猪肉,但它们已经被切成了四份,上面还有一个碗。他们拿着烤肉准备食用。在背景中,有几个瓶子在场景中。还有一把勺子位于桌子左侧,使盘子看起来更吸引人。一盆盆栽植物放在桌子左侧上方,为空间增添了一抹绿色。场景中的其他元素包括一个碗,里面放着葡萄酒和两根葡萄酒。 |

|
图中,一只棕色的小灰猫正坐在篮子里。这只猫身上戴着一顶棕色的帽子,很可能是一个戴帽子的男人。在篮子里,一只棕色的紫色小灰猫正沿着篮子里去休息。这些小猫似乎也在享受这份温暖,但它们似乎并没有完全放过来。此外,背景中还可以看到一把剪刀。这把剪刀看起来是专门为小猫设计的,它可以用作家庭相册或礼物。在篮子的侧边,有几条篮子,其中一条是最亮的,另一条则是最暗的。在篮子中可以看到一只棕色小灰猫,而另一条则是更暗的。 | 在这张照片中,一只小猫坐在篮子里,紧挨着它坐在篮子里的那块木篮上。猫的身体上有九条纹毛发。这个场景描绘了它们之间的亲密关系,展示了它们在一起度过时光的不同场合。画面中,一群大的猫坐在篮子里,其中一只小猫也被描述为小猫,这可能表明他们正在享受与猫互动、与它们的互动或一起度过愉快时光。 |

|
在这张图片中,沙滩上有很多椅子,还有一些人站着,可以看到一把遮阳伞。虽然它看起来很大,但却没有任何特别的设计。沙滩上有许多椅子,表明这是一家餐馆或者服务员办公室。其中最引人注目的是一张海边椅子,椅子上放着一只热带海滩椅。这个椅子非常适合放松身心、享受海滩时光。此外,还有一些椅子和其他人在场景中,可能是为了放置食物或其他用途。靠近椅子的椅子表示该位置可供使用的其他人使用,也许也有一人在靠近那个椅子的地方。 | 图片显示了一个美丽的海滩场景,有很多椅子散布在天然的棕榈树上。其中一个椅子靠近海滩,而另一个则较小。沙滩上有两把椅子,其中一把靠近中间,另一把则稍微偏左,还有一些则在靠近边缘处。在海边的海滩周围,你可以看到几个人坐在海边的沙滩上,有的靠近海水中,还有一张沙滩椅。其中一张椅子靠近海滩,另一张椅子靠近海边。此外,还可以看到几只遮阳伞,为沙滩上的躺椅提供了遮阴。 |

|
画面中,一辆蓝色的黄色公共汽车正从一辆黄色公共汽车驶过,在道路上停泊着。这辆公共汽车看起来是在一个黄色的黄色高速公路上。图中有几个人,其中一些靠近前景,而另一些则靠后一些,但都没有看到。在黄色公共汽车附近,可以看到一辆停在路边,那辆停在路边。此外,还有两辆不同方向的巴士,一辆靠近前景,另一辆靠近前景,另一辆稍微靠后一些。 | 画面中,一辆黄色和黄色相间的黄色和蓝色交叉路口的蓝色公共汽车正在一条通往路缘上的红色公交车站。有几辆公共汽车正停在路边,它们离一排车道很近。在背景中,可以看到一些长凳,它们在城市里交叉起来。一个长凳位于图中最左侧,而另一个则稍微靠后一点,为画面增添了一些城市特色。整个场景中有很多人和车辆散落在场景各处,包括黄色和蓝色的交叉路口。整个场景给人一种忙碌和迷茫的感觉,这也突显了公共汽车在市区中的存在和目的。 |
效果小结:
两个模型均能识别图像主体(飞机、蛋糕、汽车、海滩等),但普遍存在重复表述和幻觉细节。受限于模型和数据规模,整体处于"能看懂大意、细节不准"的阶段。
视觉信号对于LLM视作一种特殊的外语,因此"学习外语"的能力高低,很大程度上取决于LLM的能力。LLM性能越强,对应的VLM越强,此时效果增益会很明显。
未来值得改进的方面:
> 可引入动态分辨率和Tile-based编码(如LLaVA-NeXT),突破固定分辨率限制。
> Visual Encoder可升级为更强的视觉编码器,获取更细粒度的图像特征。
> 拓展多图理解、视频理解和视觉定位(Visual Grounding)能力。
> ...
📌 致谢
[!TIP] 如果您觉得
MiniMind-V对您有所帮助,可以在 GitHub 上加一个⭐
水平有限难免存在未知的纰漏,欢迎所有人在Issues交流指正或提交PR改进项目
您的支持就是持续改进项目的动力,谢谢!
🤝贡献者

😊鸣谢
@xinyanghuang7: 多图vlm分支 | 仓库截至此版本提供
参考链接 & 感谢以下优秀的论文或项目
- 排名不分任何先后顺序
- LlaVA
- LlaVA-VL
- Chinese-LLaVA-Vision-Instructions
🫶支持者

🎓 引用
如果您觉得 MiniMind-V 对您的研究或工作有所帮助,请引用:
@misc{minimind-v,
title = {MiniMind-V: Train a Tiny VLM from Scratch},
author = {Jingyao Gong},
year = {2024},
url = {https://github.com/jingyaogong/minimind-v},
note = {GitHub repository, accessed 2026}
}
📜 许可协议
本仓库遵循 Apache-2.0 License 开源协议。
版本历史
v22025/10/21常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
OpenHands
OpenHands 是一个专注于 AI 驱动开发的开源平台,旨在让智能体(Agent)像人类开发者一样理解、编写和调试代码。它解决了传统编程中重复性劳动多、环境配置复杂以及人机协作效率低等痛点,通过自动化流程显著提升开发速度。 无论是希望提升编码效率的软件工程师、探索智能体技术的研究人员,还是需要快速原型验证的技术团队,都能从中受益。OpenHands 提供了灵活多样的使用方式:既可以通过命令行(CLI)或本地图形界面在个人电脑上轻松上手,体验类似 Devin 的流畅交互;也能利用其强大的 Python SDK 自定义智能体逻辑,甚至在云端大规模部署上千个智能体并行工作。 其核心技术亮点在于模块化的软件智能体 SDK,这不仅构成了平台的引擎,还支持高度可组合的开发模式。此外,OpenHands 在 SWE-bench 基准测试中取得了 77.6% 的优异成绩,证明了其解决真实世界软件工程问题的能力。平台还具备完善的企业级功能,支持与 Slack、Jira 等工具集成,并提供细粒度的权限管理,适合从个人开发者到大型企业的各类用户场景。