pytorch-video-recognition
pytorch-video-recognition 是一个基于 PyTorch 框架开发的开源项目,专注于视频动作识别任务。它复现了 C3D、R3D 和 R2Plus1D 等经典深度学习模型,旨在帮助开发者高效地分析和理解视频内容中的人类行为,解决了从动态影像中自动提取动作特征并进行分类的技术难题。
该项目特别适合计算机视觉领域的研究人员、AI 工程师以及希望深入探索视频分析技术的学生使用。用户可以直接利用其在 UCF101 和 HMDB51 主流数据集上训练好的 C3D 预训练模型进行快速验证,也可以根据提供的详细代码结构,灵活配置数据集并重新训练其他模型。其技术亮点在于提供了完整的工程化实现,涵盖从数据预处理、模型训练到结果可视化的全流程,并支持 TensorBoard 监控训练状态。此外,项目代码结构清晰,依赖环境配置简单,不仅降低了视频识别领域的入门门槛,也为后续研发更复杂的视频理解算法奠定了坚实基础。
使用场景
某智慧社区安防团队需要开发一套系统,自动从小区监控视频中识别“高空抛物”、“老人跌倒”或“打架斗殴”等异常行为,以便及时预警。
没有 pytorch-video-recognition 时
- 算法复现成本极高:团队需从零阅读 C3D、R3D 等复杂论文并手动编写 PyTorch 代码,极易因细节疏忽导致模型无法收敛。
- 数据预处理繁琐:缺乏统一的视频帧提取与目录结构规范,处理 UCF101 或自定义监控数据集时需反复编写脚本,耗时且易出错。
- 训练基线缺失:没有预训练模型作为起点,必须从头训练深度网络,在单张显卡上可能需要数周才能看到初步效果,严重拖慢项目进度。
- 实验对比困难:难以快速切换不同架构(如从 C3D 切换到 R2Plus1D)进行性能比对,导致技术选型依赖猜测而非实测数据。
使用 pytorch-video-recognition 后
- 开箱即用的模型库:直接调用已实现的 C3D、R3D 等标准模型,将算法验证周期从数周缩短至几天,让团队专注于业务逻辑调整。
- 标准化的数据流水线:利用其预设的数据集目录结构和加载器,快速完成监控视频的帧提取与格式化,无缝衔接训练流程。
- 预训练权重加速迭代:加载官方提供的 C3D 预训练模型进行迁移学习,仅需少量标注数据即可在特定异常行为识别上达到高精度。
- 灵活的实验配置:通过修改
train.py即可轻松切换模型架构与数据集,快速产出对比实验报告,科学确定最优部署方案。
pytorch-video-recognition 通过提供成熟的视频动作识别基础设施,将研发团队从重复的底层造轮子工作中解放出来,实现了异常行为监测系统的快速落地与迭代。
运行环境要求
- 未说明
需要 NVIDIA GPU,实验环境为 TITAN X (12GB 显存)
未说明

快速开始
pytorch-video-recognition
 |
 |
简介
本仓库包含多个用于视频动作识别的模型,包括 C3D、R2Plus1D 和 R3D,均使用 PyTorch (0.4.0) 实现。目前,我们已在 UCF101 和 HMDB51 数据集上训练这些模型。 更多模型和数据集将很快推出!
注:基于 C3D 模型的一个有趣的在线网页游戏请见 这里。
安装
代码已在 Anaconda 和 Python 3.5 环境下测试通过。安装好 Anaconda 环境后:
克隆仓库:
git clone https://github.com/jfzhang95/pytorch-video-recognition.git cd pytorch-video-recognition安装依赖:
对于 PyTorch 的依赖,请参阅 pytorch.org 获取更多详细信息。
对于自定义依赖:
conda install opencv pip install tqdm scikit-learn tensorboardX从 BaiduYun 或 GoogleDrive 下载预训练模型。 目前仅支持 C3D 的预训练模型。
在 mypath.py 中配置您的数据集路径和预训练模型路径。
您可以在 train.py 中选择不同的模型和数据集。
要训练模型,请执行:
python train.py
数据集:
我使用了两个不同的数据集:UCF101 和 HMDB。
数据集目录结构如下所示:
- UCF101
请确保文件按以下结构放置:
UCF-101 ├── ApplyEyeMakeup │ ├── v_ApplyEyeMakeup_g01_c01.avi │ └── ... ├── ApplyLipstick │ ├── v_ApplyLipstick_g01_c01.avi │ └── ... └── Archery │ ├── v_Archery_g01_c01.avi │ └── ...
预处理后,输出目录的结构如下:
ucf101
├── ApplyEyeMakeup
│ ├── v_ApplyEyeMakeup_g01_c01
│ │ ├── 00001.jpg
│ │ └── ...
│ └── ...
├── ApplyLipstick
│ ├── v_ApplyLipstick_g01_c01
│ │ ├── 00001.jpg
│ │ └── ...
│ └── ...
└── Archery
│ ├── v_Archery_g01_c01
│ │ ├── 00001.jpg
│ │ └── ...
│ └── ...
注意:HMDB 数据集的目录结构与 UCF101 类似。
实验
这些模型是在配备 NVIDIA TITAN X 12GB 显卡的机器上训练的。请注意,我使用 sklearn 将每个数据集的训练/验证/测试数据进行了划分。如果您希望使用官方的训练/验证/测试数据来训练模型,可以查看 dataset.py,并根据需要进行修改。
目前,我仅在 UCF 和 HMDB 数据集上训练了 C3D 模型。每次实验的训练/验证/测试准确率及损失曲线如下:
- UCF101
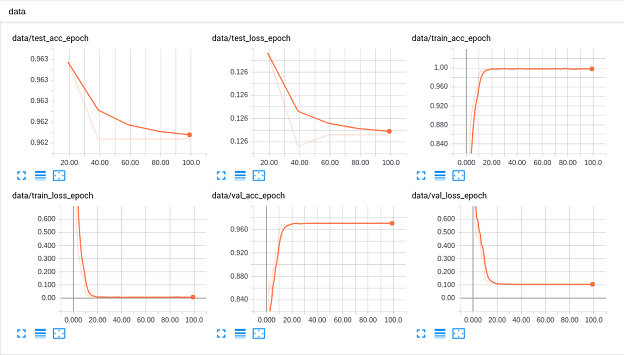
- HMDB51
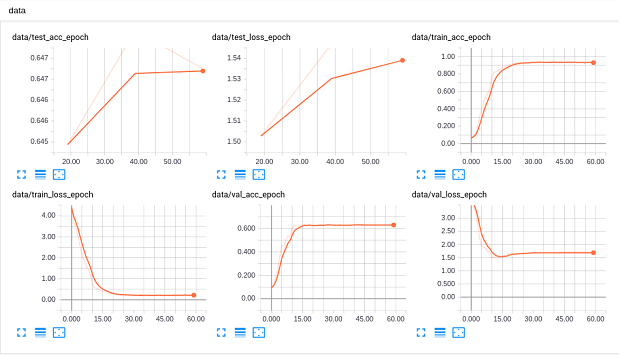
其他模型的实验结果将很快更新……
常见问题
相似工具推荐
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
cs-video-courses
cs-video-courses 是一个精心整理的计算机科学视频课程清单,旨在为自学者提供系统化的学习路径。它汇集了全球知名高校(如加州大学伯克利分校、新南威尔士大学等)的完整课程录像,涵盖从编程基础、数据结构与算法,到操作系统、分布式系统、数据库等核心领域,并深入延伸至人工智能、机器学习、量子计算及区块链等前沿方向。 面对网络上零散且质量参差不齐的教学资源,cs-video-courses 解决了学习者难以找到成体系、高难度大学级别课程的痛点。该项目严格筛选内容,仅收录真正的大学层级课程,排除了碎片化的简短教程或商业广告,确保用户能接触到严谨的学术内容。 这份清单特别适合希望夯实计算机基础的开发者、需要补充特定领域知识的研究人员,以及渴望像在校生一样系统学习计算机科学的自学者。其独特的技术亮点在于分类极其详尽,不仅包含传统的软件工程与网络安全,还细分了生成式 AI、大语言模型、计算生物学等新兴学科,并直接链接至官方视频播放列表,让用户能一站式获取高质量的教育资源,免费享受世界顶尖大学的课堂体验。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。