pytorch-grad-cam
pytorch-grad-cam 是一个专为计算机视觉模型设计的可解释性分析库,旨在揭开深度学习模型“黑盒”的神秘面纱。它通过生成直观的类激活热力图,清晰展示模型在做出预测时关注的图像区域,从而帮助用户理解模型的决策逻辑。
这个库主要解决了模型预测缺乏透明度的问题,让开发者能够诊断模型是否学到了正确的特征,还是仅仅依靠背景噪声进行“作弊”。pytorch-grad-cam 非常适合 AI 开发者和研究人员使用,无论是用于模型调试、验证,还是探索新的可解释性算法,它都能提供极大便利。
在技术上,它集成了 GradCAM、ScoreCAM、EigenCAM 等多种前沿的像素归因方法,支持 CNN 和 Vision Transformer 等主流网络架构。除了基础的图像分类,它还能处理目标检测、语义分割等复杂任务,并提供了评估解释可信度的指标,确保分析结果既美观又科学可靠。
使用场景
某工业视觉公司的算法工程师正在开发一款电路板表面缺陷检测模型,模型在测试集上准确率很高,但在实际产线部署时却频繁将良品误判为次品,急需排查原因。
没有 pytorch-grad-cam 时
- 面对误判结果,工程师只能看到模型输出的“次品”标签和概率值,完全不知道模型是根据图像的哪一部分特征做出的判断,调试如同“盲人摸象”。
- 为了解决误判,只能凭借经验盲目尝试调整超参数、更换骨干网络或重新清洗数据,往往耗费数天时间却收效甚微。
- 缺乏直观的证据来定位问题,无法判断是数据标注错误还是模型学到了错误的特征关联,难以向项目组解释模型失效的原因。
- 产线工人对频繁的“黑盒”误报感到困惑和不信任,导致人机协作困难,AI 项目落地阻力重重。
使用 pytorch-grad-cam 后
- 工程师只需几行代码即可对误判图片生成类激活热力图,直观地看到模型在推理时“关注”的具体图像区域。
- 热力图清晰显示模型关注的是传送带背景的阴影而非电路板本身的划痕,迅速定位到“背景干扰”这一根本原因,从而针对性地进行数据增强。
- 支持多种先进算法(如 GradCAM++、EigenCAM),适用于工程师手头的 CNN 和 Vision Transformer 等不同架构,无需自行编写复杂的梯度计算代码。
- 通过可视化图表向非技术人员展示模型决策依据,不仅快速解决了误判问题,还显著提升了团队对 AI 模型的信任度。
pytorch-grad-cam 将不可见的模型逻辑转化为可视化的热力图,让算法调试从“猜谜游戏”变为“精准诊断”,极大提升了模型优化的效率。
运行环境要求
- 未说明
未说明
未说明

快速开始
![]()
![]()


PyTorch 的高级 AI 可解释性
pip install grad-cam
包含高级教程的文档:https://jacobgil.github.io/pytorch-gradcam-book
这是一个包含计算机视觉可解释人工智能(Explainable AI)最先进方法的软件包。 它可用于诊断模型预测,无论是在生产环境还是模型开发过程中。 其目标也是作为算法和指标的基准,用于研究新的可解释性方法。
⭐ 计算机视觉像素归因(Pixel Attribution)方法的全面集合。
⭐ 在许多常见的 CNN(卷积神经网络)和 Vision Transformers(视觉 Transformer)上进行了测试。
⭐ 高级用例:适用于分类、目标检测、语义分割、嵌入相似度等场景。
⭐ 包含平滑方法,使 CAM(类激活图)看起来更美观。
⭐ 高性能:所有方法均完全支持图像批次处理。
⭐ 包含用于检查解释可信度的指标,并可对其进行调优以获得最佳性能。

| 方法 | 功能 |
|---|---|
| GradCAM | 通过平均梯度对 2D 激活进行加权 |
| HiResCAM | 类似于 GradCAM,但将激活与梯度进行逐元素相乘;对于某些模型可证明保证忠实度 |
| GradCAMElementWise | 类似于 GradCAM,但将激活与梯度进行逐元素相乘,然后在求和前应用 ReLU 操作 |
| GradCAM++ | 类似于 GradCAM,但使用二阶梯度 |
| XGradCAM | 类似于 GradCAM,但通过归一化的激活对梯度进行缩放 |
| AblationCAM | 将激活置零并测量输出下降的程度(本仓库包含快速的批处理实现) |
| ScoreCAM | 通过缩放的激活对图像进行扰动,并测量输出下降的程度 |
| EigenCAM | 获取 2D 激活的第一主成分(无类别区分能力,但似乎能产生很好的结果) |
| EigenGradCAM | 类似于 EigenCAM 但具有类别区分能力:激活*梯度的第一主成分。看起来像 GradCAM,但更清晰 |
| LayerCAM | 通过正梯度在空间上对激活进行加权。在较低层表现更好 |
| FullGrad | 计算网络中所有偏置的梯度,然后将它们相加 |
| Deep Feature Factorizations | 对 2D 激活进行非负矩阵分解 |
| KPCA-CAM | 类似于 EigenCAM,但使用核 PCA(Kernel PCA)代替 PCA |
| FEM | 一种无梯度方法,通过激活 > 均值 + k * 标准差的规则对激活进行二值化。 |
| ShapleyCAM | 使用梯度和海森向量积对激活进行加权。 |
| FinerCAM | 通过比较相似类别、抑制共享特征并突出判别性细节来改进细粒度分类。 |
可视化示例
| 是什么让网络认为图像标签是 'pug, pug-dog' | 是什么让网络认为图像标签是 'tabby, tabby cat' | 将 Grad-CAM 与 Guided Backpropagation 结合用于 'pug, pug-dog' 类 |
|---|---|---|
 |
 |
 |
目标检测和语义分割
| 目标检测 | 语义分割 |
|---|---|
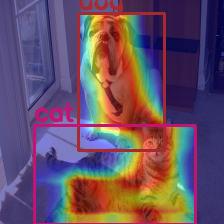 |
 |
| 3D 医疗语义分割 |
|---|
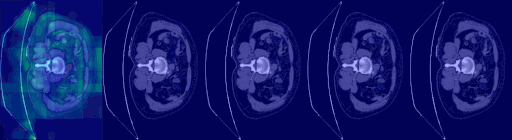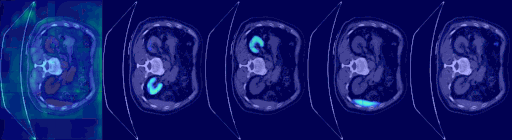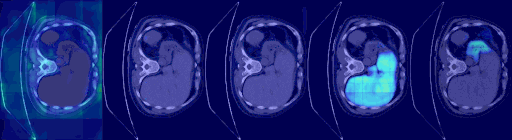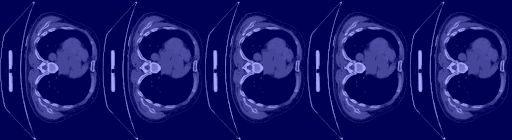 |
解释与其他图像/嵌入的相似度

深度特征分解


CLIP
| 解释文本提示 "a dog" | 解释文本提示 "a cat" |
|---|---|
 |
 |
分类
Resnet50:
| 类别 | 图片 | GradCAM | AblationCAM (消融CAM) | ScoreCAM (得分CAM) |
|---|---|---|---|---|
| Dog (狗) |  |
 |
 |
 |
| Cat (猫) |  |
 |
 |
 |
Vision Transformer (Deit Tiny):
| 类别 | 图片 | GradCAM | AblationCAM (消融CAM) | ScoreCAM (得分CAM) |
|---|---|---|---|---|
| Dog (狗) | |
 |
 |
 |
| Cat (猫) | |
 |
 |
 |
Swin Transformer (Tiny window:7 patch:4 input-size:224):
| 类别 | 图片 | GradCAM | AblationCAM (消融CAM) | ScoreCAM (得分CAM) |
|---|---|---|---|---|
| Dog (狗) | |
 |
 |
 |
| Cat (猫) | |
 |
 |
 |
XAI 的指标与评估


使用示例
from pytorch_grad_cam import GradCAM, HiResCAM, ScoreCAM, GradCAMPlusPlus, AblationCAM, XGradCAM, EigenCAM, FullGrad
from pytorch_grad_cam.utils.model_targets import ClassifierOutputTarget
from pytorch_grad_cam.utils.image import show_cam_on_image
from torchvision.models import resnet50
model = resnet50(pretrained=True)
target_layers = [model.layer4[-1]]
input_tensor = # Create an input tensor image for your model..
# Note: input_tensor can be a batch tensor with several images!
# We have to specify the target we want to generate the CAM for.
targets = [ClassifierOutputTarget(281)]
# Construct the CAM object once, and then re-use it on many images.
with GradCAM(model=model, target_layers=target_layers) as cam:
# You can also pass aug_smooth=True and eigen_smooth=True, to apply smoothing.
grayscale_cam = cam(input_tensor=input_tensor, targets=targets)
# In this example grayscale_cam has only one image in the batch:
grayscale_cam = grayscale_cam[0, :]
visualization = show_cam_on_image(rgb_img, grayscale_cam, use_rgb=True)
# You can also get the model outputs without having to redo inference
model_outputs = cam.outputs
cam.py 包含更详细的使用示例。
选择提取激活值的层
你需要选择目标层来计算 CAM (类激活映射)。 一些常见的选择是:
- FasterRCNN: model.backbone
- Resnet18 和 50: model.layer4[-1]
- VGG, densenet161 和 mobilenet: model.features[-1]
- mnasnet1_0: model.layers[-1]
- ViT: model.blocks[-1].norm1
- SwinT: model.layers[-1].blocks[-1].norm1
如果你传入一个包含多个层的列表,CAM 将在这些层上进行平均。 如果你不确定哪一层表现最好,这会很有用。
适配新的架构和任务
像 GradCAM (梯度加权类激活映射) 这样的方法是为分类模型设计的,最初主要应用于分类模型,特别是 CNN (卷积神经网络) 分类模型。 然而,你也可以将此库用于新的架构,如 Vision Transformer (视觉 Transformer),以及非分类任务,如目标检测或语义分割。
为了能够适应非标准情况,我们有两个概念。
- Reshape Transform (形状变换) —— 我们如何将激活值转换为代表空间图像的形式?
- Model Targets (模型目标) —— 可解释性方法究竟应该尝试解释什么?
reshape_transform 参数
在 CNN 中,模型的中间激活值是一个具有通道 x 行 x 列维度的多通道图像,各种可解释性方法利用这些值来生成新图像。
对于其他架构,例如 Vision Transformer,形状可能会有所不同,例如 (行 x 列 + 1) x 通道,或者其他形式。 Reshape Transform 将激活值转换回多通道图像,例如通过移除 Vision Transformer 中的 class token (类标记)。 示例请查看 这里
model_target 参数
Model Target 只是一个可调用对象,它能够获取模型输出,并筛选出我们想要解释的特定标量输出。
对于分类任务,Model Target 通常是特定类别的输出。
传递给 CAM 方法的 targets 参数可以使用 ClassifierOutputTarget:
targets = [ClassifierOutputTarget(281)]
然而,对于更高级的情况,你可能需要不同的行为。 查看 这里 获取更多示例。
教程
这里您可以找到关于如何将其用于各种自定义用例(如目标检测)的详细示例:
这些链接指向新的文档 jupyter-book 以实现快速渲染。 Jupyter notebooks 本身可以在 git 仓库的 tutorials 文件夹下找到。
引导反向传播
from pytorch_grad_cam import GuidedBackpropReLUModel
from pytorch_grad_cam.utils.image import (
show_cam_on_image, deprocess_image, preprocess_image
)
gb_model = GuidedBackpropReLUModel(model=model, device=model.device())
gb = gb_model(input_tensor, target_category=None)
cam_mask = cv2.merge([grayscale_cam, grayscale_cam, grayscale_cam])
cam_gb = deprocess_image(cam_mask * gb)
result = deprocess_image(gb)
指标与评估解释
from pytorch_grad_cam.utils.model_targets import ClassifierOutputSoftmaxTarget
from pytorch_grad_cam.metrics.cam_mult_image import CamMultImageConfidenceChange
# Create the metric target, often the confidence drop in a score of some category
metric_target = ClassifierOutputSoftmaxTarget(281)
scores, batch_visualizations = CamMultImageConfidenceChange()(input_tensor,
inverse_cams, targets, model, return_visualization=True)
visualization = deprocess_image(batch_visualizations[0, :])
# State of the art metric: Remove and Debias
from pytorch_grad_cam.metrics.road import ROADMostRelevantFirst, ROADLeastRelevantFirst
cam_metric = ROADMostRelevantFirst(percentile=75)
scores, perturbation_visualizations = cam_metric(input_tensor,
grayscale_cams, targets, model, return_visualization=True)
# You can also average across different percentiles, and combine
# (LeastRelevantFirst - MostRelevantFirst) / 2
from pytorch_grad_cam.metrics.road import ROADMostRelevantFirstAverage,
ROADLeastRelevantFirstAverage,
ROADCombined
cam_metric = ROADCombined(percentiles=[20, 40, 60, 80])
scores = cam_metric(input_tensor, grayscale_cams, targets, model)
平滑处理以获得美观的 CAM
为了减少 CAM (类别激活映射) 中的噪声,并使其更好地贴合目标物体,支持两种平滑方法:
aug_smooth=True测试时增强:运行时间增加 6 倍。
应用水平翻转和将图像乘以 [1.0, 1.1, 0.9] 的组合。
这具有将 CAM 更好地集中在物体周围的效果。
eigen_smooth=Trueactivations*weights的第一主成分。这具有消除大量噪声的效果。
| AblationCAM | aug 平滑 | eigen 平滑 | aug+eigen 平滑 |
|---|---|---|---|
 |
 |
 |
 |
运行示例脚本:
用法: python cam.py --image-path <path_to_image> --method <method> --output-dir <output_dir_path>
若要使用特定设备,如 cpu、cuda、cuda:0、mps 或 hpu:
python cam.py --image-path <path_to_image> --device cuda --output-dir <output_dir_path>
您可以在以下方法中进行选择:
GradCAM , HiResCAM, ScoreCAM, GradCAMPlusPlus, AblationCAM, XGradCAM , LayerCAM, FullGrad, EigenCAM, ShapleyCAM, 和 FinerCAM。
某些方法如 ScoreCAM 和 AblationCAM 需要大量的前向传播,并具有批处理实现。
您可以使用 cam.batch_size = 来控制批大小。
引用
如果您在研究中使用此代码,请引用。以下是一个 BibTeX 条目示例:
@misc{jacobgilpytorchcam,
title={PyTorch library for CAM methods},
author={Jacob Gildenblat and contributors},
year={2021},
publisher={GitHub},
howpublished={\url{https://github.com/jacobgil/pytorch-grad-cam}},
}
参考文献
https://arxiv.org/abs/1610.02391
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra
https://arxiv.org/abs/2011.08891
Use HiResCAM instead of Grad-CAM for faithful explanations of convolutional neural networks Rachel L. Draelos, Lawrence Carin
https://arxiv.org/abs/1710.11063
Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks Aditya Chattopadhyay, Anirban Sarkar, Prantik Howlader, Vineeth N Balasubramanian
https://arxiv.org/abs/1910.01279
Score-CAM: Score-Weighted Visual Explanations for Convolutional Neural Networks Haofan Wang, Zifan Wang, Mengnan Du, Fan Yang, Zijian Zhang, Sirui Ding, Piotr Mardziel, Xia Hu
https://ieeexplore.ieee.org/abstract/document/9093360/
Ablation-cam: Visual explanations for deep convolutional network via gradient-free localization. Saurabh Desai and Harish G Ramaswamy. In WACV, pages 972–980, 2020
https://arxiv.org/abs/2008.02312
Axiom-based Grad-CAM: Towards Accurate Visualization and Explanation of CNNs Ruigang Fu, Qingyong Hu, Xiaohu Dong, Yulan Guo, Yinghui Gao, Biao Li
https://arxiv.org/abs/2008.00299
Eigen-CAM: Class Activation Map using Principal Components Mohammed Bany Muhammad, Mohammed Yeasin
http://mftp.mmcheng.net/Papers/21TIP_LayerCAM.pdf
LayerCAM: Exploring Hierarchical Class Activation Maps for Localization Peng-Tao Jiang; Chang-Bin Zhang; Qibin Hou; Ming-Ming Cheng; Yunchao Wei
https://arxiv.org/abs/1905.00780
Full-Gradient Representation for Neural Network Visualization Suraj Srinivas, Francois Fleuret
https://arxiv.org/abs/1806.10206
Deep Feature Factorization For Concept Discovery Edo Collins, Radhakrishna Achanta, Sabine Süsstrunk
https://arxiv.org/abs/2410.00267
KPCA-CAM: Visual Explainability of Deep Computer Vision Models using Kernel PCA Sachin Karmani, Thanushon Sivakaran, Gaurav Prasad, Mehmet Ali, Wenbo Yang, Sheyang Tang
https://hal.science/hal-02963298/document
Features Understanding in 3D CNNs for Actions Recognition in Video Kazi Ahmed Asif Fuad, Pierre-Etienne Martin, Romain Giot, Romain Bourqui, Jenny Benois-Pineau, Akka Zemmar
https://arxiv.org/abs/2501.06261
CAMs as Shapley Value-based Explainers Huaiguang Cai
https://arxiv.org/pdf/2501.11309
Finer-CAM : Spotting the Difference Reveals Finer Details for Visual ExplanationZiheng Zhang*, Jianyang Gu*, Arpita Chowdhury, Zheda Mai, David Carlyn,Tanya Berger-Wolf, Yu Su, Wei-Lun Chao
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。