cml
CML(Continuous Machine Learning)是一款面向机器学习运维(MLOps)的开源命令行工具,致力于让机器学习项目也能享受持续集成与交付(CI/CD)带来的便利。它主要解决 ML 实验中模型训练、评估及结果汇报繁琐的问题,避免人工整理指标的低效与误差。
CML 特别适合机器学习工程师、数据科学家以及希望建立标准化 ML 流程的研发团队。其核心亮点在于将 Git 工作流理念引入数据科学,无需部署额外的数据库或服务,直接依托 GitHub、GitLab 等现有平台即可运行。每当发起代码合并请求时,CML 会自动执行模型训练与评估,并在 PR 页面生成包含关键指标和可视化图表的报告。此外,CML 还能与 DVC 无缝配合,帮助团队更好地管理数据与模型版本,让每一次实验变更都清晰可追溯,助力团队做出更明智的数据驱动决策。
使用场景
某电商风控团队正在开发用户信用评分模型,面临频繁迭代与协作效率低下的挑战。
没有 cml 时
- 每次算法调整都需要工程师手动在服务器执行训练脚本,占用大量计算资源且易遗漏步骤。
- 实验产生的准确率、召回率等指标分散在本地日志文件中,难以跨分支进行横向对比。
- 代码审查人员无法直观评估模型变更带来的性能波动,往往直到上线后才发现问题。
- 数据分布发生变化时,缺乏自动化机制来预警模型可能出现的性能衰退。
使用 cml 后
- 代码提交即自动触发训练任务,cml 无需人工介入即可验证新策略的有效性。
- 每个 Pull Request 会自动生成包含可视化图表和关键指标的评论报告,一目了然。
- 团队成员可直接在 PR 界面查看当前版本与基线模型的详细性能对比数据。
- 结合 DVC 管理数据版本,自动监测数据集变化并关联模型评估结果,确保稳定性。
cml 将机器学习工程化落地,实现了从代码提交到模型评估的闭环自动化。
运行环境要求
- Linux
未说明
未说明
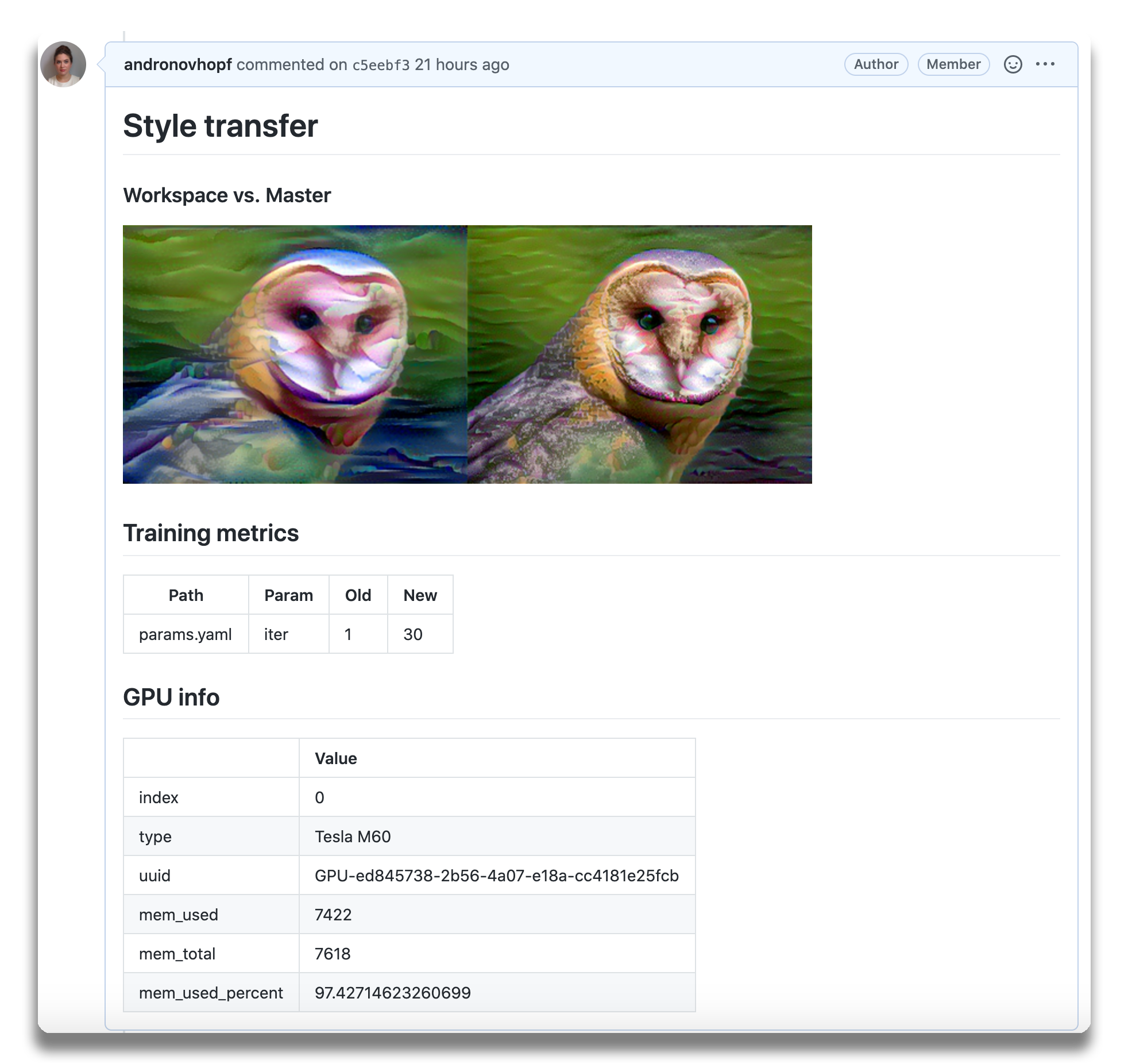
快速开始



什么是 CML? 连续机器学习(CML)是一个开源的命令行界面 (CLI) 工具,专注于 MLOps,用于实现持续集成与交付 (CI/CD)。使用它来自动化开发工作流——包括机器配置、模型训练和评估、跨项目历史比较 ML 实验,以及监控变化的数据集。
CML 可以帮助训练和评估模型——并在每次 pull request (拉取请求) 时自动生成包含结果和指标的可视化报告。
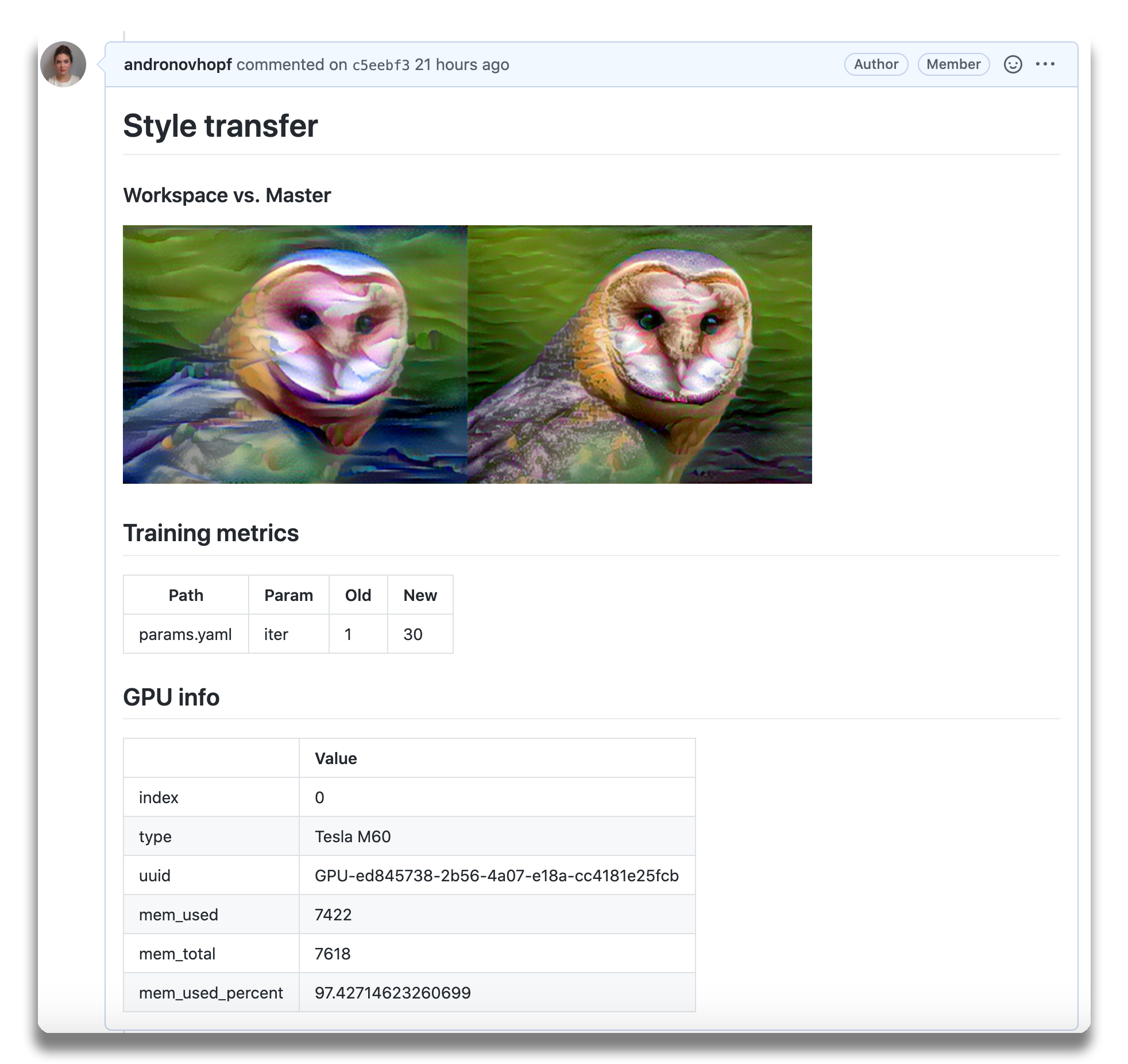 一个 神经风格迁移模型 的报告示例。
一个 神经风格迁移模型 的报告示例。
CML 原则:
- GitFlow 用于数据科学。 使用 GitLab 或 GitHub 管理 ML 实验,跟踪谁训练了 ML 模型或修改了数据及时间。使用 DVC 对数据和模型进行代码化管理,而不是推送到 Git 仓库。
- ML 实验自动报告。 在每个 Git pull request 中自动生成带有指标和图表的报告。严谨的工程实践帮助您的团队做出明智的、数据驱动的决策。
- 无需额外服务。 使用 GitLab、Bitbucket 或 GitHub 构建您自己的 ML 平台。可选地,使用 云存储 以及自托管或云运行器(如 AWS EC2 或 Azure)。无需数据库、服务或复杂设置。
:question: 需要帮助?只是想聊聊 ML 的持续集成吗?访问我们的 Discord 频道!
:play_or_pause_button: 查看我们的 YouTube 视频系列,获取使用 CML 的动手 MLOps 教程!
目录
设置
您需要一个 GitLab、GitHub 或 Bitbucket 账户才能开始。用户可能希望熟悉 Github Actions 或 GitLab CI/CD。这里我们将讨论 GitHub 用例。
GitLab
请参阅我们关于 CML with GitLab CI/CD 的文档,特别是 personal access token (个人访问令牌) 要求。
Bitbucket
请参阅我们关于 CML with Bitbucket Cloud 的文档。
GitHub
任何 CML 项目中的关键文件是 .github/workflows/cml.yaml:
name: your-workflow-name
on: [push]
jobs:
run:
runs-on: ubuntu-latest
# optionally use a convenient Ubuntu LTS + DVC + CML image
# container: ghcr.io/iterative/cml:0-dvc2-base1
steps:
- uses: actions/checkout@v3
# may need to setup NodeJS & Python3 on e.g. self-hosted
# - uses: actions/setup-node@v3
# with:
# node-version: '16'
# - uses: actions/setup-python@v4
# with:
# python-version: '3.x'
- uses: iterative/setup-cml@v1
- name: Train model
run: |
# Your ML workflow goes here
pip install -r requirements.txt
python train.py
- name: Write CML report
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
# Post reports as comments in GitHub PRs
cat results.txt >> report.md
cml comment create report.md
用法
我们在 自定义 Docker 镜像 上预先安装了 CML 和其他有用的库。在上面的示例中,取消注释字段 container: ghcr.io/iterative/cml:0-dvc2-base1) 将使运行器拉取 CML Docker 镜像。该镜像为了方便起见,已在 Ubuntu LTS 基础之上设置了 Node.js、Python 3、DVC 和 CML。
CML 函数
CML 提供了一系列函数,帮助将 ML 工作流的输出(包括数值数据和关于模型性能的可视化)打包到 CML 报告中。
以下是用于编写 Markdown 报告并将这些报告交付给 CI 系统的 CML 函数表。
| 函数 | 描述 | 示例输入 |
|---|---|---|
cml runner launch |
在本地启动运行器或由云提供商托管 | 参见 参数 |
cml comment create |
将 CML 报告作为评论返回到您的 GitLab/GitHub 工作流中 | <path to report> --head-sha <sha> |
cml check create |
将 CML 报告作为检查项返回到 GitHub | <path to report> --head-sha <sha> |
cml pr create |
将给定文件提交到新分支并创建 pull request | <path>... |
cml tensorboard connect |
返回 TensorBoard.dev 页面的链接 | --logdir <path to logs> --title <experiment title> --md |
CML 报告
cml comment create 命令可用于发布报告。CML 报告是用 Markdown 编写的(GitHub、GitLab 或 Bitbucket 风格)。这意味着它们可以包含图片、表格、格式化文本、HTML 块、代码片段等——实际上,您在 CML 报告中放入什么取决于您。一些示例:
:spiral_notepad: 文本 使用您喜欢的方法写入报告。例如,复制包含 ML 模型训练结果的文本文件的内容:
cat results.txt >> report.md
:framed_picture: 图片 使用 Markdown 或 HTML 显示图片。请注意,如果图片是您的 ML 工作流的输出(即由您的工作流生成),它可以被上传并自动包含到您的 CML 报告中。例如,如果 graph.png 是由 python train.py 输出的,请运行:
echo "" >> report.md
cml comment create report.md
开始使用
- Fork(复制)我们的 示例项目仓库。
:warning: 注意,如果您使用的是 GitLab, 您需要创建一个 Personal Access Token(个人访问令牌) 才能使此示例正常工作。
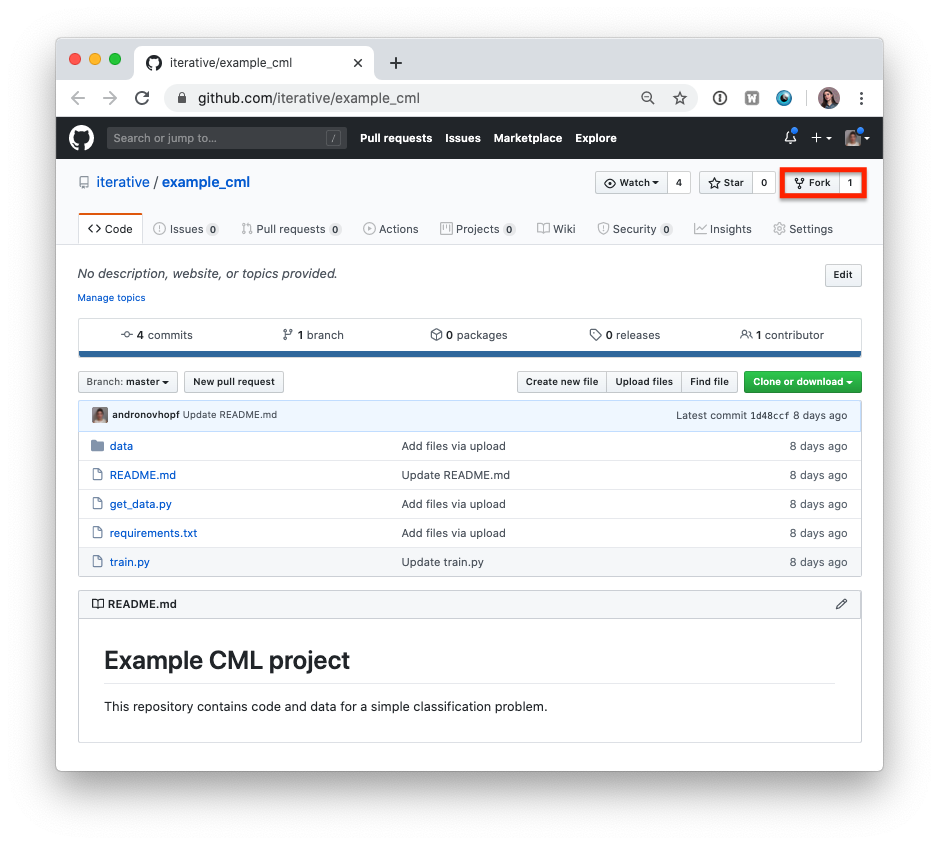
:warning: 以下步骤都可以在 GitHub 浏览器界面中完成。但是,为了跟随命令操作,我们建议将您的 Fork(复制)克隆到本地工作站:
git clone https://github.com/<your-username>/example_cml
- 要创建 CML(Continuous Machine Learning)工作流,请将以下内容复制到新文件
.github/workflows/cml.yaml:
name: model-training
on: [push]
jobs:
run:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: actions/setup-python@v4
- uses: iterative/setup-cml@v1
- name: Train model
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
pip install -r requirements.txt
python train.py
cat metrics.txt >> report.md
echo "" >> report.md
cml comment create report.md
在您选择的文本编辑器中,将
train.py的第 16 行修改为depth = 5。提交并推送更改:
git checkout -b experiment
git add . && git commit -m "modify forest depth"
git push origin experiment
- 在 GitHub 上,打开一个拉取请求(Pull Request)以比较
experiment分支和main分支。
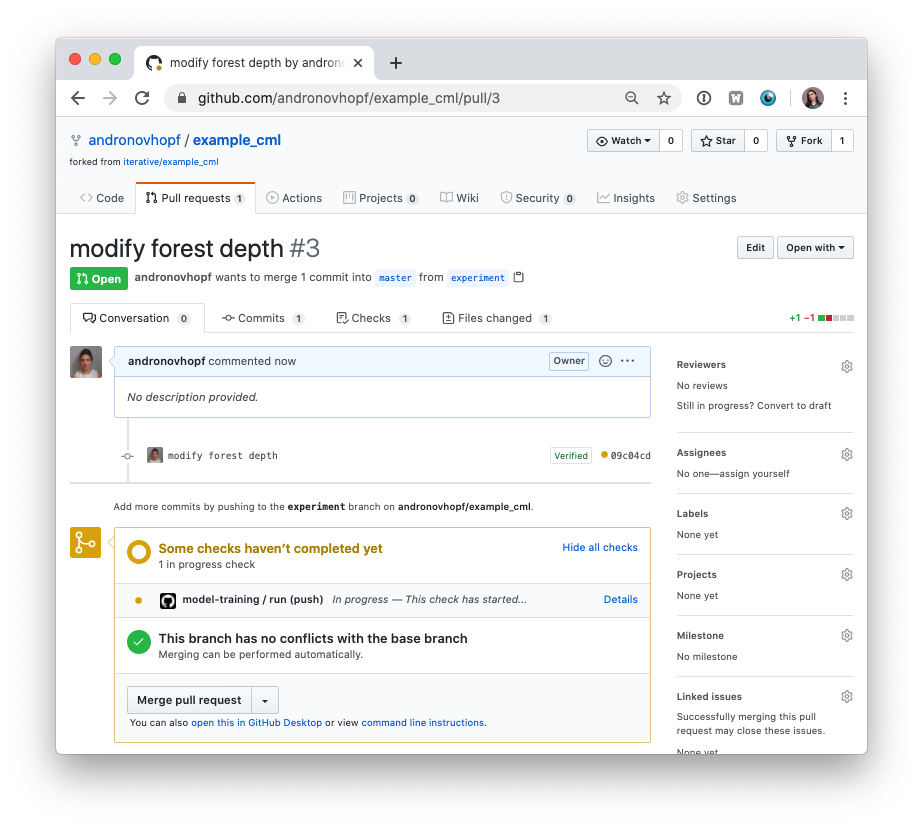
很快,您应该在拉取请求中看到来自 github-actions 的评论,其中包含您的 CML 报告。这是您工作流中 cml send-comment 函数的结果。
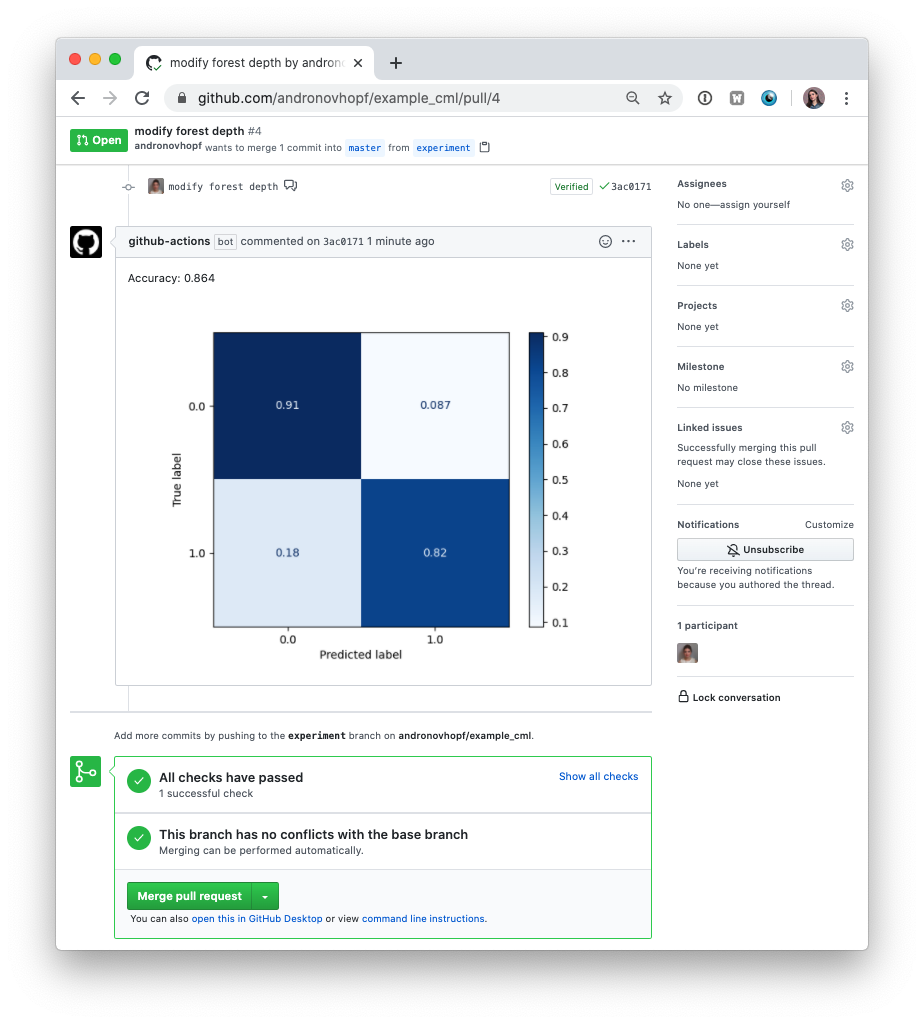
这是 CML 工作流的概述:
- 您将更改推送到 GitHub 仓库,
- 运行
.github/workflows/cml.yaml文件中的工作流,以及 - 生成报告并发布到 GitHub。
CML 功能允许您在 GitHub Checks(检查)和评论中显示工作流的相关结果——例如模型性能指标和可视化图表。您想要运行哪种工作流,以及想要在 CML 报告中放入什么内容,由您决定。
将 CML 与 DVC 结合使用
在许多机器学习(ML)项目中,数据不存储在 Git 仓库中,而是需要从外部来源下载。DVC(Data Version Control)是将数据带入您的 CML 运行器的常见方式。DVC 还允许您可视化不同提交之间的指标差异,从而生成如下报告:
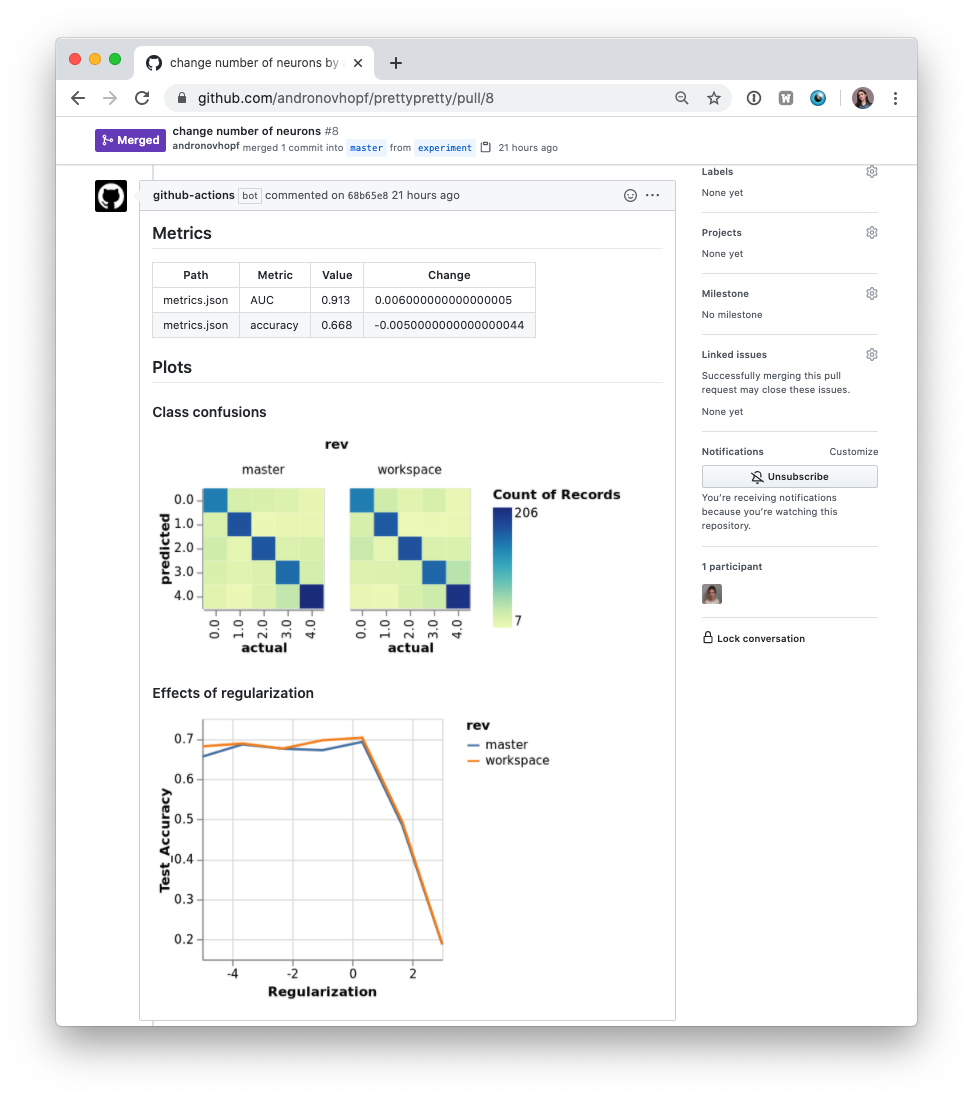
用于创建此报告的 .github/workflows/cml.yaml 文件如下:
name: model-training
on: [push]
jobs:
run:
runs-on: ubuntu-latest
container: ghcr.io/iterative/cml:0-dvc2-base1
steps:
- uses: actions/checkout@v3
- name: Train model
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
run: |
# Install requirements
pip install -r requirements.txt
# Pull data & run-cache from S3 and reproduce pipeline
dvc pull data --run-cache
dvc repro
# Report metrics
echo "## Metrics" >> report.md
git fetch --prune
dvc metrics diff main --show-md >> report.md
# Publish confusion matrix diff
echo "## Plots" >> report.md
echo "### Class confusions" >> report.md
dvc plots diff --target classes.csv --template confusion -x actual -y predicted --show-vega main > vega.json
vl2png vega.json -s 1.5 > confusion_plot.png
echo "" >> report.md
# Publish regularization function diff
echo "### Effects of regularization" >> report.md
dvc plots diff --target estimators.csv -x Regularization --show-vega main > vega.json
vl2png vega.json -s 1.5 > plot.png
echo "" >> report.md
cml comment create report.md
:warning: 如果您将 DVC 与云存储一起使用,请注意您的存储格式的环境变量。
配置云存储提供商
有许多 支持的云存储提供商。 以下是一些最常用提供商的示例:
S3 及兼容 S3 的存储(Minio、DigitalOcean Spaces、IBM Cloud Object Storage...)
# Github
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
AWS_SESSION_TOKEN: ${{ secrets.AWS_SESSION_TOKEN }}
:point_right:
AWS_SESSION_TOKEN是可选的。
:point_right:
AWS_ACCESS_KEY_ID和AWS_SECRET_ACCESS_KEY也可被cml runner(运行器)用于启动 EC2 实例。请参阅 [环境变量]。
Azure
env:
AZURE_STORAGE_CONNECTION_STRING:
${{ secrets.AZURE_STORAGE_CONNECTION_STRING }}
AZURE_STORAGE_CONTAINER_NAME: ${{ secrets.AZURE_STORAGE_CONTAINER_NAME }}
Aliyun
env:
OSS_BUCKET: ${{ secrets.OSS_BUCKET }}
OSS_ACCESS_KEY_ID: ${{ secrets.OSS_ACCESS_KEY_ID }}
OSS_ACCESS_KEY_SECRET: ${{ secrets.OSS_ACCESS_KEY_SECRET }}
OSS_ENDPOINT: ${{ secrets.OSS_ENDPOINT }}
Google Storage
:warning: 通常,
GOOGLE_APPLICATION_CREDENTIALS是包含凭据的 JSON 文件的路径。但在该 Action 中,此密钥变量是文件的内容。复制 JSON 内容并将其添加为密钥。
env:
GOOGLE_APPLICATION_CREDENTIALS: ${{ secrets.GOOGLE_APPLICATION_CREDENTIALS }}
Google Drive
:warning: 配置您的 Google Drive 凭据 后,您将在
your_project_path/.dvc/tmp/gdrive-user-credentials.json找到一个 JSON 文件。复制其内容 并将其添加为密钥变量。
env:
GDRIVE_CREDENTIALS_DATA: ${{ secrets.GDRIVE_CREDENTIALS_DATA }}
高级设置
自托管(本地或云端)运行器
默认情况下,GitHub Actions 在 GitHub 托管的运行器上运行。但是,使用自己的运行器有很多很好的理由:利用 GPU、协调团队共享的计算资源,或在云端进行训练。
:point_up: 提示! 查看 官方 GitHub 文档 以开始设置您自己的自托管运行器。
使用 CML 分配云计算资源
当工作流需要计算资源(如 GPU)时,CML 可以使用 cml runner(CML Runner)自动分配云实例。你可以在 AWS、Azure、GCP 或 Kubernetes 上启动实例。
例如,以下工作流在 AWS EC2 上部署一个 g4dn.xlarge 实例并在该实例上训练模型。作业运行后,实例会自动关闭。
你可能会注意到这个工作流与上面的 基本用例 非常相似。唯一的区别是增加了 cml runner 和一些环境变量,用于将云服务凭证传递给工作流。
请注意,cml runner 也会自动重启你的任务(无论是由于 GitHub Actions 35 天工作流超时 还是 AWS EC2 竞价实例中断)。
name: Train-in-the-cloud
on: [push]
jobs:
deploy-runner:
runs-on: ubuntu-latest
steps:
- uses: iterative/setup-cml@v1
- uses: actions/checkout@v3
- name: Deploy runner on EC2
env:
REPO_TOKEN: ${{ secrets.PERSONAL_ACCESS_TOKEN }}
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
run: |
cml runner launch \
--cloud=aws \
--cloud-region=us-west \
--cloud-type=g4dn.xlarge \
--labels=cml-gpu
train-model:
needs: deploy-runner
runs-on: [self-hosted, cml-gpu]
timeout-minutes: 50400 # 35 days
container:
image: ghcr.io/iterative/cml:0-dvc2-base1-gpu
options: --gpus all
steps:
- uses: actions/checkout@v3
- name: Train model
env:
REPO_TOKEN: ${{ secrets.PERSONAL_ACCESS_TOKEN }}
run: |
pip install -r requirements.txt
python train.py
cat metrics.txt > report.md
cml comment create report.md
在上述工作流中,deploy-runner 步骤在 us-west 区域启动了一个 EC2 g4dn.xlarge 实例。然后 model-training 步骤在新启动的实例上运行。有关所需 secrets(机密)的详细信息,请参见下方的 [环境变量]。
:tada: 注意:作业可以使用任何 Docker 容器! 要从作业中使用
cml send-comment等功能,唯一的要求是 安装 CML。
Docker 镜像
CML Docker 镜像(ghcr.io/iterative/cml 或 iterativeai/cml)预装了 Python、CUDA、git、node 以及全栈数据科学所需的其他基础组件。这些基础组件的不同版本可通过不同的镜像标签获取。标签约定为 {CML_VER}-dvc{DVC_VER}-base{BASE_VER}{-gpu}:
{BASE_VER} |
包含的软件(-gpu) |
|---|---|
| 0 | Ubuntu 18.04, Python 2.7 (CUDA 10.1, CuDNN 7) |
| 1 | Ubuntu 20.04, Python 3.8 (CUDA 11.2, CuDNN 8) |
例如,iterativeai/cml:0-dvc2-base1-gpu,或 ghcr.io/iterative/cml:0-dvc2-base1。
参数
cml runner launch 函数接受以下参数:
--labels 一个或多个用户定义的标签,用于此运行器 (Runner)(以逗号分隔) [string] [default: "cml"] --idle-timeout 关闭前等待作业的时间(例如 "5min")。使用 "never" 可禁用 [string] [default: "5 minutes"] --name 注册后在仓库中显示的名称 [string] [default: cml-{ID}] --no-retry 不重启因实例销毁或 GitHub Actions 超时而终止的工作流 [boolean] --single 运行单个作业后退出 [boolean] --reuse 如果已存在的运行器具有相同名称或 重叠的标签,则不启动新的运行器 [boolean] --reuse-idle 仅当匹配的标签不存在或已占用时,才 创建新的运行器 [boolean] --docker-volumes Docker 卷,仅在 GitLab 中支持 [array] [default: []] --cloud 部署运行器的云服务 [string] [choices: "aws", "azure", "gcp", "kubernetes"] --cloud-region 实例部署的区域。选项:[us-east, us-west, eu-west, eu-north]。也 接受原生云区域 [string] [default: "us-west"] --cloud-type 实例类型。选项:[m, l, xl]。 也支持原生类型,如 t2.micro [string] --cloud-permission-set 指定 AWS 中的实例配置文件或 GCP 中的实例服务账户 [string] [default: ""] --cloud-metadata 与提供商上的 cml-runner 实例关联 的键值对,即标签/标签 "key=value" [array] [default: []] --cloud-gpu GPU 类型。选项:k80, v100,或 原生类型,例如 nvidia-tesla-t4 [string] --cloud-hdd-size HDD 大小(GB) [number] --cloud-ssh-private 自定义私有 RSA SSH 密钥。如果未 提供,将使用自动生成的临时密钥 [string] --cloud-spot 请求抢占式实例 [boolean] --cloud-spot-price 抢占式实例的最高竞价价格 (美元)。默认为当前竞价价格 [number] [default: -1] --cloud-startup-script 在实例初始化期间运行提供的 Base64 编码 的 Linux shell 脚本 [string] --cloud-aws-security-group 指定 AWS 中的安全组 [string] [default: ""] --cloud-aws-subnet, 指定要在 AWS 内使用的子网 --cloud-aws-subnet-id AWS [string] [default: ""]
环境变量
:warning: 你需要 创建一个个人访问令牌 (PAT) 并拥有仓库读写权限及工作流权限。在示例工作流中,此令牌存储为
PERSONAL_ACCESS_TOKEN。
:information_source: 如果使用 --cloud 选项,你还需要提供云计算资源的访问凭据作为机密。在
上述示例中,需要提供 AWS_ACCESS_KEY_ID 和 AWS_SECRET_ACCESS_KEY(具有创建和销毁 EC2 实例的权限)。
对于 AWS,相同的凭据也可用于 配置云存储。
代理支持
CML 通过已知环境变量 http_proxy 和
https_proxy 支持代理。
本地部署 (On-premise) 运行器
这意味着使用本地部署的机器作为自托管运行器。cml runner launch 函数用于设置本地自托管运行器。在本地机器或本地 GPU 集群上,
安装 CML 包,然后运行:
cml runner launch \
--repo=$your_project_repository_url \
--token=$PERSONAL_ACCESS_TOKEN \
--labels="local,runner" \
--idle-timeout=180
该机器将监听来自项目仓库的工作流。
本地包
在上述示例中,CML 是通过 setup-cml action 安装的,或者随持续集成 (CI) 运行器拉取的自定义 Docker 镜像预装。您也可以将 CML 作为包进行安装:
npm install --location=global @dvcorg/cml
您可以通过从 releases 的资源部分下载适用于您系统的正确独立二进制文件,从而在不使用 Node 的情况下使用 cml。
您可能需要安装额外的依赖项才能使用 DVC 图表和 Vega-Lite 命令行命令:
sudo apt-get install -y libcairo2-dev libpango1.0-dev libjpeg-dev libgif-dev \
librsvg2-dev libfontconfig-dev
npm install -g vega-cli vega-lite
CML 和 Vega-Lite 包的安装需要 NodeJS 包管理器(npm),该管理器随 NodeJS 一同提供。安装说明如下。
安装 NodeJS
- GitHub:在使用 GitHub 默认容器或 CML 的 Docker 容器之一时,这可能不是必需的。自托管运行器可能需要使用设置 action 来安装 NodeJS:
uses: actions/setup-node@v3
with:
node-version: '16'
- GitLab:需要直接安装。
curl -sL https://deb.nodesource.com/setup_16.x | bash
apt-get update
apt-get install -y nodejs
参见
以下是一些使用 CML 的示例项目。
:key: 需要 个人访问令牌 (PAT)。
:warning: 维护 :warning:
版本历史
v0.19.02023/06/04v0.18.212023/02/14v0.18.202023/02/02v0.18.192023/02/02v0.18.182023/02/13v0.18.172023/01/17v0.18.162023/01/17v0.18.152023/01/16v0.18.142022/12/22v0.18.132022/12/02v0.18.122022/12/02v0.18.102022/11/11v0.20.62024/10/24v0.20.52024/10/24v0.20.42024/05/28v0.20.32024/05/11v0.20.22024/05/11v0.20.12024/05/10v0.20.02023/08/25v0.19.12023/06/21常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。