UI-Venus
UI-Venus 是一款原生的图形界面(GUI)智能体,专为通过屏幕截图精准定位界面元素并执行复杂导航任务而设计。它主要解决了传统自动化工具在面对动态变化、多步骤操作及不同应用界面时适应性差、容易出错的难题,能够像人类一样“看懂”屏幕并自主完成指令。
无论是需要构建自动化测试流程的开发者、研究多模态交互的科研人员,还是希望提升移动端操作效率的技术爱好者,都能从 UI-Venus 中获益。其最新发布的 1.5 版本在技术上颇具亮点:采用了包含密集模型与混合专家(MoE)架构的统一端到端方案,并通过千万级 token 的中间阶段训练和在线强化学习,显著提升了长程任务规划能力。该模型不仅融合了网页与移动端的专业技能,更在多个权威基准测试中取得领先成绩,尤其在四十多款中文主流移动应用(如喜马拉雅、微博、小红书等)中展现出卓越的鲁棒性与实操能力,是实现真实场景下智能人机交互的有力助手。
使用场景
某大型电商公司的自动化测试团队需要每日对旗下 App 在安卓端的 50+ 核心业务流程(如领券、下单、查看物流)进行回归测试,以确保新版本上线后的功能稳定性。
没有 UI-Venus 时
- 脚本维护成本极高:传统自动化依赖固定的控件 ID 或 XPath,一旦 App 界面微调或更新,大量测试脚本立即失效,工程师需花费数天重新定位元素。
- 复杂指令难以执行:面对“查找销量最高且评分大于 4.8 的商品”这类多步逻辑任务,传统工具无法理解语义,必须编写冗长且脆弱的硬编码逻辑。
- 跨应用场景割裂:若流程涉及从微信跳转到自家 App 再返回,不同工具间难以协同,往往需要人工介入或放弃覆盖此类真实用户路径。
- 视觉识别能力弱:对于纯图片展示的按钮或非标准控件,传统 OCR 或模板匹配准确率低下,导致测试频繁误报或漏测。
使用 UI-Venus 后
- 纯视觉自适应导航:UI-Venus 仅凭截图即可精准定位 GUI 元素,无需依赖底层代码特征,即使 App 界面频繁迭代,测试流程也能稳定运行,维护工作量减少 90%。
- 自然语言驱动操作:测试人员直接用中文下达“将脑洞榜前三本小说加入书架”等复杂指令,UI-Venus 能自主规划长程步骤并准确执行,大幅降低脚本编写门槛。
- 端到端全链路覆盖:得益于其强大的移动端泛化能力,UI-Venus 能流畅处理跨应用跳转及动态内容加载,完美复现真实用户在 40+ 主流中文 App 中的操作路径。
- 高精度元素接地:在 ScreenSpot-Pro 等基准测试中达到 SOTA 水平,确保了对模糊图标、动态广告等复杂视觉元素的精准点击,显著提升测试通过率。
UI-Venus 通过将自然语言指令直接转化为高鲁棒性的屏幕操作,彻底解决了传统自动化测试在动态 UI 和复杂逻辑面前的脆弱性难题。
运行环境要求
- Linux
- 必需 NVIDIA GPU
- 支持单卡或多卡配置(示例显示最多 8 卡)
- 运行 30B MoE 模型建议使用多卡并行(Tensor Parallel),显存需求取决于模型大小:2B/8B 模型需较高显存,30B 模型需多卡分摊(配置中建议 GPU_MEMORY_UTIL=0.8 以防 OOM)
- 需支持 CUDA 环境(具体版本未说明,通常需 11.7+ 以配合现代 PyTorch/vLLM)
未说明(建议根据模型大小配置充足系统内存,运行 30B 模型推荐 64GB+)

快速开始
 UI-Venus 1.5
UI-Venus 1.5
![]()
UI-Venus 1.5 是一款面向稳健真实世界应用的统一端到端 GUI 智能体。该模型家族包含两个密集型(2B/8B)和一个 MoE 型(30B-A3B)变体,以满足各类下游场景需求。
UI-Venus 1.0 的升级点:
- 🔹 训练中期阶段:在 30 多个数据集上进行了 100 亿 token 的预训练,用于构建基础的 GUI 语义理解能力。
- 🔹 在线强化学习:支持全轨迹回放,实现长时程动态导航。
- 🔹 模型融合:整合了视觉定位、网页和移动端专长,形成统一的智能体。
结果: 在 ScreenSpot-Pro(69.6%)、VenusBench-GD(75.0%)、AndroidWorld(77.6%)等基准测试中达到 SOTA 水平,并在 40 多款中国主流移动应用中表现出稳健的导航能力。
📈 UI-Venus 基准性能
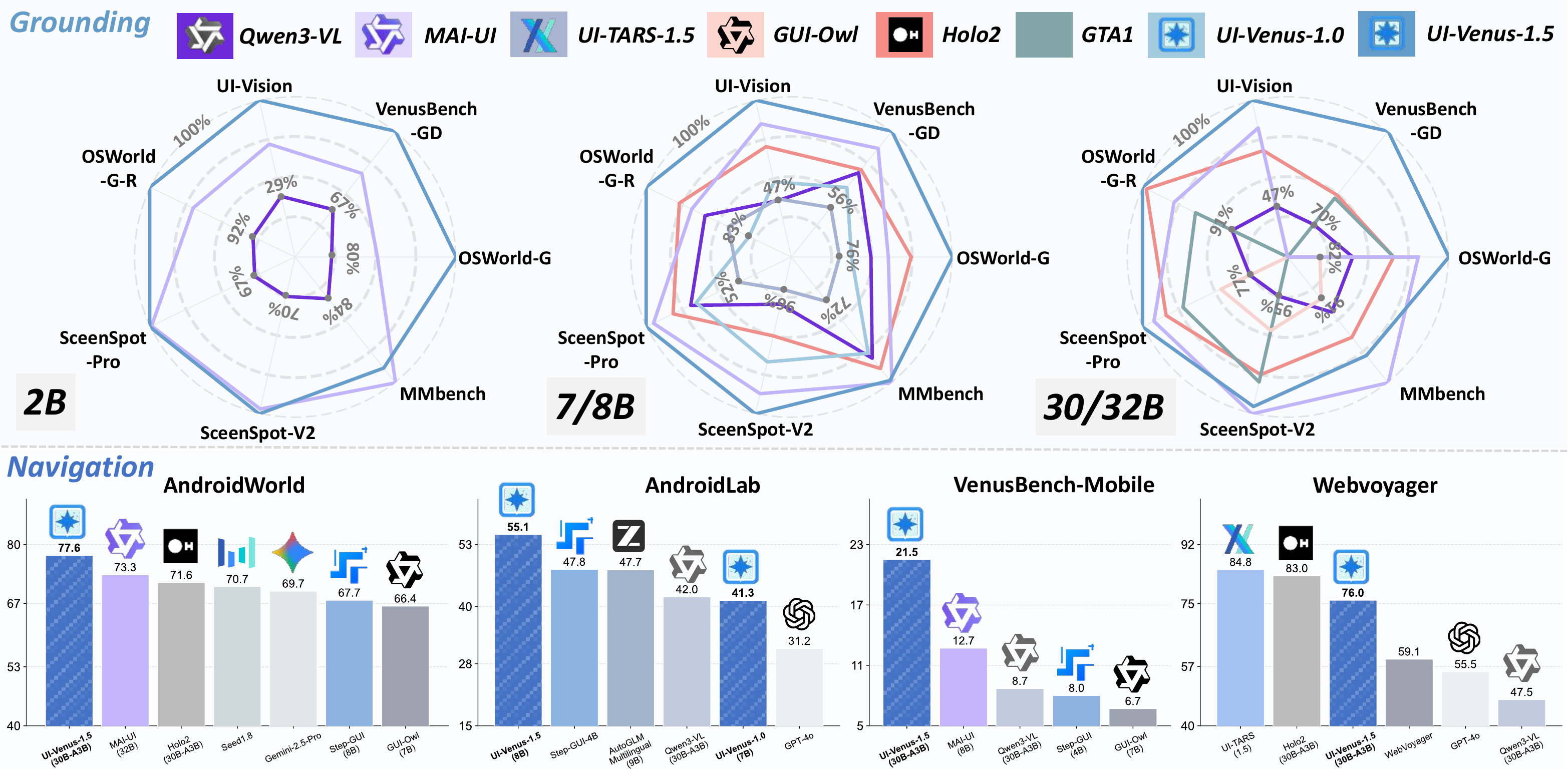
图示: UI-Venus 1.5 在多个基准上的表现。该模型在关键的视觉定位基准(ScreenSpot-Pro、VenusBench-GD、OSWorld-G、UI-Vision)以及智能体基准(AndroidWorld、AndroidLab、VenusBench-Mobile)上均取得了 SOTA 成绩。
🚀 新闻
- [2026年2月] 我们发布了 UI-Venus 1.5,这是一款专为稳健真实世界应用设计的端到端 GUI 智能体。
- [2026年2月] 我们推出了 VenusBench-Mobile,这是一个针对移动端 GUI 智能体的高难度在线基准测试。详情请见分支 VenusBench-Mobile。
- [2025年12月] 我们发布了 VenusBench-GD,这是一个全面的跨平台 GUI 视觉定位基准测试。详情请见分支 VenusBench-GD。
- [2025年8月] 我们发布了 UI-Venus 1.0,这是我们首款 GUI 智能体模型。
概述
✨ 演示
中文应用演示视频 / 中文应用演示视频
Ximalaya - 喜马拉雅
打开喜马拉雅,帮我播放疯狂动物城2,设置列表循环播放。
打开喜马拉雅,播放“Zootopia 2”,并设置为列表循环模式。

Qimao Novel - 七猫免费小说
打开七猫免费小说,将小说脑洞榜前三名都加入书架。
打开七猫免费小说,把“脑洞榜”前三名的小说添加到书架上。
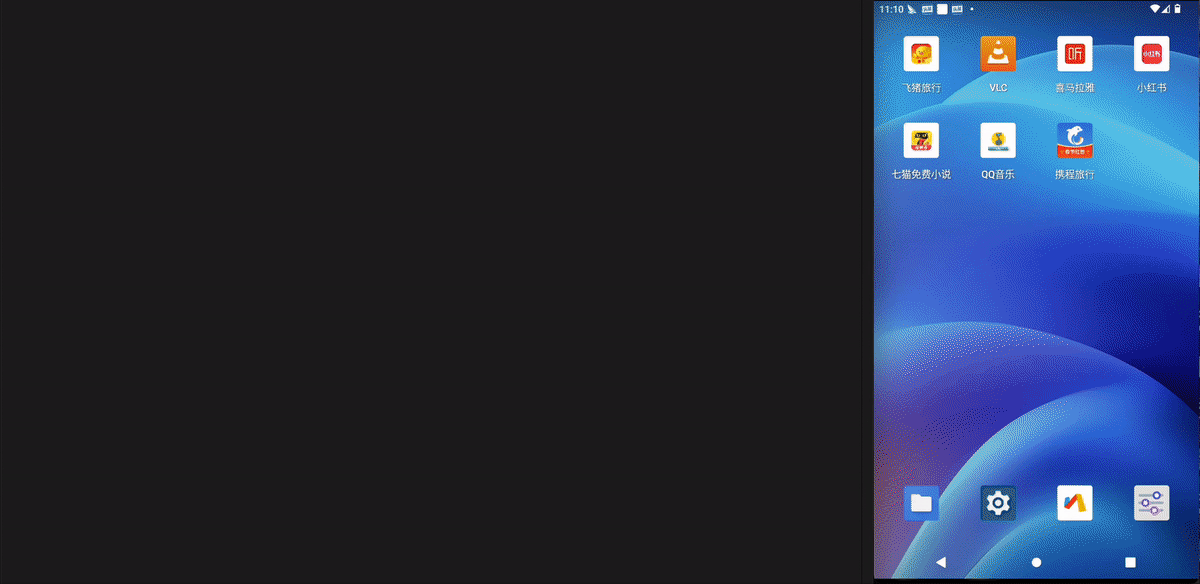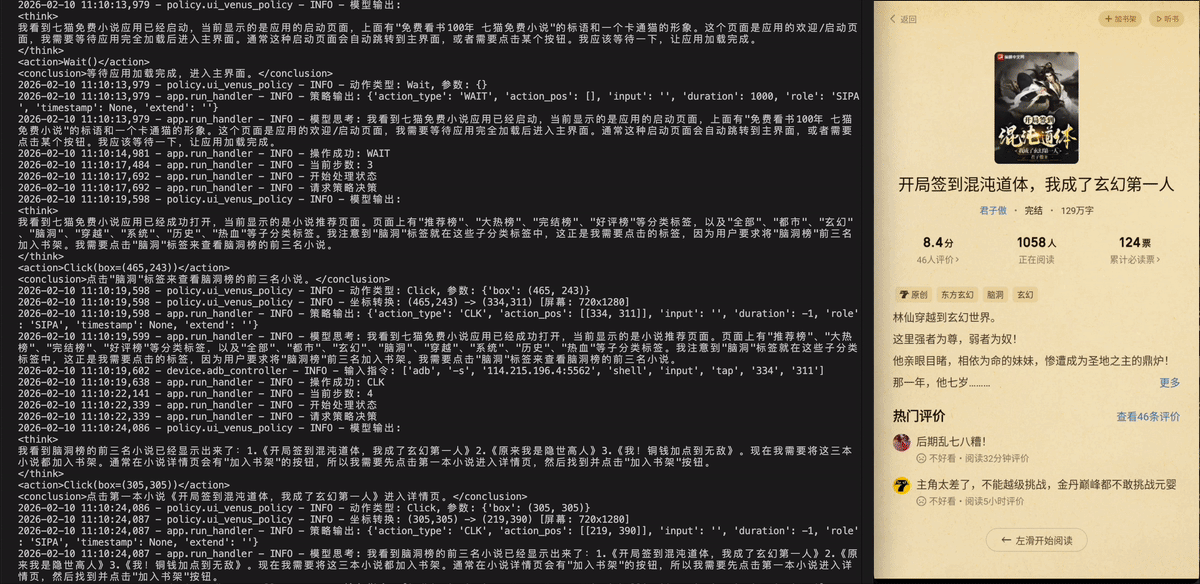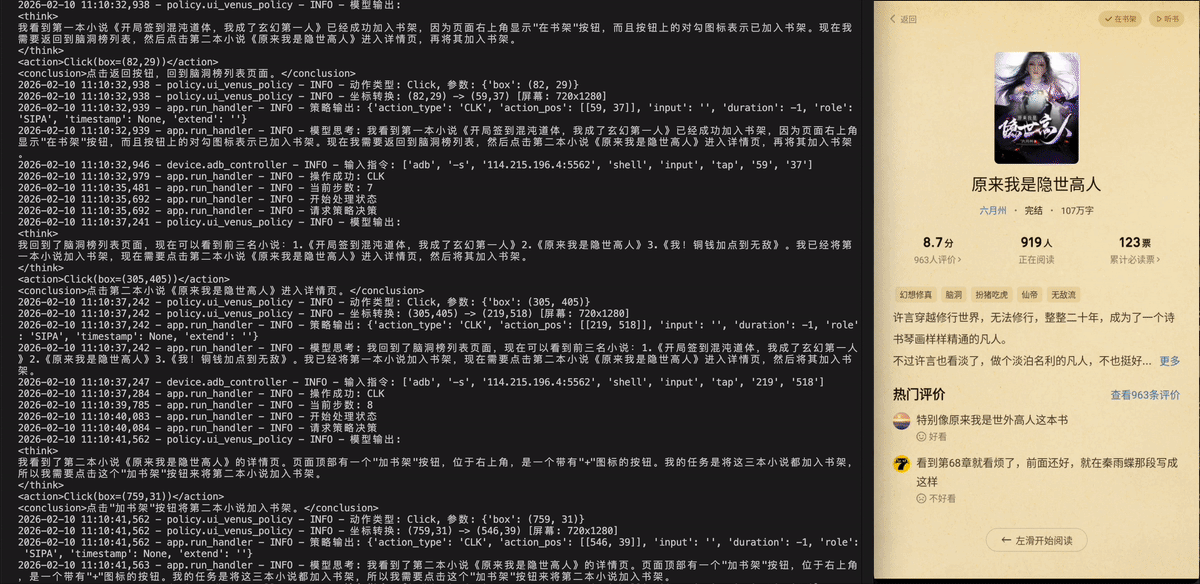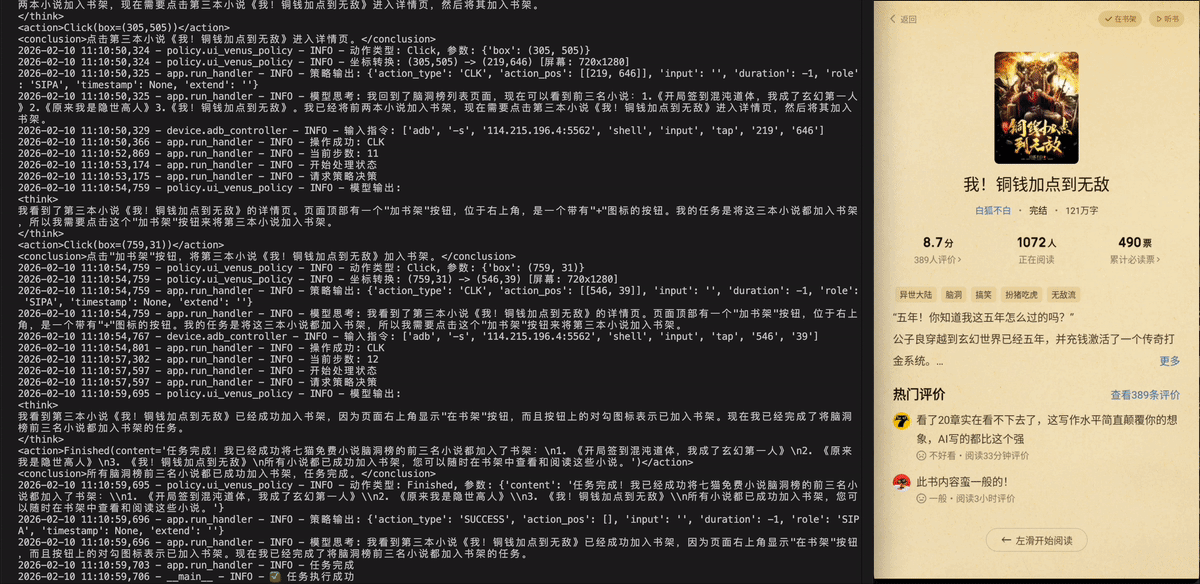
Weibo - 微博
打开微博,搜索杭州天气,并根据天气进行评论。
打开微博,搜索“杭州天气”,然后根据当前天气状况发表评论。
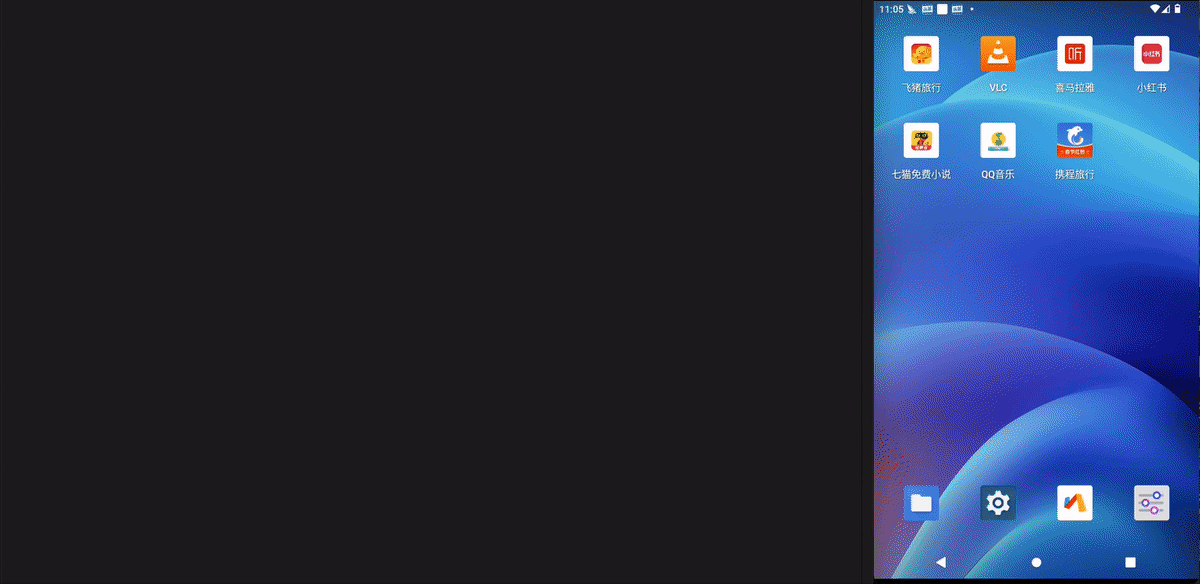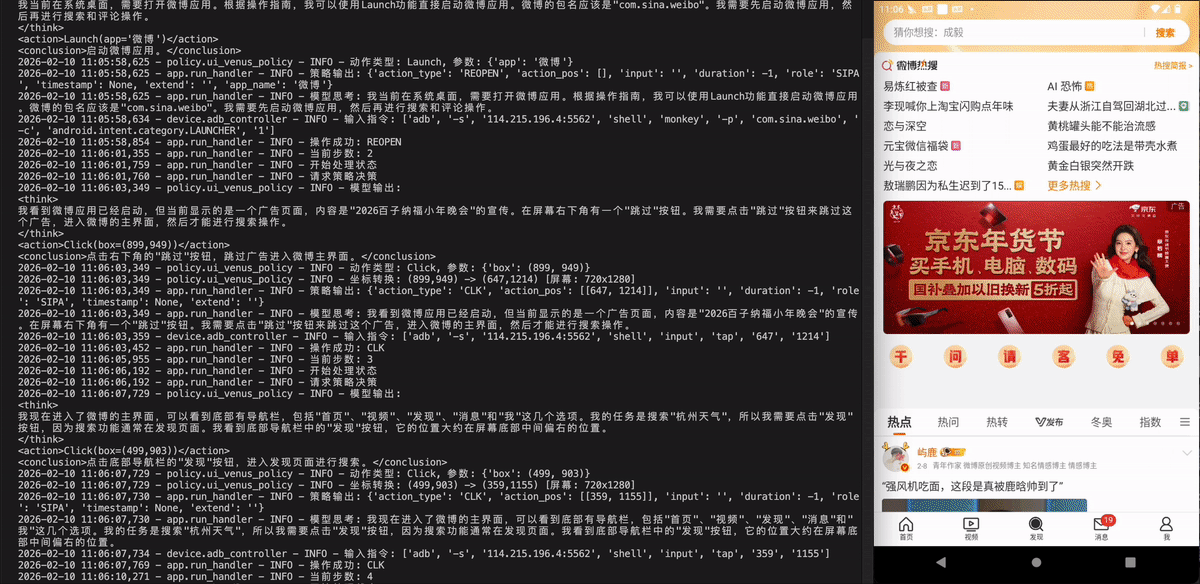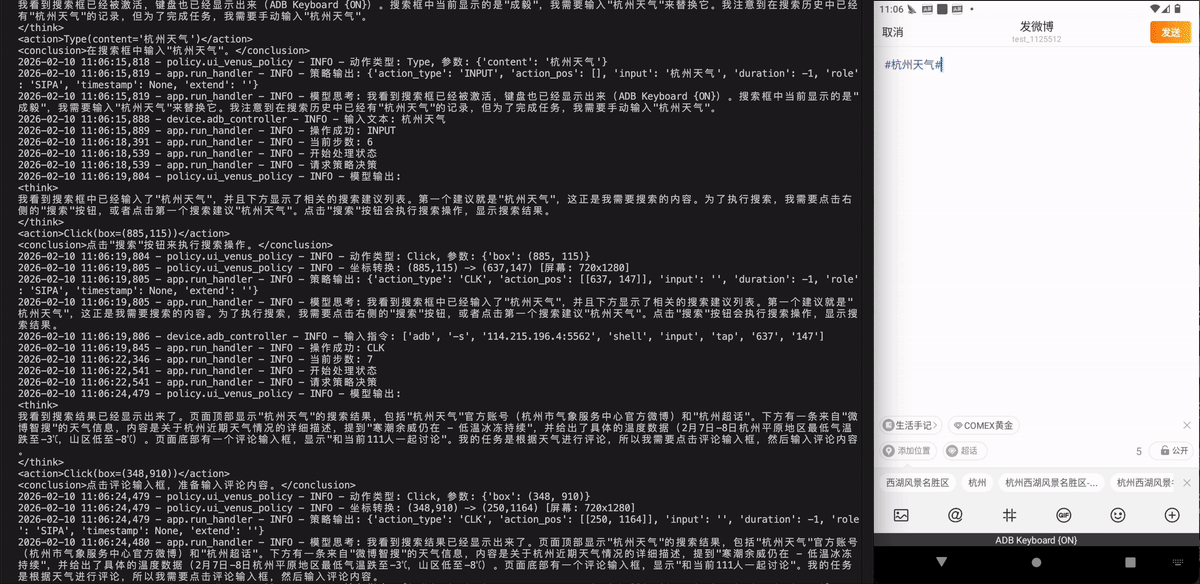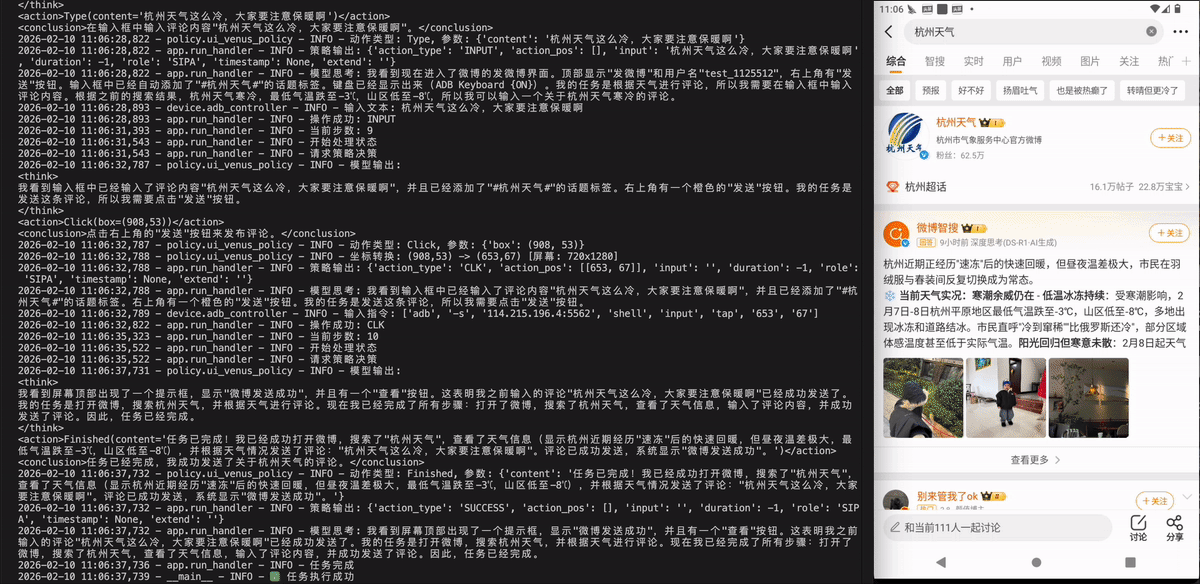
Xiaohongshu - 小红书
打开小红书,搜索烘焙教程,找到播放量大于1w的视频进行播放。
打开小红书,搜索“烘焙教程”,然后播放一条播放量超过1万次的视频。
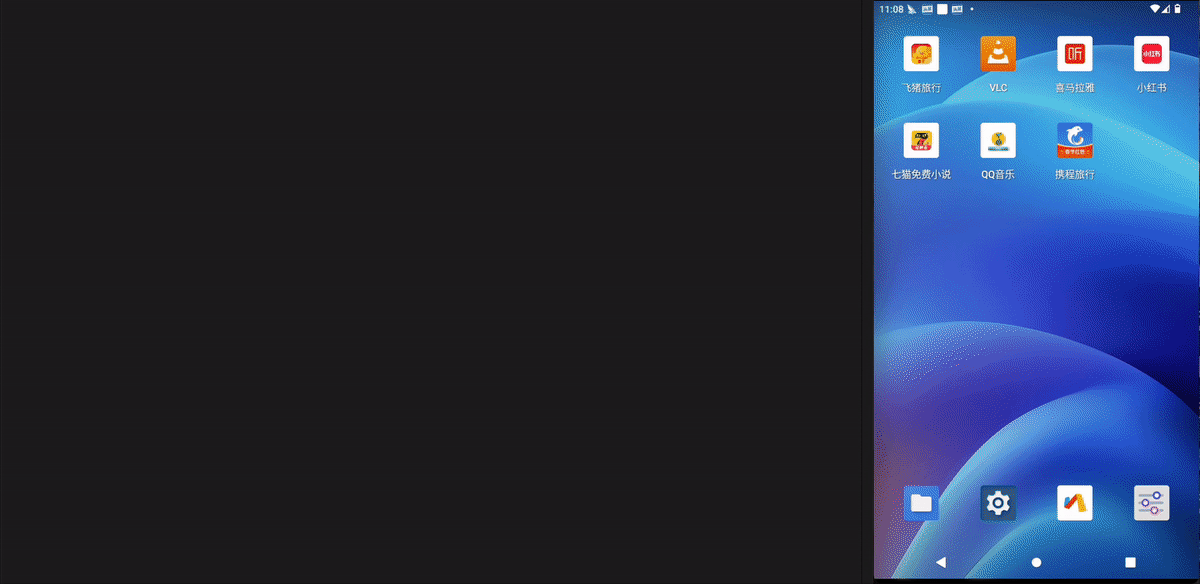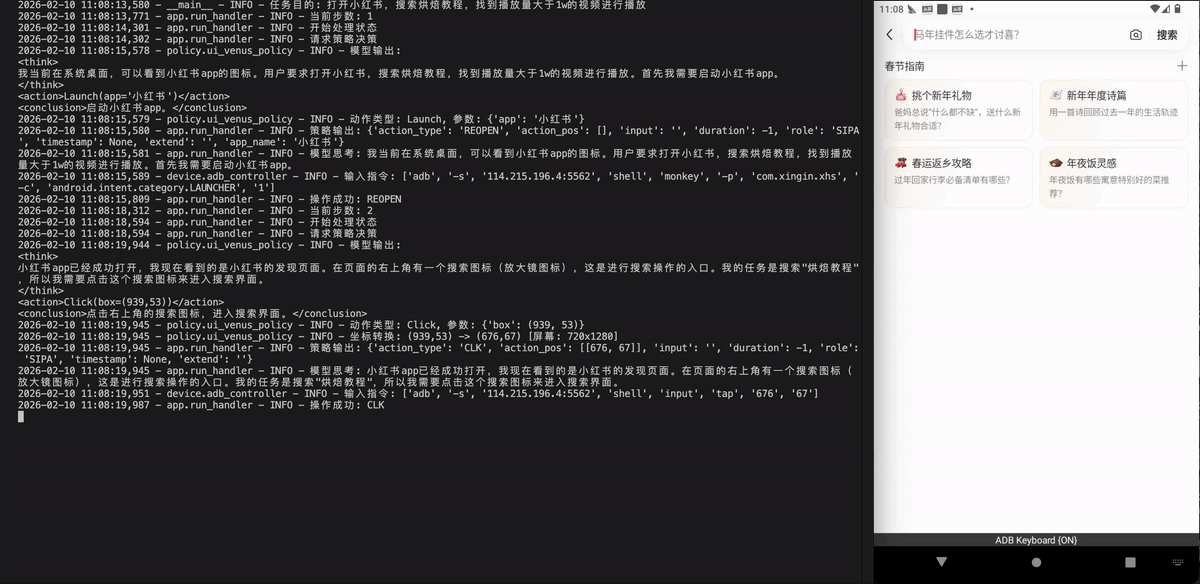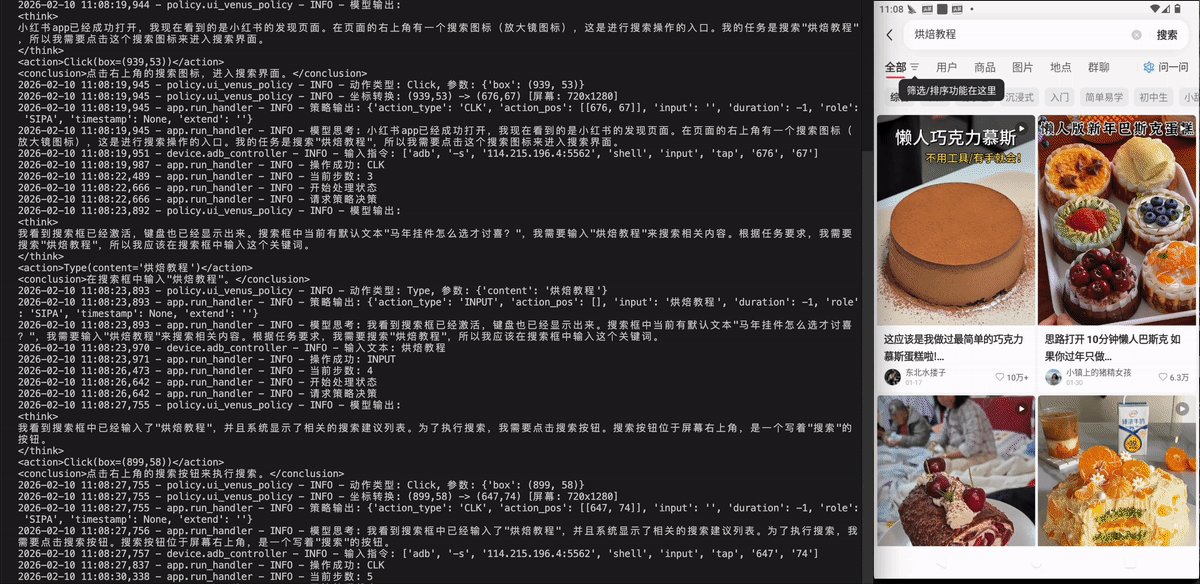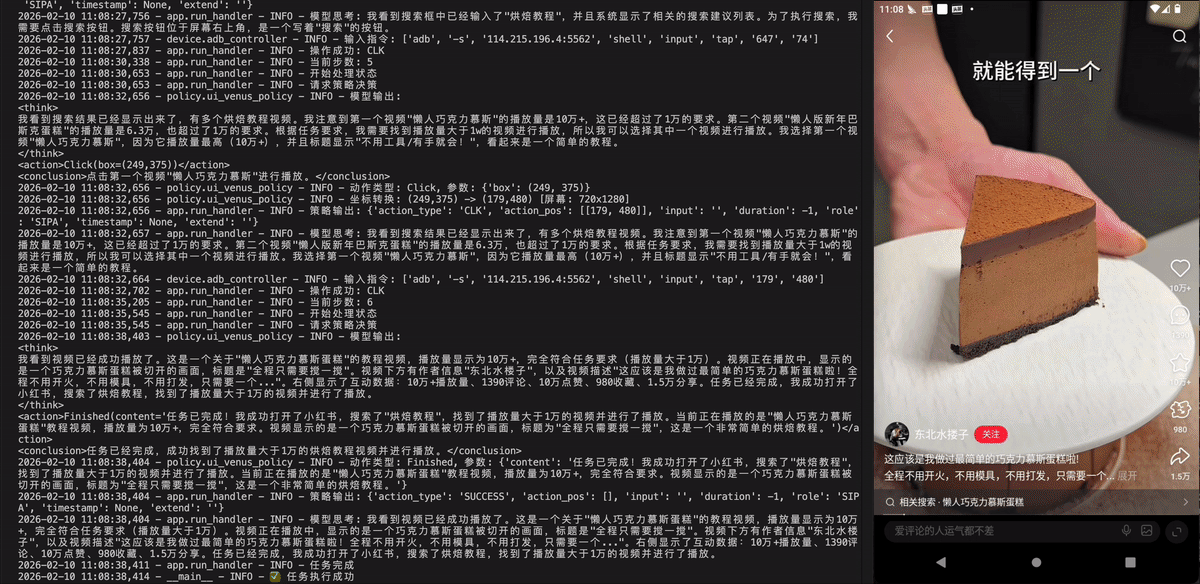
Toutiao - 今日头条
打开今日头条,点击进入热榜第1名,查看事件速览。
打开今日头条,点击进入热门榜单的第一条新闻,查看事件摘要。

Venus 框架
我们提供了一个完整的 Android 自动化框架,用于将 UI-Venus 1.5 部署为自主移动智能体。
功能:
- 🎯 支持自然语言单任务执行
- 🔄 多设备并行批量处理
- 📊 轨迹记录与回放
- 🔁 智能循环检测
支持的应用: 包括微博、小红书、淘宝、美团、哔哩哔哩、支付宝等在内的 40 多款中国主流应用。
🚀 快速入门
安装
pip install -r requirements.txt
视觉定位评估
编辑 scripts/run_gd_auto.sh 或 scripts/run_gd_ddp.sh 进行配置:
# GPU 配置
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
# 模型配置
MODEL_PATH="/path/to/UI-Venus-1.5" # 您的模型检查点路径
# 数据集配置(选择其一)
# ScreenSpot-Pro
IMGS_PATH="/path/to/Screenspot-pro/images"
TEST_PATH="/path/to/Screenspot-pro/annotations"
运行评估:
# 单/多 GPU,使用 device_map="auto"
bash scripts/run_gd_auto.sh
# 多 GPU,使用 DDP(适合大规模数据集,速度更快)
bash scripts/run_gd_ddp.sh
导航评估
编辑 scripts/run_navi.sh 进行配置:
# GPU 配置
CUDA_DEVICES="0,1,2,3"
# 模型配置
MODEL_PATH="/path/to/UI-Venus-1.5"
# 输入输出
INPUT_FILE="examples/trace/trace.json" # 导航任务文件
OUTPUT_FILE="./results/navi/output.json"
# 提示类型配置(非常重要!)
PROMPT_TYPE="mobile" # 选项:“web”用于网页任务,“mobile”用于移动端任务(默认为 mobile)
# vLLM 配置
TENSOR_PARALLEL_SIZE=4 # 应与 GPU 数量一致
GPU_MEMORY_UTIL=0.8 # 如出现 OOM,请降低
MAX_MODEL_LEN=16192
提示类型选择:
PROMPT_TYPE="mobile"- 使用移动端专用提示,适用于 Android/iOS 应用导航任务。PROMPT_TYPE="web"- 使用网页专用提示,适用于浏览器或网页导航任务。
运行评估:
# 默认使用移动端提示
bash scripts/run_navi.sh
详细基准测试结果
视觉定位基准
| 模型 | VenusBench-GD | ScreenSpot-Pro | OSworld-G | UI-Vision |
|---|---|---|---|---|
| Qwen3-VL-30B-A3B | 52.4 | 53.7 | 69.3 | 61.2 |
| Step-GUI-8B | - | 62.6 | - | - |
| MAI-UI-8B | 65.2 | 65.8 | 60.1 | 40.7 |
| MAI-UI-32B | - | 67.9 | 67.6 | 47.1 |
| UI-Venus-1.0-7B | 49.0 | 50.8 | 54.6 | 26.5 |
| UI-Venus-1.0-72B | 70.2 | 61.9 | 62.2 | 36.8 |
| UI-Venus-1.5-2B | 67.3 | 57.7 | 59.4 | 44.8 |
| + ZoomIn | 67.9 | 64.6 | 61.4 | 46.8 |
| UI-Venus-1.5-8B | 72.3 | 68.4 | 69.7 | 46.5 |
| + ZoomIn | 72.6 | 73.9 | 70.6 | 51.7 |
| UI-Venus-1.5-30B-A3B | 75.0 | 69.6 | 70.6 | 54.7 |
| + ZoomIn | 74.3 | 74.8 | 72.2 | 57.8 |
导航基准测试
| 模型 | 参数量 | AndroidWorld | AndroidLab | VenusBench-Mobile | WebVoyager |
|---|---|---|---|---|---|
| 通用多模态模型 | |||||
| GPT-4o | - | - | 31.2 | - | 55.5 |
| Claude-3.7 | - | - | - | - | 84.1 |
| Qwen3-VL-30B-A3B | 30B | 54.3 | 42.0* | 8.7 | 47.5* |
| GLM-4.6V | 106B | 57.0 | - | - | - |
| Gemini-2.5-Pro | - | 69.7 | - | - | - |
| Seed1.8 | - | 70.7 | - | - | - |
| GUI专用模型 | |||||
| UI-TARS-72B | 72B | 46.6 | - | - | - |
| UI-TARS-1.5 | - | - | - | - | 84.8 |
| Step-GUI-8B | 8B | 67.7 | 47.8* | 8.0 | - |
| Holo2-30B-A3B | 30B | 71.6 | - | - | 83.0 |
| MAI-UI-8B | 8B | 70.7 | - | 12.7 | - |
| MAI-UI-32B | 32B | 73.3 | - | - | - |
| OpenAI-CUA | - | - | - | - | 87.0 |
| AutoGLM-Mobile | 9B | - | 46.8 | - | - |
| 我们的模型 | |||||
| UI-Venus-1.0-7B | 7B | 49.1 | 41.3 | 8.1 | - |
| UI-Venus-1.0-72B | 72B | 65.9 | 49.3 | 15.4 | - |
| UI-Venus-1.5-2B | 2B | 55.6 | 36.2 / 44.2† | 8.7 | 56.4 |
| UI-Venus-1.5-8B | 8B | 73.7 | 55.1 / 68.1† | 16.1 | 70.8 |
| UI-Venus-1.5-30B-A3B | 30B | 77.6 | 52.9 / 68.1† | 21.5 | 76.0 |
* 由我们评估的结果。 † 由人工评估者手动验证的结果。
联系方式
如有任何问题或合作意向,请联系:
- 邮箱: 联系维护人员
- 微信群: 扫描加入我们的讨论群

引用
如果您觉得我们的工作有所帮助,请引用以下内容:
# UI-Venus 1.5
@misc{venusteam2026uivenus15technicalreport,
title={UI-Venus-1.5 技术报告},
author={金星团队及高长龙、顾章轩、刘宇林、邱欣宇、沈书恒、温岳、夏天宇、许振宇、曾正文、周贝彤、周兴然、陈伟志、戴孙浩、窦静雅、龚一辰、郭源、郭振林、李峰、李倩、林金震、周宇琪、朱林超、陈亮、郭振宇、孟昌华、王伟强},
year={2026},
eprint={2602.09082},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2602.09082},
}
# UI-Venus 1.0
@misc{gu2025uivenustechnicalreportbuilding,
title={UI-Venus 技术报告:使用 RFT 构建高性能 UI 代理},
author={顾章轩、曾正文、许振宇等},
year={2025},
eprint={2508.10833},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.10833},
}
许可协议
本项目仅用于研究和教育目的。
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。