ai-file-sorter
AI File Sorter 是一款跨平台的桌面应用,利用人工智能帮助用户整理文件并生成更清晰、一致的文件名。它能分析图片、文档和音视频文件,自动分类并建议命名,让文件更易于查找和管理。对于下载文件夹、外接硬盘或网络存储中的杂乱文件,它能根据名称、扩展名和用户习惯进行智能归类。
这款工具解决了文件命名混乱、分类不规范的问题,尤其适合需要处理大量文件的用户。无论是开发者、设计师还是普通用户,都能通过它提升工作效率。AI File Sorter 支持本地和远程大模型,注重隐私保护,所有操作都在本地完成,无需上传数据。其基于内容的智能分析和可自定义的命名规则是主要技术亮点。
使用场景
一位自由摄影师在完成一次为期两周的旅行后,需要整理超过2000张照片和相关素材文件,包括视频、音频和文档。这些文件分散在多个设备和存储介质中,命名混乱,缺乏统一标准。
没有 ai-file-sorter 时
- 文件名杂乱无章,如“DSC_001.jpg”、“IMG_20240501_123456.jpg”,难以快速识别内容
- 需要手动分类和重命名,耗时且容易出错
- 不同设备上的文件结构不一致,整理效率低下
- 缺乏统一命名规则,后期查找和归档困难
使用 ai-file-sorter 后
- 自动识别图片内容并生成描述性文件名,如“sunset_over_mountain.jpg”
- 根据文件类型和内容自动分类,如“风景照”、“人物照”、“视频素材”等
- 支持跨设备同步整理结果,保持文件结构一致性
- 提供清晰命名建议,提升后期检索和管理效率
通过 AI File Sorter,摄影师在不到两小时内完成了原本需要数天的工作,大幅提升了文件管理效率和组织质量。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明
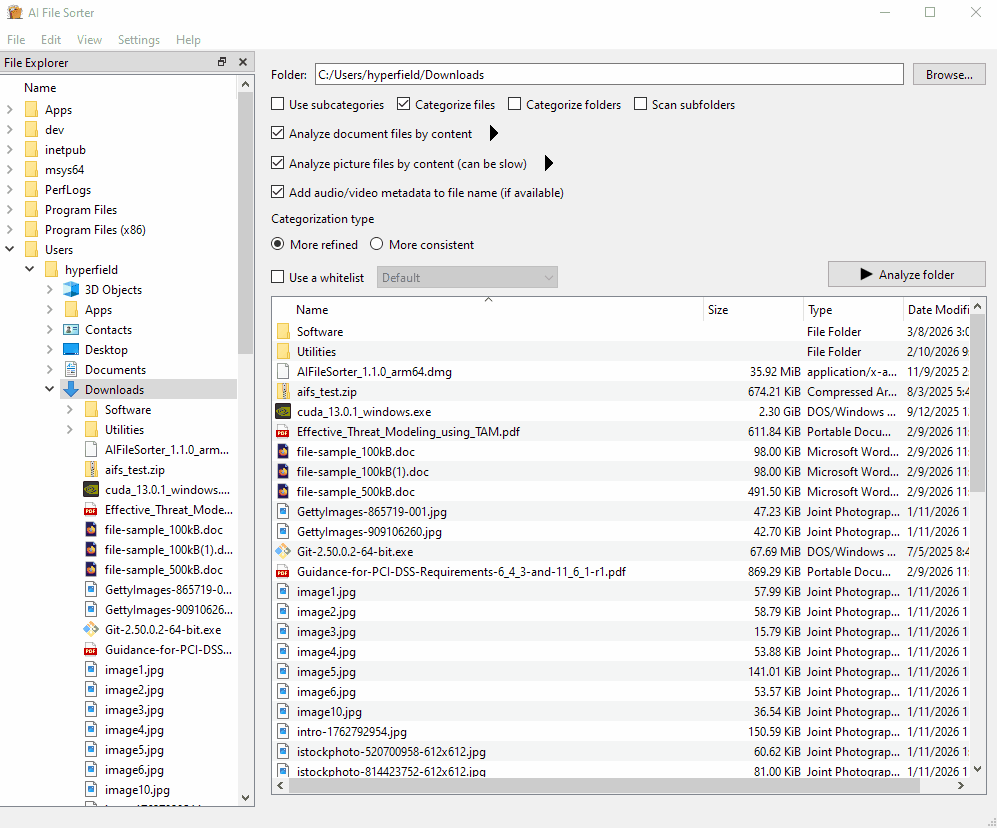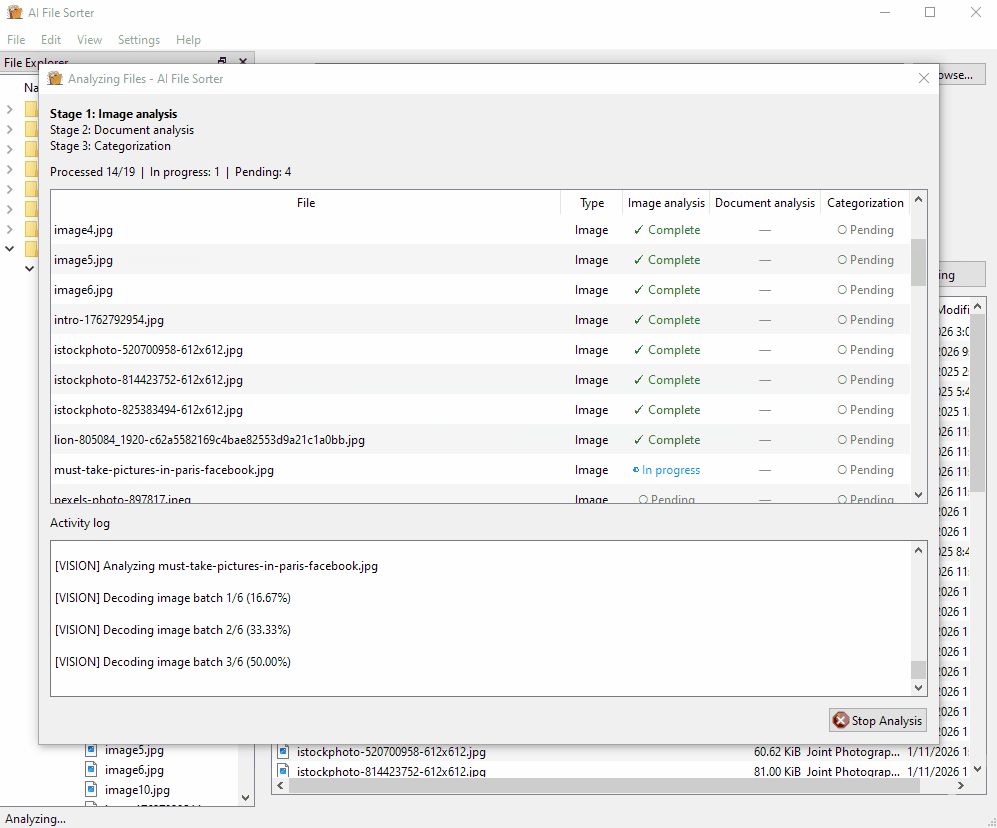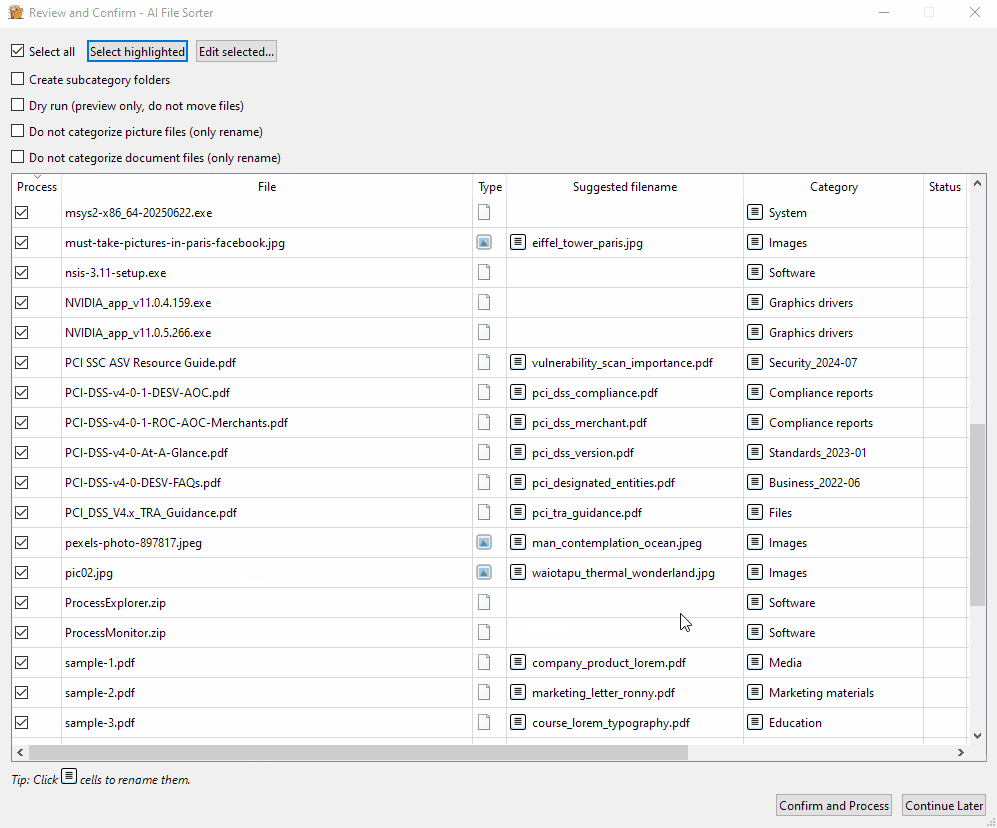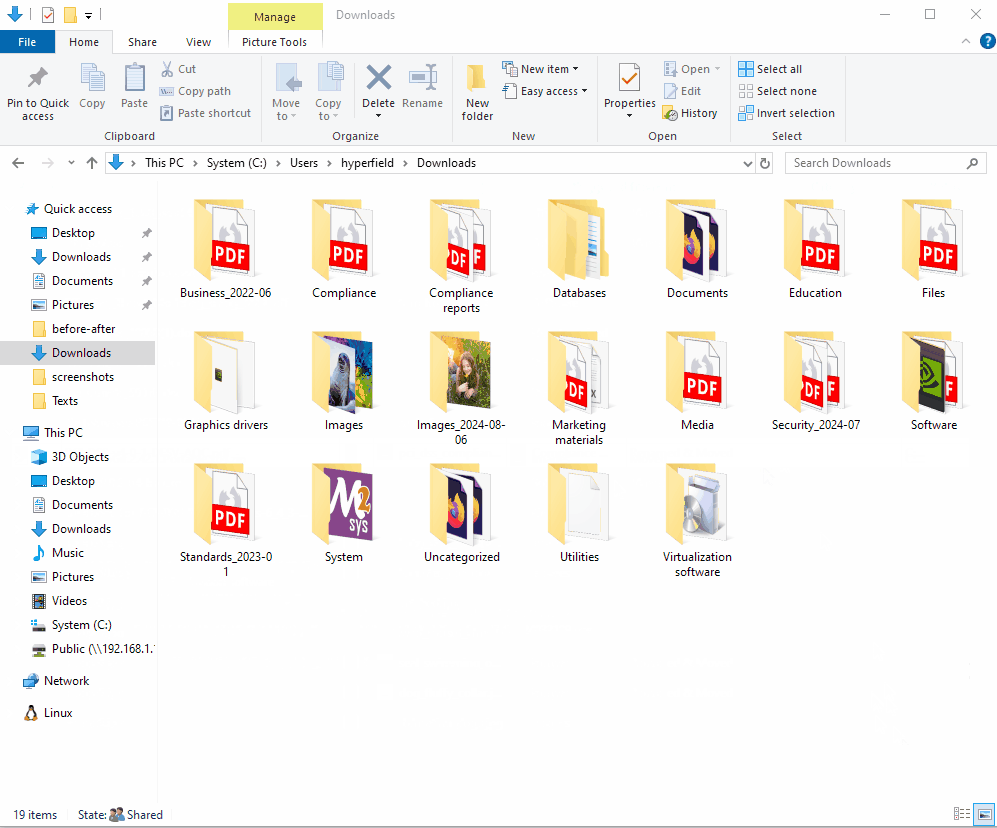
快速开始
AI 文件整理器

![]()









AI 文件整理器是一款跨平台桌面应用,利用人工智能对文件进行整理,并为图片、文档以及支持的音视频文件建议更简洁、更一致的命名。它旨在减少杂乱、提升一致性,使文件日后更容易查找,无论是用于审阅、归档还是长期存储。
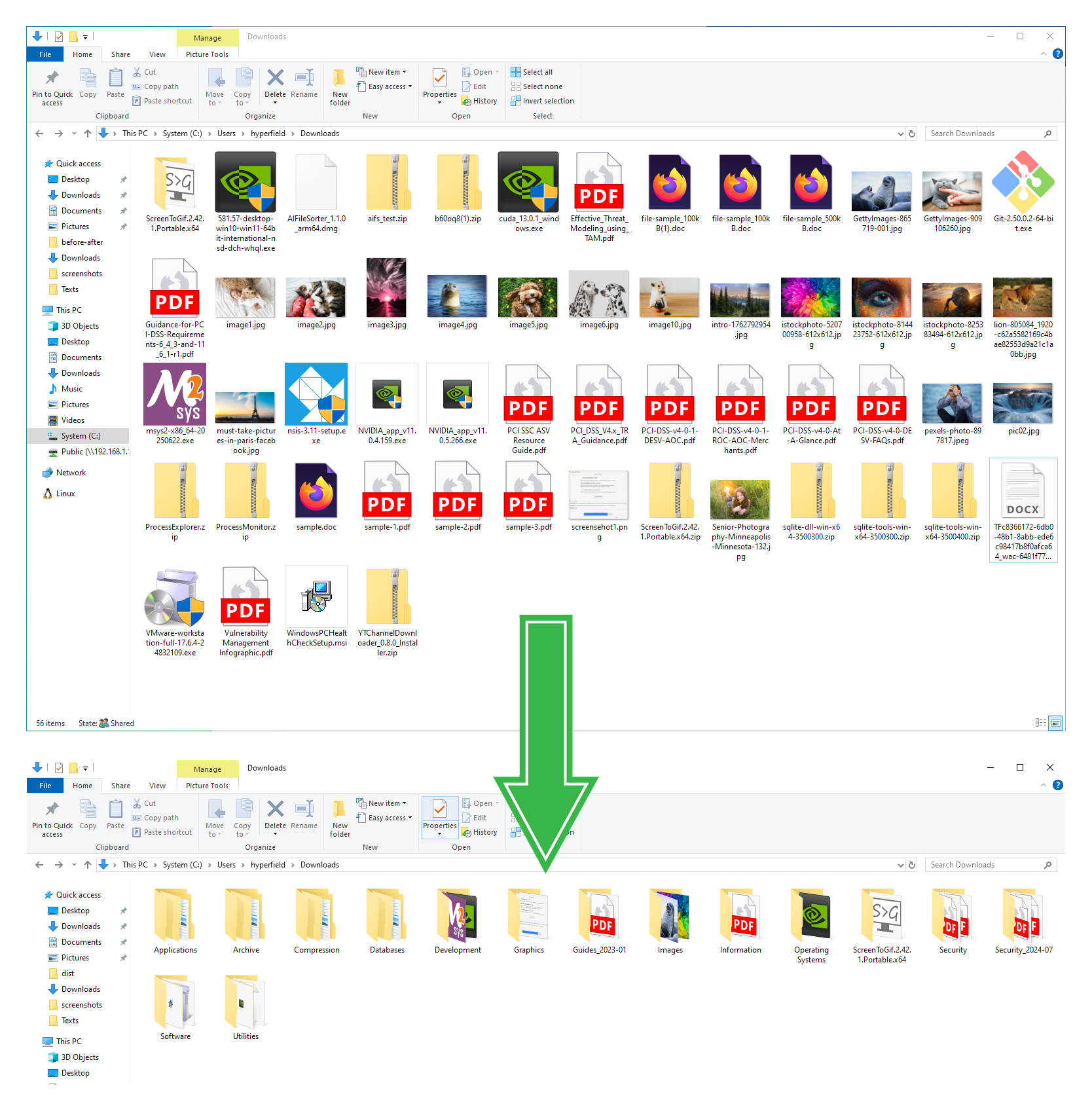
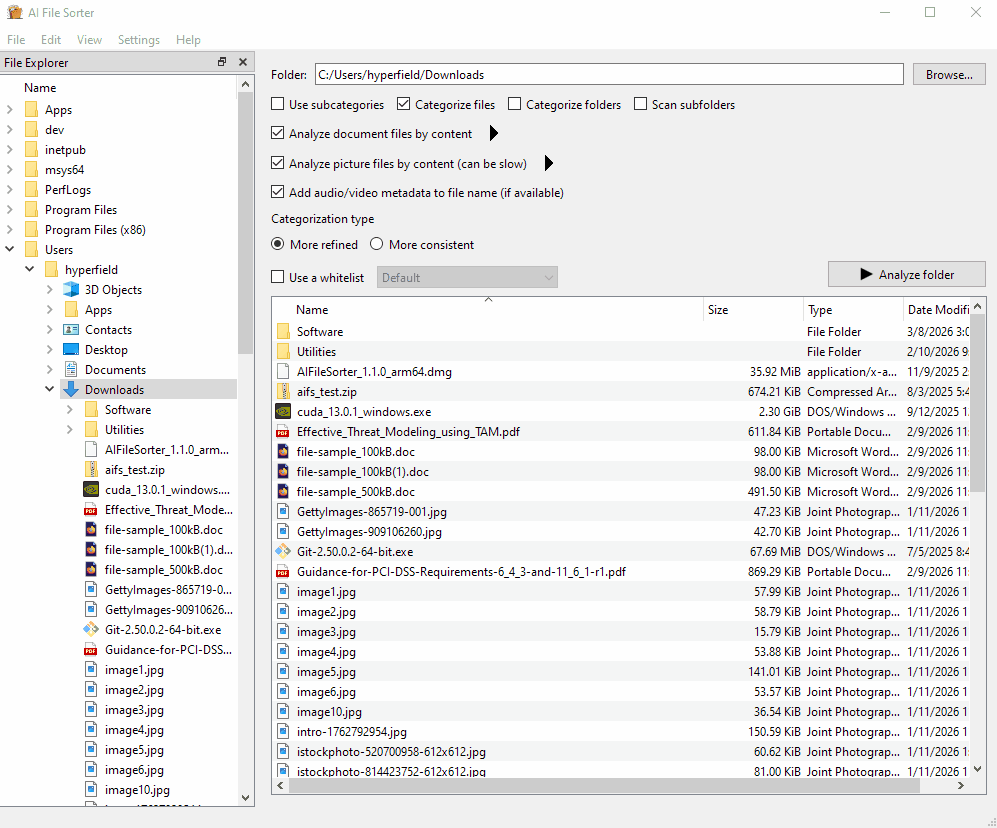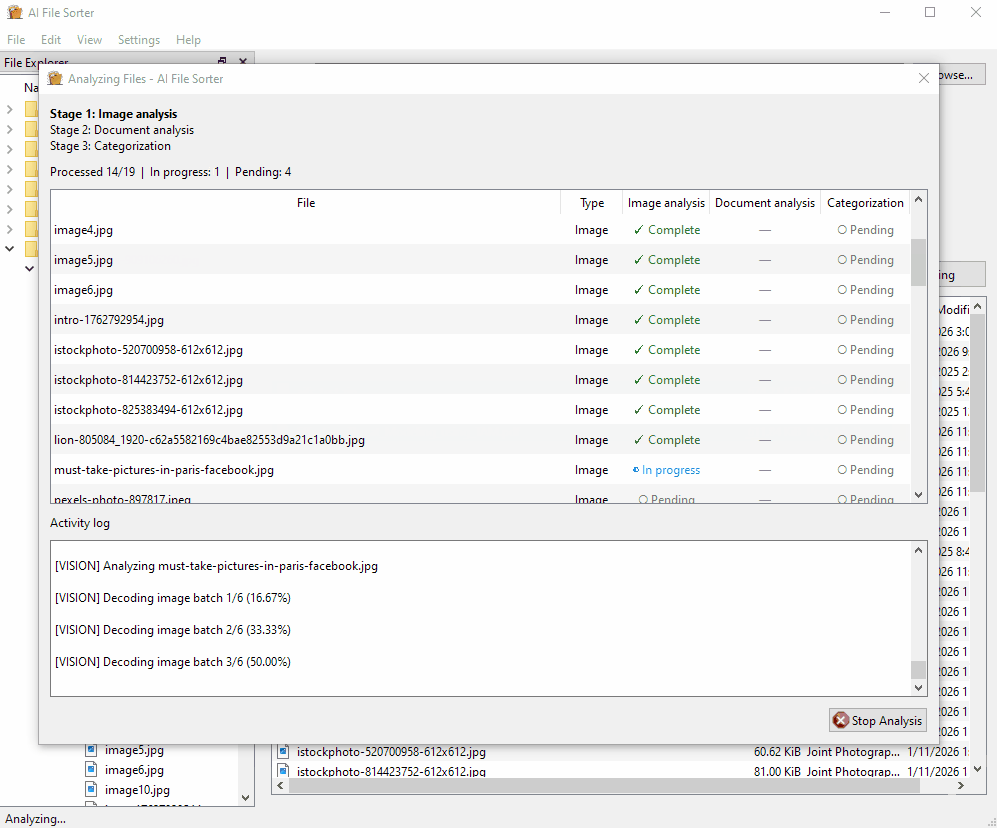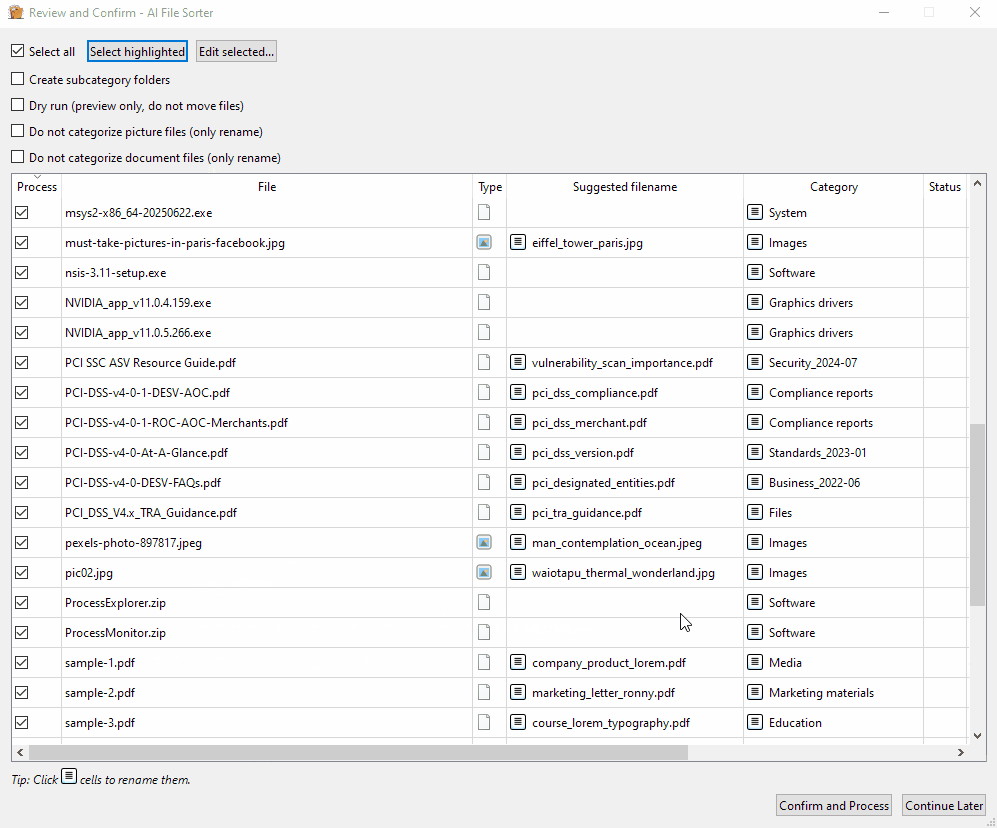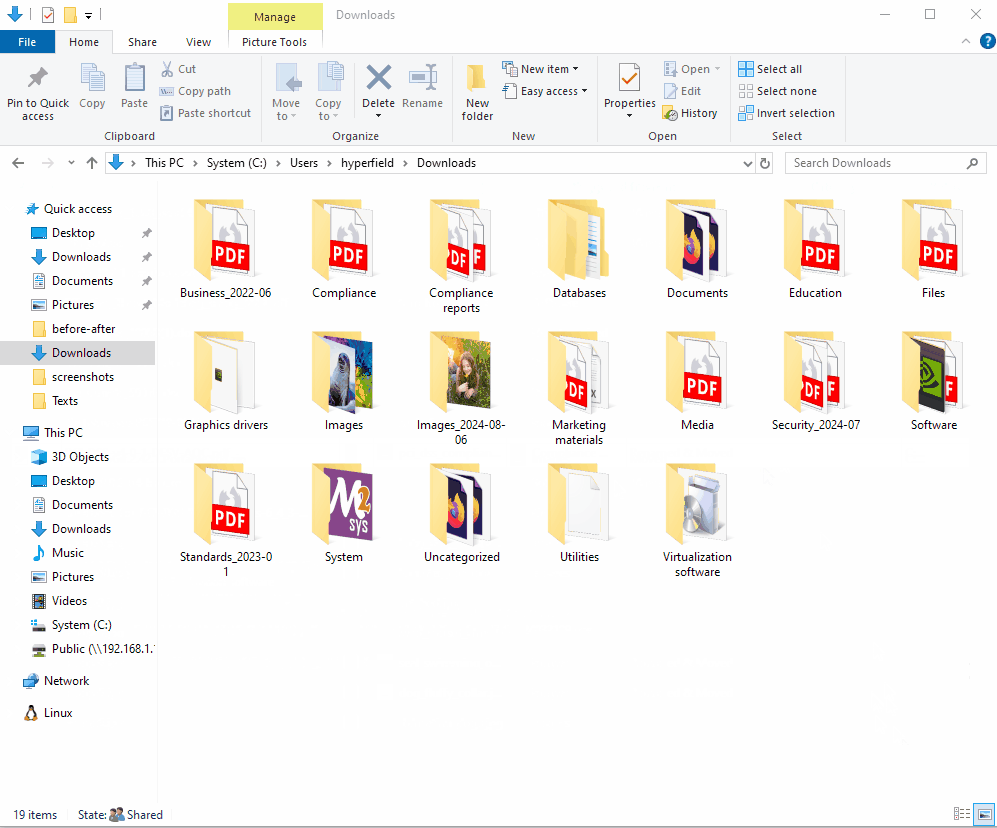
该应用可以在本地分析图片文件,并建议有意义、易于理解的名称。例如,一个通用文件如 IMG_2048.jpg 可以被重命名为更具描述性的 clouds_over_lake.jpg。它还可以分析支持的文档文件,并根据其文本内容提出更清晰的名称建议。AI 文件整理器还能通过使用已存储在支持媒体文件中的元数据来清理混乱的音频和视频文件名。如果存在年份、艺术家、专辑或标题等标签,该应用可以将其转化为清晰的建议,如 2024_artist_album_title.mp3,您可以在应用任何更改之前对其进行审查、编辑或忽略。
AI 文件整理器通过自动根据文件名、扩展名、所属文件夹上下文以及学习到的整理模式对文件进行分组,帮助整理下载文件夹、外部硬盘或 NAS 存储等杂乱的文件夹。
与依赖固定规则不同,该应用会逐步建立对您文件通常组织方式和命名习惯的内部理解。这使其能够随着时间推移提出更加一致的分类和命名建议,同时仍允许您在应用任何更改之前进行审查和调整。
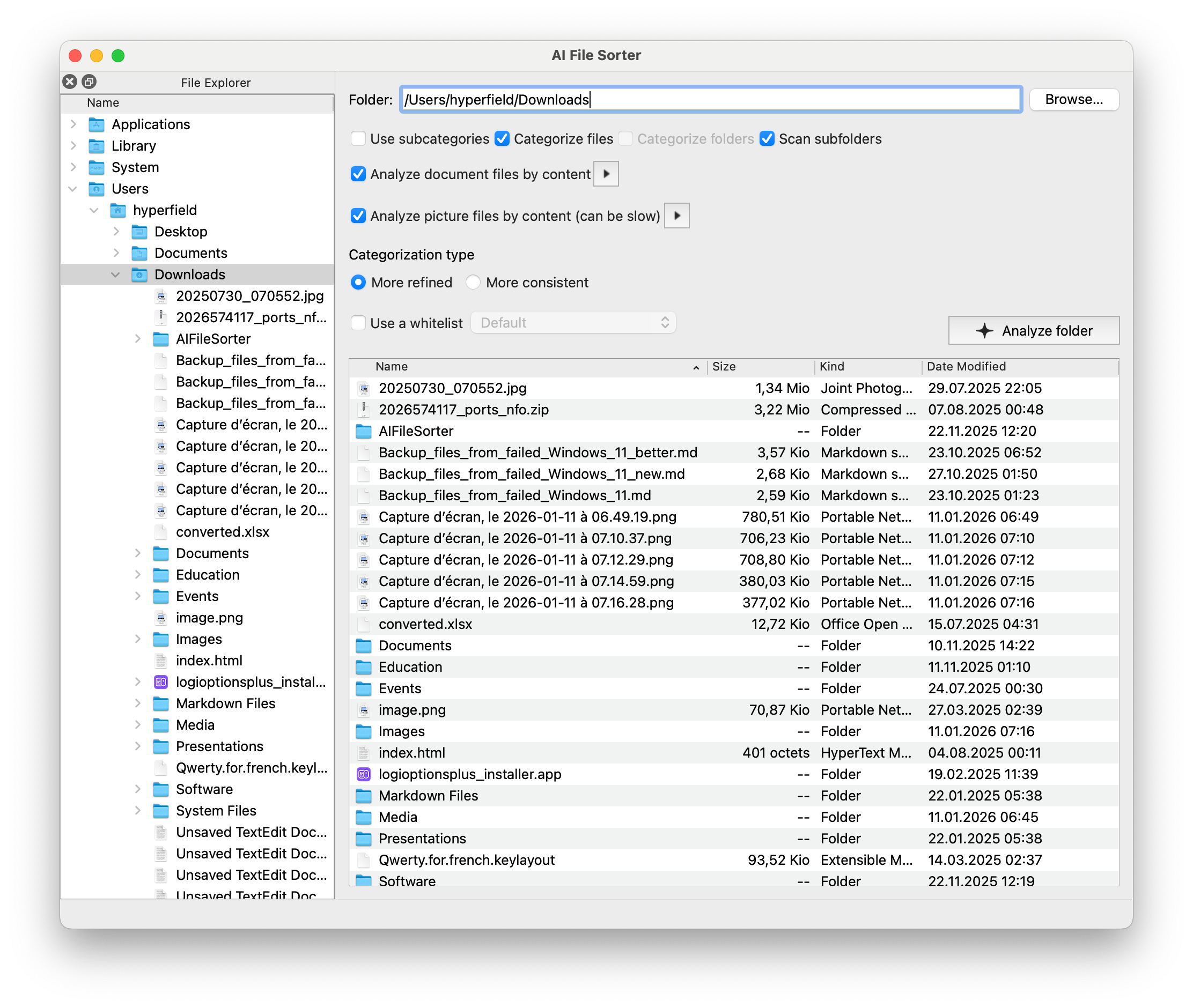
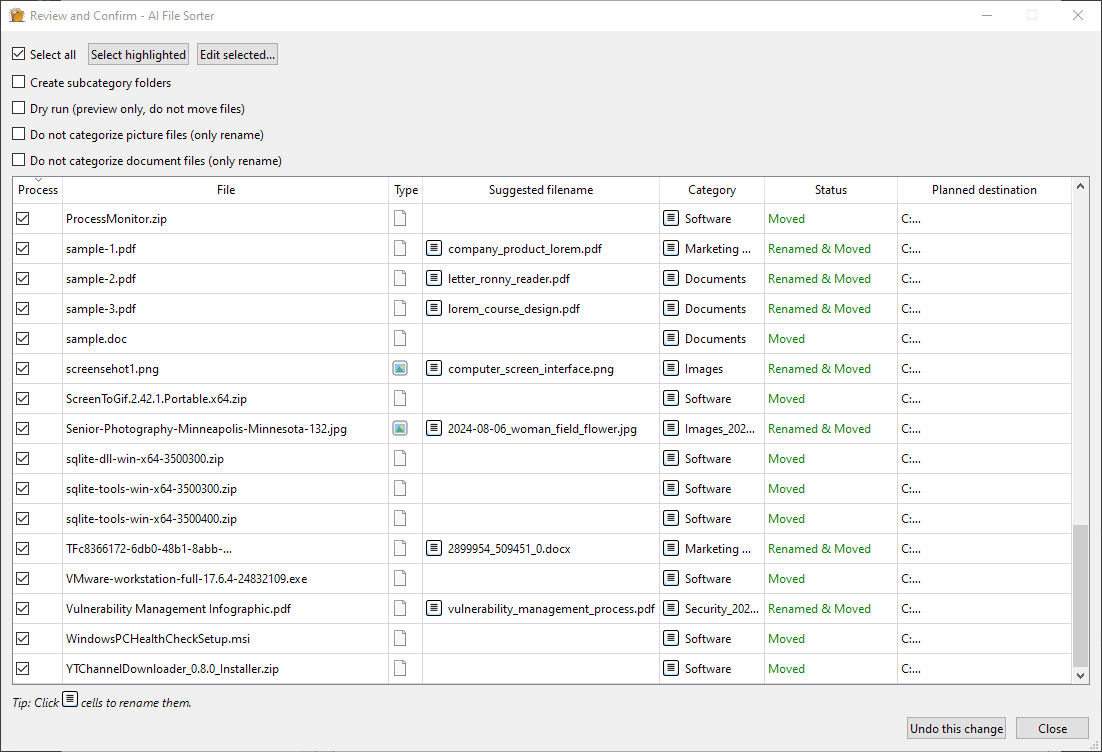
系统会为每个文件建议类别(以及可选的子类别),并对支持的文件类型提供重命名建议。一旦您确认,所需的文件夹将自动创建,文件也将相应地被分类整理。
隐私优先的设计: AI 文件整理器完全可以在您的设备上运行,使用本地人工智能模型,如 Llama 3B (Q4) 和 Mistral 7B。不会上传任何文件、文件名、图像或元数据,也不会发送任何遥测信息。只有在您明确选择启用远程模型时才需要互联网连接。
工作原理
- 将应用指向一个文件夹或驱动器
- 使用选定的本地或远程模型分析文件(以及图像内容,如适用)
- 生成分类和重命名建议
- 您进行审查并根据需要调整 - 完成


更新日志
[1.7.3] - 2026-03-22
- 非英语分类现在更加可靠:文件首先以英语进行规范分类,然后再翻译成所选的类别语言。这一变化是由于 LLM 的语言限制所致。
- 应用更新现在支持 Windows、macOS 和 Linux 的独立更新流,同时仍然接受较新客户端使用的旧版单流清单格式。
- Windows 更新源现在可以提供直接的安装程序 URL 以及 SHA-256 校验和,以便应用可以下载安装程序、显示下载进度、验证其完整性,并在确认后启动安装。
- UI 翻译系统已完全迁移到 Qt
.ts/.qm目录。 - 使用本地 LLM 进行本地分类现在更加稳健。
- 缓存的类别标签经过更严格的清理,以避免因 UTF-8 数据格式错误而导致后续分类或显示出现问题。
- 其他改进。
- 其他错误修复。
完整历史请参阅 CHANGELOG.md。
功能
- AI 驱动的分类:使用本地 LLM(Llama、Mistral)或远程模型(使用您自己的 OpenAI API 密钥的 ChatGPT,或使用 Gemini API 密钥的 Gemini)智能地对文件进行分类。
- 离线友好:使用本地 LLM 完全在本地对文件进行分类——无需互联网或 API 密钥。
- 强大的分类能力:通过分类体系和启发式方法,确保每次运行时标签更加一致。
- 可自定义的排序规则:自动分配类别和子类别,实现精细化组织。
- 两种分类模式:选择“更精细”以获得详细标签,或选择“更一致”以偏向于文件夹内统一的类别。
- 类别白名单:定义允许的类别/子类别的命名白名单,在“设置 → 管理类别白名单…”中进行管理,并在主窗口中根据需要启用或选择,以限制会话期间模型的输出。
- 多语言分类:让 LLM 以荷兰语、法语、德语、意大利语、波兰语、葡萄牙语、西班牙语或土耳其语为文件分配类别(取决于所使用的模型)。
- 自定义本地 LLM:直接从“选择 LLM”对话框注册您自己的本地 GGUF 模型。
- 图像内容分析(视觉 LLM):使用 LLaVA 分析支持的图片文件,生成描述并提供可选的文件名建议(支持仅重命名模式)。
- 图像日期到类别后缀(可选):如果可用,将图像创建日期元数据附加到图像类别名称上。
- 文档内容分析(文本 LLM):分析支持的文档文件以总结内容并建议文件名;使用相同的选定 LLM(本地或远程)。
- 音视频元数据文件名建议:将嵌入式媒体标签转换为干净的、图书馆风格的文件名,适用于支持的音频和视频文件,并在任何文件被重命名之前进行全面审核。
- 可排序的审查:按文件名、类别或子类别对分类审查表进行排序,以便更快地进行分类整理。
- Qt6 界面:轻量且响应迅速的用户界面,配有更新的菜单和图标。
- 界面语言:英语、荷兰语、法国语、德语、意大利语、韩语、西班牙语和土耳其语。
- 跨平台兼容性:可在 Windows、macOS 和 Linux 上运行。
- 本地数据库缓存:加快重复分类速度,并最大限度减少远程 LLM 的使用成本。
- 排序预览:在确认更改之前,查看文件将如何被组织。
- 试运行 / 仅预览模式,用于检查计划中的移动而不会实际更改文件。
- 持久撤销功能(“撤销上次运行”),即使关闭排序对话框后仍可使用。
- 自带密钥:只需粘贴一次您的 OpenAI 或 Gemini API 密钥;该密钥将本地存储并在后续远程运行中重复使用。
- 更新通知:接收有关更新的通知——可以选择是否强制更新。
分类
分类模式
- 更精细:灵活、注重细节的模式。禁用一致性提示,使模型能够选择其认为最具体的类别或子类别,这对于长尾或混合文件夹非常有用。
- 更一致:统一模式。模型会收到当前会话中先前分配的一致性提示,因此具有相似名称或扩展名的文件倾向于归入相同的类别。当您希望一批文件保持严格统一时,此模式非常有帮助。
- 在主窗口上的“分类类型”单选按钮之间切换;您的选择将保存下来,供下次运行时使用。
类别白名单
- 启用“使用白名单”以将选定的白名单注入 LLM 提示中;禁用则让模型自由选择。
- 在“设置 → 管理类别白名单…”中管理列表(添加、编辑、删除)。只有在没有现有列表时才会自动创建默认列表,并且可以为不同项目保留多个命名列表。
- 将每个白名单控制在大约 15–20 个类别/子类别以内,以避免在较小的本地模型上出现过长的提示。与其使用一个非常长的列表,不如使用几个较窄的列表。
- 白名单适用于任一分类模式;当您希望最大程度地遵守受限词汇表时,可将其与“更一致”模式搭配使用。
图像分析(视觉 LLM)
图像分析使用基于 LLaVA 的本地视觉 LLM 来描述图像内容,并(可选)建议更好的文件名。此过程完全在本地运行,无需 API 密钥。
必需的视觉 LLM 文件
“选择 LLM”对话框现在包含一个“图像分析模型(LLaVA)”部分,其中有两个下载选项:
- LLaVA 文本模型(GGUF):主要的语言模型,用于生成描述和文件名建议。
- LLaVA mmproj(视觉编码器投影,GGUF):将视觉嵌入映射到 LLM 令牌空间的适配器,使模型能够接受图像输入。
这两个文件都是必需的。如果缺少任何一个,图像分析功能将被禁用,应用程序会提示您打开“选择 LLM”对话框以下载它们。下载 URL 可以通过 LLAVA_MODEL_URL 和 LLAVA_MMPROJ_URL 覆盖(参见“环境变量”部分)。
主窗口选项
图像分析在主窗口中增加了六个相关复选框:
- 按内容分析图片文件(可能较慢):对支持的图片文件运行视觉 LLM,并在分析对话框中显示进度。
- 仅处理图片文件(忽略其他文件):将运行限制在支持的图片文件上,并在启用时禁用分类控件。
- 将图像创建日期(如可用)添加到类别名称:如果可用,将图像元数据中的
YYYY-MM-DD附加到类别标签上。启用仅重命名模式时禁用此选项。 - 将照片日期和地点添加到文件名(如可用):如果可用,将基于元数据的日期/地点前缀添加到建议的图像文件名中。
- 提供重命名图片文件的选项:在审查对话框中显示“建议文件名”列,列出视觉 LLM 的建议。您可以在确认之前对其进行编辑。
- 不分类图片文件(仅重命名):跳过对图像的文本分类,仅对其应用(可选)重命名操作。
位于顶部的独立复选框“将音视频元数据添加到文件名(如可用)”控制支持的音视频文件的基于元数据的重命名建议。请参阅“音视频元数据文件名建议”。
文档分析(文本 LLM)
文档分析使用相同的选定 LLM(本地或远程)从支持的文档文件中提取文本,总结内容,并可选地建议更好的文件名。无需额外下载模型。
支持的文档格式
- 纯文本:
.txt、.md、.rtf、.csv、.tsv、.json、.xml、.yml/.yaml、.ini/.cfg/.conf、.log、.html/.htm、.tex、.rst - PDF:
.pdf(默认嵌入PDFium;仅在您显式配置-DAI_FILE_SORTER_REQUIRE_EMBEDDED_PDF_BACKEND=OFF时,才可使用pdftotext作为 CLI 备用方案) - Office/OpenOffice:
.docx、.xlsx、.pptx、.odt、.ods、.odp(捆绑构建中嵌入了 libzip+pugixml;若不使用 vendored 库构建,则 CLI 备用方案会使用unzip) - 当前不支持
.doc、.xls、.ppt等旧版二进制格式。
源码构建:默认使用内置提取器。如果您的目标平台上缺少 vendored 的 PDFium 工件,CMake 现在会明确报错,而不再静默禁用 PDF 内容提取。您可以通过设置 -DAI_FILE_SORTER_REQUIRE_EMBEDDED_PDF_BACKEND=OFF 恢复旧有的 CLI 备用方案。
主窗口选项(文档)
- 按内容分析文档文件:提取文档文本并将其输入 LLM 以生成摘要及重命名建议。
- 仅处理文档文件(忽略其他文件):运行时仅处理支持的文档文件,并在启用此选项期间禁用分类控件。
- 提供文档重命名建议:在审查对话框中显示包含 LLM 建议的“建议文件名”列,您可在确认前进行编辑。
- 不分类文档文件(仅重命名):跳过文档的文本分类步骤,在应用(可选)重命名的同时保持文件原位。
- 将文档创建日期(如可用)添加到类别名称中:在元数据中存在年月信息时,将其追加为
YYYY-MM格式。启用仅重命名模式时,此功能将被禁用。
音频/视频元数据的文件名建议
让 AI 文件整理工具将嵌入式媒体标签转化为整洁、一致的文件名,用于您的音乐和视频库。启用后,应用程序会读取支持的元数据字段,并按照 年份_艺术家_专辑_标题.扩展名 的格式构建一个精美的建议文件名。与所有重命名建议一样,除非您查看并确认,否则不会对文件进行任何更改。
支持的音频/视频格式
- 音频扩展名:
.aac、.aif、.aiff、.alac、.ape、.flac、.m4a、.mp3、.ogg、.oga、.opus、.wav、.wma - 视频扩展名:
.3gp、.avi、.flv、.m4v、.mkv、.mov、.mp4、.mpeg、.mpg、.mts、.m2ts、.ts、.webm、.wmv - 内置标签读取器目前支持 MP3(ID3v1/ID3v2)、FLAC(Vorbis 注释)、OGG/OGA/Opus(Vorbis 注释)以及 MP4 系列容器,例如
.m4a、.mp4、.m4v、.mov和.3gp(MP4/MOV 元数据原子)。 - 在使用包管理的
MediaInfoLib编译时,相同的重命名流程还可以利用 MediaInfo 提供的元数据,为更多支持的容器生成文件名建议。
系统兼容性检查
系统兼容性检查会运行一个快速基准测试,评估您的系统对以下任务的处理能力:
- 使用选定的本地 LLM 进行分类
- 按内容进行文档分析
- 使用视觉 LLM 进行图像分析
您可以通过菜单启动该检查(文件 → 系统兼容性检查…)。只有在至少下载了一个本地或视觉 LLM 时才会运行,并且一旦运行过就不会自动再次执行。
检查内容包括:
- 检测可用的 CPU 线程和 GPU 后端(例如 Vulkan/CUDA)
- 对每个默认模型的小规模分类和文档分析工作负载进行计时
- 如果存在视觉 LLM 文件,则对单次图像分析进行计时
- 报告速度等级(最佳/可接受/稍慢),并推荐合适的本地 LLM
提示:为获得更准确的结果,请在运行检查前关闭占用大量 CPU/GPU 资源的应用程序。
系统要求
- 操作系统:Linux、macOS 或 Windows。Linux/macOS 的源码构建采用下方的 Makefile 流程;Windows 的源码构建则使用 Windows 部分中的原生 Qt/MSVC + CMake 流程。
- 编译器:支持 C++20 的编译器(Linux/macOS 上为
g++或clang++,Windows 上为 MSVC 2022)。 - Qt 6:Core、Gui、Widgets 模块以及 Qt 资源编译器(Linux 上为
qt6-base-dev/qt6-tools,macOS 上为brew install qt,Windows 上则需使用 Qt 6 MSVC 工具包或通过 vcpkg 安装qtbase)。 - 库:
curl、sqlite3、fmt、spdlog、libmediainfo(完整源码构建必需),以及预编译的llama库,分别位于 Linux/Windows 的app/lib/precompiled目录下,或 macOS 变体构建的app/lib/precompiled-*目录中。在 Windows 上,这些非 Qt 库通过app/vcpkg.json清单文件提供。 - MediaInfo 政策:必须通过包管理器安装 MediaInfo(如
apt、dnf、pacman、brew或vcpkg)。构建过程拒绝使用 vendored 的 MediaInfo 子模块和已检入的二进制文件。 - 文档分析相关库(vendored):PDFium、libzip 和 pugixml。PDFium 默认为必选,因此打包和源码构建在 Windows、macOS 和 Linux 上均会保留内置的 PDF 提取功能;仅当您有意使用
pdftotext备用方案时,才需设置-DAI_FILE_SORTER_REQUIRE_EMBEDDED_PDF_BACKEND=OFF。 - 可选 GPU 后端:推荐使用 Vulkan 1.2+ 运行时,或适用于 NVIDIA 显卡的 CUDA 12.x。
StartAiFileSorter.exe/run_aifilesorter.sh会自动检测最佳可用后端,并在必要时回退到 CPU/OpenBLAS,因此运行本应用并不需要 CUDA。 - Git(可选):用于克隆本仓库。也可直接下载压缩包。
- OpenAI 或 Gemini API 密钥(可选):仅在使用远程 ChatGPT 或 Gemini 工作流时才需提供。
安装说明
使用本地 LLM 进行文件分类完全免费。如果您希望使用远程工作流(ChatGPT 或 Gemini),则需要拥有自己的 API 密钥,并确保账户中有少量余额或处于免费层级内(请参阅 使用您的 OpenAI API 密钥 或 使用您的 Gemini API 密钥)。
Linux
预编译的 Debian/Ubuntu 软件包
- 安装运行时依赖(Qt6、网络、数据库、数学库):
- Ubuntu 24.04 / Debian 12:
sudo apt update && sudo apt install -y \ libqt6widgets6 libcurl4 libjsoncpp25 libfmt9 libopenblas0-pthread \ libvulkan1 mesa-vulkan-drivers patchelf - Debian 13(trixie):
sudo apt update && sudo apt install -y \ libqt6widgets6 libcurl4t64 libjsoncpp26 libfmt10 libopenblas0-pthread \ libvulkan1 mesa-vulkan-drivers patchelf
如果您从源码构建 Vulkan 后端,请安装
glslc(Debian/Ubuntu 包:glslc;在某些发行版中为shaderc或shaderc-tools)。 在 Debian 13 上,应使用libjsoncpp26、libfmt10和libcurl4t64(如果libcurl4不可用,APT 可能会自动选择libcurl4t64)。 确保已安装 Qt 平台插件(在 Ubuntu 22.04 中,这由qt6-wayland提供)。 GPU 加速还需要一个可用的 Vulkan 1.2+ 堆栈(Mesa、AMD/Intel/NVIDIA 驱动程序),或者对于 NVIDIA 用户,需要匹配的 CUDA 运行时环境(nvidia-cuda-toolkit或厂商提供的软件包)。启动器会在两者都存在时优先使用 Vulkan,若两者均不可用则回退到 CPU。 - Ubuntu 24.04 / Debian 12:
- 安装软件包
使用sudo apt install ./aifilesorter_*.debapt install(而非dpkg -i)可确保自动安装上述所有缺失的依赖项。
从源码构建
安装依赖
- Debian / Ubuntu:
sudo apt update && sudo apt install -y \ build-essential cmake git qt6-base-dev qt6-base-dev-tools qt6-l10n-tools qt6-tools-dev-tools \ libcurl4-openssl-dev libjsoncpp-dev libsqlite3-dev libssl-dev libfmt-dev libspdlog-dev libmediainfo-dev \ zlib1g-dev- Fedora / RHEL:
export PATH="/usr/lib64/qt6/libexec:$PATH" sudo dnf install -y gcc-c++ cmake git qt6-qtbase-devel qt6-qttools-devel \ libcurl-devel jsoncpp-devel sqlite-devel openssl-devel fmt-devel spdlog-devel mediainfo-devel- Arch / Manjaro:
sudo pacman -S --needed base-devel git cmake qt6-base qt6-tools curl jsoncpp sqlite openssl fmt spdlog mediainfo可选的 GPU 加速还需要发行版提供的 Vulkan 1.2+ 驱动程序或运行时环境(Mesa、AMD、Intel、NVIDIA),或者用于 NVIDIA 显卡的 CUDA 软件包。请根据计划使用的堆栈进行安装;如果未检测到任何相关组件,应用程序将自动回退到 CPU。 MediaInfo 必须通过软件包管理方式提供;构建过程会拒绝使用自包含的
MediaInfoLib文件夹或仓库本地的二进制文件。克隆仓库
git clone https://github.com/hyperfield/ai-file-sorter.git cd ai-file-sorter git submodule update --init --recursive子模块提示:如果您之前手动下载了
llama.cpp或 Catch2,请在运行git submodule命令前移除或重命名app/include/external/llama.cpp和external/Catch2。Git 需要这些目录为空,以便填充跟踪的子模块。构建 vendored libzip(生成
zipconf.h和libzip.a)cmake -S external/libzip -B external/libzip/build \ -DBUILD_SHARED_LIBS=OFF \ -DBUILD_DOC=OFF \ -DENABLE_BZIP2=OFF \ -DENABLE_LZMA=OFF \ -DENABLE_ZSTD=OFF \ -DENABLE_OPENSSL=OFF \ -DENABLE_GNUTLS=OFF \ -DENABLE_MBEDTLS=OFF \ -DENABLE_COMMONCRYPTO=OFF \ -DENABLE_WINDOWS_CRYPTO=OFF cmake --build external/libzip/build在 Ubuntu/Debian 上,您还需要 Zlib 开发头文件(
zlib1g-dev),否则 libzip 的配置步骤将会失败。 如果您更倾向于使用系统提供的头文件,请安装libzip-dev,并确保zipconf.h位于您的包含路径中。构建 llama 运行时变体(针对您计划打包或测试的每个后端执行一次)
# CPU / OpenBLAS ./app/scripts/build_llama_linux.sh cuda=off vulkan=off # CUDA(可选;需要 NVIDIA 驱动程序 + CUDA 工具包) ./app/scripts/build_llama_linux.sh cuda=on vulkan=off # Vulkan(可选;需要可用的 Vulkan 1.2+ 堆栈及 glslc,例如 mesa-vulkan-drivers + vulkan-tools + glslc) ./app/scripts/build_llama_linux.sh cuda=off vulkan=on每次调用都会将相应的
llama/ggml库放置在app/lib/precompiled/<variant>目录下,并将运行时 DLL/SO 文件复制到app/lib/ggml/w<variant>。该脚本不允许同时启用 CUDA 和 Vulkan,因此需分别为每个后端单独运行。打包这两个目录可以让启动器在可用时优先选择 Vulkan,其次选择 CUDA,否则将继续使用 CPU——这样就不会留下仅依赖 CUDA 的情况。编译应用程序
cd app make -j4生成的二进制文件位于
app/bin/aifilesorter。Makefile 要求使用pkg-config并依赖于通过软件包管理的libmediainfo;它会明确拒绝使用自包含的 MediaInfo 复制件。系统级安装(可选)
sudo make install构建 Debian 软件包(可选)
./app/scripts/package_deb.sh打包脚本始终会捆绑 CPU 运行时,并自动包含已在
app/lib/precompiled下准备好的任何 GPU 变体(例如,在执行./app/scripts/build_llama_linux.sh cuda=off vulkan=on后的vulkan变体)。若希望生成更小的仅包含 CPU 的软件包,可使用--cpu-only参数;若希望脚本在缺少特定预编译变体时报错,则可使用--include-vulkan或--include-cuda参数。
macOS
安装 Xcode 命令行工具(运行
xcode-select --install)。安装 Homebrew(如果需要)。
安装依赖项
brew install qt curl jsoncpp sqlite openssl fmt spdlog mediainfo cmake git pkgconfig libffi如果 Qt 尚未添加到环境变量中,请执行以下命令:
export PATH="$(brew --prefix)/opt/qt/bin:$PATH" export PKG_CONFIG_PATH="$(brew --prefix)/lib/pkgconfig:$(brew --prefix)/share/pkgconfig:$PKG_CONFIG_PATH"克隆仓库及子模块(与 Linux 相同的命令)。
macOS 构建会固定
MACOSX_DEPLOYMENT_TARGET=11.0,以确保 Mach-O 的LC_BUILD_VERSION能够覆盖 Apple Silicon 及更高版本(包括 Sequoia)。如果您需要不同的最低目标版本,请相应地调整该值,例如export MACOSX_DEPLOYMENT_TARGET=15.0。构建 vendored libzip(生成
zipconf.h和libzip.a)cmake -S external/libzip -B external/libzip/build \ -DBUILD_SHARED_LIBS=OFF \ -DBUILD_DOC=OFF \ -DENABLE_BZIP2=OFF \ -DENABLE_LZMA=OFF \ -DENABLE_ZSTD=OFF \ -DENABLE_OPENSSL=OFF \ -DENABLE_GNUTLS=OFF \ -DENABLE_MBEDTLS=OFF \ -DENABLE_COMMONCRYPTO=OFF \ -DENABLE_WINDOWS_CRYPTO=OFF cmake --build external/libzip/build构建 llama 运行时(在 Apple Silicon 上启用 Metal)
./app/scripts/build_llama_macos.shmacOS 应用程序及其
.app包使用位于app/lib/precompiled*下的预编译运行时;它们不需要 Homebrew 安装的ggml或llama.cpp库。如果您在通用库路径中安装了旧版本的ggml或llama.cpp,建议将其卸载或移除,而不是依赖这些库。编译应用程序
cd app make -j8 # 使用 -jN 控制并行度 sudo make install # 可选默认情况下,二进制文件会被放置在
app/bin/aifilesorter。变体目标:
make -j8 MACOS_LLAMA_M1 # 输出 app/bin/m1/aifilesorter make -j8 MACOS_LLAMA_M2 # 输出 app/bin/m2/aifilesorter make -j8 MACOS_LLAMA_INTEL # 输出 app/bin/intel/aifilesorter这些目标会在编译应用程序之前重新构建 llama.cpp 运行时。在 Apple Silicon 上进行 Intel 交叉编译时,应使用 x86_64 版本的 Homebrew(位于
/usr/local),或者设置BREW_PREFIX=/usr/local,以便 Qt 和 pkg-config 正确解析路径。运行sudo make install会将 macOS 运行时库放置在/usr/local/lib/aifilesorter中,以避免与系统或其他 Homebrew 安装的 ggml 库发生冲突。每个变体使用不同的构建目录,以避免跨架构的文件冲突:- llama.cpp 库:
app/lib/precompiled-m1、app/lib/precompiled-m2、app/lib/precompiled-intel - 对象文件:
app/obj/arm64或app/obj/x86_64
- llama.cpp 库:
Windows
现在构建支持原生 MSVC + Qt6,无需 MSYS2。有两种方式可供选择,其中 vcpkg 方法最为简单。
选项 A - CMake + vcpkg(推荐)
安装先决条件:
- Visual Studio 2022,并安装“桌面 C++”工作负载
- CMake 3.21 或更高版本(Visual Studio 自带最新版本)
- vcpkg:https://github.com/microsoft/vcpkg(克隆并初始化)
- 通过 vcpkg 清单管理的
libmediainfo包(无需使用 vendored MediaInfo 子模块或二进制文件) - MSYS2 MinGW64 + OpenBLAS:从 https://www.msys2.org 安装 MSYS2,打开 MSYS2 MINGW64 终端,并运行
pacman -S --needed mingw-w64-x86_64-openblas。build_llama_windows.ps1脚本会使用此 OpenBLAS 版本来进行仅 CPU 构建(vcpkg 方案不适用),默认路径为C:\msys64\mingw64,除非您指定openblasroot=<path>或设置OPENBLAS_ROOT。
克隆仓库及子模块:
git clone https://github.com/hyperfield/ai-file-sorter.git cd ai-file-sorter git submodule update --init --recursive构建 vendored libzip(生成
zipconf.h和libzip.lib)在您将用于构建应用程序的相同 x64 Native Tools / VS Developer PowerShell 中运行以下命令:
cmake -S external\libzip -B external\libzip\build -A x64 ` -DBUILD_SHARED_LIBS=OFF ` -DBUILD_DOC=OFF ` -DENABLE_BZIP2=OFF ` -DENABLE_LZMA=OFF ` -DENABLE_ZSTD=OFF ` -DENABLE_OPENSSL=OFF ` -DENABLE_GNUTLS=OFF ` -DENABLE_MBEDTLS=OFF ` -DENABLE_COMMONCRYPTO=OFF ` -DENABLE_WINDOWS_CRYPTO=OFF cmake --build external\libzip\build --config Release确定您的 vcpkg 根目录。它就是包含
vcpkg.exe的文件夹(例如C:\dev\vcpkg)。如果
vcpkg已经在您的PATH中,可以运行以下命令来打印其位置:Split-Path -Parent (Get-Command vcpkg).Source否则,请使用您克隆 vcpkg 的目录。
关于 MediaInfo 的说明:在 Windows 上,您无需手动添加
MediaInfoLib的头文件和库路径。项目已经在app/vcpkg.json中声明了libmediainfo,而app\build_windows.ps1会使用 vcpkg 工具链和清单配置 CMake,从而让find_package(MediaInfoLib ...)自动解析该包。如果您想预先安装或明确验证,可以运行vcpkg install libmediainfo:x64-windows。构建捆绑的
llama.cpp运行时变体(请在同一台 x64 Native Tools / VS 2022 Developer PowerShell 终端中运行)。针对您需要的每个后端分别调用一次脚本。在运行仅 CPU 变体之前,请确保第 1 步中安装的 MSYS2 OpenBLAS 已就位(或显式指定openblasroot=<path>):# 仅 CPU / OpenBLAS app\scripts\build_llama_windows.ps1 cuda=off vulkan=off vcpkgroot=C:\dev\vcpkg # CUDA(需要匹配的 NVIDIA 工具包/驱动程序) app\scripts\build_llama_windows.ps1 cuda=on vulkan=off vcpkgroot=C:\dev\vcpkg # Vulkan(需要 LunarG Vulkan SDK 或厂商提供的 Vulkan 1.2+ 运行时) app\scripts\build_llama_windows.ps1 cuda=off vulkan=on vcpkgroot=C:\dev\vcpkg每次运行都会在
app\lib\precompiled\<cpu|cuda|vulkan>中生成相应的llama.dll/ggml*.dll对,并将运行时 DLL 复制到app\lib\ggml\w<variant>中。对于 Vulkan 构建,请安装最新的 LunarG Vulkan SDK(或厂商提供的运行时),确保在同一终端中运行vulkaninfo成功,然后再运行脚本。同时提供 Vulkan 和(可选)CUDA 构件,可以让StartAiFileSorter.exe在启动时自动检测最佳后端——优先使用 Vulkan,若 Vulkan 不可用则使用 CUDA,最后才回退到 CPU,因此 CUDA 并非必需。使用辅助脚本构建 Qt6 应用程序(仍在 VS 终端中运行)。该辅助脚本会通过
windeployqt阶段化运行时 DLL,并在不同变体之间共享同一套依赖项安装树,默认情况下可在一次运行中生成三个 Windows 版本:# 如果脚本执行被阻止,需在每次运行前执行一次: Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass app\build_windows.ps1 -Configuration Release -VcpkgRoot C:\dev\vcpkg
- 将
C:\dev\vcpkg替换为你克隆 vcpkg 的路径;该路径必须包含scripts\buildsystems\vcpkg.cmake。- 默认情况下,辅助脚本会生成以下输出目录:
- 启用 Windows 自动更新的标准安装程序构建:
app\build-windows\Release - 禁用更新检查的 Microsoft Store 构建:
app\build-windows-store\Release - 仅通知/手动更新的独立 Windows 构建:
app\build-windows-standalone\Release
- 启用 Windows 自动更新的标准安装程序构建:
- 使用
-Variants Standard、-Variants MsStore或-Variants Standalone只构建其中一部分。 aifilesorter.exe是主要的 Windows GUI 入口。StartAiFileSorter.exe仍作为旧版引导程序与其并存,并采用相同的更新模式。- 如果已设置
VCPKG_ROOT或VPKG_ROOT环境变量,或者vcpkg/vpkg已在PATH中,则-VcpkgRoot为可选。 - 每个变体目录都会生成各自的可执行文件以及暂存的 Qt/第三方 DLL 文件。如果只需二进制文件而不打包运行时 DLL,请使用
-SkipDeploy参数。 - 使用
-Parallel <N>可以覆盖默认的“所有核心”并行构建行为(例如,-Parallel 8)。默认情况下,脚本会调用cmake --build ... --parallel <core-count>和ctest -j <core-count>,以确保 MSBuild 和 Ninja 均得到充分利用。
- 默认情况下,辅助脚本会生成以下输出目录:
选项 B - CMake + Qt 在线安装程序
安装先决条件:
- Visual Studio 2022,配备桌面 C++ 工作负载
- 通过 Qt 在线安装程序安装 Qt 6.x MSVC 工具包(例如 Qt 6.6+ 配合 MSVC 2019/2022)
- CMake 3.21+
- vcpkg(用于非 Qt 库):curl、jsoncpp、sqlite3、openssl、fmt、spdlog、gettext、libmediainfo
构建自包含 libzip(生成
zipconf.h和libzip.lib)请在同一 x64 本机工具 / VS 开发者 PowerShell 中运行以下命令:
cmake -S external\libzip -B external\libzip\build -A x64 ` -DBUILD_SHARED_LIBS=OFF ` -DBUILD_DOC=OFF ` -DENABLE_BZIP2=OFF ` -DENABLE_LZMA=OFF ` -DENABLE_ZSTD=OFF ` -DENABLE_OPENSSL=OFF ` -DENABLE_GNUTLS=OFF ` -DENABLE_MBEDTLS=OFF ` -DENABLE_COMMONCRYPTO=OFF ` -DENABLE_WINDOWS_CRYPTO=OFF cmake --build external\libzip\build --config Release构建捆绑的
llama.cpp运行时(使用相同的 VS Shell)。任何缺失的 OpenBLAS/cURL 包都将通过 vcpkg 自动安装:pwsh .\app\scripts\build_llama_windows.ps1 [cuda=on|off] [vulkan=on|off] [vcpkgroot=C:\dev\vcpkg]在配置 GUI 之前需要完成此步骤,因为构建过程会链接到生成的
llama静态库/DLL。从仓库根目录配置 CMake,使 CMake 能够同时识别 Qt 安装和应用的 vcpkg 清单文件(根据你的 Qt 安装调整
CMAKE_PREFIX_PATH):$env:VCPKG_ROOT = "C:\path\to\vcpkg" # 例如 C:\dev\vcpkg $qt = "C:\Qt\6.6.3\msvc2019_64" # 示例 cmake -S app -B build -G "Ninja" ` -DCMAKE_PREFIX_PATH=$qt ` -DCMAKE_TOOLCHAIN_FILE=$env:VCPKG_ROOT\scripts\buildsystems\vcpkg.cmake ` -DVCPKG_MANIFEST_DIR=app ` -DAI_FILE_SORTER_REQUIRE_MEDIAINFOLIB=ON ` -DVCPKG_TARGET_TRIPLET=x64-windows cmake --build build --config Release此配置步骤启用了 vcpkg 清单模式,因此
libmediainfo会自动从app\vcpkg.json安装并解析。在 Windows 上无需手动编辑链接器或包含路径即可使用 MediaInfo。
注意事项
- 若要从头开始重新构建,运行
.\app\build_windows.ps1 -Clean。该脚本会在配置前删除选定变体的构建目录以及共享的app\build-windows-vcpkg_installed依赖树。 - 每次成功构建后,运行时 DLL 都会通过
windeployqt自动复制;如果你自行管理部署,可以使用-SkipDeploy跳过此步骤。 - 如果 Visual Studio 将
VCPKG_ROOT设置为其安装目录下的内置副本,请将 vcpkg 克隆到一个可写目录(例如C:\dev\vcpkg),并在运行build_llama_windows.ps1时指定vcpkgroot=<path>。 - 如果你计划支持 CUDA 或 Vulkan 加速,请在配置 CMake 之前为每个目标后端运行
build_llama_*辅助脚本,以确保相关库已存在。运行时可以同时支持两者,并在启动时自动选择,因此 CUDA 并非必需。 -BuildTests和-RunTests目前仅在Standard变体中构建并执行测试,这是主要的 Windows 开发和 CI 配置。
运行测试
基于 Catch2 的单元测试是可选的。可通过 CMake 启用:
cmake -S app -B build-tests -DAI_FILE_SORTER_BUILD_TESTS=ON -DAI_FILE_SORTER_REQUIRE_MEDIAINFOLIB=ON
cmake --build build-tests --target ai_file_sorter_tests --parallel $(nproc)
ctest --test-dir build-tests --output-on-failure -j $(nproc)
在 macOS 上,将 $(nproc) 替换为 $(sysctl -n hw.ncpu)。
在 Windows(PowerShell)上,使用:
cmake -S app -B build-tests -DAI_FILE_SORTER_BUILD_TESTS=ON -DAI_FILE_SORTER_REQUIRE_MEDIAINFOLIB=ON
cmake --build build-tests --target ai_file_sorter_tests --parallel $env:NUMBER_OF_PROCESSORS
ctest --test-dir build-tests --output-on-failure -j $env:NUMBER_OF_PROCESSORS
注意事项
- 列出单个 Catch2 测试用例:
./build-tests/ai_file_sorter_tests --list-tests - 打印每个测试用例名称(包括通过的用例):
./build-tests/ai_file_sorter_tests --verbosity high --success
在 Windows 上,你可以将 -BuildTests(以及 -RunTests 以执行 ctest)传递给 app\build_windows.ps1:
app\build_windows.ps1 -Configuration Release -Variants Standard -BuildTests -RunTests
当前的测试套件(位于 tests/unit)专注于核心实用工具;随着新功能的覆盖,可逐步扩展。
运行时选择后端
Linux 启动脚本(app/bin/run_aifilesorter.sh 或 aifilesorter-bin)以及 Windows 启动程序都接受以下可选标志:
--cuda={on|off}– 强制启用或禁用 CUDA 后端。--vulkan={on|off}– 强制启用或禁用 Vulkan 后端。
如果不提供任何标志,应用程序会按优先级顺序自动检测可用的运行时环境(Vulkan → CUDA → CPU)。可以使用这些标志来跳过某个后端(例如,--cuda=off 会强制使用 Vulkan 或 CPU,即使已安装 CUDA;--vulkan=off 则会显式尝试使用 CUDA),或者用于验证新安装的软件栈(例如,--vulkan=on)。同时为两个标志传递 on 将被拒绝;如果未检测到任何 GPU 后端,应用程序将自动回退到 CPU 模式。
Vulkan 与显存注意事项
- 在可用的情况下优先使用 Vulkan;只有在缺少 Vulkan 或明确请求时才会使用 CUDA。
- 应用程序会根据可用显存自动估算
n_gpu_layers值。为确保安全,集成显卡的上限被限制为 4 GiB,这可能会限制模型的卸载程度。 - 如果显存紧张,应用程序可能会回退到 CPU 或减少卸载比例。一般来说,8 GB 及以上的显存能够提供更流畅的 Vulkan 卸载和图像分析体验;而 4 GB 显存通常会导致部分卸载或直接回退到 CPU。
- 可以通过设置环境变量
AI_FILE_SORTER_N_GPU_LAYERS来覆盖自动估算值(-1表示自动,0表示强制使用 CPU),或通过AI_FILE_SORTER_GPU_BACKEND=cpu强制使用 CPU 后端。 - 对于图像分析任务,可以将
AI_FILE_SORTER_VISUAL_USE_GPU=0设置为 0,以强制视觉编码器在 CPU 上运行,从而避免显存分配错误。
环境变量
运行时与 GPU:
AI_FILE_SORTER_GPU_BACKEND- 选择 GPU 后端:auto(默认)、vulkan、cuda或cpu。AI_FILE_SORTER_N_GPU_LAYERS- 覆盖 llama.cpp 的n_gpu_layers;-1表示自动,0表示强制使用 CPU。AI_FILE_SORTER_CTX_TOKENS- 覆盖本地 LLM 上下文长度(默认 2048;限制在 512–8192)。AI_FILE_SORTER_GGML_DIR- 指定加载 ggml 后端共享库的目录。在 macOS 上,此路径仅会从捆绑包或同级应用运行时目录中自动发现;若需自定义 ggml 运行时,请显式设置该变量。
视觉 LLM:
LLAVA_MODEL_URL- 视觉 LLM GGUF 模型的下载 URL(启用图像分析所必需)。LLAVA_MMPROJ_URL- 视觉 LLM mmproj GGUF 文件的下载 URL(启用图像分析所必需)。AI_FILE_SORTER_VISUAL_USE_GPU- 强制视觉编码器使用 GPU(1)或 CPU(0)。默认为自动;若 VRAM 较低,Vulkan 可能会回退到 CPU。
超时与日志:
AI_FILE_SORTER_LOCAL_LLM_TIMEOUT- 等待本地 LLM 响应的秒数(默认 60)。AI_FILE_SORTER_REMOTE_LLM_TIMEOUT- 等待 OpenAI/Gemini 响应的秒数(默认 10)。AI_FILE_SORTER_CUSTOM_LLM_TIMEOUT- 等待自定义 OpenAI 兼容 API 响应的秒数(默认 60)。AI_FILE_SORTER_LLAMA_LOGS- 启用 verbose llama.cpp 日志(1/true);同时也会尊重LLAMA_CPP_DEBUG_LOGS设置。
存储与更新:
AI_FILE_SORTER_CONFIG_DIR- 覆盖基础配置目录(config.ini所在位置)。CATEGORIZATION_CACHE_FILE- 覆盖配置目录内的 SQLite 缓存文件名。UPDATE_SPEC_FILE_URL- 覆盖更新源规范 URL(开发/测试专用)。更新程序现会分别读取update.windows、update.macos和update.linux中的平台特定流,同时仍兼容旧版单一流格式。AI_FILE_SORTER_UPDATER_TEST_MODE- 启用 Windows 更新程序的实时测试模式(1/true)。启用后,应用将跳过获取更新源,并根据以下值合成一个较新版本。AI_FILE_SORTER_UPDATER_TEST_URL- Windows 更新程序实时测试包的直接 URL。该 URL 可指向.exe、.msi,或包含且仅包含一个.exe或.msi的.zip文件。AI_FILE_SORTER_UPDATER_TEST_SHA256- 下载的实时测试包的 SHA-256 校验和。若 URL 指向 ZIP 文件,则此校验和必须针对 ZIP 归档本身。AI_FILE_SORTER_UPDATER_TEST_VERSION- 实时测试模式显示的可选合成版本。默认为当前应用版本加一个额外的尾段,例如1.7.2.1。AI_FILE_SORTER_UPDATER_TEST_MIN_VERSION- 实时测试模式的可选最小版本。默认为0.0.0,使测试表现为可选更新。
更新源示例:
{
"update": {
"current_version": "1.7.1",
"min_version": "1.6.0",
"download_url": "https://filesorter.app/download",
"windows": {
"current_version": "1.7.1",
"min_version": "1.6.0",
"download_url": "https://filesorter.app/download",
"installer_url": "https://filesorter.app/downloads/AIFileSorterSetup-1.7.1.exe",
"installer_sha256": "0123456789abcdef0123456789abcdef0123456789abcdef0123456789abcdef"
},
"macos": {
"current_version": "1.7.1",
"min_version": "1.6.0",
"download_url": "https://filesorter.app/download"
},
"linux": {
"current_version": "1.7.1",
"min_version": "1.6.0",
"download_url": "https://filesorter.app/download"
}
}
}
兼容性说明:
- 较旧版本的应用仅读取
update下的扁平顶层字段,因此若仍需支持这些版本,请在其中保留current_version、min_version和download_url作为旧版兼容流。 - 新版本的应用更倾向于使用平台特定的流,当存在
update.windows、update.macos或update.linux时,将优先使用这些流。 - 旧版兼容流只能表示一个通用流,无法区分不同平台的版本或安装程序。
仅限 Windows 的直接安装程序更新:
installer_url- Windows 安装程序包的直接 URL。installer_sha256- 用于在启动前验证下载的安装程序的 SHA-256 校验和。installer_url现在也可以指向 ZIP 归档,只要归档内恰好包含一个安装程序有效载荷(.exe或.msi)即可。- 当这两个字段同时存在于 Windows 平台上时,应用可以下载安装程序、验证其完整性,然后提示用户:“退出应用并启动安装程序以完成更新。”
Windows 更新程序实时测试模式:
aifilesorter.exe在 Windows 上直接接受以下标志:--updater-live-test--updater-live-test-url=<https://.../AIFileSorterSetup.zip>--updater-live-test-sha256=<下载包的 SHA-256>--updater-live-test-version=<可选版本>--updater-live-test-min-version=<可选最小版本>- 若您仍在使用引导程序路径,
StartAiFileSorter.exe也会接受并转发相同的标志系列。 - 实时测试模式仅适用于 Windows,且会绕过正常的更新 JSON 流。
- 如果 ZIP 包含多个
.exe或.msi,更新程序将停止操作,而不会猜测应启动哪个安装程序。 - 若已设置
--updater-live-test但未提供 URL 或 SHA 校验和标志,aifilesorter.exe还会查找可执行文件旁边的live-test.ini文件,并从中填充缺失的值。 - 命令行标志优先于
live-test.ini,因此您可以保留一个默认文件,并在需要时仅覆盖某一字段。
live-test.ini 示例:
[LiveTest]
download_url = https://files.example.com/AIFileSorterSetup-1.7.3.zip
sha256 = 0123456789abcdef0123456789abcdef0123456789abcdef0123456789abcdef
current_version = 1.7.3
min_version = 0.0.0
PowerShell 启动示例:
.\aifilesorter.exe `
--development `
--updater-live-test
分类缓存数据库
AI 文件分类器会将分类结果存储在 config.ini 旁边的本地 SQLite 数据库中(可通过 AI_FILE_SORTER_CONFIG_DIR 覆盖基础目录)。此缓存允许应用程序跳过已处理的文件,并在多次运行之间保留重命名建议。
存储的内容包括:
- 目录路径、文件名和文件类型(用作唯一键)。
- 类别/子类别、分类体系 ID、分类风格和时间戳。
- 建议的文件名(用于图片和文档的重命名建议)。
- 仅重命名标志(在启用图片/文档仅重命名模式时使用)。
- 已应用重命名标志(标记已执行重命名操作,以避免再次提供该建议)。
如果您从“审核”对话框中重命名或移动文件,缓存条目将更新为新名称。后续运行时,已重命名的图片文件将被跳过,不再进行视觉分析和重命名建议。在“审核”对话框中,当启用仅重命名模式时,这些已重命名的行会被隐藏;但若启用分类功能,则仍会显示,以便您将其移动到相应类别文件夹中。要重置某个文件夹的缓存,您可以接受重新分类提示,或删除缓存文件(或将 CATEGORIZATION_CACHE_FILE 指向一个新的文件名)。
卸载
- Debian/Ubuntu 包安装:
sudo apt remove aifilesorter - Linux 源码安装:
cd app && sudo make uninstall - macOS 源码安装:
cd app && sudo make uninstall
对于源码安装,make uninstall 会移除可执行文件以及暂存的预编译库。如果您不再需要它们,也可以删除位于 ~/.local/share/aifilesorter/llms(Linux)或 ~/Library/Application Support/aifilesorter/llms(macOS)中的本地 LLM 模型缓存。
使用您的 OpenAI API 密钥
想使用 ChatGPT 而不是内置的本地模型吗?请提供您自己的 OpenAI API 密钥:
- 在应用程序中打开“设置 -> 选择 LLM”。
- 选择“ChatGPT(OpenAI API 密钥)”,粘贴您的密钥,并输入您想要使用的 ChatGPT 模型(例如
gpt-4o-mini、gpt-4.1或o3-mini)。 - 点击“确定”。密钥将本地存储在您的 AI 文件分类器配置文件中(应用程序数据文件夹中的
config.ini),并在后续运行中重复使用。清空该字段即可移除密钥。 - 只有在此选项被选中时才需要互联网连接。
应用程序不再嵌入捆绑密钥;您始终需要提供自己的 OpenAI 密钥。
使用您的 Gemini API 密钥
更喜欢 Google 的模型吗?请使用您自己的 Gemini API 密钥:
- 访问 https://aistudio.google.com 并使用您的 Google 帐户登录。
- 在左侧导航栏中,打开“API 密钥”(或“获取 API 密钥”),然后点击“创建 API 密钥”。选择“在新项目中创建 API 密钥”(或选择现有项目),并复制生成的密钥。
- 在应用程序中,打开“设置 -> 选择 LLM”,选择“Gemini(Google AI Studio API 密钥)”,粘贴您的密钥,并输入您想要的 Gemini 模型(例如
gemini-2.5-flash-lite、gemini-2.5-flash或gemini-2.5-pro)。 - 点击“确定”。密钥将本地存储在您的 AI 文件分类器配置文件中,并在后续运行中重复使用。清空该字段即可移除密钥。
AI Studio 密钥可在免费层级使用,直到达到 Google 的使用限制;更高的配额或企业级使用则需要通过 Google Cloud 进行付费。 应用程序调用 Gemini 的
v1generateContent端点;请使用来自https://generativelanguage.googleapis.com/v1/models?key=YOUR_KEY的模型 ID。您可以带或不带前缀models/输入这些 ID。
测试
从仓库根目录清理任何旧缓存并运行 CTest 包装脚本:
cd app rm -rf ../build-tests # 清除另一个检出中的缓存 ./scripts/rebuild_and_test.sh该脚本会配置到
../build-tests,构建后运行ctest。如果您有多个仓库副本(例如
ai-file-sorter和ai-file-sorter-mac-dist),每个都需要自己的build-tests文件夹;如果复用其他路径下的文件夹,CMake 会报错,提示源代码和构建目录不匹配。
诊断工具
如果您需要报告错误或收集故障排除数据,可以使用内置的诊断脚本:
- macOS:
./app/scripts/collect_macos_diagnostics.sh - Linux:
./app/scripts/collect_linux_diagnostics.sh - Windows(PowerShell):
.\app\scripts\collect_windows_diagnostics.ps1
每个脚本会收集相关日志,屏蔽常见的敏感路径,并将结果打包成 ZIP 存档以便分享。有关时间过滤和自动打开输出文件夹等选项,请参阅 app/scripts/README.md。
使用方法
- 启动应用程序(根据您的操作系统,参见“安装”部分的最后一步)。
- 选择一个要分析的目录。
使用试运行和撤销功能
- 在结果对话框中,您可以启用“试运行(仅预览,不移动文件)”以预览计划中的移动操作。预览对话框会显示源路径和目标路径,但不会实际移动任何文件。
- 实际排序完成后,应用程序会保存持久化的撤销计划。您可以通过“编辑 → ‘撤销上次运行’”来恢复原状(尽力而为;会跳过冲突或已更改的情况)。
- 根据您的偏好,在主窗口上勾选相应的复选框。
- 点击“分析”按钮。应用程序将根据您选择的选项扫描每个文件和/或目录。
- 将出现一个审核对话框。请确认分配的类别(以及子类别,如果步骤 3 中已启用)。
- 点击“确认并排序!”以移动文件,或点击“稍后再继续”以推迟操作。由于分类结果已被保存,您可以随时从中断处继续。
对远程目录(如 NAS)进行分类
按照“使用方法”中的步骤操作,但修改第 2 步如下:
Windows: 为您的网络共享分配一个驱动器号(例如
Z:或X:)参考此处的说明。Linux 和 macOS: 使用类似以下命令将网络共享挂载到本地文件夹:
sudo mount -t cifs //192.168.1.100/shared_folder /mnt/nas -o username=myuser,password=mypass,uid=$(id -u),gid=$(id -g)
(请将 192.168.1.100/shared_folder 替换为您实际的网络位置路径,并根据需要调整选项。)
贡献
- 分支仓库并提交拉取请求。
- 在 GitHub 问题跟踪器中报告问题或提出功能建议。
- 遵循现有的代码风格和文档格式。
知识产权声明
- Curl:https://github.com/curl/curl
- Dotenv:https://github.com/motdotla/dotenv
- git-scm:https://git-scm.com
- Hugging Face:https://huggingface.co
- JSONCPP:https://github.com/open-source-parsers/jsoncpp
- Llama:https://www.llama.com
- libzip:https://libzip.org
- 本地文件整理器:https://github.com/QiuYannnn/Local-File-Organizer
- llama.cpp:https://github.com/ggml-org/llama.cpp
- MediaInfoLib:https://mediaarea.net/en/MediaInfo
- Mistral AI:https://mistral.ai
- OpenAI:https://platform.openai.com/docs/overview
- OpenSSL:https://github.com/openssl/openssl
- PDFium:https://pdfium.googlesource.com/pdfium/
- Poppler (pdftotext):https://poppler.freedesktop.org/
- pugixml:https://pugixml.org
- Qt:https://www.qt.io/
- spdlog:https://github.com/gabime/spdlog
- unzip (Info-ZIP):https://infozip.sourceforge.net/
许可证
本项目采用 GNU Affero 通用公共许可证(GNU AGPL)进行授权。详情请参阅 LICENSE 文件,或访问 https://www.gnu.org/licenses/agpl-3.0.html。
捐赠
支持 AI 文件排序器 的开发及其未来功能。您的每一份贡献都至关重要!
版本历史
v1.7.32026/03/22v1.7.02026/03/09v1.6.02026/02/05v1.5.02026/01/11v1.4.02025/11/30v1.3.02025/11/22v1.1.02025/11/09v1.0.02025/10/30v0.9.72025/10/19v0.9.32025/09/22v0.9.22025/08/06v0.9.12025/08/01v0.9.02025/07/17v0.8.32025/02/06v0.8.02025/01/30常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。