nanoVLM
nanoVLM 是 Hugging Face 推出的一个极简视觉语言模型(VLM)训练框架,专为想要快速上手理解和定制小型多模态 AI 的开发者与研究人员设计。
这个项目最大的特点是"小而美"——整个核心代码仅约 750 行纯 PyTorch 实现,包含视觉编码器、语言解码器、模态投影和训练循环等全部组件,代码清晰易读,没有复杂抽象。借鉴了 Andrej Karpathy nanoGPT 的教育理念,nanoVLM 不追求最新 SOTA 性能,而是让开发者能够真正"看懂并改动"每一行代码。
nanoVLM 解决了传统 VLM 框架过于复杂、难以定制的问题。基于 SigLIP 视觉骨干和 SmolLM2 语言模型构建的 222M 参数版本,仅需单张 H100 GPU 训练约 6 小时即可在 MMStar 基准达到 35.3% 的准确率,证明了小模型也能具备实用能力。
适合 AI 研究者、算法工程师以及希望深入理解多模态模型原理的技术爱好者。无论是想快速验证新想法、教学演示,还是为特定场景微调小型 VLM,nanoVLM 都是理想的起点。项目提供 Colab 一键运行和详细教程,大幅降低入门门槛。
使用场景
某高校计算机视觉实验室的研究生小李,需要为智能仓储机器人开发一个视觉问答模块,让机器人能够理解仓库场景图像并回答"货架第三层还剩多少箱货物"这类问题。
没有 nanoVLM 时
- 代码黑箱,无从下手:尝试基于 LLaVA 或 Qwen-VL 做微调,但官方仓库动辄上万行代码,Vision Encoder、Projector、LLM 的交互逻辑层层嵌套,花了两周还没理清数据流
- 算力门槛高不可攀:实验室只有一台 4×A6000 的服务器,主流 VLM 微调需要 8×A100 起步,不得不申请校外云计算资源,预算和审批流程拖慢进度
- 调试如同盲人摸象:训练 loss 异常时,由于框架封装过深,无法快速定位是图像 token 化、投影层还是注意力机制的问题,只能盲目调参
使用 nanoVLM 后
- 750 行代码全透明:SigLIP 视觉编码器、SmolLM 语言模型、模态投影层各自独立且精简,小李半天就梳理完数据流,直接在
models/modality_projection.py里实验新的融合策略 - 单卡 H100 六小时出模型:222M 参数规模配合高效 packing 策略,实验室现有硬件即可训练,当天完成原型验证,无需额外申请资源
- 问题定位精准高效:训练不稳定时,借助纯 PyTorch 实现和清晰的模块划分,快速发现是图像 patch 数量与文本长度不匹配,调整
image_splitting参数后顺利解决
nanoVLM 用极简代码架构打破了 VLM 研发的门槛,让研究者把精力从"看懂框架"转向"创新算法"本身。
运行环境要求
- Linux
- macOS
- Windows
需要 NVIDIA GPU(CUDA-enabled),显存最低 4.5GB(batch size=1),推荐 8GB+(batch size≤16),支持 H100 等高端显卡进行大规模训练
未说明

快速开始
nanoVLM

[!TIP] 我们撰写了一篇 nanoVLM 教程,将引导你了解整个仓库并帮助你快速上手。
[!NOTE] 我们在 2025 年 9 月 9 日推送了一些重大变更(breaking changes)。这些更新包括使用图像分割(image splitting)以及在多节点上训练。这些功能用于 FineVision 发布的消融实验(ablations)。代码库中一些支持脚本(例如 notebook 或内存评估)可能已经无法正常工作。同样,旧版本的 nanoVLM 训练模型也可能受到影响(类似于下方的说明)。如果你发现某些功能无法正常工作,请在 Issues 中告知我们或提交 PR!
[!NOTE] 我们在 2025 年 6 月 4 日对仓库推送了一些重大变更(breaking changes)。为了实现更智能的打包(smarter packing),我们重构了图像和文本嵌入(embeddings)的组合方式。为了保持一切尽可能顺畅,我们使用新的流程训练了一个新的 nanoVLM-450M 模型,同时保留旧的 nanoVLM-222M 与旧流程兼容。如果你现在克隆此仓库或将更新拉取到本地,默认将是新的 450M 模型。如果你希望获得更简单的理解和更简洁的代码库,可以使用 v0.1 版本。该版本与旧的 222M 模型开箱即用。
nanoVLM 是用于训练/微调小型视觉语言模型(Vision-Language Model, VLM)的最简仓库,采用纯 PyTorch 轻量级实现。代码本身非常易读且易于理解,模型由视觉骨干网络(Vision Backbone,models/vision_transformer.py 约 150 行)、语言解码器(Language Decoder,models/language_model.py 约 250 行)、模态投影(Modality Projection,models/modality_projection.py 约 50 行)、VLM 本身(models/vision_language_model.py 约 100 行)以及简单的训练循环(train.py 约 200 行)组成。
类似于 Andrej Karpathy 的 nanoGPT,我们希望为社区提供一个非常简单的视觉语言模型实现和训练脚本。我们并不声称这是一个新的 SOTA(State-of-the-Art,最先进)模型,而是一项教育性工作——如果你拥有合适的硬件,它能发挥相当大的威力!你应该能够在短时间内调整和尝试代码。
nanoVLM 能做什么?
本仓库的模型定义和训练逻辑约 750 行,外加一些样板化的日志记录和参数加载代码。
使用 SigLIP-B/16-224-85M 和 HuggingFaceTB/SmolLM2-135M 作为骨干网络,可得到一个 222M 的 nanoVLM。在单张 H100 GPU 上训练约 6 小时,使用约 170 万条 the cauldron 样本,可在 MMStar 上达到 35.3% 的准确率。
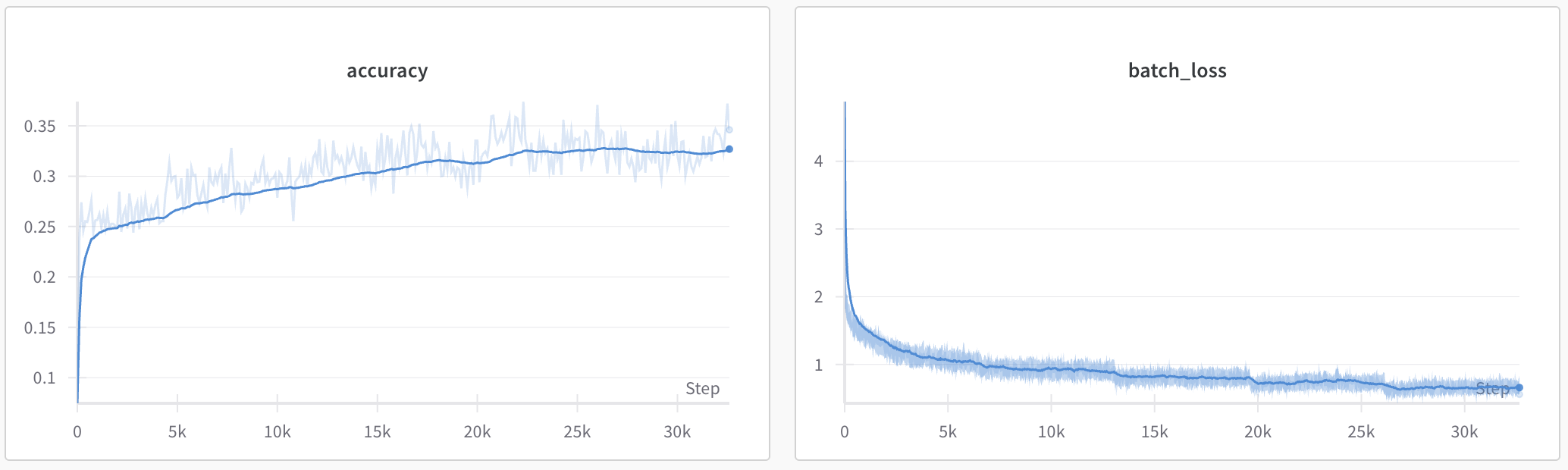
因此,这是一个简单但强大的视觉语言模型入门平台。非常适合尝试不同的设置和配置,探索小型视觉语言模型的能力和效率!
快速开始
你可以克隆仓库、设置环境并使用脚本开始,或者直接 在 Colab 中打开。你也可以使用 交互式 notebook 来上手!
环境设置
我们非常喜欢 uv,推荐将其作为包管理器。但你可以随意使用自己喜欢的工具。
首先克隆仓库:
git clone https://github.com/huggingface/nanoVLM.git
cd nanoVLM
如果你想使用 uv:
uv init --bare --python 3.12
uv sync --python 3.12
source .venv/bin/activate
uv add torch numpy torchvision pillow datasets huggingface-hub transformers wandb
# 可选:如需 lmms-eval 集成,需要从源码安装,参见"使用 lmms-eval 评估"部分
如果你更喜欢其他环境管理器,只需安装这些包:
pip install torch numpy torchvision pillow datasets huggingface-hub transformers wandb
# 可选:如需 lmms-eval 集成,需要从源码安装,参见"使用 lmms-eval 评估"部分
依赖项:
torch<3numpy<3torchvision用于图像处理器(image processors)pillow用于图像加载datasets用于训练数据集huggingface-hub和transformers用于加载预训练骨干网络wandb用于日志记录
训练
要训练 nanoVLM,你可以直接使用提供的训练脚本。训练完成后,你的模型将被上传到 Hub!
wandb login --relogin
huggingface-cli login
python train.py
这将使用默认的 models/config.py。
生成
要尝试 训练好的模型,你可以直接使用提供的生成脚本
python generate.py
或者,要使用你自己训练的模型,你可以直接运行:
python generate.py --checkpoint /your/path/to/trained_models
如果我们将 assets/image.png 中的示例图像与问题一起输入模型,我们会得到以下输出。即使经过短期训练,模型也能识别出图片中的猫。
输入:
图像 + 'What is this?'
输出:
生成 1: This is a cat sitting on the ground. I think this is a cat sitting on the ground.
生成 2: This picture is clicked outside. In the center there is a brown color cat seems to be sitting on
生成 3: This is a cat sitting on the ground, which is of white and brown in color. This cat
生成 4: This is a cat sitting on the ground. I think this is a cat sitting on the ground.
生成 5: This is a cat sitting on the ground, which is covered with a mat. I think this is
使用 lmms-eval 评估
nanoVLM 现在支持使用全面的 lmms-eval 工具包进行评估:
# 安装 lmms-eval(必须从源码安装)
uv pip install git+https://github.com/EvolvingLMMs-Lab/lmms-eval.git
# 确保环境变量设置正确,并且已登录 HF
export HF_HOME="<Path to HF cache>"
huggingface-cli login
# 在多个基准测试上评估训练好的模型
python evaluation.py --model lusxvr/nanoVLM-450M --tasks mmstar,mme
# 如果你想在训练期间使用它,只需导入模块并像命令行一样调用它。
# 你可以传递所有能在命令行中传递的参数。
训练过程中的评估在完整的 DDP(Distributed Data Parallel,分布式数据并行)设置下运行。
from evaluation import cli_evaluate args = argparse.Namespace( model='lusxvr/nanoVLM-450M', # 这可以是检查点路径或模型本身 tasks='mmstar,mmmu,ocrbench', batch_size=128 # 根据你的 GPU 进行调整,需要传递此参数以避免 OOM(Out of Memory,内存不足)错误 ) results = cli_evaluate(args)
## Hub 集成
**nanoVLM** 提供了便捷的方法,用于从 Hugging Face Hub 加载和保存模型。
### 预训练权重
以下是从 Hugging Face Hub 上的仓库加载的方法。这是开始使用预训练权重的推荐方式。
```python
# 从 Hub 加载预训练权重
from models.vision_language_model import VisionLanguageModel
model = VisionLanguageModel.from_pretrained("lusxvr/nanoVLM-450M")
推送到 Hub
当你训练好一个 nanoVLM 模型后,你可能希望将其分享到 Hugging Face Hub。你可以通过以下方式轻松实现:
... # 加载并训练你的模型
# 推送到 `username/my-awesome-nanovlm-model` 仓库
model.push_to_hub("my-awesome-nanovlm-model")
模型将以配置文件 config.json 和权重文件 model.safetensors 的形式保存在 Hub 上。同时还会为你生成一个模型卡片 README.md,其中包含一些高级信息。你可以手动更新它以说明你的工作。
如果仓库不存在,系统会为你自动创建。默认情况下仓库是公开的。如果你不想公开分享,可以传递 private=True 参数。
本地保存/加载
如果你不想将模型托管在 Hugging Face Hub 上,仍然可以将其保存在本地:
... # 加载并训练你的模型
# 保存到本地文件夹
model.save_pretrained("path/to/local/model")
然后你可以从本地路径重新加载:
# 从本地路径加载预训练权重
from models.vision_language_model import VisionLanguageModel
model = VisionLanguageModel.from_pretrained("path/to/local/model")
VRAM 使用量
了解训练时的 VRAM(Video Random Access Memory,显存)需求对于选择合适的硬件和 batch size(批量大小)至关重要。我们在单张 NVIDIA H100 GPU 上对默认的 nanoVLM 模型(222M 参数)进行了基准测试。以下是训练过程中不同 batch size 下观察到的峰值 VRAM 使用量摘要(包括模型、梯度和优化器状态):
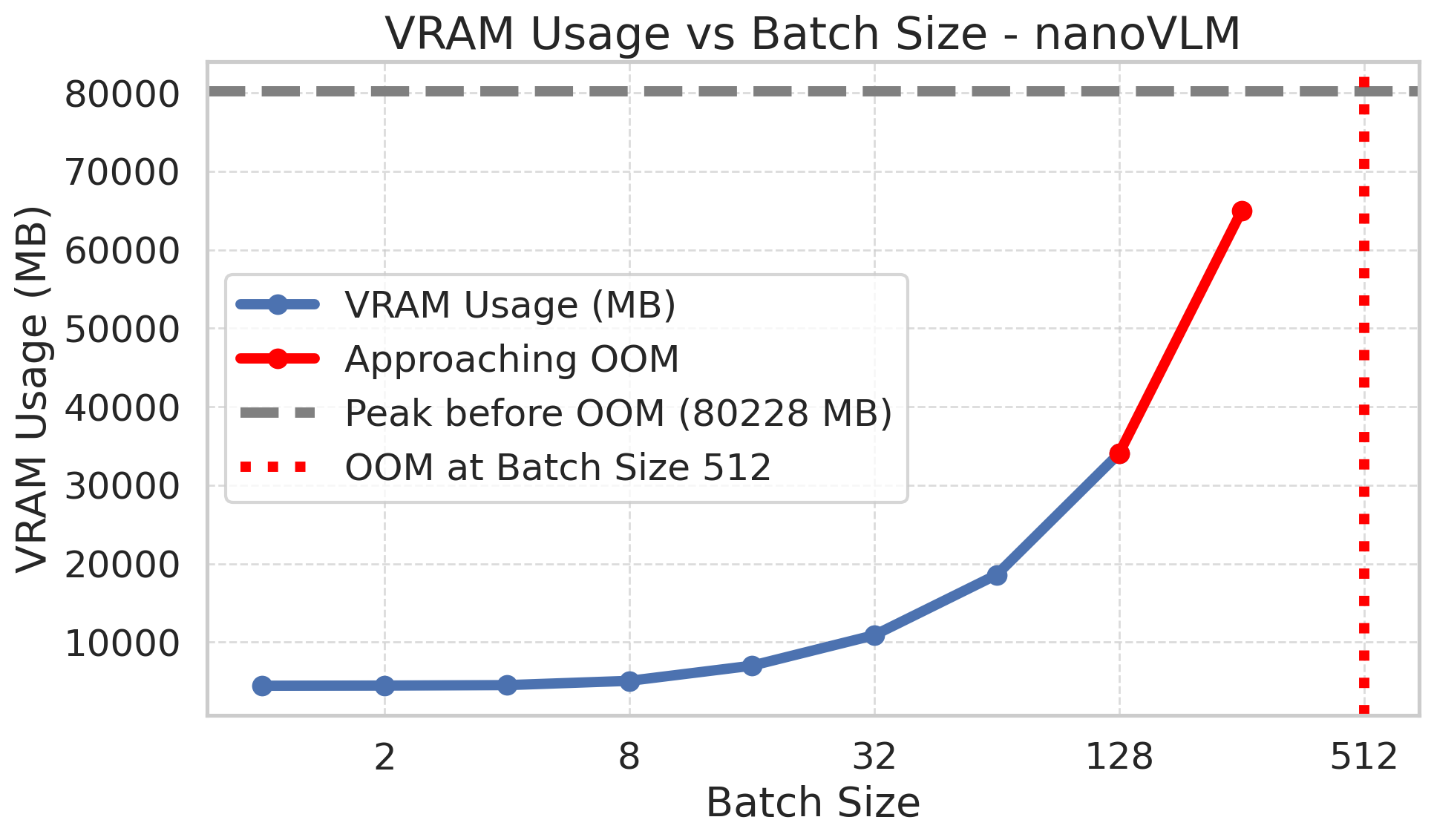
以下是近似峰值 VRAM 使用量的详细分解:
模型加载到设备后的 VRAM 分配: 871.44 MB
--- VRAM 使用量摘要 ---
Batch Size 1: 4448.58 MB
Batch Size 2: 4465.39 MB
Batch Size 4: 4532.29 MB
Batch Size 8: 5373.46 MB
Batch Size 16: 7604.36 MB
Batch Size 32: 12074.31 MB
Batch Size 64: 20995.06 MB
Batch Size 128: 38834.19 MB
Batch Size 256: 74561.08 MB
Batch Size 512: OOM (OOM 前峰值: 80247.67 MB)
请注意,VRAM 测量是在一个小型设置上进行的,使用的是 'SmolLM2-135M',最大输入序列长度为 128 个 token。这可能与项目中当前的默认配置有所不同。
关键要点:
- 即使 batch size 为 1,你也需要至少约 4.5 GB 的 VRAM 来训练默认模型。
- 拥有约 8 GB VRAM 时,你应该能够使用最大为 16 的 batch size 进行训练。
为你的设置测量:
上述数值是针对默认模型配置的。如果你修改了模型架构(例如,更改 backbone(主干网络)、hidden size(隐藏层大小))或使用不同的序列长度,你的 VRAM 需求将会发生变化。
我们提供了一个脚本 measure_vram.py,允许你在特定机器上测试 VRAM 需求,以及针对你选择的模型配置和 batch size。
使用方法:
- 确保你拥有支持 CUDA 的 GPU 并安装了 PyTorch。
- 使用你期望的 batch size 运行脚本。你也可以指定一个模型检查点(如果有的话),或者让它基于默认的
VLMConfig初始化一个新模型。
# 示例:使用新的默认模型测试 batch size 1, 2, 4, 8
python measure_vram.py --batch_sizes "1 2 4 8"
# 示例:使用特定检查点和不同的 batch size 进行测试
python measure_vram.py --vlm_checkpoint_path path/to/your/model.pth --batch_sizes "16 32 64"
该脚本将输出每个测试 batch size 的峰值 VRAM 分配量,帮助你确定适合你硬件的可行训练配置。
贡献
我们欢迎对 nanoVLM 的贡献!然而,为了保持仓库对简洁性和纯 PyTorch 的关注,我们有以下指导原则:
- 纯 PyTorch: 我们的目标是将 nanoVLM 保持为轻量级的纯 PyTorch 实现。引入
transformers.Trainer、accelerate或deepspeed等依赖的贡献将不被接受。 - 新功能: 如果你有新功能的想法,请先开启一个 issue 讨论范围和实现细节。这有助于确保你的贡献与项目目标保持一致。
- Bug 修复: 欢迎提交 bug 修复的 pull request。
路线图
以下是我们近期计划开展的一些领域。欢迎在这些领域做出贡献:
- 评估: 实现更多评估方法或改进我们的 MMStar 实现(高度重视)
- 数据打包: 实现一种从输入数据创建给定大小 pack(数据包)的方法,以优化训练。
- 多 GPU 训练: 在多个 GPU 上进行训练
- 多图像支持: 使用多张图像进行训练
- 图像分割: 通过图像分割实现更高分辨率,如同 SmolVLM 中所做的那样。
- VLMEvalKit: 集成到 VLMEvalKit 以启用更多基准测试
引用
如果你喜欢这个项目并希望在某些地方使用它,请使用以下引用:
@misc{wiedmann2025nanovlm,
author = {Luis Wiedmann and Aritra Roy Gosthipaty and Andrés Marafioti},
title = {nanoVLM},
year = {2025},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/huggingface/nanoVLM}}
}
版本历史
v0.22025/06/04v0.12025/05/20常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。