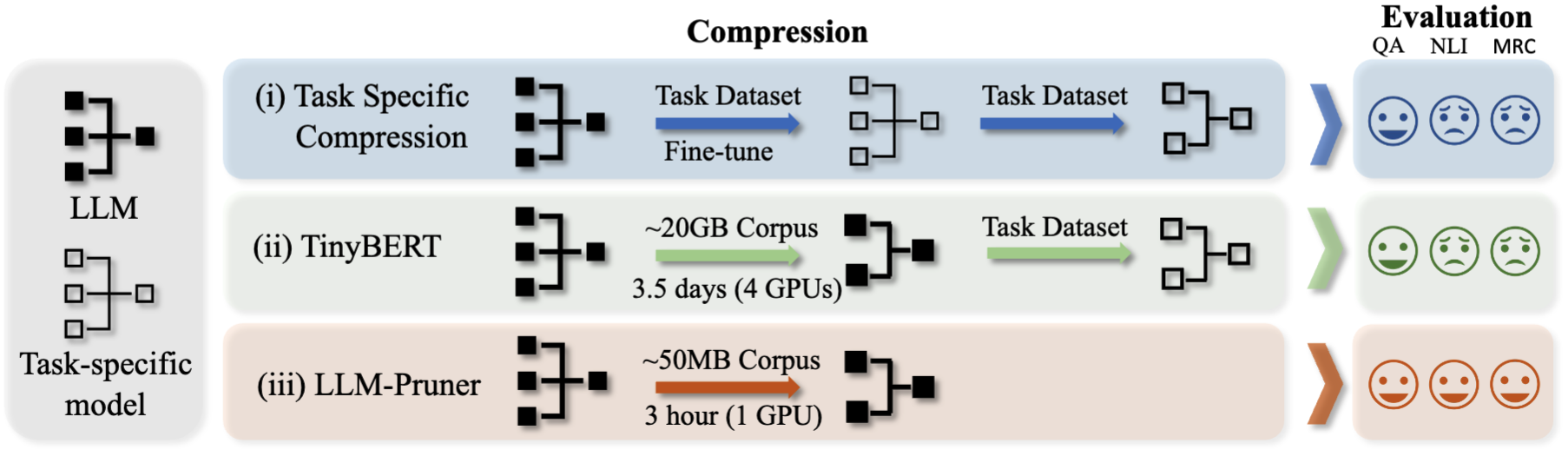
LLM-Pruner
LLM-Pruner 是一款专注于大语言模型结构剪枝的开源项目,致力于将庞大的语言模型压缩至任意尺寸。针对大模型部署成本高、推理速度慢的痛点,LLM-Pruner 通过结构剪枝技术,在显著减少模型参数的同时,有效保留其原有的多任务处理能力。
LLM-Pruner 的一大亮点在于极高的效率与低资源门槛。用户仅需约 5 万条公开样本进行后训练,便可在数分钟内完成剪枝,数小时内恢复模型性能。LLM-Pruner 广泛支持 Llama 系列(含最新的 Llama 3/3.1)、BLOOM、Vicuna、Baichuan 等主流架构,并持续更新以适配新特性如 GQA。
无论是希望降低推理成本的开发者,还是探索模型压缩策略的研究人员,LLM-Pruner 都能提供自动化且便捷的解决方案,大幅减少人工干预,助力高效构建轻量级大模型应用。
使用场景
某电商初创团队计划将 Llama-3-8B 模型部署到本地边缘服务器以构建私有客服机器人,但面临显存不足和推理成本过高的严峻挑战。
没有 LLM-Pruner 时
- 原始 8B 模型体积庞大,需要昂贵的多卡 GPU 集群才能勉强运行,硬件预算超支。
- 推理延迟高达数秒,用户等待时间过长,严重影响客服交互体验。
- 若强行蒸馏为小模型,会丢失关键逻辑处理能力,导致回答质量大幅下降。
- 缺乏高效的压缩方案,团队只能在“高性能高成本”与“低成本低性能”之间妥协。
使用 LLM-Pruner 后
- LLM-Pruner 通过结构剪枝将模型压缩至 4B 规模,显存占用减少近 50%,单卡即可流畅部署。
- 仅需 5 万条公开样本进行后训练,便保留了原模型在问答场景下的核心逻辑与准确性。
- 推理速度提升明显,响应时间缩短至毫秒级,满足了实时对话的流畅性要求。
- 自动化剪枝流程无需大量人工干预,团队在三天内完成了模型适配并上线测试。
LLM-Pruner 成功实现了大模型的结构化压缩,让高性能模型在资源受限环境下也能低成本落地。
运行环境要求
- 未说明
需要 NVIDIA GPU 及 CUDA 环境,Taylor 剪枝法需较大显存,具体视模型规模而定
未说明

快速开始

LLM-Pruner
关于大语言模型 (LLM) 的结构化剪枝 (Structural Pruning)
:llama: :llama: :llama: :llama: :llama: 将您的 LLM 压缩至任意规模!:llama: :llama: :llama: :llama: :llama:
简介
LLM-Pruner: On the Structural Pruning of Large Language Models [arXiv]
Xinyin Ma, Gongfan Fang, Xinchao Wang
新加坡国立大学 (National University of Singapore)
为什么选择 LLM-Pruner
- 任务无关的压缩 (Task-agnostic compression):压缩后的 LLM 应保留其作为多任务求解器的原始能力。
- 较少的训练语料 (Less training corpus):在本工作中,我们仅使用 5 万条公开可用的样本 (alpaca) 对 LLM 进行后训练 (Post-training)。
- 高效压缩 (Efficient compression):剪枝耗时 3 分钟,后训练耗时 3 小时。(您可以根据需要延长)
- 自动结构化剪枝 (Automatic structural pruning):以最少的人工干预剪枝新的 LLM。(进行中)。
支持的 LLM:
更新日志:
- 2024 年 7 月 27 日::rocket: 支持 GQA (群查询注意力)! 现在 LLM-Pruner 可以在 Llama3 和 Llama 3.1 上运行。我们仍在测试新 LLM(Llama3, Llama3.1, Gemma)的剪枝结果,您可以在 此处 找到剪枝结果。
- 2023 年 8 月 30 日:LLM-Pruner 现在支持 BLOOM :cherry_blossom:
- 2023 年 8 月 14 日:代码 和 结果 现已支持使用大规模语料进行微调 (Finetuning)。微调后的 LLaMA-5.4B 模型平均准确率达到 62.36%,非常接近原始 LLaMA-7B (63.25%)。
- 2023 年 7 月 19 日::fire: LLM-Pruner 现在支持 Llama-2-7b 和 Llama-2-13b(Huggingface 版本)
- 2023 年 7 月 18 日::rocket: 支持 Baichuan,一款双语 LLM。
- 2023 年 5 月 20 日::tada: 代码和预印本论文发布!
待办事项 (TODO List):
- 针对新 LLM 剪枝的教程。
- 支持使用
.from_pretrained()加载模型。
联系我们:
加入我们的微信群进行交流:
目录
快速开始
安装
pip install -r requirement.txt
最小示例
bash script/llama_prune.sh
此脚本将压缩 LLaMA-7B 模型,剪去约 20% 的参数。所有预训练模型和数据集都将自动下载,因此您无需手动下载资源。首次运行此脚本时,需要一些时间来下载模型和数据集。
逐步说明
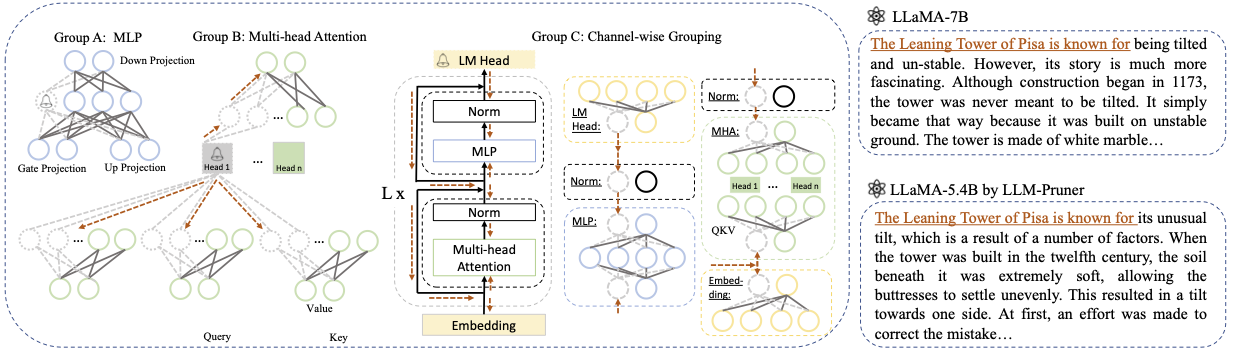
剪枝一个 LLM 需要三个步骤:
- 发现阶段 (Discovery Stage):发现 LLM 中复杂的相互依赖关系,并找到可移除的最小单元,即组 (group)。
- 估计阶段 (Estimation Stage):估计每个组对模型整体性能的贡献,并决定剪枝哪个组。
- 恢复阶段 (Recover Stage):通过快速后训练恢复模型性能。
剪枝和后训练完成后,我们遵循 lm-evaluation-harness 进行评估。
1. 剪枝(发现阶段 + 估计阶段)
:llama: LLaMA/Llama-2 模型剪枝,约剪去 20% 参数:
python hf_prune.py --pruning_ratio 0.25 \
--block_wise \
--block_mlp_layer_start 4 --block_mlp_layer_end 30 \
--block_attention_layer_start 4 --block_attention_layer_end 30 \
--pruner_type taylor \
--test_after_train \
--device cpu --eval_device cuda \
--save_ckpt_log_name llama_prune
参数说明:
基础模型:从 LLaMA 或 Llama-2 中选择基础模型,并将pretrained_model_name_or_path传递给--base_model。模型名称用于AutoModel.from_pretrained加载预训练的大语言模型(LLM)。例如,如果你想使用 130 亿参数的 llama-2,则将meta-llama/Llama-2-13b-hf传递给--base_model。剪枝策略:使用相应的命令选项选择块级(block-wise)、通道级(channel-wise)或层级(layer-wise)剪枝:{--block_wise},{--channel_wise},{--layer_wise --layer NUMBER_OF_LAYERS}。对于块级剪枝,指定要剪枝的起始和结束层。通道级剪枝不需要额外参数。对于层级剪枝,使用 --layer NUMBER_OF_LAYERS 指定剪枝后保留的层数。重要性准则:使用 --pruner_type 参数从 l1, l2, random 或 taylor 中选择。对于泰勒剪枝器(Taylor pruner),选择以下选项之一:vectorize, param_second, param_first, param_mix。默认使用 param_mix,它结合了近似二阶海森矩阵(Hessian)和一阶梯度(Gradient)。如果使用 l1, l2 或 random,则不需要额外参数。剪枝比例:指定组的剪枝比例。它与参数剪枝率不同,因为组是最小的移除单位。设备和评估设备:剪枝和评估可以在不同的设备上执行。基于泰勒的方法在剪枝期间需要反向计算,这可能需要大量的 GPU 显存。我们的实现使用 CPU 进行重要性估计(也支持 GPU,只需使用 --device cuda)。eval_device 用于测试剪枝后的模型。
:llama: Vicuna 剪枝
详情:
如果你想尝试 Vicuna,请将参数 --base_model 指定为 Vicuna 权重的路径。请遵循 https://github.com/lm-sys/FastChat 获取 Vicuna 权重。
python hf_prune.py --pruning_ratio 0.25 \
--block_wise \
--block_mlp_layer_start 4 --block_mlp_layer_end 30 \
--block_attention_layer_start 4 --block_attention_layer_end 30 \
--pruner_type taylor \
--test_after_train \
--device cpu --eval_device cuda \
--save_ckpt_log_name llama_prune \
--base_model PATH_TO_VICUNA_WEIGHTS
:llama: Baichuan 剪枝
详情:
有关更多详细信息,请参阅 Example/Baichuan。
:llama: Llama3/Llama3.1 剪枝
详情:
python llama3.py --pruning_ratio 0.25 \
--device cuda --eval_device cuda \
--base_model meta-llama/Meta-Llama-3-8B-Instruct \
--block_wise --block_mlp_layer_start 4 --block_mlp_layer_end 30 \
--block_attention_layer_start 4 --block_attention_layer_end 30 \
--save_ckpt_log_name llama3_prune \
--pruner_type taylor --taylor param_first \
--max_seq_len 2048 \
--test_after_train --test_before_train --save_model
2. 后训练(恢复阶段)
- 使用 Alpaca 进行训练,包含 50,000 个样本。以下是单 GPU 训练的示例:
CUDA_VISIBLE_DEVICES=X python post_training.py --prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin \
--data_path yahma/alpaca-cleaned \
--lora_r 8 \
--num_epochs 2 \
--learning_rate 1e-4 \
--batch_size 64\
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL \
--wandb_project llama_tune
请确保将 PATH_TO_PRUNE_MODEL 替换为步骤 1 中剪枝模型的路径,并将 PATH_TO_SAVE_TUNE_MODEL 替换为你希望保存微调模型的位置。
提示:在 float16 下训练 LLaMA-2 不推荐,已知会产生 nan;因此,模型应在 bfloat16 下训练。
- 使用 MBZUAI/LaMini-instruction 进行训练,包含 2.59M 个样本。以下是使用多 GPU 进行训练的示例:
deepspeed --include=localhost:1,2,3,4 post_training.py \
--prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin \
--data_path MBZUAI/LaMini-instruction \
--lora_r 8 \
--num_epochs 3 \
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL \
--extra_val_dataset wikitext2,ptb \
--wandb_project llmpruner_lamini_tune \
--learning_rate 5e-5 \
--cache_dataset
3. 生成
如何加载剪枝/预训练模型:
对于剪枝模型,只需使用以下命令加载你的模型。
pruned_dict = torch.load(YOUR_CHECKPOINT_PATH, map_location='cpu')
tokenizer, model = pruned_dict['tokenizer'], pruned_dict['model']
由于剪枝模型中模块之间的配置不同,某些层可能具有更大的宽度,而其他层则经过了更多的剪枝,因此无法像 Hugging Face 提供的那样使用 .from_pretrained() 加载模型。目前,我们采用 torch.save 来存储剪枝模型。
由于剪枝模型在每一层的配置不同,比如某些层可能更宽,但某些层被剪枝得更多,模型无法通过 Hugging Face 的 .from_pretrained() 加载。目前,我们简单地使用 torch.save 保存剪枝模型,并使用 torch.load 加载剪枝模型。
使用 Gradio 界面进行生成
我们提供了一个简单的脚本,用于使用预训练/剪枝模型/经过后训练的剪枝模型生成文本。
- LLaMA-7B 预训练模型
python generate.py --model_type pretrain
- 未经过后训练的剪枝模型
python generate.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
- 经过后训练的剪枝模型
python generate.py --model_type tune_prune_LLM --ckpt <YOUR_CKPT_PATH_FOR_PRUNE_MODEL> --lora_ckpt <YOUR_CKPT_PATH_FOR_LORA_WEIGHT>
上述指令将在本地部署您的大语言模型(LLM)。
4. 评估
为了评估剪枝模型(pruned model)的性能,我们遵循 lm-evaluation-harness(语言模型评估工具集) 来评估模型:
- 步骤 1:如果您只需要评估剪枝模型,请跳过此步骤并跳转到步骤 2。
此步骤是为了整理文件以满足
lm-evaluation-harness的输入要求。来自后训练阶段的微调检查点 将按以下格式保存:
- PATH_TO_SAVE_TUNE_MODEL
| - checkpoint-200
| - pytorch_model.bin
| - optimizer.pt
...
| - checkpoint-400
| - checkpoint-600
...
| - adapter_config.bin
| - adapter-config.json
通过以下命令整理文件:
cd PATH_TO_SAVE_TUNE_MODEL
export epoch=YOUR_EVALUATE_EPOCH
cp adapter_config.json checkpoint-$epoch/
mv checkpoint-$epoch/pytorch_model.bin checkpoint-$epoch/adapter_model.bin
如果您想评估 checkpoint-200,则通过 export epoch=200 将 epoch(轮次)设置为 200。
- 步骤 2:
export PYTHONPATH='.'
python lm-evaluation-harness/main.py --model hf-causal-experimental \
--model_args checkpoint=PATH_TO_PRUNE_MODEL,peft=PATH_TO_SAVE_TUNE_MODEL,config_pretrained=PATH_OR_NAME_TO_BASE_MODEL \
--tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq \
--device cuda:0 --no_cache \
--output_path PATH_TO_SAVE_EVALUATION_LOG
在此处,将 PATH_TO_PRUNE_MODEL 和 PATH_TO_SAVE_TUNE_MODEL 替换为您保存剪枝模型和微调模型的路径,而 PATH_OR_NAME_TO_BASE_MODEL 用于加载基础模型的配置文件。
[更新]:如果您想使用微调检查点评估剪枝模型,我们上传了一个脚本来简化评估过程。直接使用以下命令:
CUDA_VISIBLE_DEVICES=X bash scripts/evaluate.sh PATH_OR_NAME_TO_BASE_MODEL PATH_TO_SAVE_TUNE_MODEL PATH_TO_PRUNE_MODEL EPOCHS_YOU_WANT_TO_EVALUATE
在命令中替换您模型的必要信息。最后一个参数用于在一个命令中迭代不同的 epoch,以便评估多个检查点。例如:
CUDA_VISIBLE_DEVICES=1 bash scripts/evaluate.sh decapoda-research/llama-7b-hf tune_log/llama_7B_hessian prune_log/llama_prune_7B 200 1000 2000
5. 测试 MACs(乘加运算次数)、Params(参数量)和内存
- 预训练
python test_speedup.py --model_type pretrain
- 剪枝模型
python test_speedup.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
零样本 (Zero-shot) 评估
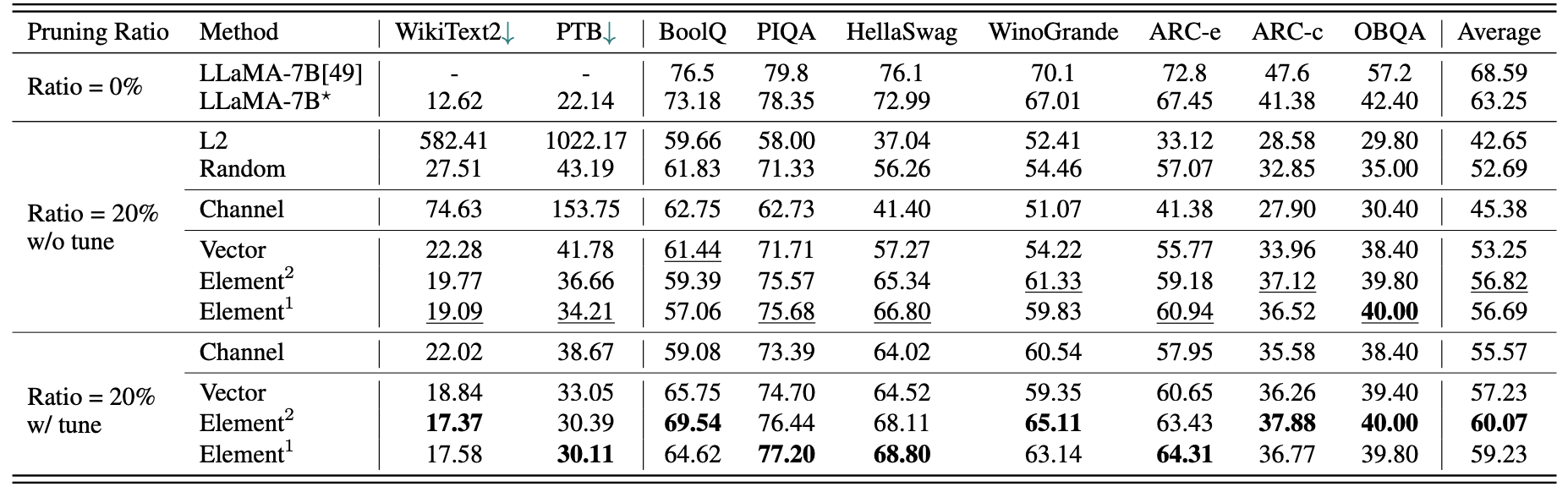
LLaMA-7B 的简要定量结果:
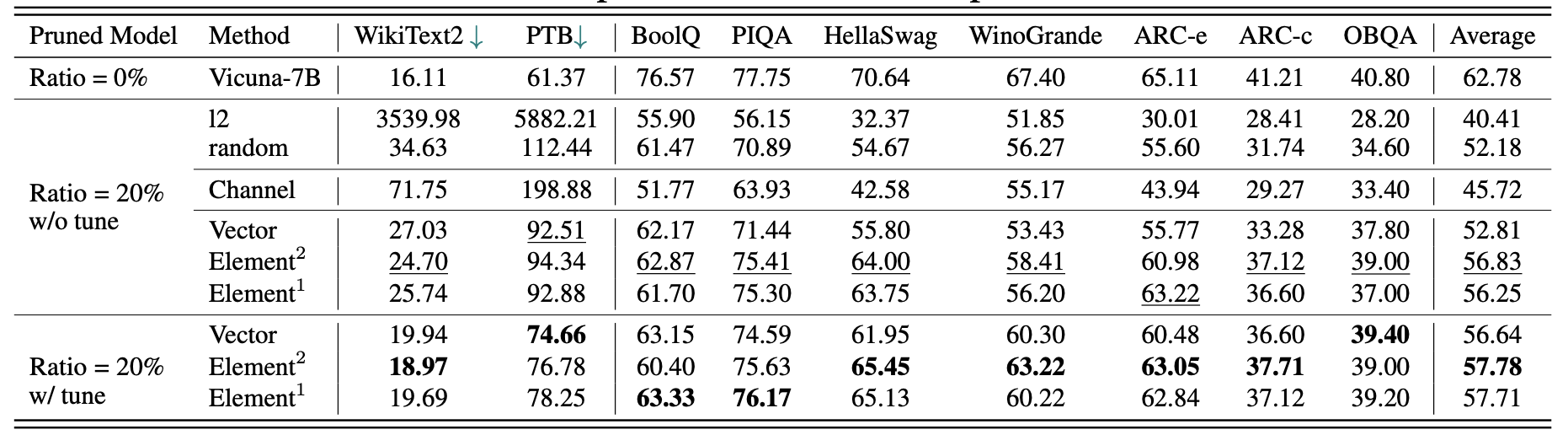
Vicuna-7B 的结果:
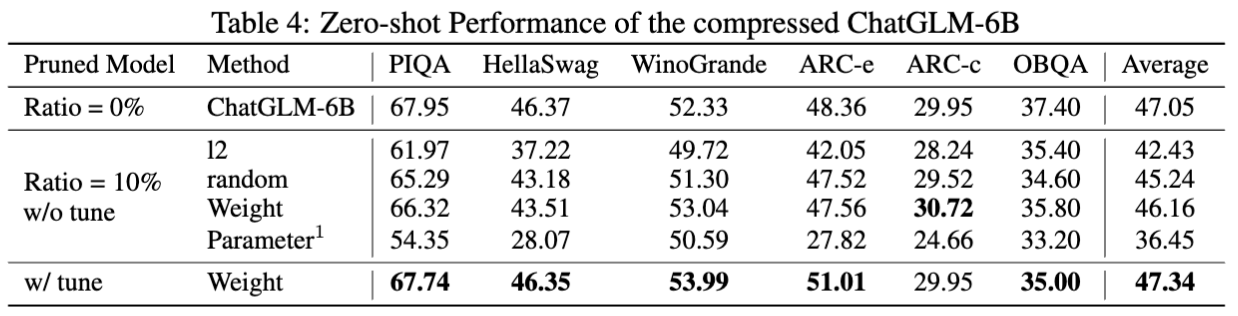
ChatGLM-6B 的结果:
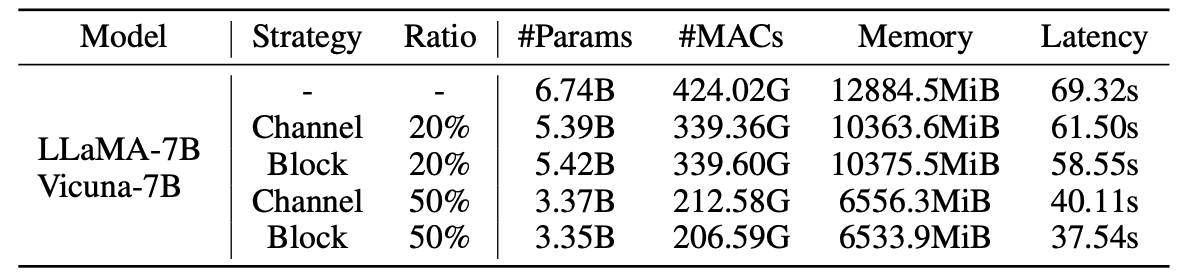
剪枝模型的统计数据:
LLM-Pruner 使用 2.59M 样本的结果:
| 剪枝比例 | 参数量 | 内存 | 延迟 | 加速比 | BoolQ | PIQA | HellaSwag | WinoGrande | ARC-e | ARC-c | OBQA | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA-7B | 6.74B | 12884.5MiB | 69.32s | 1x | 73.18 | 78.35 | 72.99 | 67.01 | 67.45 | 41.38 | 42.40 | 63.25 |
| LLaMA-5.4B with Alpaca(50k) | 5.47B | 10488.4MiB | 58.55s | 1.18x | 64.62 | 77.20 | 68.80 | 63.14 | 64.31 | 36.77 | 39.80 | 59.23 |
| LLaMA-5.4B with LaMini(2.59M) | 5.47B | 10488.4MiB | 58.55s | 1.18x | 76.57 | 77.37 | 66.60 | 65.82 | 70.62 | 40.70 | 38.80 | 62.36 |
更多结果可在论文中找到。
更多示例
| 原始模型 | 输出 | 剪枝模型 | 输出 |
|---|---|---|---|
| LLaMa-7B | The universe is the entirety of space, time, matter, and energy that exists. It includes all matter and energy, whether visible or not, and in fact the whole universe is invisible. There are many theories regarding its origin and ultimate fate... | LLaMa-5.4B | The universe is the entirety of space, time, matter, and energy that exists. The laws that make up physics — electrons orbiting atoms, magnets attracting other objects, planets orbiting the Sun—have been consistent over ... |
| Vicuna-7B | 10 steps to build an ios app: 1. Research and develop the idea. 2. Decide on the platform you want to use (iOS, Android, or both). 3. Create a plan and budget. 4. Hire a team of developers. 5. Design the user interface (UI). 6. Develop the user interface (UI). 7. Test and iterate on the app. 8. Submit the app to the app store. 9. Optimize the app for performance and user experience (UX). 10. Market and promote the app. | Vicuna-5.4B | 10 steps to build an ios app: 1. Plan your app: decide what it should do, what it will look like, and what it will cost to build it. 2. Hire a developer: A good iOS developer will help you design the user interface, create the app, and make sure it's bug-free. 3. Create a user interface: This is where the magic happens. Your app's user interface will be designed and mocked up at this point... |
| ChatGLM-6B | Write a poetry about love and peace. In the midst of life's hustle and bustle, I find your love a soothing peace. It is a feeling that cannot be conveyed, A connection that cannot be distanced. With your smile, your eyes, your embrace, I feel a sense of belonging that only you can give. It is a love that lasts forever, A love that cannot be defeat... | ChatGLM-5.6B | Write a poetry about love and peace. Love and peace, two such wonderful things\ A pure and endless desire in my heart\ And both of them, I must seek for\ A long, long time, I know..\ Love, I know, is a feeling of being\ A perfect partner, in every sense\ And peace, I need it, so much, one day\ A long, long way, my heart will go.. |
版本信息
由于本项目使用的模型和仓库版本发生变化,我们列出了一些已知的版本问题以及复现我们方法所需的具体版本:
- lm-eval-harness:我们使用了 lm-evaluation-harness 的 此 commit,代码也包含在此仓库中。详细信息请查看 Issue #25。
- LLaMA1-7B:我们在实验中使用的是 decapoda-research/llama-7b-hf 的检查点,目前该链接不可用。请考虑使用复制的版本,例如 baffo32/decapoda-research-llama-7B-hf。
局限性
- 尽管我们仅使用了 5 万条数据并训练了三个小时,但更多的数据肯定会更好。我们正在对此进行测试。
- 当前的压缩模型仍然存在一些问题,例如生成重复的 token(词元) 或产生无意义的句子。我们相信压缩模型的质量还有很大的提升空间。
- 仍然有一些模型,我们无法在 concatenation(拼接) 和 view(视图) 操作后自动识别索引的映射关系。因此,我们需要执行额外的手动操作。
致谢
- Logo 由 Stable Diffusion 生成
- 大语言模型 (LLM) 评估: lm-evaluation-harness
- LLaMA: https://github.com/facebookresearch/llama
- Vicuna: https://github.com/lm-sys/FastChat
- Peft: https://github.com/huggingface/peft
- Alpaca-lora: https://github.com/tloen/alpaca-lora
引用
如果您觉得本项目有用,请引用
@inproceedings{ma2023llmpruner,
title={LLM-Pruner: On the Structural Pruning of Large Language Models},
author={Xinyin Ma and Gongfan Fang and Xinchao Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2023},
}
@article{fang2023depgraph,
title={DepGraph: Towards Any Structural Pruning},
author={Fang, Gongfan and Ma, Xinyin and Song, Mingli and Mi, Michael Bi and Wang, Xinchao},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。